 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Onboard Object Detection for Augmented Reality: Enhancing Head-Mounted Display with YOLOv8
Jun 06, 2023

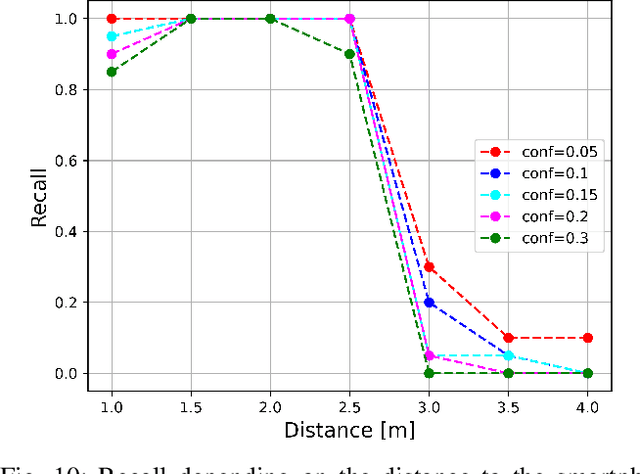
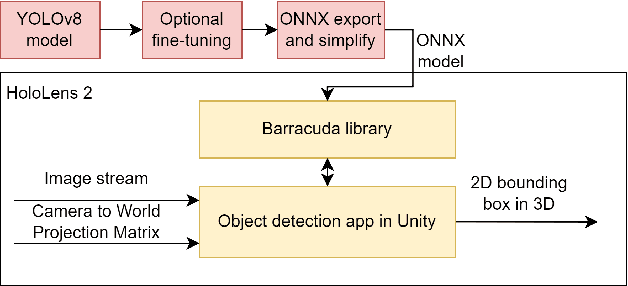
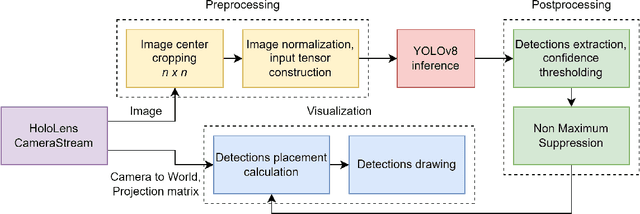
This paper introduces a software architecture for real-time object detection using machine learning (ML) in an augmented reality (AR) environment. Our approach uses the recent state-of-the-art YOLOv8 network that runs onboard on the Microsoft HoloLens 2 head-mounted display (HMD). The primary motivation behind this research is to enable the application of advanced ML models for enhanced perception and situational awareness with a wearable, hands-free AR platform. We show the image processing pipeline for the YOLOv8 model and the techniques used to make it real-time on the resource-limited edge computing platform of the headset. The experimental results demonstrate that our solution achieves real-time processing without needing offloading tasks to the cloud or any other external servers while retaining satisfactory accuracy regarding the usual mAP metric and measured qualitative performance
An Intentional Forgetting-Driven Self-Healing Method For Deep Reinforcement Learning Systems
Aug 23, 2023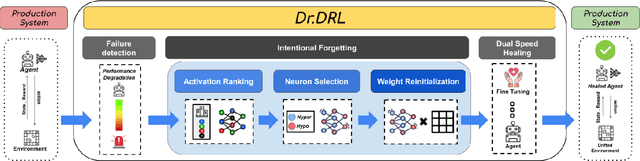
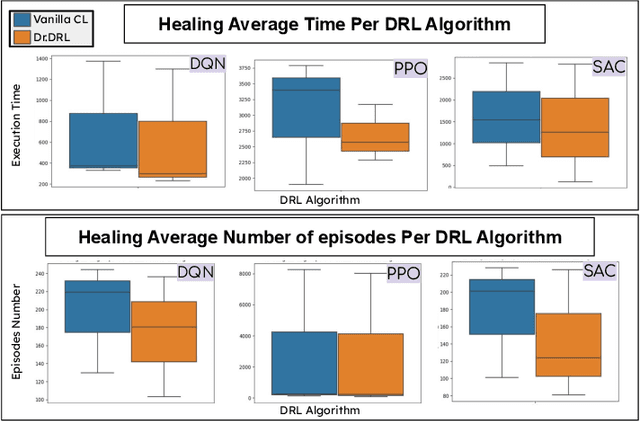
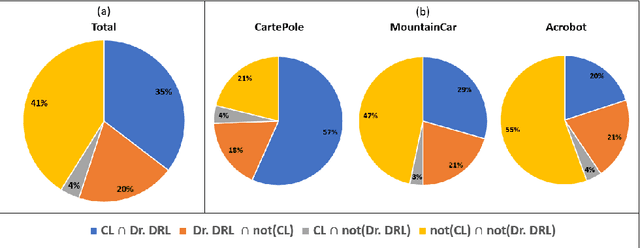
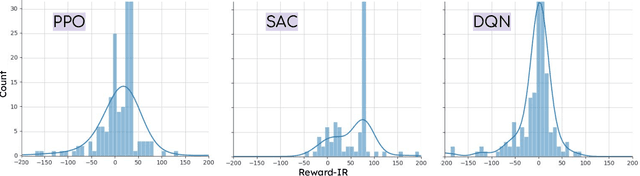
Deep reinforcement learning (DRL) is increasingly applied in large-scale productions like Netflix and Facebook. As with most data-driven systems, DRL systems can exhibit undesirable behaviors due to environmental drifts, which often occur in constantly-changing production settings. Continual Learning (CL) is the inherent self-healing approach for adapting the DRL agent in response to the environment's conditions shifts. However, successive shifts of considerable magnitude may cause the production environment to drift from its original state. Recent studies have shown that these environmental drifts tend to drive CL into long, or even unsuccessful, healing cycles, which arise from inefficiencies such as catastrophic forgetting, warm-starting failure, and slow convergence. In this paper, we propose Dr. DRL, an effective self-healing approach for DRL systems that integrates a novel mechanism of intentional forgetting into vanilla CL to overcome its main issues. Dr. DRL deliberately erases the DRL system's minor behaviors to systematically prioritize the adaptation of the key problem-solving skills. Using well-established DRL algorithms, Dr. DRL is compared with vanilla CL on various drifted environments. Dr. DRL is able to reduce, on average, the healing time and fine-tuning episodes by, respectively, 18.74% and 17.72%. Dr. DRL successfully helps agents to adapt to 19.63% of drifted environments left unsolved by vanilla CL while maintaining and even enhancing by up to 45% the obtained rewards for drifted environments that are resolved by both approaches.
Addressing Selection Bias in Computerized Adaptive Testing: A User-Wise Aggregate Influence Function Approach
Aug 23, 2023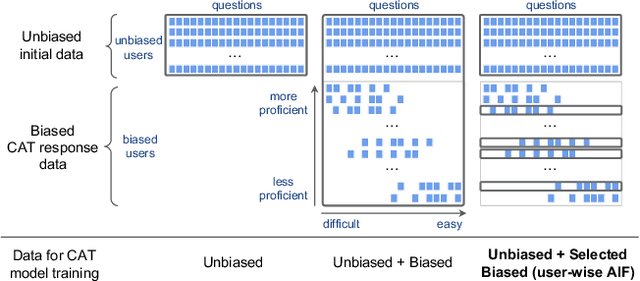


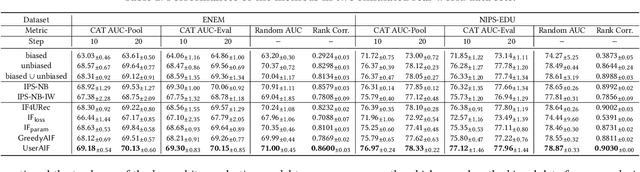
Computerized Adaptive Testing (CAT) is a widely used, efficient test mode that adapts to the examinee's proficiency level in the test domain. CAT requires pre-trained item profiles, for CAT iteratively assesses the student real-time based on the registered items' profiles, and selects the next item to administer using candidate items' profiles. However, obtaining such item profiles is a costly process that involves gathering a large, dense item-response data, then training a diagnostic model on the collected data. In this paper, we explore the possibility of leveraging response data collected in the CAT service. We first show that this poses a unique challenge due to the inherent selection bias introduced by CAT, i.e., more proficient students will receive harder questions. Indeed, when naively training the diagnostic model using CAT response data, we observe that item profiles deviate significantly from the ground-truth. To tackle the selection bias issue, we propose the user-wise aggregate influence function method. Our intuition is to filter out users whose response data is heavily biased in an aggregate manner, as judged by how much perturbation the added data will introduce during parameter estimation. This way, we may enhance the performance of CAT while introducing minimal bias to the item profiles. We provide extensive experiments to demonstrate the superiority of our proposed method based on the three public datasets and one dataset that contains real-world CAT response data.
Bridging High-Quality Audio and Video via Language for Sound Effects Retrieval from Visual Queries
Aug 17, 2023
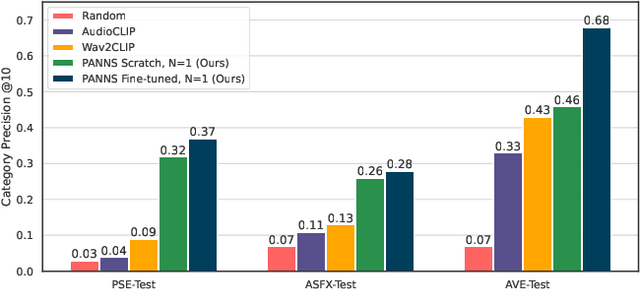
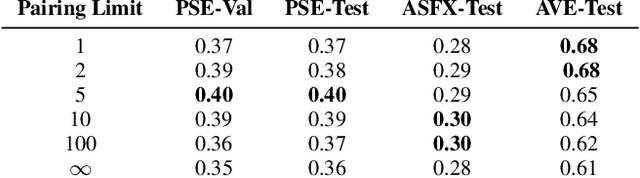
Finding the right sound effects (SFX) to match moments in a video is a difficult and time-consuming task, and relies heavily on the quality and completeness of text metadata. Retrieving high-quality (HQ) SFX using a video frame directly as the query is an attractive alternative, removing the reliance on text metadata and providing a low barrier to entry for non-experts. Due to the lack of HQ audio-visual training data, previous work on audio-visual retrieval relies on YouTube (in-the-wild) videos of varied quality for training, where the audio is often noisy and the video of amateur quality. As such it is unclear whether these systems would generalize to the task of matching HQ audio to production-quality video. To address this, we propose a multimodal framework for recommending HQ SFX given a video frame by (1) leveraging large language models and foundational vision-language models to bridge HQ audio and video to create audio-visual pairs, resulting in a highly scalable automatic audio-visual data curation pipeline; and (2) using pre-trained audio and visual encoders to train a contrastive learning-based retrieval system. We show that our system, trained using our automatic data curation pipeline, significantly outperforms baselines trained on in-the-wild data on the task of HQ SFX retrieval for video. Furthermore, while the baselines fail to generalize to this task, our system generalizes well from clean to in-the-wild data, outperforming the baselines on a dataset of YouTube videos despite only being trained on the HQ audio-visual pairs. A user study confirms that people prefer SFX retrieved by our system over the baseline 67% of the time both for HQ and in-the-wild data. Finally, we present ablations to determine the impact of model and data pipeline design choices on downstream retrieval performance. Please visit our project website to listen to and view our SFX retrieval results.
Graph-based Time Series Clustering for End-to-End Hierarchical Forecasting
May 30, 2023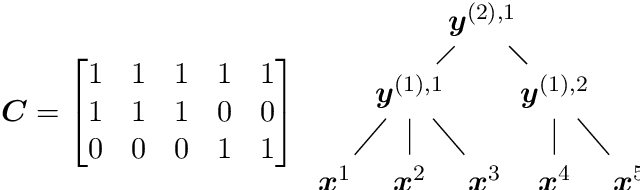
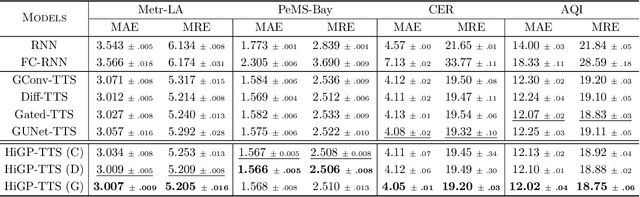
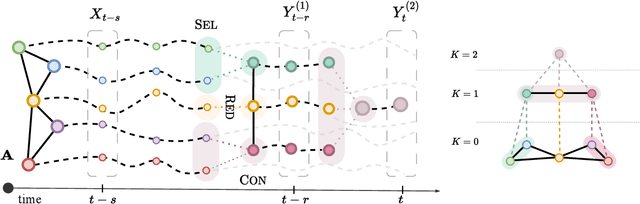
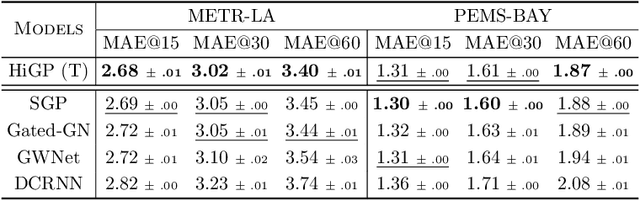
Existing relationships among time series can be exploited as inductive biases in learning effective forecasting models. In hierarchical time series, relationships among subsets of sequences induce hard constraints (hierarchical inductive biases) on the predicted values. In this paper, we propose a graph-based methodology to unify relational and hierarchical inductive biases in the context of deep learning for time series forecasting. In particular, we model both types of relationships as dependencies in a pyramidal graph structure, with each pyramidal layer corresponding to a level of the hierarchy. By exploiting modern - trainable - graph pooling operators we show that the hierarchical structure, if not available as a prior, can be learned directly from data, thus obtaining cluster assignments aligned with the forecasting objective. A differentiable reconciliation stage is incorporated into the processing architecture, allowing hierarchical constraints to act both as an architectural bias as well as a regularization element for predictions. Simulation results on representative datasets show that the proposed method compares favorably against the state of the art.
Delphic Costs and Benefits in Web Search: A utilitarian and historical analysis
Aug 15, 2023We present a new framework to conceptualize and operationalize the total user experience of search, by studying the entirety of a search journey from an utilitarian point of view. Web search engines are widely perceived as "free". But search requires time and effort: in reality there are many intermingled non-monetary costs (e.g. time costs, cognitive costs, interactivity costs) and the benefits may be marred by various impairments, such as misunderstanding and misinformation. This characterization of costs and benefits appears to be inherent to the human search for information within the pursuit of some larger task: most of the costs and impairments can be identified in interactions with any web search engine, interactions with public libraries, and even in interactions with ancient oracles. To emphasize this innate connection, we call these costs and benefits Delphic, in contrast to explicitly financial costs and benefits. Our main thesis is that the users' satisfaction with a search engine mostly depends on their experience of Delphic cost and benefits, in other words on their utility. The consumer utility is correlated with classic measures of search engine quality, such as ranking, precision, recall, etc., but is not completely determined by them. To argue our thesis, we catalog the Delphic costs and benefits and show how the development of search engines over the last quarter century, from classic Information Retrieval roots to the integration of Large Language Models, was driven to a great extent by the quest of decreasing Delphic costs and increasing Delphic benefits. We hope that the Delphic costs framework will engender new ideas and new research for evaluating and improving the web experience for everyone.
A Circuit Domain Generalization Framework for Efficient Logic Synthesis in Chip Design
Aug 22, 2023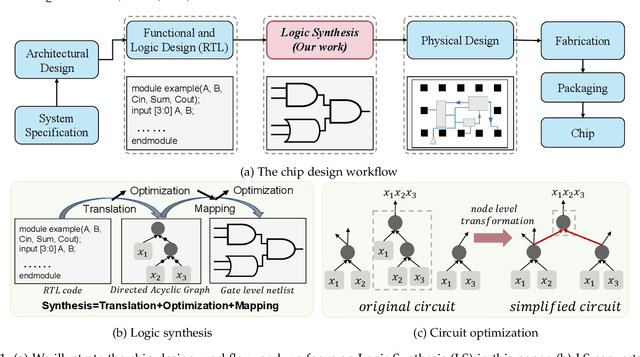
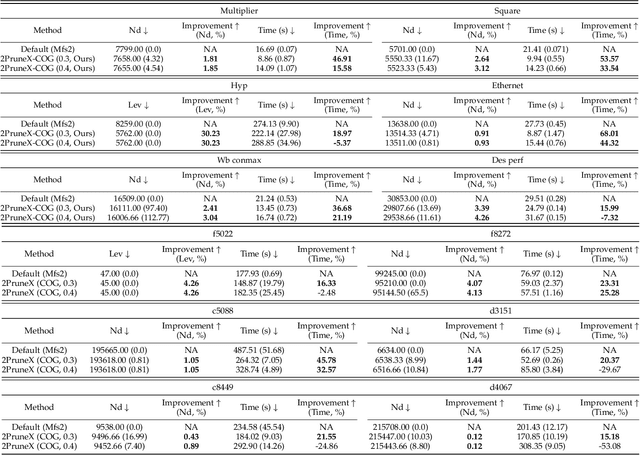
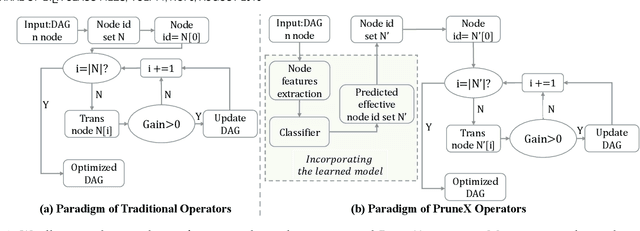
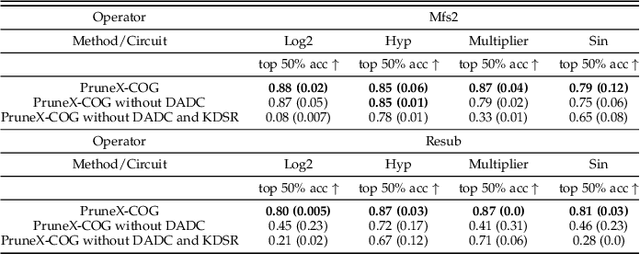
Logic Synthesis (LS) plays a vital role in chip design -- a cornerstone of the semiconductor industry. A key task in LS is to transform circuits -- modeled by directed acyclic graphs (DAGs) -- into simplified circuits with equivalent functionalities. To tackle this task, many LS operators apply transformations to subgraphs -- rooted at each node on an input DAG -- sequentially. However, we found that a large number of transformations are ineffective, which makes applying these operators highly time-consuming. In particular, we notice that the runtime of the Resub and Mfs2 operators often dominates the overall runtime of LS optimization processes. To address this challenge, we propose a novel data-driven LS operator paradigm, namely PruneX, to reduce ineffective transformations. The major challenge of developing PruneX is to learn models that well generalize to unseen circuits, i.e., the out-of-distribution (OOD) generalization problem. Thus, the major technical contribution of PruneX is the novel circuit domain generalization framework, which learns domain-invariant representations based on the transformation-invariant domain-knowledge. To the best of our knowledge, PruneX is the first approach to tackle the OOD problem in LS operators. We integrate PruneX with the aforementioned Resub and Mfs2 operators. Experiments demonstrate that PruneX significantly improves their efficiency while keeping comparable optimization performance on industrial and very large-scale circuits, achieving up to $3.1\times$ faster runtime.
Towards Validating Long-Term User Feedbacks in Interactive Recommendation Systems
Aug 22, 2023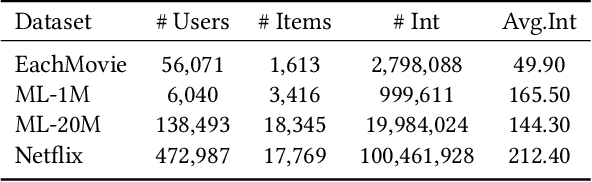
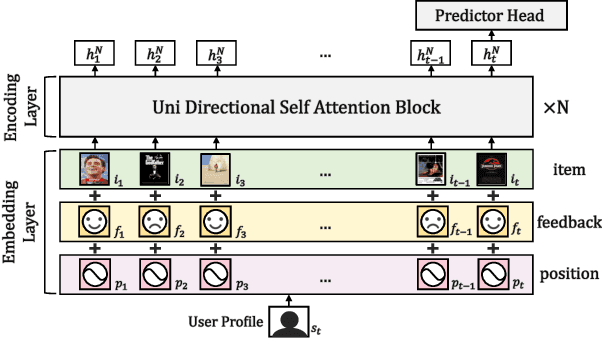
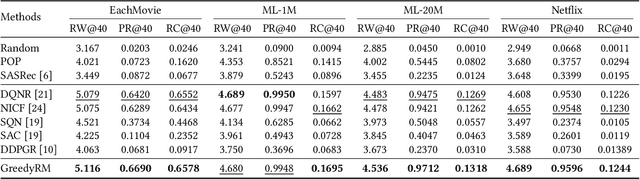
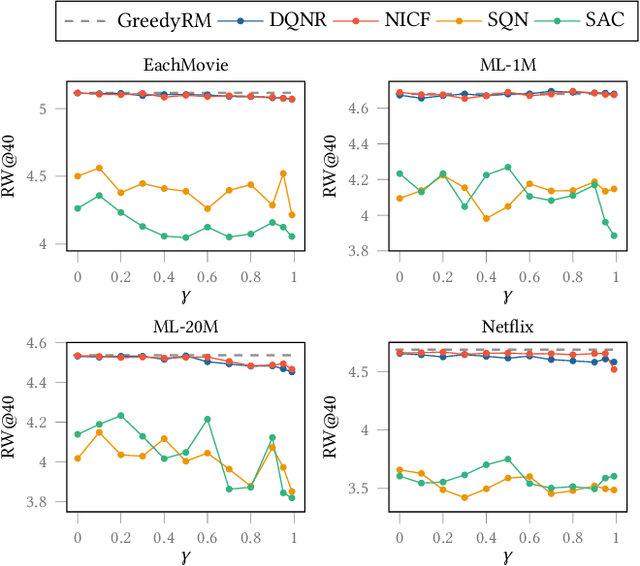
Interactive Recommender Systems (IRSs) have attracted a lot of attention, due to their ability to model interactive processes between users and recommender systems. Numerous approaches have adopted Reinforcement Learning (RL) algorithms, as these can directly maximize users' cumulative rewards. In IRS, researchers commonly utilize publicly available review datasets to compare and evaluate algorithms. However, user feedback provided in public datasets merely includes instant responses (e.g., a rating), with no inclusion of delayed responses (e.g., the dwell time and the lifetime value). Thus, the question remains whether these review datasets are an appropriate choice to evaluate the long-term effects of the IRS. In this work, we revisited experiments on IRS with review datasets and compared RL-based models with a simple reward model that greedily recommends the item with the highest one-step reward. Following extensive analysis, we can reveal three main findings: First, a simple greedy reward model consistently outperforms RL-based models in maximizing cumulative rewards. Second, applying higher weighting to long-term rewards leads to a degradation of recommendation performance. Third, user feedbacks have mere long-term effects on the benchmark datasets. Based on our findings, we conclude that a dataset has to be carefully verified and that a simple greedy baseline should be included for a proper evaluation of RL-based IRS approaches.
SwinFace: A Multi-task Transformer for Face Recognition, Expression Recognition, Age Estimation and Attribute Estimation
Aug 22, 2023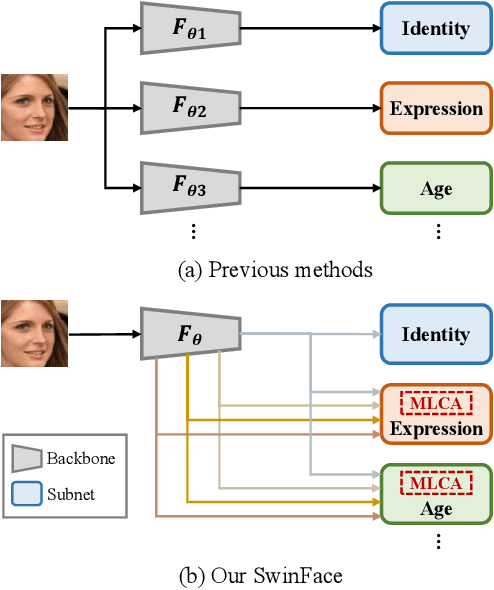
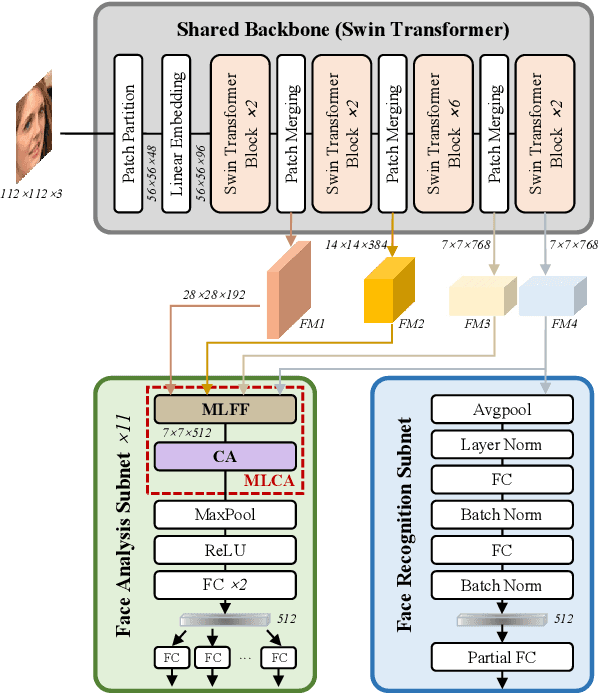
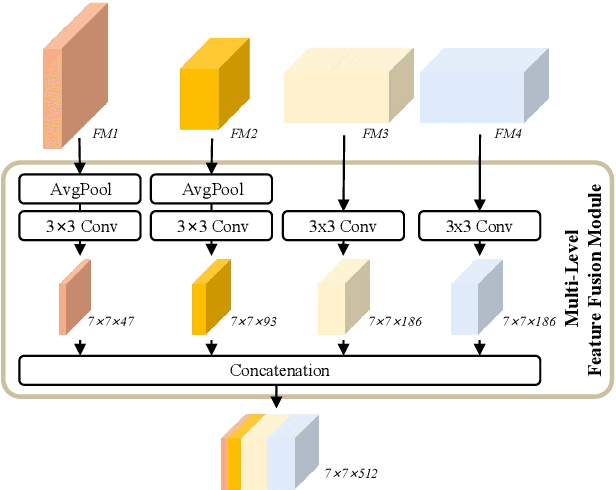
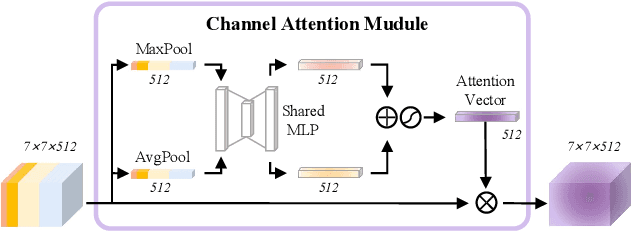
In recent years, vision transformers have been introduced into face recognition and analysis and have achieved performance breakthroughs. However, most previous methods generally train a single model or an ensemble of models to perform the desired task, which ignores the synergy among different tasks and fails to achieve improved prediction accuracy, increased data efficiency, and reduced training time. This paper presents a multi-purpose algorithm for simultaneous face recognition, facial expression recognition, age estimation, and face attribute estimation (40 attributes including gender) based on a single Swin Transformer. Our design, the SwinFace, consists of a single shared backbone together with a subnet for each set of related tasks. To address the conflicts among multiple tasks and meet the different demands of tasks, a Multi-Level Channel Attention (MLCA) module is integrated into each task-specific analysis subnet, which can adaptively select the features from optimal levels and channels to perform the desired tasks. Extensive experiments show that the proposed model has a better understanding of the face and achieves excellent performance for all tasks. Especially, it achieves 90.97% accuracy on RAF-DB and 0.22 $\epsilon$-error on CLAP2015, which are state-of-the-art results on facial expression recognition and age estimation respectively. The code and models will be made publicly available at https://github.com/lxq1000/SwinFace.
PatchBackdoor: Backdoor Attack against Deep Neural Networks without Model Modification
Aug 22, 2023Backdoor attack is a major threat to deep learning systems in safety-critical scenarios, which aims to trigger misbehavior of neural network models under attacker-controlled conditions. However, most backdoor attacks have to modify the neural network models through training with poisoned data and/or direct model editing, which leads to a common but false belief that backdoor attack can be easily avoided by properly protecting the model. In this paper, we show that backdoor attacks can be achieved without any model modification. Instead of injecting backdoor logic into the training data or the model, we propose to place a carefully-designed patch (namely backdoor patch) in front of the camera, which is fed into the model together with the input images. The patch can be trained to behave normally at most of the time, while producing wrong prediction when the input image contains an attacker-controlled trigger object. Our main techniques include an effective training method to generate the backdoor patch and a digital-physical transformation modeling method to enhance the feasibility of the patch in real deployments. Extensive experiments show that PatchBackdoor can be applied to common deep learning models (VGG, MobileNet, ResNet) with an attack success rate of 93% to 99% on classification tasks. Moreover, we implement PatchBackdoor in real-world scenarios and show that the attack is still threatening.