 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An O.D.E. Framework of Distributed TD-Learning for Networked Multi-Agent Markov Decision Processes
Aug 17, 2023
The primary objective of this paper is to investigate distributed ordinary differential equation (ODE) and distributed temporal difference (TD) learning algorithms for networked multi-agent Markov decision problems (MAMDPs). In our study, we adopt a distributed multi-agent framework where individual agents have access only to their own rewards, lacking insights into the rewards of other agents. Additionally, each agent has the ability to share its parameters with neighboring agents through a communication network, represented by a graph. Our contributions can be summarized in two key points: 1) We introduce novel distributed ODEs, inspired by the averaging consensus method in the continuous-time domain. The convergence of the ODEs is assessed through control theory perspectives. 2) Building upon the aforementioned ODEs, we devise new distributed TD-learning algorithms. A standout feature of one of our proposed distributed ODEs is its incorporation of two independent dynamic systems, each with a distinct role. This characteristic sets the stage for a novel distributed TD-learning strategy, the convergence of which can potentially be established using Borkar-Meyn theorem.
MIPS-Fusion: Multi-Implicit-Submaps for Scalable and Robust Online Neural RGB-D Reconstruction
Aug 17, 2023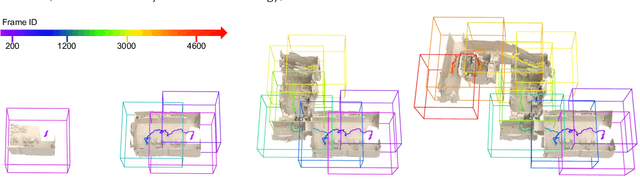
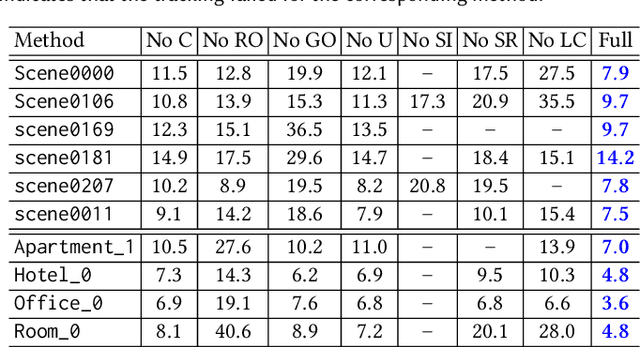
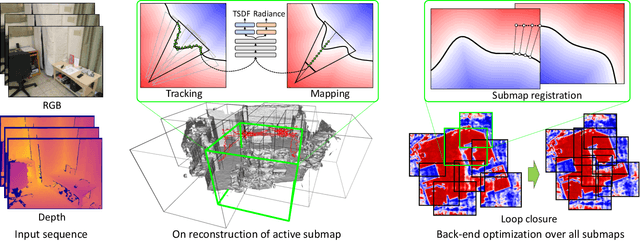
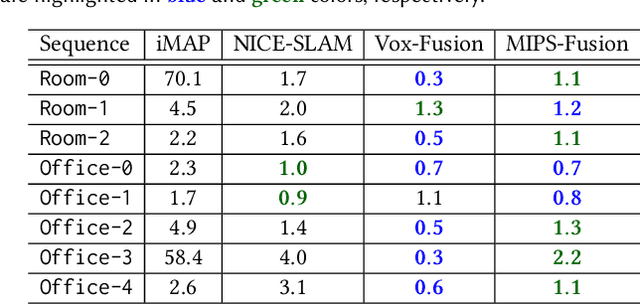
We introduce MIPS-Fusion, a robust and scalable online RGB-D reconstruction method based on a novel neural implicit representation -- multi-implicit-submap. Different from existing neural RGB-D reconstruction methods lacking either flexibility with a single neural map or scalability due to extra storage of feature grids, we propose a pure neural representation tackling both difficulties with a divide-and-conquer design. In our method, neural submaps are incrementally allocated alongside the scanning trajectory and efficiently learned with local neural bundle adjustments. The submaps can be refined individually in a back-end optimization and optimized jointly to realize submap-level loop closure. Meanwhile, we propose a hybrid tracking approach combining randomized and gradient-based pose optimizations. For the first time, randomized optimization is made possible in neural tracking with several key designs to the learning process, enabling efficient and robust tracking even under fast camera motions. The extensive evaluation demonstrates that our method attains higher reconstruction quality than the state of the arts for large-scale scenes and under fast camera motions.
Polynomial Bounds for Learning Noisy Optical Physical Unclonable Functions and Connections to Learning With Errors
Aug 17, 2023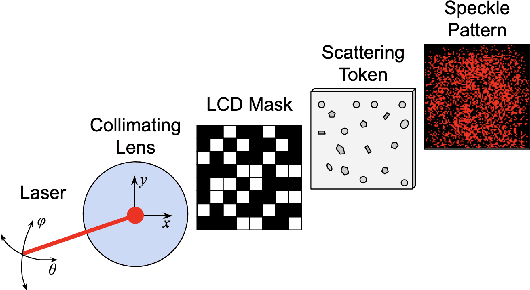

It is shown that a class of optical physical unclonable functions (PUFs) can be learned to arbitrary precision with arbitrarily high probability, even in the presence of noise, given access to polynomially many challenge-response pairs and polynomially bounded computational power, under mild assumptions about the distributions of the noise and challenge vectors. This extends the results of Rh\"uramir et al. (2013), who showed a subset of this class of PUFs to be learnable in polynomial time in the absence of noise, under the assumption that the optics of the PUF were either linear or had negligible nonlinear effects. We derive polynomial bounds for the required number of samples and the computational complexity of a linear regression algorithm, based on size parameters of the PUF, the distributions of the challenge and noise vectors, and the probability and accuracy of the regression algorithm, with a similar analysis to one done by Bootle et al. (2018), who demonstrated a learning attack on a poorly implemented version of the Learning With Errors problem.
A polynomial-time iterative algorithm for random graph matching with non-vanishing correlation
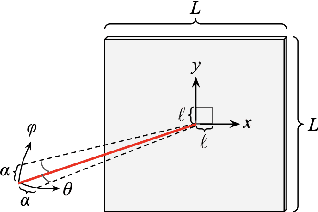
Jun 01, 2023
We propose an efficient algorithm for matching two correlated Erd\H{o}s--R\'enyi graphs with $n$ vertices whose edges are correlated through a latent vertex correspondence. When the edge density $q= n^{- \alpha+o(1)}$ for a constant $\alpha \in [0,1)$, we show that our algorithm has polynomial running time and succeeds to recover the latent matching as long as the edge correlation is non-vanishing. This is closely related to our previous work on a polynomial-time algorithm that matches two Gaussian Wigner matrices with non-vanishing correlation, and provides the first polynomial-time random graph matching algorithm (regardless of the regime of $q$) when the edge correlation is below the square root of the Otter's constant (which is $\approx 0.338$).
A GPS Alternative using Electrical Transmission Grids as Precision Timing Networks
Jul 26, 2023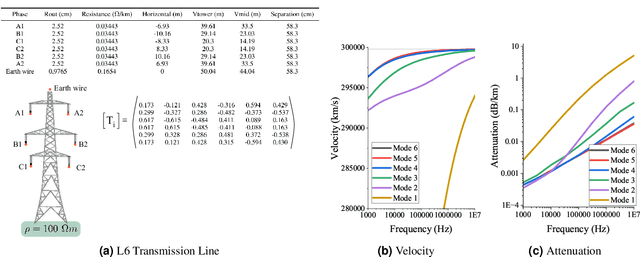
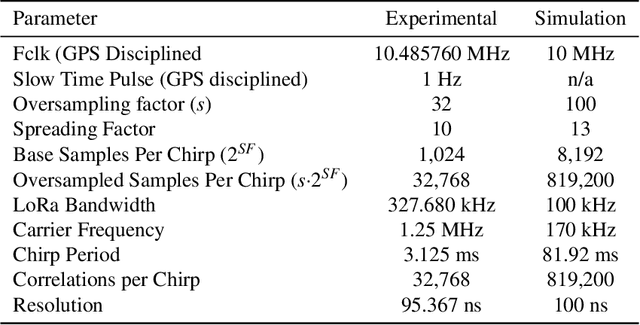
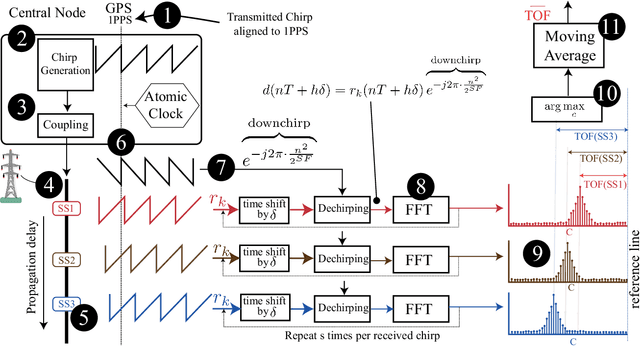
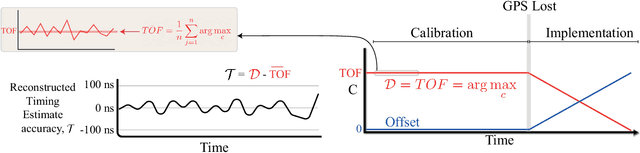
It is widely recognised that over-reliance on GNSS (e.g GPS) for time synchronisation represents an acute threat to modern society, and a diversity of alternatives are required to mitigate the threat of an outage. This paper proposes a GNSS alternative using time dissemination over national scale transmission or distribution networks. The method utilises the same frequency bandwidth and coupling technology as established power line carrier technology in conjunction with modern chirp Spread Spectrum modulation. The basis of the method is the transmission of a time synchronised chirp from a central substation. During GNSS operation, all substations can estimate the time of flight by correlating the received chirp with a time-synchronised local copy. During GNSS outage, time sychronisation to the central substation is maintained by correcting for the precalculated time of flight. It is shown that recent advances in chirp spread spectrum allow for a computationally efficient algorithm with the capacity to compute hundreds of thousand of chirp correlations every second, improving the resolution of the system. ATP-EMTP simulations of the method on large transmission networks demonstrate sub-$\mu$s timing accuracy even in the presence of low SNR and impulsive noise. An FPGA based prototype is developed and experimental testing also demonstrates sub-$\mu$s accuracy for time dissemination over a distance of 700 m. Averaging over time allows operation down to -20 dB, which could extend the range of the system to a national scale.
Sensing as a Service in 6G Perceptive Mobile Networks: Architecture, Advances, and the Road Ahead
Aug 16, 2023Sensing-as-a-service is anticipated to be the core feature of 6G perceptive mobile networks (PMN), where high-precision real-time sensing will become an inherent capability rather than being an auxiliary function as before. With the proliferation of wireless connected devices, resource allocation in terms of the users' specific quality-of-service (QoS) requirements plays a pivotal role to enhance the interference management ability and resource utilization efficiency. In this article, we comprehensively introduce the concept of sensing service in PMN, including the types of tasks, the distinctions/advantages compared to conventional networks, and the definitions of sensing QoS. Subsequently, we provide a unified RA framework in sensing-centric PMN and elaborate on the unique challenges. Furthermore, we present a typical case study named "communication-assisted sensing" and evaluate the performance trade-off between sensing and communication procedure. Finally, we shed light on several open problems and opportunities deserving further investigation in the future.
Fast Training of NMT Model with Data Sorting
Aug 16, 2023The Transformer model has revolutionized Natural Language Processing tasks such as Neural Machine Translation, and many efforts have been made to study the Transformer architecture, which increased its efficiency and accuracy. One potential area for improvement is to address the computation of empty tokens that the Transformer computes only to discard them later, leading to an unnecessary computational burden. To tackle this, we propose an algorithm that sorts translation sentence pairs based on their length before batching, minimizing the waste of computing power. Since the amount of sorting could violate the independent and identically distributed (i.i.d) data assumption, we sort the data partially. In experiments, we apply the proposed method to English-Korean and English-Luganda language pairs for machine translation and show that there are gains in computational time while maintaining the performance. Our method is independent of architectures, so that it can be easily integrated into any training process with flexible data lengths.
Multi-Instance Adversarial Attack on GNN-Based Malicious Domain Detection
Aug 22, 2023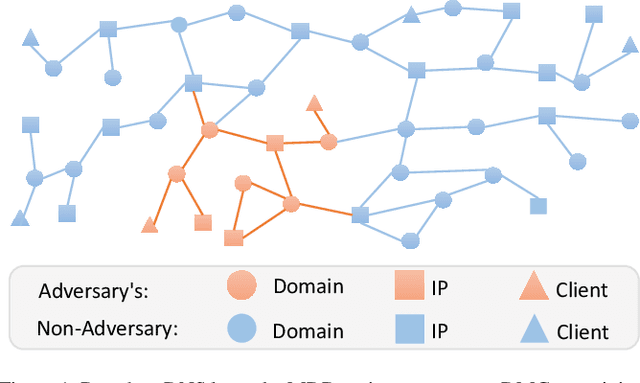

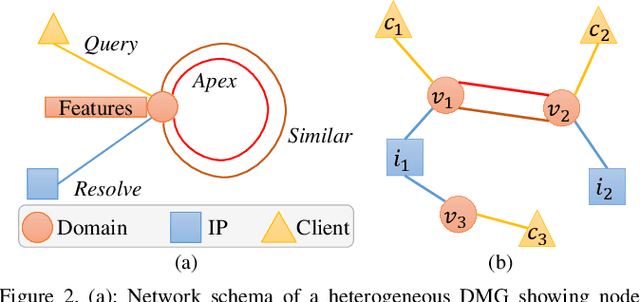
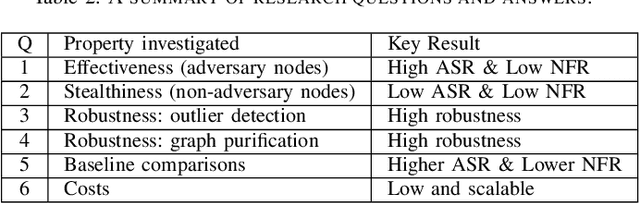
Malicious domain detection (MDD) is an open security challenge that aims to detect if an Internet domain is associated with cyber-attacks. Among many approaches to this problem, graph neural networks (GNNs) are deemed highly effective. GNN-based MDD uses DNS logs to represent Internet domains as nodes in a maliciousness graph (DMG) and trains a GNN to infer their maliciousness by leveraging identified malicious domains. Since this method relies on accessible DNS logs to construct DMGs, it exposes a vulnerability for adversaries to manipulate their domain nodes' features and connections within DMGs. Existing research mainly concentrates on threat models that manipulate individual attacker nodes. However, adversaries commonly generate multiple domains to achieve their goals economically and avoid detection. Their objective is to evade discovery across as many domains as feasible. In this work, we call the attack that manipulates several nodes in the DMG concurrently a multi-instance evasion attack. We present theoretical and empirical evidence that the existing single-instance evasion techniques for are inadequate to launch multi-instance evasion attacks against GNN-based MDDs. Therefore, we introduce MintA, an inference-time multi-instance adversarial attack on GNN-based MDDs. MintA enhances node and neighborhood evasiveness through optimized perturbations and operates successfully with only black-box access to the target model, eliminating the need for knowledge about the model's specifics or non-adversary nodes. We formulate an optimization challenge for MintA, achieving an approximate solution. Evaluating MintA on a leading GNN-based MDD technique with real-world data showcases an attack success rate exceeding 80%. These findings act as a warning for security experts, underscoring GNN-based MDDs' susceptibility to practical attacks that can undermine their effectiveness and benefits.
I/O Burst Prediction for HPC Clusters using Darshan Logs
Aug 20, 2023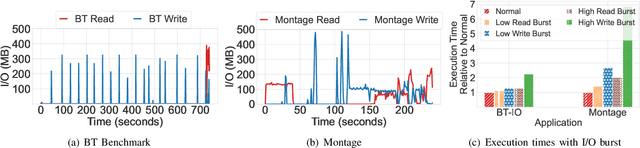
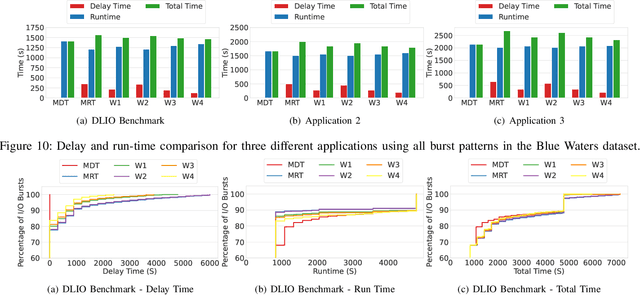
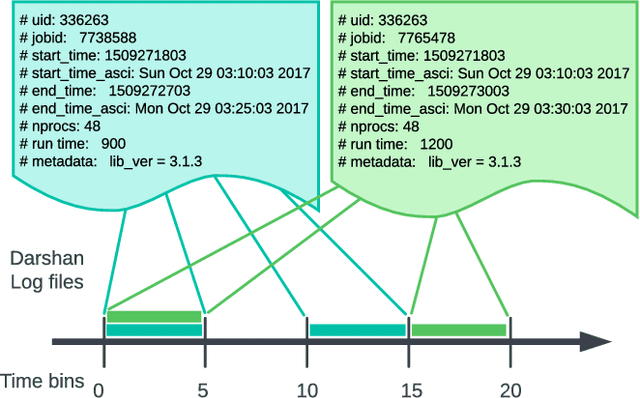
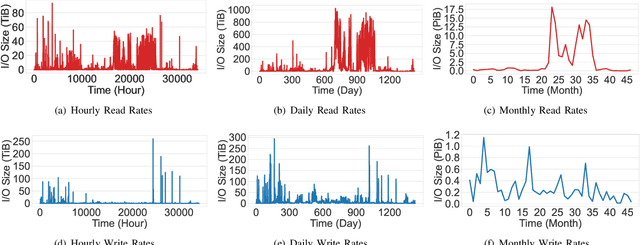
Understanding cluster-wide I/O patterns of large-scale HPC clusters is essential to minimize the occurrence and impact of I/O interference. Yet, most previous work in this area focused on monitoring and predicting task and node-level I/O burst events. This paper analyzes Darshan reports from three supercomputers to extract system-level read and write I/O rates in five minutes intervals. We observe significant (over 100x) fluctuations in read and write I/O rates in all three clusters. We then train machine learning models to estimate the occurrence of system-level I/O bursts 5 - 120 minutes ahead. Evaluation results show that we can predict I/O bursts with more than 90% accuracy (F-1 score) five minutes ahead and more than 87% accuracy two hours ahead. We also show that the ML models attain more than 70% accuracy when estimating the degree of the I/O burst. We believe that high-accuracy predictions of I/O bursts can be used in multiple ways, such as postponing delay-tolerant I/O operations (e.g., checkpointing), pausing nonessential applications (e.g., file system scrubbers), and devising I/O-aware job scheduling methods. To validate this claim, we simulated a burst-aware job scheduler that can postpone the start time of applications to avoid I/O bursts. We show that the burst-aware job scheduling can lead to an up to 5x decrease in application runtime.
Adversarial Collaborative Filtering for Free
Aug 20, 2023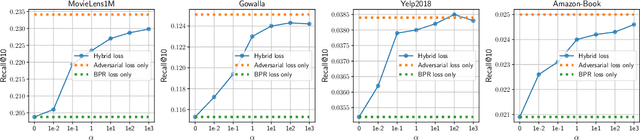
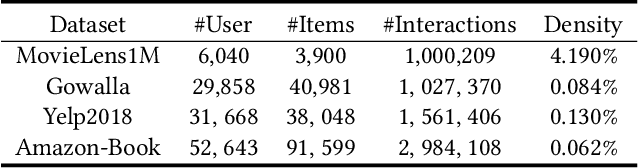
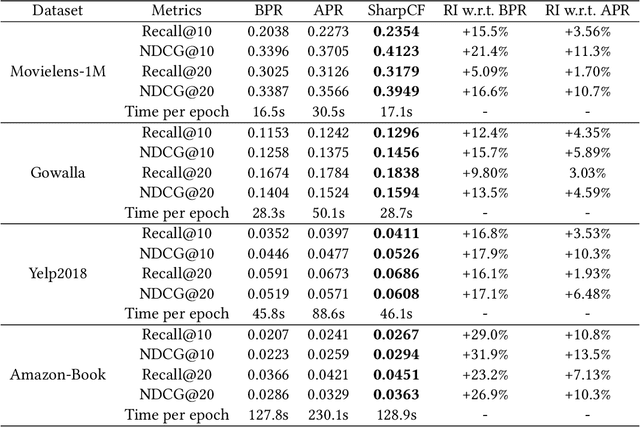
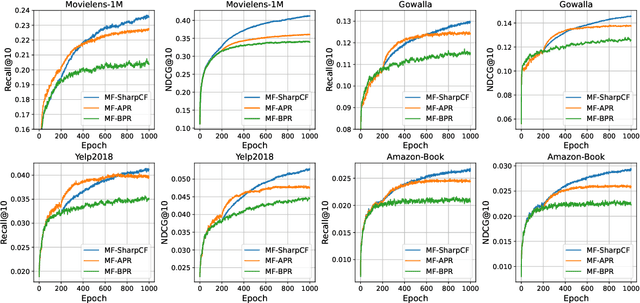
Collaborative Filtering (CF) has been successfully used to help users discover the items of interest. Nevertheless, existing CF methods suffer from noisy data issue, which negatively impacts the quality of recommendation. To tackle this problem, many prior studies leverage adversarial learning to regularize the representations of users/items, which improves both generalizability and robustness. Those methods often learn adversarial perturbations and model parameters under min-max optimization framework. However, there still have two major drawbacks: 1) Existing methods lack theoretical guarantees of why adding perturbations improve the model generalizability and robustness; 2) Solving min-max optimization is time-consuming. In addition to updating the model parameters, each iteration requires additional computations to update the perturbations, making them not scalable for industry-scale datasets. In this paper, we present Sharpness-aware Collaborative Filtering (SharpCF), a simple yet effective method that conducts adversarial training without extra computational cost over the base optimizer. To achieve this goal, we first revisit the existing adversarial collaborative filtering and discuss its connection with recent Sharpness-aware Minimization. This analysis shows that adversarial training actually seeks model parameters that lie in neighborhoods around the optimal model parameters having uniformly low loss values, resulting in better generalizability. To reduce the computational overhead, SharpCF introduces a novel trajectory loss to measure the alignment between current weights and past weights. Experimental results on real-world datasets demonstrate that our SharpCF achieves superior performance with almost zero additional computational cost comparing to adversarial training.