 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Application of Artificial Neural Networks for Investigation of Pressure Filtration Performance, a Zinc Leaching Filter Cake Moisture Modeling
Aug 11, 2023
Machine Learning (ML) is a powerful tool for material science applications. Artificial Neural Network (ANN) is a machine learning technique that can provide high prediction accuracy. This study aimed to develop an ANN model to predict the cake moisture of the pressure filtration process of zinc production. The cake moisture was influenced by seven parameters: temperature (35 and 65 Celsius), solid concentration (0.2 and 0.38 g/L), pH (2, 3.5, and 5), air-blow time (2, 10, and 15 min), cake thickness (14, 20, 26, and 34 mm), pressure, and filtration time. The study conducted 288 tests using two types of fabrics: polypropylene (S1) and polyester (S2). The ANN model was evaluated by the Coefficient of determination (R2), the Mean Square Error (MSE), and the Mean Absolute Error (MAE) metrics for both datasets. The results showed R2 values of 0.88 and 0.83, MSE values of 6.243x10-07 and 1.086x10-06, and MAE values of 0.00056 and 0.00088 for S1 and S2, respectively. These results indicated that the ANN model could predict the cake moisture of pressure filtration in the zinc leaching process with high accuracy.
gSASRec: Reducing Overconfidence in Sequential Recommendation Trained with Negative Sampling
Aug 14, 2023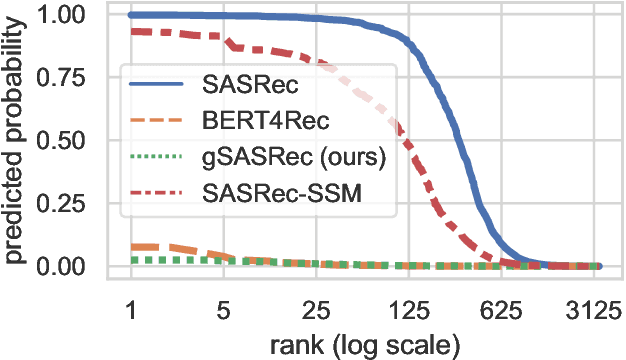
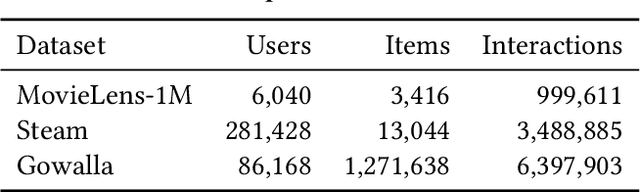
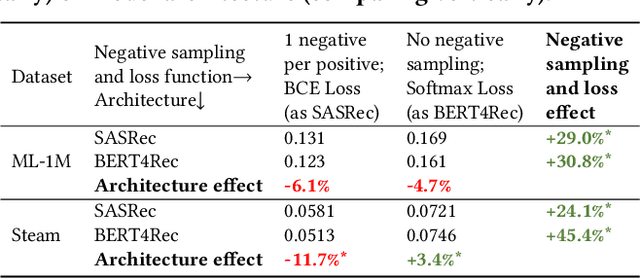
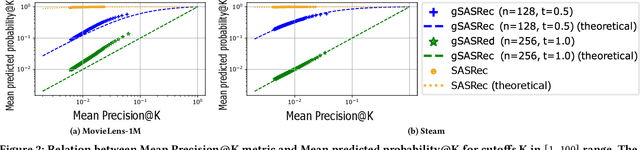
A large catalogue size is one of the central challenges in training recommendation models: a large number of items makes them memory and computationally inefficient to compute scores for all items during training, forcing these models to deploy negative sampling. However, negative sampling increases the proportion of positive interactions in the training data, and therefore models trained with negative sampling tend to overestimate the probabilities of positive interactions a phenomenon we call overconfidence. While the absolute values of the predicted scores or probabilities are not important for the ranking of retrieved recommendations, overconfident models may fail to estimate nuanced differences in the top-ranked items, resulting in degraded performance. In this paper, we show that overconfidence explains why the popular SASRec model underperforms when compared to BERT4Rec. This is contrary to the BERT4Rec authors explanation that the difference in performance is due to the bi-directional attention mechanism. To mitigate overconfidence, we propose a novel Generalised Binary Cross-Entropy Loss function (gBCE) and theoretically prove that it can mitigate overconfidence. We further propose the gSASRec model, an improvement over SASRec that deploys an increased number of negatives and the gBCE loss. We show through detailed experiments on three datasets that gSASRec does not exhibit the overconfidence problem. As a result, gSASRec can outperform BERT4Rec (e.g. +9.47% NDCG on the MovieLens-1M dataset), while requiring less training time (e.g. -73% training time on MovieLens-1M). Moreover, in contrast to BERT4Rec, gSASRec is suitable for large datasets that contain more than 1 million items.
Multi-User Modular XL-MIMO Communications: Near-Field Beam Focusing Pattern and User Grouping
Aug 23, 2023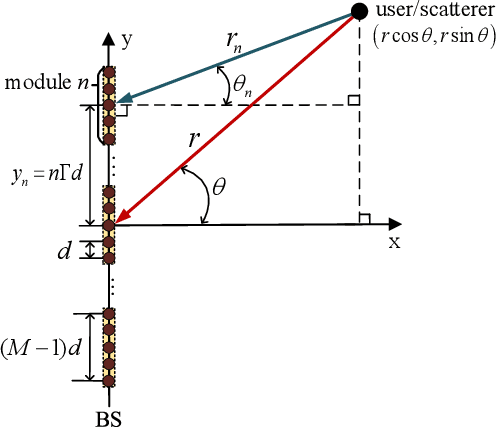
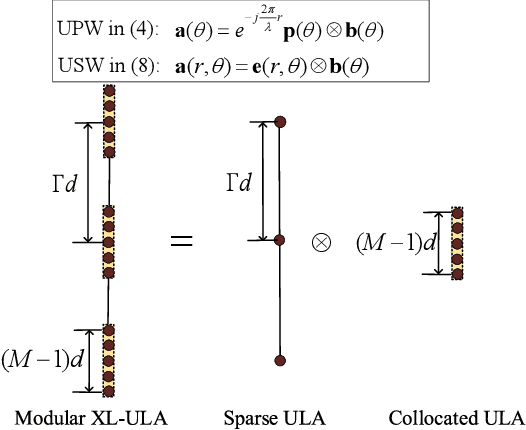
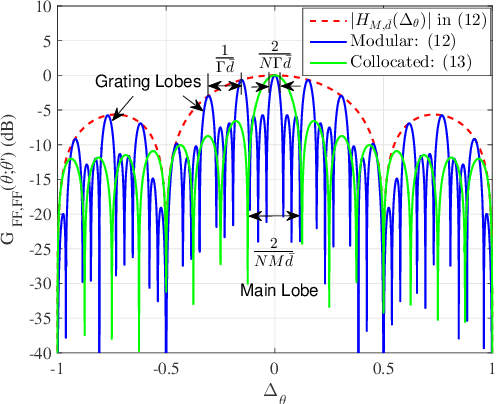
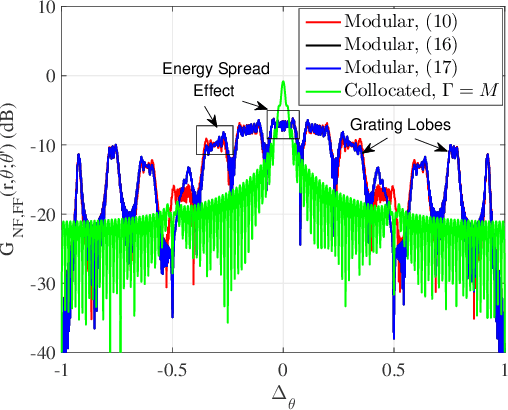
In this paper, we investigate multi-user modular extremely large-scale multiple-input multiple-output (XL-MIMO) communication systems, where modular extremely large-scale uniform linear array (XL-ULA) is deployed at the base station (BS) to serve multiple single-antenna users. By exploiting the unique modular array architecture and considering the potential near-field propagation, we develop sub-array based uniform spherical wave (USW) models for distinct versus common angles of arrival/departure (AoAs/AoDs) with respect to different sub-arrays/modules, respectively. Under such USW models, we analyze the beam focusing patterns at the near-field observation location by using near-field beamforming. The analysis reveals that compared to the conventional XL-MIMO with collocated antenna elements, modular XL-MIMO can provide better spatial resolution by benefiting from its larger array aperture. However, it also incurs undesired grating lobes due to the large inter-module separation. Moreover, it is found that for multi-user modular XL-MIMO communications, the achievable signal-to-interference-plus-noise ratio (SINR) for users may be degraded by the grating lobes of the beam focusing pattern. To address this issue, an efficient user grouping method is proposed for multi-user transmission scheduling, so that users located within the grating lobes of each other are not allocated to the same time-frequency resource block (RB) for their communications. Numerical results are presented to verify the effectiveness of the proposed user grouping method, as well as the superior performance of modular XL-MIMO over its collocated counterpart with densely distributed users.
Multi-Modal Multi-Task (3MT) Road Segmentation
Aug 23, 2023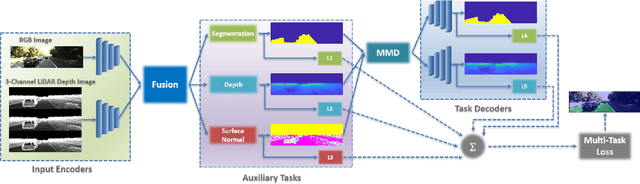



Multi-modal systems have the capacity of producing more reliable results than systems with a single modality in road detection due to perceiving different aspects of the scene. We focus on using raw sensor inputs instead of, as it is typically done in many SOTA works, leveraging architectures that require high pre-processing costs such as surface normals or dense depth predictions. By using raw sensor inputs, we aim to utilize a low-cost model thatminimizes both the pre-processing andmodel computation costs. This study presents a cost-effective and highly accurate solution for road segmentation by integrating data from multiple sensorswithin a multi-task learning architecture.Afusion architecture is proposed in which RGB and LiDAR depth images constitute the inputs of the network. Another contribution of this study is to use IMU/GNSS (inertial measurement unit/global navigation satellite system) inertial navigation system whose data is collected synchronously and calibrated with a LiDAR-camera to compute aggregated dense LiDAR depth images. It has been demonstrated by experiments on the KITTI dataset that the proposed method offers fast and high-performance solutions. We have also shown the performance of our method on Cityscapes where raw LiDAR data is not available. The segmentation results obtained for both full and half resolution images are competitive with existing methods. Therefore, we conclude that our method is not dependent only on raw LiDAR data; rather, it can be used with different sensor modalities. The inference times obtained in all experiments are very promising for real-time experiments.
Critical Evaluation of Artificial Intelligence as Digital Twin of Pathologist for Prostate Cancer Pathology
Aug 23, 2023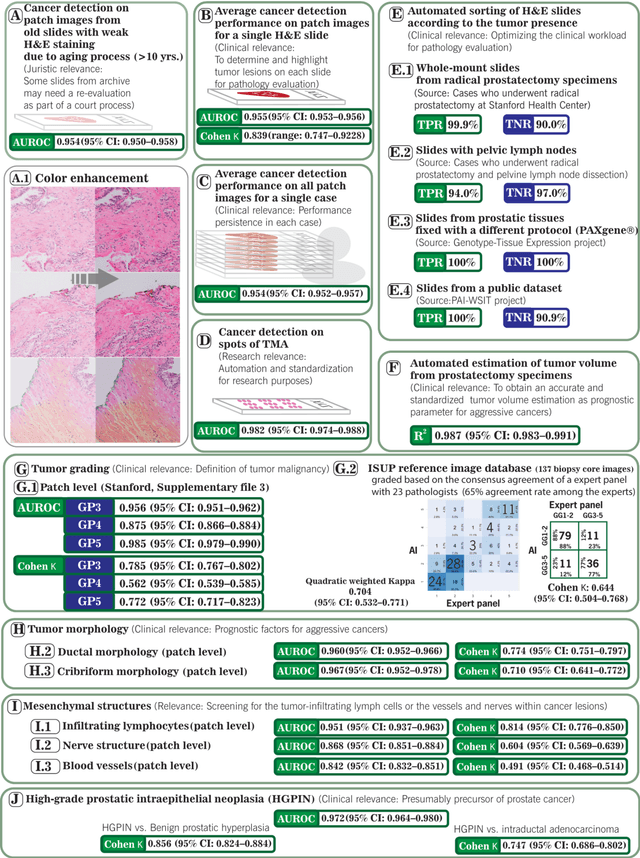
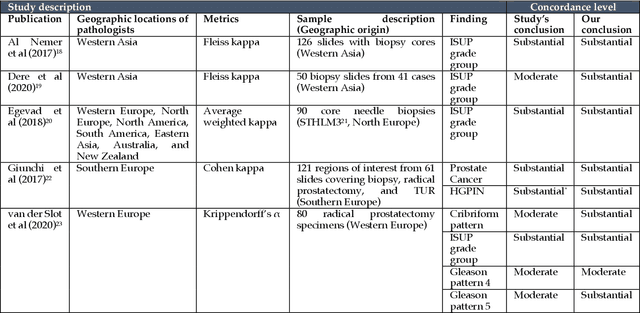
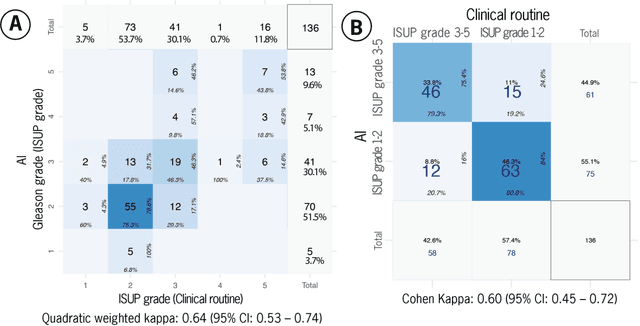
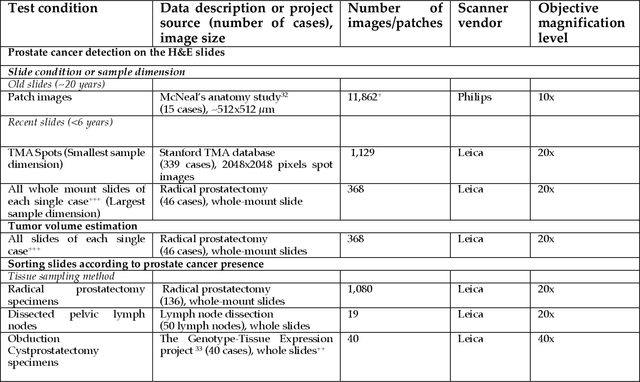
Prostate cancer pathology plays a crucial role in clinical management but is time-consuming. Artificial intelligence (AI) shows promise in detecting prostate cancer and grading patterns. We tested an AI-based digital twin of a pathologist, vPatho, on 2,603 histology images of prostate tissue stained with hematoxylin and eosin. We analyzed various factors influencing tumor-grade disagreement between vPatho and six human pathologists. Our results demonstrated that vPatho achieved comparable performance in prostate cancer detection and tumor volume estimation, as reported in the literature. Concordance levels between vPatho and human pathologists were examined. Notably, moderate to substantial agreement was observed in identifying complementary histological features such as ductal, cribriform, nerve, blood vessels, and lymph cell infiltrations. However, concordance in tumor grading showed a decline when applied to prostatectomy specimens (kappa = 0.44) compared to biopsy cores (kappa = 0.70). Adjusting the decision threshold for the secondary Gleason pattern from 5% to 10% improved the concordance level between pathologists and vPatho for tumor grading on prostatectomy specimens (kappa from 0.44 to 0.64). Potential causes of grade discordance included the vertical extent of tumors toward the prostate boundary and the proportions of slides with prostate cancer. Gleason pattern 4 was particularly associated with discordance. Notably, grade discordance with vPatho was not specific to any of the six pathologists involved in routine clinical grading. In conclusion, our study highlights the potential utility of AI in developing a digital twin of a pathologist. This approach can help uncover limitations in AI adoption and the current grading system for prostate cancer pathology.
Exploring Linguistic Similarity and Zero-Shot Learning for Multilingual Translation of Dravidian Languages
Aug 10, 2023
Current research in zero-shot translation is plagued by several issues such as high compute requirements, increased training time and off target translations. Proposed remedies often come at the cost of additional data or compute requirements. Pivot based neural machine translation is preferred over a single-encoder model for most settings despite the increased training and evaluation time. In this work, we overcome the shortcomings of zero-shot translation by taking advantage of transliteration and linguistic similarity. We build a single encoder-decoder neural machine translation system for Dravidian-Dravidian multilingual translation and perform zero-shot translation. We compare the data vs zero-shot accuracy tradeoff and evaluate the performance of our vanilla method against the current state of the art pivot based method. We also test the theory that morphologically rich languages require large vocabularies by restricting the vocabulary using an optimal transport based technique. Our model manages to achieves scores within 3 BLEU of large-scale pivot-based models when it is trained on 50\% of the language directions.
Deep generative models for unsupervised delamination detection using guided waves
Aug 10, 2023With the rising demands for robust structural health monitoring procedures for aerospace structures, the scope of intelligent algorithms and learning techniques is expanding. Supervised algorithms have shown promising results in the field provided a large, balanced, and labeled amount of data for training. For some applications like aerospace, the data collection process is cumbersome, time-taking, and costly. Also, generating possible damage scenarios in a laboratory setup is challenging because of the complexity of the damage initiation and failure mechanism. Besides this, the uncertainties of the real-time operation restrict the online prediction accuracy with supervised learning. In this paper, deep generative models are proposed for unsupervised delamination prediction as an anomaly detection problem. In this one-class-based model, the deep learning network is trained to learn the distribution of baseline signals. In the testing phase, damage signals and unseen baseline signals are fed into the trained network to predict the state of the structure, i.e., healthy or unhealthy (delamination). It is seen that the proposed method can successfully predict the delamination with high accuracy.
Thompson Sampling for Real-Valued Combinatorial Pure Exploration of Multi-Armed Bandit
Aug 20, 2023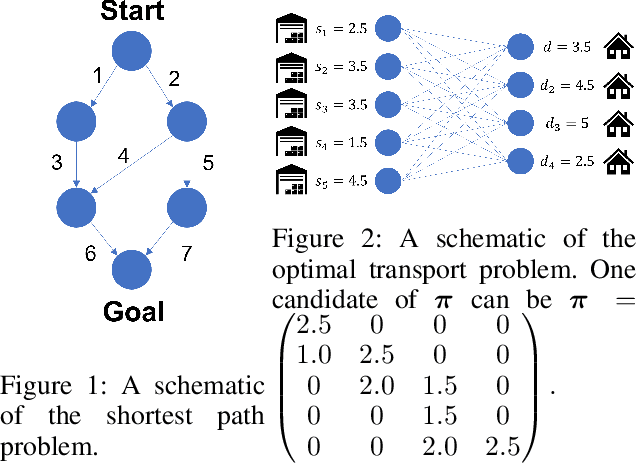
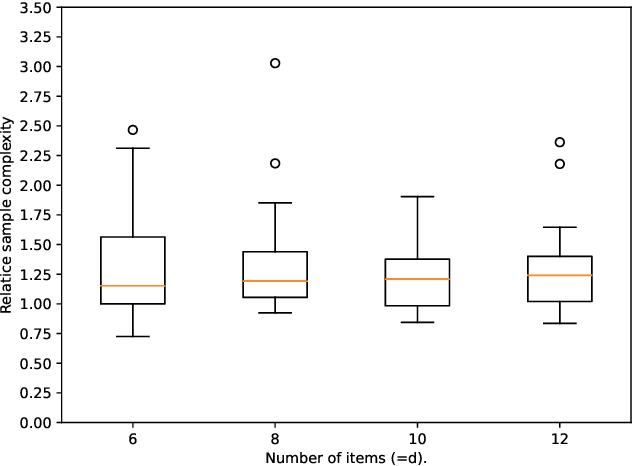
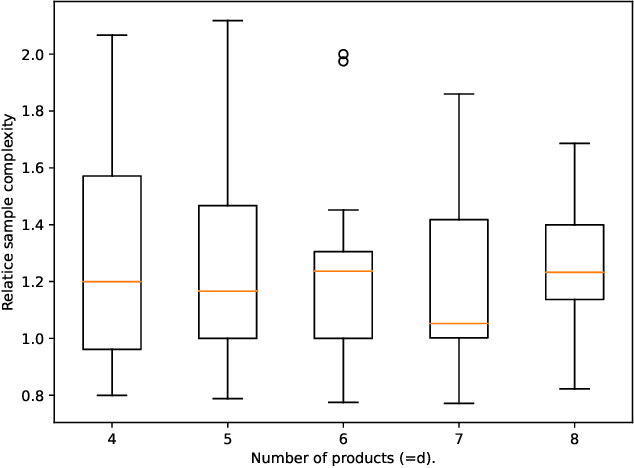
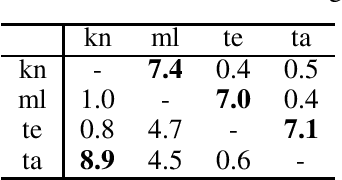
We study the real-valued combinatorial pure exploration of the multi-armed bandit (R-CPE-MAB) problem. In R-CPE-MAB, a player is given $d$ stochastic arms, and the reward of each arm $s\in\{1, \ldots, d\}$ follows an unknown distribution with mean $\mu_s$. In each time step, a player pulls a single arm and observes its reward. The player's goal is to identify the optimal \emph{action} $\boldsymbol{\pi}^{*} = \argmax_{\boldsymbol{\pi} \in \mathcal{A}} \boldsymbol{\mu}^{\top}\boldsymbol{\pi}$ from a finite-sized real-valued \emph{action set} $\mathcal{A}\subset \mathbb{R}^{d}$ with as few arm pulls as possible. Previous methods in the R-CPE-MAB assume that the size of the action set $\mathcal{A}$ is polynomial in $d$. We introduce an algorithm named the Generalized Thompson Sampling Explore (GenTS-Explore) algorithm, which is the first algorithm that can work even when the size of the action set is exponentially large in $d$. We also introduce a novel problem-dependent sample complexity lower bound of the R-CPE-MAB problem, and show that the GenTS-Explore algorithm achieves the optimal sample complexity up to a problem-dependent constant factor.
Deep Learning Driven Detection of Tsunami Related Internal GravityWaves: a path towards open-ocean natural hazards detection
Aug 08, 2023
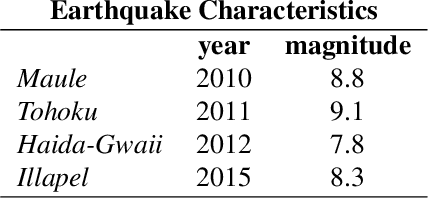
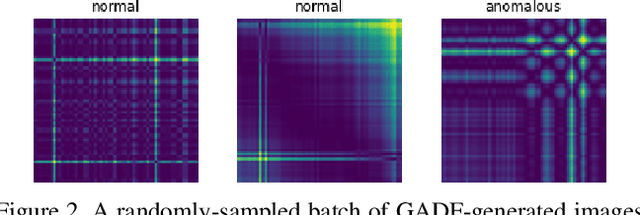

Tsunamis can trigger internal gravity waves (IGWs) in the ionosphere, perturbing the Total Electron Content (TEC) - referred to as Traveling Ionospheric Disturbances (TIDs) that are detectable through the Global Navigation Satellite System (GNSS). The GNSS are constellations of satellites providing signals from Earth orbit - Europe's Galileo, the United States' Global Positioning System (GPS), Russia's Global'naya Navigatsionnaya Sputnikovaya Sistema (GLONASS) and China's BeiDou. The real-time detection of TIDs provides an approach for tsunami detection, enhancing early warning systems by providing open-ocean coverage in geographic areas not serviceable by buoy-based warning systems. Large volumes of the GNSS data is leveraged by deep learning, which effectively handles complex non-linear relationships across thousands of data streams. We describe a framework leveraging slant total electron content (sTEC) from the VARION (Variometric Approach for Real-Time Ionosphere Observation) algorithm by Gramian Angular Difference Fields (from Computer Vision) and Convolutional Neural Networks (CNNs) to detect TIDs in near-real-time. Historical data from the 2010 Maule, 2011 Tohoku and the 2012 Haida-Gwaii earthquakes and tsunamis are used in model training, and the later-occurring 2015 Illapel earthquake and tsunami in Chile for out-of-sample model validation. Using the experimental framework described in the paper, we achieved a 91.7% F1 score. Source code is available at: https://github.com/vc1492a/tidd. Our work represents a new frontier in detecting tsunami-driven IGWs in open-ocean, dramatically improving the potential for natural hazards detection for coastal communities.
Minimizing Turns in Watchman Robot Navigation: Strategies and Solutions
Aug 19, 2023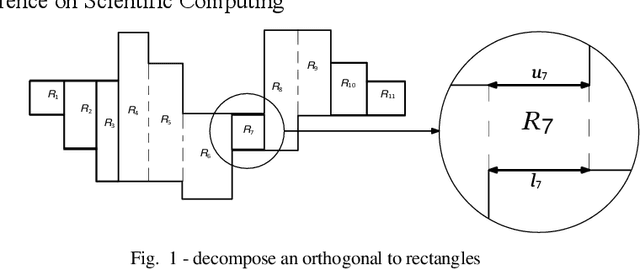
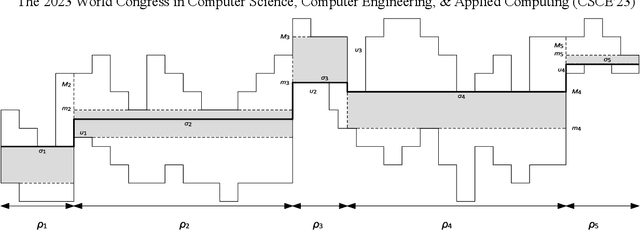
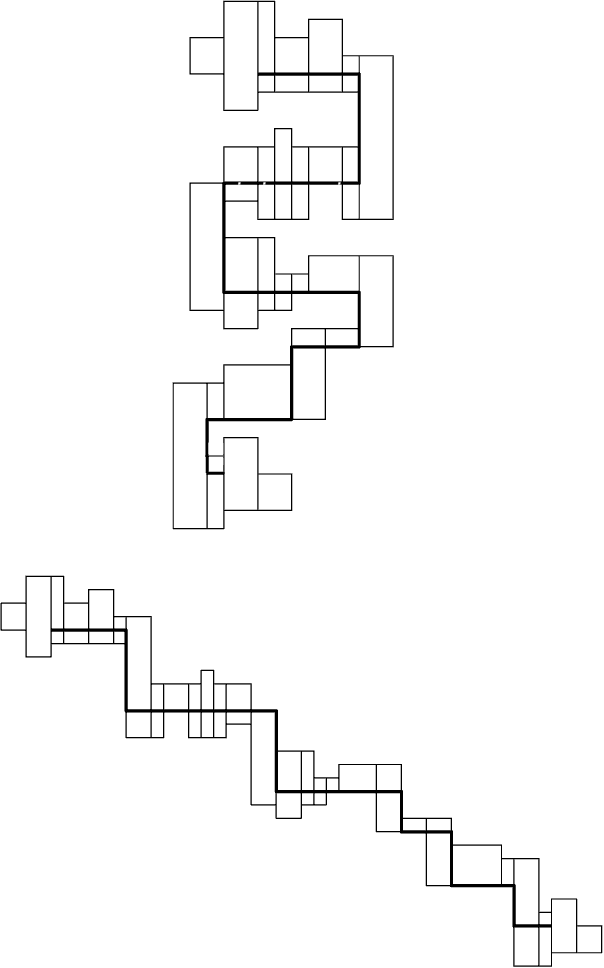
The Orthogonal Watchman Route Problem (OWRP) entails the search for the shortest path, known as the watchman route, that a robot must follow within a polygonal environment. The primary objective is to ensure that every point in the environment remains visible from at least one point on the route, allowing the robot to survey the entire area in a single, continuous sweep. This research places particular emphasis on reducing the number of turns in the route, as it is crucial for optimizing navigation in watchman routes within the field of robotics. The cost associated with changing direction is of significant importance, especially for specific types of robots. This paper introduces an efficient linear-time algorithm for solving the OWRP under the assumption that the environment is monotone. The findings of this study contribute to the progress of robotic systems by enabling the design of more streamlined patrol robots. These robots are capable of efficiently navigating complex environments while minimizing the number of turns. This advancement enhances their coverage and surveillance capabilities, making them highly effective in various real-world applications.
* 6 pages, 3 figures