 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ConservationBots: Autonomous Aerial Robot for Fast Robust Wildlife Tracking in Complex Terrains
Aug 17, 2023

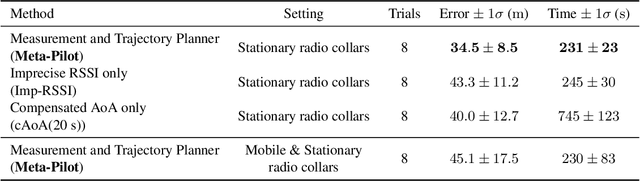
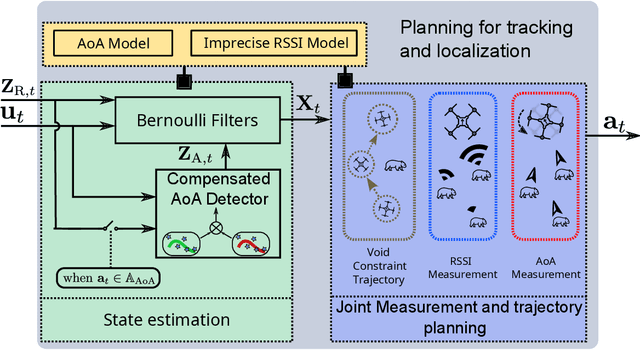
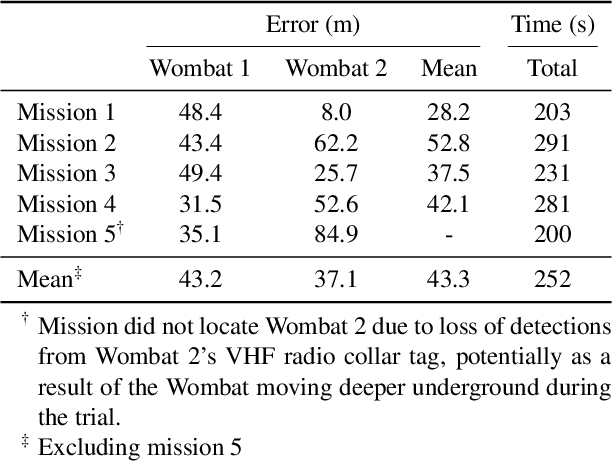
Today, the most widespread, widely applicable technology for gathering data relies on experienced scientists armed with handheld radio telemetry equipment to locate low-power radio transmitters attached to wildlife from the ground. Although aerial robots can transform labor-intensive conservation tasks, the realization of autonomous systems for tackling task complexities under real-world conditions remains a challenge. We developed ConservationBots-small aerial robots for tracking multiple, dynamic, radio-tagged wildlife. The aerial robot achieves robust localization performance and fast task completion times -- significant for energy-limited aerial systems while avoiding close encounters with potential, counter-productive disturbances to wildlife. Our approach overcomes the technical and practical problems posed by combining a lightweight sensor with new concepts: i) planning to determine both trajectory and measurement actions guided by an information-theoretic objective, which allows the robot to strategically select near-instantaneous range-only measurements to achieve faster localization, and time-consuming sensor rotation actions to acquire bearing measurements and achieve robust tracking performance; ii) a bearing detector more robust to noise and iii) a tracking algorithm formulation robust to missed and false detections experienced in real-world conditions. We conducted extensive studies: simulations built upon complex signal propagation over high-resolution elevation data on diverse geographical terrains; field testing; studies with wombats (Lasiorhinus latifrons; nocturnal, vulnerable species dwelling in underground warrens) and tracking comparisons with a highly experienced biologist to validate the effectiveness of our aerial robot and demonstrate the significant advantages over the manual method.
Improving Zero-Shot Text Matching for Financial Auditing with Large Language Models
Aug 11, 2023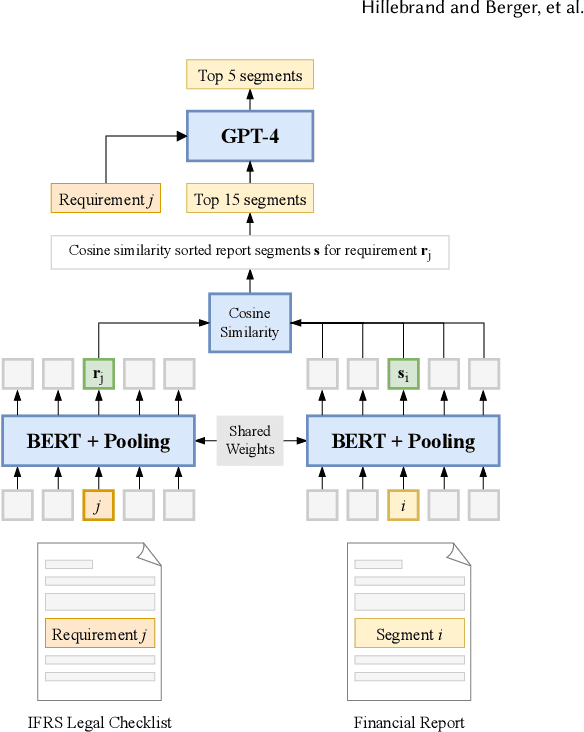

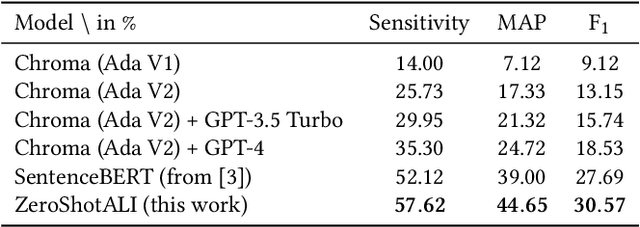
Auditing financial documents is a very tedious and time-consuming process. As of today, it can already be simplified by employing AI-based solutions to recommend relevant text passages from a report for each legal requirement of rigorous accounting standards. However, these methods need to be fine-tuned regularly, and they require abundant annotated data, which is often lacking in industrial environments. Hence, we present ZeroShotALI, a novel recommender system that leverages a state-of-the-art large language model (LLM) in conjunction with a domain-specifically optimized transformer-based text-matching solution. We find that a two-step approach of first retrieving a number of best matching document sections per legal requirement with a custom BERT-based model and second filtering these selections using an LLM yields significant performance improvements over existing approaches.
Latent Masking for Multimodal Self-supervised Learning in Health Timeseries
Jul 31, 2023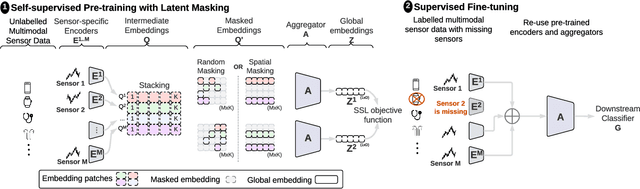
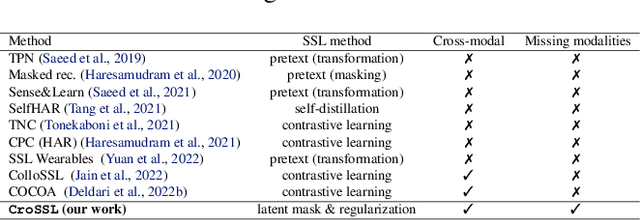
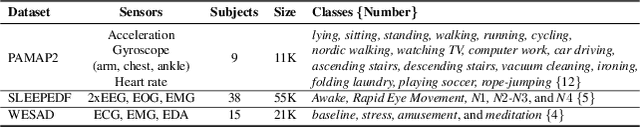
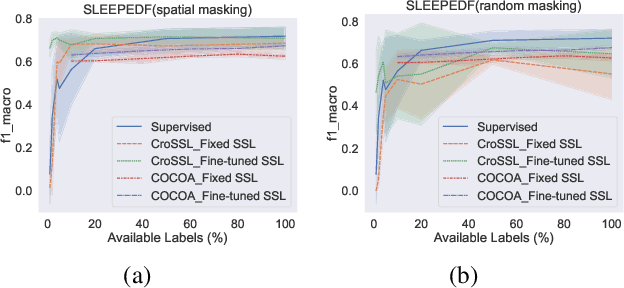
Limited availability of labeled data for machine learning on biomedical time-series hampers progress in the field. Self-supervised learning (SSL) is a promising approach to learning data representations without labels. However, current SSL methods require expensive computations for negative pairs and are designed for single modalities, limiting their versatility. To overcome these limitations, we introduce CroSSL (Cross-modal SSL). CroSSL introduces two novel concepts: masking intermediate embeddings from modality-specific encoders and aggregating them into a global embedding using a cross-modal aggregator. This enables the handling of missing modalities and end-to-end learning of cross-modal patterns without prior data preprocessing or time-consuming negative-pair sampling. We evaluate CroSSL on various multimodal time-series benchmarks, including both medical-grade and consumer biosignals. Our results demonstrate superior performance compared to previous SSL techniques and supervised benchmarks with minimal labeled data. We additionally analyze the impact of different masking ratios and strategies and assess the robustness of the learned representations to missing modalities. Overall, our work achieves state-of-the-art performance while highlighting the benefits of masking latent embeddings for cross-modal learning in temporal health data.
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
Jun 07, 2023
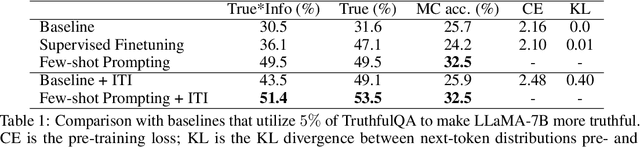
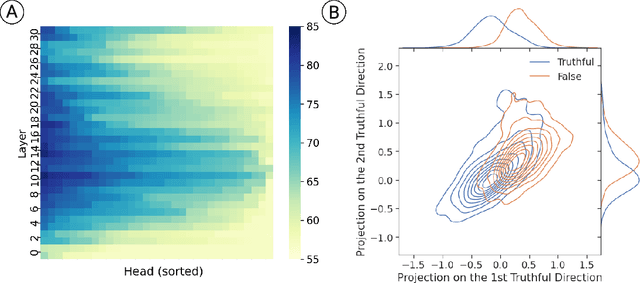
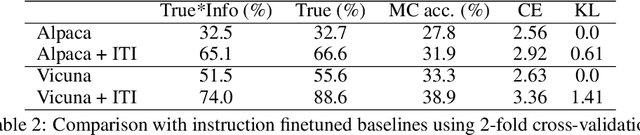
We introduce Inference-Time Intervention (ITI), a technique designed to enhance the truthfulness of large language models (LLMs). ITI operates by shifting model activations during inference, following a set of directions across a limited number of attention heads. This intervention significantly improves the performance of LLaMA models on the TruthfulQA benchmark. On an instruction-finetuned LLaMA called Alpaca, ITI improves its truthfulness from 32.5% to 65.1%. We identify a tradeoff between truthfulness and helpfulness and demonstrate how to balance it by tuning the intervention strength. ITI is minimally invasive and computationally inexpensive. Moreover, the technique is data efficient: while approaches like RLHF require extensive annotations, ITI locates truthful directions using only few hundred examples. Our findings suggest that LLMs may have an internal representation of the likelihood of something being true, even as they produce falsehoods on the surface.
Denoising Diffusion Probabilistic Model for Retinal Image Generation and Segmentation
Aug 16, 2023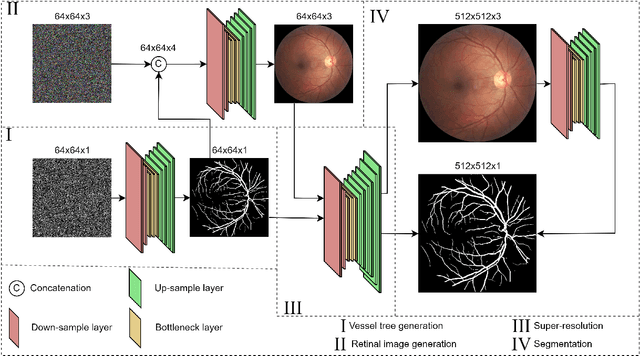
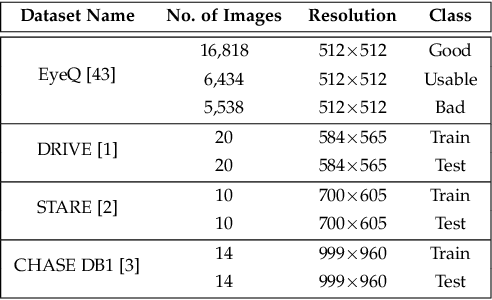
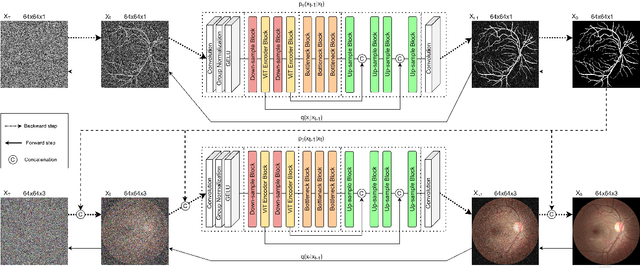

Experts use retinal images and vessel trees to detect and diagnose various eye, blood circulation, and brain-related diseases. However, manual segmentation of retinal images is a time-consuming process that requires high expertise and is difficult due to privacy issues. Many methods have been proposed to segment images, but the need for large retinal image datasets limits the performance of these methods. Several methods synthesize deep learning models based on Generative Adversarial Networks (GAN) to generate limited sample varieties. This paper proposes a novel Denoising Diffusion Probabilistic Model (DDPM) that outperformed GANs in image synthesis. We developed a Retinal Trees (ReTree) dataset consisting of retinal images, corresponding vessel trees, and a segmentation network based on DDPM trained with images from the ReTree dataset. In the first stage, we develop a two-stage DDPM that generates vessel trees from random numbers belonging to a standard normal distribution. Later, the model is guided to generate fundus images from given vessel trees and random distribution. The proposed dataset has been evaluated quantitatively and qualitatively. Quantitative evaluation metrics include Frechet Inception Distance (FID) score, Jaccard similarity coefficient, Cohen's kappa, Matthew's Correlation Coefficient (MCC), precision, recall, F1-score, and accuracy. We trained the vessel segmentation model with synthetic data to validate our dataset's efficiency and tested it on authentic data. Our developed dataset and source code is available at https://github.com/AAleka/retree.
Challenges and Opportunities of Using Transformer-Based Multi-Task Learning in NLP Through ML Lifecycle: A Survey
Aug 16, 2023The increasing adoption of natural language processing (NLP) models across industries has led to practitioners' need for machine learning systems to handle these models efficiently, from training to serving them in production. However, training, deploying, and updating multiple models can be complex, costly, and time-consuming, mainly when using transformer-based pre-trained language models. Multi-Task Learning (MTL) has emerged as a promising approach to improve efficiency and performance through joint training, rather than training separate models. Motivated by this, we first provide an overview of transformer-based MTL approaches in NLP. Then, we discuss the challenges and opportunities of using MTL approaches throughout typical ML lifecycle phases, specifically focusing on the challenges related to data engineering, model development, deployment, and monitoring phases. This survey focuses on transformer-based MTL architectures and, to the best of our knowledge, is novel in that it systematically analyses how transformer-based MTL in NLP fits into ML lifecycle phases. Furthermore, we motivate research on the connection between MTL and continual learning (CL), as this area remains unexplored. We believe it would be practical to have a model that can handle both MTL and CL, as this would make it easier to periodically re-train the model, update it due to distribution shifts, and add new capabilities to meet real-world requirements.
Graph Relation Aware Continual Learning
Aug 16, 2023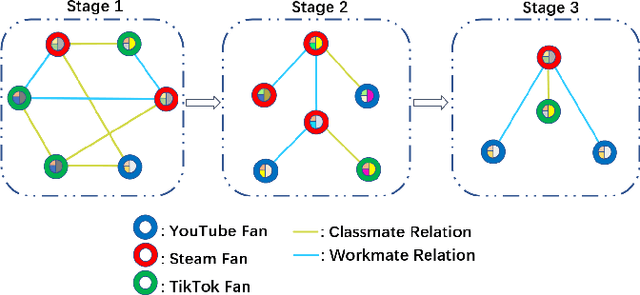
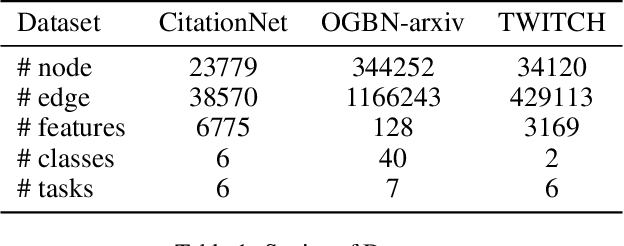
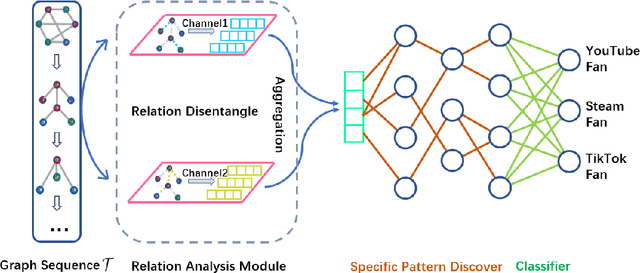
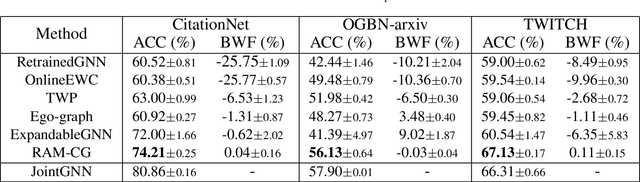
Continual graph learning (CGL) studies the problem of learning from an infinite stream of graph data, consolidating historical knowledge, and generalizing it to the future task. At once, only current graph data are available. Although some recent attempts have been made to handle this task, we still face two potential challenges: 1) most of existing works only manipulate on the intermediate graph embedding and ignore intrinsic properties of graphs. It is non-trivial to differentiate the transferred information across graphs. 2) recent attempts take a parameter-sharing policy to transfer knowledge across time steps or progressively expand new architecture given shifted graph distribution. Learning a single model could loss discriminative information for each graph task while the model expansion scheme suffers from high model complexity. In this paper, we point out that latent relations behind graph edges can be attributed as an invariant factor for the evolving graphs and the statistical information of latent relations evolves. Motivated by this, we design a relation-aware adaptive model, dubbed as RAM-CG, that consists of a relation-discovery modular to explore latent relations behind edges and a task-awareness masking classifier to accounts for the shifted. Extensive experiments show that RAM-CG provides significant 2.2%, 6.9% and 6.6% accuracy improvements over the state-of-the-art results on CitationNet, OGBN-arxiv and TWITCH dataset, respective.
Physics Informed Recurrent Neural Networks for Seismic Response Evaluation of Nonlinear Systems
Aug 16, 2023Dynamic response evaluation in structural engineering is the process of determining the response of a structure, such as member forces, node displacements, etc when subjected to dynamic loads such as earthquakes, wind, or impact. This is an important aspect of structural analysis, as it enables engineers to assess structural performance under extreme loading conditions and make informed decisions about the design and safety of the structure. Conventional methods for dynamic response evaluation involve numerical simulations using finite element analysis (FEA), where the structure is modeled using finite elements, and the equations of motion are solved numerically. Although effective, this approach can be computationally intensive and may not be suitable for real-time applications. To address these limitations, recent advancements in machine learning, specifically artificial neural networks, have been applied to dynamic response evaluation in structural engineering. These techniques leverage large data sets and sophisticated algorithms to learn the complex relationship between inputs and outputs, making them ideal for such problems. In this paper, a novel approach is proposed for evaluating the dynamic response of multi-degree-of-freedom (MDOF) systems using physics-informed recurrent neural networks. The focus of this paper is to evaluate the seismic (earthquake) response of nonlinear structures. The predicted response will be compared to state-of-the-art methods such as FEA to assess the efficacy of the physics-informed RNN model.
Real-time Object Detection: YOLOv1 Re-Implementation in PyTorch
May 28, 2023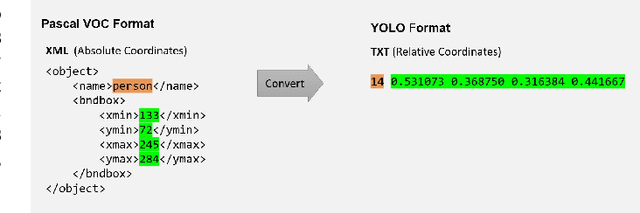

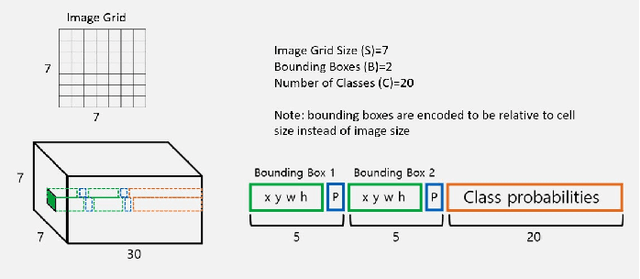
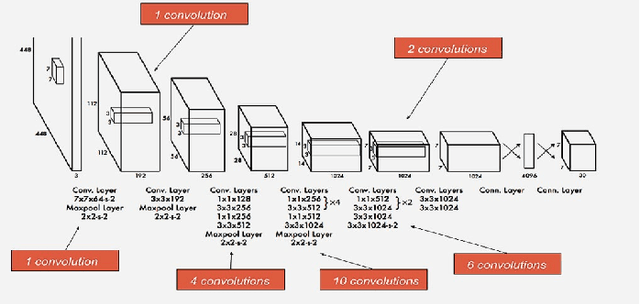
Real-time object detection is a crucial problem to solve when in comes to computer vision systems that needs to make appropriate decision based on detection in a timely manner. I have chosen the YOLO v1 architecture to implement it using PyTorch framework, with goal to familiarize with entire object detection pipeline I attempted different techniques to modify the original architecture to improve the results. Finally, I compare the metrics of my implementation to the original.
Diffusion Variational Autoencoder for Tackling Stochasticity in Multi-Step Regression Stock Price Prediction
Aug 18, 2023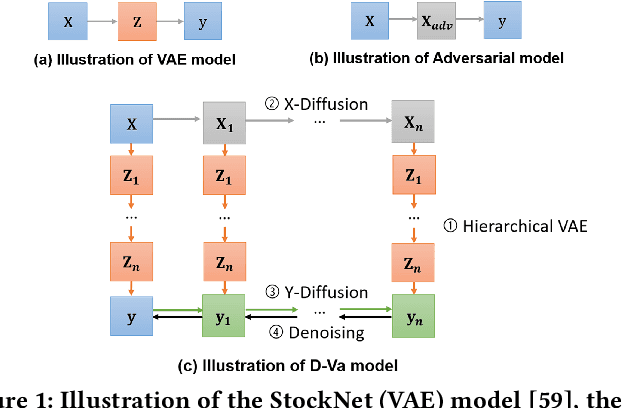
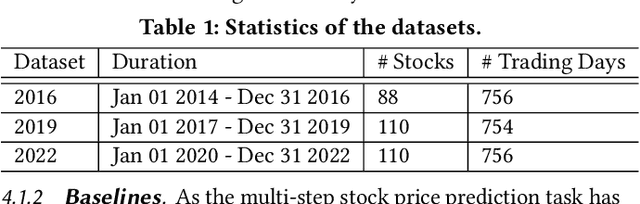
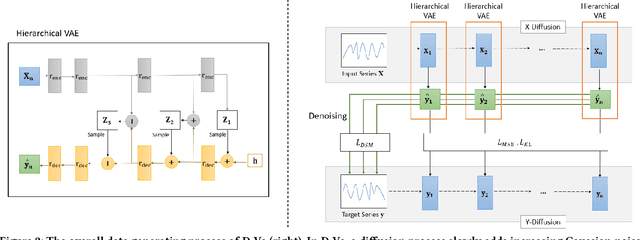

Multi-step stock price prediction over a long-term horizon is crucial for forecasting its volatility, allowing financial institutions to price and hedge derivatives, and banks to quantify the risk in their trading books. Additionally, most financial regulators also require a liquidity horizon of several days for institutional investors to exit their risky assets, in order to not materially affect market prices. However, the task of multi-step stock price prediction is challenging, given the highly stochastic nature of stock data. Current solutions to tackle this problem are mostly designed for single-step, classification-based predictions, and are limited to low representation expressiveness. The problem also gets progressively harder with the introduction of the target price sequence, which also contains stochastic noise and reduces generalizability at test-time. To tackle these issues, we combine a deep hierarchical variational-autoencoder (VAE) and diffusion probabilistic techniques to do seq2seq stock prediction through a stochastic generative process. The hierarchical VAE allows us to learn the complex and low-level latent variables for stock prediction, while the diffusion probabilistic model trains the predictor to handle stock price stochasticity by progressively adding random noise to the stock data. Our Diffusion-VAE (D-Va) model is shown to outperform state-of-the-art solutions in terms of its prediction accuracy and variance. More importantly, the multi-step outputs can also allow us to form a stock portfolio over the prediction length. We demonstrate the effectiveness of our model outputs in the portfolio investment task through the Sharpe ratio metric and highlight the importance of dealing with different types of prediction uncertainties.