 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How Does Pruning Impact Long-Tailed Multi-Label Medical Image Classifiers?
Aug 17, 2023
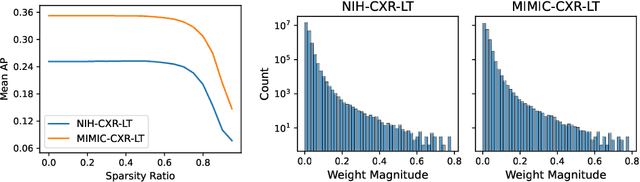

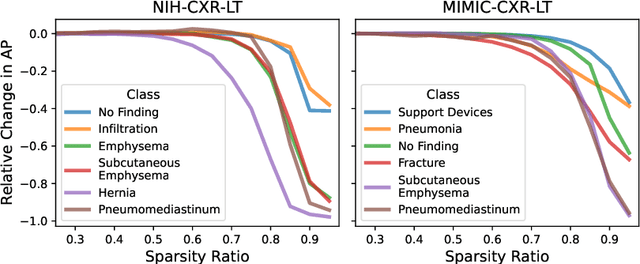
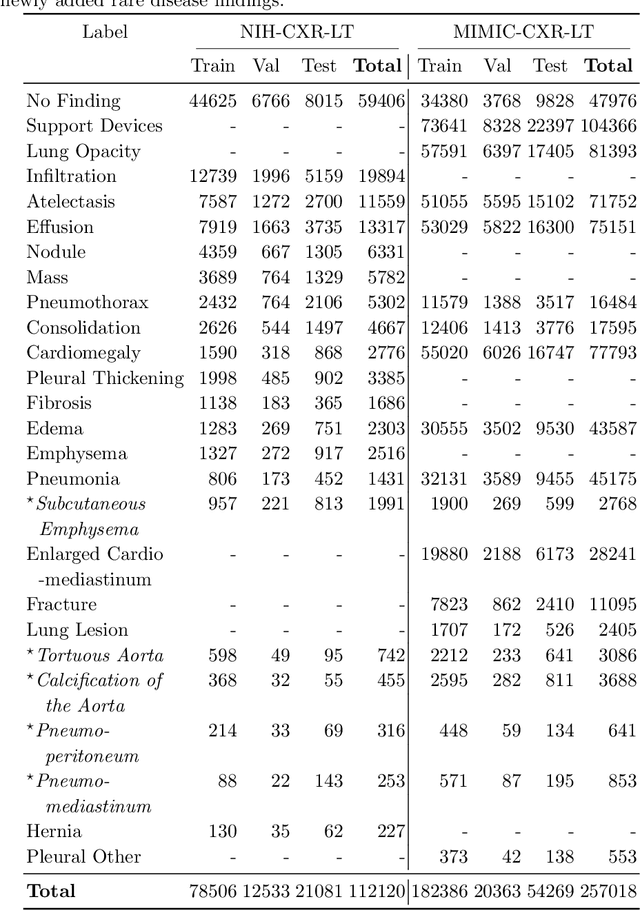
Pruning has emerged as a powerful technique for compressing deep neural networks, reducing memory usage and inference time without significantly affecting overall performance. However, the nuanced ways in which pruning impacts model behavior are not well understood, particularly for long-tailed, multi-label datasets commonly found in clinical settings. This knowledge gap could have dangerous implications when deploying a pruned model for diagnosis, where unexpected model behavior could impact patient well-being. To fill this gap, we perform the first analysis of pruning's effect on neural networks trained to diagnose thorax diseases from chest X-rays (CXRs). On two large CXR datasets, we examine which diseases are most affected by pruning and characterize class "forgettability" based on disease frequency and co-occurrence behavior. Further, we identify individual CXRs where uncompressed and heavily pruned models disagree, known as pruning-identified exemplars (PIEs), and conduct a human reader study to evaluate their unifying qualities. We find that radiologists perceive PIEs as having more label noise, lower image quality, and higher diagnosis difficulty. This work represents a first step toward understanding the impact of pruning on model behavior in deep long-tailed, multi-label medical image classification. All code, model weights, and data access instructions can be found at https://github.com/VITA-Group/PruneCXR.
ReProHRL: Towards Multi-Goal Navigation in the Real World using Hierarchical Agents
Aug 17, 2023
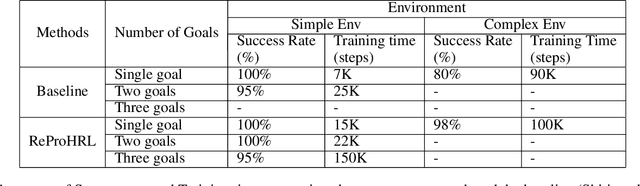
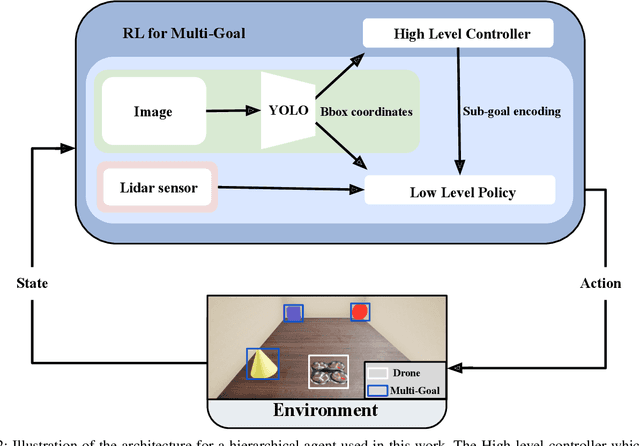
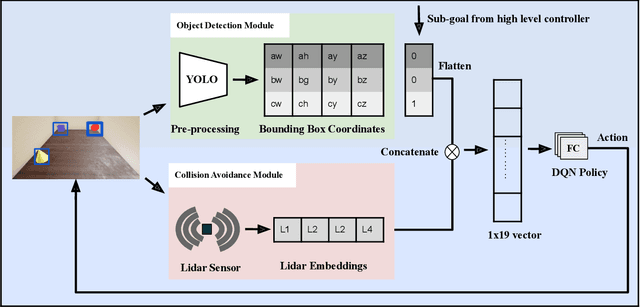
Robots have been successfully used to perform tasks with high precision. In real-world environments with sparse rewards and multiple goals, learning is still a major challenge and Reinforcement Learning (RL) algorithms fail to learn good policies. Training in simulation environments and then fine-tuning in the real world is a common approach. However, adapting to the real-world setting is a challenge. In this paper, we present a method named Ready for Production Hierarchical RL (ReProHRL) that divides tasks with hierarchical multi-goal navigation guided by reinforcement learning. We also use object detectors as a pre-processing step to learn multi-goal navigation and transfer it to the real world. Empirical results show that the proposed ReProHRL method outperforms the state-of-the-art baseline in simulation and real-world environments in terms of both training time and performance. Although both methods achieve a 100% success rate in a simple environment for single goal-based navigation, in a more complex environment and multi-goal setting, the proposed method outperforms the baseline by 18% and 5%, respectively. For the real-world implementation and proof of concept demonstration, we deploy the proposed method on a nano-drone named Crazyflie with a front camera to perform multi-goal navigation experiments.
Long-frame-shift Neural Speech Phase Prediction with Spectral Continuity Enhancement and Interpolation Error Compensation
Aug 17, 2023Speech phase prediction, which is a significant research focus in the field of signal processing, aims to recover speech phase spectra from amplitude-related features. However, existing speech phase prediction methods are constrained to recovering phase spectra with short frame shifts, which are considerably smaller than the theoretical upper bound required for exact waveform reconstruction of short-time Fourier transform (STFT). To tackle this issue, we present a novel long-frame-shift neural speech phase prediction (LFS-NSPP) method which enables precise prediction of long-frame-shift phase spectra from long-frame-shift log amplitude spectra. The proposed method consists of three stages: interpolation, prediction and decimation. The short-frame-shift log amplitude spectra are first constructed from long-frame-shift ones through frequency-by-frequency interpolation to enhance the spectral continuity, and then employed to predict short-frame-shift phase spectra using an NSPP model, thereby compensating for interpolation errors. Ultimately, the long-frame-shift phase spectra are obtained from short-frame-shift ones through frame-by-frame decimation. Experimental results show that the proposed LFS-NSPP method can yield superior quality in predicting long-frame-shift phase spectra than the original NSPP model and other signal-processing-based phase estimation algorithms.
Controlling Federated Learning for Covertness
Aug 17, 2023
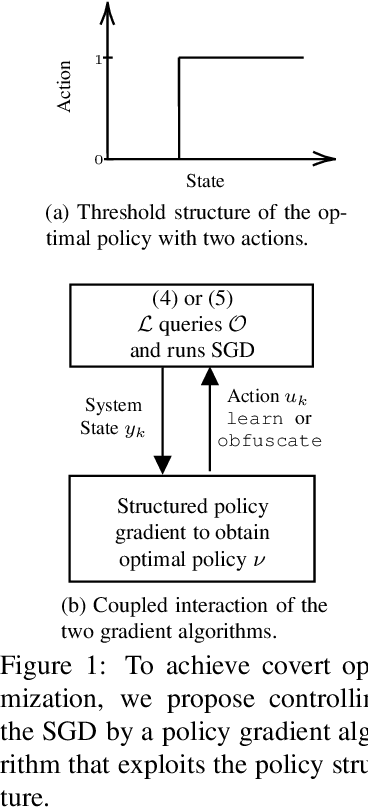
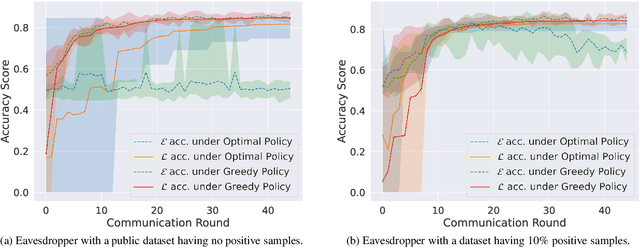
A learner aims to minimize a function $f$ by repeatedly querying a distributed oracle that provides noisy gradient evaluations. At the same time, the learner seeks to hide $\arg\min f$ from a malicious eavesdropper that observes the learner's queries. This paper considers the problem of \textit{covert} or \textit{learner-private} optimization, where the learner has to dynamically choose between learning and obfuscation by exploiting the stochasticity. The problem of controlling the stochastic gradient algorithm for covert optimization is modeled as a Markov decision process, and we show that the dynamic programming operator has a supermodular structure implying that the optimal policy has a monotone threshold structure. A computationally efficient policy gradient algorithm is proposed to search for the optimal querying policy without knowledge of the transition probabilities. As a practical application, our methods are demonstrated on a hate speech classification task in a federated setting where an eavesdropper can use the optimal weights to generate toxic content, which is more easily misclassified. Numerical results show that when the learner uses the optimal policy, an eavesdropper can only achieve a validation accuracy of $52\%$ with no information and $69\%$ when it has a public dataset with 10\% positive samples compared to $83\%$ when the learner employs a greedy policy.
Federated Reinforcement Learning for Electric Vehicles Charging Control on Distribution Networks
Aug 17, 2023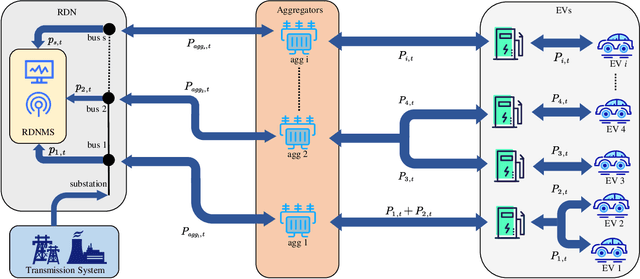
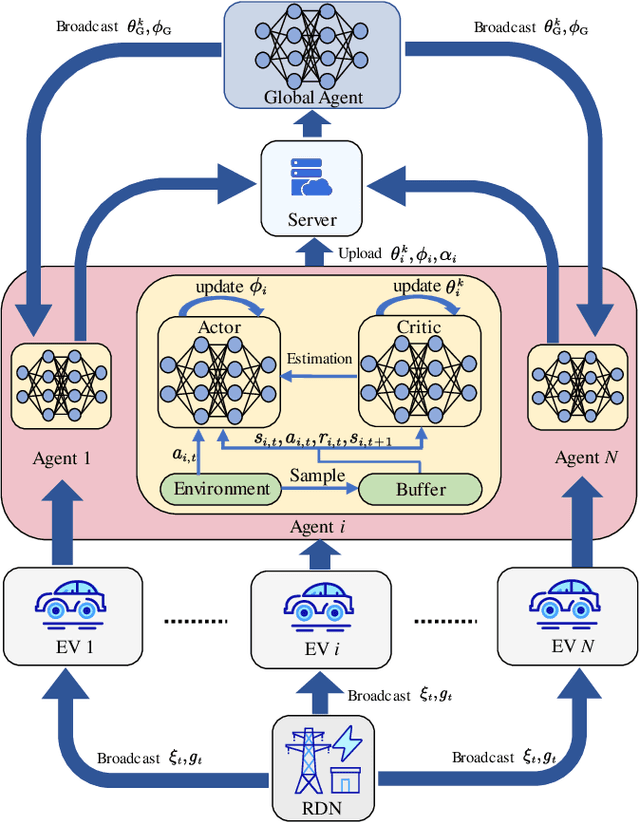
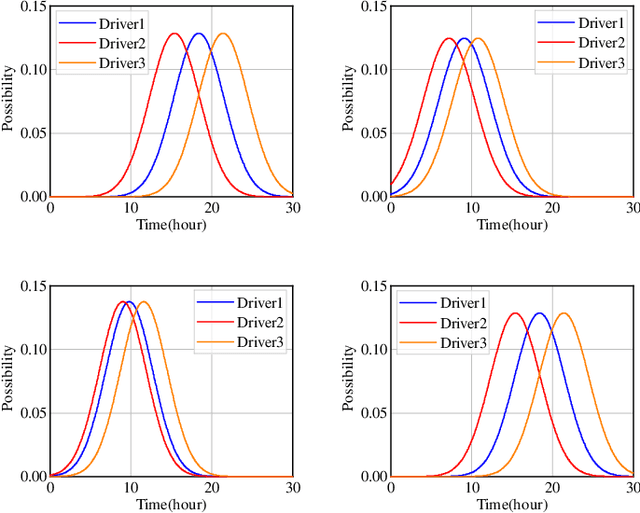
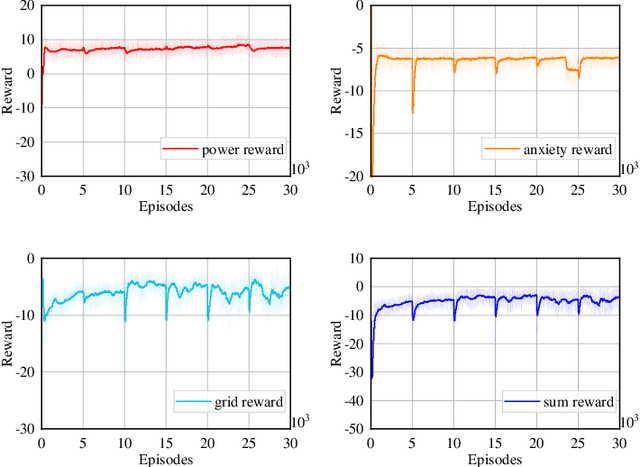
With the growing popularity of electric vehicles (EVs), maintaining power grid stability has become a significant challenge. To address this issue, EV charging control strategies have been developed to manage the switch between vehicle-to-grid (V2G) and grid-to-vehicle (G2V) modes for EVs. In this context, multi-agent deep reinforcement learning (MADRL) has proven its effectiveness in EV charging control. However, existing MADRL-based approaches fail to consider the natural power flow of EV charging/discharging in the distribution network and ignore driver privacy. To deal with these problems, this paper proposes a novel approach that combines multi-EV charging/discharging with a radial distribution network (RDN) operating under optimal power flow (OPF) to distribute power flow in real time. A mathematical model is developed to describe the RDN load. The EV charging control problem is formulated as a Markov Decision Process (MDP) to find an optimal charging control strategy that balances V2G profits, RDN load, and driver anxiety. To effectively learn the optimal EV charging control strategy, a federated deep reinforcement learning algorithm named FedSAC is further proposed. Comprehensive simulation results demonstrate the effectiveness and superiority of our proposed algorithm in terms of the diversity of the charging control strategy, the power fluctuations on RDN, the convergence efficiency, and the generalization ability.
Subspace-Constrained Continuous Methane Leak Monitoring and Optimal Sensor Placement
Aug 03, 2023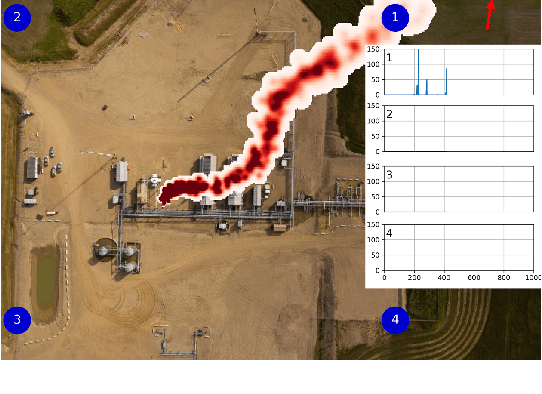

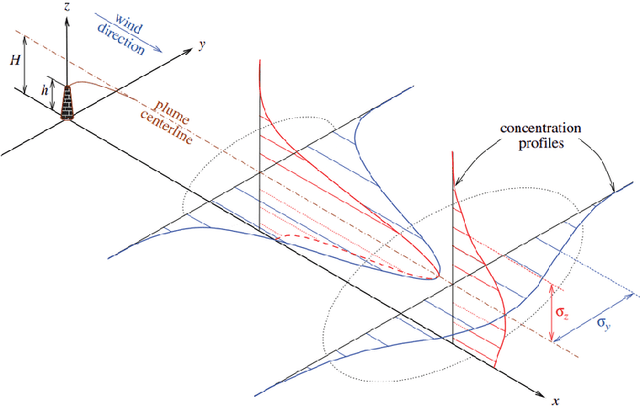
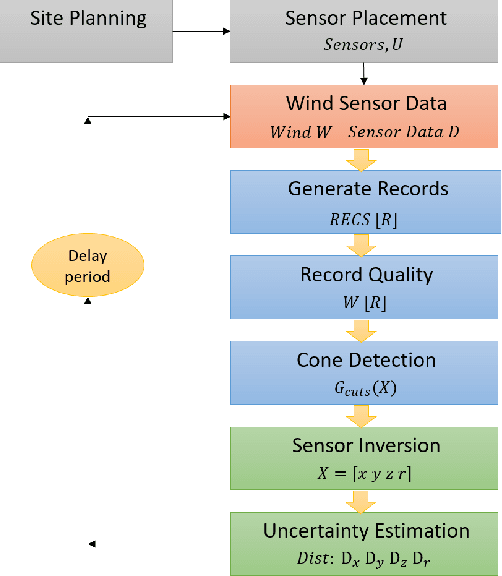
This work presents a procedure that can quickly identify and isolate methane emission sources leading to expedient remediation. Minimizing the time required to identify a leak and the subsequent time to dispatch repair crews can significantly reduce the amount of methane released into the atmosphere. The procedure developed utilizes permanently installed low-cost methane sensors at an oilfield facility to continuously monitor leaked gas concentration above background levels. The methods developed for optimal sensor placement and leak inversion in consideration of predefined subspaces and restricted zones are presented. In particular, subspaces represent regions comprising one or more equipment items that may leak, and restricted zones define regions in which a sensor may not be placed due to site restrictions by design. Thus, subspaces constrain the inversion problem to specified locales, while restricted zones constrain sensor placement to feasible zones. The development of synthetic wind models, and those based on historical data, are also presented as a means to accommodate optimal sensor placement under wind uncertainty. The wind models serve as realizations for planning purposes, with the aim of maximizing the mean coverage measure for a given number of sensors. Once the optimal design is established, continuous real-time monitoring permits localization and quantification of a methane leak source. The necessary methods, mathematical formulation and demonstrative test results are presented.
An End-to-End Time Series Model for Simultaneous Imputation and Forecast
Jun 01, 2023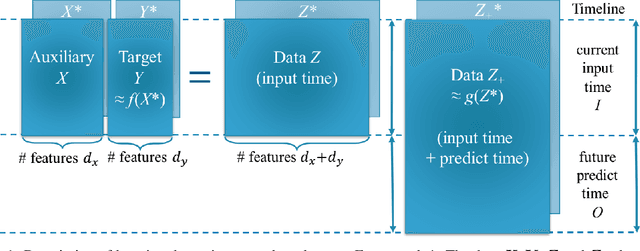
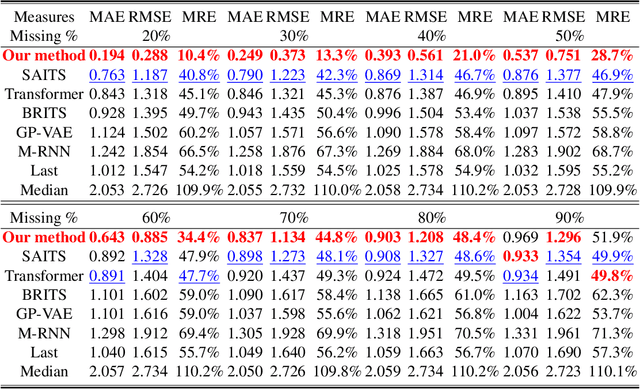
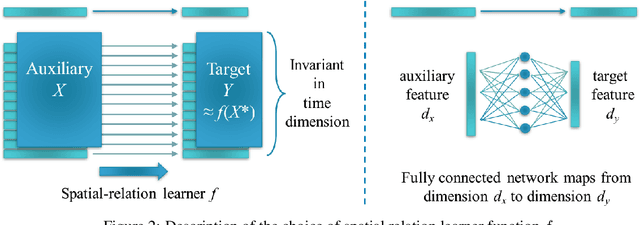
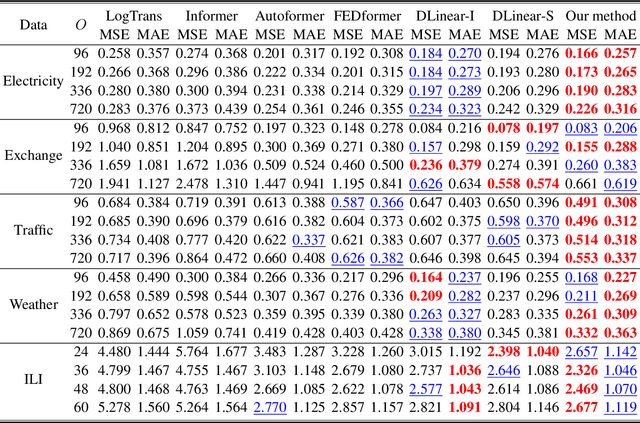
Time series forecasting using historical data has been an interesting and challenging topic, especially when the data is corrupted by missing values. In many industrial problem, it is important to learn the inference function between the auxiliary observations and target variables as it provides additional knowledge when the data is not fully observed. We develop an end-to-end time series model that aims to learn the such inference relation and make a multiple-step ahead forecast. Our framework trains jointly two neural networks, one to learn the feature-wise correlations and the other for the modeling of temporal behaviors. Our model is capable of simultaneously imputing the missing entries and making a multiple-step ahead prediction. The experiments show good overall performance of our framework over existing methods in both imputation and forecasting tasks.
EnrichEvent: Enriching Social Data with Contextual Information for Emerging Event Extraction
Aug 16, 2023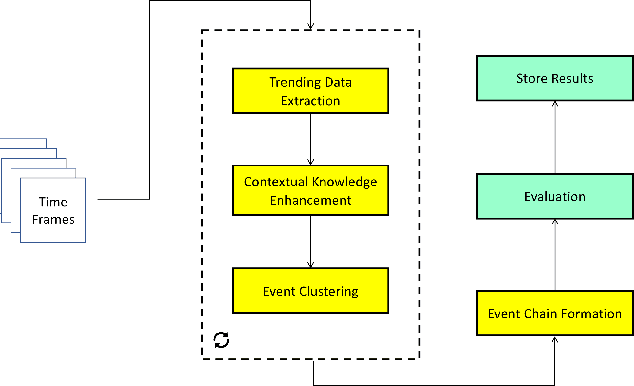
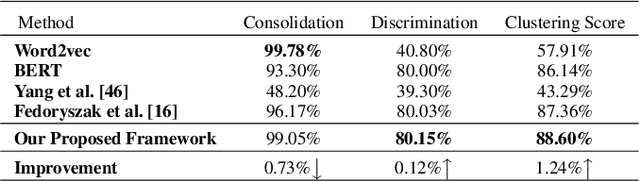
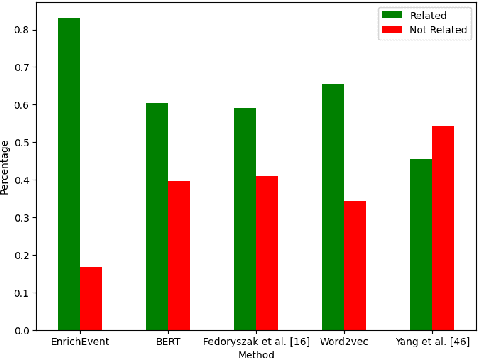
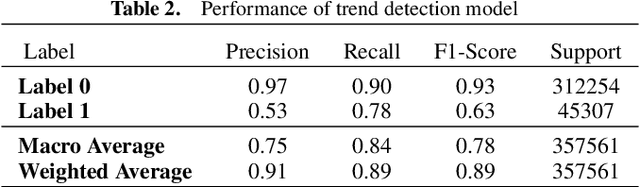
Social platforms have emerged as crucial platforms for disseminating information and discussing real-life social events, which offers an excellent opportunity for researchers to design and implement novel event detection frameworks. However, most existing approaches merely exploit keyword burstiness or network structures to detect unspecified events. Thus, they often fail to identify unspecified events regarding the challenging nature of events and social data. Social data, e.g., tweets, is characterized by misspellings, incompleteness, word sense ambiguation, and irregular language, as well as variation in aspects of opinions. Moreover, extracting discriminative features and patterns for evolving events by exploiting the limited structural knowledge is almost infeasible. To address these challenges, in this thesis, we propose a novel framework, namely EnrichEvent, that leverages the lexical and contextual representations of streaming social data. In particular, we leverage contextual knowledge, as well as lexical knowledge, to detect semantically related tweets and enhance the effectiveness of the event detection approaches. Eventually, our proposed framework produces cluster chains for each event to show the evolving variation of the event through time. We conducted extensive experiments to evaluate our framework, validating its high performance and effectiveness in detecting and distinguishing unspecified social events.
Agglomerative Transformer for Human-Object Interaction Detection
Aug 16, 2023

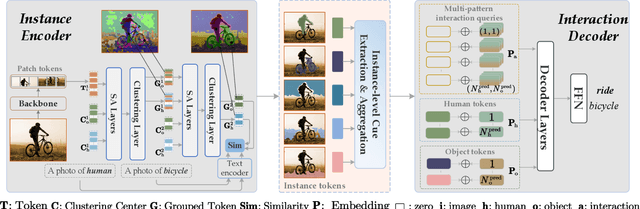
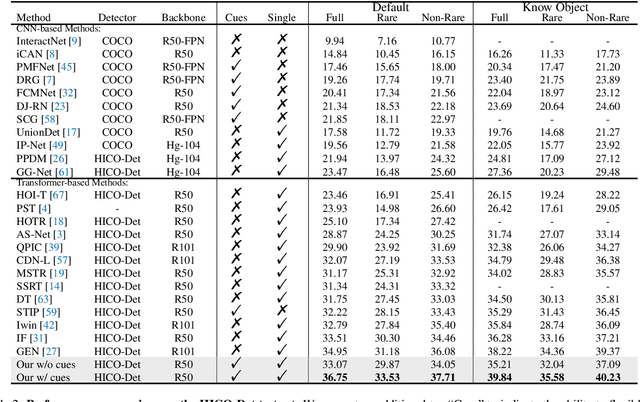
We propose an agglomerative Transformer (AGER) that enables Transformer-based human-object interaction (HOI) detectors to flexibly exploit extra instance-level cues in a single-stage and end-to-end manner for the first time. AGER acquires instance tokens by dynamically clustering patch tokens and aligning cluster centers to instances with textual guidance, thus enjoying two benefits: 1) Integrality: each instance token is encouraged to contain all discriminative feature regions of an instance, which demonstrates a significant improvement in the extraction of different instance-level cues and subsequently leads to a new state-of-the-art performance of HOI detection with 36.75 mAP on HICO-Det. 2) Efficiency: the dynamical clustering mechanism allows AGER to generate instance tokens jointly with the feature learning of the Transformer encoder, eliminating the need of an additional object detector or instance decoder in prior methods, thus allowing the extraction of desirable extra cues for HOI detection in a single-stage and end-to-end pipeline. Concretely, AGER reduces GFLOPs by 8.5% and improves FPS by 36%, even compared to a vanilla DETR-like pipeline without extra cue extraction.
Partially Observable Multi-agent RL with (Quasi-)Efficiency: The Blessing of Information Sharing
Aug 16, 2023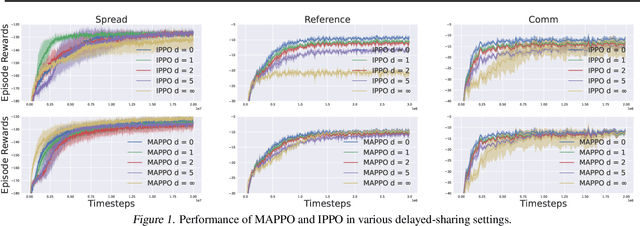
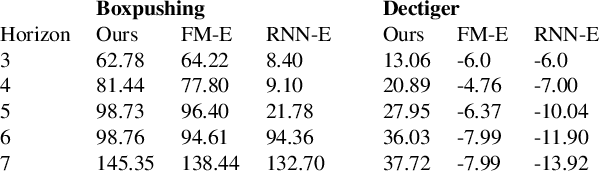
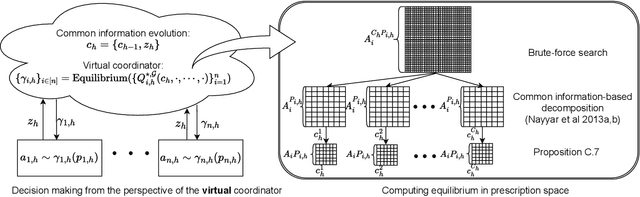
We study provable multi-agent reinforcement learning (MARL) in the general framework of partially observable stochastic games (POSGs). To circumvent the known hardness results and the use of computationally intractable oracles, we advocate leveraging the potential \emph{information-sharing} among agents, a common practice in empirical MARL, and a standard model for multi-agent control systems with communications. We first establish several computation complexity results to justify the necessity of information-sharing, as well as the observability assumption that has enabled quasi-efficient single-agent RL with partial observations, for computational efficiency in solving POSGs. We then propose to further \emph{approximate} the shared common information to construct an {approximate model} of the POSG, in which planning an approximate equilibrium (in terms of solving the original POSG) can be quasi-efficient, i.e., of quasi-polynomial-time, under the aforementioned assumptions. Furthermore, we develop a partially observable MARL algorithm that is both statistically and computationally quasi-efficient. We hope our study may open up the possibilities of leveraging and even designing different \emph{information structures}, for developing both sample- and computation-efficient partially observable MARL.