 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SwinFace: A Multi-task Transformer for Face Recognition, Expression Recognition, Age Estimation and Attribute Estimation
Aug 22, 2023
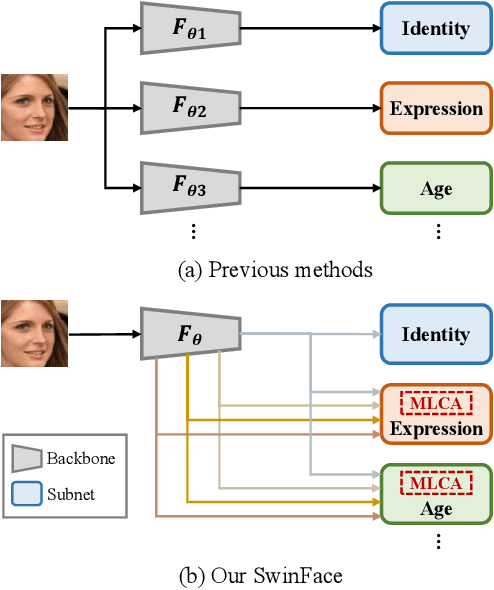
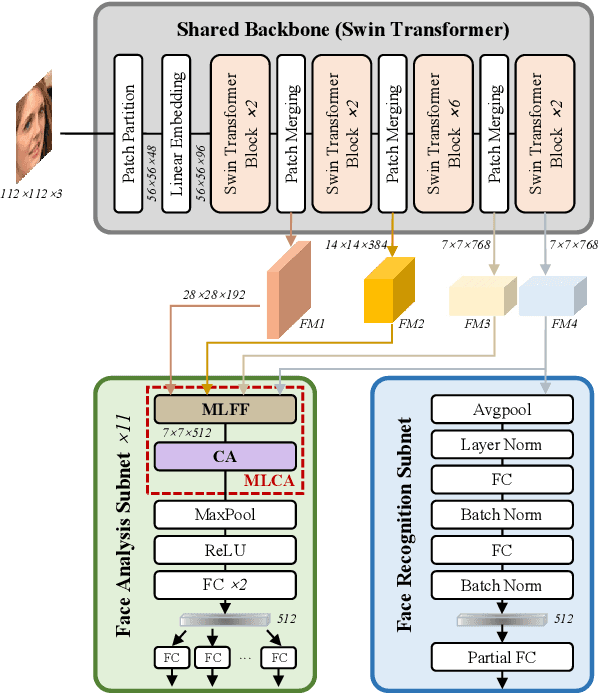
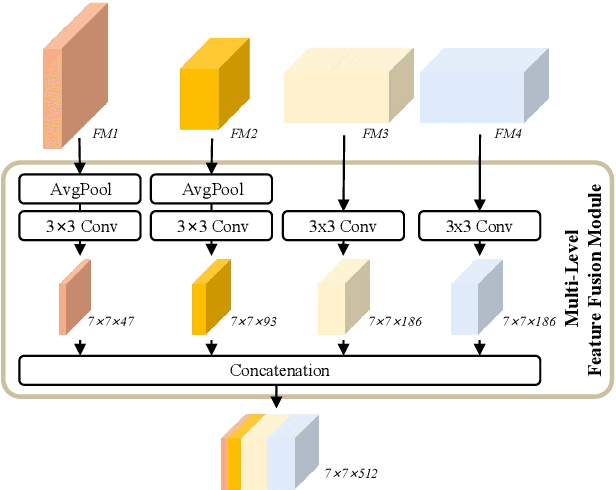
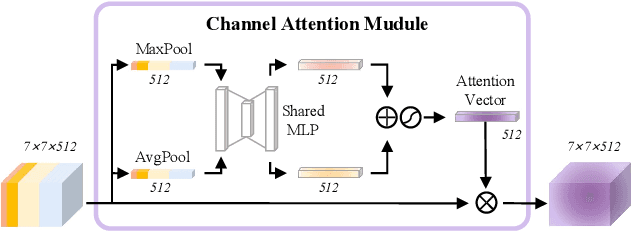
In recent years, vision transformers have been introduced into face recognition and analysis and have achieved performance breakthroughs. However, most previous methods generally train a single model or an ensemble of models to perform the desired task, which ignores the synergy among different tasks and fails to achieve improved prediction accuracy, increased data efficiency, and reduced training time. This paper presents a multi-purpose algorithm for simultaneous face recognition, facial expression recognition, age estimation, and face attribute estimation (40 attributes including gender) based on a single Swin Transformer. Our design, the SwinFace, consists of a single shared backbone together with a subnet for each set of related tasks. To address the conflicts among multiple tasks and meet the different demands of tasks, a Multi-Level Channel Attention (MLCA) module is integrated into each task-specific analysis subnet, which can adaptively select the features from optimal levels and channels to perform the desired tasks. Extensive experiments show that the proposed model has a better understanding of the face and achieves excellent performance for all tasks. Especially, it achieves 90.97% accuracy on RAF-DB and 0.22 $\epsilon$-error on CLAP2015, which are state-of-the-art results on facial expression recognition and age estimation respectively. The code and models will be made publicly available at https://github.com/lxq1000/SwinFace.
PatchBackdoor: Backdoor Attack against Deep Neural Networks without Model Modification
Aug 22, 2023Backdoor attack is a major threat to deep learning systems in safety-critical scenarios, which aims to trigger misbehavior of neural network models under attacker-controlled conditions. However, most backdoor attacks have to modify the neural network models through training with poisoned data and/or direct model editing, which leads to a common but false belief that backdoor attack can be easily avoided by properly protecting the model. In this paper, we show that backdoor attacks can be achieved without any model modification. Instead of injecting backdoor logic into the training data or the model, we propose to place a carefully-designed patch (namely backdoor patch) in front of the camera, which is fed into the model together with the input images. The patch can be trained to behave normally at most of the time, while producing wrong prediction when the input image contains an attacker-controlled trigger object. Our main techniques include an effective training method to generate the backdoor patch and a digital-physical transformation modeling method to enhance the feasibility of the patch in real deployments. Extensive experiments show that PatchBackdoor can be applied to common deep learning models (VGG, MobileNet, ResNet) with an attack success rate of 93% to 99% on classification tasks. Moreover, we implement PatchBackdoor in real-world scenarios and show that the attack is still threatening.
HMD-NeMo: Online 3D Avatar Motion Generation From Sparse Observations
Aug 22, 2023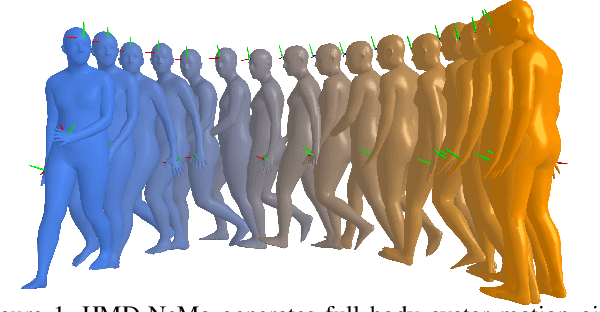
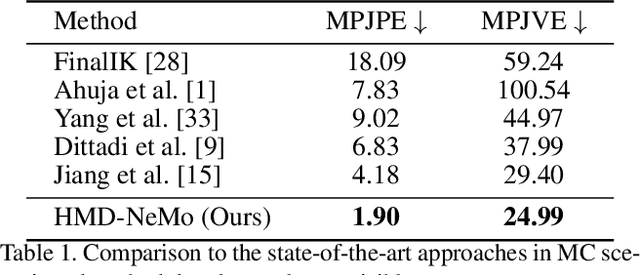


Generating both plausible and accurate full body avatar motion is the key to the quality of immersive experiences in mixed reality scenarios. Head-Mounted Devices (HMDs) typically only provide a few input signals, such as head and hands 6-DoF. Recently, different approaches achieved impressive performance in generating full body motion given only head and hands signal. However, to the best of our knowledge, all existing approaches rely on full hand visibility. While this is the case when, e.g., using motion controllers, a considerable proportion of mixed reality experiences do not involve motion controllers and instead rely on egocentric hand tracking. This introduces the challenge of partial hand visibility owing to the restricted field of view of the HMD. In this paper, we propose the first unified approach, HMD-NeMo, that addresses plausible and accurate full body motion generation even when the hands may be only partially visible. HMD-NeMo is a lightweight neural network that predicts the full body motion in an online and real-time fashion. At the heart of HMD-NeMo is the spatio-temporal encoder with novel temporally adaptable mask tokens that encourage plausible motion in the absence of hand observations. We perform extensive analysis of the impact of different components in HMD-NeMo and introduce a new state-of-the-art on AMASS dataset through our evaluation.
Pose2Gait: Extracting Gait Features from Monocular Video of Individuals with Dementia
Aug 22, 2023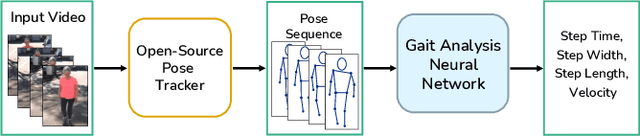

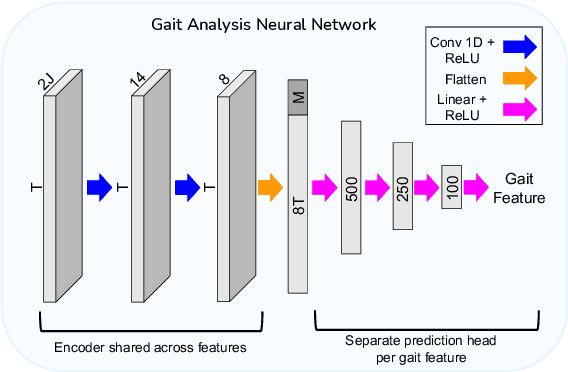

Video-based ambient monitoring of gait for older adults with dementia has the potential to detect negative changes in health and allow clinicians and caregivers to intervene early to prevent falls or hospitalizations. Computer vision-based pose tracking models can process video data automatically and extract joint locations; however, publicly available models are not optimized for gait analysis on older adults or clinical populations. In this work we train a deep neural network to map from a two dimensional pose sequence, extracted from a video of an individual walking down a hallway toward a wall-mounted camera, to a set of three-dimensional spatiotemporal gait features averaged over the walking sequence. The data of individuals with dementia used in this work was captured at two sites using a wall-mounted system to collect the video and depth information used to train and evaluate our model. Our Pose2Gait model is able to extract velocity and step length values from the video that are correlated with the features from the depth camera, with Spearman's correlation coefficients of .83 and .60 respectively, showing that three dimensional spatiotemporal features can be predicted from monocular video. Future work remains to improve the accuracy of other features, such as step time and step width, and test the utility of the predicted values for detecting meaningful changes in gait during longitudinal ambient monitoring.
CNN based Cuneiform Sign Detection Learned from Annotated 3D Renderings and Mapped Photographs with Illumination Augmentation
Aug 22, 2023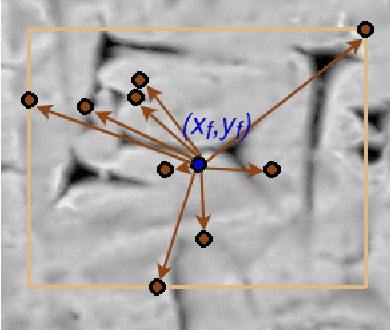

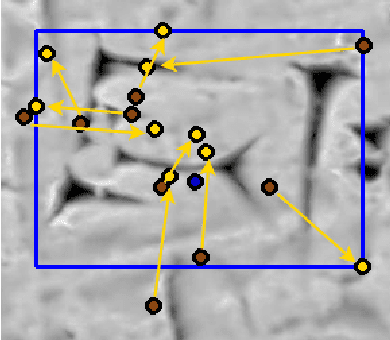
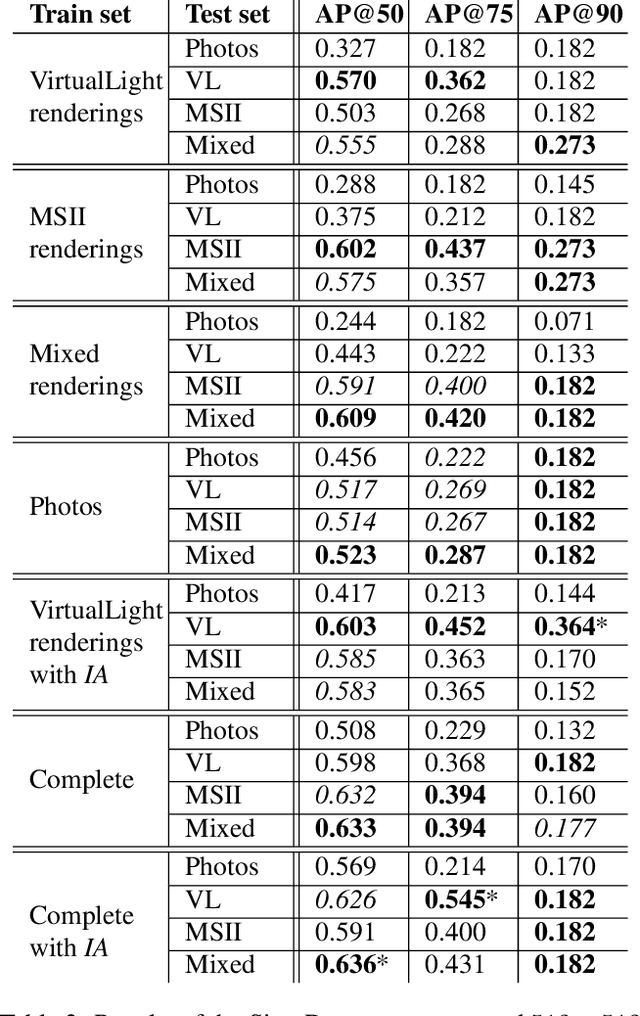
Motivated by the challenges of the Digital Ancient Near Eastern Studies (DANES) community, we develop digital tools for processing cuneiform script being a 3D script imprinted into clay tablets used for more than three millennia and at least eight major languages. It consists of thousands of characters that have changed over time and space. Photographs are the most common representations usable for machine learning, while ink drawings are prone to interpretation. Best suited 3D datasets that are becoming available. We created and used the HeiCuBeDa and MaiCuBeDa datasets, which consist of around 500 annotated tablets. For our novel OCR-like approach to mixed image data, we provide an additional mapping tool for transferring annotations between 3D renderings and photographs. Our sign localization uses a RepPoints detector to predict the locations of characters as bounding boxes. We use image data from GigaMesh's MSII (curvature, see https://gigamesh.eu) based rendering, Phong-shaded 3D models, and photographs as well as illumination augmentation. The results show that using rendered 3D images for sign detection performs better than other work on photographs. In addition, our approach gives reasonably good results for photographs only, while it is best used for mixed datasets. More importantly, the Phong renderings, and especially the MSII renderings, improve the results on photographs, which is the largest dataset on a global scale.
Exemplar-Free Continual Transformer with Convolutions
Aug 22, 2023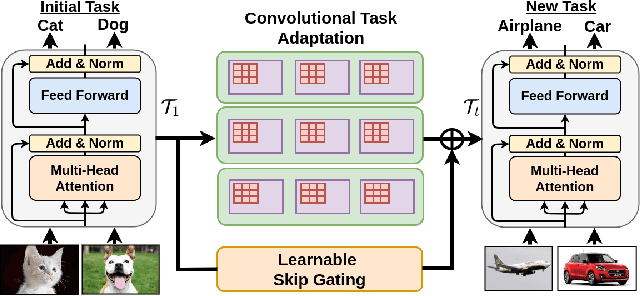
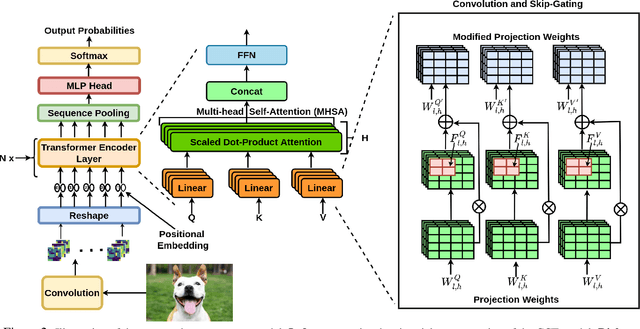
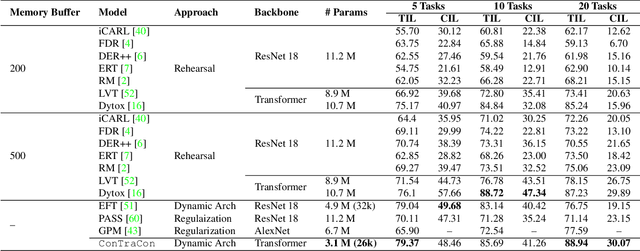
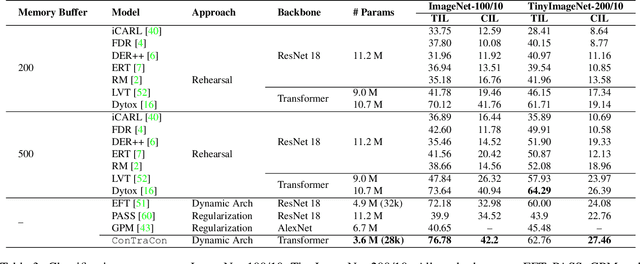
Continual Learning (CL) involves training a machine learning model in a sequential manner to learn new information while retaining previously learned tasks without the presence of previous training data. Although there has been significant interest in CL, most recent CL approaches in computer vision have focused on convolutional architectures only. However, with the recent success of vision transformers, there is a need to explore their potential for CL. Although there have been some recent CL approaches for vision transformers, they either store training instances of previous tasks or require a task identifier during test time, which can be limiting. This paper proposes a new exemplar-free approach for class/task incremental learning called ConTraCon, which does not require task-id to be explicitly present during inference and avoids the need for storing previous training instances. The proposed approach leverages the transformer architecture and involves re-weighting the key, query, and value weights of the multi-head self-attention layers of a transformer trained on a similar task. The re-weighting is done using convolution, which enables the approach to maintain low parameter requirements per task. Additionally, an image augmentation-based entropic task identification approach is used to predict tasks without requiring task-ids during inference. Experiments on four benchmark datasets demonstrate that the proposed approach outperforms several competitive approaches while requiring fewer parameters.
Graph Neural Network-Enhanced Expectation Propagation Algorithm for MIMO Turbo Receivers
Aug 22, 2023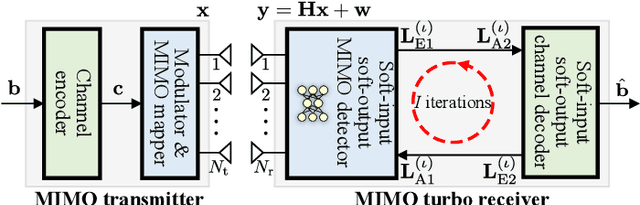
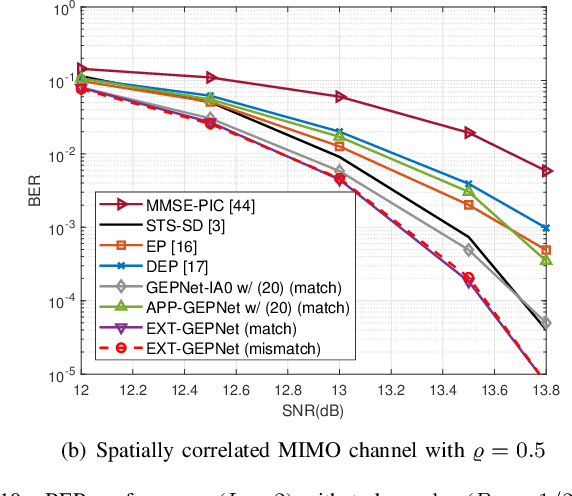
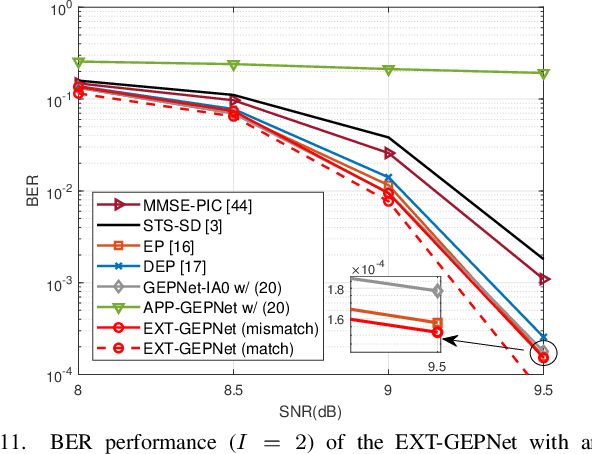
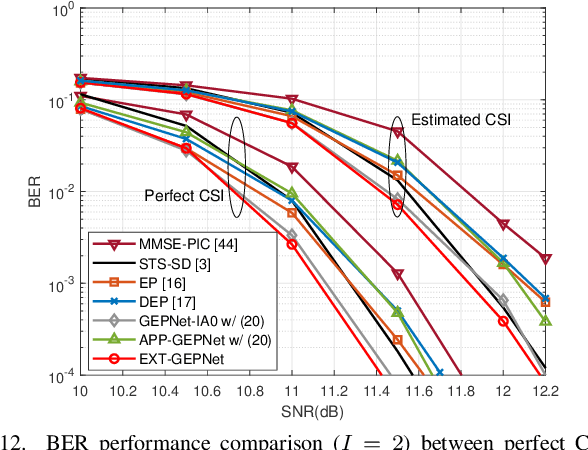
Deep neural networks (NNs) are considered a powerful tool for balancing the performance and complexity of multiple-input multiple-output (MIMO) receivers due to their accurate feature extraction, high parallelism, and excellent inference ability. Graph NNs (GNNs) have recently demonstrated outstanding capability in learning enhanced message passing rules and have shown success in overcoming the drawback of inaccurate Gaussian approximation of expectation propagation (EP)-based MIMO detectors. However, the application of the GNN-enhanced EP detector to MIMO turbo receivers is underexplored and non-trivial due to the requirement of extrinsic information for iterative processing. This paper proposes a GNN-enhanced EP algorithm for MIMO turbo receivers, which realizes the turbo principle of generating extrinsic information from the MIMO detector through a specially designed training procedure. Additionally, an edge pruning strategy is designed to eliminate redundant connections in the original fully connected model of the GNN utilizing the correlation information inherently from the EP algorithm. Edge pruning reduces the computational cost dramatically and enables the network to focus more attention on the weights that are vital for performance. Simulation results and complexity analysis indicate that the proposed MIMO turbo receiver outperforms the EP turbo approaches by over 1 dB at the bit error rate of $10^{-5}$, exhibits performance equivalent to state-of-the-art receivers with 2.5 times shorter running time, and adapts to various scenarios.
A LiDAR-Inertial SLAM Tightly-Coupled with Dropout-Tolerant GNSS Fusion for Autonomous Mine Service Vehicles
Aug 22, 2023
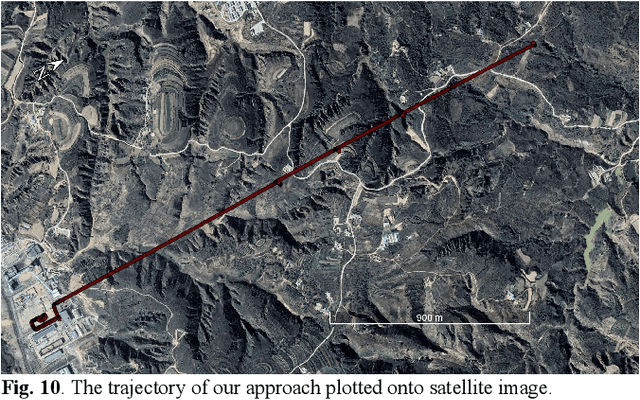


Multi-modal sensor integration has become a crucial prerequisite for the real-world navigation systems. Recent studies have reported successful deployment of such system in many fields. However, it is still challenging for navigation tasks in mine scenes due to satellite signal dropouts, degraded perception, and observation degeneracy. To solve this problem, we propose a LiDAR-inertial odometry method in this paper, utilizing both Kalman filter and graph optimization. The front-end consists of multiple parallel running LiDAR-inertial odometries, where the laser points, IMU, and wheel odometer information are tightly fused in an error-state Kalman filter. Instead of the commonly used feature points, we employ surface elements for registration. The back-end construct a pose graph and jointly optimize the pose estimation results from inertial, LiDAR odometry, and global navigation satellite system (GNSS). Since the vehicle has a long operation time inside the tunnel, the largely accumulated drift may be not fully by the GNSS measurements. We hereby leverage a loop closure based re-initialization process to achieve full alignment. In addition, the system robustness is improved through handling data loss, stream consistency, and estimation error. The experimental results show that our system has a good tolerance to the long-period degeneracy with the cooperation different LiDARs and surfel registration, achieving meter-level accuracy even for tens of minutes running during GNSS dropouts.
Convergence of mean-field Langevin dynamics: Time and space discretization, stochastic gradient, and variance reduction
Jun 12, 2023
The mean-field Langevin dynamics (MFLD) is a nonlinear generalization of the Langevin dynamics that incorporates a distribution-dependent drift, and it naturally arises from the optimization of two-layer neural networks via (noisy) gradient descent. Recent works have shown that MFLD globally minimizes an entropy-regularized convex functional in the space of measures. However, all prior analyses assumed the infinite-particle or continuous-time limit, and cannot handle stochastic gradient updates. We provide an general framework to prove a uniform-in-time propagation of chaos for MFLD that takes into account the errors due to finite-particle approximation, time-discretization, and stochastic gradient approximation. To demonstrate the wide applicability of this framework, we establish quantitative convergence rate guarantees to the regularized global optimal solution under (i) a wide range of learning problems such as neural network in the mean-field regime and MMD minimization, and (ii) different gradient estimators including SGD and SVRG. Despite the generality of our results, we achieve an improved convergence rate in both the SGD and SVRG settings when specialized to the standard Langevin dynamics.
HrSegNet : Real-time High-Resolution Neural Network with Semantic Guidance for Crack Segmentation
Jul 01, 2023
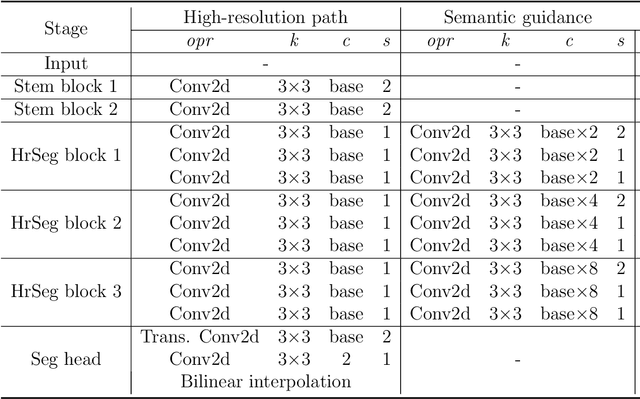
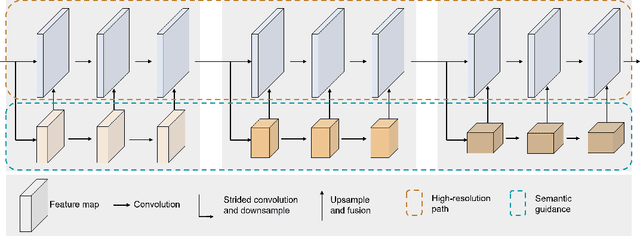
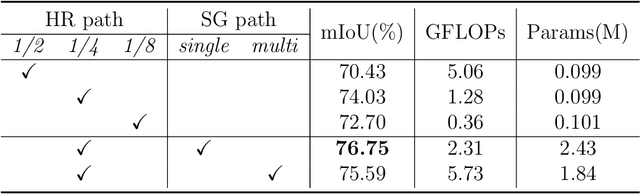
Through extensive research on deep learning in recent years and its application in construction, crack detection has evolved rapidly from rough detection at the image-level and patch-level to fine-grained detection at the pixel-level, which better suits the nature of this field. Despite numerous existing studies utilizing off-the-shelf deep learning models or enhancing them, these models are not always effective or efficient in real-world applications. In order to bridge this gap, we propose a High-resolution model with Semantic guidance, specifically designed for real-time crack segmentation, referred to as HrSegNet. Our model maintains high resolution throughout the entire process, as opposed to recovering from low-resolution features to high-resolution ones, thereby maximizing the preservation of crack details. Moreover, to enhance the context information, we use low-resolution semantic features to guide the reconstruction of high-resolution features. To ensure the efficiency of the algorithm, we design a simple yet effective method to control the computation cost of the entire model by controlling the capacity of high-resolution channels, while providing the model with extremely strong scalability. Extensive quantitative and qualitative evaluations demonstrate that our proposed HrSegNet has exceptional crack segmentation capabilities, and that maintaining high resolution and semantic guidance are crucial to the final prediction. Compared to state-of-the-art segmentation models, HrSegNet achieves the best trade-off between efficiency and effectiveness. Specifically, on the crack dataset CrackSeg9k, our fastest model HrSegNet-B16 achieves a speed of 182 FPS with 78.43% mIoU, while our most accurate model HrSegNet-B48 achieves 80.32% mIoU with an inference speed of 140.3 FPS.