 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Decoding Natural Images from EEG for Object Recognition
Aug 25, 2023
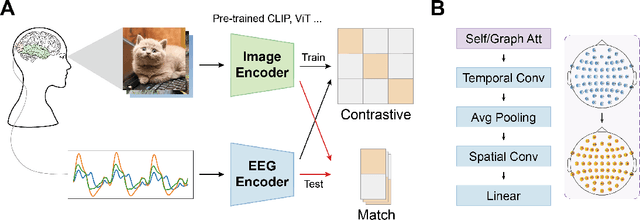

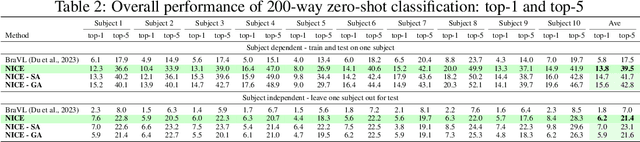
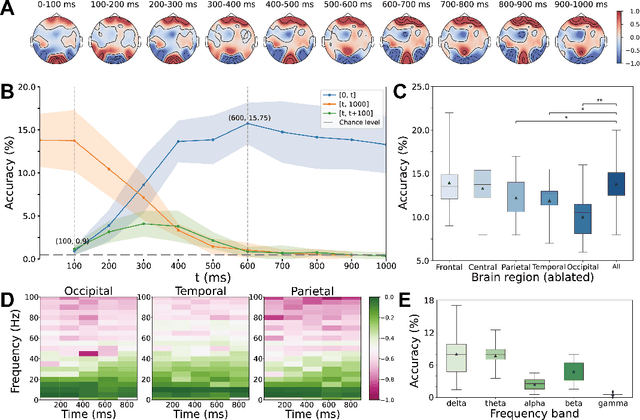
Electroencephalogram (EEG) is a brain signal known for its high time resolution and moderate signal-to-noise ratio. Whether natural images can be decoded from EEG has been a hot issue recently. In this paper, we propose a self-supervised framework to learn image representations from EEG signals. Specifically, image and EEG encoders are first used to extract features from paired image stimuli and EEG responses. Then we employ contrastive learning to align these two modalities by constraining their similarity. Additionally, we introduce two plug-in-play modules that capture spatial correlations before the EEG encoder. Our approach achieves state-of-the-art results on the most extensive EEG-image dataset, with a top-1 accuracy of 15.6% and a top-5 accuracy of 42.8% in 200-way zero-shot tasks. More importantly, extensive experiments analyzing the temporal, spatial, spectral, and semantic aspects of EEG signals demonstrate good biological plausibility. These results offer valuable insights for neural decoding and real-world applications of brain-computer interfaces. The code will be released on https://github.com/eeyhsong/NICE-EEG.
Context-Aware Composition of Agent Policies by Markov Decision Process Entity Embeddings and Agent Ensembles
Aug 30, 2023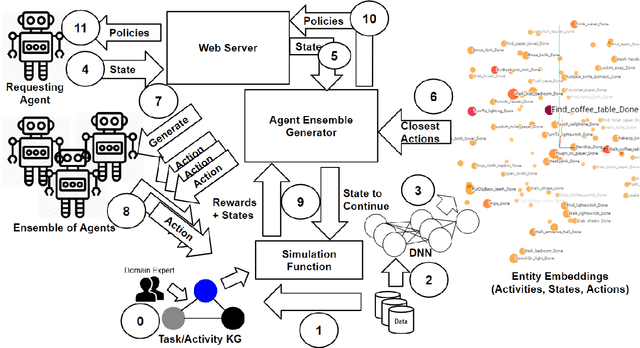
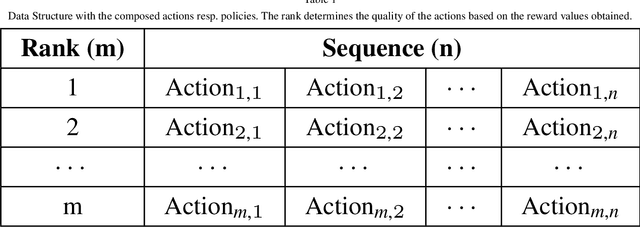
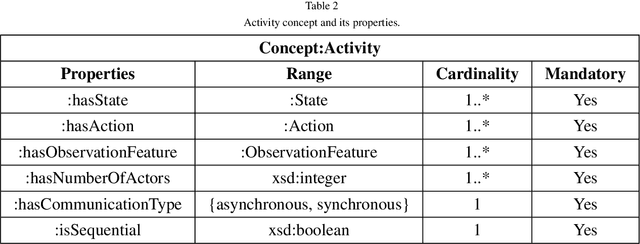
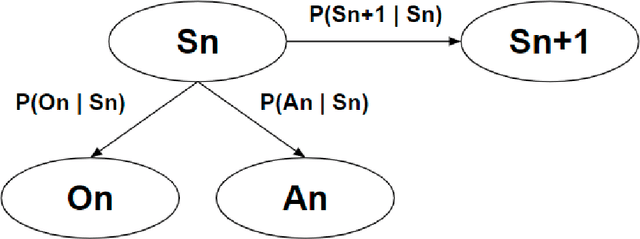
Computational agents support humans in many areas of life and are therefore found in heterogeneous contexts. This means they operate in rapidly changing environments and can be confronted with huge state and action spaces. In order to perform services and carry out activities in a goal-oriented manner, agents require prior knowledge and therefore have to develop and pursue context-dependent policies. However, prescribing policies in advance is limited and inflexible, especially in dynamically changing environments. Moreover, the context of an agent determines its choice of actions. Since the environments can be stochastic and complex in terms of the number of states and feasible actions, activities are usually modelled in a simplified way by Markov decision processes so that, e.g., agents with reinforcement learning are able to learn policies, that help to capture the context and act accordingly to optimally perform activities. However, training policies for all possible contexts using reinforcement learning is time-consuming. A requirement and challenge for agents is to learn strategies quickly and respond immediately in cross-context environments and applications, e.g., the Internet, service robotics, cyber-physical systems. In this work, we propose a novel simulation-based approach that enables a) the representation of heterogeneous contexts through knowledge graphs and entity embeddings and b) the context-aware composition of policies on demand by ensembles of agents running in parallel. The evaluation we conducted with the "Virtual Home" dataset indicates that agents with a need to switch seamlessly between different contexts, can request on-demand composed policies that lead to the successful completion of context-appropriate activities without having to learn these policies in lengthy training steps and episodes, in contrast to agents that use reinforcement learning.
Acquiring Qualitative Explainable Graphs for Automated Driving Scene Interpretation
Aug 24, 2023The future of automated driving (AD) is rooted in the development of robust, fair and explainable artificial intelligence methods. Upon request, automated vehicles must be able to explain their decisions to the driver and the car passengers, to the pedestrians and other vulnerable road users and potentially to external auditors in case of accidents. However, nowadays, most explainable methods still rely on quantitative analysis of the AD scene representations captured by multiple sensors. This paper proposes a novel representation of AD scenes, called Qualitative eXplainable Graph (QXG), dedicated to qualitative spatiotemporal reasoning of long-term scenes. The construction of this graph exploits the recent Qualitative Constraint Acquisition paradigm. Our experimental results on NuScenes, an open real-world multi-modal dataset, show that the qualitative eXplainable graph of an AD scene composed of 40 frames can be computed in real-time and light in space storage which makes it a potentially interesting tool for improved and more trustworthy perception and control processes in AD.
Video Recommendation Using Social Network Analysis and User Viewing Patterns
Aug 24, 2023
With the meteoric rise of video-on-demand (VOD) platforms, users face the challenge of sifting through an expansive sea of content to uncover shows that closely match their preferences. To address this information overload dilemma, VOD services have increasingly incorporated recommender systems powered by algorithms that analyze user behavior and suggest personalized content. However, a majority of existing recommender systems depend on explicit user feedback in the form of ratings and reviews, which can be difficult and time-consuming to collect at scale. This presents a key research gap, as leveraging users' implicit feedback patterns could provide an alternative avenue for building effective video recommendation models, circumventing the need for explicit ratings. However, prior literature lacks sufficient exploration into implicit feedback-based recommender systems, especially in the context of modeling video viewing behavior. Therefore, this paper aims to bridge this research gap by proposing a novel video recommendation technique that relies solely on users' implicit feedback in the form of their content viewing percentages.
Beyond Document Page Classification: Design, Datasets, and Challenges
Aug 24, 2023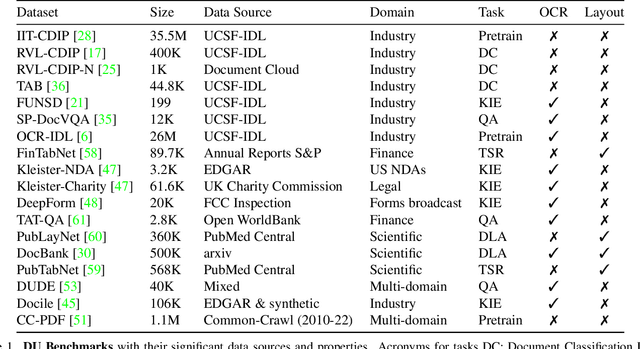
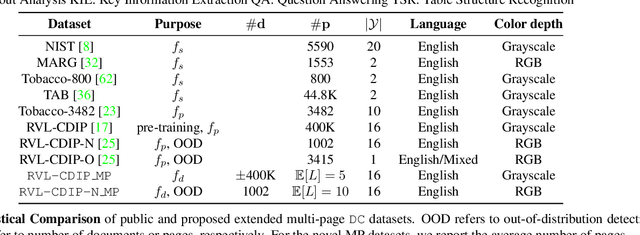

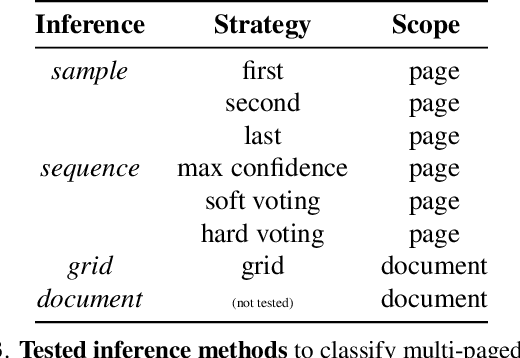
This paper highlights the need to bring document classification benchmarking closer to real-world applications, both in the nature of data tested ($X$: multi-channel, multi-paged, multi-industry; $Y$: class distributions and label set variety) and in classification tasks considered ($f$: multi-page document, page stream, and document bundle classification, ...). We identify the lack of public multi-page document classification datasets, formalize different classification tasks arising in application scenarios, and motivate the value of targeting efficient multi-page document representations. An experimental study on proposed multi-page document classification datasets demonstrates that current benchmarks have become irrelevant and need to be updated to evaluate complete documents, as they naturally occur in practice. This reality check also calls for more mature evaluation methodologies, covering calibration evaluation, inference complexity (time-memory), and a range of realistic distribution shifts (e.g., born-digital vs. scanning noise, shifting page order). Our study ends on a hopeful note by recommending concrete avenues for future improvements.}
Machine Learning aided Computer Architecture Design for CNN Inferencing Systems
Aug 10, 2023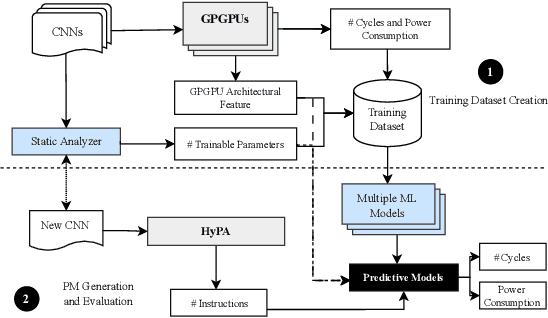
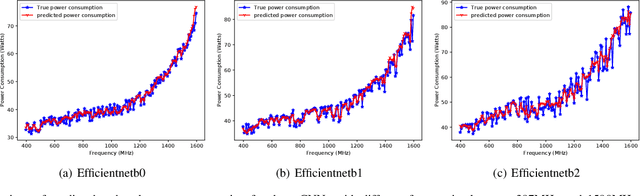
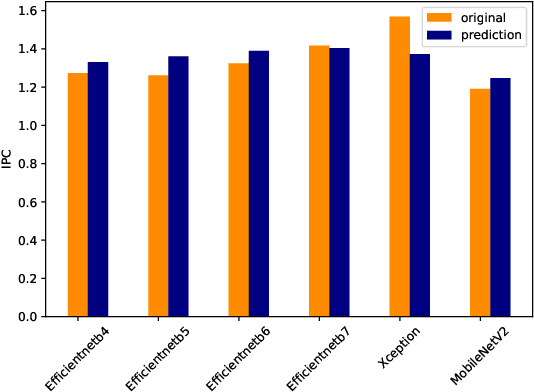
Efficient and timely calculations of Machine Learning (ML) algorithms are essential for emerging technologies like autonomous driving, the Internet of Things (IoT), and edge computing. One of the primary ML algorithms used in such systems is Convolutional Neural Networks (CNNs), which demand high computational resources. This requirement has led to the use of ML accelerators like GPGPUs to meet design constraints. However, selecting the most suitable accelerator involves Design Space Exploration (DSE), a process that is usually time-consuming and requires significant manual effort. Our work presents approaches to expedite the DSE process by identifying the most appropriate GPGPU for CNN inferencing systems. We have developed a quick and precise technique for forecasting the power and performance of CNNs during inference, with a MAPE of 5.03% and 5.94%, respectively. Our approach empowers computer architects to estimate power and performance in the early stages of development, reducing the necessity for numerous prototypes. This saves time and money while also improving the time-to-market period.
CoMIX: A Multi-agent Reinforcement Learning Training Architecture for Efficient Decentralized Coordination and Independent Decision Making
Aug 21, 2023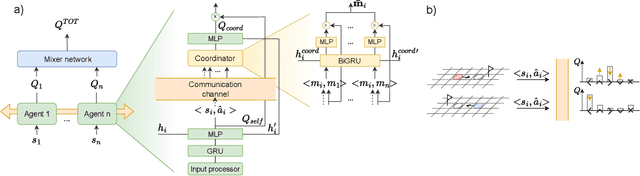
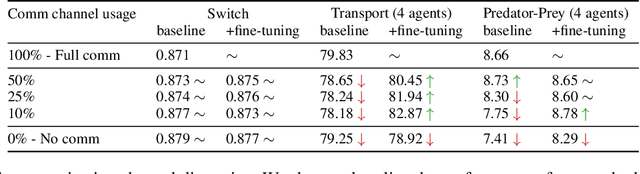
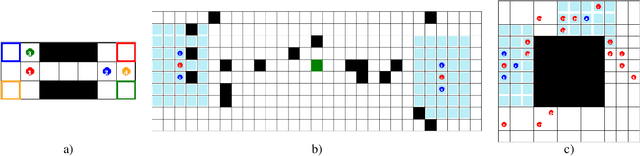
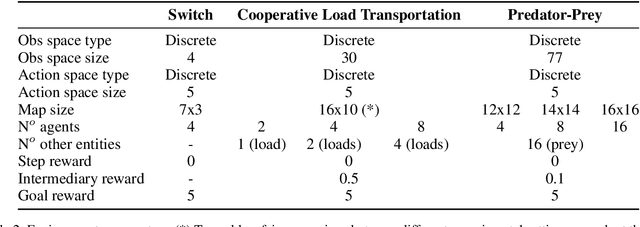
Robust coordination skills enable agents to operate cohesively in shared environments, together towards a common goal and, ideally, individually without hindering each other's progress. To this end, this paper presents Coordinated QMIX (CoMIX), a novel training framework for decentralized agents that enables emergent coordination through flexible policies, allowing at the same time independent decision-making at individual level. CoMIX models selfish and collaborative behavior as incremental steps in each agent's decision process. This allows agents to dynamically adapt their behavior to different situations balancing independence and collaboration. Experiments using a variety of simulation environments demonstrate that CoMIX outperforms baselines on collaborative tasks. The results validate our incremental policy approach as effective technique for improving coordination in multi-agent systems.
Filling time-series gaps using image techniques: Multidimensional context autoencoder approach for building energy data imputation
Jul 13, 2023Building energy prediction and management has become increasingly important in recent decades, driven by the growth of Internet of Things (IoT) devices and the availability of more energy data. However, energy data is often collected from multiple sources and can be incomplete or inconsistent, which can hinder accurate predictions and management of energy systems and limit the usefulness of the data for decision-making and research. To address this issue, past studies have focused on imputing missing gaps in energy data, including random and continuous gaps. One of the main challenges in this area is the lack of validation on a benchmark dataset with various building and meter types, making it difficult to accurately evaluate the performance of different imputation methods. Another challenge is the lack of application of state-of-the-art imputation methods for missing gaps in energy data. Contemporary image-inpainting methods, such as Partial Convolution (PConv), have been widely used in the computer vision domain and have demonstrated their effectiveness in dealing with complex missing patterns. To study whether energy data imputation can benefit from the image-based deep learning method, this study compared PConv, Convolutional neural networks (CNNs), and weekly persistence method using one of the biggest publicly available whole building energy datasets, consisting of 1479 power meters worldwide, as the benchmark. The results show that, compared to the CNN with the raw time series (1D-CNN) and the weekly persistence method, neural network models with reshaped energy data with two dimensions reduced the Mean Squared Error (MSE) by 10% to 30%. The advanced deep learning method, Partial convolution (PConv), has further reduced the MSE by 20-30% than 2D-CNN and stands out among all models.
Deep learning-based flow disaggregation for hydropower plant management
Aug 11, 2023High temporal resolution data is a vital resource for hydropower plant management. Currently, only daily resolution data are available for most of Norwegian hydropower plant, however, to achieve more accurate management, sub-daily resolution data are often required. To deal with the wide absence of sub-daily data, time series disaggregation is a potential tool. In this study, we proposed a time series disaggregation model based on deep learning, the model is tested using flow data from a Norwegian flow station, to disaggregate the daily flow into hourly flow. Preliminary results show some promising aspects for the proposed model.
A Real-time Human Pose Estimation Approach for Optimal Sensor Placement in Sensor-based Human Activity Recognition
Jul 06, 2023
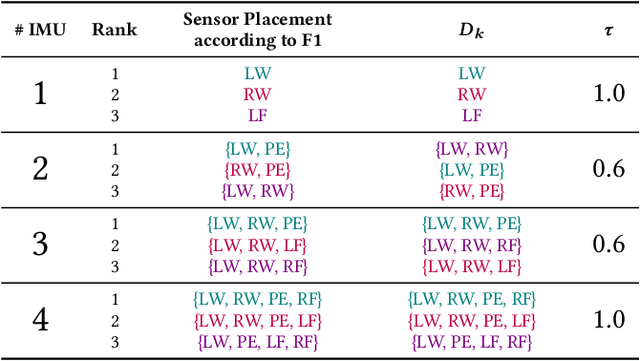

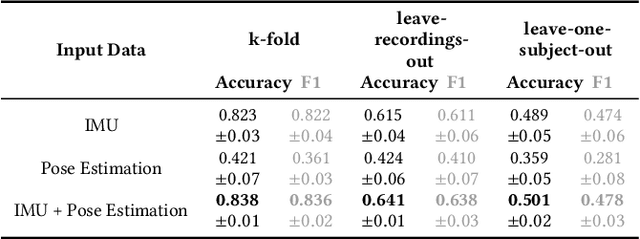
Sensor-based Human Activity Recognition facilitates unobtrusive monitoring of human movements. However, determining the most effective sensor placement for optimal classification performance remains challenging. This paper introduces a novel methodology to resolve this issue, using real-time 2D pose estimations derived from video recordings of target activities. The derived skeleton data provides a unique strategy for identifying the optimal sensor location. We validate our approach through a feasibility study, applying inertial sensors to monitor 13 different activities across ten subjects. Our findings indicate that the vision-based method for sensor placement offers comparable results to the conventional deep learning approach, demonstrating its efficacy. This research significantly advances the field of Human Activity Recognition by providing a lightweight, on-device solution for determining the optimal sensor placement, thereby enhancing data anonymization and supporting a multimodal classification approach.