 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Probabilistic Causal Discovery, Inference & Explanations for Autonomous Drones in Mine Surveying Tasks
Aug 19, 2023
Causal modelling offers great potential to provide autonomous agents the ability to understand the data-generation process that governs their interactions with the world. Such models capture formal knowledge as well as probabilistic representations of noise and uncertainty typically encountered by autonomous robots in real-world environments. Thus, causality can aid autonomous agents in making decisions and explaining outcomes, but deploying causality in such a manner introduces new challenges. Here we identify challenges relating to causality in the context of a drone system operating in a salt mine. Such environments are challenging for autonomous agents because of the presence of confounders, non-stationarity, and a difficulty in building complete causal models ahead of time. To address these issues, we propose a probabilistic causal framework consisting of: causally-informed POMDP planning, online SCM adaptation, and post-hoc counterfactual explanations. Further, we outline planned experimentation to evaluate the framework integrated with a drone system in simulated mine environments and on a real-world mine dataset.
An Evaluation of Three Distance Measurement Technologies for Flying Light Specks
Aug 19, 2023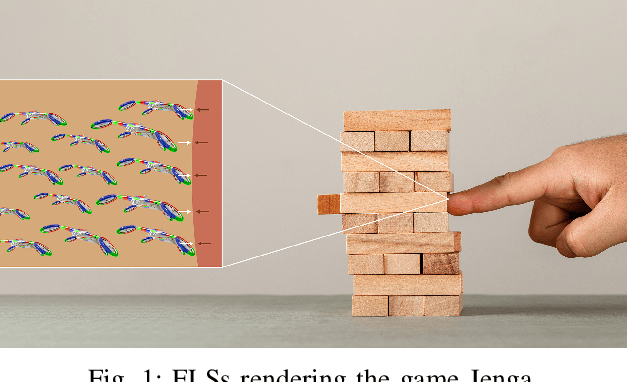
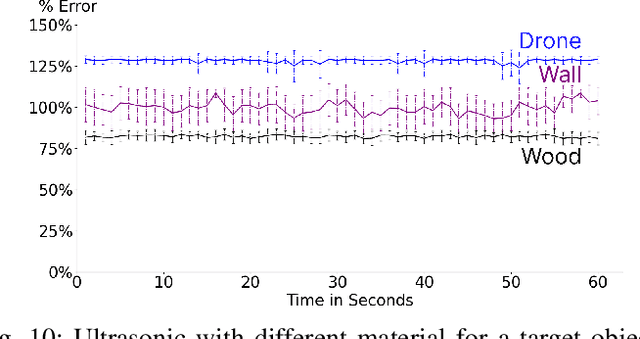

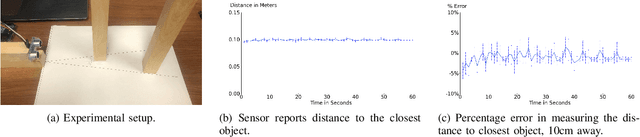
This study evaluates the accuracy of three different types of time-of-flight sensors to measure distance. We envision the possible use of these sensors to localize swarms of flying light specks (FLSs) to illuminate objects and avatars of a metaverse. An FLS is a miniature-sized drone configured with RGB light sources. It is unable to illuminate a point cloud by itself. However, the inter-FLS relationship effect of an organizational framework will compensate for the simplicity of each individual FLS, enabling a swarm of cooperating FLSs to illuminate complex shapes and render haptic interactions. Distance between FLSs is an important criterion of the inter-FLS relationship. We consider sensors that use radio frequency (UWB), infrared light (IR), and sound (ultrasonic) to quantify this metric. Obtained results show only one sensor is able to measure distances as small as 1 cm with a high accuracy. A sensor may require a calibration process that impacts its accuracy in measuring distance.
MeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance
Aug 19, 2023
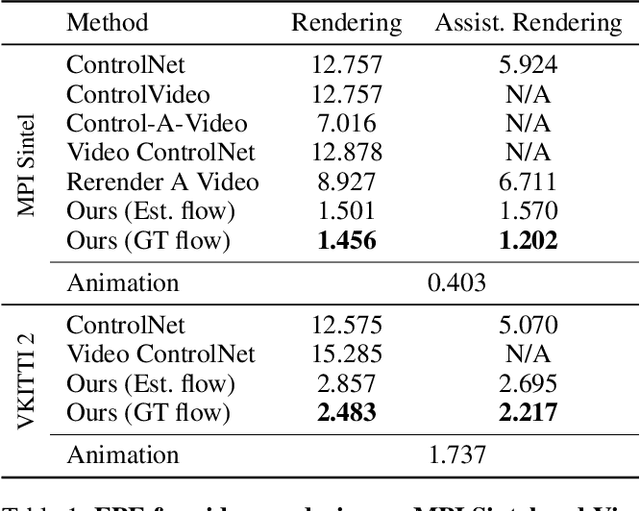
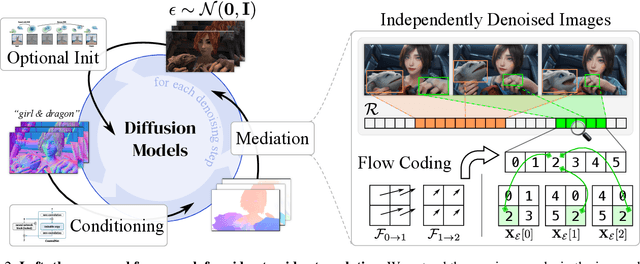
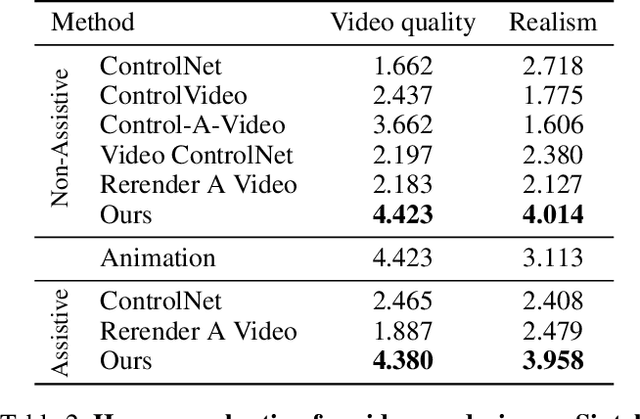
This study introduces an efficient and effective method, MeDM, that utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models. Through extensive qualitative, quantitative, and subjective experiments on various benchmarks, the study demonstrates the effectiveness and superiority of the proposed approach.
Real-time GeoAI for High-resolution Mapping and Segmentation of Arctic Permafrost Features
Jun 08, 2023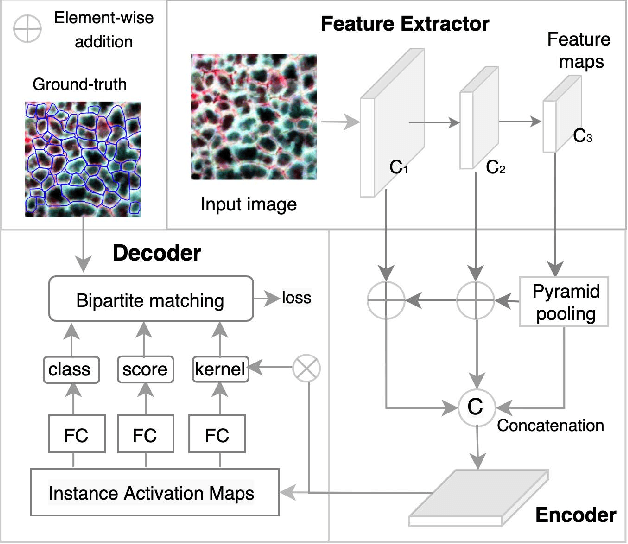
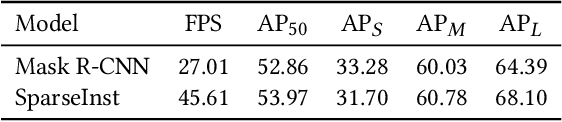
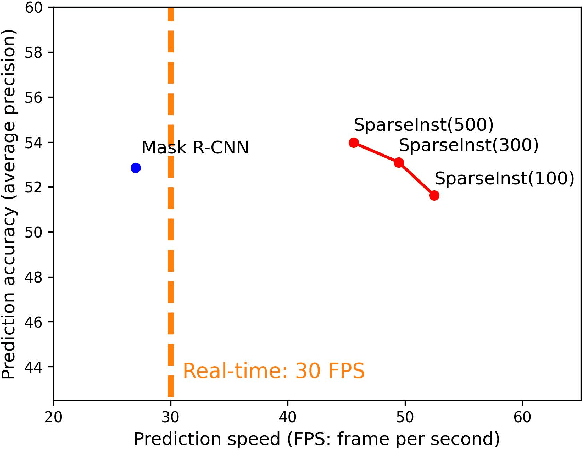

This paper introduces a real-time GeoAI workflow for large-scale image analysis and the segmentation of Arctic permafrost features at a fine-granularity. Very high-resolution (0.5m) commercial imagery is used in this analysis. To achieve real-time prediction, our workflow employs a lightweight, deep learning-based instance segmentation model, SparseInst, which introduces and uses Instance Activation Maps to accurately locate the position of objects within the image scene. Experimental results show that the model can achieve better accuracy of prediction at a much faster inference speed than the popular Mask-RCNN model.
RadGraph2: Modeling Disease Progression in Radiology Reports via Hierarchical Information Extraction
Aug 09, 2023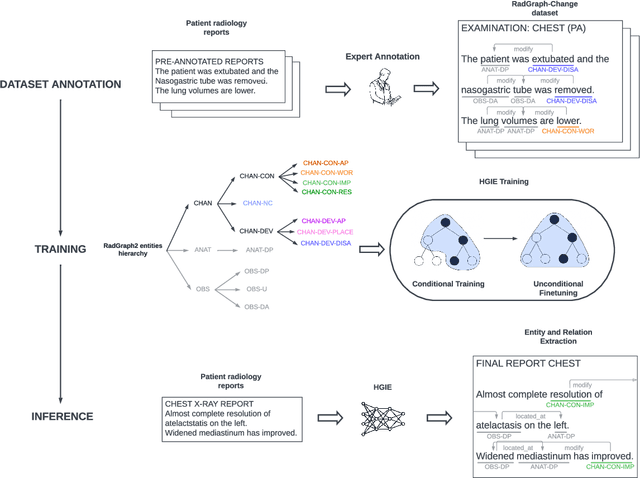
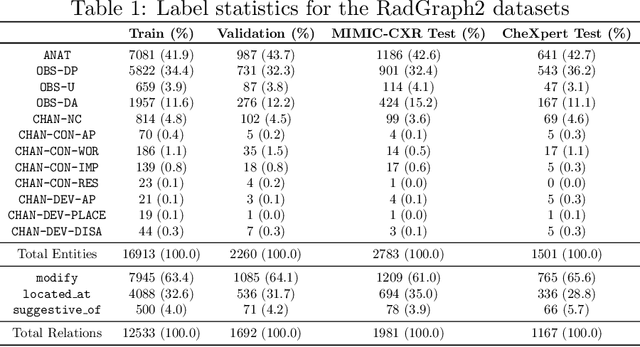
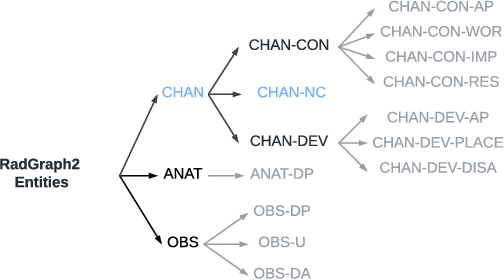
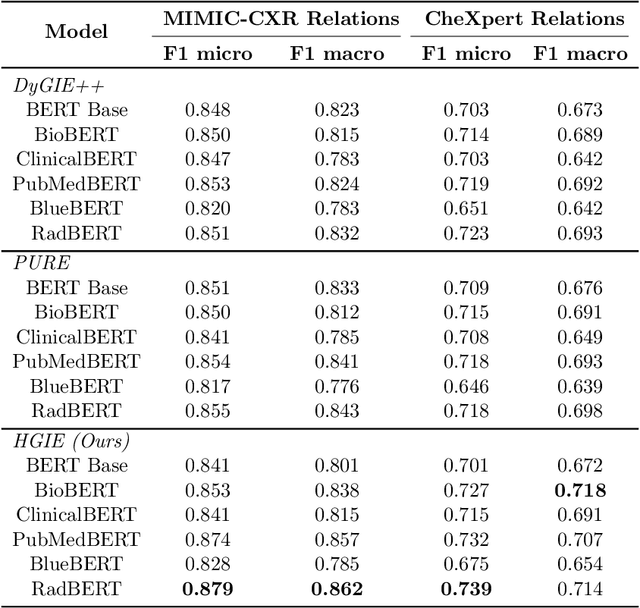
We present RadGraph2, a novel dataset for extracting information from radiology reports that focuses on capturing changes in disease state and device placement over time. We introduce a hierarchical schema that organizes entities based on their relationships and show that using this hierarchy during training improves the performance of an information extraction model. Specifically, we propose a modification to the DyGIE++ framework, resulting in our model HGIE, which outperforms previous models in entity and relation extraction tasks. We demonstrate that RadGraph2 enables models to capture a wider variety of findings and perform better at relation extraction compared to those trained on the original RadGraph dataset. Our work provides the foundation for developing automated systems that can track disease progression over time and develop information extraction models that leverage the natural hierarchy of labels in the medical domain.
Conformer-based Target-Speaker Automatic Speech Recognition for Single-Channel Audio
Aug 09, 2023
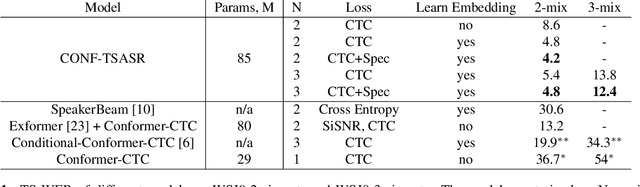
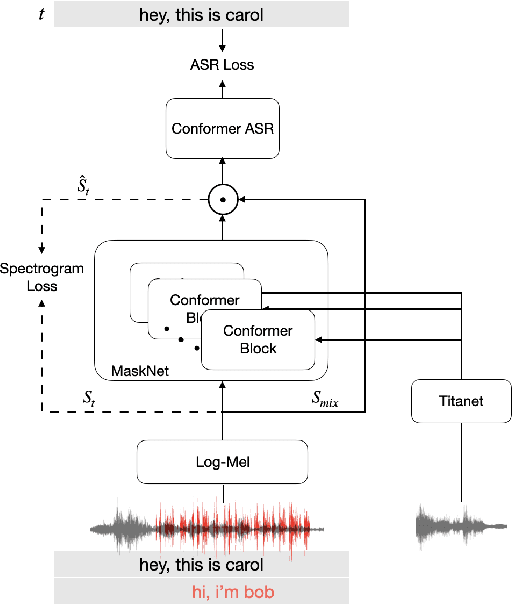
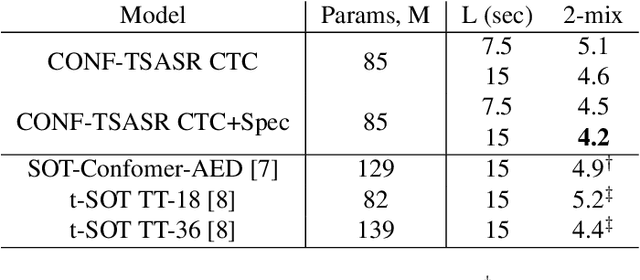
We propose CONF-TSASR, a non-autoregressive end-to-end time-frequency domain architecture for single-channel target-speaker automatic speech recognition (TS-ASR). The model consists of a TitaNet based speaker embedding module, a Conformer based masking as well as ASR modules. These modules are jointly optimized to transcribe a target-speaker, while ignoring speech from other speakers. For training we use Connectionist Temporal Classification (CTC) loss and introduce a scale-invariant spectrogram reconstruction loss to encourage the model better separate the target-speaker's spectrogram from mixture. We obtain state-of-the-art target-speaker word error rate (TS-WER) on WSJ0-2mix-extr (4.2%). Further, we report for the first time TS-WER on WSJ0-3mix-extr (12.4%), LibriSpeech2Mix (4.2%) and LibriSpeech3Mix (7.6%) datasets, establishing new benchmarks for TS-ASR. The proposed model will be open-sourced through NVIDIA NeMo toolkit.
An Intentional Forgetting-Driven Self-Healing Method For Deep Reinforcement Learning Systems
Aug 23, 2023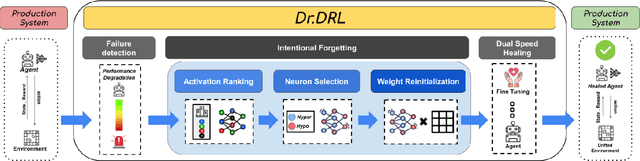
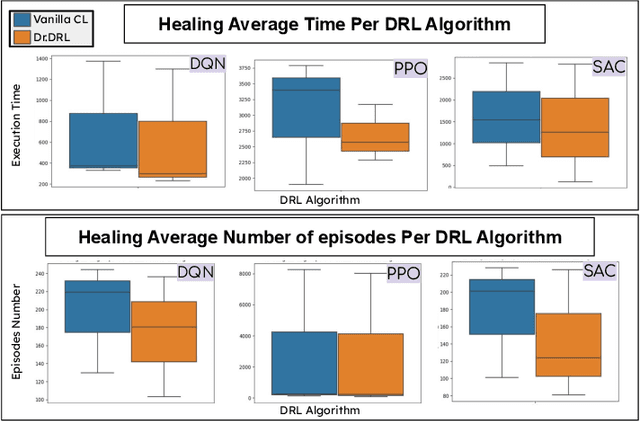
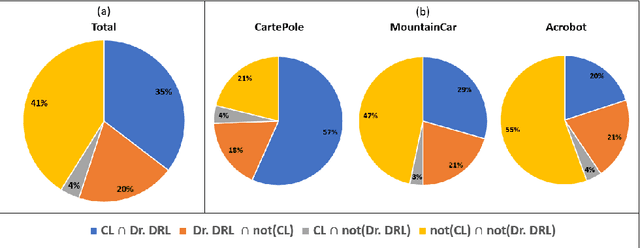
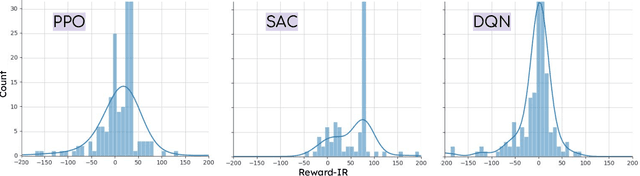
Deep reinforcement learning (DRL) is increasingly applied in large-scale productions like Netflix and Facebook. As with most data-driven systems, DRL systems can exhibit undesirable behaviors due to environmental drifts, which often occur in constantly-changing production settings. Continual Learning (CL) is the inherent self-healing approach for adapting the DRL agent in response to the environment's conditions shifts. However, successive shifts of considerable magnitude may cause the production environment to drift from its original state. Recent studies have shown that these environmental drifts tend to drive CL into long, or even unsuccessful, healing cycles, which arise from inefficiencies such as catastrophic forgetting, warm-starting failure, and slow convergence. In this paper, we propose Dr. DRL, an effective self-healing approach for DRL systems that integrates a novel mechanism of intentional forgetting into vanilla CL to overcome its main issues. Dr. DRL deliberately erases the DRL system's minor behaviors to systematically prioritize the adaptation of the key problem-solving skills. Using well-established DRL algorithms, Dr. DRL is compared with vanilla CL on various drifted environments. Dr. DRL is able to reduce, on average, the healing time and fine-tuning episodes by, respectively, 18.74% and 17.72%. Dr. DRL successfully helps agents to adapt to 19.63% of drifted environments left unsolved by vanilla CL while maintaining and even enhancing by up to 45% the obtained rewards for drifted environments that are resolved by both approaches.
Addressing Selection Bias in Computerized Adaptive Testing: A User-Wise Aggregate Influence Function Approach
Aug 23, 2023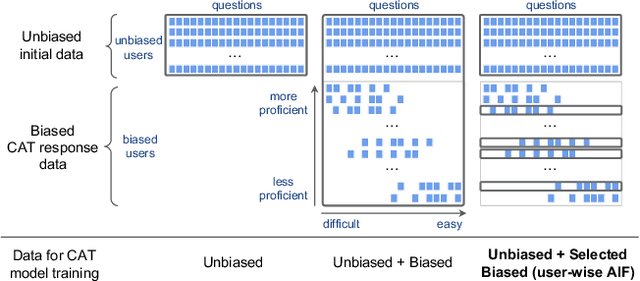


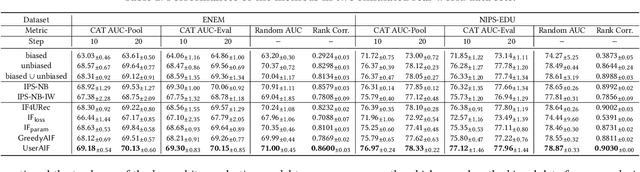
Computerized Adaptive Testing (CAT) is a widely used, efficient test mode that adapts to the examinee's proficiency level in the test domain. CAT requires pre-trained item profiles, for CAT iteratively assesses the student real-time based on the registered items' profiles, and selects the next item to administer using candidate items' profiles. However, obtaining such item profiles is a costly process that involves gathering a large, dense item-response data, then training a diagnostic model on the collected data. In this paper, we explore the possibility of leveraging response data collected in the CAT service. We first show that this poses a unique challenge due to the inherent selection bias introduced by CAT, i.e., more proficient students will receive harder questions. Indeed, when naively training the diagnostic model using CAT response data, we observe that item profiles deviate significantly from the ground-truth. To tackle the selection bias issue, we propose the user-wise aggregate influence function method. Our intuition is to filter out users whose response data is heavily biased in an aggregate manner, as judged by how much perturbation the added data will introduce during parameter estimation. This way, we may enhance the performance of CAT while introducing minimal bias to the item profiles. We provide extensive experiments to demonstrate the superiority of our proposed method based on the three public datasets and one dataset that contains real-world CAT response data.
Selective Concept Models: Permitting Stakeholder Customisation at Test-Time
Jun 14, 2023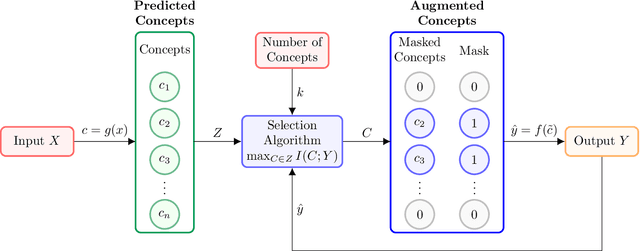
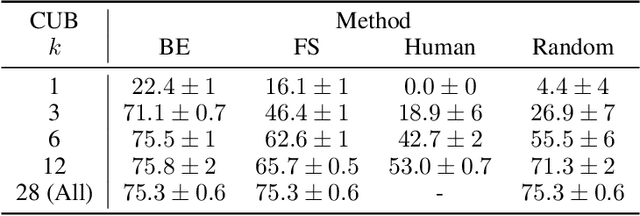
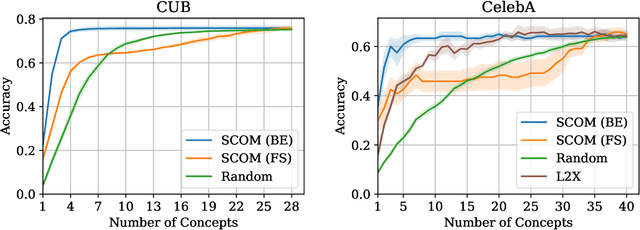

Concept-based models perform prediction using a set of concepts that are interpretable to stakeholders. However, such models often involve a fixed, large number of concepts, which may place a substantial cognitive load on stakeholders. We propose Selective COncept Models (SCOMs) which make predictions using only a subset of concepts and can be customised by stakeholders at test-time according to their preferences. We show that SCOMs only require a fraction of the total concepts to achieve optimal accuracy on multiple real-world datasets. Further, we collect and release a new dataset, CUB-Sel, consisting of human concept set selections for 900 bird images from the popular CUB dataset. Using CUB-Sel, we show that humans have unique individual preferences for the choice of concepts they prefer to reason about, and struggle to identify the most theoretically informative concepts. The customisation and concept selection provided by SCOM improves the efficiency of interpretation and intervention for stakeholders.
Phase Retrieval with Background Information: Decreased References and Efficient Methods
Aug 16, 2023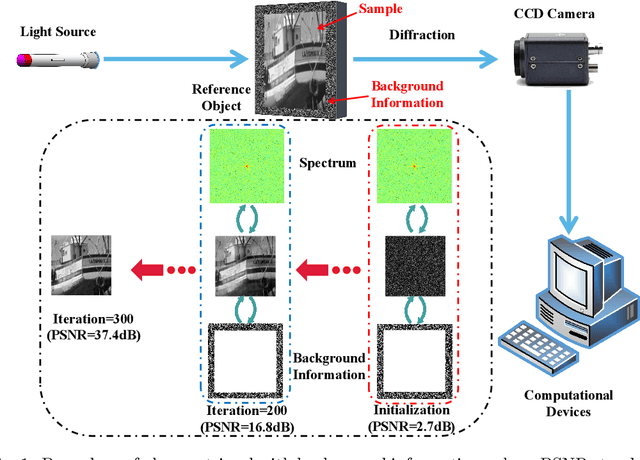
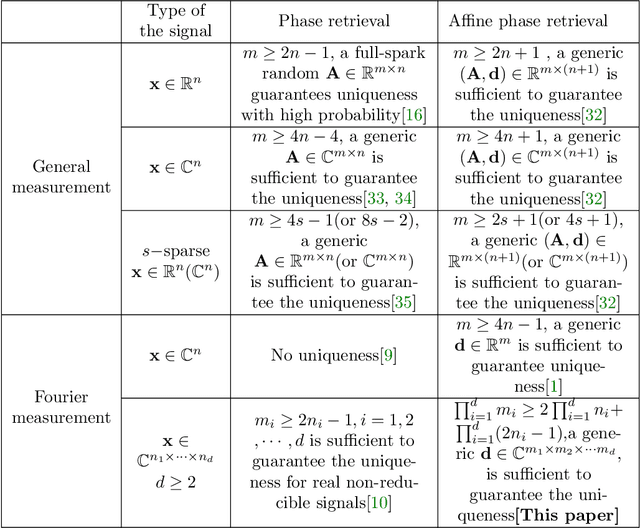
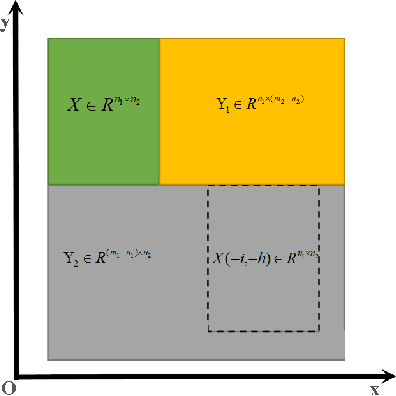
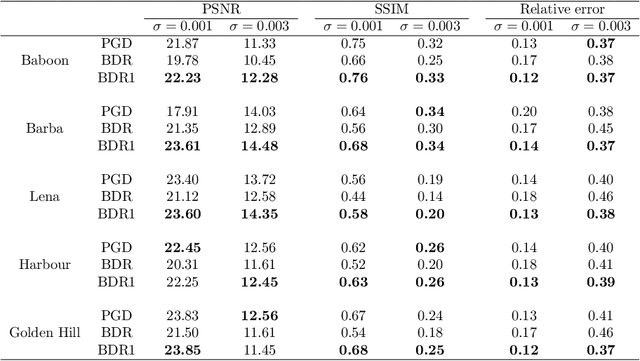
Fourier phase retrieval(PR) is a severely ill-posed inverse problem that arises in various applications. To guarantee a unique solution and relieve the dependence on the initialization, background information can be exploited as a structural priors. However, the requirement for the background information may be challenging when moving to the high-resolution imaging. At the same time, the previously proposed projected gradient descent(PGD) method also demands much background information. In this paper, we present an improved theoretical result about the demand for the background information, along with two Douglas Rachford(DR) based methods. Analytically, we demonstrate that the background required to ensure a unique solution can be decreased by nearly $1/2$ for the 2-D signals compared to the 1-D signals. By generalizing the results into $d$-dimension, we show that the length of the background information more than $(2^{\frac{d+1}{d}}-1)$ folds of the signal is sufficient to ensure the uniqueness. At the same time, we also analyze the stability and robustness of the model when measurements and background information are corrupted by the noise. Furthermore, two methods called Background Douglas-Rachford (BDR) and Convex Background Douglas-Rachford (CBDR) are proposed. BDR which is a kind of non-convex method is proven to have the local R-linear convergence rate under mild assumptions. Instead, CBDR method uses the techniques of convexification and can be proven to own a global convergence guarantee as long as the background information is sufficient. To support this, a new property called F-RIP is established. We test the performance of the proposed methods through simulations as well as real experimental measurements, and demonstrate that they achieve a higher recovery rate with less background information compared to the PGD method.