 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SMURF: Spatial Multi-Representation Fusion for 3D Object Detection with 4D Imaging Radar
Aug 02, 2023
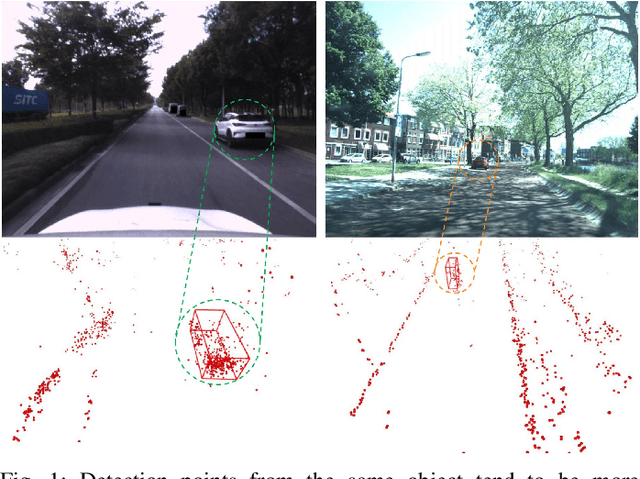
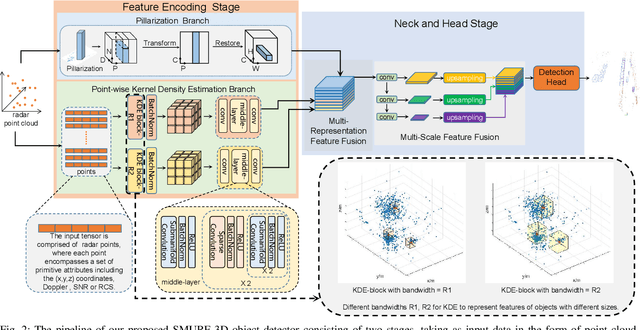
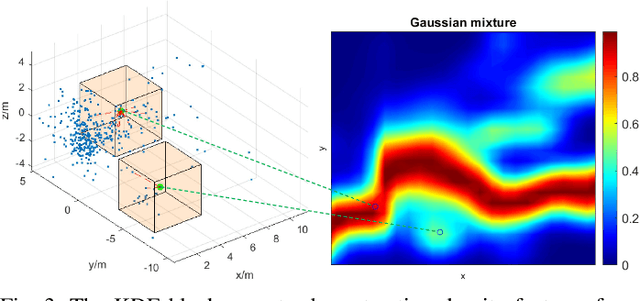
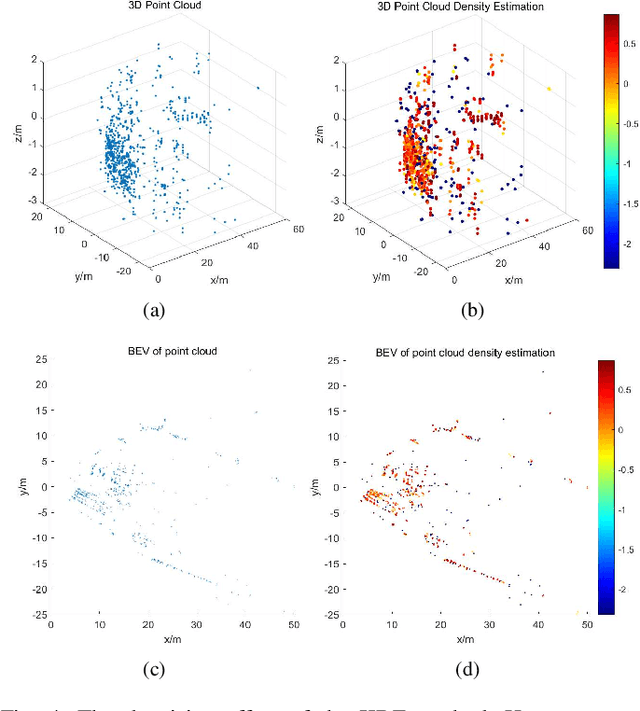
The 4D Millimeter wave (mmWave) radar is a promising technology for vehicle sensing due to its cost-effectiveness and operability in adverse weather conditions. However, the adoption of this technology has been hindered by sparsity and noise issues in radar point cloud data. This paper introduces spatial multi-representation fusion (SMURF), a novel approach to 3D object detection using a single 4D imaging radar. SMURF leverages multiple representations of radar detection points, including pillarization and density features of a multi-dimensional Gaussian mixture distribution through kernel density estimation (KDE). KDE effectively mitigates measurement inaccuracy caused by limited angular resolution and multi-path propagation of radar signals. Additionally, KDE helps alleviate point cloud sparsity by capturing density features. Experimental evaluations on View-of-Delft (VoD) and TJ4DRadSet datasets demonstrate the effectiveness and generalization ability of SMURF, outperforming recently proposed 4D imaging radar-based single-representation models. Moreover, while using 4D imaging radar only, SMURF still achieves comparable performance to the state-of-the-art 4D imaging radar and camera fusion-based method, with an increase of 1.22% in the mean average precision on bird's-eye view of TJ4DRadSet dataset and 1.32% in the 3D mean average precision on the entire annotated area of VoD dataset. Our proposed method demonstrates impressive inference time and addresses the challenges of real-time detection, with the inference time no more than 0.05 seconds for most scans on both datasets. This research highlights the benefits of 4D mmWave radar and is a strong benchmark for subsequent works regarding 3D object detection with 4D imaging radar.
Tirtha -- An Automated Platform to Crowdsource Images and Create 3D Models of Heritage Sites
Aug 15, 2023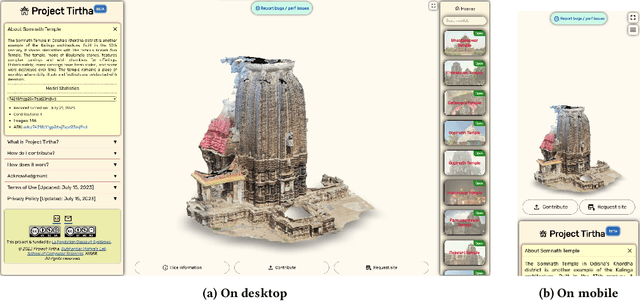
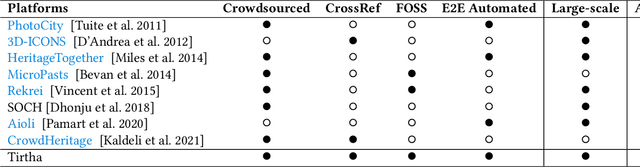
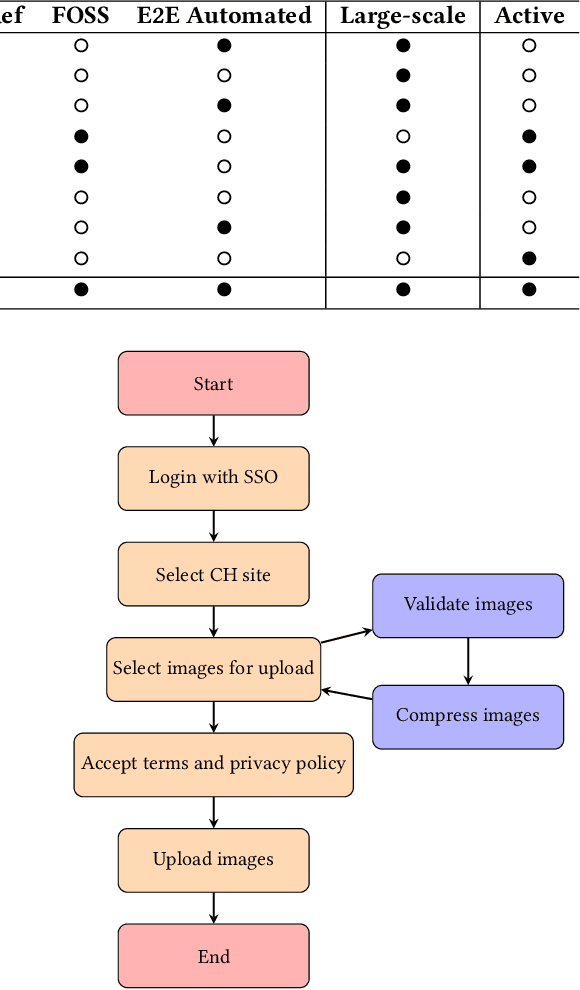
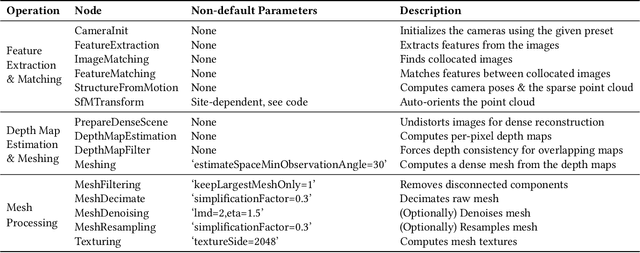
Digital preservation of Cultural Heritage (CH) sites is crucial to protect them against damage from natural disasters or human activities. Creating 3D models of CH sites has become a popular method of digital preservation thanks to advancements in computer vision and photogrammetry. However, the process is time-consuming, expensive, and typically requires specialized equipment and expertise, posing challenges in resource-limited developing countries. Additionally, the lack of an open repository for 3D models hinders research and public engagement with their heritage. To address these issues, we propose Tirtha, a web platform for crowdsourcing images of CH sites and creating their 3D models. Tirtha utilizes state-of-the-art Structure from Motion (SfM) and Multi-View Stereo (MVS) techniques. It is modular, extensible and cost-effective, allowing for the incorporation of new techniques as photogrammetry advances. Tirtha is accessible through a web interface at https://tirtha.niser.ac.in and can be deployed on-premise or in a cloud environment. In our case studies, we demonstrate the pipeline's effectiveness by creating 3D models of temples in Odisha, India, using crowdsourced images. These models are available for viewing, interaction, and download on the Tirtha website. Our work aims to provide a dataset of crowdsourced images and 3D reconstructions for research in computer vision, heritage conservation, and related domains. Overall, Tirtha is a step towards democratizing digital preservation, primarily in resource-limited developing countries.
AttMOT: Improving Multiple-Object Tracking by Introducing Auxiliary Pedestrian Attributes
Aug 15, 2023


Multi-object tracking (MOT) is a fundamental problem in computer vision with numerous applications, such as intelligent surveillance and automated driving. Despite the significant progress made in MOT, pedestrian attributes, such as gender, hairstyle, body shape, and clothing features, which contain rich and high-level information, have been less explored. To address this gap, we propose a simple, effective, and generic method to predict pedestrian attributes to support general Re-ID embedding. We first introduce AttMOT, a large, highly enriched synthetic dataset for pedestrian tracking, containing over 80k frames and 6 million pedestrian IDs with different time, weather conditions, and scenarios. To the best of our knowledge, AttMOT is the first MOT dataset with semantic attributes. Subsequently, we explore different approaches to fuse Re-ID embedding and pedestrian attributes, including attention mechanisms, which we hope will stimulate the development of attribute-assisted MOT. The proposed method AAM demonstrates its effectiveness and generality on several representative pedestrian multi-object tracking benchmarks, including MOT17 and MOT20, through experiments on the AttMOT dataset. When applied to state-of-the-art trackers, AAM achieves consistent improvements in MOTA, HOTA, AssA, IDs, and IDF1 scores. For instance, on MOT17, the proposed method yields a +1.1 MOTA, +1.7 HOTA, and +1.8 IDF1 improvement when used with FairMOT. To encourage further research on attribute-assisted MOT, we will release the AttMOT dataset.
Multimodal Dataset Distillation for Image-Text Retrieval
Aug 15, 2023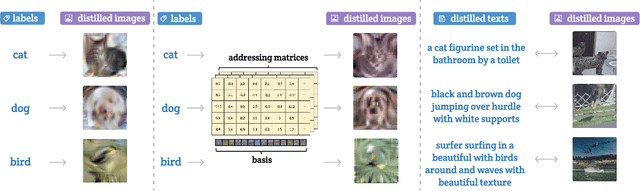
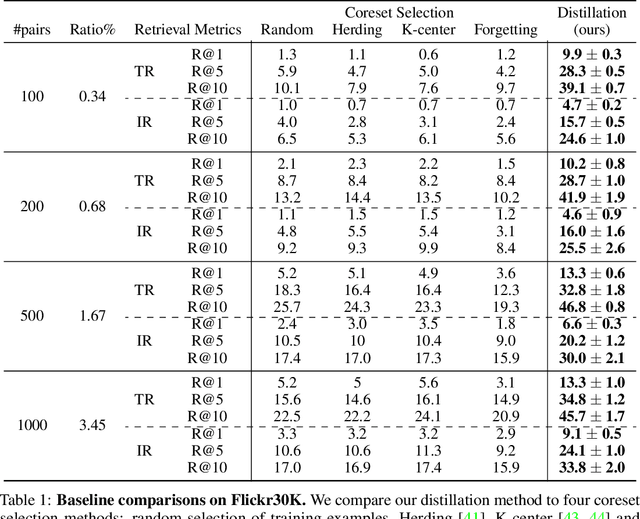
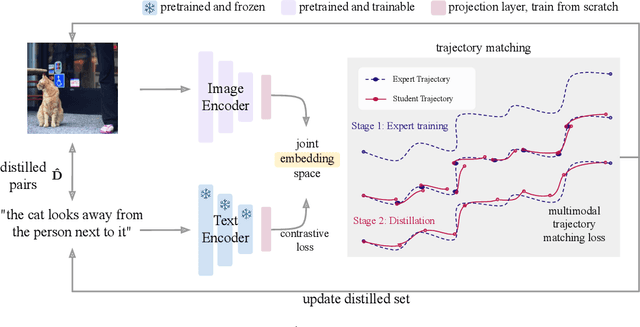
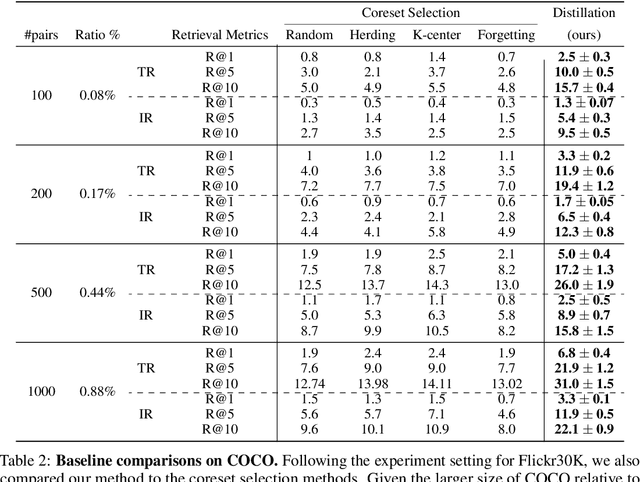
Dataset distillation methods offer the promise of reducing a large-scale dataset down to a significantly smaller set of (potentially synthetic) training examples, which preserve sufficient information for training a new model from scratch. So far dataset distillation methods have been developed for image classification. However, with the rise in capabilities of vision-language models, and especially given the scale of datasets necessary to train these models, the time is ripe to expand dataset distillation methods beyond image classification. In this work, we take the first steps towards this goal by expanding on the idea of trajectory matching to create a distillation method for vision-language datasets. The key challenge is that vision-language datasets do not have a set of discrete classes. To overcome this, our proposed multimodal dataset distillation method jointly distill the images and their corresponding language descriptions in a contrastive formulation. Since there are no existing baselines, we compare our approach to three coreset selection methods (strategic subsampling of the training dataset), which we adapt to the vision-language setting. We demonstrate significant improvements on the challenging Flickr30K and COCO retrieval benchmark: the best coreset selection method which selects 1000 image-text pairs for training is able to achieve only 5.6% image-to-text retrieval accuracy (recall@1); in contrast, our dataset distillation approach almost doubles that with just 100 (an order of magnitude fewer) training pairs.
Vision-based Semantic Communications for Metaverse Services: A Contest Theoretic Approach
Aug 15, 2023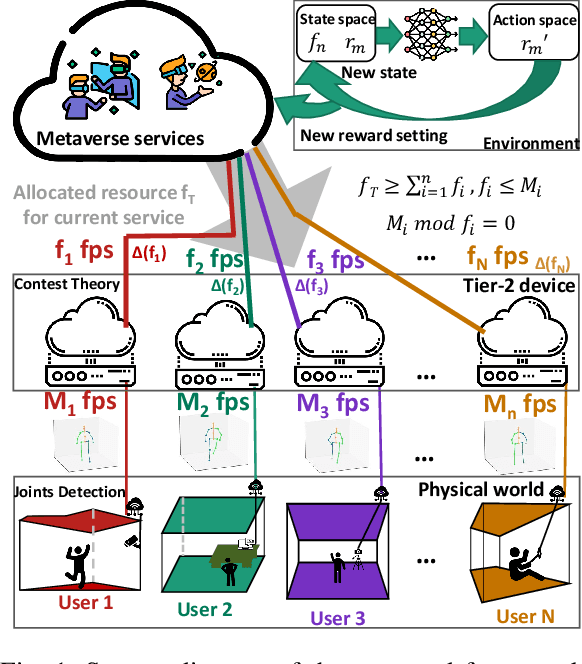
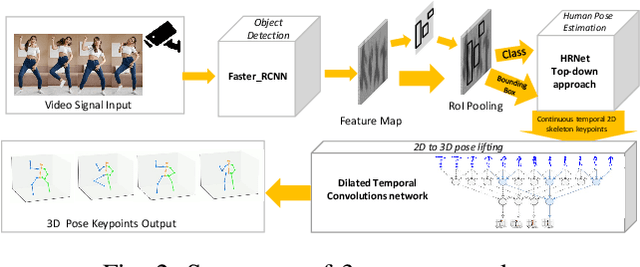
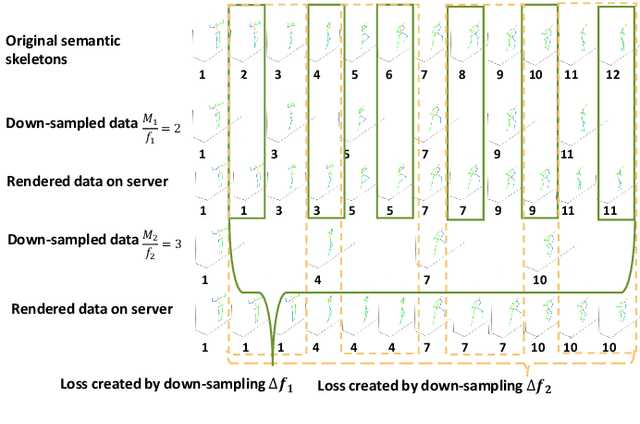
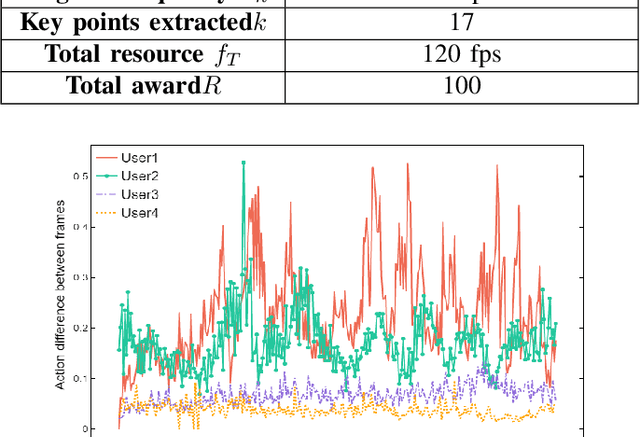
The popularity of Metaverse as an entertainment, social, and work platform has led to a great need for seamless avatar integration in the virtual world. In Metaverse, avatars must be updated and rendered to reflect users' behaviour. Achieving real-time synchronization between the virtual bilocation and the user is complex, placing high demands on the Metaverse Service Provider (MSP)'s rendering resource allocation scheme. To tackle this issue, we propose a semantic communication framework that leverages contest theory to model the interactions between users and MSPs and determine optimal resource allocation for each user. To reduce the consumption of network resources in wireless transmission, we use the semantic communication technique to reduce the amount of data to be transmitted. Under our simulation settings, the encoded semantic data only contains 51 bytes of skeleton coordinates instead of the image size of 8.243 megabytes. Moreover, we implement Deep Q-Network to optimize reward settings for maximum performance and efficient resource allocation. With the optimal reward setting, users are incentivized to select their respective suitable uploading frequency, reducing down-sampling loss due to rendering resource constraints by 66.076\% compared with the traditional average distribution method. The framework provides a novel solution to resource allocation for avatar association in VR environments, ensuring a smooth and immersive experience for all users.
Dynamic Embedding Size Search with Minimum Regret for Streaming Recommender System
Aug 15, 2023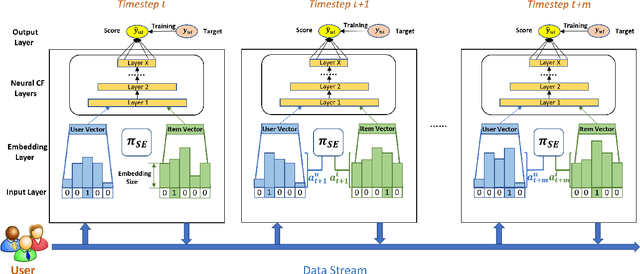
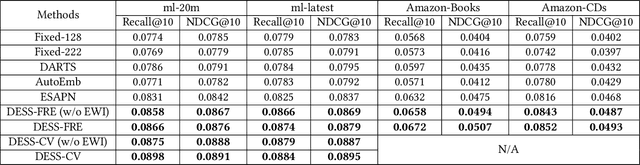
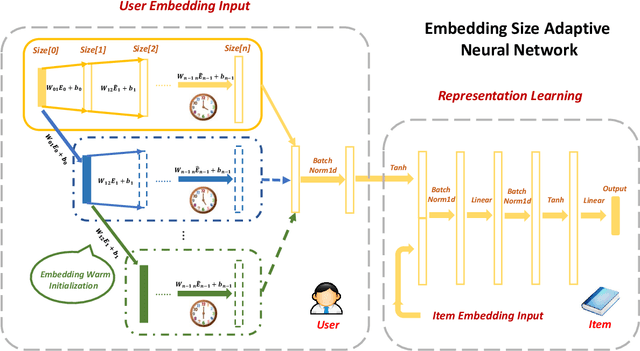
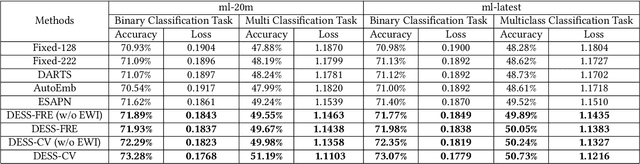
With the continuous increase of users and items, conventional recommender systems trained on static datasets can hardly adapt to changing environments. The high-throughput data requires the model to be updated in a timely manner for capturing the user interest dynamics, which leads to the emergence of streaming recommender systems. Due to the prevalence of deep learning-based recommender systems, the embedding layer is widely adopted to represent the characteristics of users, items, and other features in low-dimensional vectors. However, it has been proved that setting an identical and static embedding size is sub-optimal in terms of recommendation performance and memory cost, especially for streaming recommendations. To tackle this problem, we first rethink the streaming model update process and model the dynamic embedding size search as a bandit problem. Then, we analyze and quantify the factors that influence the optimal embedding sizes from the statistics perspective. Based on this, we propose the \textbf{D}ynamic \textbf{E}mbedding \textbf{S}ize \textbf{S}earch (\textbf{DESS}) method to minimize the embedding size selection regret on both user and item sides in a non-stationary manner. Theoretically, we obtain a sublinear regret upper bound superior to previous methods. Empirical results across two recommendation tasks on four public datasets also demonstrate that our approach can achieve better streaming recommendation performance with lower memory cost and higher time efficiency.
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
Aug 15, 2023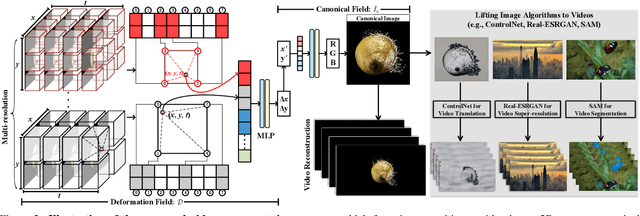



We present the content deformation field CoDeF as a new type of video representation, which consists of a canonical content field aggregating the static contents in the entire video and a temporal deformation field recording the transformations from the canonical image (i.e., rendered from the canonical content field) to each individual frame along the time axis.Given a target video, these two fields are jointly optimized to reconstruct it through a carefully tailored rendering pipeline.We advisedly introduce some regularizations into the optimization process, urging the canonical content field to inherit semantics (e.g., the object shape) from the video.With such a design, CoDeF naturally supports lifting image algorithms for video processing, in the sense that one can apply an image algorithm to the canonical image and effortlessly propagate the outcomes to the entire video with the aid of the temporal deformation field.We experimentally show that CoDeF is able to lift image-to-image translation to video-to-video translation and lift keypoint detection to keypoint tracking without any training.More importantly, thanks to our lifting strategy that deploys the algorithms on only one image, we achieve superior cross-frame consistency in processed videos compared to existing video-to-video translation approaches, and even manage to track non-rigid objects like water and smog.Project page can be found at https://qiuyu96.github.io/CoDeF/.
Helping Hands: An Object-Aware Ego-Centric Video Recognition Model
Aug 15, 2023We introduce an object-aware decoder for improving the performance of spatio-temporal representations on ego-centric videos. The key idea is to enhance object-awareness during training by tasking the model to predict hand positions, object positions, and the semantic label of the objects using paired captions when available. At inference time the model only requires RGB frames as inputs, and is able to track and ground objects (although it has not been trained explicitly for this). We demonstrate the performance of the object-aware representations learnt by our model, by: (i) evaluating it for strong transfer, i.e. through zero-shot testing, on a number of downstream video-text retrieval and classification benchmarks; and (ii) by using the representations learned as input for long-term video understanding tasks (e.g. Episodic Memory in Ego4D). In all cases the performance improves over the state of the art -- even compared to networks trained with far larger batch sizes. We also show that by using noisy image-level detection as pseudo-labels in training, the model learns to provide better bounding boxes using video consistency, as well as grounding the words in the associated text descriptions. Overall, we show that the model can act as a drop-in replacement for an ego-centric video model to improve performance through visual-text grounding.
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Aug 15, 2023
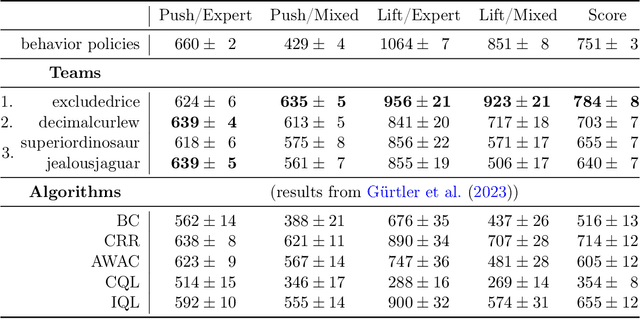
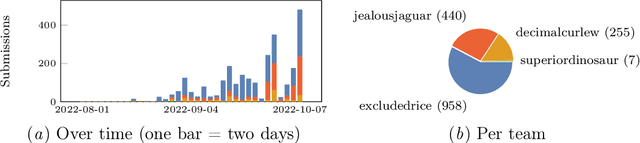
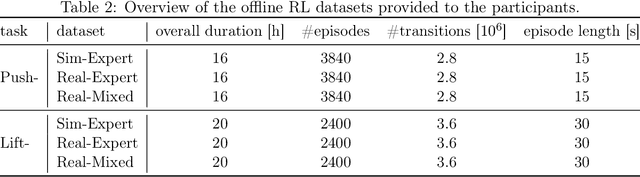
Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
From Commit Message Generation to History-Aware Commit Message Completion
Aug 15, 2023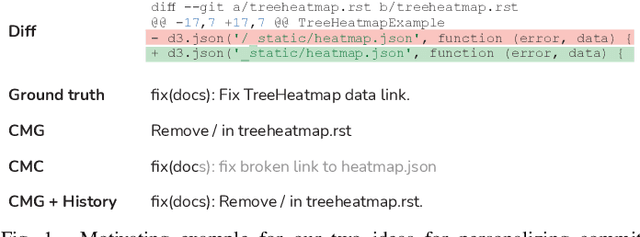
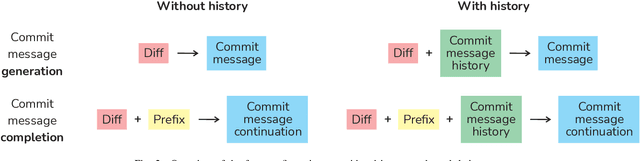
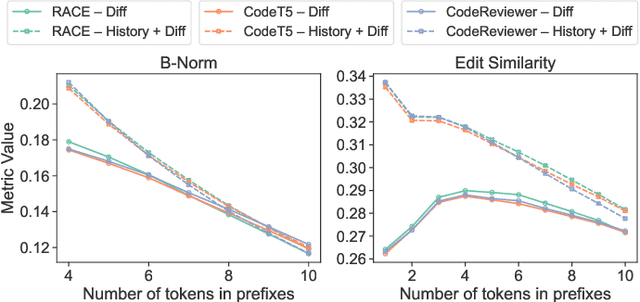
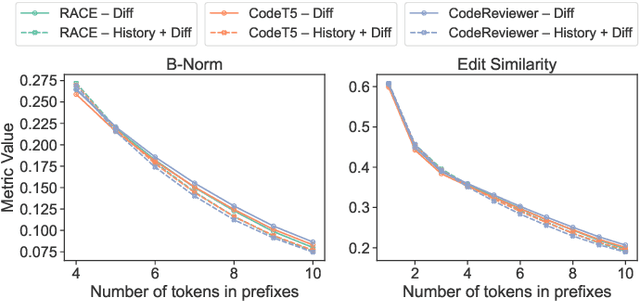
Commit messages are crucial to software development, allowing developers to track changes and collaborate effectively. Despite their utility, most commit messages lack important information since writing high-quality commit messages is tedious and time-consuming. The active research on commit message generation (CMG) has not yet led to wide adoption in practice. We argue that if we could shift the focus from commit message generation to commit message completion and use previous commit history as additional context, we could significantly improve the quality and the personal nature of the resulting commit messages. In this paper, we propose and evaluate both of these novel ideas. Since the existing datasets lack historical data, we collect and share a novel dataset called CommitChronicle, containing 10.7M commits across 20 programming languages. We use this dataset to evaluate the completion setting and the usefulness of the historical context for state-of-the-art CMG models and GPT-3.5-turbo. Our results show that in some contexts, commit message completion shows better results than generation, and that while in general GPT-3.5-turbo performs worse, it shows potential for long and detailed messages. As for the history, the results show that historical information improves the performance of CMG models in the generation task, and the performance of GPT-3.5-turbo in both generation and completion.