 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
General Anomaly Detection of Underwater Gliders Validated by Large-scale Deployment Dataset
Jul 31, 2023
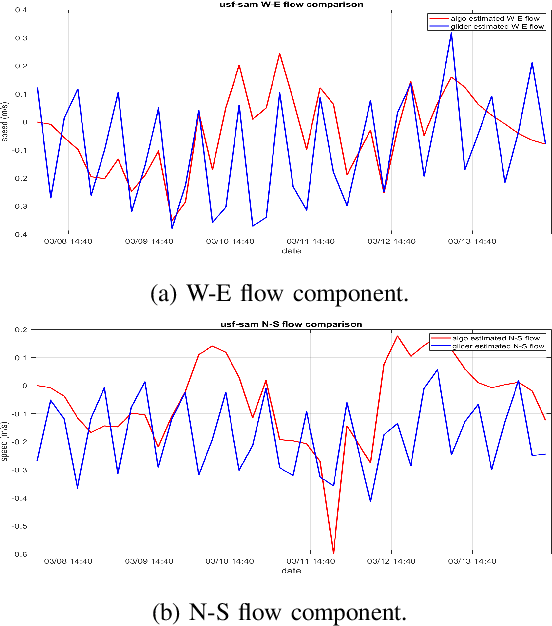
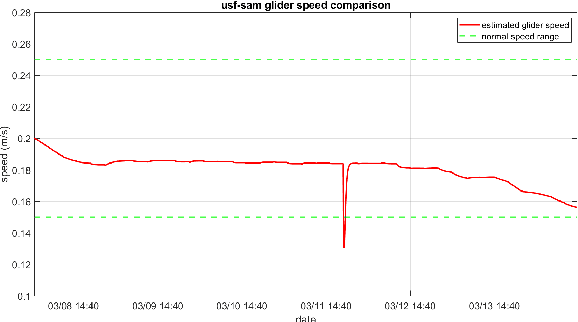
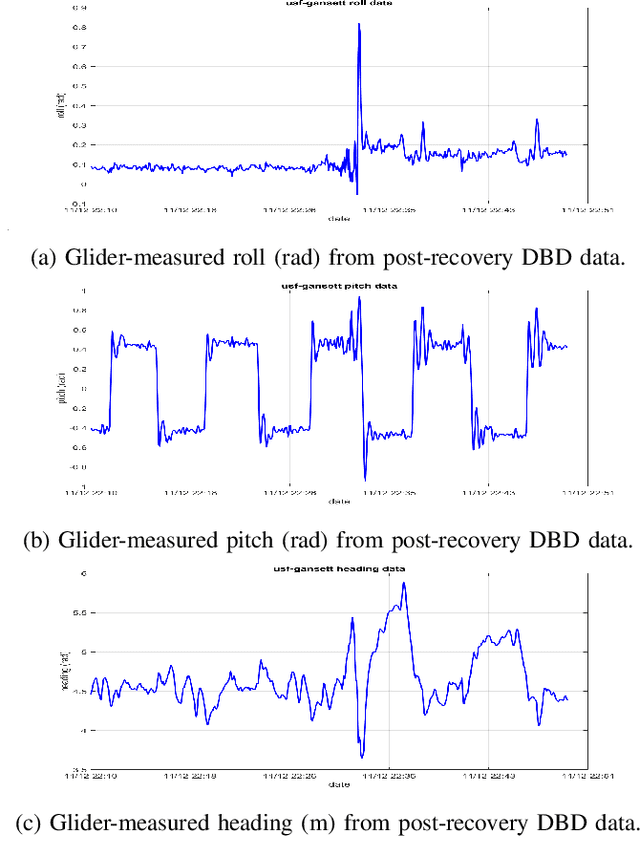

This paper employs an anomaly detection algorithm to assess the normal operation of underwater gliders in unpredictable ocean environments. Real-time alerts can be provided to glider pilots upon detecting any anomalies, enabling them to assume control of the glider and prevent further harm. The detection algorithm is applied to abundant data sets collected in real glider deployments led by the Skidaway Institute of Oceanography (SkIO) and the University of South Florida (USF). Regarding generality, the experimental evaluation is composed of both offline and online detection modes. The offline detection utilizes full post-recovery data sets, which carries high-resolution information, to present detailed analysis of the anomaly and compare it with pilot logs. The online detection focuses on the real-time subsets of data transmitted from the glider at the surfacing events. While the real-time data may not contain as much rich information as the post-recovery data, the online detection is of great importance as it allows glider pilots to monitor potential abnormal conditions in real time.
A Forecaster's Review of Judea Pearl's Causality: Models, Reasoning and Inference, Second Edition, 2009
Aug 10, 2023With the big popularity and success of Judea Pearl's original causality book, this review covers the main topics updated in the second edition in 2009 and illustrates an easy-to-follow causal inference strategy in a forecast scenario. It further discusses some potential benefits and challenges for causal inference with time series forecasting when modeling the counterfactuals, estimating the uncertainty and incorporating prior knowledge to estimate causal effects in different forecasting scenarios.
A GPS Alternative using Electrical Transmission Grids as Precision Timing Networks
Jul 26, 2023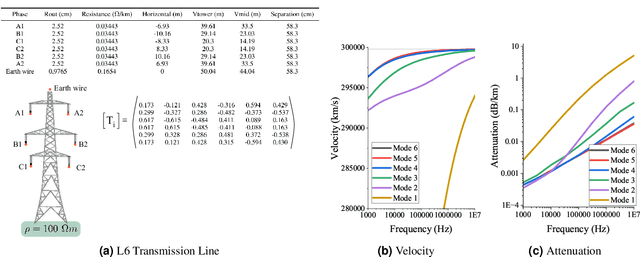
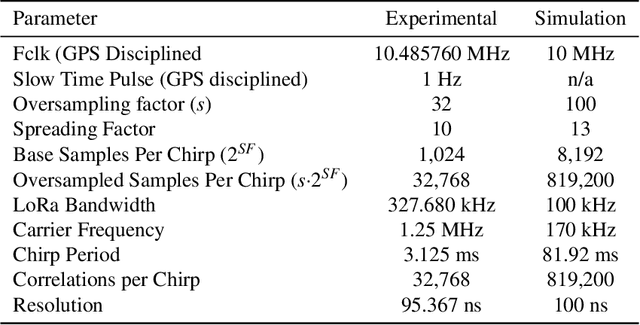
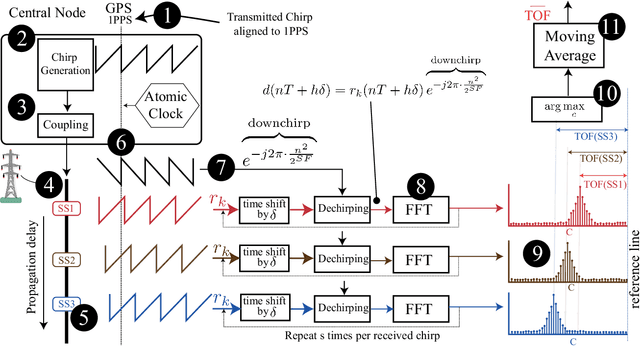
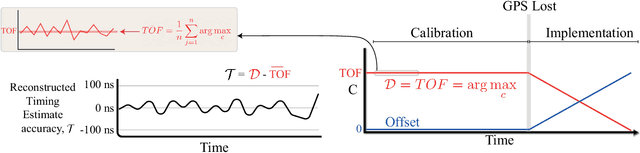
It is widely recognised that over-reliance on GNSS (e.g GPS) for time synchronisation represents an acute threat to modern society, and a diversity of alternatives are required to mitigate the threat of an outage. This paper proposes a GNSS alternative using time dissemination over national scale transmission or distribution networks. The method utilises the same frequency bandwidth and coupling technology as established power line carrier technology in conjunction with modern chirp Spread Spectrum modulation. The basis of the method is the transmission of a time synchronised chirp from a central substation. During GNSS operation, all substations can estimate the time of flight by correlating the received chirp with a time-synchronised local copy. During GNSS outage, time sychronisation to the central substation is maintained by correcting for the precalculated time of flight. It is shown that recent advances in chirp spread spectrum allow for a computationally efficient algorithm with the capacity to compute hundreds of thousand of chirp correlations every second, improving the resolution of the system. ATP-EMTP simulations of the method on large transmission networks demonstrate sub-$\mu$s timing accuracy even in the presence of low SNR and impulsive noise. An FPGA based prototype is developed and experimental testing also demonstrates sub-$\mu$s accuracy for time dissemination over a distance of 700 m. Averaging over time allows operation down to -20 dB, which could extend the range of the system to a national scale.
EndoDepthL: Lightweight Endoscopic Monocular Depth Estimation with CNN-Transformer
Aug 16, 2023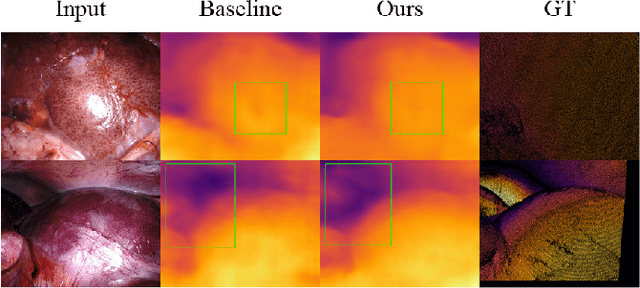
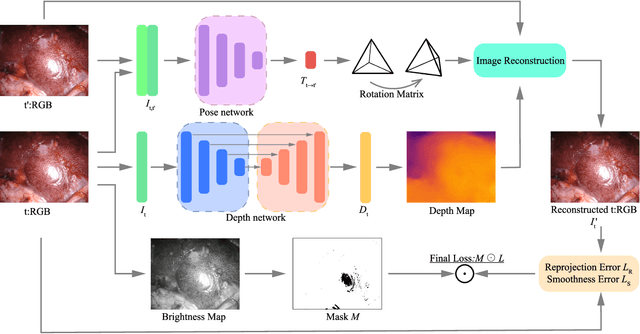
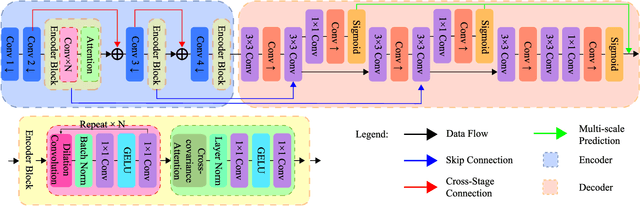
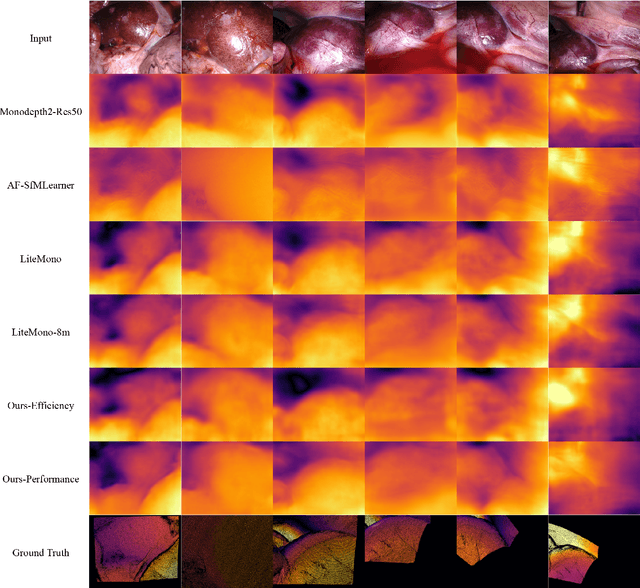
In this study, we address the key challenges concerning the accuracy and effectiveness of depth estimation for endoscopic imaging, with a particular emphasis on real-time inference and the impact of light reflections. We propose a novel lightweight solution named EndoDepthL that integrates Convolutional Neural Networks (CNN) and Transformers to predict multi-scale depth maps. Our approach includes optimizing the network architecture, incorporating multi-scale dilated convolution, and a multi-channel attention mechanism. We also introduce a statistical confidence boundary mask to minimize the impact of reflective areas. To better evaluate the performance of monocular depth estimation in endoscopic imaging, we propose a novel complexity evaluation metric that considers network parameter size, floating-point operations, and inference frames per second. We comprehensively evaluate our proposed method and compare it with existing baseline solutions. The results demonstrate that EndoDepthL ensures depth estimation accuracy with a lightweight structure.
A Survey on Time-Series Pre-Trained Models
May 18, 2023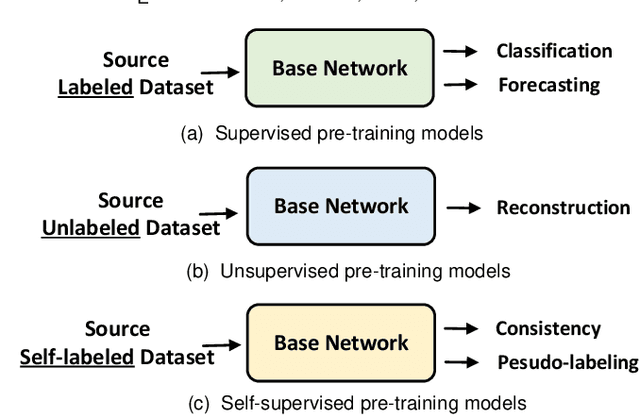

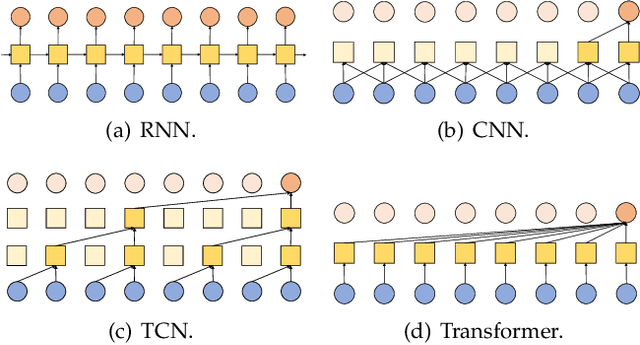

Time-Series Mining (TSM) is an important research area since it shows great potential in practical applications. Deep learning models that rely on massive labeled data have been utilized for TSM successfully. However, constructing a large-scale well-labeled dataset is difficult due to data annotation costs. Recently, Pre-Trained Models have gradually attracted attention in the time series domain due to their remarkable performance in computer vision and natural language processing. In this survey, we provide a comprehensive review of Time-Series Pre-Trained Models (TS-PTMs), aiming to guide the understanding, applying, and studying TS-PTMs. Specifically, we first briefly introduce the typical deep learning models employed in TSM. Then, we give an overview of TS-PTMs according to the pre-training techniques. The main categories we explore include supervised, unsupervised, and self-supervised TS-PTMs. Further, extensive experiments are conducted to analyze the advantages and disadvantages of transfer learning strategies, Transformer-based models, and representative TS-PTMs. Finally, we point out some potential directions of TS-PTMs for future work.
Ahead-of-Time P-Tuning
May 18, 2023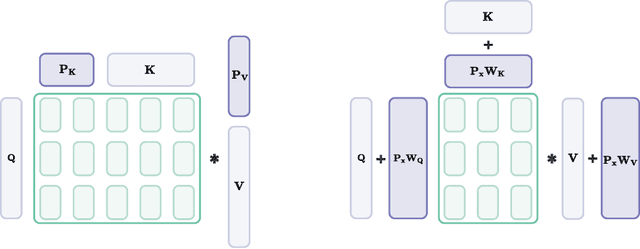
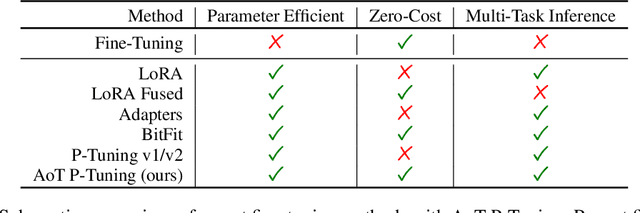
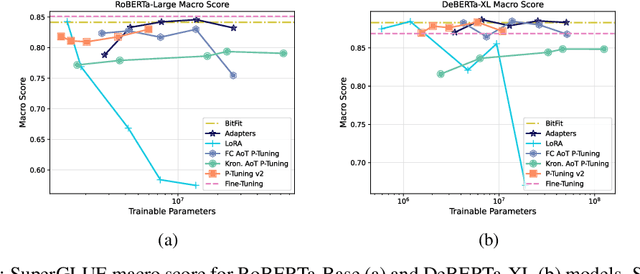
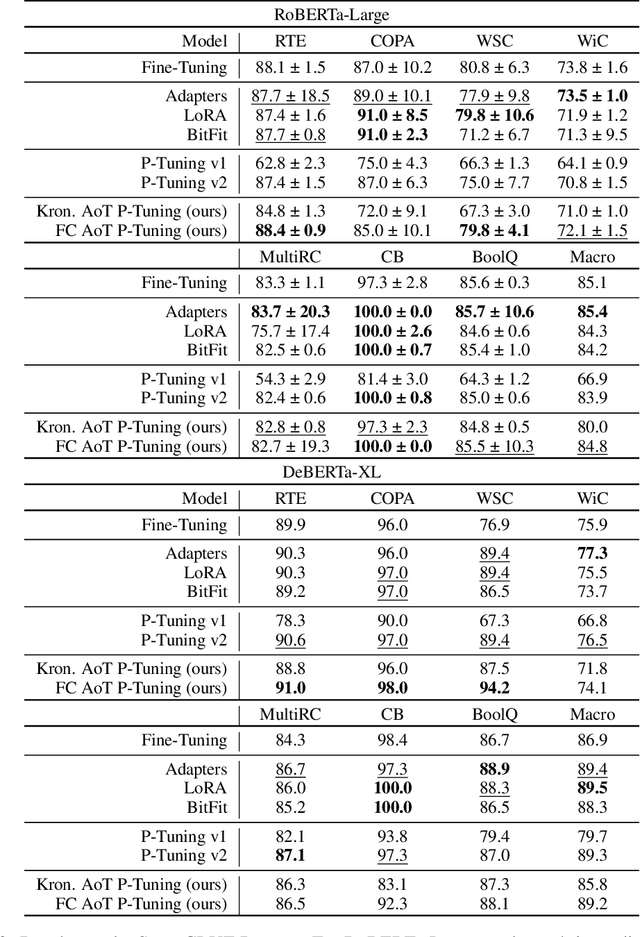
In this paper, we propose Ahead-of-Time (AoT) P-Tuning, a novel parameter-efficient fine-tuning method for pre-trained Language Models (LMs) that adds input-dependent bias before each Transformer layer. We evaluate AoT P-Tuning on GLUE and SuperGLUE benchmarking datasets using RoBERTa and DeBERTa models, showing that it outperforms BitFit and is comparable or better than other baseline methods for efficient fine-tuning. Additionally, we assess the inference overhead of AoT P-Tuning and demonstrate that it introduces negligible overhead compared to established baseline methods. Our method enables multi-task inference with a single backbone LM, making it a practical solution for real-world applications.
A Hierarchical Destroy and Repair Approach for Solving Very Large-Scale Travelling Salesman Problem
Aug 09, 2023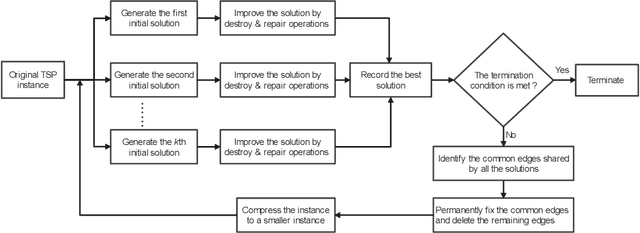
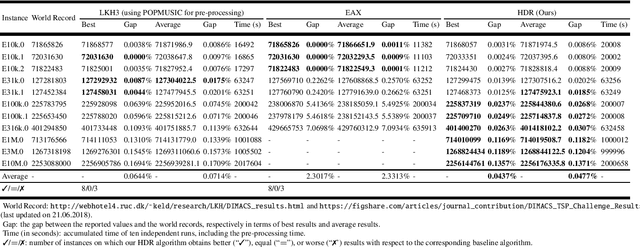
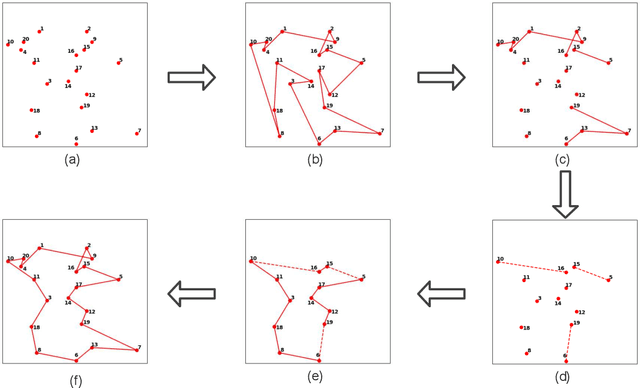
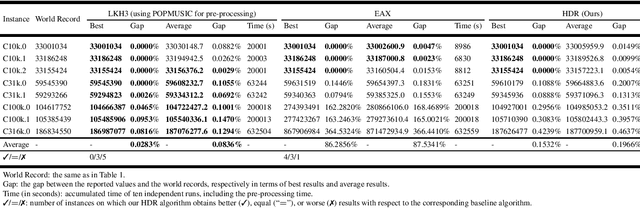
For prohibitively large-scale Travelling Salesman Problems (TSPs), existing algorithms face big challenges in terms of both computational efficiency and solution quality. To address this issue, we propose a hierarchical destroy-and-repair (HDR) approach, which attempts to improve an initial solution by applying a series of carefully designed destroy-and-repair operations. A key innovative concept is the hierarchical search framework, which recursively fixes partial edges and compresses the input instance into a small-scale TSP under some equivalence guarantee. This neat search framework is able to deliver highly competitive solutions within a reasonable time. Fair comparisons based on nineteen famous large-scale instances (with 10,000 to 10,000,000 cities) show that HDR is highly competitive against existing state-of-the-art TSP algorithms, in terms of both efficiency and solution quality. Notably, on two large instances with 3,162,278 and 10,000,000 cities, HDR breaks the world records (i.e., best-known results regardless of computation time), which were previously achieved by LKH and its variants, while HDR is completely independent of LKH. Finally, ablation studies are performed to certify the importance and validity of the hierarchical search framework.
Conceptualizing Machine Learning for Dynamic Information Retrieval of Electronic Health Record Notes
Aug 09, 2023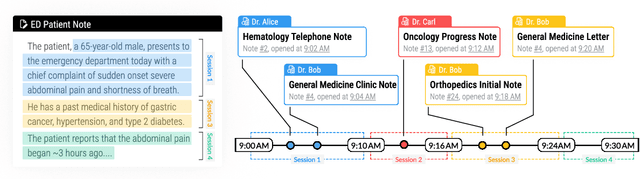
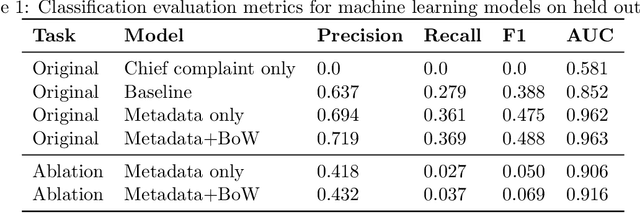
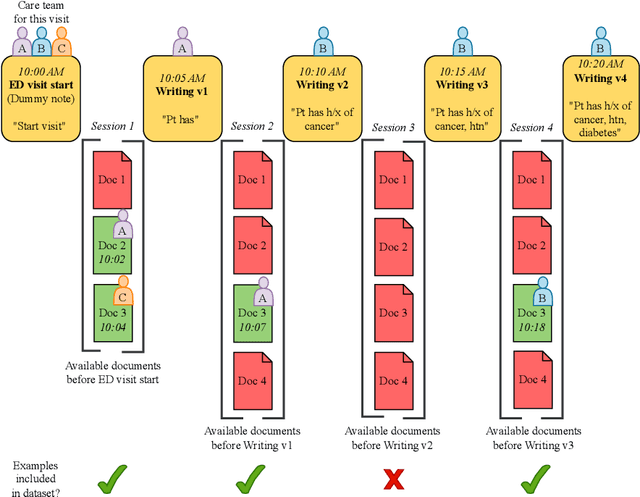
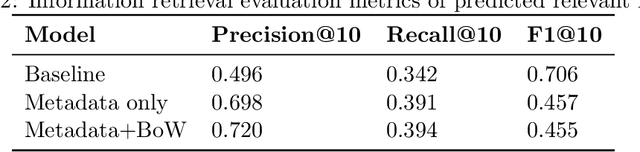
The large amount of time clinicians spend sifting through patient notes and documenting in electronic health records (EHRs) is a leading cause of clinician burnout. By proactively and dynamically retrieving relevant notes during the documentation process, we can reduce the effort required to find relevant patient history. In this work, we conceptualize the use of EHR audit logs for machine learning as a source of supervision of note relevance in a specific clinical context, at a particular point in time. Our evaluation focuses on the dynamic retrieval in the emergency department, a high acuity setting with unique patterns of information retrieval and note writing. We show that our methods can achieve an AUC of 0.963 for predicting which notes will be read in an individual note writing session. We additionally conduct a user study with several clinicians and find that our framework can help clinicians retrieve relevant information more efficiently. Demonstrating that our framework and methods can perform well in this demanding setting is a promising proof of concept that they will translate to other clinical settings and data modalities (e.g., labs, medications, imaging).
An Entropy-Awareness Meta-Learning Method for SAR Open-Set ATR
Aug 20, 2023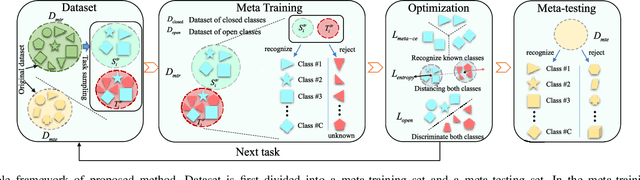
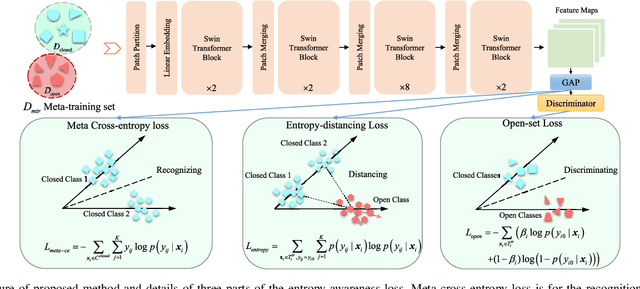

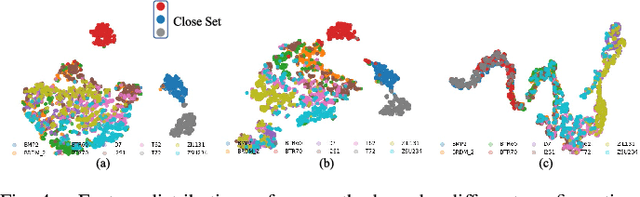
Existing synthetic aperture radar automatic target recognition (SAR ATR) methods have been effective for the classification of seen target classes. However, it is more meaningful and challenging to distinguish the unseen target classes, i.e., open set recognition (OSR) problem, which is an urgent problem for the practical SAR ATR. The key solution of OSR is to effectively establish the exclusiveness of feature distribution of known classes. In this letter, we propose an entropy-awareness meta-learning method that improves the exclusiveness of feature distribution of known classes which means our method is effective for not only classifying the seen classes but also encountering the unseen other classes. Through meta-learning tasks, the proposed method learns to construct a feature space of the dynamic-assigned known classes. This feature space is required by the tasks to reject all other classes not belonging to the known classes. At the same time, the proposed entropy-awareness loss helps the model to enhance the feature space with effective and robust discrimination between the known and unknown classes. Therefore, our method can construct a dynamic feature space with discrimination between the known and unknown classes to simultaneously classify the dynamic-assigned known classes and reject the unknown classes. Experiments conducted on the moving and stationary target acquisition and recognition (MSTAR) dataset have shown the effectiveness of our method for SAR OSR.
Make-It-4D: Synthesizing a Consistent Long-Term Dynamic Scene Video from a Single Image
Aug 20, 2023
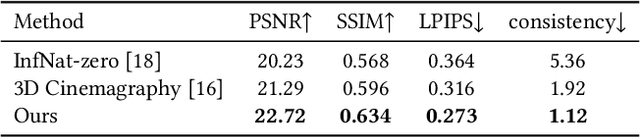
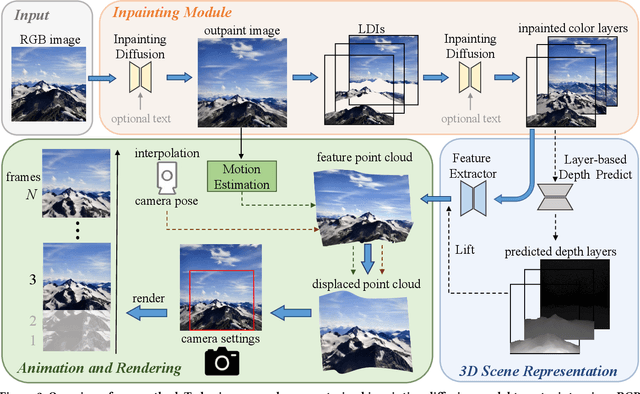
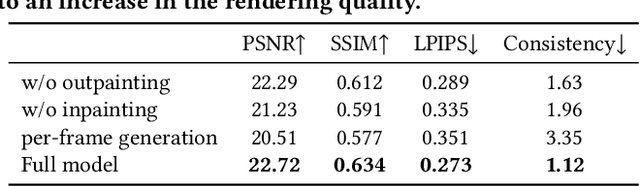
We study the problem of synthesizing a long-term dynamic video from only a single image. This is challenging since it requires consistent visual content movements given large camera motions. Existing methods either hallucinate inconsistent perpetual views or struggle with long camera trajectories. To address these issues, it is essential to estimate the underlying 4D (including 3D geometry and scene motion) and fill in the occluded regions. To this end, we present Make-It-4D, a novel method that can generate a consistent long-term dynamic video from a single image. On the one hand, we utilize layered depth images (LDIs) to represent a scene, and they are then unprojected to form a feature point cloud. To animate the visual content, the feature point cloud is displaced based on the scene flow derived from motion estimation and the corresponding camera pose. Such 4D representation enables our method to maintain the global consistency of the generated dynamic video. On the other hand, we fill in the occluded regions by using a pretrained diffusion model to inpaint and outpaint the input image. This enables our method to work under large camera motions. Benefiting from our design, our method can be training-free which saves a significant amount of training time. Experimental results demonstrate the effectiveness of our approach, which showcases compelling rendering results.