 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Local Periodicity-Based Beat Tracking for Expressive Classical Piano Music
Aug 20, 2023
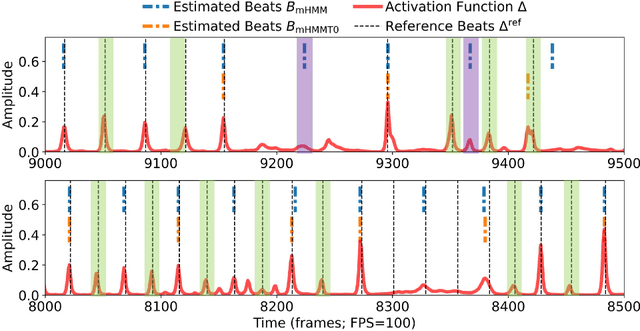
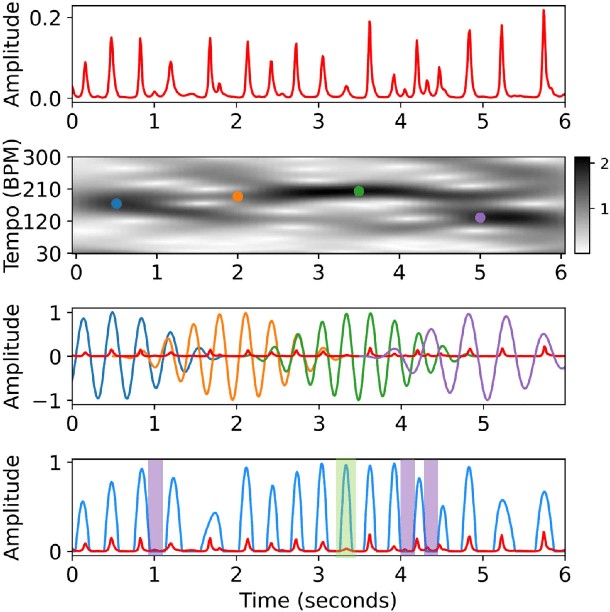
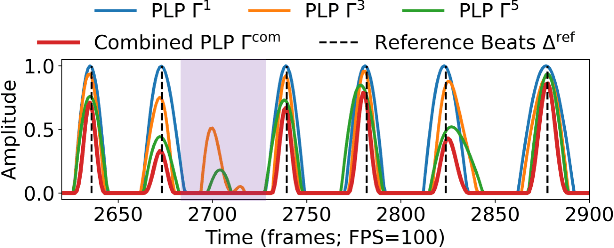
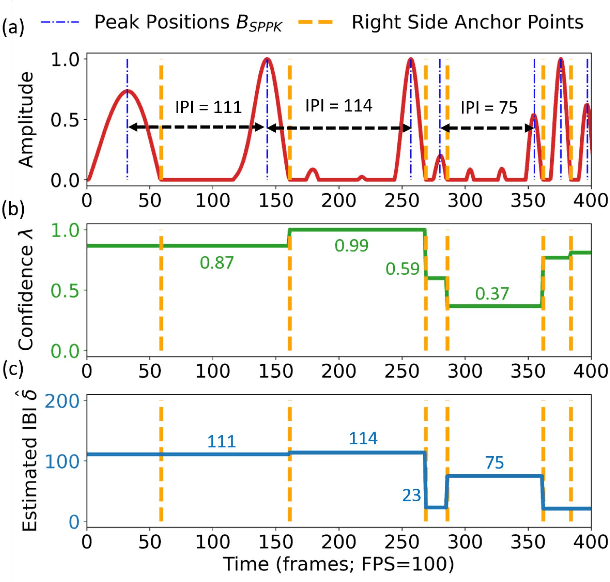
To model the periodicity of beats, state-of-the-art beat tracking systems use "post-processing trackers" (PPTs) that rely on several empirically determined global assumptions for tempo transition, which work well for music with a steady tempo. For expressive classical music, however, these assumptions can be too rigid. With two large datasets of Western classical piano music, namely the Aligned Scores and Performances (ASAP) dataset and a dataset of Chopin's Mazurkas (Maz-5), we report on experiments showing the failure of existing PPTs to cope with local tempo changes, thus calling for new methods. In this paper, we propose a new local periodicity-based PPT, called predominant local pulse-based dynamic programming (PLPDP) tracking, that allows for more flexible tempo transitions. Specifically, the new PPT incorporates a method called "predominant local pulses" (PLP) in combination with a dynamic programming (DP) component to jointly consider the locally detected periodicity and beat activation strength at each time instant. Accordingly, PLPDP accounts for the local periodicity, rather than relying on a global tempo assumption. Compared to existing PPTs, PLPDP particularly enhances the recall values at the cost of a lower precision, resulting in an overall improvement of F1-score for beat tracking in ASAP (from 0.473 to 0.493) and Maz-5 (from 0.595 to 0.838).
FPGA Implementation of Convolutional Neural Network for Real-Time Handwriting Recognition
Jun 23, 2023
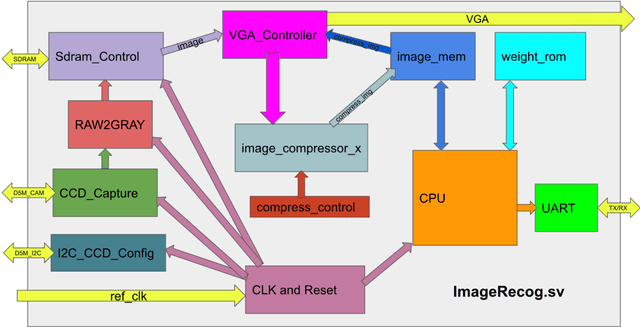
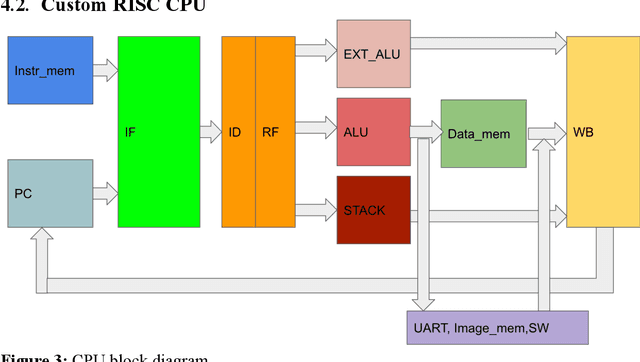
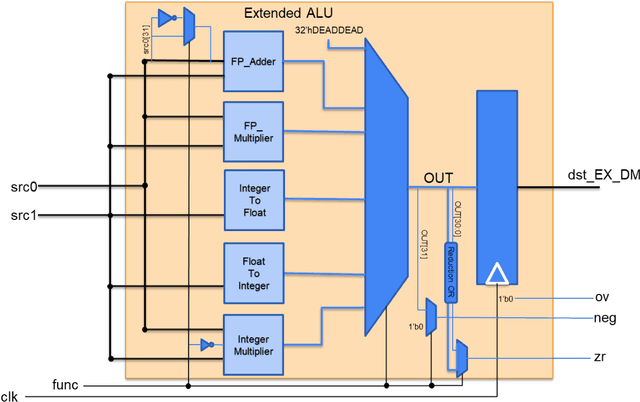
Machine Learning (ML) has recently been a skyrocketing field in Computer Science. As computer hardware engineers, we are enthusiastic about hardware implementations of popular software ML architectures to optimize their performance, reliability, and resource usage. In this project, we designed a highly-configurable, real-time device for recognizing handwritten letters and digits using an Altera DE1 FPGA Kit. We followed various engineering standards, including IEEE-754 32-bit Floating-Point Standard, Video Graphics Array (VGA) display protocol, Universal Asynchronous Receiver-Transmitter (UART) protocol, and Inter-Integrated Circuit (I2C) protocols to achieve the project goals. These significantly improved our design in compatibility, reusability, and simplicity in verifications. Following these standards, we designed a 32-bit floating-point (FP) instruction set architecture (ISA). We developed a 5-stage RISC processor in System Verilog to manage image processing, matrix multiplications, ML classifications, and user interfaces. Three different ML architectures were implemented and evaluated on our design: Linear Classification (LC), a 784-64-10 fully connected neural network (NN), and a LeNet-like Convolutional Neural Network (CNN) with ReLU activation layers and 36 classes (10 for the digits and 26 for the case-insensitive letters). The training processes were done in Python scripts, and the resulting kernels and weights were stored in hex files and loaded into the FPGA's SRAM units. Convolution, pooling, data management, and various other ML features were guided by firmware in our custom assembly language. This paper documents the high-level design block diagrams, interfaces between each System Verilog module, implementation details of our software and firmware components, and further discussions on potential impacts.
Efficient Representation Learning for Healthcare with Cross-Architectural Self-Supervision
Aug 19, 2023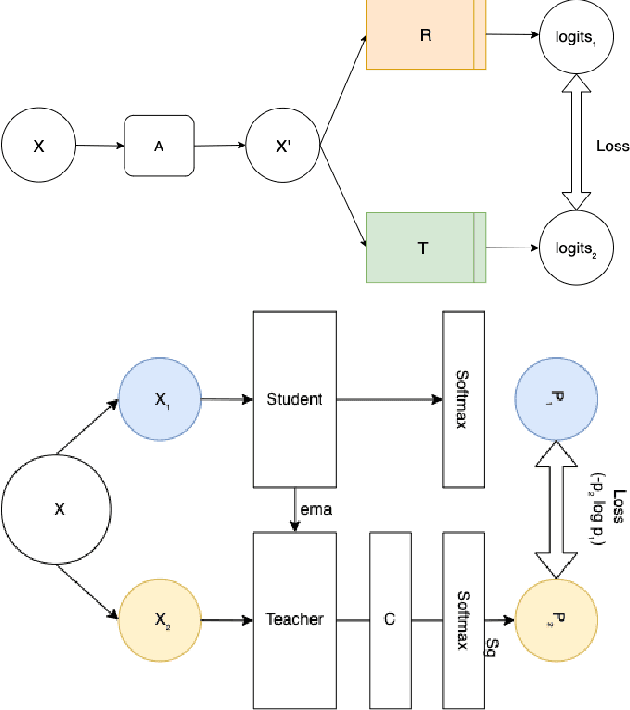
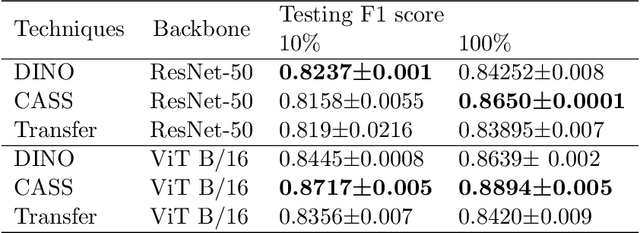
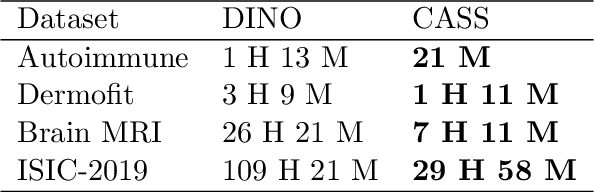
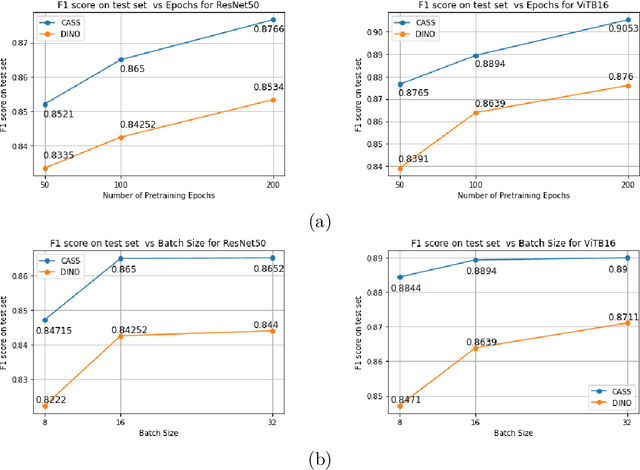
In healthcare and biomedical applications, extreme computational requirements pose a significant barrier to adopting representation learning. Representation learning can enhance the performance of deep learning architectures by learning useful priors from limited medical data. However, state-of-the-art self-supervised techniques suffer from reduced performance when using smaller batch sizes or shorter pretraining epochs, which are more practical in clinical settings. We present Cross Architectural - Self Supervision (CASS) in response to this challenge. This novel siamese self-supervised learning approach synergistically leverages Transformer and Convolutional Neural Networks (CNN) for efficient learning. Our empirical evaluation demonstrates that CASS-trained CNNs and Transformers outperform existing self-supervised learning methods across four diverse healthcare datasets. With only 1% labeled data for finetuning, CASS achieves a 3.8% average improvement; with 10% labeled data, it gains 5.9%; and with 100% labeled data, it reaches a remarkable 10.13% enhancement. Notably, CASS reduces pretraining time by 69% compared to state-of-the-art methods, making it more amenable to clinical implementation. We also demonstrate that CASS is considerably more robust to variations in batch size and pretraining epochs, making it a suitable candidate for machine learning in healthcare applications.
SIGMA: Scale-Invariant Global Sparse Shape Matching
Aug 16, 2023
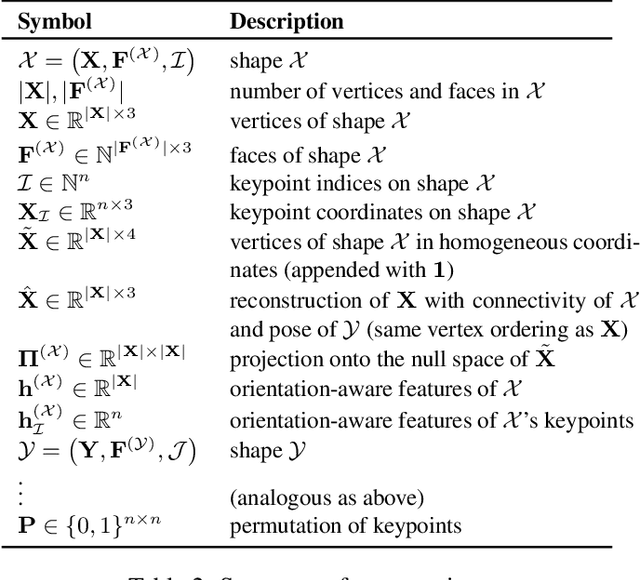
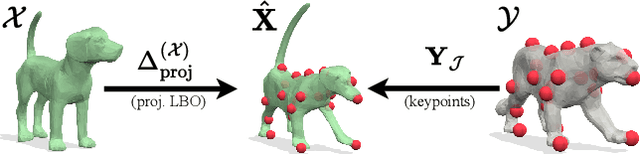
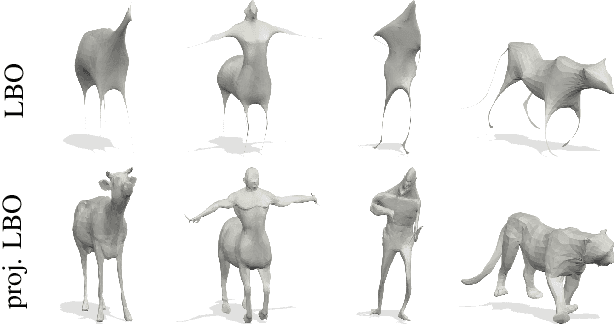
We propose a novel mixed-integer programming (MIP) formulation for generating precise sparse correspondences for highly non-rigid shapes. To this end, we introduce a projected Laplace-Beltrami operator (PLBO) which combines intrinsic and extrinsic geometric information to measure the deformation quality induced by predicted correspondences. We integrate the PLBO, together with an orientation-aware regulariser, into a novel MIP formulation that can be solved to global optimality for many practical problems. In contrast to previous methods, our approach is provably invariant to rigid transformations and global scaling, initialisation-free, has optimality guarantees, and scales to high resolution meshes with (empirically observed) linear time. We show state-of-the-art results for sparse non-rigid matching on several challenging 3D datasets, including data with inconsistent meshing, as well as applications in mesh-to-point-cloud matching.
Self-Supervised Online Camera Calibration for Automated Driving and Parking Applications
Aug 16, 2023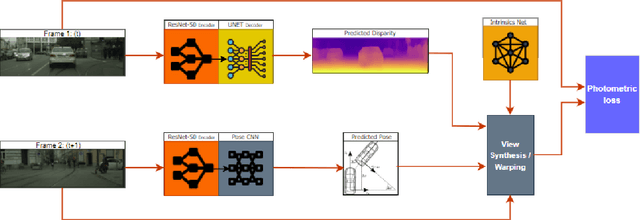

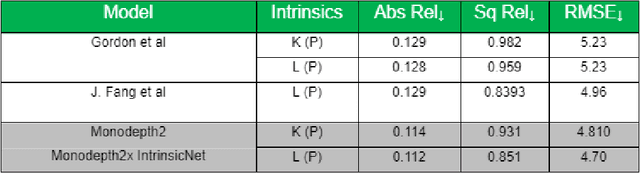
Camera-based perception systems play a central role in modern autonomous vehicles. These camera based perception algorithms require an accurate calibration to map the real world distances to image pixels. In practice, calibration is a laborious procedure requiring specialised data collection and careful tuning. This process must be repeated whenever the parameters of the camera change, which can be a frequent occurrence in autonomous vehicles. Hence there is a need to calibrate at regular intervals to ensure the camera is accurate. Proposed is a deep learning framework to learn intrinsic and extrinsic calibration of the camera in real time. The framework is self-supervised and doesn't require any labelling or supervision to learn the calibration parameters. The framework learns calibration without the need for any physical targets or to drive the car on special planar surfaces.
Tackling the Curse of Dimensionality in Large-scale Multi-agent LTL Task Planning via Poset Product
Aug 22, 2023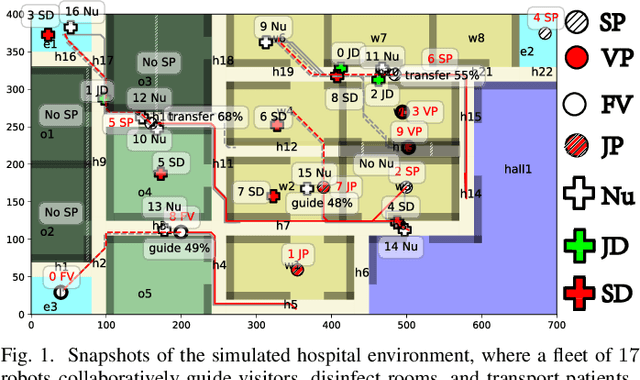
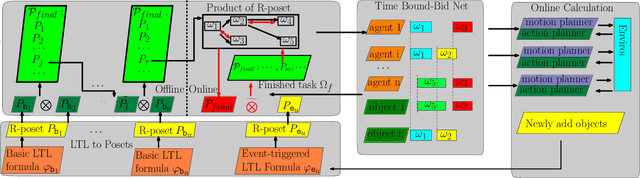
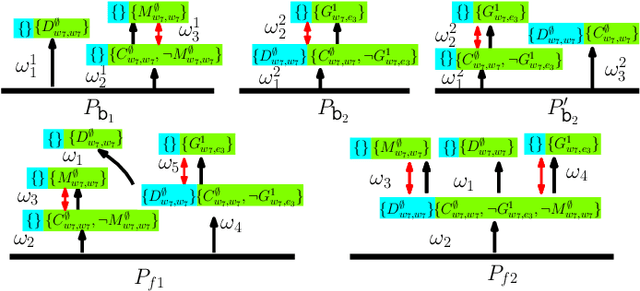
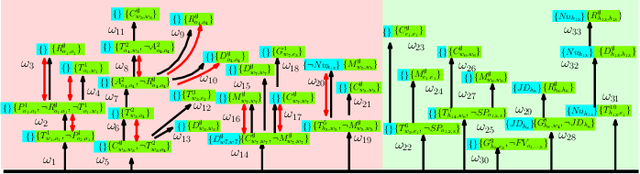
Linear Temporal Logic (LTL) formulas have been used to describe complex tasks for multi-agent systems, with both spatial and temporal constraints. However, since the planning complexity grows exponentially with the number of agents and the length of the task formula, existing applications are mostly limited to small artificial cases. To address this issue, a new planning algorithm is proposed for task formulas specified as sc-LTL formulas. It avoids two common bottlenecks in the model-checking-based planning methods, i.e., (i) the direct translation of the complete task formula to the associated B\"uchi automaton; and (ii) the synchronized product between the B\"uchi automaton and the transition models of all agents. In particular, each conjuncted sub-formula is first converted to the associated R-posets as an abstraction of the temporal dependencies among the subtasks. Then, an efficient algorithm is proposed to compute the product of these R-posets, which retains their dependencies and resolves potential conflicts. Furthermore, the proposed approach is applied to dynamic scenes where new tasks are generated online. It is capable of deriving the first valid plan with a polynomial time and memory complexity w.r.t. the system size and the formula length. Our method can plan for task formulas with a length of more than 60 and a system with more than 35 agents, while most existing methods fail at the formula length of 20. The proposed method is validated on large fleets of service robots in both simulation and hardware experiments.
Distributed Robust Learning-Based Backstepping Control Aided with Neurodynamics for Consensus Formation Tracking of Underwater Vessels
Aug 18, 2023This paper addresses distributed robust learning-based control for consensus formation tracking of multiple underwater vessels, in which the system parameters of the marine vessels are assumed to be entirely unknown and subject to the modeling mismatch, oceanic disturbances, and noises. Towards this end, graph theory is used to allow us to synthesize the distributed controller with a stability guarantee. Due to the fact that the parameter uncertainties only arise in the vessels' dynamic model, the backstepping control technique is then employed. Subsequently, to overcome the difficulties in handling time-varying and unknown systems, an online learning procedure is developed in the proposed distributed formation control protocol. Moreover, modeling errors, environmental disturbances, and measurement noises are considered and tackled by introducing a neurodynamics model in the controller design to obtain a robust solution. Then, the stability analysis of the overall closed-loop system under the proposed scheme is provided to ensure the robust adaptive performance at the theoretical level. Finally, extensive simulation experiments are conducted to further verify the efficacy of the presented distributed control protocol.
PlaneRecTR: Unified Query Learning for 3D Plane Recovery from a Single View
Aug 17, 2023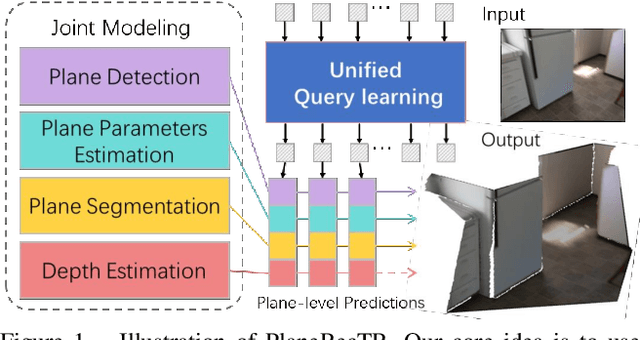
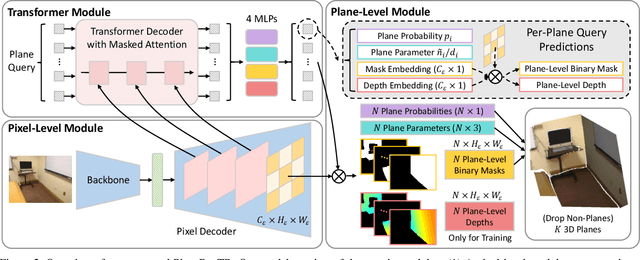
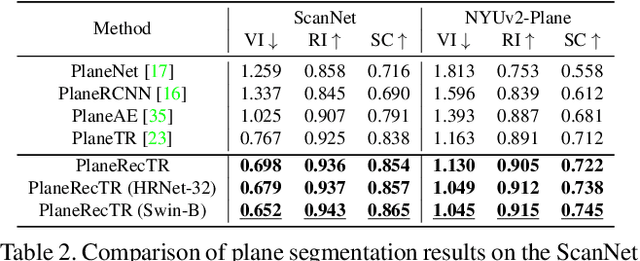
3D plane recovery from a single image can usually be divided into several subtasks of plane detection, segmentation, parameter estimation and possibly depth estimation. Previous works tend to solve this task by either extending the RCNN-based segmentation network or the dense pixel embedding-based clustering framework. However, none of them tried to integrate above related subtasks into a unified framework but treat them separately and sequentially, which we suspect is potentially a main source of performance limitation for existing approaches. Motivated by this finding and the success of query-based learning in enriching reasoning among semantic entities, in this paper, we propose PlaneRecTR, a Transformer-based architecture, which for the first time unifies all subtasks related to single-view plane recovery with a single compact model. Extensive quantitative and qualitative experiments demonstrate that our proposed unified learning achieves mutual benefits across subtasks, obtaining a new state-of-the-art performance on public ScanNet and NYUv2-Plane datasets. Codes are available at https://github.com/SJingjia/PlaneRecTR.
Bag of Tricks for Long-Tailed Multi-Label Classification on Chest X-Rays
Aug 17, 2023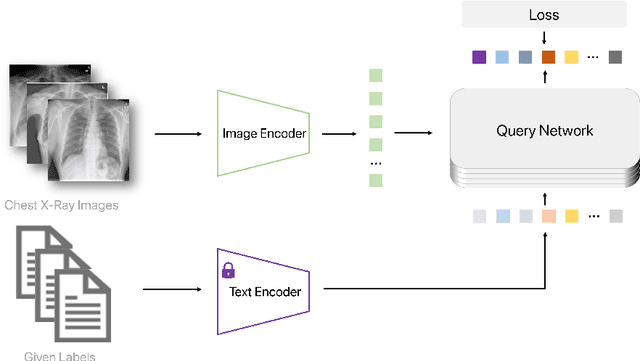
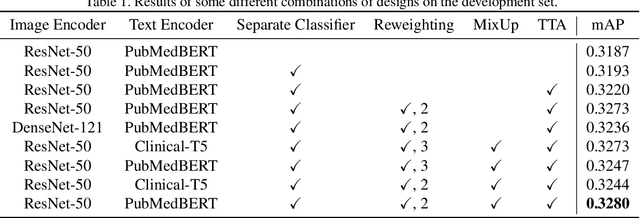

Clinical classification of chest radiography is particularly challenging for standard machine learning algorithms due to its inherent long-tailed and multi-label nature. However, few attempts take into account the coupled challenges posed by both the class imbalance and label co-occurrence, which hinders their value to boost the diagnosis on chest X-rays (CXRs) in the real-world scenarios. Besides, with the prevalence of pretraining techniques, how to incorporate these new paradigms into the current framework lacks of the systematical study. This technical report presents a brief description of our solution in the ICCV CVAMD 2023 CXR-LT Competition. We empirically explored the effectiveness for CXR diagnosis with the integration of several advanced designs about data augmentation, feature extractor, classifier design, loss function reweighting, exogenous data replenishment, etc. In addition, we improve the performance through simple test-time data augmentation and ensemble. Our framework finally achieves 0.349 mAP on the competition test set, ranking in the top five.
SDDNet: Style-guided Dual-layer Disentanglement Network for Shadow Detection
Aug 17, 2023
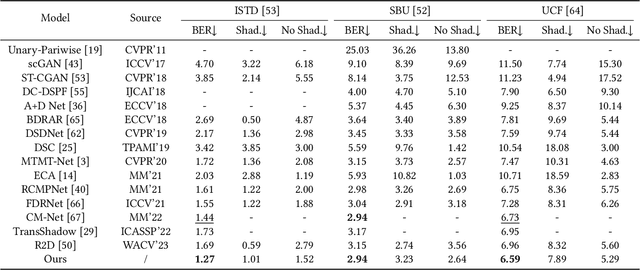
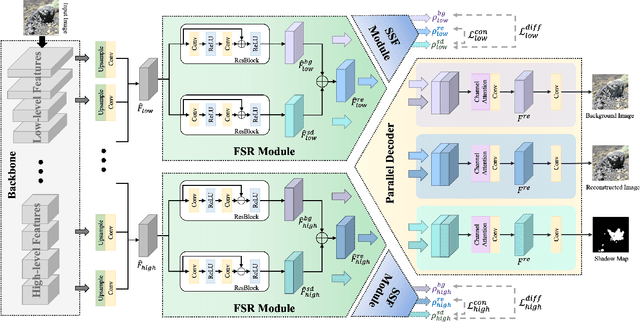
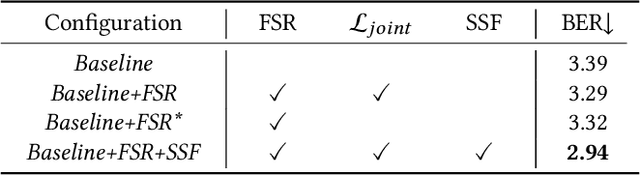
Despite significant progress in shadow detection, current methods still struggle with the adverse impact of background color, which may lead to errors when shadows are present on complex backgrounds. Drawing inspiration from the human visual system, we treat the input shadow image as a composition of a background layer and a shadow layer, and design a Style-guided Dual-layer Disentanglement Network (SDDNet) to model these layers independently. To achieve this, we devise a Feature Separation and Recombination (FSR) module that decomposes multi-level features into shadow-related and background-related components by offering specialized supervision for each component, while preserving information integrity and avoiding redundancy through the reconstruction constraint. Moreover, we propose a Shadow Style Filter (SSF) module to guide the feature disentanglement by focusing on style differentiation and uniformization. With these two modules and our overall pipeline, our model effectively minimizes the detrimental effects of background color, yielding superior performance on three public datasets with a real-time inference speed of 32 FPS.