 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Reinforcement Learning for Uplink Scheduling in NOMA-URLLC Networks
Aug 28, 2023
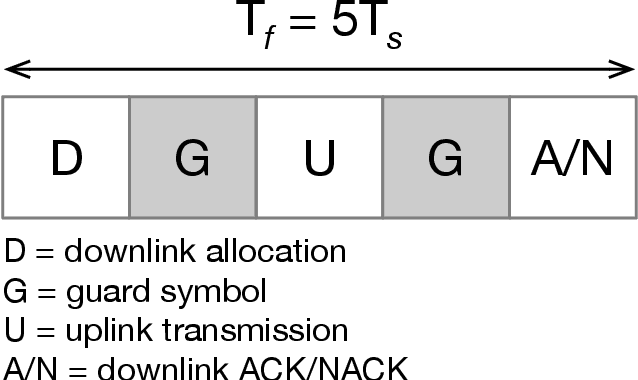
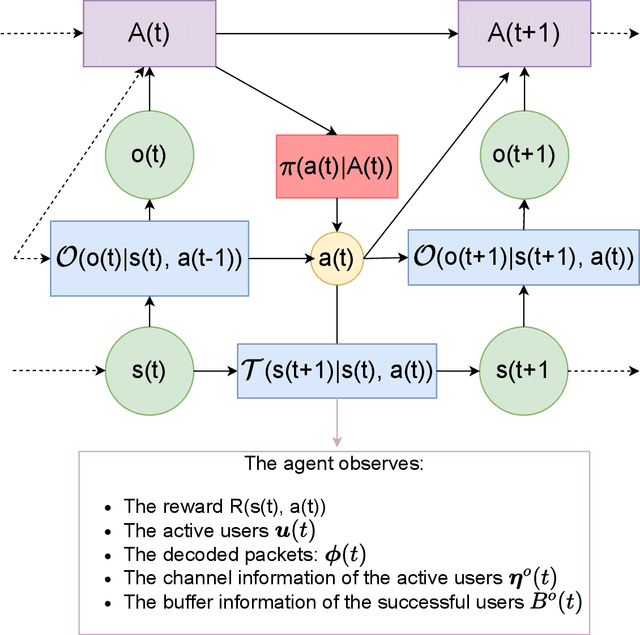
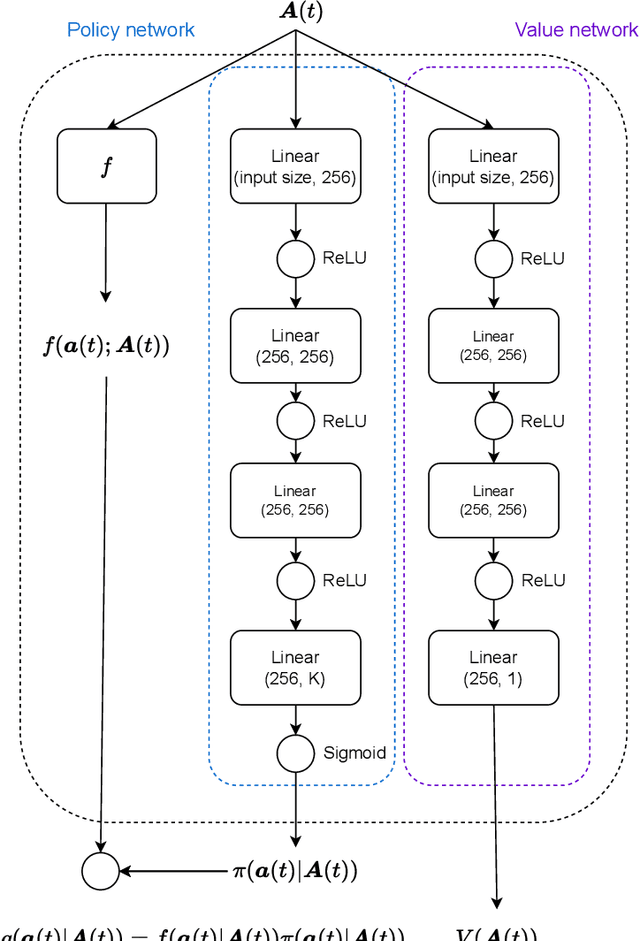
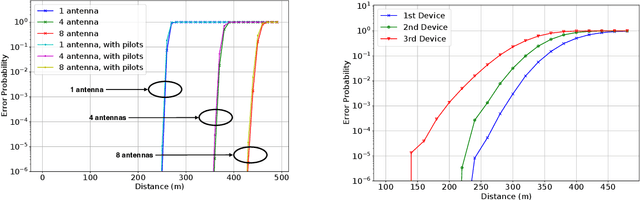
This article addresses the problem of Ultra Reliable Low Latency Communications (URLLC) in wireless networks, a framework with particularly stringent constraints imposed by many Internet of Things (IoT) applications from diverse sectors. We propose a novel Deep Reinforcement Learning (DRL) scheduling algorithm, named NOMA-PPO, to solve the Non-Orthogonal Multiple Access (NOMA) uplink URLLC scheduling problem involving strict deadlines. The challenge of addressing uplink URLLC requirements in NOMA systems is related to the combinatorial complexity of the action space due to the possibility to schedule multiple devices, and to the partial observability constraint that we impose to our algorithm in order to meet the IoT communication constraints and be scalable. Our approach involves 1) formulating the NOMA-URLLC problem as a Partially Observable Markov Decision Process (POMDP) and the introduction of an agent state, serving as a sufficient statistic of past observations and actions, enabling a transformation of the POMDP into a Markov Decision Process (MDP); 2) adapting the Proximal Policy Optimization (PPO) algorithm to handle the combinatorial action space; 3) incorporating prior knowledge into the learning agent with the introduction of a Bayesian policy. Numerical results reveal that not only does our approach outperform traditional multiple access protocols and DRL benchmarks on 3GPP scenarios, but also proves to be robust under various channel and traffic configurations, efficiently exploiting inherent time correlations.
Extend Wave Function Collapse to Large-Scale Content Generation
Aug 14, 2023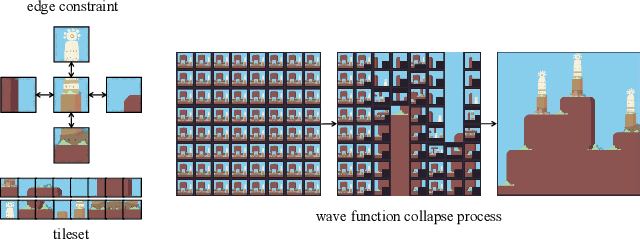
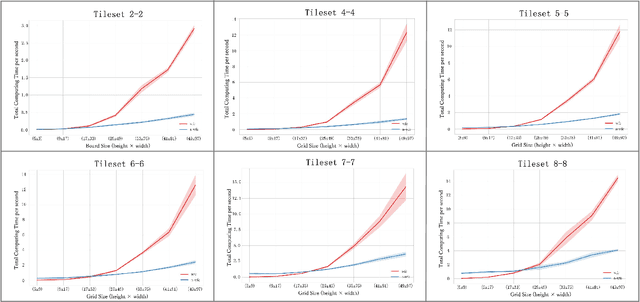
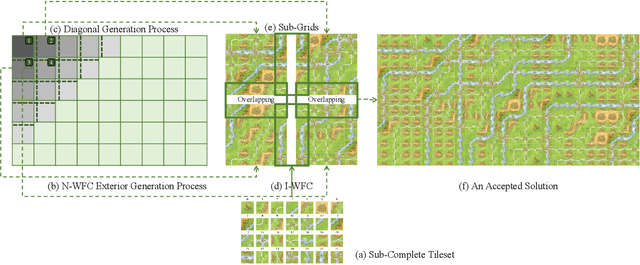
Wave Function Collapse (WFC) is a widely used tile-based algorithm in procedural content generation, including textures, objects, and scenes. However, the current WFC algorithm and related research lack the ability to generate commercialized large-scale or infinite content due to constraint conflict and time complexity costs. This paper proposes a Nested WFC (N-WFC) algorithm framework to reduce time complexity. To avoid conflict and backtracking problems, we offer a complete and sub-complete tileset preparation strategy, which requires only a small number of tiles to generate aperiodic and deterministic infinite content. We also introduce the weight-brush system that combines N-WFC and sub-complete tileset, proving its suitability for game design. Our contribution addresses WFC's challenge in massive content generation and provides a theoretical basis for implementing concrete games.
Tightest Admissible Shortest Path
Aug 15, 2023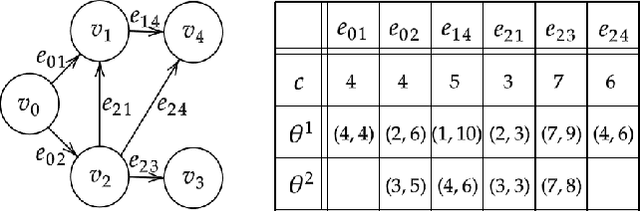

The shortest path problem in graphs is fundamental to AI. Nearly all variants of the problem and relevant algorithms that solve them ignore edge-weight computation time and its common relation to weight uncertainty. This implies that taking these factors into consideration can potentially lead to a performance boost in relevant applications. Recently, a generalized framework for weighted directed graphs was suggested, where edge-weight can be computed (estimated) multiple times, at increasing accuracy and run-time expense. We build on this framework to introduce the problem of finding the tightest admissible shortest path (TASP); a path with the tightest suboptimality bound on the optimal cost. This is a generalization of the shortest path problem to bounded uncertainty, where edge-weight uncertainty can be traded for computational cost. We present a complete algorithm for solving TASP, with guarantees on solution quality. Empirical evaluation supports the effectiveness of this approach.
Benchmarking Data Efficiency and Computational Efficiency of Temporal Action Localization Models
Aug 24, 2023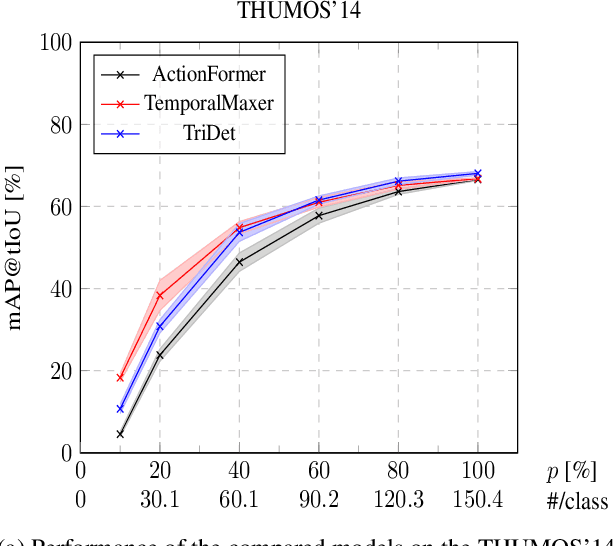
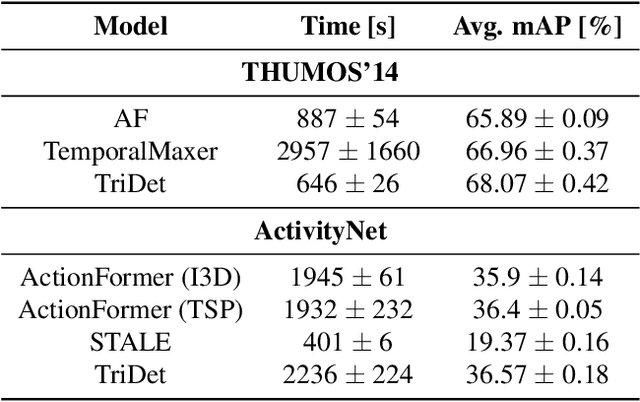
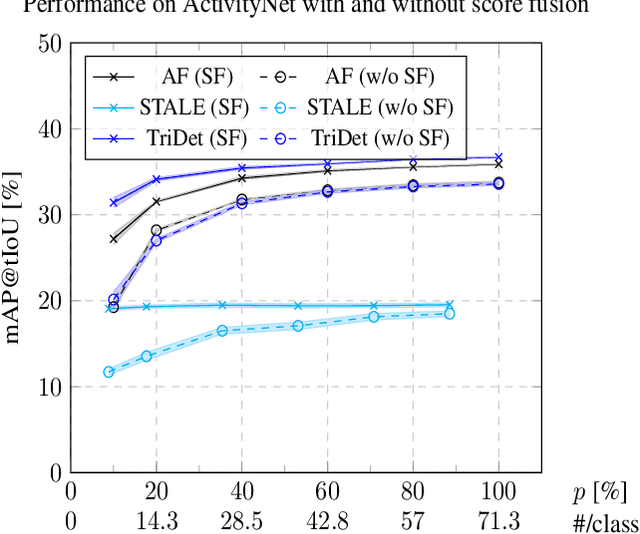
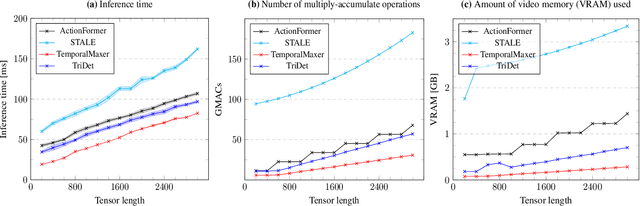
In temporal action localization, given an input video, the goal is to predict which actions it contains, where they begin, and where they end. Training and testing current state-of-the-art deep learning models requires access to large amounts of data and computational power. However, gathering such data is challenging and computational resources might be limited. This work explores and measures how current deep temporal action localization models perform in settings constrained by the amount of data or computational power. We measure data efficiency by training each model on a subset of the training set. We find that TemporalMaxer outperforms other models in data-limited settings. Furthermore, we recommend TriDet when training time is limited. To test the efficiency of the models during inference, we pass videos of different lengths through each model. We find that TemporalMaxer requires the least computational resources, likely due to its simple architecture.
Robot Pose Nowcasting: Forecast the Future to Improve the Present
Aug 24, 2023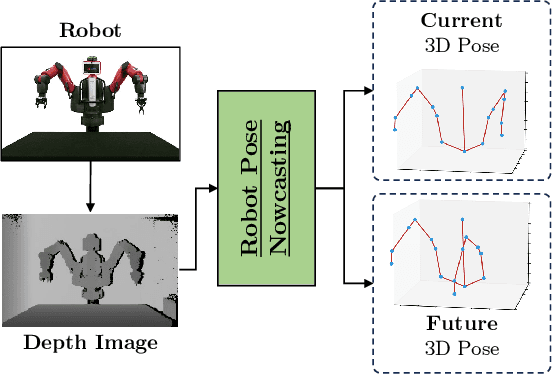
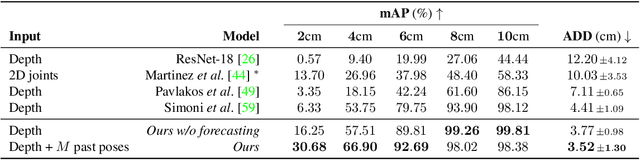
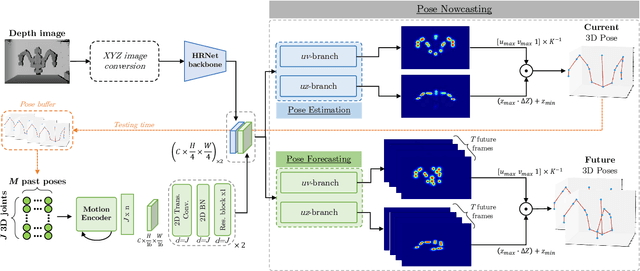
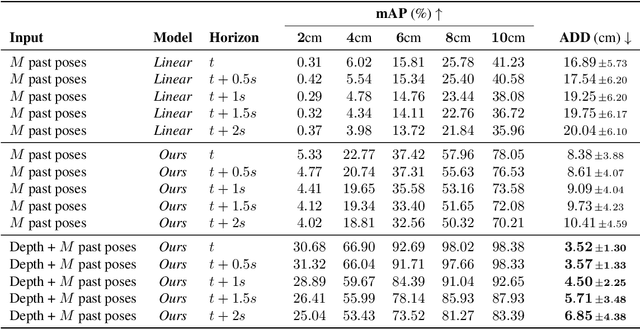
In recent years, the effective and safe collaboration between humans and machines has gained significant importance, particularly in the Industry 4.0 scenario. A critical prerequisite for realizing this collaborative paradigm is precisely understanding the robot's 3D pose within its environment. Therefore, in this paper, we introduce a novel vision-based system leveraging depth data to accurately establish the 3D locations of robotic joints. Specifically, we prove the ability of the proposed system to enhance its current pose estimation accuracy by jointly learning to forecast future poses. Indeed, we introduce the concept of Pose Nowcasting, denoting the capability of a system to exploit the learned knowledge of the future to improve the estimation of the present. The experimental evaluation is conducted on two different datasets, providing state-of-the-art and real-time performance and confirming the validity of the proposed method on both the robotic and human scenarios.
Generalized Early Stopping in Evolutionary Direct Policy Search
Aug 07, 2023
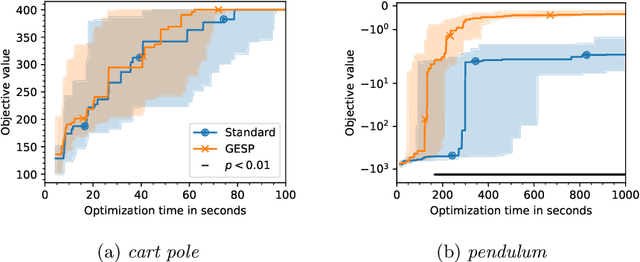
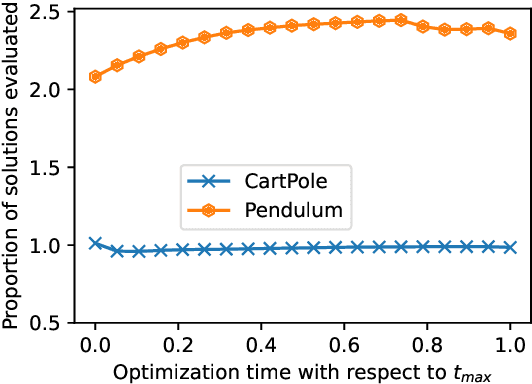
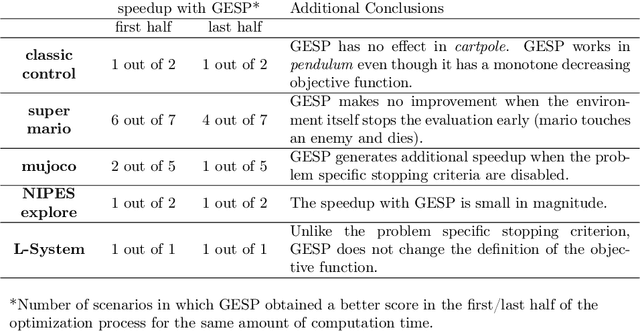
Lengthy evaluation times are common in many optimization problems such as direct policy search tasks, especially when they involve conducting evaluations in the physical world, e.g. in robotics applications. Often, when evaluating a solution over a fixed time period, it becomes clear that the objective value will not increase with additional computation time (for example, when a two-wheeled robot continuously spins on the spot). In such cases, it makes sense to stop the evaluation early to save computation time. However, most approaches to stop the evaluation are problem-specific and need to be specifically designed for the task at hand. Therefore, we propose an early stopping method for direct policy search. The proposed method only looks at the objective value at each time step and requires no problem-specific knowledge. We test the introduced stopping criterion in five direct policy search environments drawn from games, robotics, and classic control domains, and show that it can save up to 75% of the computation time. We also compare it with problem-specific stopping criteria and demonstrate that it performs comparably while being more generally applicable.
Do you know what q-means?
Aug 18, 2023Clustering is one of the most important tools for analysis of large datasets, and perhaps the most popular clustering algorithm is Lloyd's iteration for $k$-means. This iteration takes $N$ vectors $v_1,\dots,v_N\in\mathbb{R}^d$ and outputs $k$ centroids $c_1,\dots,c_k\in\mathbb{R}^d$; these partition the vectors into clusters based on which centroid is closest to a particular vector. We present an overall improved version of the "$q$-means" algorithm, the quantum algorithm originally proposed by Kerenidis, Landman, Luongo, and Prakash (2019) which performs $\varepsilon$-$k$-means, an approximate version of $k$-means clustering. This algorithm does not rely on the quantum linear algebra primitives of prior work, instead only using its QRAM to prepare and measure simple states based on the current iteration's clusters. The time complexity is $O\big(\frac{k^{2}}{\varepsilon^2}(\sqrt{k}d + \log(Nd))\big)$ and maintains the polylogarithmic dependence on $N$ while improving the dependence on most of the other parameters. We also present a "dequantized" algorithm for $\varepsilon$-$k$-means which runs in $O\big(\frac{k^{2}}{\varepsilon^2}(kd + \log(Nd))\big)$ time. Notably, this classical algorithm matches the polylogarithmic dependence on $N$ attained by the quantum algorithms.
GRINN: A Physics-Informed Neural Network for solving hydrodynamic systems in the presence of self-gravity
Aug 15, 2023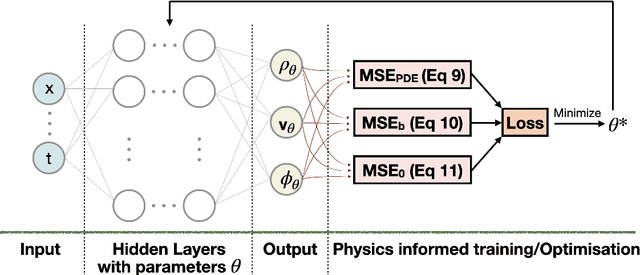
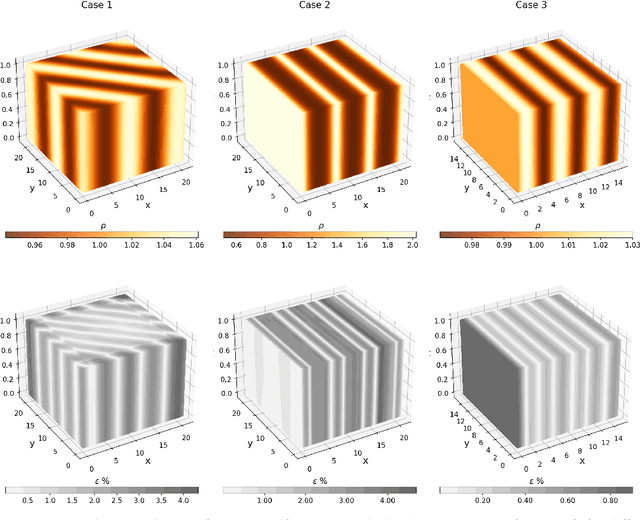
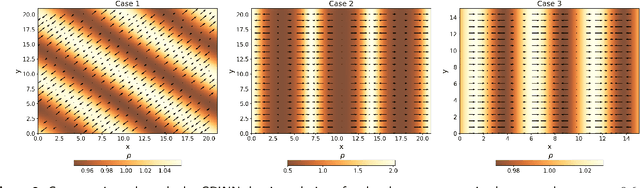

Modeling self-gravitating gas flows is essential to answering many fundamental questions in astrophysics. This spans many topics including planet-forming disks, star-forming clouds, galaxy formation, and the development of large-scale structures in the Universe. However, the nonlinear interaction between gravity and fluid dynamics offers a formidable challenge to solving the resulting time-dependent partial differential equations (PDEs) in three dimensions (3D). By leveraging the universal approximation capabilities of a neural network within a mesh-free framework, physics informed neural networks (PINNs) offer a new way of addressing this challenge. We introduce the gravity-informed neural network (GRINN), a PINN-based code, to simulate 3D self-gravitating hydrodynamic systems. Here, we specifically study gravitational instability and wave propagation in an isothermal gas. Our results match a linear analytic solution to within 1\% in the linear regime and a conventional grid code solution to within 5\% as the disturbance grows into the nonlinear regime. We find that the computation time of the GRINN does not scale with the number of dimensions. This is in contrast to the scaling of the grid-based code for the hydrodynamic and self-gravity calculations as the number of dimensions is increased. Our results show that the GRINN computation time is longer than the grid code in one- and two- dimensional calculations but is an order of magnitude lesser than the grid code in 3D with similar accuracy. Physics-informed neural networks like GRINN thus show promise for advancing our ability to model 3D astrophysical flows.
GAT-GAN : A Graph-Attention-based Time-Series Generative Adversarial Network
Jun 03, 2023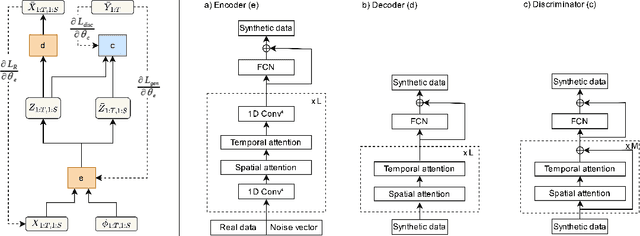
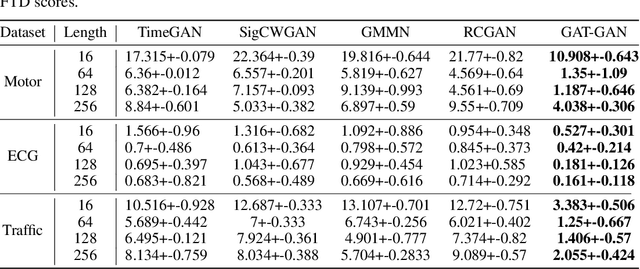
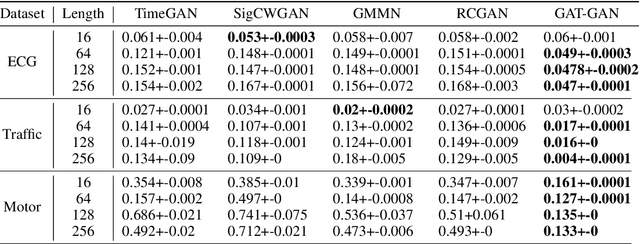
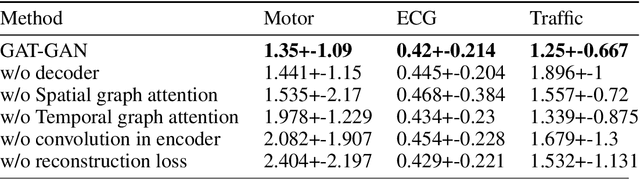
Generative Adversarial Networks (GANs) have proven to be a powerful tool for generating realistic synthetic data. However, traditional GANs often struggle to capture complex relationships between features which results in generation of unrealistic multivariate time-series data. In this paper, we propose a Graph-Attention-based Generative Adversarial Network (GAT-GAN) that explicitly includes two graph-attention layers, one that learns temporal dependencies while the other captures spatial relationships. Unlike RNN-based GANs that struggle with modeling long sequences of data points, GAT-GAN generates long time-series data of high fidelity using an adversarially trained autoencoder architecture. Our empirical evaluations, using a variety of real-time-series datasets, show that our framework consistently outperforms state-of-the-art benchmarks based on \emph{Frechet Transformer distance} and \emph{Predictive score}, that characterizes (\emph{Fidelity, Diversity}) and \emph{predictive performance} respectively. Moreover, we introduce a Frechet Inception distance-like (FID) metric for time-series data called Frechet Transformer distance (FTD) score (lower is better), to evaluate the quality and variety of generated data. We also found that low FTD scores correspond to the best-performing downstream predictive experiments. Hence, FTD scores can be used as a standardized metric to evaluate synthetic time-series data.
LDL: Line Distance Functions for Panoramic Localization
Aug 27, 2023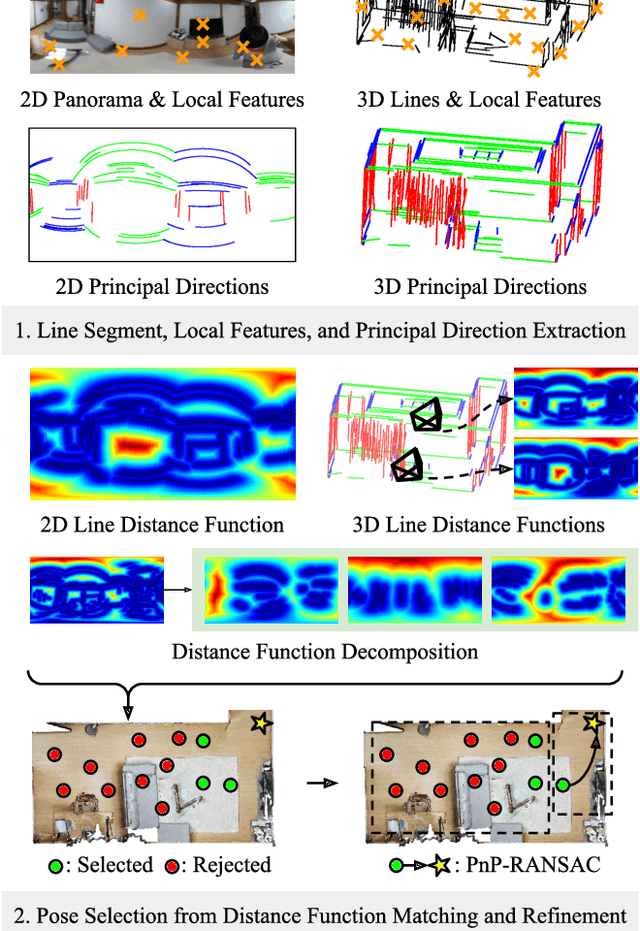
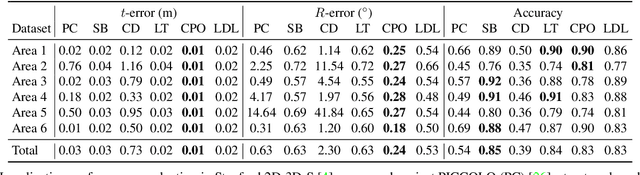
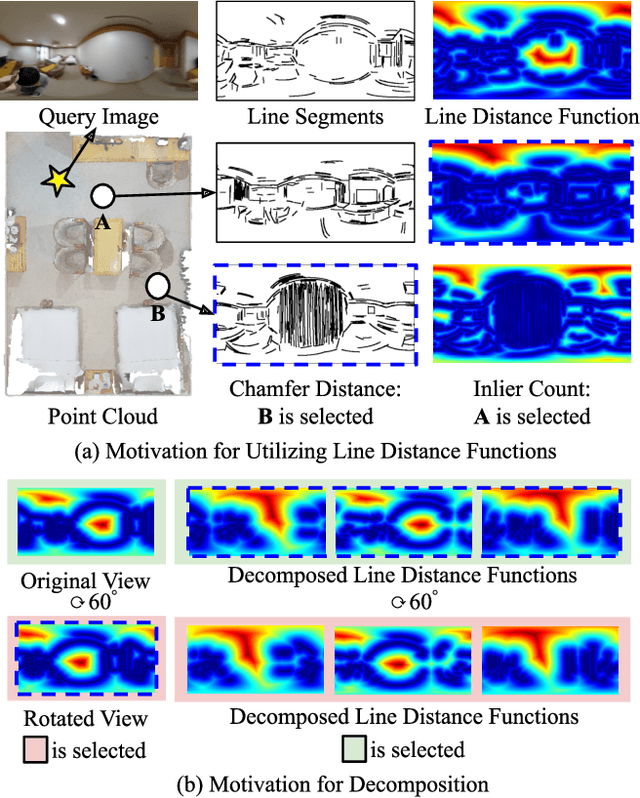
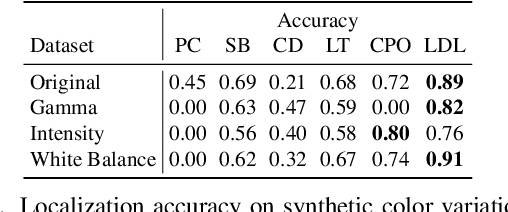
We introduce LDL, a fast and robust algorithm that localizes a panorama to a 3D map using line segments. LDL focuses on the sparse structural information of lines in the scene, which is robust to illumination changes and can potentially enable efficient computation. While previous line-based localization approaches tend to sacrifice accuracy or computation time, our method effectively observes the holistic distribution of lines within panoramic images and 3D maps. Specifically, LDL matches the distribution of lines with 2D and 3D line distance functions, which are further decomposed along principal directions of lines to increase the expressiveness. The distance functions provide coarse pose estimates by comparing the distributional information, where the poses are further optimized using conventional local feature matching. As our pipeline solely leverages line geometry and local features, it does not require costly additional training of line-specific features or correspondence matching. Nevertheless, our method demonstrates robust performance on challenging scenarios including object layout changes, illumination shifts, and large-scale scenes, while exhibiting fast pose search terminating within a matter of milliseconds. We thus expect our method to serve as a practical solution for line-based localization, and complement the well-established point-based paradigm. The code for LDL is available through the following link: https://github.com/82magnolia/panoramic-localization.