 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Don't lose the message while paraphrasing: A study on content preserving style transfer
Aug 17, 2023
Text style transfer techniques are gaining popularity in natural language processing allowing paraphrasing text in the required form: from toxic to neural, from formal to informal, from old to the modern English language, etc. Solving the task is not sufficient to generate some neural/informal/modern text, but it is important to preserve the original content unchanged. This requirement becomes even more critical in some applications such as style transfer of goal-oriented dialogues where the factual information shall be kept to preserve the original message, e.g. ordering a certain type of pizza to a certain address at a certain time. The aspect of content preservation is critical for real-world applications of style transfer studies, but it has received little attention. To bridge this gap we perform a comparison of various style transfer models on the example of the formality transfer domain. To perform a study of the content preservation abilities of various style transfer methods we create a parallel dataset of formal vs. informal task-oriented dialogues. The key difference between our dataset and the existing ones like GYAFC [17] is the presence of goal-oriented dialogues with predefined semantic slots essential to be kept during paraphrasing, e.g. named entities. This additional annotation allowed us to conduct a precise comparative study of several state-of-the-art techniques for style transfer. Another result of our study is a modification of the unsupervised method LEWIS [19] which yields a substantial improvement over the original method and all evaluated baselines on the proposed task.
Linguistically-Informed Neural Architectures for Lexical, Syntactic and Semantic Tasks in Sanskrit
Aug 17, 2023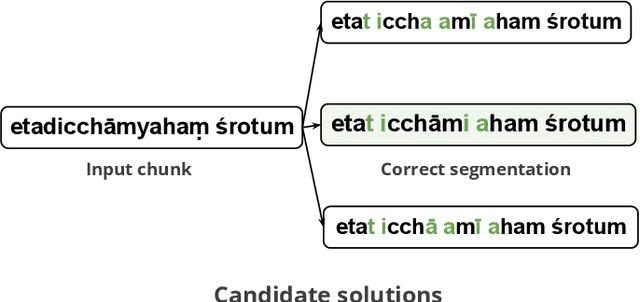
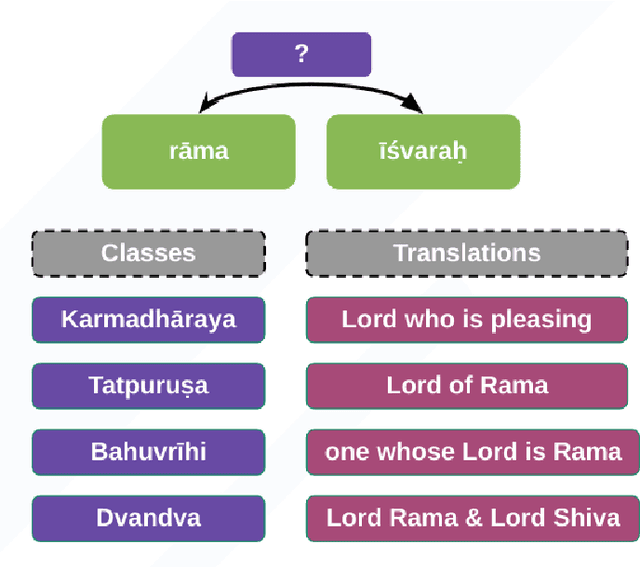
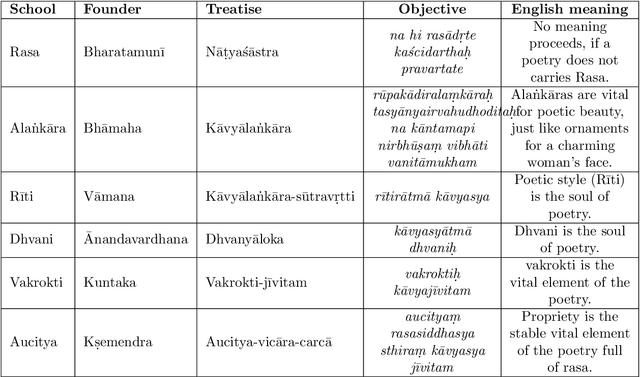
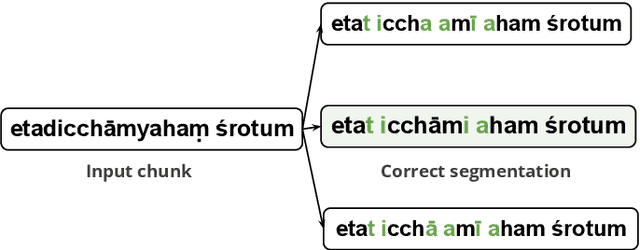
The primary focus of this thesis is to make Sanskrit manuscripts more accessible to the end-users through natural language technologies. The morphological richness, compounding, free word orderliness, and low-resource nature of Sanskrit pose significant challenges for developing deep learning solutions. We identify four fundamental tasks, which are crucial for developing a robust NLP technology for Sanskrit: word segmentation, dependency parsing, compound type identification, and poetry analysis. The first task, Sanskrit Word Segmentation (SWS), is a fundamental text processing task for any other downstream applications. However, it is challenging due to the sandhi phenomenon that modifies characters at word boundaries. Similarly, the existing dependency parsing approaches struggle with morphologically rich and low-resource languages like Sanskrit. Compound type identification is also challenging for Sanskrit due to the context-sensitive semantic relation between components. All these challenges result in sub-optimal performance in NLP applications like question answering and machine translation. Finally, Sanskrit poetry has not been extensively studied in computational linguistics. While addressing these challenges, this thesis makes various contributions: (1) The thesis proposes linguistically-informed neural architectures for these tasks. (2) We showcase the interpretability and multilingual extension of the proposed systems. (3) Our proposed systems report state-of-the-art performance. (4) Finally, we present a neural toolkit named SanskritShala, a web-based application that provides real-time analysis of input for various NLP tasks. Overall, this thesis contributes to making Sanskrit manuscripts more accessible by developing robust NLP technology and releasing various resources, datasets, and web-based toolkit.
Mining Negative Temporal Contexts For False Positive Suppression In Real-Time Ultrasound Lesion Detection
May 29, 2023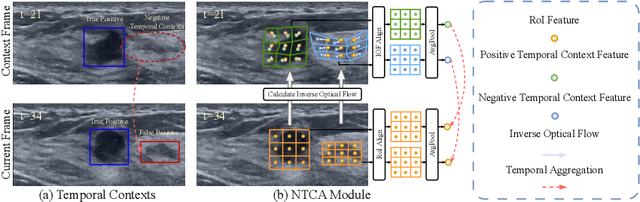
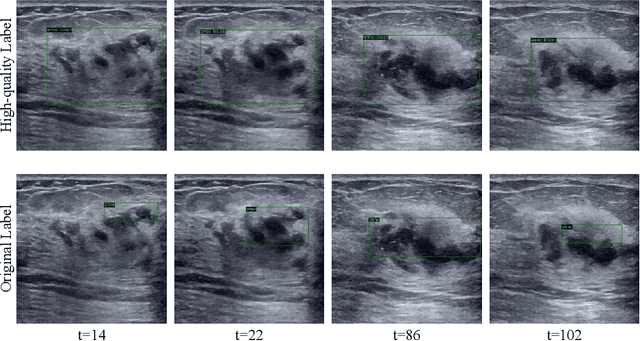

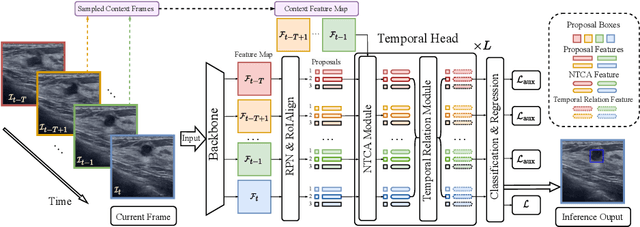
During ultrasonic scanning processes, real-time lesion detection can assist radiologists in accurate cancer diagnosis. However, this essential task remains challenging and underexplored. General-purpose real-time object detection models can mistakenly report obvious false positives (FPs) when applied to ultrasound videos, potentially misleading junior radiologists. One key issue is their failure to utilize negative symptoms in previous frames, denoted as negative temporal contexts (NTC). To address this issue, we propose to extract contexts from previous frames, including NTC, with the guidance of inverse optical flow. By aggregating extracted contexts, we endow the model with the ability to suppress FPs by leveraging NTC. We call the resulting model UltraDet. The proposed UltraDet demonstrates significant improvement over previous state-of-the-arts and achieves real-time inference speed. To facilitate future research, we will release the code, checkpoints, and high-quality labels of the CVA-BUS dataset used in our experiments.
A degree of image identification at sub-human scales could be possible with more advanced clusters
Aug 09, 2023
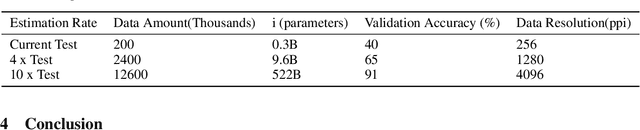
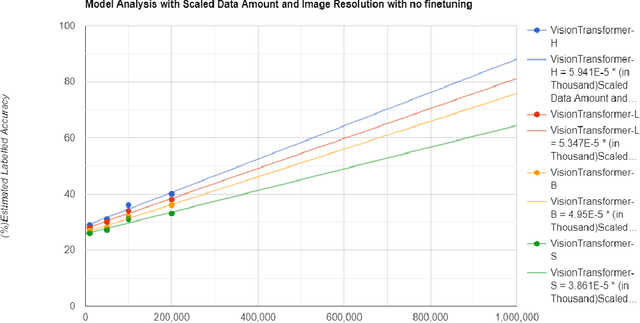
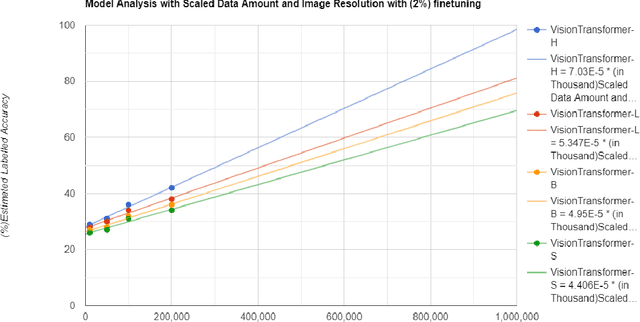
The purpose of the research is to determine if currently available self-supervised learning techniques can accomplish human level comprehension of visual images using the same degree and amount of sensory input that people acquire from. Initial research on this topic solely considered data volume scaling. Here, we scale both the volume of data and the quality of the image. This scaling experiment is a self-supervised learning method that may be done without any outside financing. We find that scaling up data volume and picture resolution at the same time enables human-level item detection performance at sub-human sizes.We run a scaling experiment with vision transformers trained on up to 200000 images up to 256 ppi.
SMURF: Spatial Multi-Representation Fusion for 3D Object Detection with 4D Imaging Radar
Aug 02, 2023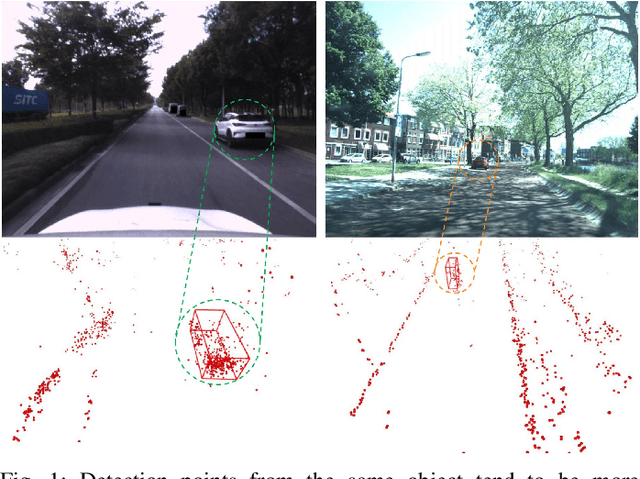
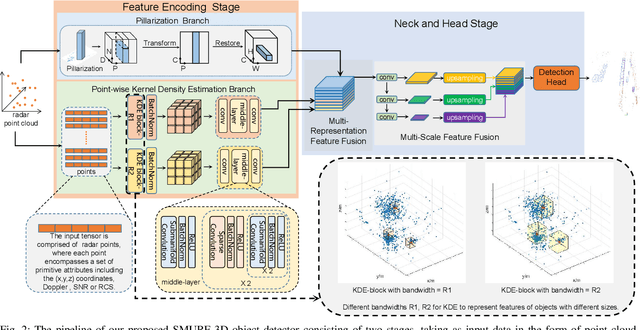
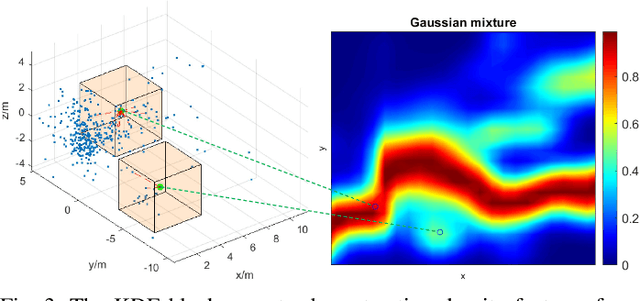
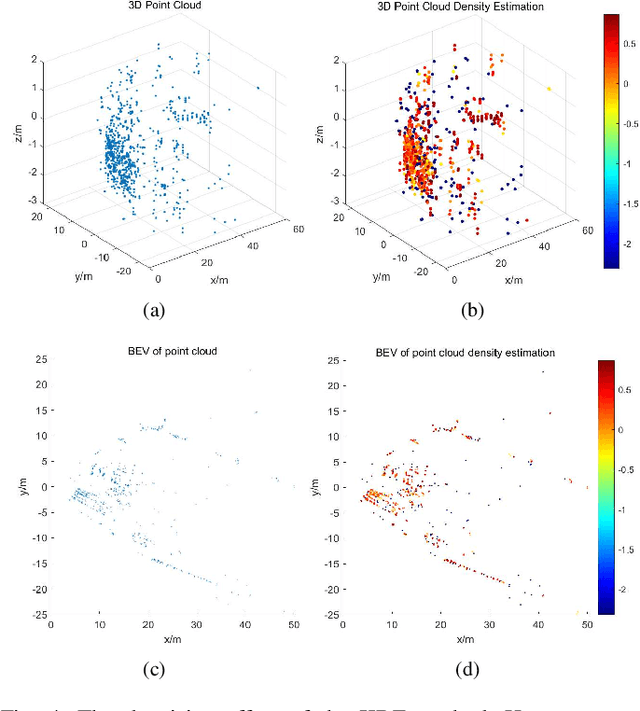
The 4D Millimeter wave (mmWave) radar is a promising technology for vehicle sensing due to its cost-effectiveness and operability in adverse weather conditions. However, the adoption of this technology has been hindered by sparsity and noise issues in radar point cloud data. This paper introduces spatial multi-representation fusion (SMURF), a novel approach to 3D object detection using a single 4D imaging radar. SMURF leverages multiple representations of radar detection points, including pillarization and density features of a multi-dimensional Gaussian mixture distribution through kernel density estimation (KDE). KDE effectively mitigates measurement inaccuracy caused by limited angular resolution and multi-path propagation of radar signals. Additionally, KDE helps alleviate point cloud sparsity by capturing density features. Experimental evaluations on View-of-Delft (VoD) and TJ4DRadSet datasets demonstrate the effectiveness and generalization ability of SMURF, outperforming recently proposed 4D imaging radar-based single-representation models. Moreover, while using 4D imaging radar only, SMURF still achieves comparable performance to the state-of-the-art 4D imaging radar and camera fusion-based method, with an increase of 1.22% in the mean average precision on bird's-eye view of TJ4DRadSet dataset and 1.32% in the 3D mean average precision on the entire annotated area of VoD dataset. Our proposed method demonstrates impressive inference time and addresses the challenges of real-time detection, with the inference time no more than 0.05 seconds for most scans on both datasets. This research highlights the benefits of 4D mmWave radar and is a strong benchmark for subsequent works regarding 3D object detection with 4D imaging radar.
US & MR Image-Fusion Based on Skin Co-Registration
Jul 26, 2023
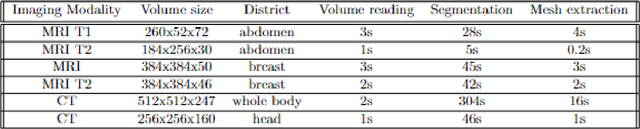


The study and development of innovative solutions for the advanced visualisation, representation and analysis of medical images offer different research directions. Current practice in medical imaging consists in combining real-time US with imaging modalities that allow internal anatomy acquisitions, such as CT, MRI, PET or similar. Application of image-fusion approaches can be found in tracking surgical tools and/or needles, in real-time during interventions. Thus, this work proposes a fusion imaging system for the registration of CT and MRI images with real-time US acquisition leveraging a 3D camera sensor. The main focus of the work is the portability of the system and its applicability to different anatomical districts.
Computer Vision for Construction Progress Monitoring: A Real-Time Object Detection Approach
May 24, 2023

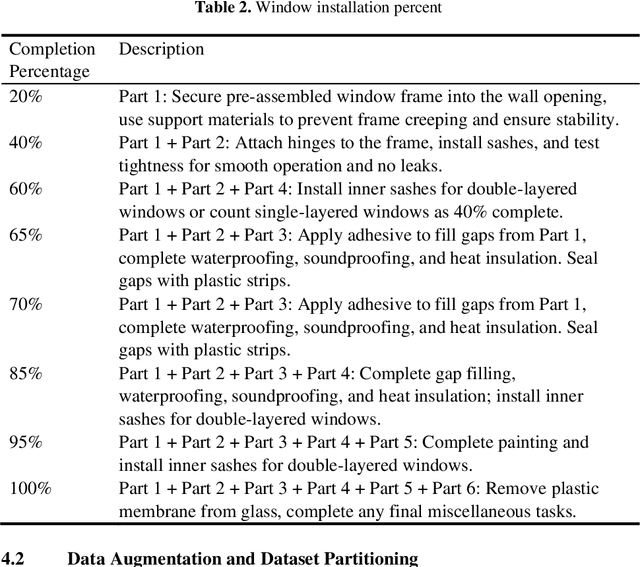
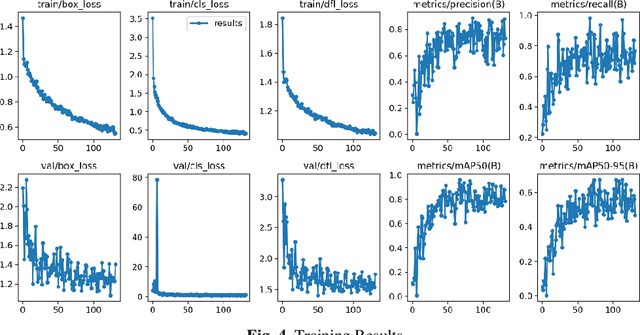
Construction progress monitoring (CPM) is essential for effective project management, ensuring on-time and on-budget delivery. Traditional CPM methods often rely on manual inspection and reporting, which are time-consuming and prone to errors. This paper proposes a novel approach for automated CPM using state-of-the-art object detection algorithms. The proposed method leverages e.g. YOLOv8's real-time capabilities and high accuracy to identify and track construction elements within site images and videos. A dataset was created, consisting of various building elements and annotated with relevant objects for training and validation. The performance of the proposed approach was evaluated using standard metrics, such as precision, recall, and F1-score, demonstrating significant improvement over existing methods. The integration of Computer Vision into CPM provides stakeholders with reliable, efficient, and cost-effective means to monitor project progress, facilitating timely decision-making and ultimately contributing to the successful completion of construction projects.
Robust Autonomous Vehicle Pursuit without Expert Steering Labels
Aug 16, 2023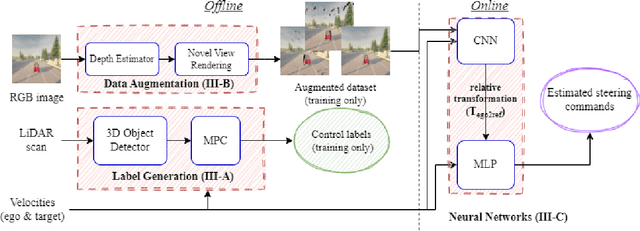

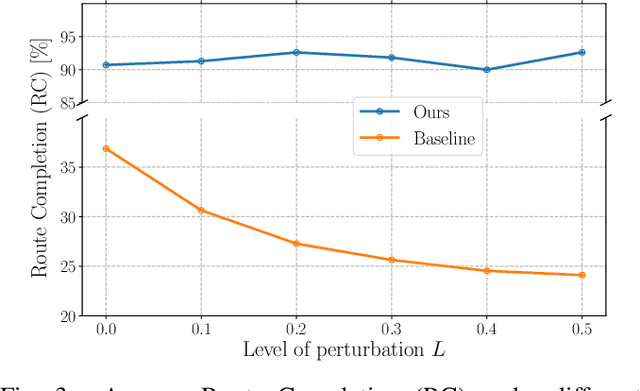
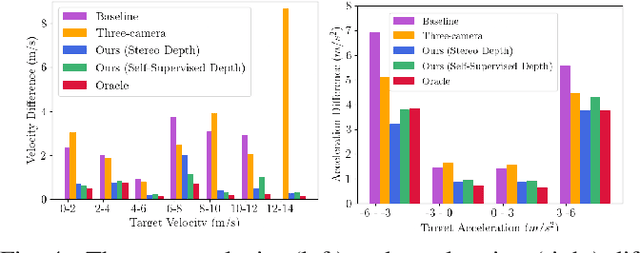
In this work, we present a learning method for lateral and longitudinal motion control of an ego-vehicle for vehicle pursuit. The car being controlled does not have a pre-defined route, rather it reactively adapts to follow a target vehicle while maintaining a safety distance. To train our model, we do not rely on steering labels recorded from an expert driver but effectively leverage a classical controller as an offline label generation tool. In addition, we account for the errors in the predicted control values, which can lead to a loss of tracking and catastrophic crashes of the controlled vehicle. To this end, we propose an effective data augmentation approach, which allows to train a network capable of handling different views of the target vehicle. During the pursuit, the target vehicle is firstly localized using a Convolutional Neural Network. The network takes a single RGB image along with cars' velocities and estimates the target vehicle's pose with respect to the ego-vehicle. This information is then fed to a Multi-Layer Perceptron, which regresses the control commands for the ego-vehicle, namely throttle and steering angle. We extensively validate our approach using the CARLA simulator on a wide range of terrains. Our method demonstrates real-time performance and robustness to different scenarios including unseen trajectories and high route completion. The project page containing code and multimedia can be publicly accessed here: https://changyaozhou.github.io/Autonomous-Vehicle-Pursuit/.
Deployment and Analysis of Instance Segmentation Algorithm for In-field Grade Estimation of Sweetpotatoes
Aug 16, 2023Shape estimation of sweetpotato (SP) storage roots is inherently challenging due to their varied size and shape characteristics. Even measuring "simple" metrics, such as length and width, requires significant time investments either directly in-field or afterward using automated graders. In this paper, we present the results of a model that can perform grading and provide yield estimates directly in the field quicker than manual measurements. Detectron2, a library consisting of deep-learning object detection algorithms, was used to implement Mask R-CNN, an instance segmentation model. This model was deployed for in-field grade estimation of SPs and evaluated against an optical sorter. Storage roots from various clones imaged with a cellphone during trials between 2019 and 2020, were used in the model's training and validation to fine-tune a model to detect SPs. Our results showed that the model could distinguish individual SPs in various environmental conditions including variations in lighting and soil characteristics. RMSE for length, width, and weight, from the model compared to a commercial optical sorter, were 0.66 cm, 1.22 cm, and 74.73 g, respectively, while the RMSE of root counts per plot was 5.27 roots, with r^2 = 0.8. This phenotyping strategy has the potential enable rapid yield estimates in the field without the need for sophisticated and costly optical sorters and may be more readily deployed in environments with limited access to these kinds of resources or facilities.
HTP: Exploiting Holistic Temporal Patterns for Sequential Recommendation
Jul 22, 2023
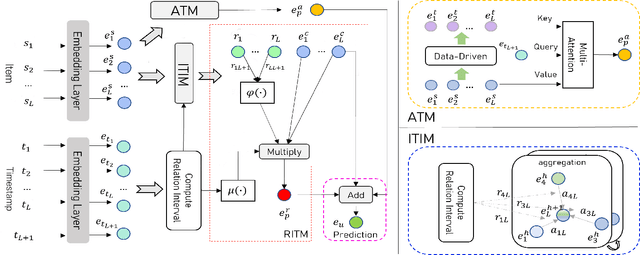

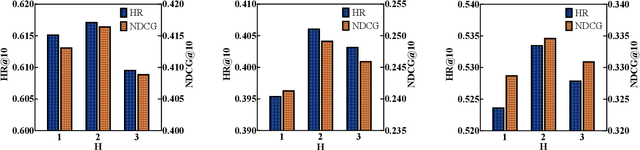
Sequential recommender systems have demonstrated a huge success for next-item recommendation by explicitly exploiting the temporal order of users' historical interactions. In practice, user interactions contain more useful temporal information beyond order, as shown by some pioneering studies. In this paper, we systematically investigate various temporal information for sequential recommendation and identify three types of advantageous temporal patterns beyond order, including absolute time information, relative item time intervals and relative recommendation time intervals. We are the first to explore item-oriented absolute time patterns. While existing models consider only one or two of these three patterns, we propose a novel holistic temporal pattern based neural network, named HTP, to fully leverage all these three patterns. In particular, we introduce novel components to address the subtle correlations between relative item time intervals and relative recommendation time intervals, which render a major technical challenge. Extensive experiments on three real-world benchmark datasets show that our HTP model consistently and substantially outperforms many state-of-the-art models. Our code is publically available at https://github.com/623851394/HTP/tree/main/HTP-main