 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
POLCA: Power Oversubscription in LLM Cloud Providers
Aug 24, 2023
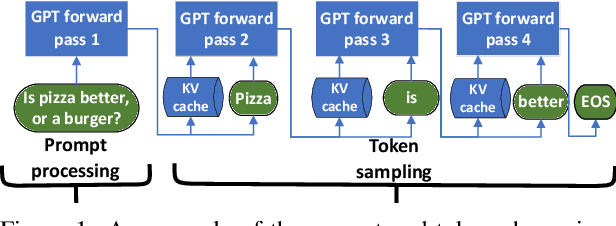

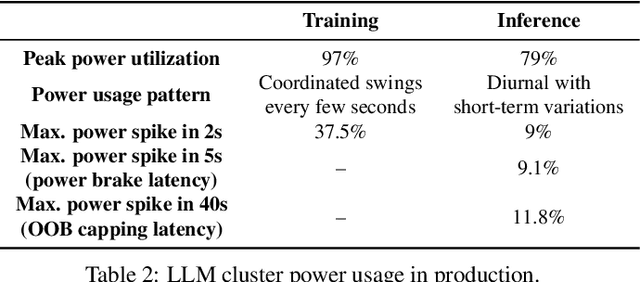
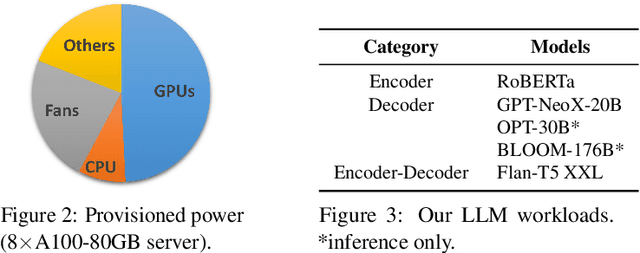
Recent innovation in large language models (LLMs), and their myriad use-cases have rapidly driven up the compute capacity demand for datacenter GPUs. Several cloud providers and other enterprises have made substantial plans of growth in their datacenters to support these new workloads. One of the key bottleneck resources in datacenters is power, and given the increasing model sizes of LLMs, they are becoming increasingly power intensive. In this paper, we show that there is a significant opportunity to oversubscribe power in LLM clusters. Power oversubscription improves the power efficiency of these datacenters, allowing more deployable servers per datacenter, and reduces the deployment time, since building new datacenters is slow. We extensively characterize the power consumption patterns of a variety of LLMs and their configurations. We identify the differences between the inference and training power consumption patterns. Based on our analysis of these LLMs, we claim that the average and peak power utilization in LLM clusters for inference should not be very high. Our deductions align with the data from production LLM clusters, revealing that inference workloads offer substantial headroom for power oversubscription. However, the stringent set of telemetry and controls that GPUs offer in a virtualized environment, makes it challenging to have a reliable and robust power oversubscription mechanism. We propose POLCA, our framework for power oversubscription that is robust, reliable, and readily deployable for GPU clusters. Using open-source models to replicate the power patterns observed in production, we simulate POLCA and demonstrate that we can deploy 30% more servers in the same GPU cluster for inference, with minimal performance loss
Adapt Your Teacher: Improving Knowledge Distillation for Exemplar-free Continual Learning
Aug 18, 2023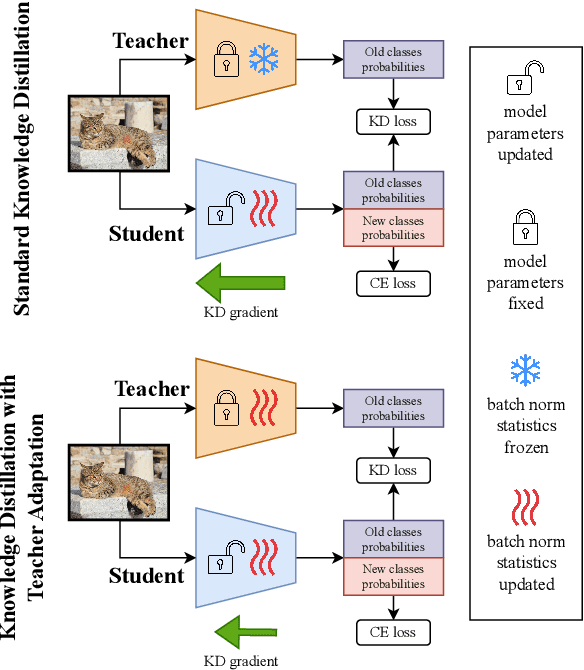
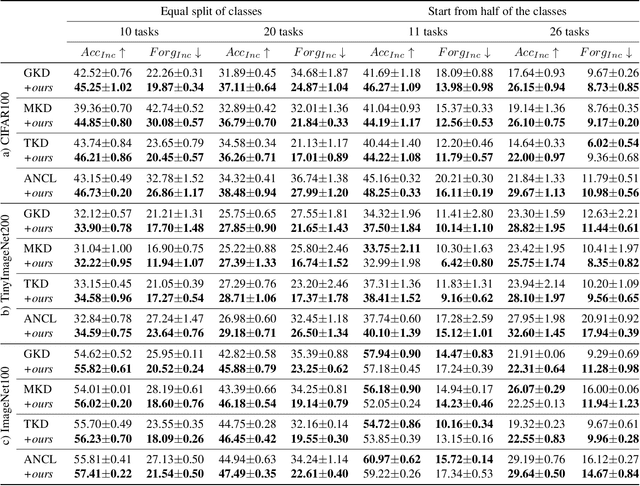
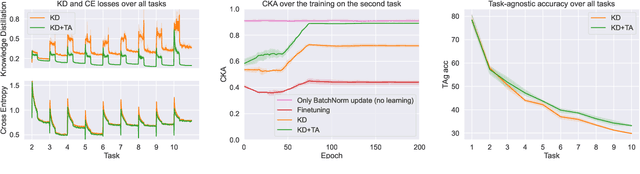
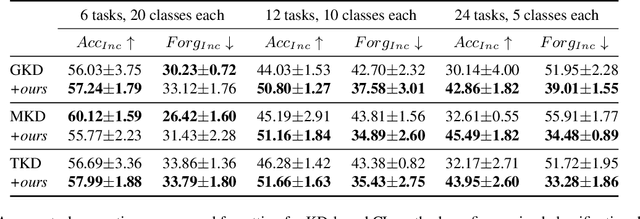
In this work, we investigate exemplar-free class incremental learning (CIL) with knowledge distillation (KD) as a regularization strategy, aiming to prevent forgetting. KD-based methods are successfully used in CIL, but they often struggle to regularize the model without access to exemplars of the training data from previous tasks. Our analysis reveals that this issue originates from substantial representation shifts in the teacher network when dealing with out-of-distribution data. This causes large errors in the KD loss component, leading to performance degradation in CIL. Inspired by recent test-time adaptation methods, we introduce Teacher Adaptation (TA), a method that concurrently updates the teacher and the main model during incremental training. Our method seamlessly integrates with KD-based CIL approaches and allows for consistent enhancement of their performance across multiple exemplar-free CIL benchmarks.
OCR Language Models with Custom Vocabularies
Aug 18, 2023Language models are useful adjuncts to optical models for producing accurate optical character recognition (OCR) results. One factor which limits the power of language models in this context is the existence of many specialized domains with language statistics very different from those implied by a general language model - think of checks, medical prescriptions, and many other specialized document classes. This paper introduces an algorithm for efficiently generating and attaching a domain specific word based language model at run time to a general language model in an OCR system. In order to best use this model the paper also introduces a modified CTC beam search decoder which effectively allows hypotheses to remain in contention based on possible future completion of vocabulary words. The result is a substantial reduction in word error rate in recognizing material from specialized domains.
Towards Probabilistic Causal Discovery, Inference & Explanations for Autonomous Drones in Mine Surveying Tasks
Aug 19, 2023Causal modelling offers great potential to provide autonomous agents the ability to understand the data-generation process that governs their interactions with the world. Such models capture formal knowledge as well as probabilistic representations of noise and uncertainty typically encountered by autonomous robots in real-world environments. Thus, causality can aid autonomous agents in making decisions and explaining outcomes, but deploying causality in such a manner introduces new challenges. Here we identify challenges relating to causality in the context of a drone system operating in a salt mine. Such environments are challenging for autonomous agents because of the presence of confounders, non-stationarity, and a difficulty in building complete causal models ahead of time. To address these issues, we propose a probabilistic causal framework consisting of: causally-informed POMDP planning, online SCM adaptation, and post-hoc counterfactual explanations. Further, we outline planned experimentation to evaluate the framework integrated with a drone system in simulated mine environments and on a real-world mine dataset.
MeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance
Aug 19, 2023
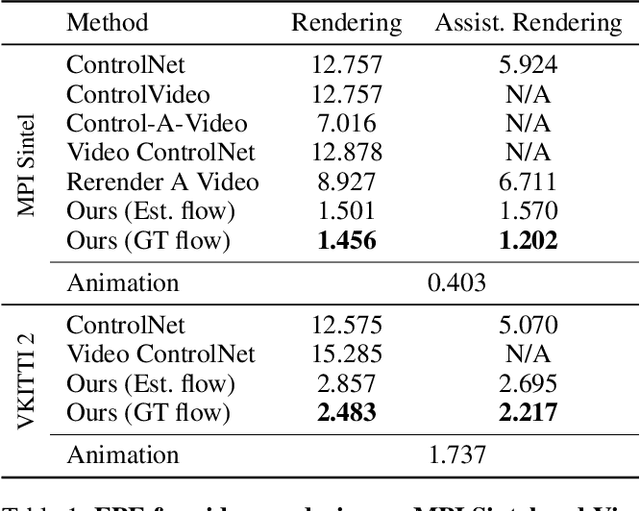
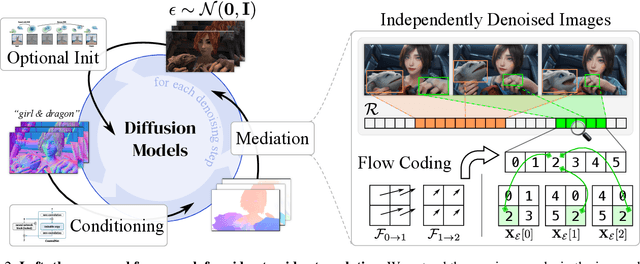
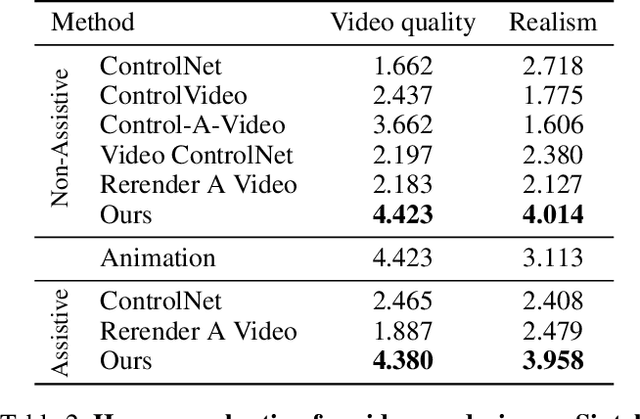
This study introduces an efficient and effective method, MeDM, that utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models. Through extensive qualitative, quantitative, and subjective experiments on various benchmarks, the study demonstrates the effectiveness and superiority of the proposed approach.
An Evaluation of Three Distance Measurement Technologies for Flying Light Specks
Aug 19, 2023
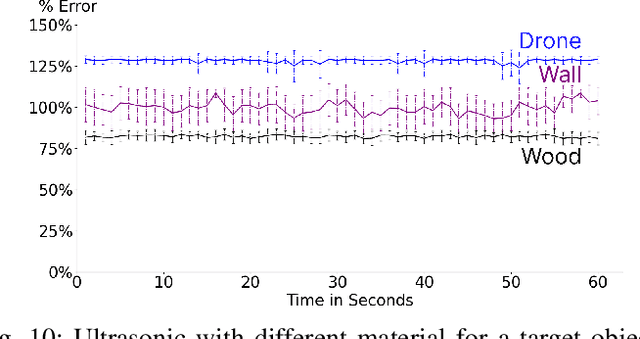

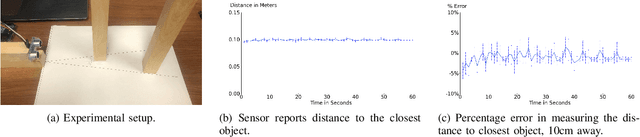
This study evaluates the accuracy of three different types of time-of-flight sensors to measure distance. We envision the possible use of these sensors to localize swarms of flying light specks (FLSs) to illuminate objects and avatars of a metaverse. An FLS is a miniature-sized drone configured with RGB light sources. It is unable to illuminate a point cloud by itself. However, the inter-FLS relationship effect of an organizational framework will compensate for the simplicity of each individual FLS, enabling a swarm of cooperating FLSs to illuminate complex shapes and render haptic interactions. Distance between FLSs is an important criterion of the inter-FLS relationship. We consider sensors that use radio frequency (UWB), infrared light (IR), and sound (ultrasonic) to quantify this metric. Obtained results show only one sensor is able to measure distances as small as 1 cm with a high accuracy. A sensor may require a calibration process that impacts its accuracy in measuring distance.
Robust Asymmetric Loss for Multi-Label Long-Tailed Learning
Aug 10, 2023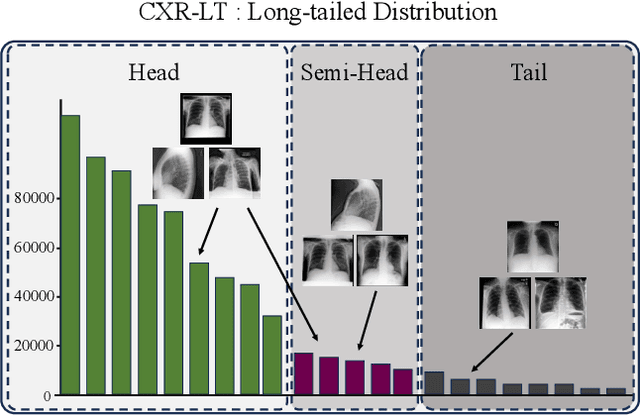
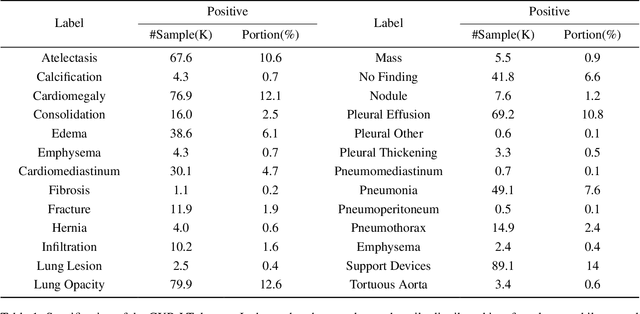
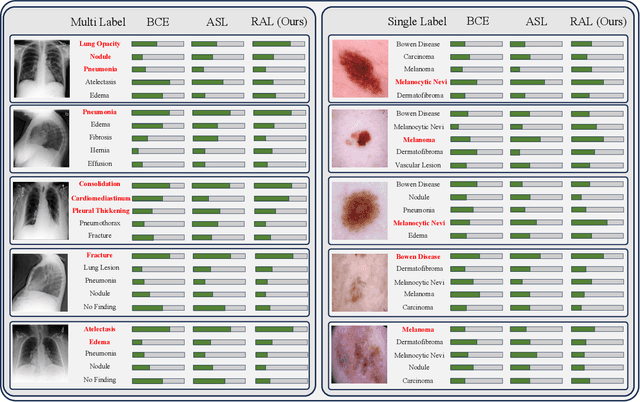
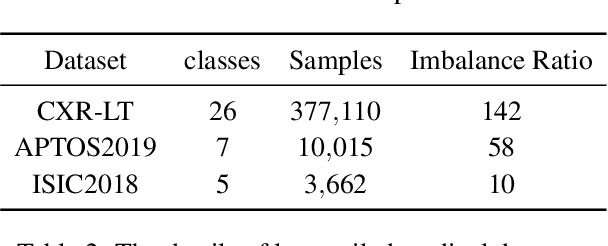
In real medical data, training samples typically show long-tailed distributions with multiple labels. Class distribution of the medical data has a long-tailed shape, in which the incidence of different diseases is quite varied, and at the same time, it is not unusual for images taken from symptomatic patients to be multi-label diseases. Therefore, in this paper, we concurrently address these two issues by putting forth a robust asymmetric loss on the polynomial function. Since our loss tackles both long-tailed and multi-label classification problems simultaneously, it leads to a complex design of the loss function with a large number of hyper-parameters. Although a model can be highly fine-tuned due to a large number of hyper-parameters, it is difficult to optimize all hyper-parameters at the same time, and there might be a risk of overfitting a model. Therefore, we regularize the loss function using the Hill loss approach, which is beneficial to be less sensitive against the numerous hyper-parameters so that it reduces the risk of overfitting the model. For this reason, the proposed loss is a generic method that can be applied to most medical image classification tasks and does not make the training process more time-consuming. We demonstrate that the proposed robust asymmetric loss performs favorably against the long-tailed with multi-label medical image classification in addition to the various long-tailed single-label datasets. Notably, our method achieves Top-5 results on the CXR-LT dataset of the ICCV CVAMD 2023 competition. We opensource our implementation of the robust asymmetric loss in the public repository: https://github.com/kalelpark/RAL.
Phase Retrieval with Background Information: Decreased References and Efficient Methods
Aug 16, 2023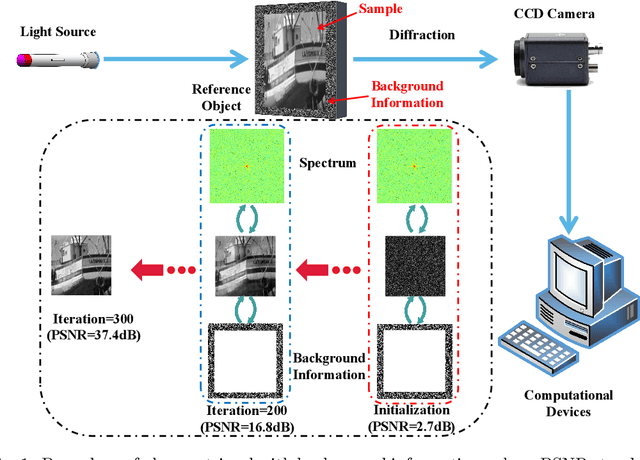
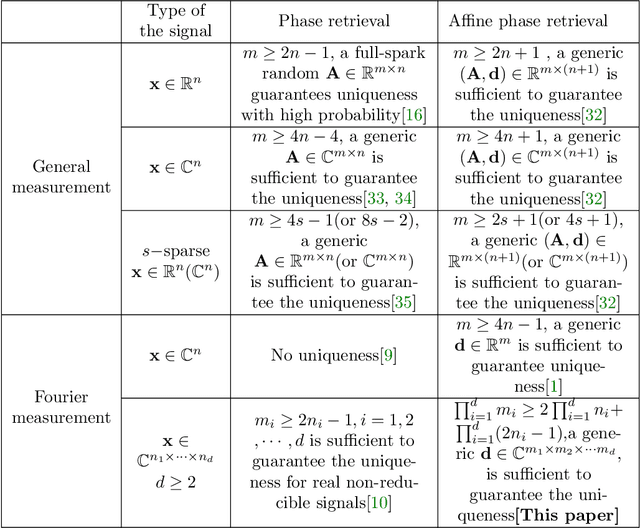
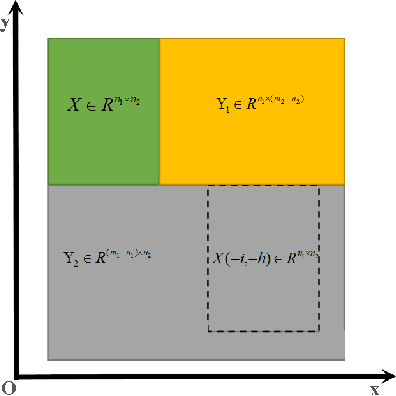
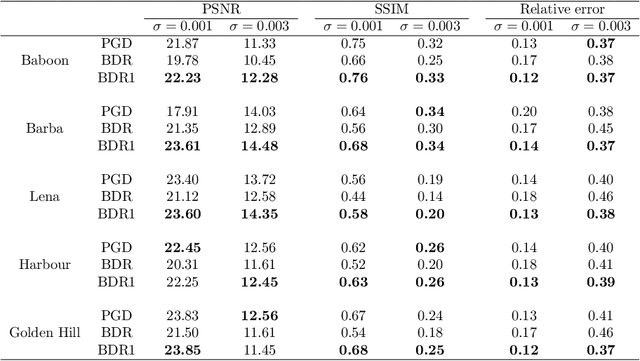
Fourier phase retrieval(PR) is a severely ill-posed inverse problem that arises in various applications. To guarantee a unique solution and relieve the dependence on the initialization, background information can be exploited as a structural priors. However, the requirement for the background information may be challenging when moving to the high-resolution imaging. At the same time, the previously proposed projected gradient descent(PGD) method also demands much background information. In this paper, we present an improved theoretical result about the demand for the background information, along with two Douglas Rachford(DR) based methods. Analytically, we demonstrate that the background required to ensure a unique solution can be decreased by nearly $1/2$ for the 2-D signals compared to the 1-D signals. By generalizing the results into $d$-dimension, we show that the length of the background information more than $(2^{\frac{d+1}{d}}-1)$ folds of the signal is sufficient to ensure the uniqueness. At the same time, we also analyze the stability and robustness of the model when measurements and background information are corrupted by the noise. Furthermore, two methods called Background Douglas-Rachford (BDR) and Convex Background Douglas-Rachford (CBDR) are proposed. BDR which is a kind of non-convex method is proven to have the local R-linear convergence rate under mild assumptions. Instead, CBDR method uses the techniques of convexification and can be proven to own a global convergence guarantee as long as the background information is sufficient. To support this, a new property called F-RIP is established. We test the performance of the proposed methods through simulations as well as real experimental measurements, and demonstrate that they achieve a higher recovery rate with less background information compared to the PGD method.
Differentiable Robust Model Predictive Control
Aug 16, 2023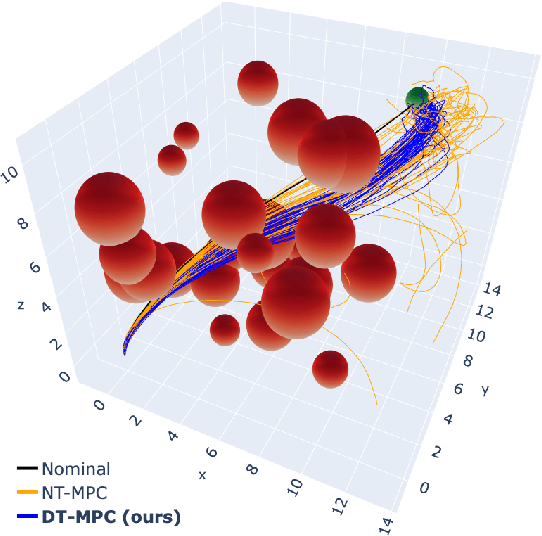


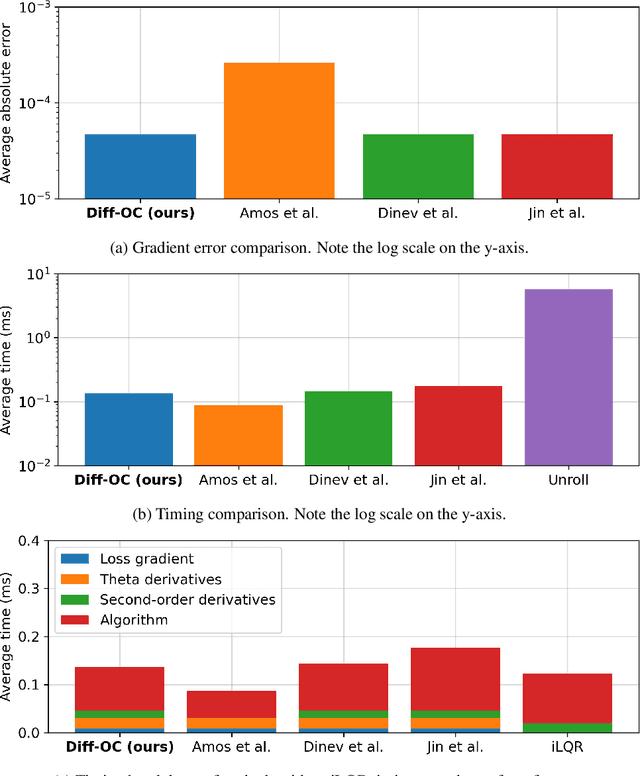
Deterministic model predictive control (MPC), while powerful, is often insufficient for effectively controlling autonomous systems in the real-world. Factors such as environmental noise and model error can cause deviations from the expected nominal performance. Robust MPC algorithms aim to bridge this gap between deterministic and uncertain control. However, these methods are often excessively difficult to tune for robustness due to the nonlinear and non-intuitive effects that controller parameters have on performance. To address this challenge, a unifying perspective on differentiable optimization for control is presented, which enables derivation of a general, differentiable tube-based MPC algorithm. The proposed approach facilitates the automatic and real-time tuning of robust controllers in the presence of large uncertainties and disturbances.
Unified Matrix Factorization with Dynamic Multi-view Clustering
Aug 13, 2023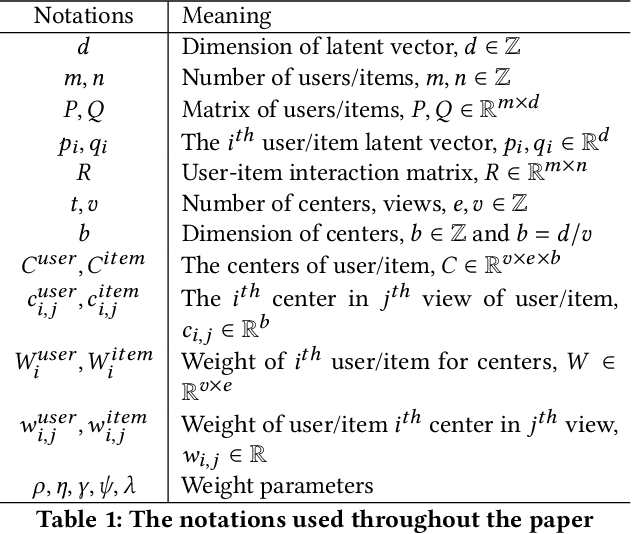
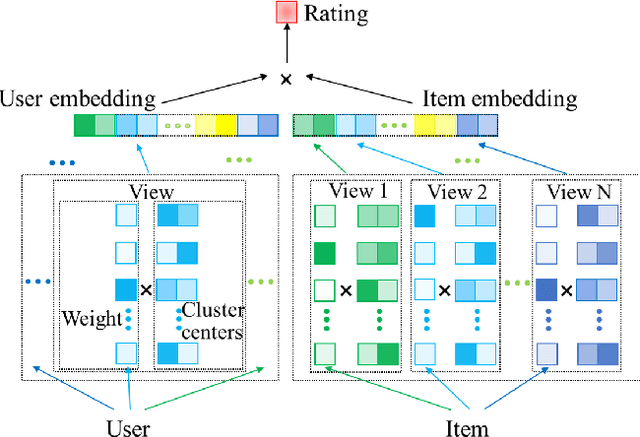

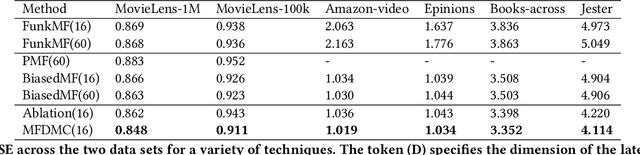
Matrix factorization (MF) is a classical collaborative filtering algorithm for recommender systems. It decomposes the user-item interaction matrix into a product of low-dimensional user representation matrix and item representation matrix. In typical recommendation scenarios, the user-item interaction paradigm is usually a two-stage process and requires static clustering analysis of the obtained user and item representations. The above process, however, is time and computationally intensive, making it difficult to apply in real-time to e-commerce or Internet of Things environments with billions of users and trillions of items. To address this, we propose a unified matrix factorization method based on dynamic multi-view clustering (MFDMC) that employs an end-to-end training paradigm. Specifically, in each view, a user/item representation is regarded as a weighted projection of all clusters. The representation of each cluster is learnable, enabling the dynamic discarding of bad clusters. Furthermore, we employ multi-view clustering to represent multiple roles of users/items, effectively utilizing the representation space and improving the interpretability of the user/item representations for downstream tasks. Extensive experiments show that our proposed MFDMC achieves state-of-the-art performance on real-world recommendation datasets. Additionally, comprehensive visualization and ablation studies interpretably confirm that our method provides meaningful representations for downstream tasks of users/items.