 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies
Aug 06, 2023
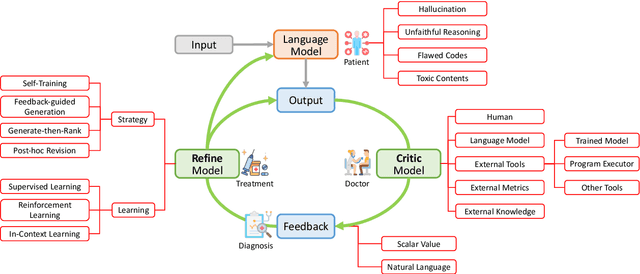
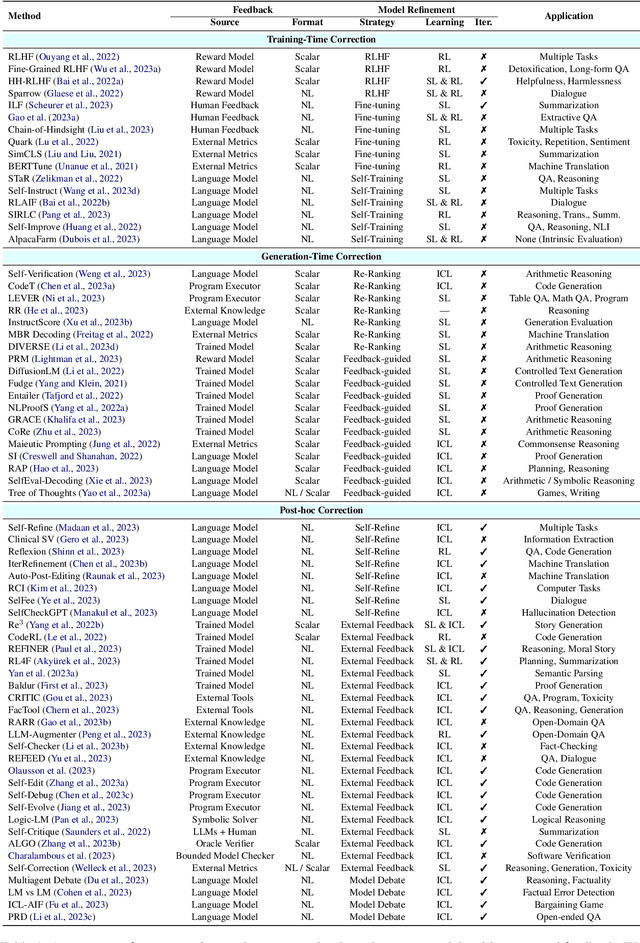
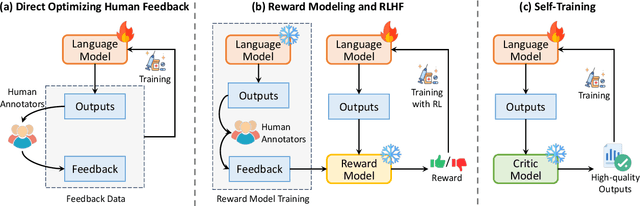
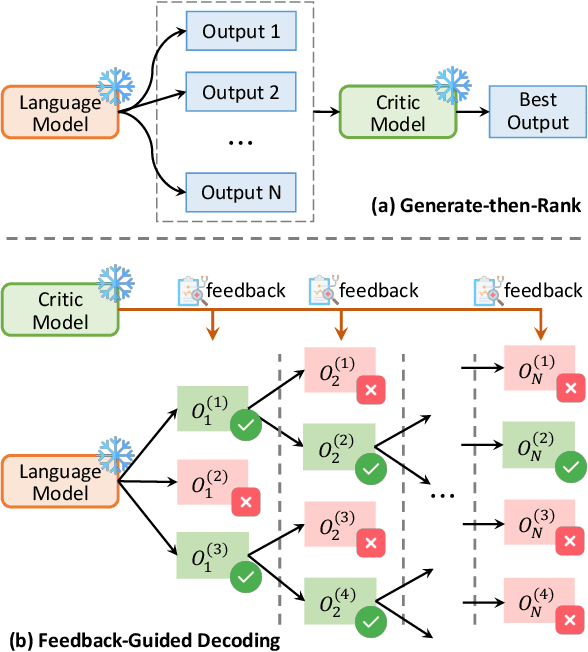
Large language models (LLMs) have demonstrated remarkable performance across a wide array of NLP tasks. However, their efficacy is undermined by undesired and inconsistent behaviors, including hallucination, unfaithful reasoning, and toxic content. A promising approach to rectify these flaws is self-correction, where the LLM itself is prompted or guided to fix problems in its own output. Techniques leveraging automated feedback -- either produced by the LLM itself or some external system -- are of particular interest as they are a promising way to make LLM-based solutions more practical and deployable with minimal human feedback. This paper presents a comprehensive review of this emerging class of techniques. We analyze and taxonomize a wide array of recent work utilizing these strategies, including training-time, generation-time, and post-hoc correction. We also summarize the major applications of this strategy and conclude by discussing future directions and challenges.
PDE-Refiner: Achieving Accurate Long Rollouts with Neural PDE Solvers
Aug 10, 2023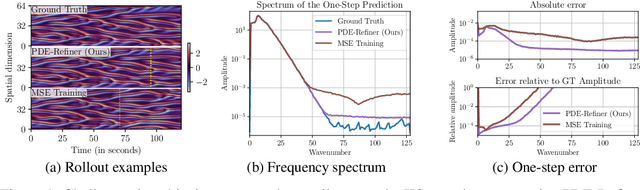
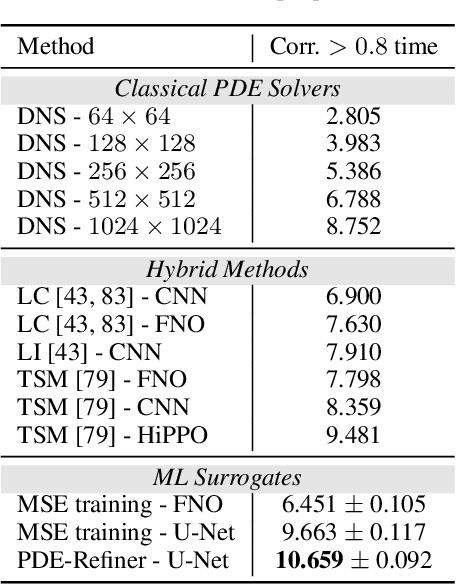
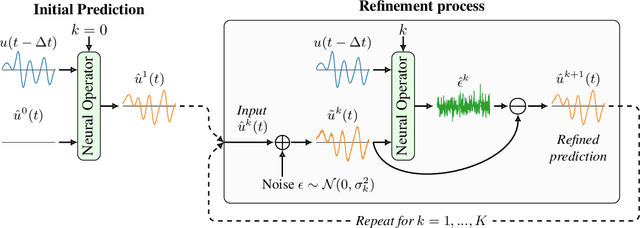

Time-dependent partial differential equations (PDEs) are ubiquitous in science and engineering. Recently, mostly due to the high computational cost of traditional solution techniques, deep neural network based surrogates have gained increased interest. The practical utility of such neural PDE solvers relies on their ability to provide accurate, stable predictions over long time horizons, which is a notoriously hard problem. In this work, we present a large-scale analysis of common temporal rollout strategies, identifying the neglect of non-dominant spatial frequency information, often associated with high frequencies in PDE solutions, as the primary pitfall limiting stable, accurate rollout performance. Based on these insights, we draw inspiration from recent advances in diffusion models to introduce PDE-Refiner; a novel model class that enables more accurate modeling of all frequency components via a multistep refinement process. We validate PDE-Refiner on challenging benchmarks of complex fluid dynamics, demonstrating stable and accurate rollouts that consistently outperform state-of-the-art models, including neural, numerical, and hybrid neural-numerical architectures. We further demonstrate that PDE-Refiner greatly enhances data efficiency, since the denoising objective implicitly induces a novel form of spectral data augmentation. Finally, PDE-Refiner's connection to diffusion models enables an accurate and efficient assessment of the model's predictive uncertainty, allowing us to estimate when the surrogate becomes inaccurate.
Automatic Extraction of Relevant Road Infrastructure using Connected vehicle data and Deep Learning Model
Aug 10, 2023In today's rapidly evolving urban landscapes, efficient and accurate mapping of road infrastructure is critical for optimizing transportation systems, enhancing road safety, and improving the overall mobility experience for drivers and commuters. Yet, a formidable bottleneck obstructs progress - the laborious and time-intensive manual identification of intersections. Simply considering the shear number of intersections that need to be identified, and the labor hours required per intersection, the need for an automated solution becomes undeniable. To address this challenge, we propose a novel approach that leverages connected vehicle data and cutting-edge deep learning techniques. By employing geohashing to segment vehicle trajectories and then generating image representations of road segments, we utilize the YOLOv5 (You Only Look Once version 5) algorithm for accurate classification of both straight road segments and intersections. Experimental results demonstrate an impressive overall classification accuracy of 95%, with straight roads achieving a remarkable 97% F1 score and intersections reaching a 90% F1 score. This approach not only saves time and resources but also enables more frequent updates and a comprehensive understanding of the road network. Our research showcases the potential impact on traffic management, urban planning, and autonomous vehicle navigation systems. The fusion of connected vehicle data and deep learning models holds promise for a transformative shift in road infrastructure mapping, propelling us towards a smarter, safer, and more connected transportation ecosystem.
CSPM: A Contrastive Spatiotemporal Preference Model for CTR Prediction in On-Demand Food Delivery Services
Aug 10, 2023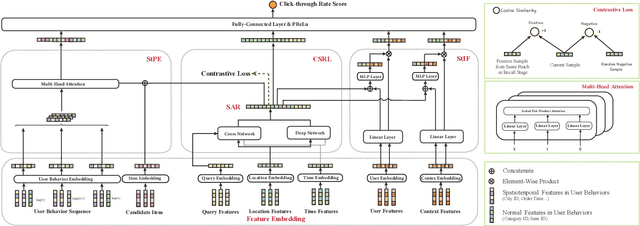
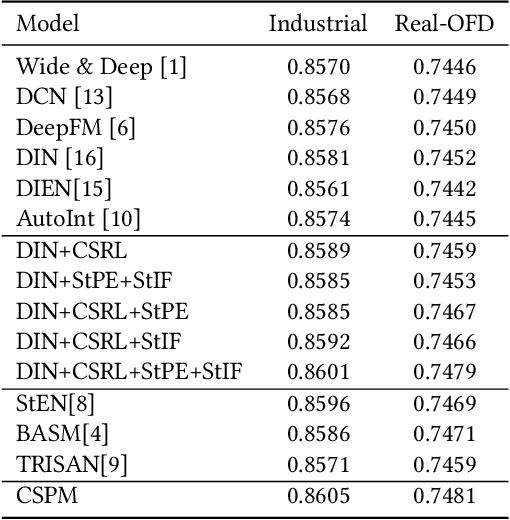
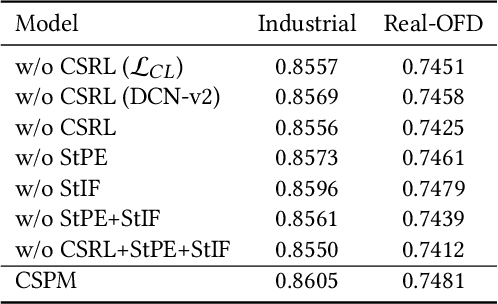
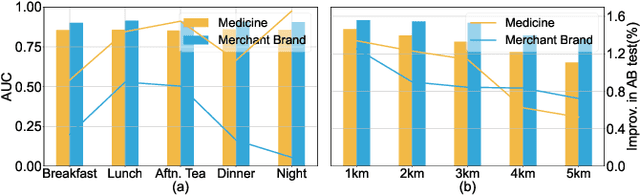
Click-through rate (CTR) prediction is a crucial task in the context of an online on-demand food delivery (OFD) platform for precisely estimating the probability of a user clicking on food items. Unlike universal e-commerce platforms such as Taobao and Amazon, user behaviors and interests on the OFD platform are more location and time-sensitive due to limited delivery ranges and regional commodity supplies. However, existing CTR prediction algorithms in OFD scenarios concentrate on capturing interest from historical behavior sequences, which fails to effectively model the complex spatiotemporal information within features, leading to poor performance. To address this challenge, this paper introduces the Contrastive Sres under different search states using three modules: contrastive spatiotemporal representation learning (CSRL), spatiotemporal preference extractor (StPE), and spatiotemporal information filter (StIF). CSRL utilizes a contrastive learning framework to generate a spatiotemporal activation representation (SAR) for the search action. StPE employs SAR to activate users' diverse preferences related to location and time from the historical behavior sequence field, using a multi-head attention mechanism. StIF incorporates SAR into a gating network to automatically capture important features with latent spatiotemporal effects. Extensive experiments conducted on two large-scale industrial datasets demonstrate the state-of-the-art performance of CSPM. Notably, CSPM has been successfully deployed in Alibaba's online OFD platform Ele.me, resulting in a significant 0.88% lift in CTR, which has substantial business implications.
I/O Burst Prediction for HPC Clusters using Darshan Logs
Aug 20, 2023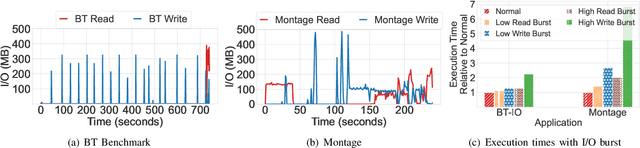
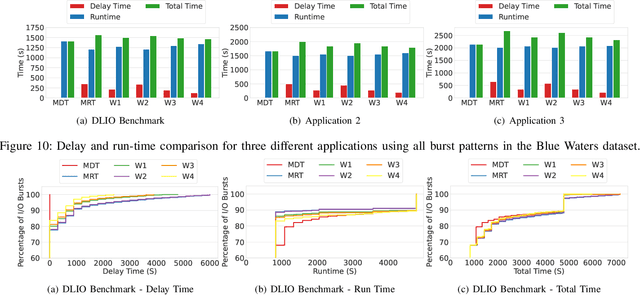
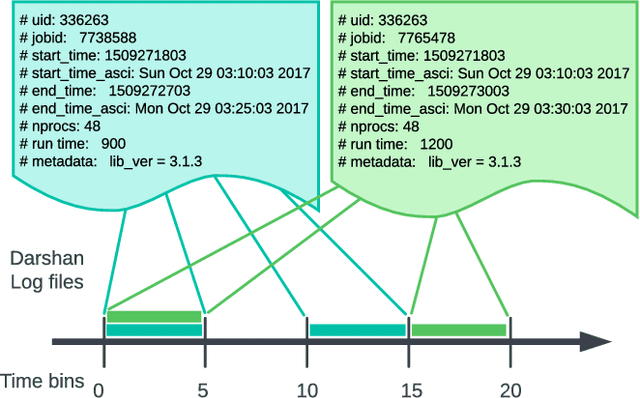
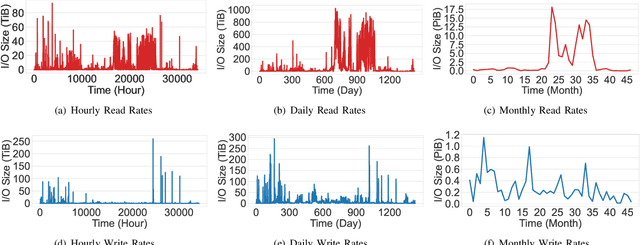
Understanding cluster-wide I/O patterns of large-scale HPC clusters is essential to minimize the occurrence and impact of I/O interference. Yet, most previous work in this area focused on monitoring and predicting task and node-level I/O burst events. This paper analyzes Darshan reports from three supercomputers to extract system-level read and write I/O rates in five minutes intervals. We observe significant (over 100x) fluctuations in read and write I/O rates in all three clusters. We then train machine learning models to estimate the occurrence of system-level I/O bursts 5 - 120 minutes ahead. Evaluation results show that we can predict I/O bursts with more than 90% accuracy (F-1 score) five minutes ahead and more than 87% accuracy two hours ahead. We also show that the ML models attain more than 70% accuracy when estimating the degree of the I/O burst. We believe that high-accuracy predictions of I/O bursts can be used in multiple ways, such as postponing delay-tolerant I/O operations (e.g., checkpointing), pausing nonessential applications (e.g., file system scrubbers), and devising I/O-aware job scheduling methods. To validate this claim, we simulated a burst-aware job scheduler that can postpone the start time of applications to avoid I/O bursts. We show that the burst-aware job scheduling can lead to an up to 5x decrease in application runtime.
Adversarial Collaborative Filtering for Free
Aug 20, 2023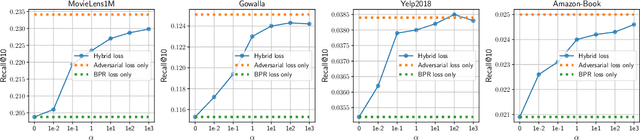
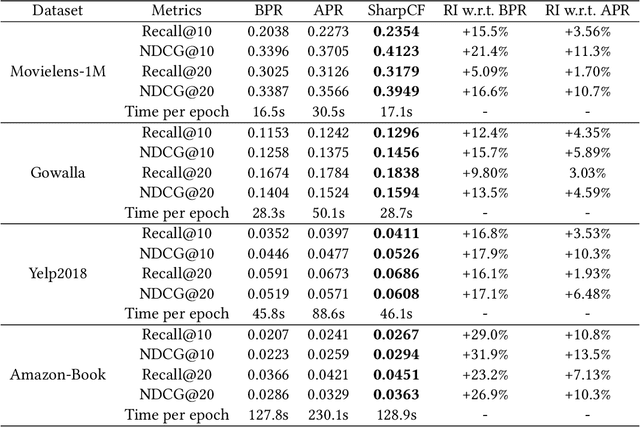
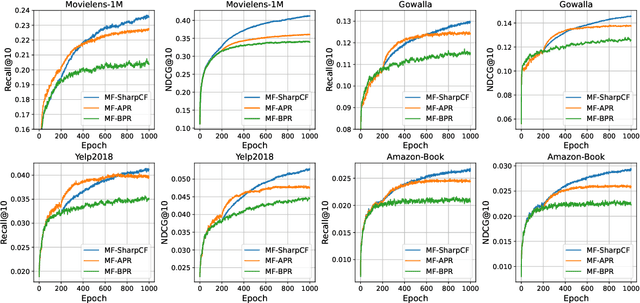
Collaborative Filtering (CF) has been successfully used to help users discover the items of interest. Nevertheless, existing CF methods suffer from noisy data issue, which negatively impacts the quality of recommendation. To tackle this problem, many prior studies leverage adversarial learning to regularize the representations of users/items, which improves both generalizability and robustness. Those methods often learn adversarial perturbations and model parameters under min-max optimization framework. However, there still have two major drawbacks: 1) Existing methods lack theoretical guarantees of why adding perturbations improve the model generalizability and robustness; 2) Solving min-max optimization is time-consuming. In addition to updating the model parameters, each iteration requires additional computations to update the perturbations, making them not scalable for industry-scale datasets. In this paper, we present Sharpness-aware Collaborative Filtering (SharpCF), a simple yet effective method that conducts adversarial training without extra computational cost over the base optimizer. To achieve this goal, we first revisit the existing adversarial collaborative filtering and discuss its connection with recent Sharpness-aware Minimization. This analysis shows that adversarial training actually seeks model parameters that lie in neighborhoods around the optimal model parameters having uniformly low loss values, resulting in better generalizability. To reduce the computational overhead, SharpCF introduces a novel trajectory loss to measure the alignment between current weights and past weights. Experimental results on real-world datasets demonstrate that our SharpCF achieves superior performance with almost zero additional computational cost comparing to adversarial training.
Make Transformer Great Again for Time Series Forecasting: Channel Aligned Robust Dual Transformer
May 24, 2023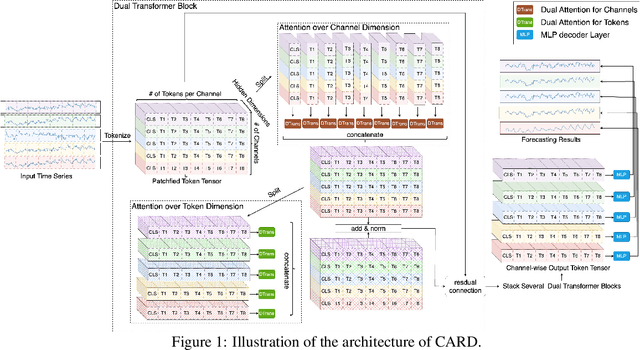
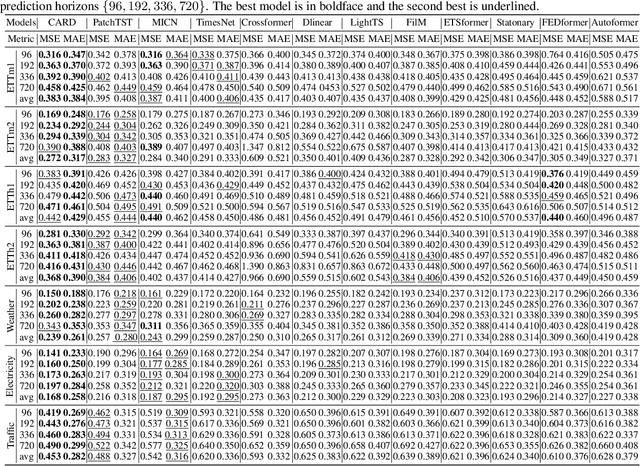
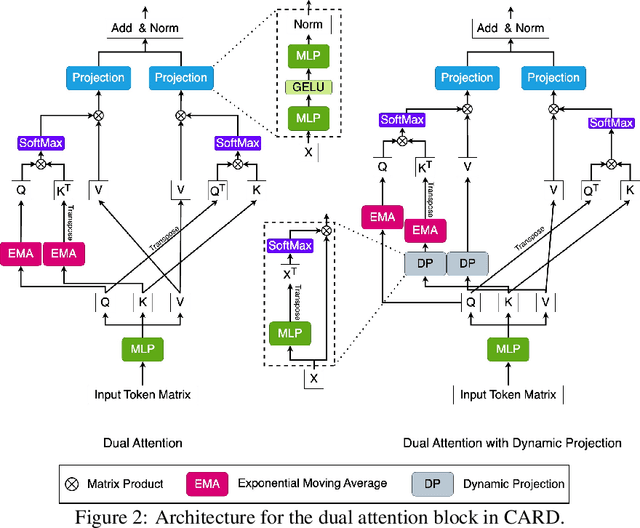
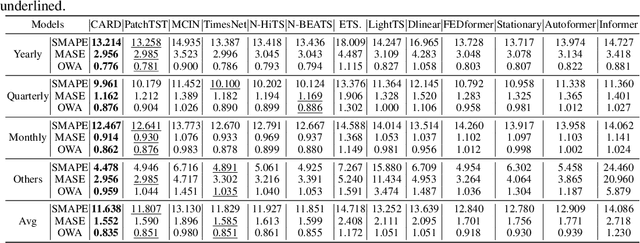
Recent studies have demonstrated the great power of deep learning methods, particularly Transformer and MLP, for time series forecasting. Despite its success in NLP and CV, many studies found that Transformer is less effective than MLP for time series forecasting. In this work, we design a special Transformer, i.e., channel-aligned robust dual Transformer (CARD for short), that addresses key shortcomings of Transformer in time series forecasting. First, CARD introduces a dual Transformer structure that allows it to capture both temporal correlations among signals and dynamical dependence among multiple variables over time. Second, we introduce a robust loss function for time series forecasting to alleviate the potential overfitting issue. This new loss function weights the importance of forecasting over a finite horizon based on prediction uncertainties. Our evaluation of multiple long-term and short-term forecasting datasets demonstrates that CARD significantly outperforms state-of-the-art time series forecasting methods, including both Transformer and MLP-based models.
Improving Time and Memory Efficiency of Genetic Algorithms by Storing Populations as Minimum Spanning Trees of Patches
Jun 29, 2023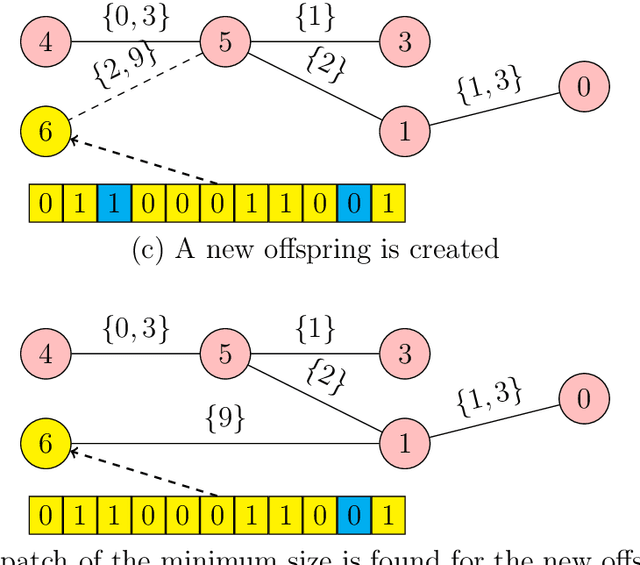
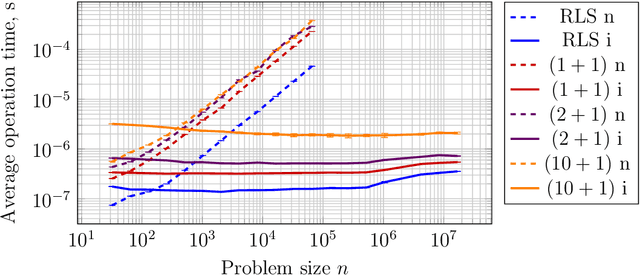
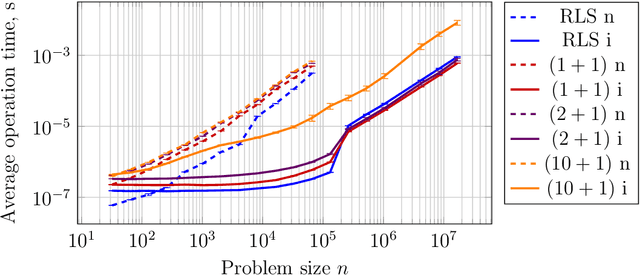
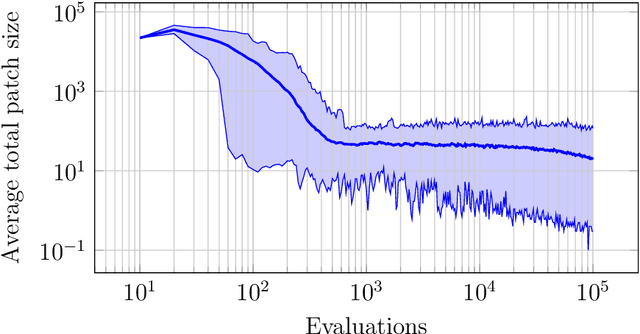
In many applications of evolutionary algorithms the computational cost of applying operators and storing populations is comparable to the cost of fitness evaluation. Furthermore, by knowing what exactly has changed in an individual by an operator, it is possible to recompute fitness value much more efficiently than from scratch. The associated time and memory improvements have been available for simple evolutionary algorithms, few specific genetic algorithms and in the context of gray-box optimization, but not for all algorithms, and the main reason is that it is difficult to achieve in algorithms using large arbitrarily structured populations. This paper makes a first step towards improving this situation. We show that storing the population as a minimum spanning tree, where vertices correspond to individuals but only contain meta-information about them, and edges store structural differences, or patches, between the individuals, is a viable alternative to the straightforward implementation. Our experiments suggest that significant, even asymptotic, improvements -- including execution of crossover operators! -- can be achieved in terms of both memory usage and computational costs.
Improving Zero-Shot Text Matching for Financial Auditing with Large Language Models
Aug 14, 2023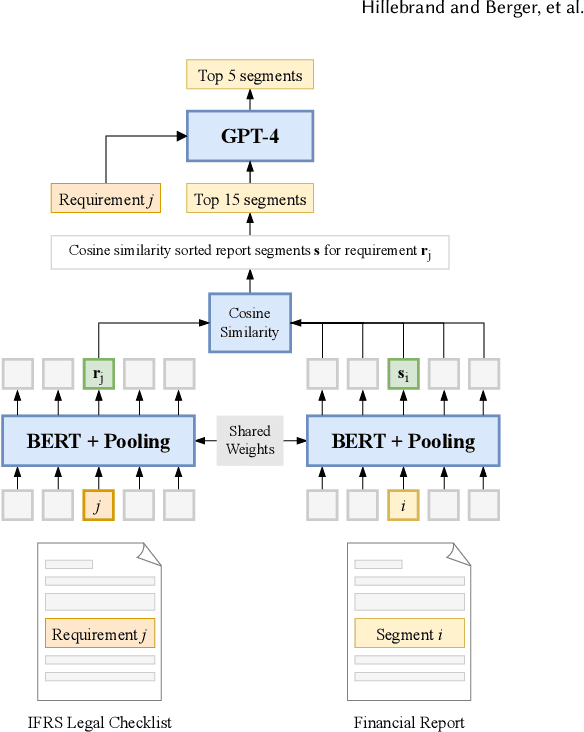

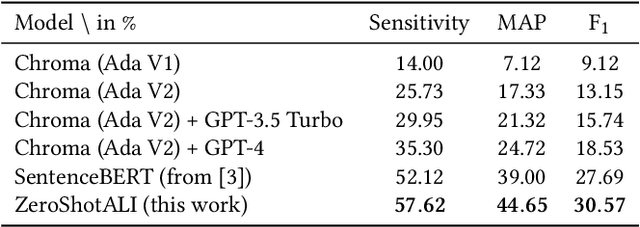
Auditing financial documents is a very tedious and time-consuming process. As of today, it can already be simplified by employing AI-based solutions to recommend relevant text passages from a report for each legal requirement of rigorous accounting standards. However, these methods need to be fine-tuned regularly, and they require abundant annotated data, which is often lacking in industrial environments. Hence, we present ZeroShotALI, a novel recommender system that leverages a state-of-the-art large language model (LLM) in conjunction with a domain-specifically optimized transformer-based text-matching solution. We find that a two-step approach of first retrieving a number of best matching document sections per legal requirement with a custom BERT-based model and second filtering these selections using an LLM yields significant performance improvements over existing approaches.
Generating Individual Trajectories Using GPT-2 Trained from Scratch on Encoded Spatiotemporal Data
Aug 14, 2023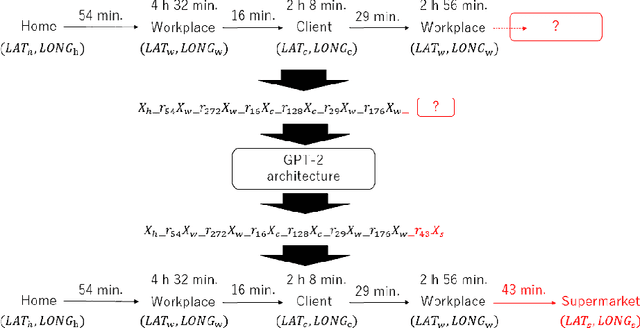

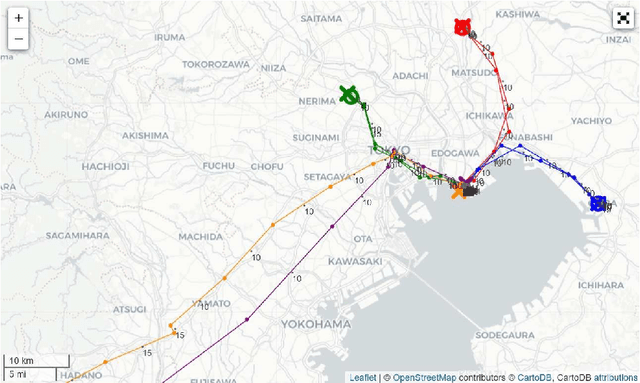
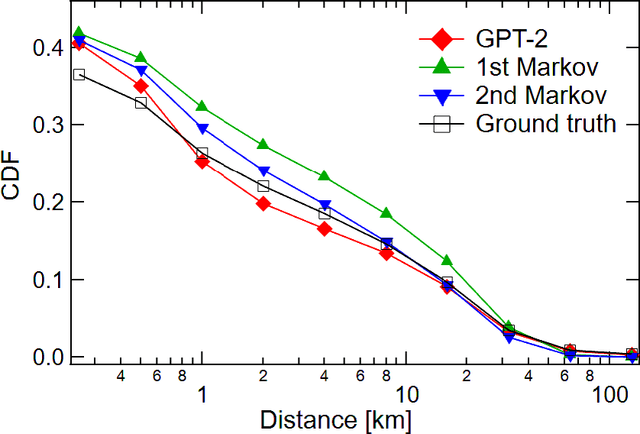
Following Mizuno, Fujimoto, and Ishikawa's research (Front. Phys. 2022), we transpose geographical coordinates expressed in latitude and longitude into distinctive location tokens that embody positions across varied spatial scales. We encapsulate an individual daily trajectory as a sequence of tokens by adding unique time interval tokens to the location tokens. Using the architecture of an autoregressive language model, GPT-2, this sequence of tokens is trained from scratch, allowing us to construct a deep learning model that sequentially generates an individual daily trajectory. Environmental factors such as meteorological conditions and individual attributes such as gender and age are symbolized by unique special tokens, and by training these tokens and trajectories on the GPT-2 architecture, we can generate trajectories that are influenced by both environmental factors and individual attributes.