 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Grid Hopping: Accelerating Direct Estimation Algorithms for Multistatic FMCW Radar
Jul 31, 2023
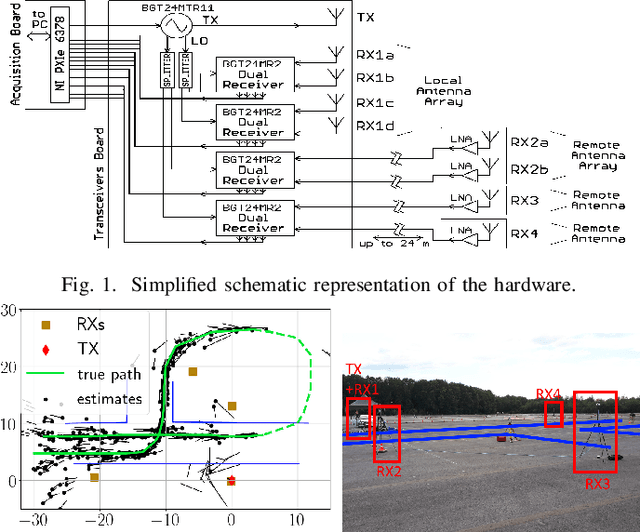
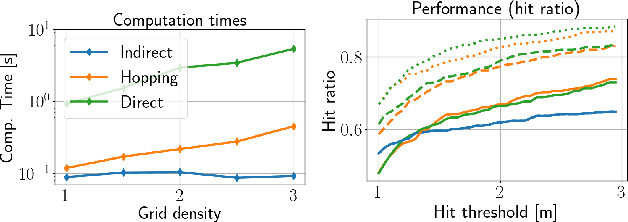
This paper presents a novel signal processing technique, coined grid hopping, as well as an active multistatic Frequency-Modulated Continuous Wave (FMCW) radar system designed to evaluate its performance. The design of grid hopping is motivated by two existing estimation algorithms. The first one is the indirect algorithm estimating ranges and speeds separately for each received signal, before combining them to obtain location and velocity estimates. The second one is the direct method jointly processing the received signals to directly estimate target location and velocity. While the direct method is known to provide better performance, it is seldom used because of its high computation time. Our grid hopping approach, which relies on interpolation strategies, offers a reduced computation time while its performance stays on par with the direct method. We validate the efficiency of this technique on actual FMCW radar measurements and compare it with other methods.
SLoRA: Federated Parameter Efficient Fine-Tuning of Language Models
Aug 12, 2023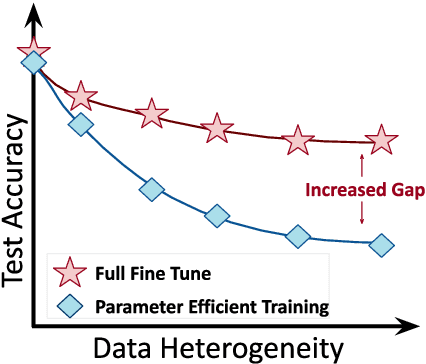
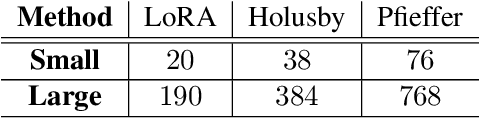
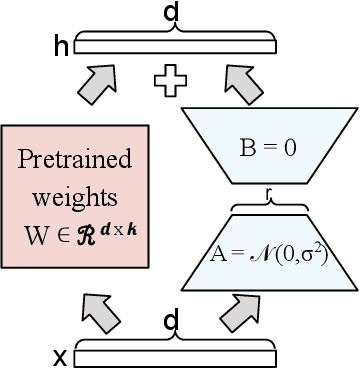
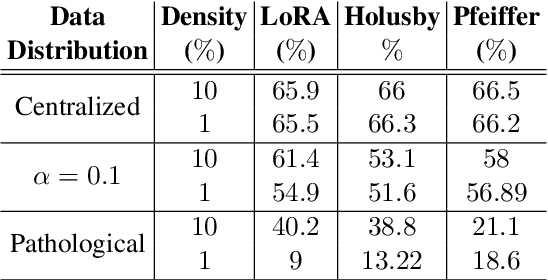
Transfer learning via fine-tuning pre-trained transformer models has gained significant success in delivering state-of-the-art results across various NLP tasks. In the absence of centralized data, Federated Learning (FL) can benefit from distributed and private data of the FL edge clients for fine-tuning. However, due to the limited communication, computation, and storage capabilities of edge devices and the huge sizes of popular transformer models, efficient fine-tuning is crucial to make federated training feasible. This work explores the opportunities and challenges associated with applying parameter efficient fine-tuning (PEFT) methods in different FL settings for language tasks. Specifically, our investigation reveals that as the data across users becomes more diverse, the gap between fully fine-tuning the model and employing PEFT methods widens. To bridge this performance gap, we propose a method called SLoRA, which overcomes the key limitations of LoRA in high heterogeneous data scenarios through a novel data-driven initialization technique. Our experimental results demonstrate that SLoRA achieves performance comparable to full fine-tuning, with significant sparse updates with approximately $\sim 1\%$ density while reducing training time by up to $90\%$.
Distributionally Robust Optimization and Invariant Representation Learning for Addressing Subgroup Underrepresentation: Mechanisms and Limitations
Aug 12, 2023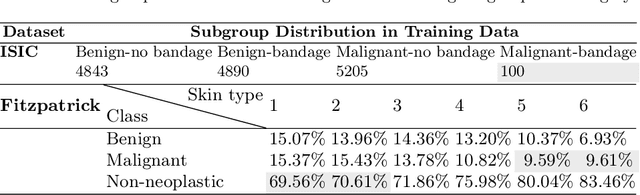
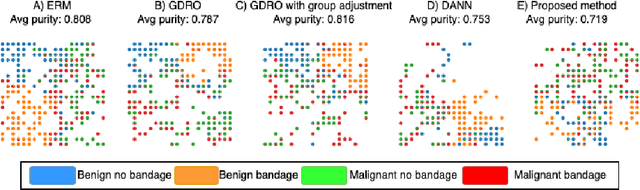
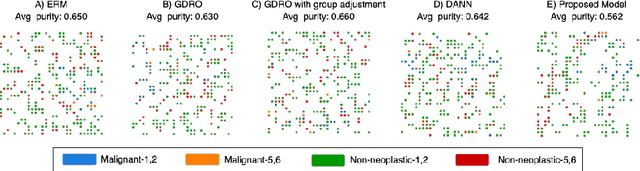
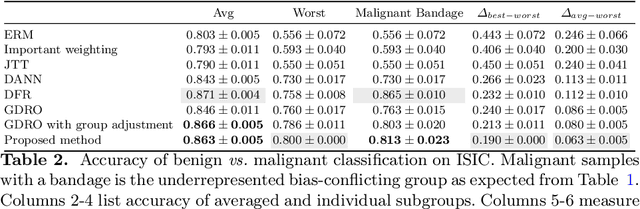
Spurious correlation caused by subgroup underrepresentation has received increasing attention as a source of bias that can be perpetuated by deep neural networks (DNNs). Distributionally robust optimization has shown success in addressing this bias, although the underlying working mechanism mostly relies on upweighting under-performing samples as surrogates for those underrepresented in data. At the same time, while invariant representation learning has been a powerful choice for removing nuisance-sensitive features, it has been little considered in settings where spurious correlations are caused by significant underrepresentation of subgroups. In this paper, we take the first step to better understand and improve the mechanisms for debiasing spurious correlation due to subgroup underrepresentation in medical image classification. Through a comprehensive evaluation study, we first show that 1) generalized reweighting of under-performing samples can be problematic when bias is not the only cause for poor performance, while 2) naive invariant representation learning suffers from spurious correlations itself. We then present a novel approach that leverages robust optimization to facilitate the learning of invariant representations at the presence of spurious correlations. Finetuned classifiers utilizing such representation demonstrated improved abilities to reduce subgroup performance disparity, while maintaining high average and worst-group performance.
Causal Discovery from Subsampled Time Series with Proxy Variables
May 09, 2023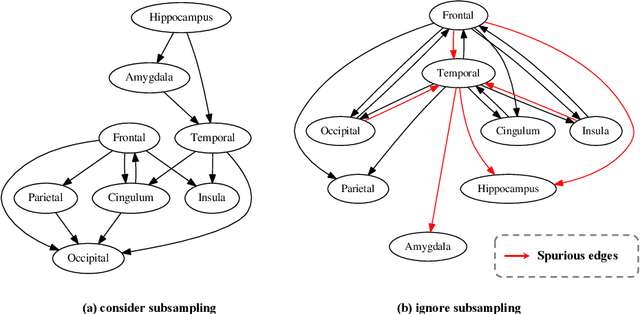

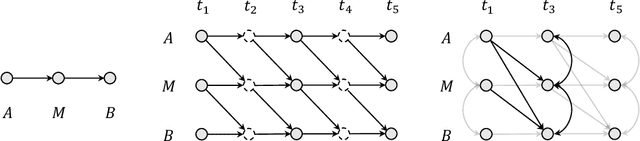
Inferring causal structures from time series data is the central interest of many scientific inquiries. A major barrier to such inference is the problem of subsampling, i.e., the frequency of measurements is much lower than that of causal influence. To overcome this problem, numerous model-based and model-free methods have been proposed, yet either limited to the linear case or failed to establish identifiability. In this work, we propose a model-free algorithm that can identify the entire causal structure from subsampled time series, without any parametric constraint. The idea is that the challenge of subsampling arises mainly from \emph{unobserved} time steps and therefore should be handled with tools designed for unobserved variables. Among these tools, we find the proxy variable approach particularly fits, in the sense that the proxy of an unobserved variable is naturally itself at the observed time step. Following this intuition, we establish comprehensive structural identifiability results. Our method is constraint-based and requires no more regularities than common continuity and differentiability. Theoretical advantages are reflected in experimental results.
Updating Clinical Risk Stratification Models Using Rank-Based Compatibility: Approaches for Evaluating and Optimizing Clinician-Model Team Performance
Aug 10, 2023As data shift or new data become available, updating clinical machine learning models may be necessary to maintain or improve performance over time. However, updating a model can introduce compatibility issues when the behavior of the updated model does not align with user expectations, resulting in poor user-model team performance. Existing compatibility measures depend on model decision thresholds, limiting their applicability in settings where models are used to generate rankings based on estimated risk. To address this limitation, we propose a novel rank-based compatibility measure, $C^R$, and a new loss function that aims to optimize discriminative performance while encouraging good compatibility. Applied to a case study in mortality risk stratification leveraging data from MIMIC, our approach yields more compatible models while maintaining discriminative performance compared to existing model selection techniques, with an increase in $C^R$ of $0.019$ ($95\%$ confidence interval: $0.005$, $0.035$). This work provides new tools to analyze and update risk stratification models used in clinical care.
Who Answers It Better? An In-Depth Analysis of ChatGPT and Stack Overflow Answers to Software Engineering Questions
Aug 10, 2023Over the last decade, Q&A platforms have played a crucial role in how programmers seek help online. The emergence of ChatGPT, however, is causing a shift in this pattern. Despite ChatGPT's popularity, there hasn't been a thorough investigation into the quality and usability of its responses to software engineering queries. To address this gap, we undertook a comprehensive analysis of ChatGPT's replies to 517 questions from Stack Overflow (SO). We assessed the correctness, consistency, comprehensiveness, and conciseness of these responses. Additionally, we conducted an extensive linguistic analysis and a user study to gain insights into the linguistic and human aspects of ChatGPT's answers. Our examination revealed that 52% of ChatGPT's answers contain inaccuracies and 77% are verbose. Nevertheless, users still prefer ChatGPT's responses 39.34% of the time due to their comprehensiveness and articulate language style. These findings underscore the need for meticulous error correction in ChatGPT while also raising awareness among users about the potential risks associated with seemingly accurate answers.
Enhancing Trust in LLM-Based AI Automation Agents: New Considerations and Future Challenges
Aug 10, 2023

Trust in AI agents has been extensively studied in the literature, resulting in significant advancements in our understanding of this field. However, the rapid advancements in Large Language Models (LLMs) and the emergence of LLM-based AI agent frameworks pose new challenges and opportunities for further research. In the field of process automation, a new generation of AI-based agents has emerged, enabling the execution of complex tasks. At the same time, the process of building automation has become more accessible to business users via user-friendly no-code tools and training mechanisms. This paper explores these new challenges and opportunities, analyzes the main aspects of trust in AI agents discussed in existing literature, and identifies specific considerations and challenges relevant to this new generation of automation agents. We also evaluate how nascent products in this category address these considerations. Finally, we highlight several challenges that the research community should address in this evolving landscape.
Deep Fusion Transformer Network with Weighted Vector-Wise Keypoints Voting for Robust 6D Object Pose Estimation
Aug 10, 2023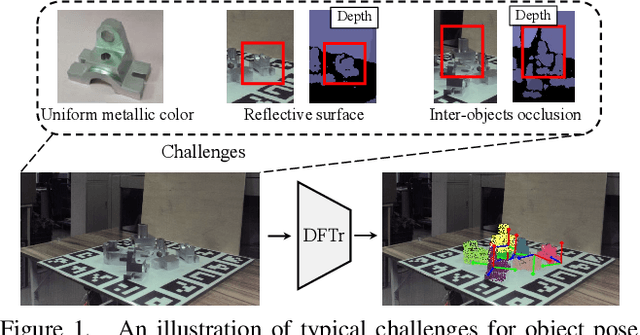
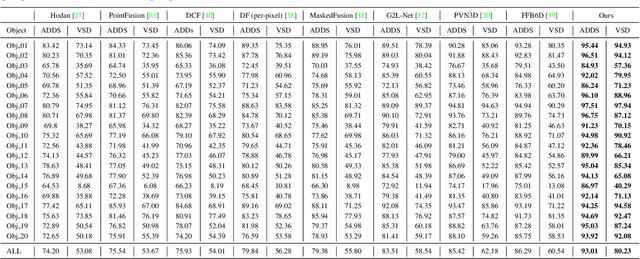
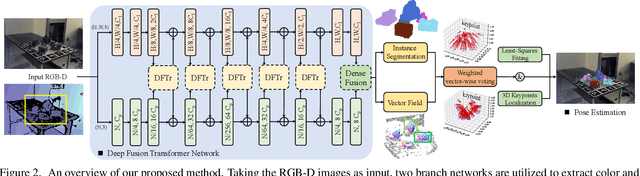
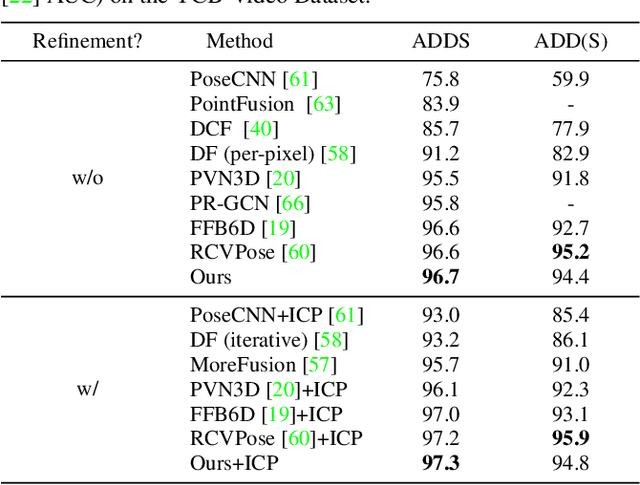
One critical challenge in 6D object pose estimation from a single RGBD image is efficient integration of two different modalities, i.e., color and depth. In this work, we tackle this problem by a novel Deep Fusion Transformer~(DFTr) block that can aggregate cross-modality features for improving pose estimation. Unlike existing fusion methods, the proposed DFTr can better model cross-modality semantic correlation by leveraging their semantic similarity, such that globally enhanced features from different modalities can be better integrated for improved information extraction. Moreover, to further improve robustness and efficiency, we introduce a novel weighted vector-wise voting algorithm that employs a non-iterative global optimization strategy for precise 3D keypoint localization while achieving near real-time inference. Extensive experiments show the effectiveness and strong generalization capability of our proposed 3D keypoint voting algorithm. Results on four widely used benchmarks also demonstrate that our method outperforms the state-of-the-art methods by large margins.
Enhancing Generalization of Universal Adversarial Perturbation through Gradient Aggregation
Aug 11, 2023Deep neural networks are vulnerable to universal adversarial perturbation (UAP), an instance-agnostic perturbation capable of fooling the target model for most samples. Compared to instance-specific adversarial examples, UAP is more challenging as it needs to generalize across various samples and models. In this paper, we examine the serious dilemma of UAP generation methods from a generalization perspective -- the gradient vanishing problem using small-batch stochastic gradient optimization and the local optima problem using large-batch optimization. To address these problems, we propose a simple and effective method called Stochastic Gradient Aggregation (SGA), which alleviates the gradient vanishing and escapes from poor local optima at the same time. Specifically, SGA employs the small-batch training to perform multiple iterations of inner pre-search. Then, all the inner gradients are aggregated as a one-step gradient estimation to enhance the gradient stability and reduce quantization errors. Extensive experiments on the standard ImageNet dataset demonstrate that our method significantly enhances the generalization ability of UAP and outperforms other state-of-the-art methods. The code is available at https://github.com/liuxuannan/Stochastic-Gradient-Aggregation.
Spatiotemporal Receding Horizon Control with Proactive Interaction Towards Safe and Efficient Autonomous Driving in Dense Traffic
Aug 11, 2023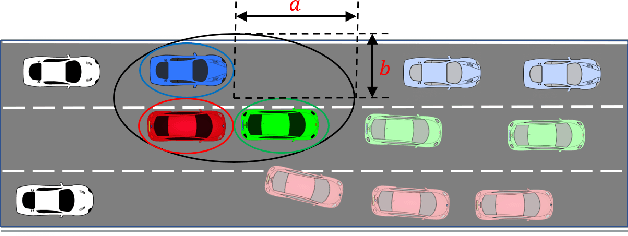
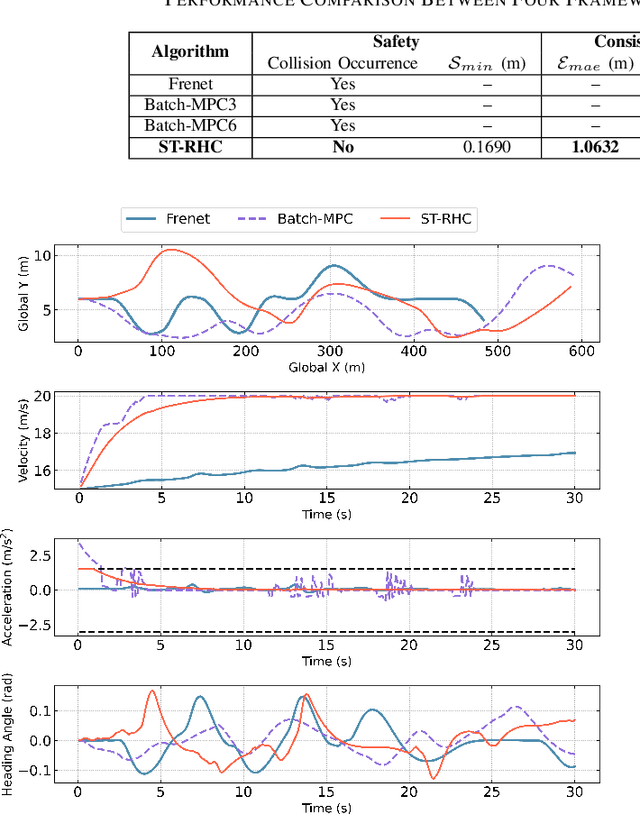
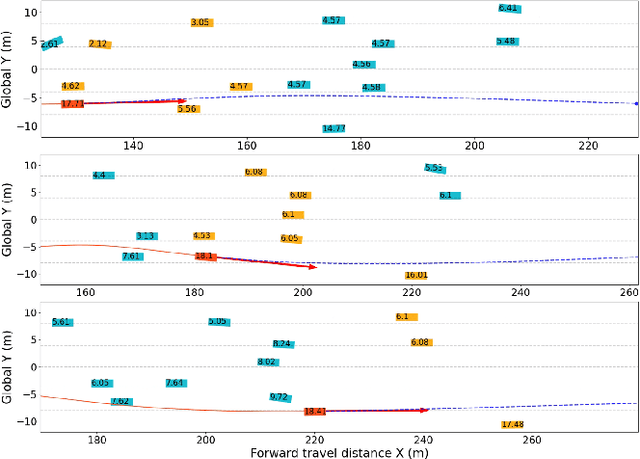
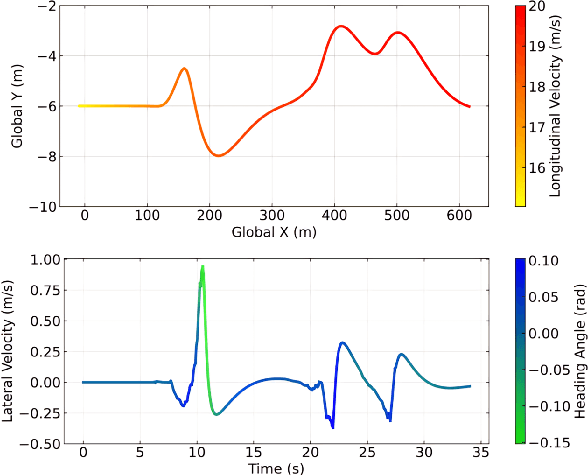
In dense traffic scenarios, ensuring safety while keeping high task performance for autonomous driving is a critical challenge. To address this problem, this paper proposes a computationally-efficient spatiotemporal receding horizon control (ST-RHC) scheme to generate a safe, dynamically feasible, energy-efficient trajectory in control space, where different driving tasks in dense traffic can be achieved with high accuracy and safety in real time. In particular, an embodied spatiotemporal safety barrier module considering proactive interactions is devised to mitigate the effects of inaccuracies resulting from the trajectory prediction of other vehicles. Subsequently, the motion planning and control problem is formulated as a constrained nonlinear optimization problem, which favorably facilitates the effective use of off-the-shelf optimization solvers in conjunction with multiple shooting. The effectiveness of the proposed ST-RHC scheme is demonstrated through comprehensive comparisons with state-of-the-art algorithms on synthetic and real-world traffic datasets under dense traffic, and the attendant outcome of superior performance in terms of accuracy, efficiency and safety is achieved.