 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Conformal prediction for multi-dimensional time series by ellipsoidal sets
Mar 06, 2024

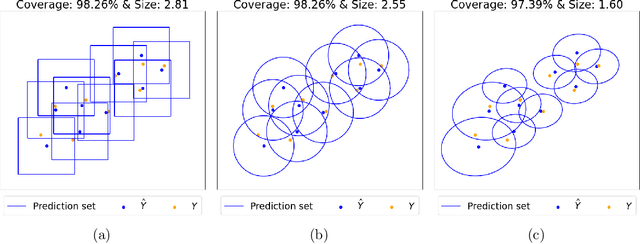
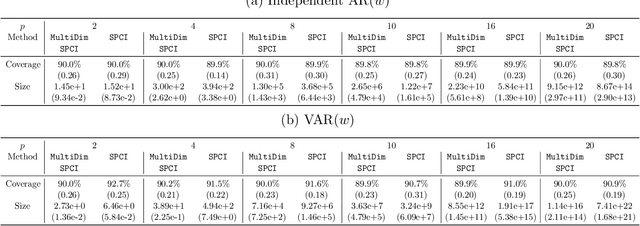
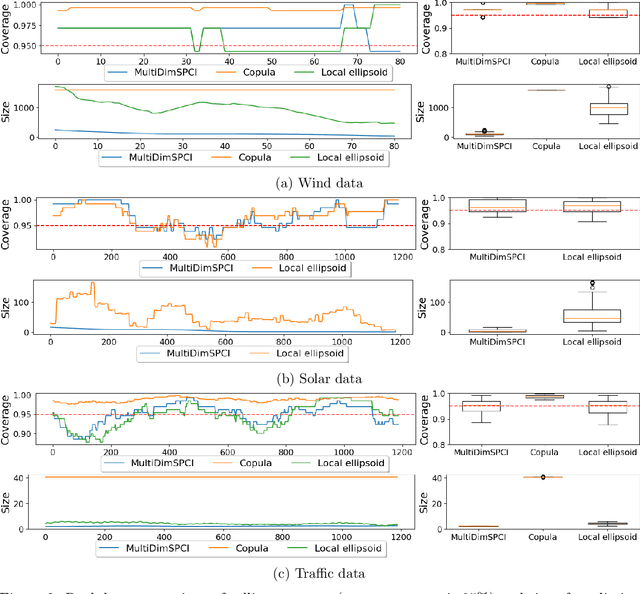
Conformal prediction (CP) has been a popular method for uncertainty quantification because it is distribution-free, model-agnostic, and theoretically sound. For forecasting problems in supervised learning, most CP methods focus on building prediction intervals for univariate responses. In this work, we develop a sequential CP method called $\texttt{MultiDimSPCI}$ that builds prediction regions for a multivariate response, especially in the context of multivariate time series, which are not exchangeable. Theoretically, we estimate finite-sample high-probability bounds on the conditional coverage gap. Empirically, we demonstrate that $\texttt{MultiDimSPCI}$ maintains valid coverage on a wide range of multivariate time series while producing smaller prediction regions than CP and non-CP baselines.
In-context Prompt Learning for Test-time Vision Recognition with Frozen Vision-language Model
Mar 10, 2024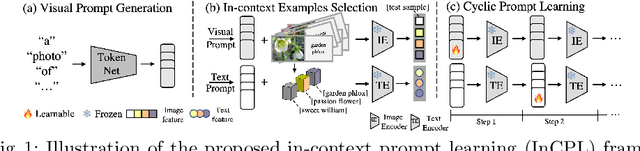

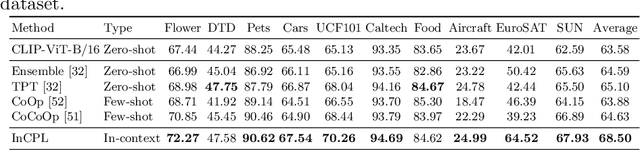
Existing pre-trained vision-language models, e.g., CLIP, have demonstrated impressive zero-shot generalization capabilities in various downstream tasks. However, the performance of these models will degrade significantly when test inputs present different distributions. To this end, we explore the concept of test-time prompt tuning (TTPT), which enables the adaptation of the CLIP model to novel downstream tasks through only one step of optimization on an unsupervised objective that involves the test sample. Motivated by in-context learning within field of natural language processing (NLP), we propose In-Context Prompt Learning (InCPL) for test-time visual recognition task. InCPL involves associating a new test sample with very few or even just one labeled example as its in-context prompt. As a result, it can reliably estimate a label for the test sample, thereby facilitating the model adaptation process. InCPL first employs a token net to represent language descriptions as visual prompts that the vision encoder of a CLIP model can comprehend. Paired with in-context examples, we further propose a context-aware unsupervised loss to optimize test sample-aware visual prompts. This optimization allows a pre-trained, frozen CLIP model to be adapted to a test sample from any task using its learned adaptive prompt. Our method has demonstrated superior performance and achieved state-of-the-art results across various downstream datasets.
RetiGen: A Framework for Generalized Retinal Diagnosis Using Multi-View Fundus Images
Mar 22, 2024This study introduces a novel framework for enhancing domain generalization in medical imaging, specifically focusing on utilizing unlabelled multi-view colour fundus photographs. Unlike traditional approaches that rely on single-view imaging data and face challenges in generalizing across diverse clinical settings, our method leverages the rich information in the unlabelled multi-view imaging data to improve model robustness and accuracy. By incorporating a class balancing method, a test-time adaptation technique and a multi-view optimization strategy, we address the critical issue of domain shift that often hampers the performance of machine learning models in real-world applications. Experiments comparing various state-of-the-art domain generalization and test-time optimization methodologies show that our approach consistently outperforms when combined with existing baseline and state-of-the-art methods. We also show our online method improves all existing techniques. Our framework demonstrates improvements in domain generalization capabilities and offers a practical solution for real-world deployment by facilitating online adaptation to new, unseen datasets. Our code is available at https://github.com/zgy600/RetiGen .
Fundamentals of Delay-Doppler Communications: Practical Implementation and Extensions to OTFS
Mar 21, 2024
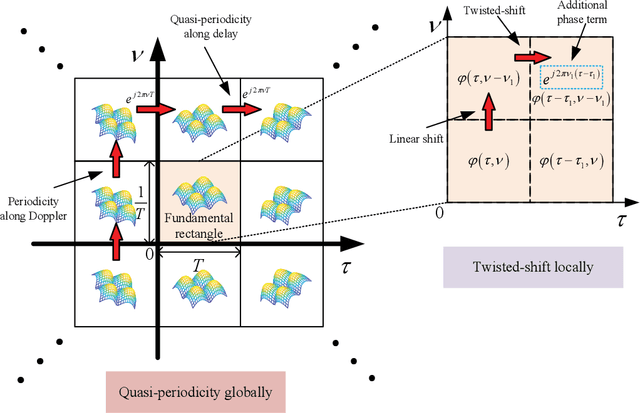
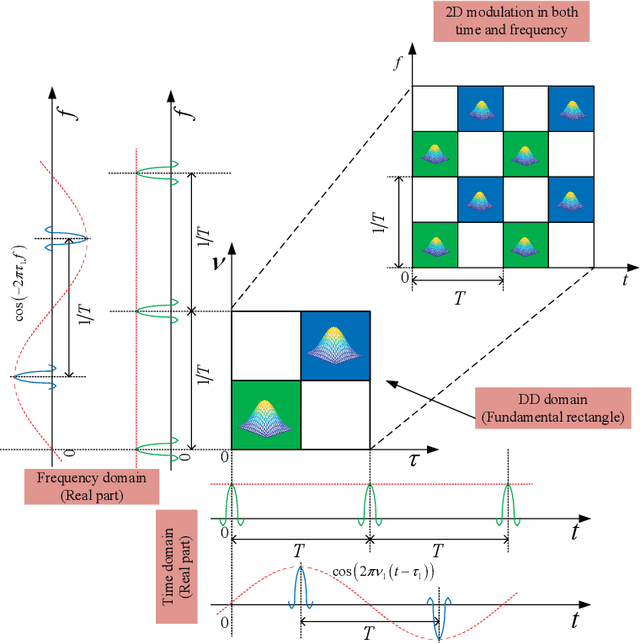
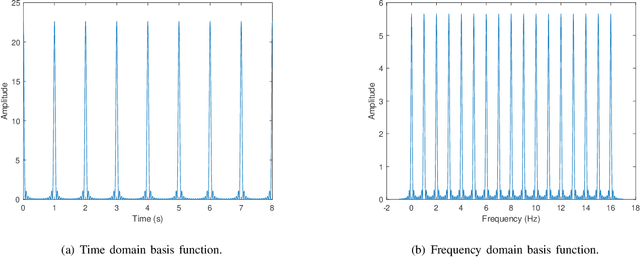
The recently proposed orthogonal time frequency space (OTFS) modulation, which is a typical Delay-Doppler (DD) communication scheme, has attracted significant attention thanks to its appealing performance over doubly-selective channels. In this paper, we present the fundamentals of general DD communications from the viewpoint of the Zak transform. We start our study by constructing DD domain basis functions aligning with the time-frequency (TF)-consistency condition, which are globally quasi-periodic and locally twisted-shifted. We unveil that these features are translated to unique signal structures in both time and frequency, which are beneficial for communication purposes. Then, we focus on the practical implementations of DD Nyquist communications, where we show that rectangular windows achieve perfect DD orthogonality, while truncated periodic signals can obtain sufficient DD orthogonality. Particularly, smoothed rectangular window with excess bandwidth can result in a slightly worse orthogonality but better pulse localization in the DD domain. Furthermore, we present a practical pulse shaping framework for general DD communications and derive the corresponding input-output relation under various shaping pulses. Our numerical results agree with our derivations and also demonstrate advantages of DD communications over conventional orthogonal frequency-division multiplexing (OFDM).
Logic-based Explanations for Linear Support Vector Classifiers with Reject Option
Mar 24, 2024Support Vector Classifier (SVC) is a well-known Machine Learning (ML) model for linear classification problems. It can be used in conjunction with a reject option strategy to reject instances that are hard to correctly classify and delegate them to a specialist. This further increases the confidence of the model. Given this, obtaining an explanation of the cause of rejection is important to not blindly trust the obtained results. While most of the related work has developed means to give such explanations for machine learning models, to the best of our knowledge none have done so for when reject option is present. We propose a logic-based approach with formal guarantees on the correctness and minimality of explanations for linear SVCs with reject option. We evaluate our approach by comparing it to Anchors, which is a heuristic algorithm for generating explanations. Obtained results show that our proposed method gives shorter explanations with reduced time cost.
CG-SLAM: Efficient Dense RGB-D SLAM in a Consistent Uncertainty-aware 3D Gaussian Field
Mar 24, 2024Recently neural radiance fields (NeRF) have been widely exploited as 3D representations for dense simultaneous localization and mapping (SLAM). Despite their notable successes in surface modeling and novel view synthesis, existing NeRF-based methods are hindered by their computationally intensive and time-consuming volume rendering pipeline. This paper presents an efficient dense RGB-D SLAM system, i.e., CG-SLAM, based on a novel uncertainty-aware 3D Gaussian field with high consistency and geometric stability. Through an in-depth analysis of Gaussian Splatting, we propose several techniques to construct a consistent and stable 3D Gaussian field suitable for tracking and mapping. Additionally, a novel depth uncertainty model is proposed to ensure the selection of valuable Gaussian primitives during optimization, thereby improving tracking efficiency and accuracy. Experiments on various datasets demonstrate that CG-SLAM achieves superior tracking and mapping performance with a notable tracking speed of up to 15 Hz. We will make our source code publicly available. Project page: https://zju3dv.github.io/cg-slam.
V2X-PC: Vehicle-to-everything Collaborative Perception via Point Cluster
Mar 25, 2024The objective of the collaborative vehicle-to-everything perception task is to enhance the individual vehicle's perception capability through message communication among neighboring traffic agents. Previous methods focus on achieving optimal performance within bandwidth limitations and typically adopt BEV maps as the basic collaborative message units. However, we demonstrate that collaboration with dense representations is plagued by object feature destruction during message packing, inefficient message aggregation for long-range collaboration, and implicit structure representation communication. To tackle these issues, we introduce a brand new message unit, namely point cluster, designed to represent the scene sparsely with a combination of low-level structure information and high-level semantic information. The point cluster inherently preserves object information while packing messages, with weak relevance to the collaboration range, and supports explicit structure modeling. Building upon this representation, we propose a novel framework V2X-PC for collaborative perception. This framework includes a Point Cluster Packing (PCP) module to keep object feature and manage bandwidth through the manipulation of cluster point numbers. As for effective message aggregation, we propose a Point Cluster Aggregation (PCA) module to match and merge point clusters associated with the same object. To further handle time latency and pose errors encountered in real-world scenarios, we propose parameter-free solutions that can adapt to different noisy levels without finetuning. Experiments on two widely recognized collaborative perception benchmarks showcase the superior performance of our method compared to the previous state-of-the-art approaches relying on BEV maps.
How Reliable is Your Simulator? Analysis on the Limitations of Current LLM-based User Simulators for Conversational Recommendation
Mar 25, 2024Conversational Recommender System (CRS) interacts with users through natural language to understand their preferences and provide personalized recommendations in real-time. CRS has demonstrated significant potential, prompting researchers to address the development of more realistic and reliable user simulators as a key focus. Recently, the capabilities of Large Language Models (LLMs) have attracted a lot of attention in various fields. Simultaneously, efforts are underway to construct user simulators based on LLMs. While these works showcase innovation, they also come with certain limitations that require attention. In this work, we aim to analyze the limitations of using LLMs in constructing user simulators for CRS, to guide future research. To achieve this goal, we conduct analytical validation on the notable work, iEvaLM. Through multiple experiments on two widely-used datasets in the field of conversational recommendation, we highlight several issues with the current evaluation methods for user simulators based on LLMs: (1) Data leakage, which occurs in conversational history and the user simulator's replies, results in inflated evaluation results. (2) The success of CRS recommendations depends more on the availability and quality of conversational history than on the responses from user simulators. (3) Controlling the output of the user simulator through a single prompt template proves challenging. To overcome these limitations, we propose SimpleUserSim, employing a straightforward strategy to guide the topic toward the target items. Our study validates the ability of CRS models to utilize the interaction information, significantly improving the recommendation results.
Developing and Deploying Industry Standards for Artificial Intelligence in Education (AIED): Challenges, Strategies, and Future Directions
Mar 25, 2024The adoption of Artificial Intelligence in Education (AIED) holds the promise of revolutionizing educational practices by offering personalized learning experiences, automating administrative and pedagogical tasks, and reducing the cost of content creation. However, the lack of standardized practices in the development and deployment of AIED solutions has led to fragmented ecosystems, which presents challenges in interoperability, scalability, and ethical governance. This article aims to address the critical need to develop and implement industry standards in AIED, offering a comprehensive analysis of the current landscape, challenges, and strategic approaches to overcome these obstacles. We begin by examining the various applications of AIED in various educational settings and identify key areas lacking in standardization, including system interoperability, ontology mapping, data integration, evaluation, and ethical governance. Then, we propose a multi-tiered framework for establishing robust industry standards for AIED. In addition, we discuss methodologies for the iterative development and deployment of standards, incorporating feedback loops from real-world applications to refine and adapt standards over time. The paper also highlights the role of emerging technologies and pedagogical theories in shaping future standards for AIED. Finally, we outline a strategic roadmap for stakeholders to implement these standards, fostering a cohesive and ethical AIED ecosystem. By establishing comprehensive industry standards, such as those by IEEE Artificial Intelligence Standards Committee (AISC) and International Organization for Standardization (ISO), we can accelerate and scale AIED solutions to improve educational outcomes, ensuring that technological advances align with the principles of inclusivity, fairness, and educational excellence.
RL for Consistency Models: Faster Reward Guided Text-to-Image Generation
Mar 25, 2024Reinforcement learning (RL) has improved guided image generation with diffusion models by directly optimizing rewards that capture image quality, aesthetics, and instruction following capabilities. However, the resulting generative policies inherit the same iterative sampling process of diffusion models that causes slow generation. To overcome this limitation, consistency models proposed learning a new class of generative models that directly map noise to data, resulting in a model that can generate an image in as few as one sampling iteration. In this work, to optimize text-to-image generative models for task specific rewards and enable fast training and inference, we propose a framework for fine-tuning consistency models via RL. Our framework, called Reinforcement Learning for Consistency Model (RLCM), frames the iterative inference process of a consistency model as an RL procedure. RLCM improves upon RL fine-tuned diffusion models on text-to-image generation capabilities and trades computation during inference time for sample quality. Experimentally, we show that RLCM can adapt text-to-image consistency models to objectives that are challenging to express with prompting, such as image compressibility, and those derived from human feedback, such as aesthetic quality. Comparing to RL finetuned diffusion models, RLCM trains significantly faster, improves the quality of the generation measured under the reward objectives, and speeds up the inference procedure by generating high quality images with as few as two inference steps. Our code is available at https://rlcm.owenoertell.com