 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Time-of-Arrival Localization via ADMM
Jun 15, 2023
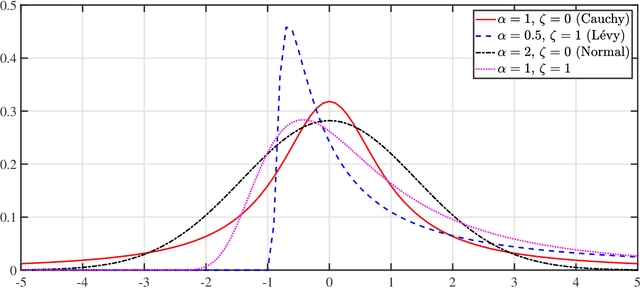
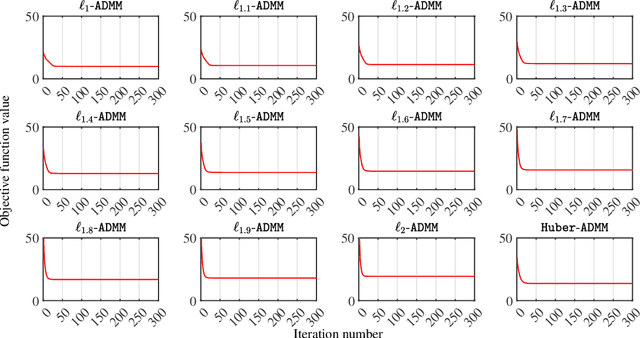
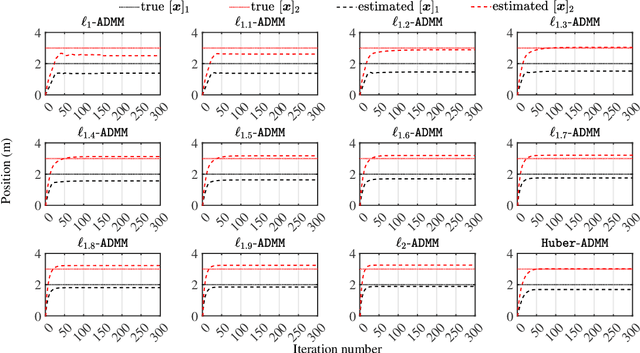
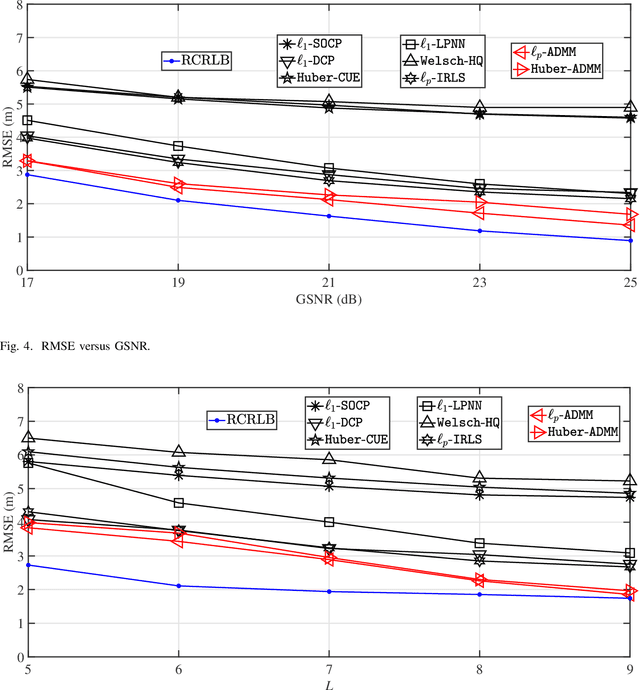
This article considers the problem of source localization (SL) using possibly unreliable time-of-arrival (TOA) based range measurements. Adopting the strategy of statistical robustification, we formulate the TOA SL as minimization of a versatile loss that possesses resistance against the occurrence of outliers. We then present an alternating direction method of multipliers (ADMM) to tackle the nonconvex optimization problem in a computationally attractive iterative manner. Moreover, we prove that the solution obtained by the proposed ADMM will correspond to a Karush-Kuhn-Tucker point of the formulation when the algorithm converges, and discuss reasonable assumptions about the robust loss function under which the approach can be theoretically guaranteed to be convergent. Numerical investigations demonstrate the superiority of our method over many existing TOA SL schemes in terms of positioning accuracy and computational simplicity. In comparison with its competitors, the proposed ADMM is in particular observed to produce location estimates with mean squared error performance closer to the Cram\'{e}r-Rao lower bound in our simulations of impulsive noise environments.
Vision-Based Intelligent Robot Grasping Using Sparse Neural Network
Aug 22, 2023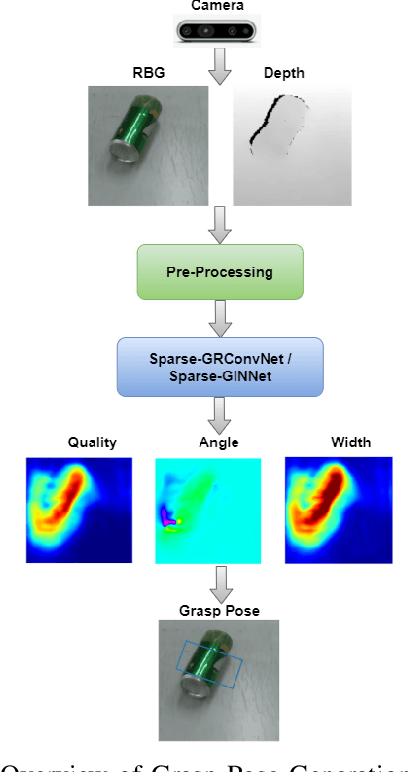



In the modern era of Deep Learning, network parameters play a vital role in models efficiency but it has its own limitations like extensive computations and memory requirements, which may not be suitable for real time intelligent robot grasping tasks. Current research focuses on how the model efficiency can be maintained by introducing sparsity but without compromising accuracy of the model in the robot grasping domain. More specifically, in this research two light-weighted neural networks have been introduced, namely Sparse-GRConvNet and Sparse-GINNet, which leverage sparsity in the robotic grasping domain for grasp pose generation by integrating the Edge-PopUp algorithm. This algorithm facilitates the identification of the top K% of edges by considering their respective score values. Both the Sparse-GRConvNet and Sparse-GINNet models are designed to generate high-quality grasp poses in real-time at every pixel location, enabling robots to effectively manipulate unfamiliar objects. We extensively trained our models using two benchmark datasets: Cornell Grasping Dataset (CGD) and Jacquard Grasping Dataset (JGD). Both Sparse-GRConvNet and Sparse-GINNet models outperform the current state-of-the-art methods in terms of performance, achieving an impressive accuracy of 97.75% with only 10% of the weight of GR-ConvNet and 50% of the weight of GI-NNet, respectively, on CGD. Additionally, Sparse-GRConvNet achieve an accuracy of 85.77% with 30% of the weight of GR-ConvNet and Sparse-GINNet achieve an accuracy of 81.11% with 10% of the weight of GI-NNet on JGD. To validate the performance of our proposed models, we conducted extensive experiments using the Anukul (Baxter) hardware cobot.
Collect, Measure, Repeat: Reliability Factors for Responsible AI Data Collection
Aug 22, 2023The rapid entry of machine learning approaches in our daily activities and high-stakes domains demands transparency and scrutiny of their fairness and reliability. To help gauge machine learning models' robustness, research typically focuses on the massive datasets used for their deployment, e.g., creating and maintaining documentation for understanding their origin, process of development, and ethical considerations. However, data collection for AI is still typically a one-off practice, and oftentimes datasets collected for a certain purpose or application are reused for a different problem. Additionally, dataset annotations may not be representative over time, contain ambiguous or erroneous annotations, or be unable to generalize across issues or domains. Recent research has shown these practices might lead to unfair, biased, or inaccurate outcomes. We argue that data collection for AI should be performed in a responsible manner where the quality of the data is thoroughly scrutinized and measured through a systematic set of appropriate metrics. In this paper, we propose a Responsible AI (RAI) methodology designed to guide the data collection with a set of metrics for an iterative in-depth analysis of the factors influencing the quality and reliability} of the generated data. We propose a granular set of measurements to inform on the internal reliability of a dataset and its external stability over time. We validate our approach across nine existing datasets and annotation tasks and four content modalities. This approach impacts the assessment of data robustness used for AI applied in the real world, where diversity of users and content is eminent. Furthermore, it deals with fairness and accountability aspects in data collection by providing systematic and transparent quality analysis for data collections.
Contracting Dynamics for Time-Varying Convex Optimization
May 24, 2023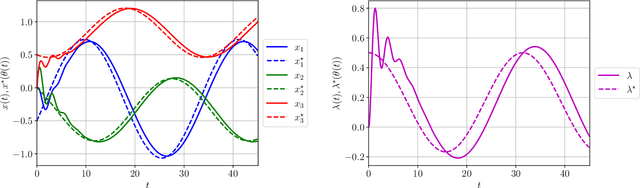
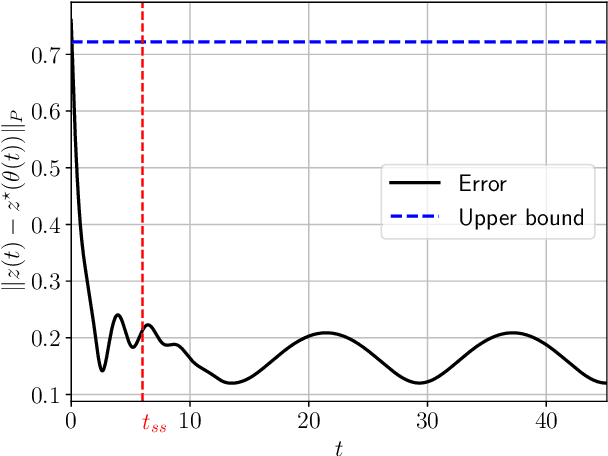
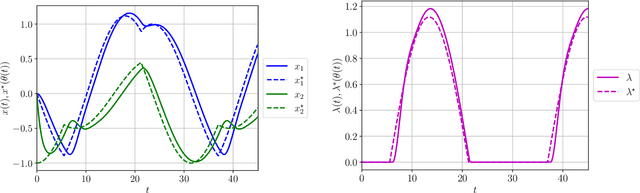
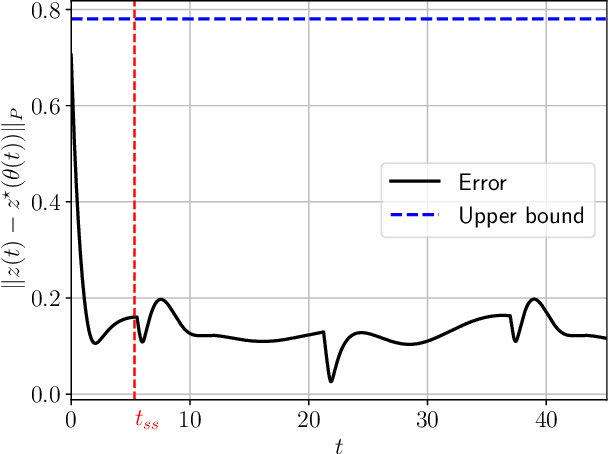
In this article, we provide a novel and broadly-applicable contraction-theoretic approach to continuous-time time-varying convex optimization. For any parameter-dependent contracting dynamics, we show that the tracking error between any solution trajectory and the equilibrium trajectory is uniformly upper bounded in terms of the contraction rate, the Lipschitz constant in which the parameter appears, and the rate of change of the parameter. To apply this result to time-varying convex optimization problems, we establish the strong infinitesimal contraction of dynamics solving three canonical problems, namely monotone inclusions, linear equality-constrained problems, and composite minimization problems. For each of these problems, we prove the sharpest-known rates of contraction and provide explicit tracking error bounds between solution trajectories and minimizing trajectories. We validate our theoretical results on two numerical examples.
Domain Adaptation via Minimax Entropy for Real/Bogus Classification of Astronomical Alerts
Aug 15, 2023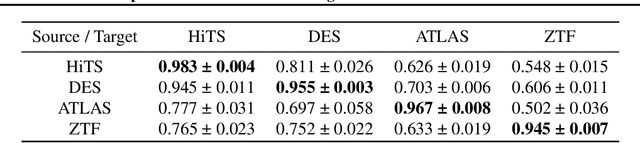
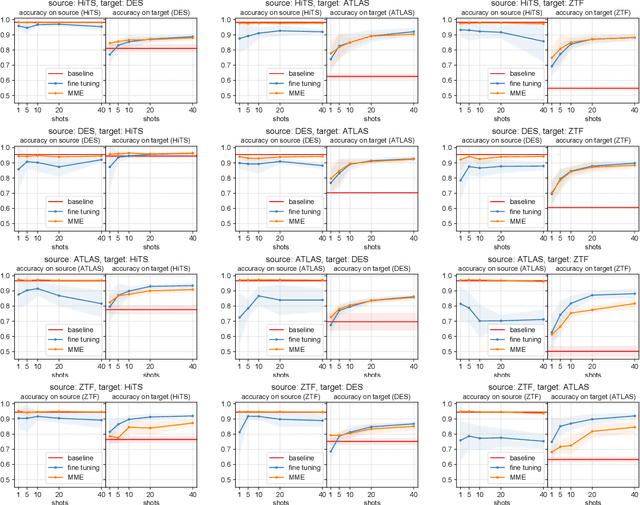
Time domain astronomy is advancing towards the analysis of multiple massive datasets in real time, prompting the development of multi-stream machine learning models. In this work, we study Domain Adaptation (DA) for real/bogus classification of astronomical alerts using four different datasets: HiTS, DES, ATLAS, and ZTF. We study the domain shift between these datasets, and improve a naive deep learning classification model by using a fine tuning approach and semi-supervised deep DA via Minimax Entropy (MME). We compare the balanced accuracy of these models for different source-target scenarios. We find that both the fine tuning and MME models improve significantly the base model with as few as one labeled item per class coming from the target dataset, but that the MME does not compromise its performance on the source dataset.
SkinDistilViT: Lightweight Vision Transformer for Skin Lesion Classification
Aug 16, 2023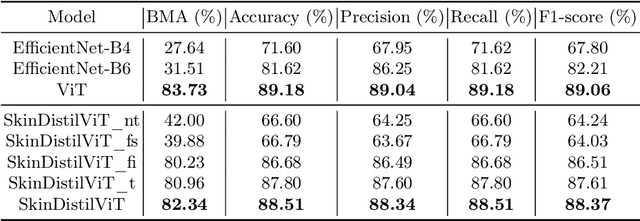

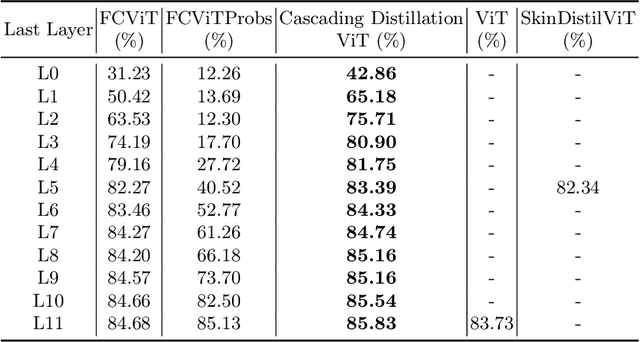
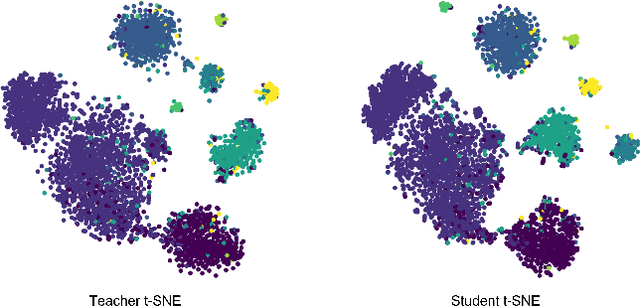
Skin cancer is a treatable disease if discovered early. We provide a production-specific solution to the skin cancer classification problem that matches human performance in melanoma identification by training a vision transformer on melanoma medical images annotated by experts. Since inference cost, both time and memory wise is important in practice, we employ knowledge distillation to obtain a model that retains 98.33% of the teacher's balanced multi-class accuracy, at a fraction of the cost. Memory-wise, our model is 49.60% smaller than the teacher. Time-wise, our solution is 69.25% faster on GPU and 97.96% faster on CPU. By adding classification heads at each level of the transformer and employing a cascading distillation process, we improve the balanced multi-class accuracy of the base model by 2.1%, while creating a range of models of various sizes but comparable performance. We provide the code at https://github.com/Longman-Stan/SkinDistilVit.
Wideband Power Spectrum Sensing: a Fast Practical Solution for Nyquist Folding Receiver
Aug 14, 2023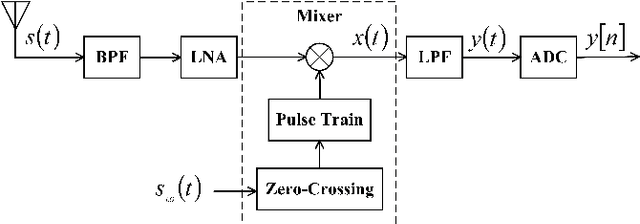
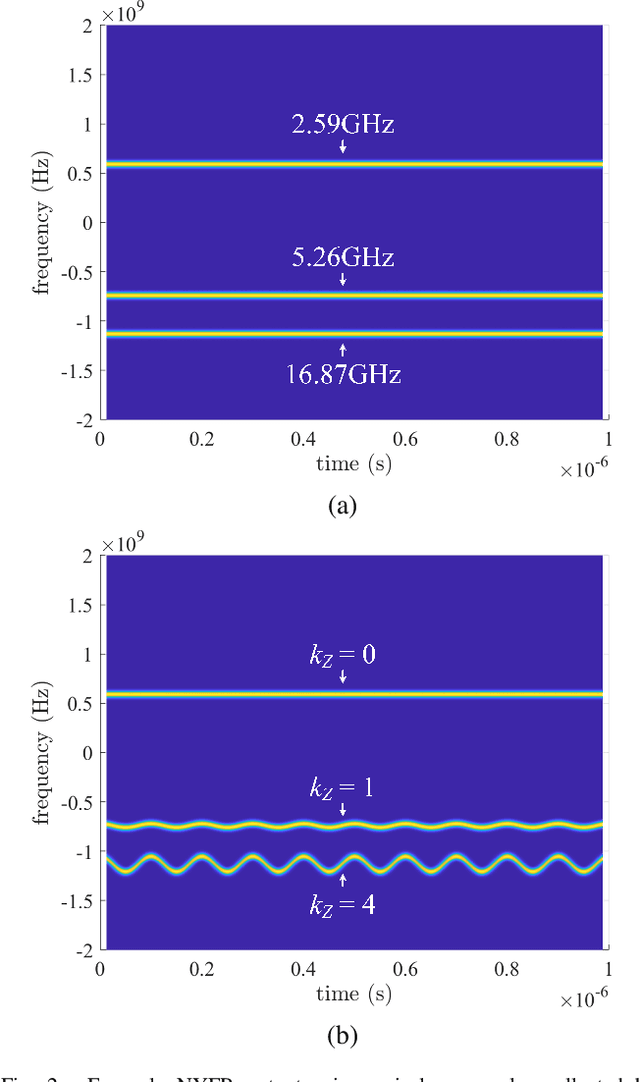
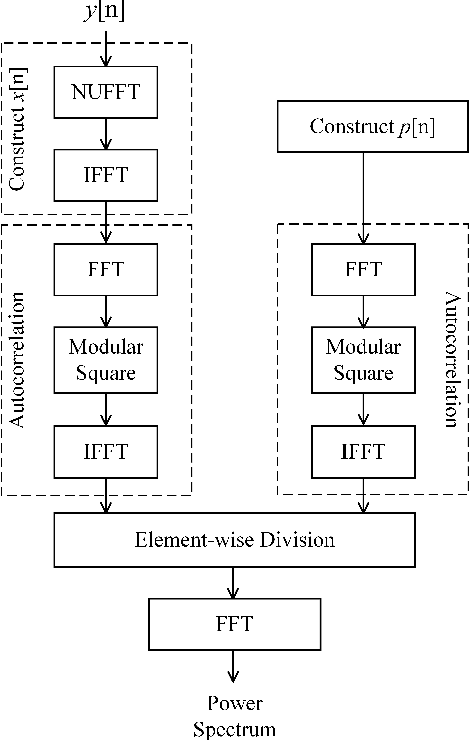
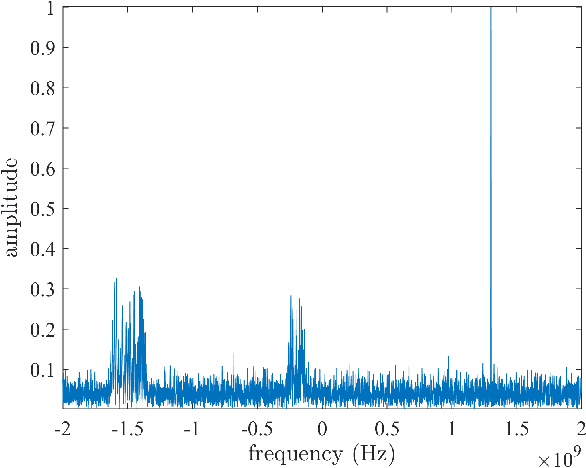
The limited availability of spectrum resources has been growing into a critical problem in wireless communications, remote sensing, and electronic surveillance, etc. To address the high-speed sampling bottleneck of wideband spectrum sensing, a fast and practical solution of power spectrum estimation for Nyquist folding receiver (NYFR) is proposed in this paper. The NYFR architectures is can theoretically achieve the full-band signal sensing with a hundred percent of probability of intercept. But the existing algorithm is difficult to realize in real-time due to its high complexity and complicated calculations. By exploring the sub-sampling principle inherent in NYFR, a computationally efficient method is introduced with compressive covariance sensing. That can be efficient implemented via only the non-uniform fast Fourier transform, fast Fourier transform, and some simple multiplication operations. Meanwhile, the state-of-the-art power spectrum reconstruction model for NYFR of time-domain and frequency-domain is constructed in this paper as a comparison. Furthermore, the computational complexity of the proposed method scales linearly with the Nyquist-rate sampled number of samples and the sparsity of spectrum occupancy. Simulation results and discussion demonstrate that the low complexity in sampling and computation is a more practical solution to meet the real-time wideband spectrum sensing applications.
Auto-Prompting SAM for Mobile Friendly 3D Medical Image Segmentation
Aug 28, 2023The Segment Anything Model (SAM) has rapidly been adopted for segmenting a wide range of natural images. However, recent studies have indicated that SAM exhibits subpar performance on 3D medical image segmentation tasks. In addition to the domain gaps between natural and medical images, disparities in the spatial arrangement between 2D and 3D images, the substantial computational burden imposed by powerful GPU servers, and the time-consuming manual prompt generation impede the extension of SAM to a broader spectrum of medical image segmentation applications. To address these challenges, in this work, we introduce a novel method, AutoSAM Adapter, designed specifically for 3D multi-organ CT-based segmentation. We employ parameter-efficient adaptation techniques in developing an automatic prompt learning paradigm to facilitate the transformation of the SAM model's capabilities to 3D medical image segmentation, eliminating the need for manually generated prompts. Furthermore, we effectively transfer the acquired knowledge of the AutoSAM Adapter to other lightweight models specifically tailored for 3D medical image analysis, achieving state-of-the-art (SOTA) performance on medical image segmentation tasks. Through extensive experimental evaluation, we demonstrate the AutoSAM Adapter as a critical foundation for effectively leveraging the emerging ability of foundation models in 2D natural image segmentation for 3D medical image segmentation.
Evaluation of Key Spatiotemporal Learners for Print Track Anomaly Classification Using Melt Pool Image Streams
Aug 28, 2023
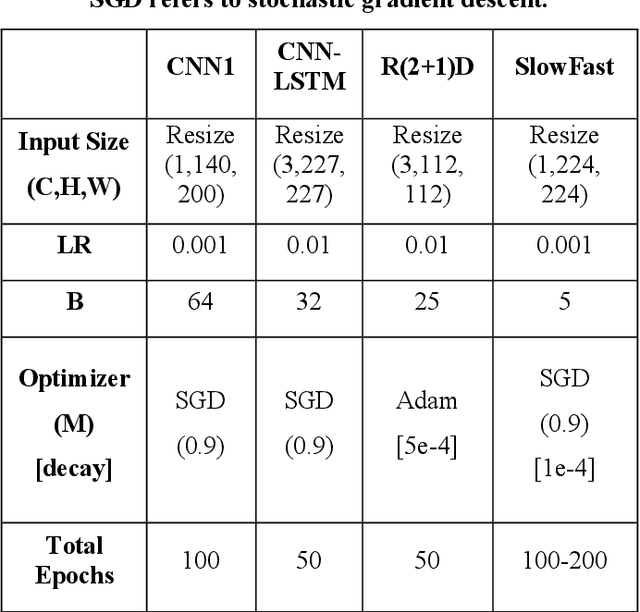


Recent applications of machine learning in metal additive manufacturing (MAM) have demonstrated significant potential in addressing critical barriers to the widespread adoption of MAM technology. Recent research in this field emphasizes the importance of utilizing melt pool signatures for real-time defect prediction. While high-quality melt pool image data holds the promise of enabling precise predictions, there has been limited exploration into the utilization of cutting-edge spatiotemporal models that can harness the inherent transient and sequential characteristics of the additive manufacturing process. This research introduces and puts into practice some of the leading deep spatiotemporal learning models that can be adapted for the classification of melt pool image streams originating from various materials, systems, and applications. Specifically, it investigates two-stream networks comprising spatial and temporal streams, a recurrent spatial network, and a factorized 3D convolutional neural network. The capacity of these models to generalize when exposed to perturbations in melt pool image data is examined using data perturbation techniques grounded in real-world process scenarios. The implemented architectures demonstrate the ability to capture the spatiotemporal features of melt pool image sequences. However, among these models, only the Kinetics400 pre-trained SlowFast network, categorized as a two-stream network, exhibits robust generalization capabilities in the presence of data perturbations.
Meta Attentive Graph Convolutional Recurrent Network for Traffic Forecasting
Aug 28, 2023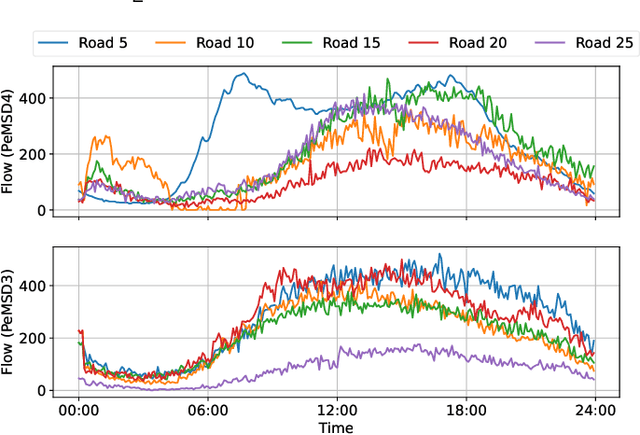

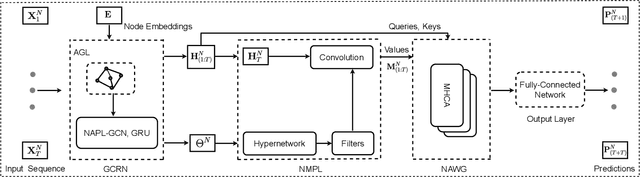

Traffic forecasting is a fundamental problem in intelligent transportation systems. Existing traffic predictors are limited by their expressive power to model the complex spatial-temporal dependencies in traffic data, mainly due to the following limitations. Firstly, most approaches are primarily designed to model the local shared patterns, which makes them insufficient to capture the specific patterns associated with each node globally. Hence, they fail to learn each node's unique properties and diversified patterns. Secondly, most existing approaches struggle to accurately model both short- and long-term dependencies simultaneously. In this paper, we propose a novel traffic predictor, named Meta Attentive Graph Convolutional Recurrent Network (MAGCRN). MAGCRN utilizes a Graph Convolutional Recurrent Network (GCRN) as a core module to model local dependencies and improves its operation with two novel modules: 1) a Node-Specific Meta Pattern Learning (NMPL) module to capture node-specific patterns globally and 2) a Node Attention Weight Generation Module (NAWG) module to capture short- and long-term dependencies by connecting the node-specific features with the ones learned initially at each time step during GCRN operation. Experiments on six real-world traffic datasets demonstrate that NMPL and NAWG together enable MAGCRN to outperform state-of-the-art baselines on both short- and long-term predictions.