 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
IoT Data Trust Evaluation via Machine Learning
Aug 15, 2023
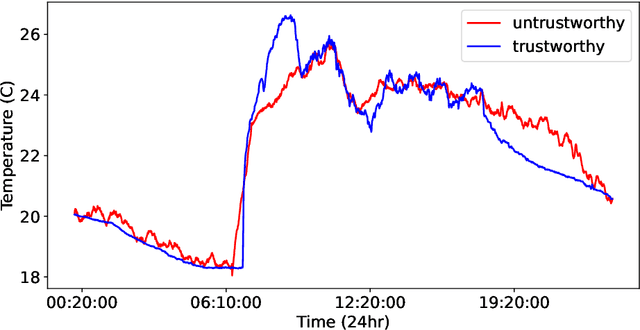
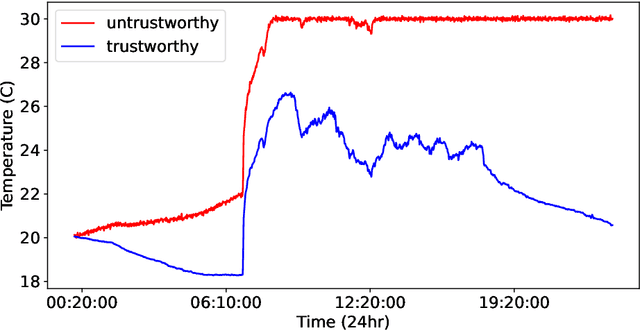
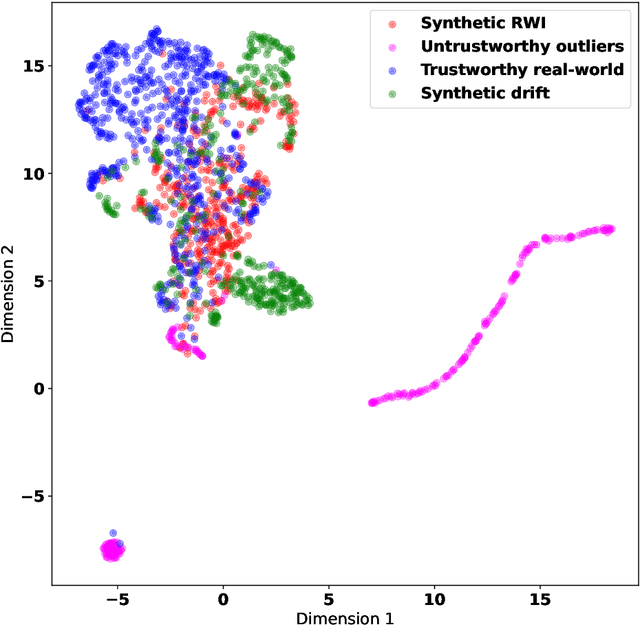
Various approaches based on supervised or unsupervised machine learning (ML) have been proposed for evaluating IoT data trust. However, assessing their real-world efficacy is hard mainly due to the lack of related publicly-available datasets that can be used for benchmarking. Since obtaining such datasets is challenging, we propose a data synthesis method, called random walk infilling (RWI), to augment IoT time-series datasets by synthesizing untrustworthy data from existing trustworthy data. Thus, RWI enables us to create labeled datasets that can be used to develop and validate ML models for IoT data trust evaluation. We also extract new features from IoT time-series sensor data that effectively capture its auto-correlation as well as its cross-correlation with the data of the neighboring (peer) sensors. These features can be used to learn ML models for recognizing the trustworthiness of IoT sensor data. Equipped with our synthesized ground-truth-labeled datasets and informative correlation-based feature, we conduct extensive experiments to critically examine various approaches to evaluating IoT data trust via ML. The results reveal that commonly used ML-based approaches to IoT data trust evaluation, which rely on unsupervised cluster analysis to assign trust labels to unlabeled data, perform poorly. This poor performance can be attributed to the underlying unsubstantiated assumption that clustering provides reliable labels for data trust, a premise that is found to be untenable. The results also show that the ML models learned from datasets augmented via RWI while using the proposed features generalize well to unseen data and outperform existing related approaches. Moreover, we observe that a semi-supervised ML approach that requires only about 10% of the data labeled offers competitive performance while being practically more appealing compared to the fully-supervised approaches.
Full-dose PET Synthesis from Low-dose PET Using High-efficiency Diffusion Denoising Probabilistic Model
Aug 24, 2023
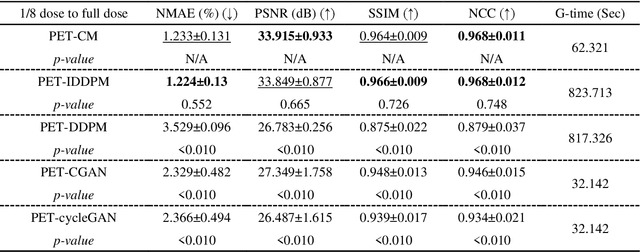
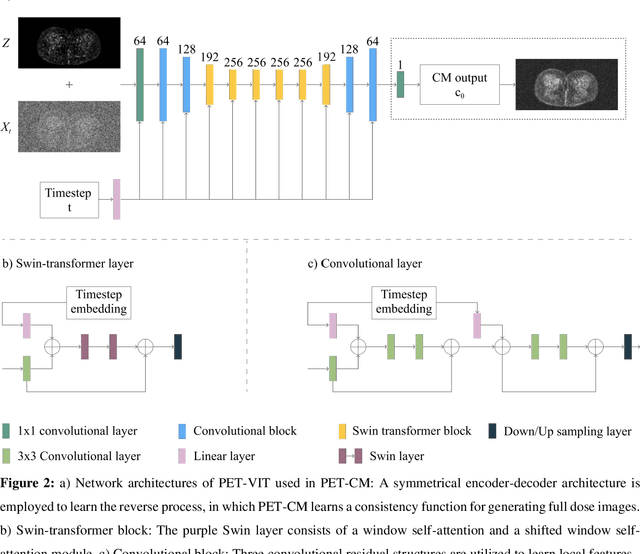
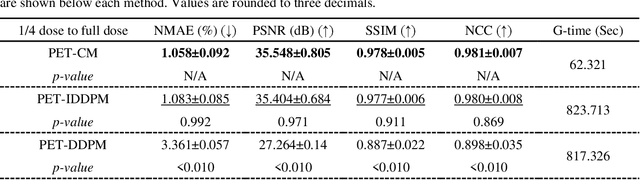
To reduce the risks associated with ionizing radiation, a reduction of radiation exposure in PET imaging is needed. However, this leads to a detrimental effect on image contrast and quantification. High-quality PET images synthesized from low-dose data offer a solution to reduce radiation exposure. We introduce a diffusion-model-based approach for estimating full-dose PET images from low-dose ones: the PET Consistency Model (PET-CM) yielding synthetic quality comparable to state-of-the-art diffusion-based synthesis models, but with greater efficiency. There are two steps: a forward process that adds Gaussian noise to a full dose PET image at multiple timesteps, and a reverse diffusion process that employs a PET Shifted-window Vision Transformer (PET-VIT) network to learn the denoising procedure conditioned on the corresponding low-dose PETs. In PET-CM, the reverse process learns a consistency function for direct denoising of Gaussian noise to a clean full-dose PET. We evaluated the PET-CM in generating full-dose images using only 1/8 and 1/4 of the standard PET dose. Comparing 1/8 dose to full-dose images, PET-CM demonstrated impressive performance with normalized mean absolute error (NMAE) of 1.233+/-0.131%, peak signal-to-noise ratio (PSNR) of 33.915+/-0.933dB, structural similarity index (SSIM) of 0.964+/-0.009, and normalized cross-correlation (NCC) of 0.968+/-0.011, with an average generation time of 62 seconds per patient. This is a significant improvement compared to the state-of-the-art diffusion-based model with PET-CM reaching this result 12x faster. In the 1/4 dose to full-dose image experiments, PET-CM is also competitive, achieving an NMAE 1.058+/-0.092%, PSNR of 35.548+/-0.805dB, SSIM of 0.978+/-0.005, and NCC 0.981+/-0.007 The results indicate promising low-dose PET image quality improvements for clinical applications.
Multi-stage feature decorrelation constraints for improving CNN classification performance
Aug 24, 2023
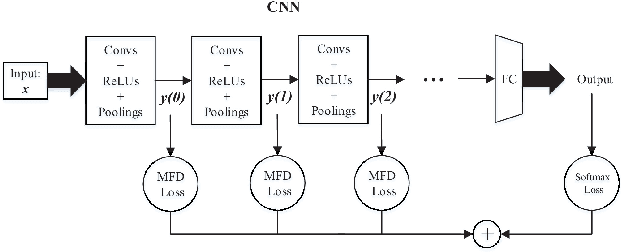
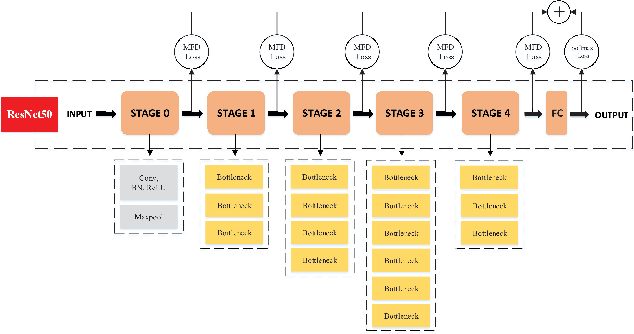

For the convolutional neural network (CNN) used for pattern classification, the training loss function is usually applied to the final output of the network, except for some regularization constraints on the network parameters. However, with the increasing of the number of network layers, the influence of the loss function on the network front layers gradually decreases, and the network parameters tend to fall into local optimization. At the same time, it is found that the trained network has significant information redundancy at all stages of features, which reduces the effectiveness of feature mapping at all stages and is not conducive to the change of the subsequent parameters of the network in the direction of optimality. Therefore, it is possible to obtain a more optimized solution of the network and further improve the classification accuracy of the network by designing a loss function for restraining the front stage features and eliminating the information redundancy of the front stage features .For CNN, this article proposes a multi-stage feature decorrelation loss (MFD Loss), which refines effective features and eliminates information redundancy by constraining the correlation of features at all stages. Considering that there are many layers in CNN, through experimental comparison and analysis, MFD Loss acts on multiple front layers of CNN, constrains the output features of each layer and each channel, and performs supervision training jointly with classification loss function during network training. Compared with the single Softmax Loss supervised learning, the experiments on several commonly used datasets on several typical CNNs prove that the classification performance of Softmax Loss+MFD Loss is significantly better. Meanwhile, the comparison experiments before and after the combination of MFD Loss and some other typical loss functions verify its good universality.
On-line Parameter Estimation of the Polarization Curve of a Fuel Cell with Guaranteed Convergence Properties: Theoretical and Experimental Results
Aug 12, 2023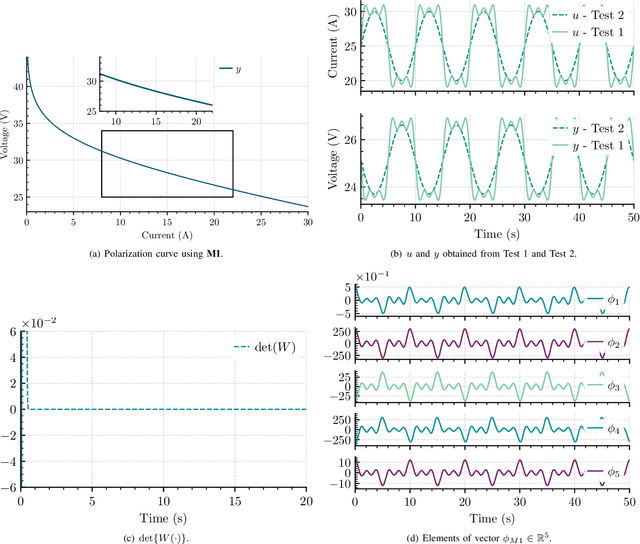
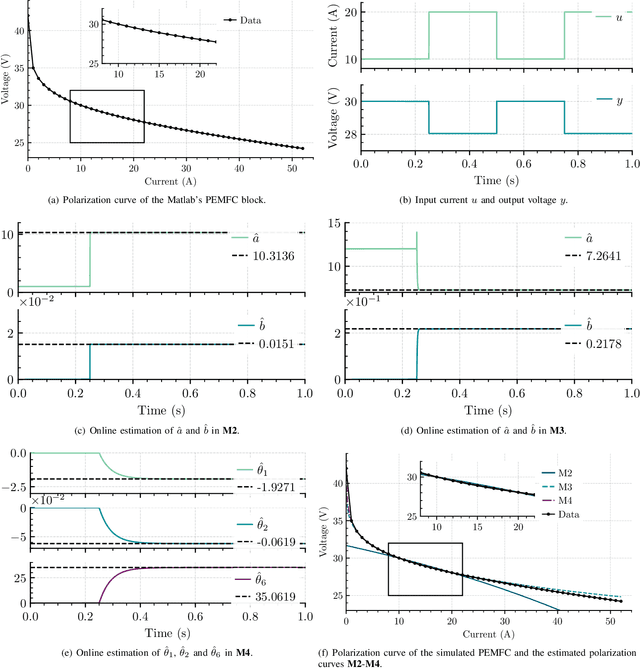

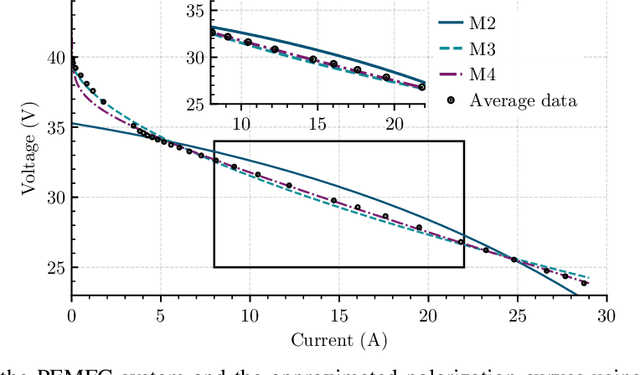
In this paper, we address the problem of online parameter estimation of a Proton Exchange Membrane Fuel Cell (PEMFC) polarization curve, that is the static relation between the voltage and the current of the PEMFC. The task of designing this estimator -- even off-line -- is complicated by the fact that the uncertain parameters enter the curve in a highly nonlinear fashion, namely in the form of nonseparable nonlinearities. We consider several scenarios for the model of the polarization curve, starting from the standard full model and including several popular simplifications to this complicated mathematical function. In all cases, we derive separable regression equations -- either linearly or nonlinearly parameterized -- which are instrumental for the implementation of the parameter estimators. We concentrate our attention on on-line estimation schemes for which, under suitable excitation conditions, global parameter convergence is ensured. Due to these global convergence properties, the estimators are robust to unavoidable additive noise and structural uncertainty. Moreover, their on-line nature endows the schemes with the ability to track (slow) parameter variations, that occur during the operation of the PEMFC. These two features -- unavailable in time-consuming off-line data-fitting procedures -- make the proposed estimators helpful for on-line time-saving characterization of a given PEMFC, and the implementation of fault-detection procedures and model-based adaptive control strategies. Simulation and experimental results that validate the theoretical claims are presented.
Gated Attention Coding for Training High-performance and Efficient Spiking Neural Networks
Aug 12, 2023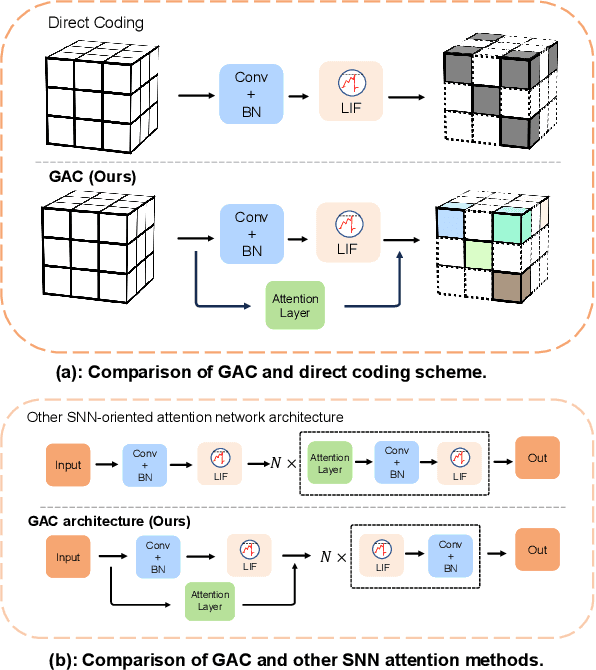
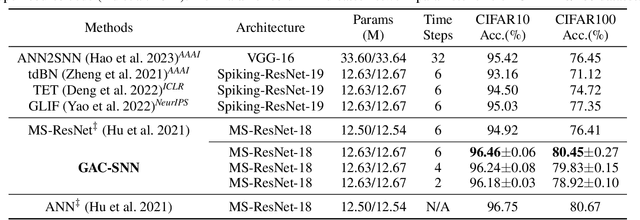
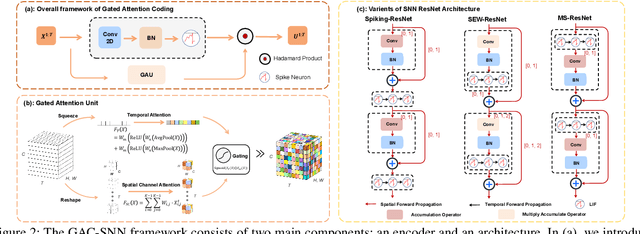
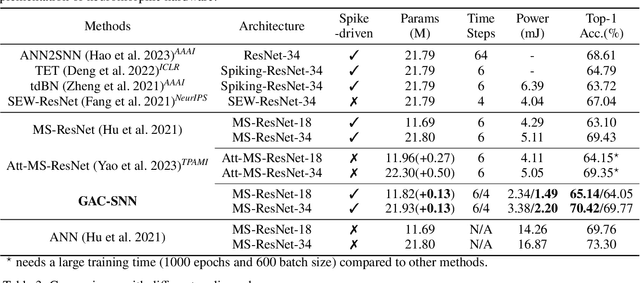
Spiking neural networks (SNNs) are emerging as an energy-efficient alternative to traditional artificial neural networks (ANNs) due to their unique spike-based event-driven nature. Coding is crucial in SNNs as it converts external input stimuli into spatio-temporal feature sequences. However, most existing deep SNNs rely on direct coding that generates powerless spike representation and lacks the temporal dynamics inherent in human vision. Hence, we introduce Gated Attention Coding (GAC), a plug-and-play module that leverages the multi-dimensional gated attention unit to efficiently encode inputs into powerful representations before feeding them into the SNN architecture. GAC functions as a preprocessing layer that does not disrupt the spike-driven nature of the SNN, making it amenable to efficient neuromorphic hardware implementation with minimal modifications. Through an observer model theoretical analysis, we demonstrate GAC's attention mechanism improves temporal dynamics and coding efficiency. Experiments on CIFAR10/100 and ImageNet datasets demonstrate that GAC achieves state-of-the-art accuracy with remarkable efficiency. Notably, we improve top-1 accuracy by 3.10\% on CIFAR100 with only 6-time steps and 1.07\% on ImageNet while reducing energy usage to 66.9\% of the previous works. To our best knowledge, it is the first time to explore the attention-based dynamic coding scheme in deep SNNs, with exceptional effectiveness and efficiency on large-scale datasets.
A Bayesian Active Learning Approach to Comparative Judgement
Aug 25, 2023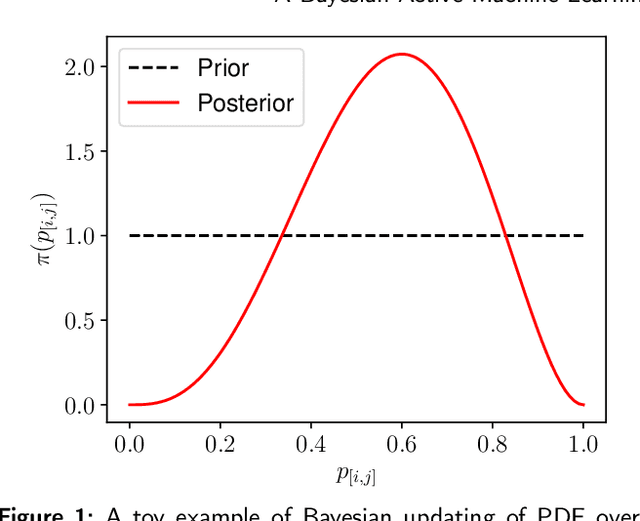
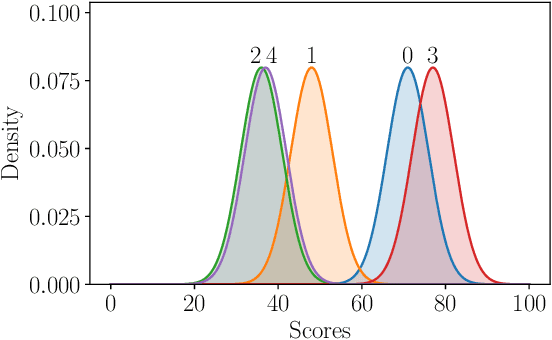
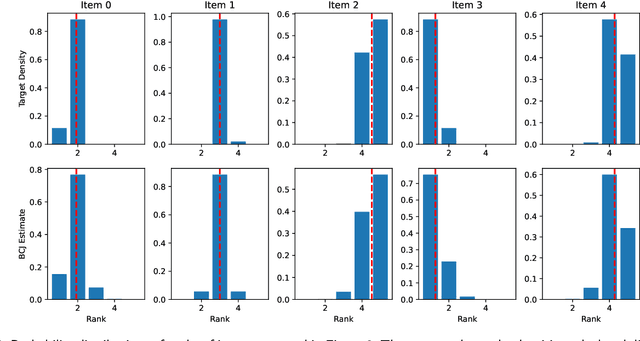
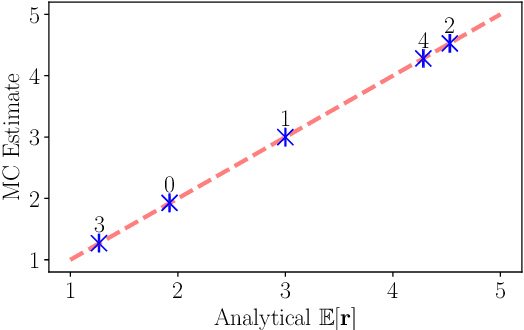
Assessment is a crucial part of education. Traditional marking is a source of inconsistencies and unconscious bias, placing a high cognitive load on the assessors. An approach to address these issues is comparative judgement (CJ). In CJ, the assessor is presented with a pair of items and is asked to select the better one. Following a series of comparisons, a rank is derived using a ranking model, for example, the BTM, based on the results. While CJ is considered a reliable method for marking, there are concerns around transparency, and the ideal number of pairwise comparisons to generate a reliable estimation of the rank order is not known. Additionally, there have been attempts to generate a method of selecting pairs that should be compared next in an informative manner, but some existing methods are known to have created their own bias within results inflating the reliability metric used. As a result, a random selection approach is usually deployed. We propose a novel Bayesian approach to CJ (BCJ) for determining the ranks of compared items alongside a new way to select the pairs to present to the marker(s) using active learning (AL), addressing the key shortcomings of traditional CJ. Furthermore, we demonstrate how the entire approach may provide transparency by providing the user insights into how it is making its decisions and, at the same time, being more efficient. Results from our experiments confirm that the proposed BCJ combined with entropy-driven AL pair-selection method is superior to other alternatives. We also find that the more comparisons done, the more accurate BCJ becomes, which solves the issue the current method has of the model deteriorating if too many comparisons are performed. As our approach can generate the complete predicted rank distribution for an item, we also show how this can be utilised in devising a predicted grade, guided by the assessor.
Revisiting and Exploring Efficient Fast Adversarial Training via LAW: Lipschitz Regularization and Auto Weight Averaging
Aug 22, 2023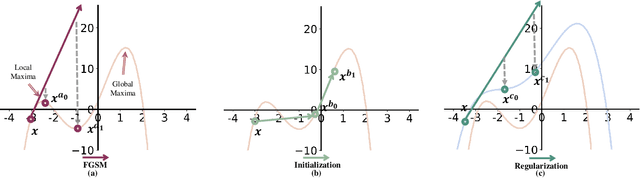
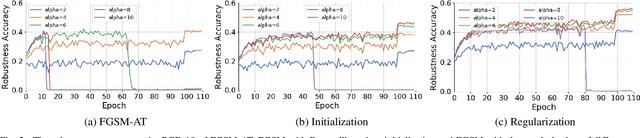
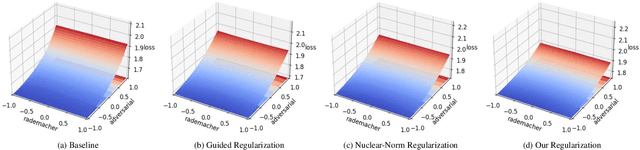
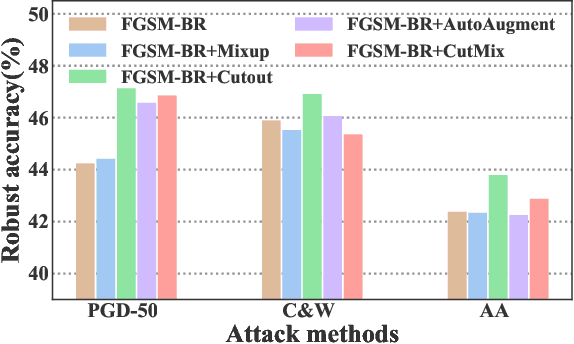
Fast Adversarial Training (FAT) not only improves the model robustness but also reduces the training cost of standard adversarial training. However, fast adversarial training often suffers from Catastrophic Overfitting (CO), which results in poor robustness performance. Catastrophic Overfitting describes the phenomenon of a sudden and significant decrease in robust accuracy during the training of fast adversarial training. Many effective techniques have been developed to prevent Catastrophic Overfitting and improve the model robustness from different perspectives. However, these techniques adopt inconsistent training settings and require different training costs, i.e, training time and memory costs, leading to unfair comparisons. In this paper, we conduct a comprehensive study of over 10 fast adversarial training methods in terms of adversarial robustness and training costs. We revisit the effectiveness and efficiency of fast adversarial training techniques in preventing Catastrophic Overfitting from the perspective of model local nonlinearity and propose an effective Lipschitz regularization method for fast adversarial training. Furthermore, we explore the effect of data augmentation and weight averaging in fast adversarial training and propose a simple yet effective auto weight averaging method to improve robustness further. By assembling these techniques, we propose a FGSM-based fast adversarial training method equipped with Lipschitz regularization and Auto Weight averaging, abbreviated as FGSM-LAW. Experimental evaluations on four benchmark databases demonstrate the superiority of the proposed method over state-of-the-art fast adversarial training methods and the advanced standard adversarial training methods.
Efficient View Synthesis with Neural Radiance Distribution Field
Aug 22, 2023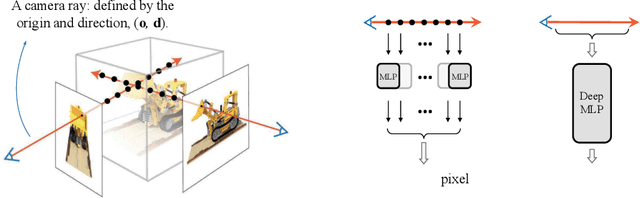

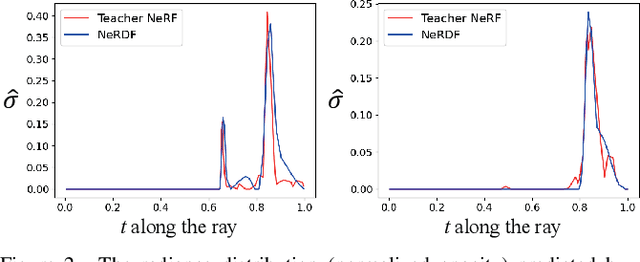
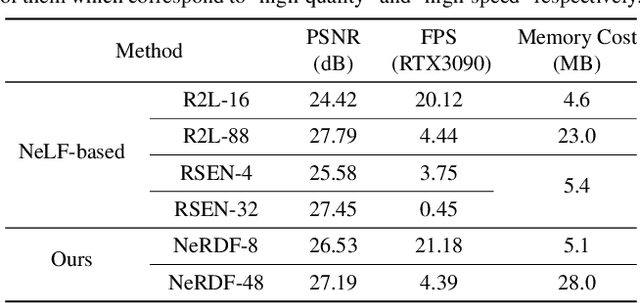
Recent work on Neural Radiance Fields (NeRF) has demonstrated significant advances in high-quality view synthesis. A major limitation of NeRF is its low rendering efficiency due to the need for multiple network forwardings to render a single pixel. Existing methods to improve NeRF either reduce the number of required samples or optimize the implementation to accelerate the network forwarding. Despite these efforts, the problem of multiple sampling persists due to the intrinsic representation of radiance fields. In contrast, Neural Light Fields (NeLF) reduce the computation cost of NeRF by querying only one single network forwarding per pixel. To achieve a close visual quality to NeRF, existing NeLF methods require significantly larger network capacities which limits their rendering efficiency in practice. In this work, we propose a new representation called Neural Radiance Distribution Field (NeRDF) that targets efficient view synthesis in real-time. Specifically, we use a small network similar to NeRF while preserving the rendering speed with a single network forwarding per pixel as in NeLF. The key is to model the radiance distribution along each ray with frequency basis and predict frequency weights using the network. Pixel values are then computed via volume rendering on radiance distributions. Experiments show that our proposed method offers a better trade-off among speed, quality, and network size than existing methods: we achieve a ~254x speed-up over NeRF with similar network size, with only a marginal performance decline. Our project page is at yushuang-wu.github.io/NeRDF.
G3Reg: Pyramid Graph-based Global Registration using Gaussian Ellipsoid Model
Aug 22, 2023This study introduces a novel framework, G3Reg, for fast and robust global registration of LiDAR point clouds. In contrast to conventional complex keypoints and descriptors, we extract fundamental geometric primitives including planes, clusters, and lines (PCL) from the raw point cloud to obtain low-level semantic segments. Each segment is formulated as a unified Gaussian Ellipsoid Model (GEM) by employing a probability ellipsoid to ensure the ground truth centers are encompassed with a certain degree of probability. Utilizing these GEMs, we then present a distrust-and-verify scheme based on a Pyramid Compatibility Graph for Global Registration (PAGOR). Specifically, we establish an upper bound, which can be traversed based on the confidence level for compatibility testing to construct the pyramid graph. Gradually, we solve multiple maximum cliques (MAC) for each level of the graph, generating numerous transformation candidates. In the verification phase, we adopt a precise and efficient metric for point cloud alignment quality, founded on geometric primitives, to identify the optimal candidate. The performance of the algorithm is extensively validated on three publicly available datasets and a self-collected multi-session dataset, without changing any parameter settings in the experimental evaluation. The results exhibit superior robustness and real-time performance of the G3Reg framework compared to state-of-the-art methods. Furthermore, we demonstrate the potential for integrating individual GEM and PAGOR components into other algorithmic frameworks to enhance their efficacy. To advance further research and promote community understanding, we have publicly shared the source code.
A Preliminary Investigation into Search and Matching for Tumour Discrimination in WHO Breast Taxonomy Using Deep Networks
Aug 22, 2023Breast cancer is one of the most common cancers affecting women worldwide. They include a group of malignant neoplasms with a variety of biological, clinical, and histopathological characteristics. There are more than 35 different histological forms of breast lesions that can be classified and diagnosed histologically according to cell morphology, growth, and architecture patterns. Recently, deep learning, in the field of artificial intelligence, has drawn a lot of attention for the computerized representation of medical images. Searchable digital atlases can provide pathologists with patch matching tools allowing them to search among evidently diagnosed and treated archival cases, a technology that may be regarded as computational second opinion. In this study, we indexed and analyzed the WHO breast taxonomy (Classification of Tumours 5th Ed.) spanning 35 tumour types. We visualized all tumour types using deep features extracted from a state-of-the-art deep learning model, pre-trained on millions of diagnostic histopathology images from the TCGA repository. Furthermore, we test the concept of a digital "atlas" as a reference for search and matching with rare test cases. The patch similarity search within the WHO breast taxonomy data reached over 88% accuracy when validating through "majority vote" and more than 91% accuracy when validating using top-n tumour types. These results show for the first time that complex relationships among common and rare breast lesions can be investigated using an indexed digital archive.