 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
IBCB: Efficient Inverse Batched Contextual Bandit for Behavioral Evolution History
Mar 24, 2024
Traditional imitation learning focuses on modeling the behavioral mechanisms of experts, which requires a large amount of interaction history generated by some fixed expert. However, in many streaming applications, such as streaming recommender systems, online decision-makers typically engage in online learning during the decision-making process, meaning that the interaction history generated by online decision-makers includes their behavioral evolution from novice expert to experienced expert. This poses a new challenge for existing imitation learning approaches that can only utilize data from experienced experts. To address this issue, this paper proposes an inverse batched contextual bandit (IBCB) framework that can efficiently perform estimations of environment reward parameters and learned policy based on the expert's behavioral evolution history. Specifically, IBCB formulates the inverse problem into a simple quadratic programming problem by utilizing the behavioral evolution history of the batched contextual bandit with inaccessible rewards. We demonstrate that IBCB is a unified framework for both deterministic and randomized bandit policies. The experimental results indicate that IBCB outperforms several existing imitation learning algorithms on synthetic and real-world data and significantly reduces running time. Additionally, empirical analyses reveal that IBCB exhibits better out-of-distribution generalization and is highly effective in learning the bandit policy from the interaction history of novice experts.
Improving Sequence-to-Sequence Models for Abstractive Text Summarization Using Meta Heuristic Approaches
Mar 24, 2024As human society transitions into the information age, reduction in our attention span is a contingency, and people who spend time reading lengthy news articles are decreasing rapidly and the need for succinct information is higher than ever before. Therefore, it is essential to provide a quick overview of important news by concisely summarizing the top news article and the most intuitive headline. When humans try to make summaries, they extract the essential information from the source and add useful phrases and grammatical annotations from the original extract. Humans have a unique ability to create abstractions. However, automatic summarization is a complicated problem to solve. The use of sequence-to-sequence (seq2seq) models for neural abstractive text summarization has been ascending as far as prevalence. Numerous innovative strategies have been proposed to develop the current seq2seq models further, permitting them to handle different issues like saliency, familiarity, and human lucidness and create excellent synopses. In this article, we aimed toward enhancing the present architectures and models for abstractive text summarization. The modifications have been aimed at fine-tuning hyper-parameters, attempting specific encoder-decoder combinations. We examined many experiments on an extensively used CNN/DailyMail dataset to check the effectiveness of various models.
From Discrete to Continuous: Deep Fair Clustering With Transferable Representations
Mar 24, 2024We consider the problem of deep fair clustering, which partitions data into clusters via the representations extracted by deep neural networks while hiding sensitive data attributes. To achieve fairness, existing methods present a variety of fairness-related objective functions based on the group fairness criterion. However, these works typically assume that the sensitive attributes are discrete and do not work for continuous sensitive variables, such as the proportion of the female population in an area. Besides, the potential of the representations learned from clustering tasks to improve performance on other tasks is ignored by existing works. In light of these limitations, we propose a flexible deep fair clustering method that can handle discrete and continuous sensitive attributes simultaneously. Specifically, we design an information bottleneck style objective function to learn fair and clustering-friendly representations. Furthermore, we explore for the first time the transferability of the extracted representations to other downstream tasks. Unlike existing works, we impose fairness at the representation level, which could guarantee fairness for the transferred task regardless of clustering results. To verify the effectiveness of the proposed method, we perform extensive experiments on datasets with discrete and continuous sensitive attributes, demonstrating the advantage of our method in comparison with state-of-the-art methods.
Improve accessibility for Low Vision and Blind people using Machine Learning and Computer Vision
Mar 24, 2024With the ever-growing expansion of mobile technology worldwide, there is an increasing need for accommodation for those who are disabled. This project explores how machine learning and computer vision could be utilized to improve accessibility for people with visual impairments. There have been many attempts to develop various software that would improve accessibility in the day-to-day lives of blind people. However, applications on the market have low accuracy and only provide audio feedback. This project will concentrate on building a mobile application that helps blind people to orient in space by receiving audio and haptic feedback, e.g. vibrations, about their surroundings in real-time. The mobile application will have 3 main features. The initial feature is scanning text from the camera and reading it to a user. This feature can be used on paper with text, in the environment, and on road signs. The second feature is detecting objects around the user, and providing audio feedback about those objects. It also includes providing the description of the objects and their location, and giving haptic feedback if the user is too close to an object. The last feature is currency detection which provides a total amount of currency value to the user via the camera.
Entropy is not Enough for Test-Time Adaptation: From the Perspective of Disentangled Factors
Mar 12, 2024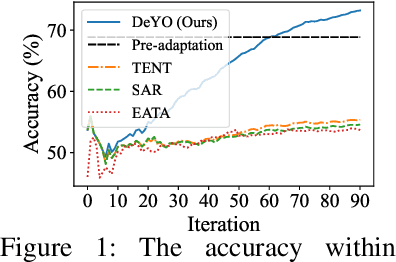
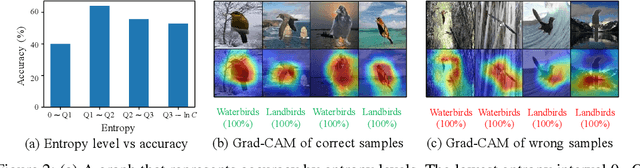
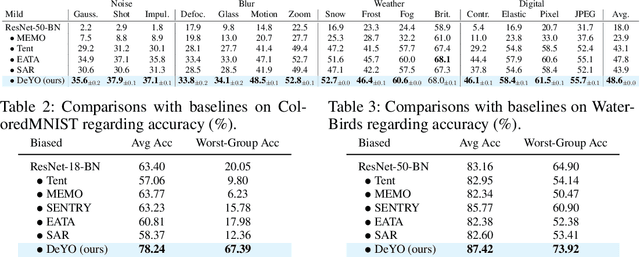

Test-time adaptation (TTA) fine-tunes pre-trained deep neural networks for unseen test data. The primary challenge of TTA is limited access to the entire test dataset during online updates, causing error accumulation. To mitigate it, TTA methods have utilized the model output's entropy as a confidence metric that aims to determine which samples have a lower likelihood of causing error. Through experimental studies, however, we observed the unreliability of entropy as a confidence metric for TTA under biased scenarios and theoretically revealed that it stems from the neglect of the influence of latent disentangled factors of data on predictions. Building upon these findings, we introduce a novel TTA method named Destroy Your Object (DeYO), which leverages a newly proposed confidence metric named Pseudo-Label Probability Difference (PLPD). PLPD quantifies the influence of the shape of an object on prediction by measuring the difference between predictions before and after applying an object-destructive transformation. DeYO consists of sample selection and sample weighting, which employ entropy and PLPD concurrently. For robust adaptation, DeYO prioritizes samples that dominantly incorporate shape information when making predictions. Our extensive experiments demonstrate the consistent superiority of DeYO over baseline methods across various scenarios, including biased and wild. Project page is publicly available at https://whitesnowdrop.github.io/DeYO/.
Simple Hack for Transformers against Heavy Long-Text Classification on a Time- and Memory-Limited GPU Service
Mar 19, 2024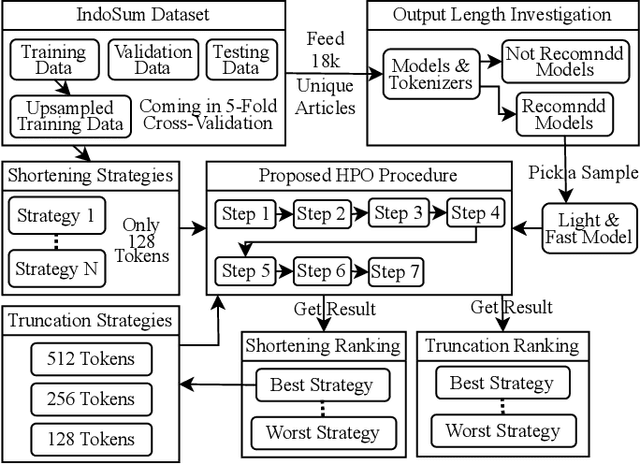

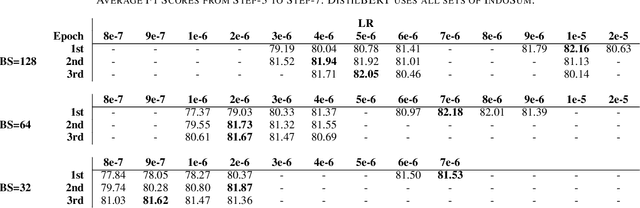
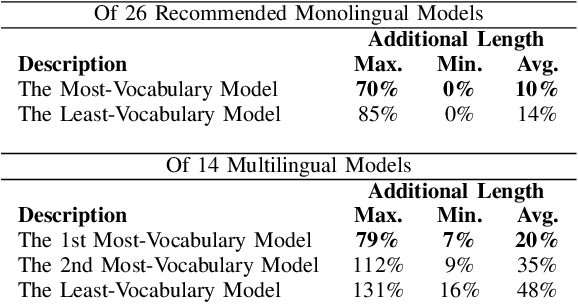
Many NLP researchers rely on free computational services, such as Google Colab, to fine-tune their Transformer models, causing a limitation for hyperparameter optimization (HPO) in long-text classification due to the method having quadratic complexity and needing a bigger resource. In Indonesian, only a few works were found on long-text classification using Transformers. Most only use a small amount of data and do not report any HPO. In this study, using 18k news articles, we investigate which pretrained models are recommended to use based on the output length of the tokenizer. We then compare some hacks to shorten and enrich the sequences, which are the removals of stopwords, punctuation, low-frequency words, and recurring words. To get a fair comparison, we propose and run an efficient and dynamic HPO procedure that can be done gradually on a limited resource and does not require a long-running optimization library. Using the best hack found, we then compare 512, 256, and 128 tokens length. We find that removing stopwords while keeping punctuation and low-frequency words is the best hack. Some of our setups manage to outperform taking 512 first tokens using a smaller 128 or 256 first tokens which manage to represent the same information while requiring less computational resources. The findings could help developers to efficiently pursue optimal performance of the models using limited resources.
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models
Mar 11, 2024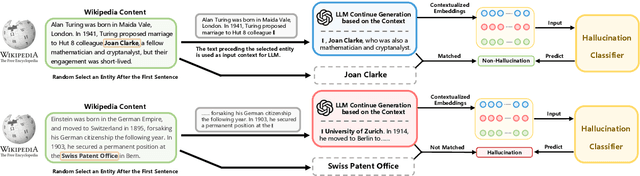
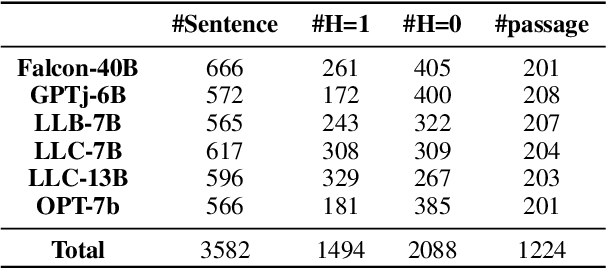
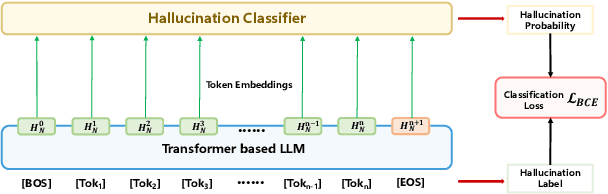
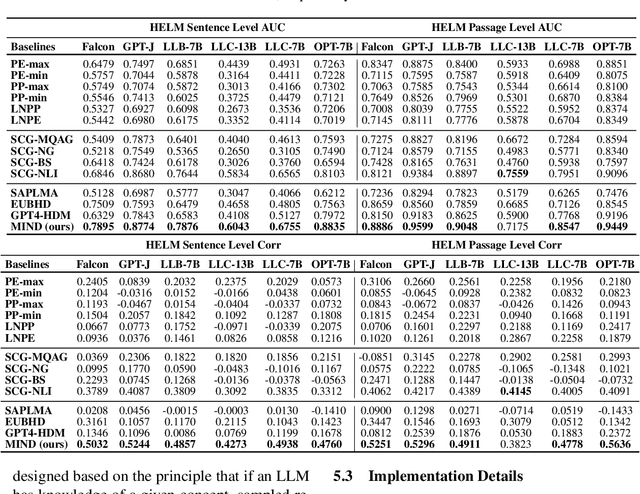
Hallucinations in large language models (LLMs) refer to the phenomenon of LLMs producing responses that are coherent yet factually inaccurate. This issue undermines the effectiveness of LLMs in practical applications, necessitating research into detecting and mitigating hallucinations of LLMs. Previous studies have mainly concentrated on post-processing techniques for hallucination detection, which tend to be computationally intensive and limited in effectiveness due to their separation from the LLM's inference process. To overcome these limitations, we introduce MIND, an unsupervised training framework that leverages the internal states of LLMs for real-time hallucination detection without requiring manual annotations. Additionally, we present HELM, a new benchmark for evaluating hallucination detection across multiple LLMs, featuring diverse LLM outputs and the internal states of LLMs during their inference process. Our experiments demonstrate that MIND outperforms existing state-of-the-art methods in hallucination detection.
Online Identification of Stochastic Continuous-Time Wiener Models Using Sampled Data
Mar 09, 2024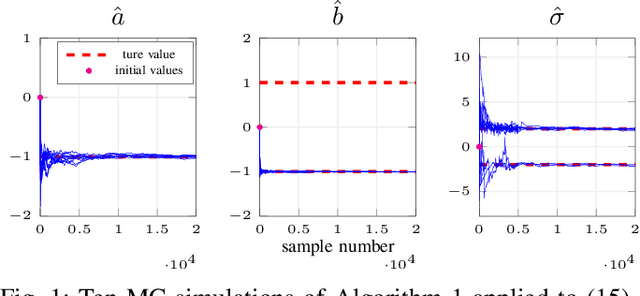
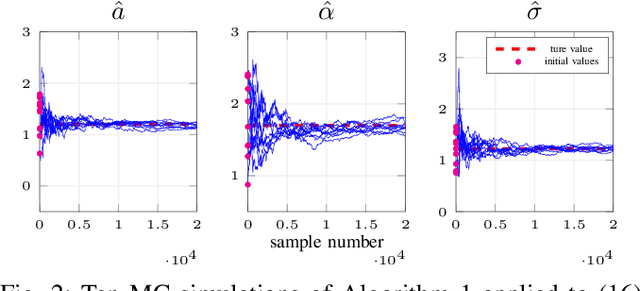
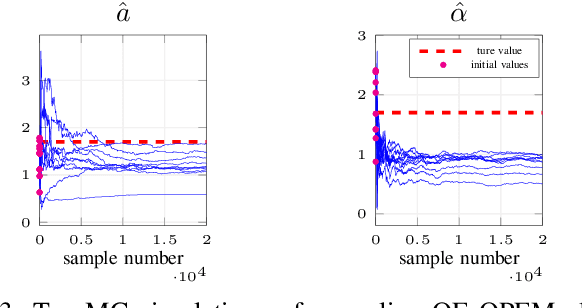
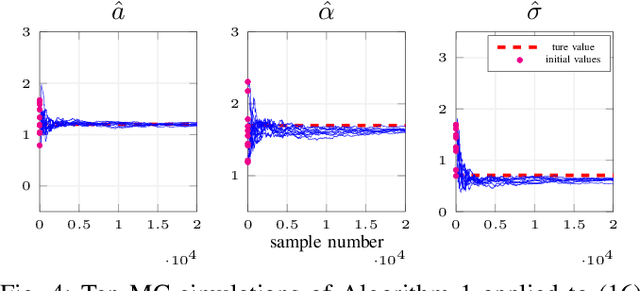
It is well known that ignoring the presence of stochastic disturbances in the identification of stochastic Wiener models leads to asymptotically biased estimators. On the other hand, optimal statistical identification, via likelihood-based methods, is sensitive to the assumptions on the data distribution and is usually based on relatively complex sequential Monte Carlo algorithms. We develop a simple recursive online estimation algorithm based on an output-error predictor, for the identification of continuous-time stochastic parametric Wiener models through stochastic approximation. The method is applicable to generic model parameterizations and, as demonstrated in the numerical simulation examples, it is robust with respect to the assumptions on the spectrum of the disturbance process.
Raw Instinct: Trust Your Classifiers and Skip the Conversion
Mar 21, 2024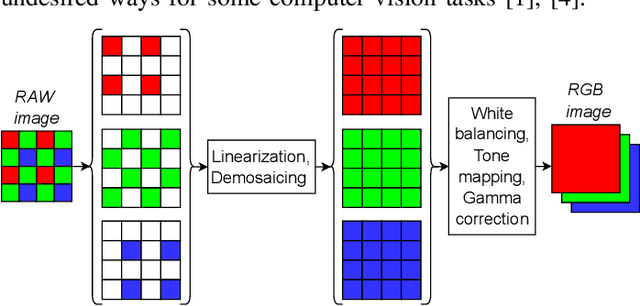
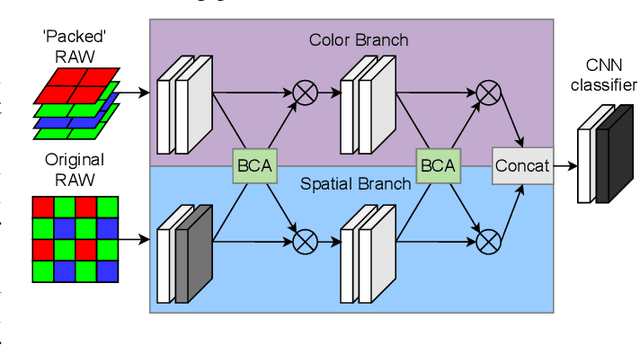

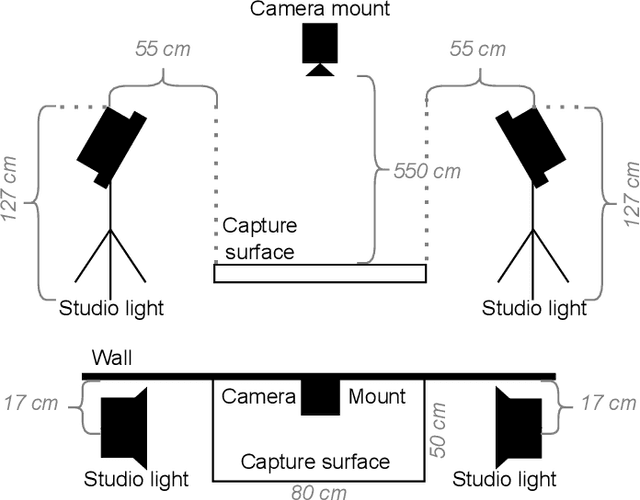
Using RAW-images in computer vision problems is surprisingly underexplored considering that converting from RAW to RGB does not introduce any new capture information. In this paper, we show that a sufficiently advanced classifier can yield equivalent results on RAW input compared to RGB and present a new public dataset consisting of RAW images and the corresponding converted RGB images. Classifying images directly from RAW is attractive, as it allows for skipping the conversion to RGB, lowering computation time significantly. Two CNN classifiers are used to classify the images in both formats, confirming that classification performance can indeed be preserved. We furthermore show that the total computation time from RAW image data to classification results for RAW images can be up to 8.46 times faster than RGB. These results contribute to the evidence found in related works, that using RAW images as direct input to computer vision algorithms looks very promising.
* https://www.kaggle.com/datasets/mathiasviborg/raw-instinct
PNAS-MOT: Multi-Modal Object Tracking with Pareto Neural Architecture Search
Mar 23, 2024Multiple object tracking is a critical task in autonomous driving. Existing works primarily focus on the heuristic design of neural networks to obtain high accuracy. As tracking accuracy improves, however, neural networks become increasingly complex, posing challenges for their practical application in real driving scenarios due to the high level of latency. In this paper, we explore the use of the neural architecture search (NAS) methods to search for efficient architectures for tracking, aiming for low real-time latency while maintaining relatively high accuracy. Another challenge for object tracking is the unreliability of a single sensor, therefore, we propose a multi-modal framework to improve the robustness. Experiments demonstrate that our algorithm can run on edge devices within lower latency constraints, thus greatly reducing the computational requirements for multi-modal object tracking while keeping lower latency.
* IEEE Robotics and Automation Letters 2024. Code is available at https://github.com/PholyPeng/PNAS-MOT