 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Nexus sine qua non: Essentially connected neural networks for spatial-temporal forecasting of multivariate time series
Jul 04, 2023
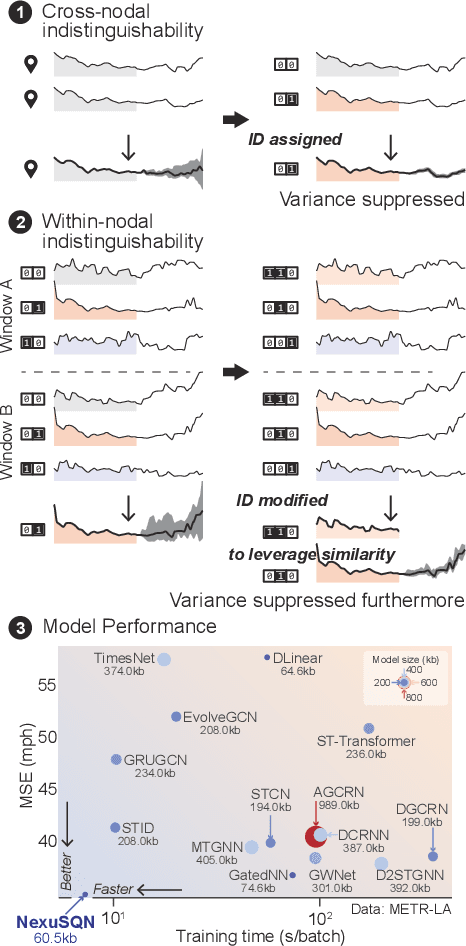
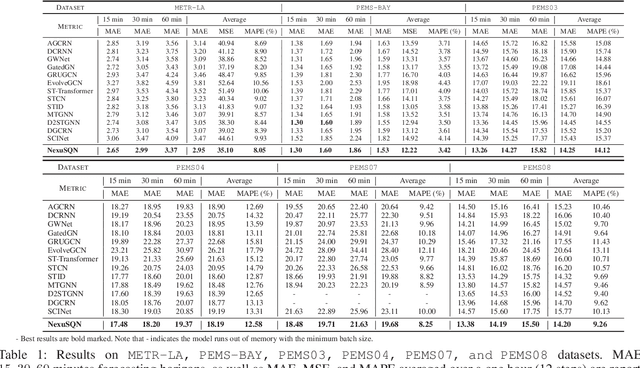
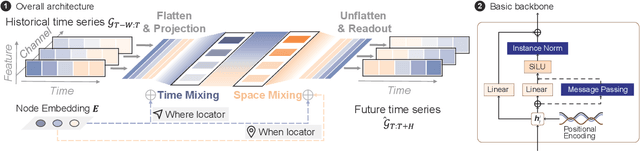
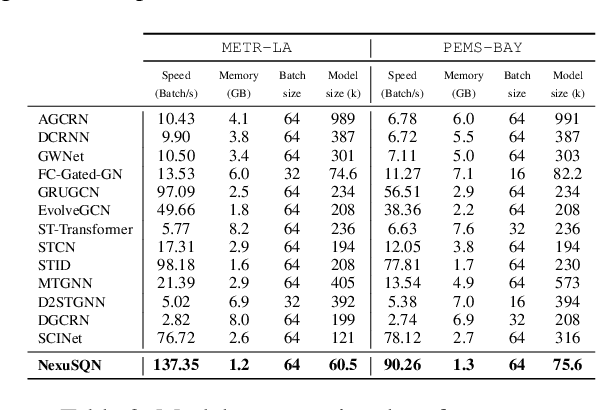
Modeling and forecasting multivariate time series not only facilitates the decision making of practitioners, but also deepens our scientific understanding of the underlying dynamical systems. Spatial-temporal graph neural networks (STGNNs) are emerged as powerful predictors and have become the de facto models for learning spatiotemporal representations in recent years. However, existing architectures of STGNNs tend to be complicated by stacking a series of fancy layers. The designed models could be either redundant or enigmatic, which pose great challenges on their complexity and scalability. Such concerns prompt us to re-examine the designs of modern STGNNs and identify core principles that contribute to a powerful and efficient neural predictor. Here we present a compact predictive model that is fully defined by a dense encoder-decoder and a message-passing layer, powered by node identifications, without any complex sequential modules, e.g., TCNs, RNNs, and Transformers. Empirical results demonstrate how a simple and elegant model with proper inductive basis can compare favorably w.r.t. the state of the art with elaborate designs, while being much more interpretable and computationally efficient for spatial-temporal forecasting problem. We hope our findings would open new horizons for future studies to revisit the design of more concise neural forecasting architectures.
TS-MoCo: Time-Series Momentum Contrast for Self-Supervised Physiological Representation Learning
Jun 10, 2023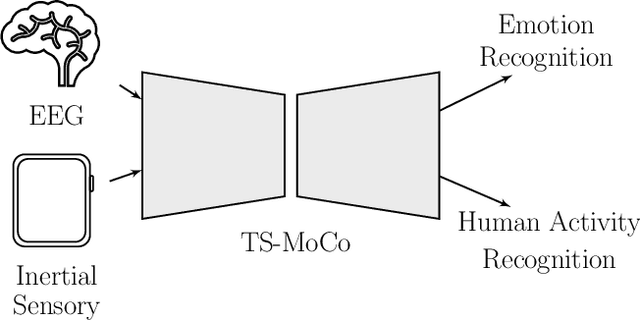
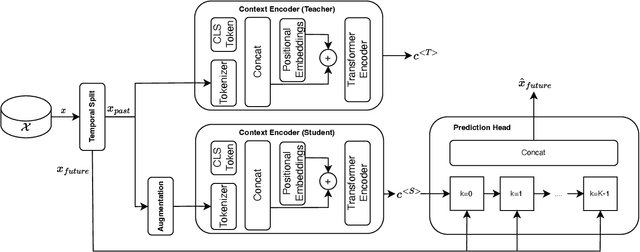

Limited availability of labeled physiological data often prohibits the use of powerful supervised deep learning models in the biomedical machine intelligence domain. We approach this problem and propose a novel encoding framework that relies on self-supervised learning with momentum contrast to learn representations from multivariate time-series of various physiological domains without needing labels. Our model uses a transformer architecture that can be easily adapted to classification problems by optimizing a linear output classification layer. We experimentally evaluate our framework using two publicly available physiological datasets from different domains, i.e., human activity recognition from embedded inertial sensory and emotion recognition from electroencephalography. We show that our self-supervised learning approach can indeed learn discriminative features which can be exploited in downstream classification tasks. Our work enables the development of domain-agnostic intelligent systems that can effectively analyze multivariate time-series data from physiological domains.
Differentiable Robust Model Predictive Control
Aug 16, 2023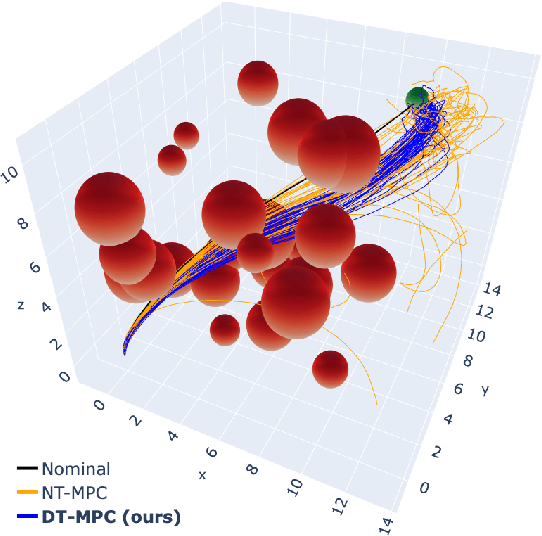


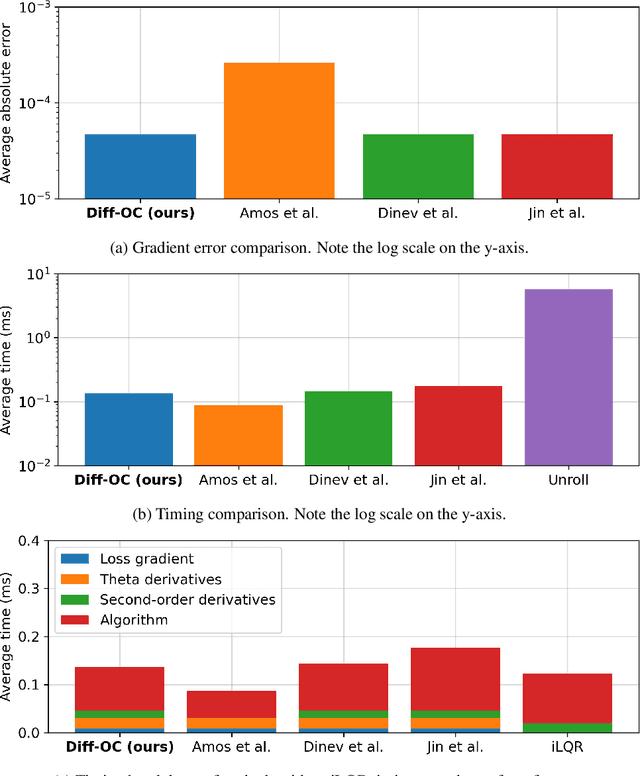
Deterministic model predictive control (MPC), while powerful, is often insufficient for effectively controlling autonomous systems in the real-world. Factors such as environmental noise and model error can cause deviations from the expected nominal performance. Robust MPC algorithms aim to bridge this gap between deterministic and uncertain control. However, these methods are often excessively difficult to tune for robustness due to the nonlinear and non-intuitive effects that controller parameters have on performance. To address this challenge, a unifying perspective on differentiable optimization for control is presented, which enables derivation of a general, differentiable tube-based MPC algorithm. The proposed approach facilitates the automatic and real-time tuning of robust controllers in the presence of large uncertainties and disturbances.
Robust Asymmetric Loss for Multi-Label Long-Tailed Learning
Aug 10, 2023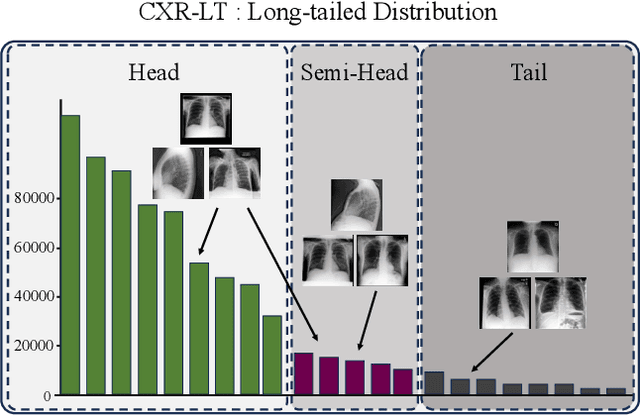
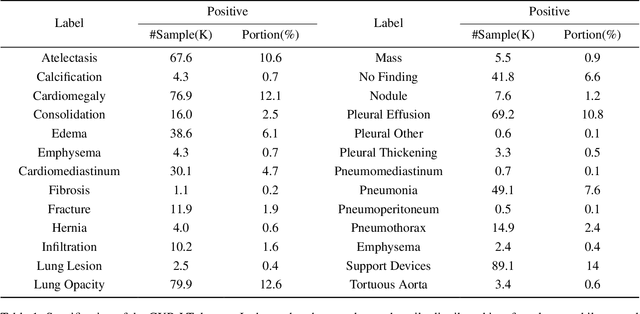
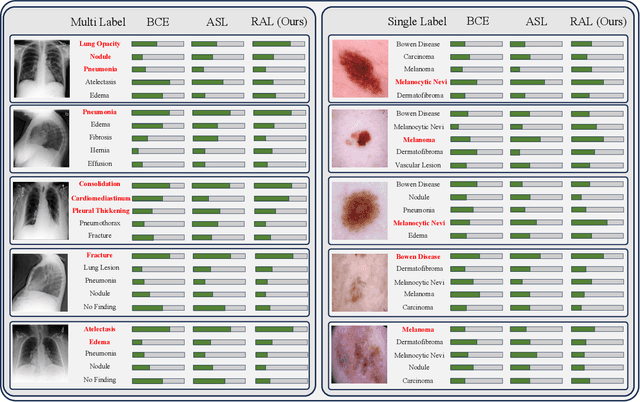
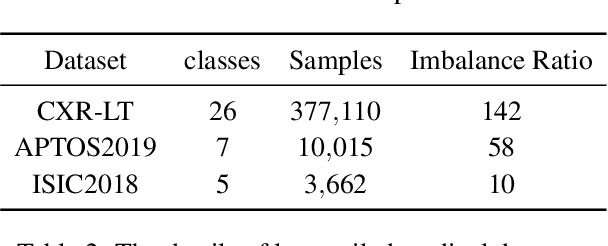
In real medical data, training samples typically show long-tailed distributions with multiple labels. Class distribution of the medical data has a long-tailed shape, in which the incidence of different diseases is quite varied, and at the same time, it is not unusual for images taken from symptomatic patients to be multi-label diseases. Therefore, in this paper, we concurrently address these two issues by putting forth a robust asymmetric loss on the polynomial function. Since our loss tackles both long-tailed and multi-label classification problems simultaneously, it leads to a complex design of the loss function with a large number of hyper-parameters. Although a model can be highly fine-tuned due to a large number of hyper-parameters, it is difficult to optimize all hyper-parameters at the same time, and there might be a risk of overfitting a model. Therefore, we regularize the loss function using the Hill loss approach, which is beneficial to be less sensitive against the numerous hyper-parameters so that it reduces the risk of overfitting the model. For this reason, the proposed loss is a generic method that can be applied to most medical image classification tasks and does not make the training process more time-consuming. We demonstrate that the proposed robust asymmetric loss performs favorably against the long-tailed with multi-label medical image classification in addition to the various long-tailed single-label datasets. Notably, our method achieves Top-5 results on the CXR-LT dataset of the ICCV CVAMD 2023 competition. We opensource our implementation of the robust asymmetric loss in the public repository: https://github.com/kalelpark/RAL.
Bridging High-Quality Audio and Video via Language for Sound Effects Retrieval from Visual Queries
Aug 17, 2023
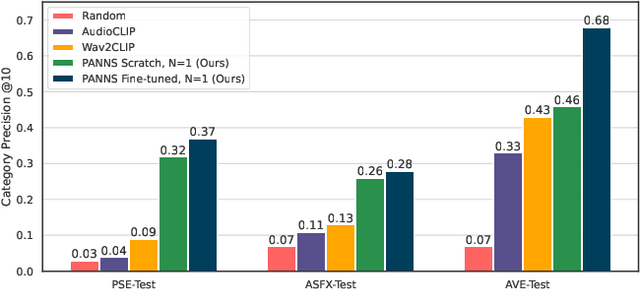
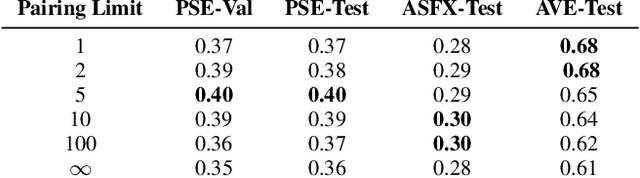
Finding the right sound effects (SFX) to match moments in a video is a difficult and time-consuming task, and relies heavily on the quality and completeness of text metadata. Retrieving high-quality (HQ) SFX using a video frame directly as the query is an attractive alternative, removing the reliance on text metadata and providing a low barrier to entry for non-experts. Due to the lack of HQ audio-visual training data, previous work on audio-visual retrieval relies on YouTube (in-the-wild) videos of varied quality for training, where the audio is often noisy and the video of amateur quality. As such it is unclear whether these systems would generalize to the task of matching HQ audio to production-quality video. To address this, we propose a multimodal framework for recommending HQ SFX given a video frame by (1) leveraging large language models and foundational vision-language models to bridge HQ audio and video to create audio-visual pairs, resulting in a highly scalable automatic audio-visual data curation pipeline; and (2) using pre-trained audio and visual encoders to train a contrastive learning-based retrieval system. We show that our system, trained using our automatic data curation pipeline, significantly outperforms baselines trained on in-the-wild data on the task of HQ SFX retrieval for video. Furthermore, while the baselines fail to generalize to this task, our system generalizes well from clean to in-the-wild data, outperforming the baselines on a dataset of YouTube videos despite only being trained on the HQ audio-visual pairs. A user study confirms that people prefer SFX retrieved by our system over the baseline 67% of the time both for HQ and in-the-wild data. Finally, we present ablations to determine the impact of model and data pipeline design choices on downstream retrieval performance. Please visit our project website to listen to and view our SFX retrieval results.
Causal discovery for time series with constraint-based model and PMIME measure
May 31, 2023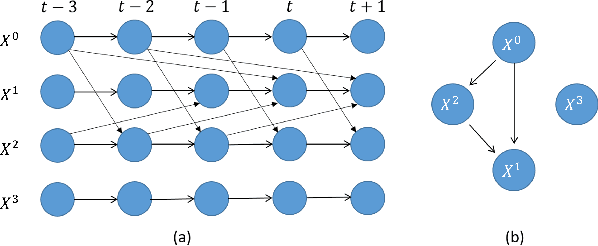
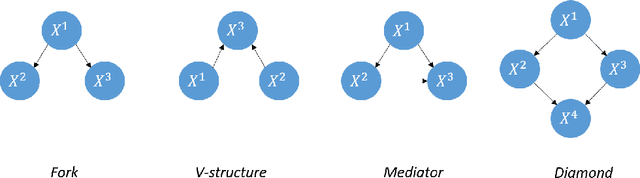
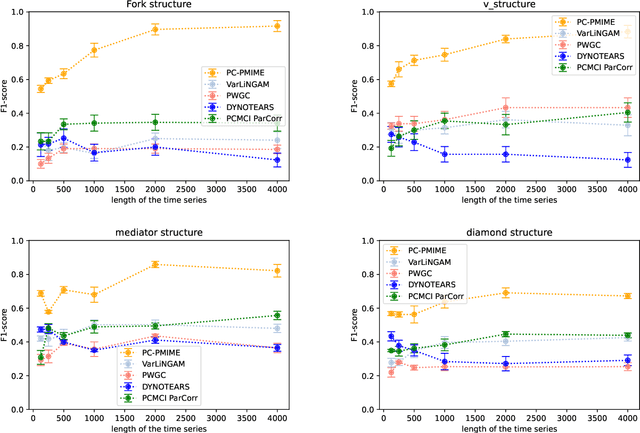
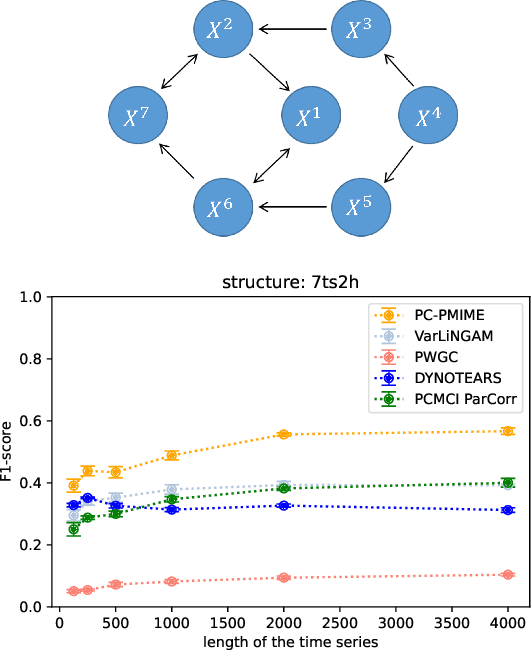
Causality defines the relationship between cause and effect. In multivariate time series field, this notion allows to characterize the links between several time series considering temporal lags. These phenomena are particularly important in medicine to analyze the effect of a drug for example, in manufacturing to detect the causes of an anomaly in a complex system or in social sciences... Most of the time, studying these complex systems is made through correlation only. But correlation can lead to spurious relationships. To circumvent this problem, we present in this paper a novel approach for discovering causality in time series data that combines a causal discovery algorithm with an information theoretic-based measure. Hence the proposed method allows inferring both linear and non-linear relationships and building the underlying causal graph. We evaluate the performance of our approach on several simulated data sets, showing promising results.
Unified Matrix Factorization with Dynamic Multi-view Clustering
Aug 13, 2023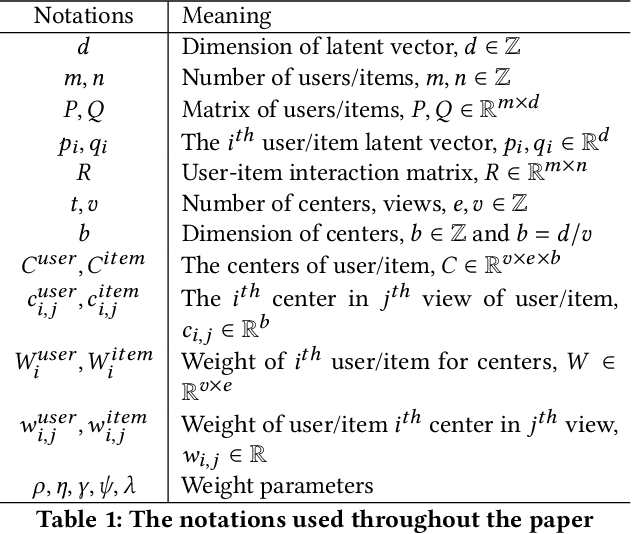
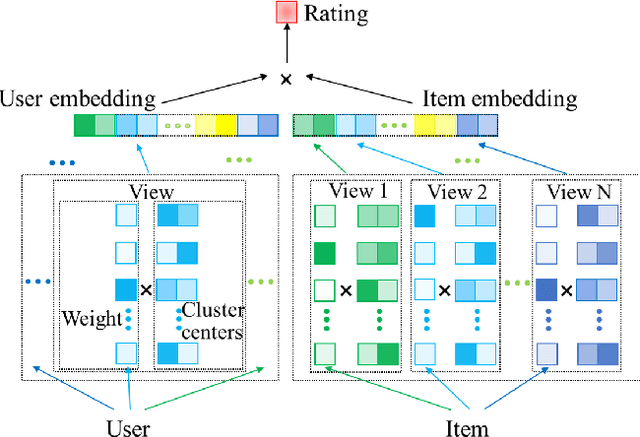

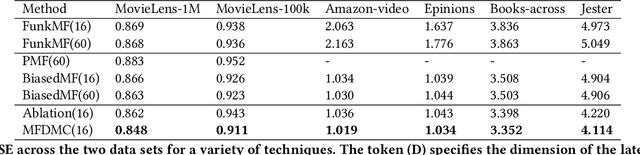
Matrix factorization (MF) is a classical collaborative filtering algorithm for recommender systems. It decomposes the user-item interaction matrix into a product of low-dimensional user representation matrix and item representation matrix. In typical recommendation scenarios, the user-item interaction paradigm is usually a two-stage process and requires static clustering analysis of the obtained user and item representations. The above process, however, is time and computationally intensive, making it difficult to apply in real-time to e-commerce or Internet of Things environments with billions of users and trillions of items. To address this, we propose a unified matrix factorization method based on dynamic multi-view clustering (MFDMC) that employs an end-to-end training paradigm. Specifically, in each view, a user/item representation is regarded as a weighted projection of all clusters. The representation of each cluster is learnable, enabling the dynamic discarding of bad clusters. Furthermore, we employ multi-view clustering to represent multiple roles of users/items, effectively utilizing the representation space and improving the interpretability of the user/item representations for downstream tasks. Extensive experiments show that our proposed MFDMC achieves state-of-the-art performance on real-world recommendation datasets. Additionally, comprehensive visualization and ablation studies interpretably confirm that our method provides meaningful representations for downstream tasks of users/items.
Towards Validating Long-Term User Feedbacks in Interactive Recommendation Systems
Aug 22, 2023
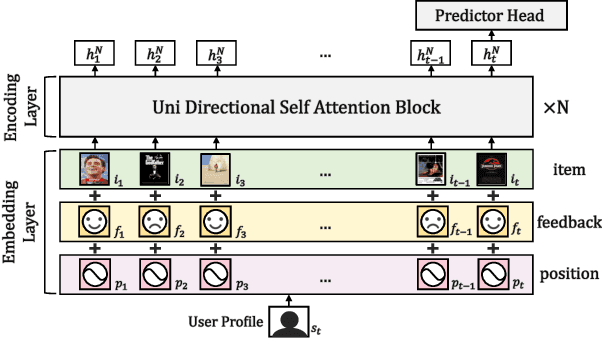
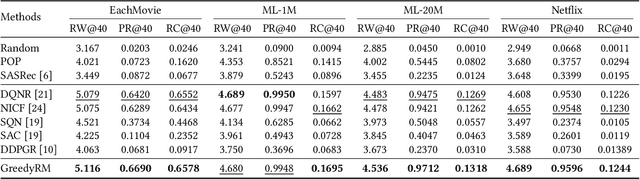
Interactive Recommender Systems (IRSs) have attracted a lot of attention, due to their ability to model interactive processes between users and recommender systems. Numerous approaches have adopted Reinforcement Learning (RL) algorithms, as these can directly maximize users' cumulative rewards. In IRS, researchers commonly utilize publicly available review datasets to compare and evaluate algorithms. However, user feedback provided in public datasets merely includes instant responses (e.g., a rating), with no inclusion of delayed responses (e.g., the dwell time and the lifetime value). Thus, the question remains whether these review datasets are an appropriate choice to evaluate the long-term effects of the IRS. In this work, we revisited experiments on IRS with review datasets and compared RL-based models with a simple reward model that greedily recommends the item with the highest one-step reward. Following extensive analysis, we can reveal three main findings: First, a simple greedy reward model consistently outperforms RL-based models in maximizing cumulative rewards. Second, applying higher weighting to long-term rewards leads to a degradation of recommendation performance. Third, user feedbacks have mere long-term effects on the benchmark datasets. Based on our findings, we conclude that a dataset has to be carefully verified and that a simple greedy baseline should be included for a proper evaluation of RL-based IRS approaches.
PatchBackdoor: Backdoor Attack against Deep Neural Networks without Model Modification
Aug 22, 2023Backdoor attack is a major threat to deep learning systems in safety-critical scenarios, which aims to trigger misbehavior of neural network models under attacker-controlled conditions. However, most backdoor attacks have to modify the neural network models through training with poisoned data and/or direct model editing, which leads to a common but false belief that backdoor attack can be easily avoided by properly protecting the model. In this paper, we show that backdoor attacks can be achieved without any model modification. Instead of injecting backdoor logic into the training data or the model, we propose to place a carefully-designed patch (namely backdoor patch) in front of the camera, which is fed into the model together with the input images. The patch can be trained to behave normally at most of the time, while producing wrong prediction when the input image contains an attacker-controlled trigger object. Our main techniques include an effective training method to generate the backdoor patch and a digital-physical transformation modeling method to enhance the feasibility of the patch in real deployments. Extensive experiments show that PatchBackdoor can be applied to common deep learning models (VGG, MobileNet, ResNet) with an attack success rate of 93% to 99% on classification tasks. Moreover, we implement PatchBackdoor in real-world scenarios and show that the attack is still threatening.
Pose2Gait: Extracting Gait Features from Monocular Video of Individuals with Dementia
Aug 22, 2023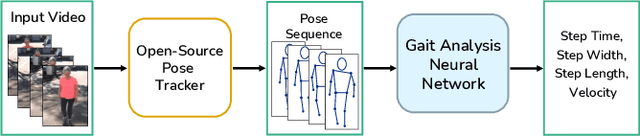

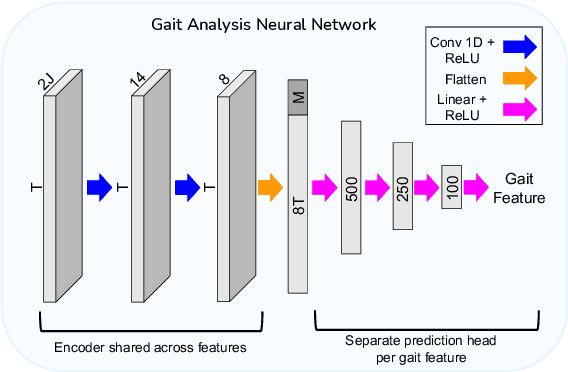

Video-based ambient monitoring of gait for older adults with dementia has the potential to detect negative changes in health and allow clinicians and caregivers to intervene early to prevent falls or hospitalizations. Computer vision-based pose tracking models can process video data automatically and extract joint locations; however, publicly available models are not optimized for gait analysis on older adults or clinical populations. In this work we train a deep neural network to map from a two dimensional pose sequence, extracted from a video of an individual walking down a hallway toward a wall-mounted camera, to a set of three-dimensional spatiotemporal gait features averaged over the walking sequence. The data of individuals with dementia used in this work was captured at two sites using a wall-mounted system to collect the video and depth information used to train and evaluate our model. Our Pose2Gait model is able to extract velocity and step length values from the video that are correlated with the features from the depth camera, with Spearman's correlation coefficients of .83 and .60 respectively, showing that three dimensional spatiotemporal features can be predicted from monocular video. Future work remains to improve the accuracy of other features, such as step time and step width, and test the utility of the predicted values for detecting meaningful changes in gait during longitudinal ambient monitoring.