 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Compact Real-time Radiance Fields with Neural Codebook
May 29, 2023
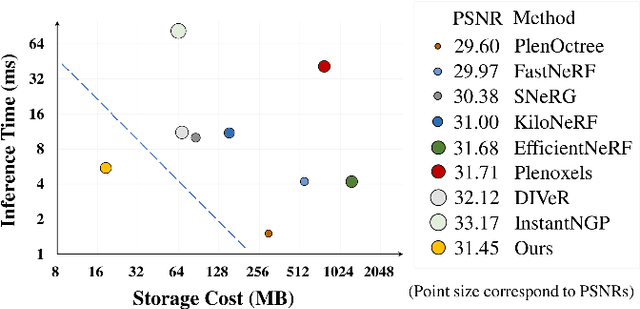
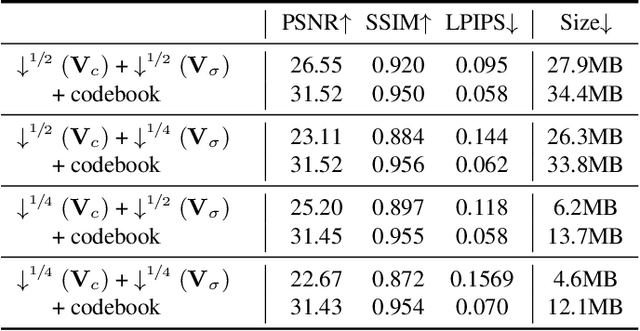


Reconstructing neural radiance fields with explicit volumetric representations, demonstrated by Plenoxels, has shown remarkable advantages on training and rendering efficiency, while grid-based representations typically induce considerable overhead for storage and transmission. In this work, we present a simple and effective framework for pursuing compact radiance fields from the perspective of compression methodology. By exploiting intrinsic properties exhibiting in grid models, a non-uniform compression stem is developed to significantly reduce model complexity and a novel parameterized module, named Neural Codebook, is introduced for better encoding high-frequency details specific to per-scene models via a fast optimization. Our approach can achieve over 40 $\times$ reduction on grid model storage with competitive rendering quality. In addition, the method can achieve real-time rendering speed with 180 fps, realizing significant advantage on storage cost compared to real-time rendering methods.
Networked Time Series Imputation via Position-aware Graph Enhanced Variational Autoencoders
May 29, 2023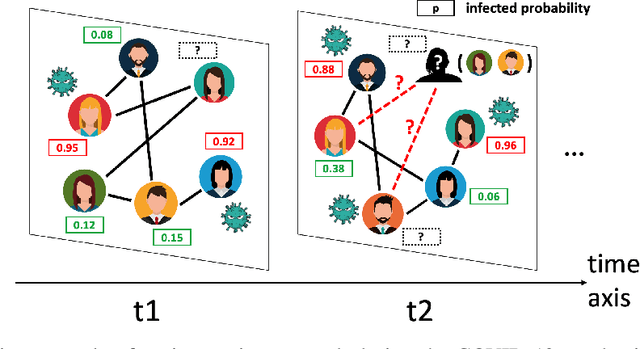

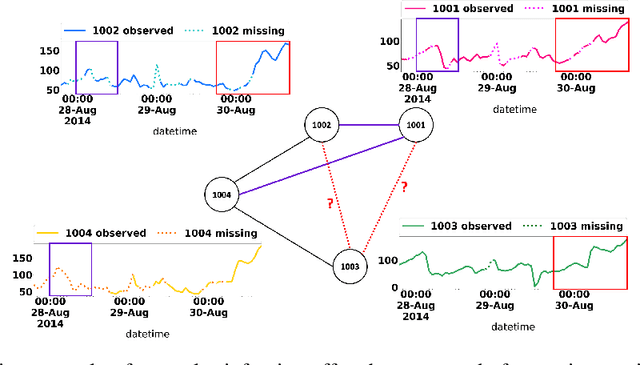
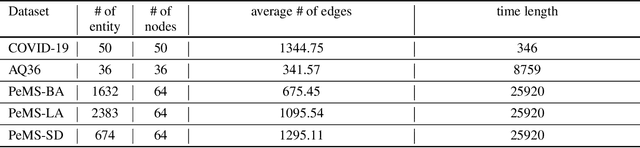
Multivariate time series (MTS) imputation is a widely studied problem in recent years. Existing methods can be divided into two main groups, including (1) deep recurrent or generative models that primarily focus on time series features, and (2) graph neural networks (GNNs) based models that utilize the topological information from the inherent graph structure of MTS as relational inductive bias for imputation. Nevertheless, these methods either neglect topological information or assume the graph structure is fixed and accurately known. Thus, they fail to fully utilize the graph dynamics for precise imputation in more challenging MTS data such as networked time series (NTS), where the underlying graph is constantly changing and might have missing edges. In this paper, we propose a novel approach to overcome these limitations. First, we define the problem of imputation over NTS which contains missing values in both node time series features and graph structures. Then, we design a new model named PoGeVon which leverages variational autoencoder (VAE) to predict missing values over both node time series features and graph structures. In particular, we propose a new node position embedding based on random walk with restart (RWR) in the encoder with provable higher expressive power compared with message-passing based graph neural networks (GNNs). We further design a decoder with 3-stage predictions from the perspective of multi-task learning to impute missing values in both time series and graph structures reciprocally. Experiment results demonstrate the effectiveness of our model over baselines.
Convex Risk Bounded Continuous-Time Trajectory Planning and Tube Design in Uncertain Nonconvex Environments
Jun 04, 2023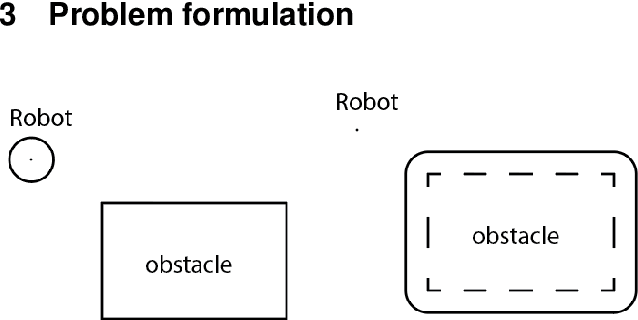
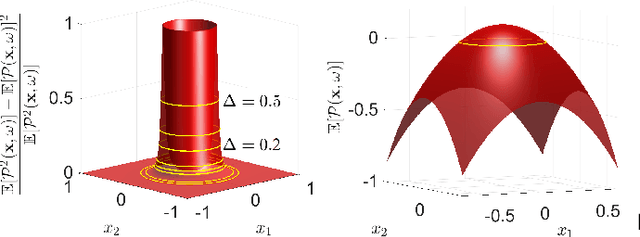
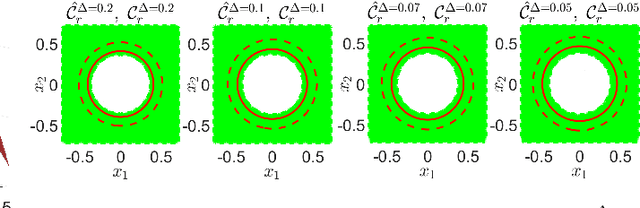
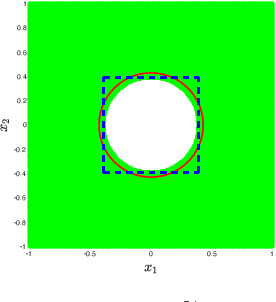
In this paper, we address the trajectory planning problem in uncertain nonconvex static and dynamic environments that contain obstacles with probabilistic location, size, and geometry. To address this problem, we provide a risk bounded trajectory planning method that looks for continuous-time trajectories with guaranteed bounded risk over the planning time horizon. Risk is defined as the probability of collision with uncertain obstacles. Existing approaches to address risk bounded trajectory planning problems either are limited to Gaussian uncertainties and convex obstacles or rely on sampling-based methods that need uncertainty samples and time discretization. To address the risk bounded trajectory planning problem, we leverage the notion of risk contours to transform the risk bounded planning problem into a deterministic optimization problem. Risk contours are the set of all points in the uncertain environment with guaranteed bounded risk. The obtained deterministic optimization is, in general, nonlinear and nonconvex time-varying optimization. We provide convex methods based on sum-of-squares optimization to efficiently solve the obtained nonconvex time-varying optimization problem and obtain the continuous-time risk bounded trajectories without time discretization. The provided approach deals with arbitrary (and known) probabilistic uncertainties, nonconvex and nonlinear, static and dynamic obstacles, and is suitable for online trajectory planning problems. In addition, we provide convex methods based on sum-of-squares optimization to build the max-sized tube with respect to its parameterization along the trajectory so that any state inside the tube is guaranteed to have bounded risk.
Neural Field Movement Primitives for Joint Modelling of Scenes and Motions
Aug 09, 2023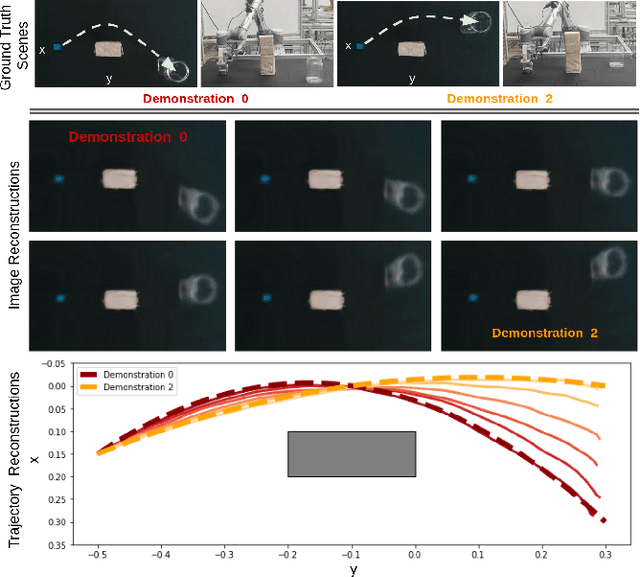
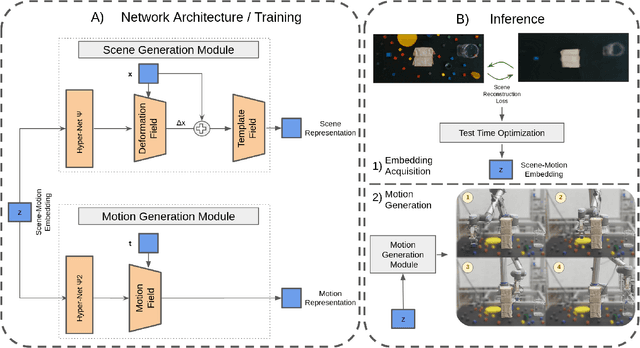
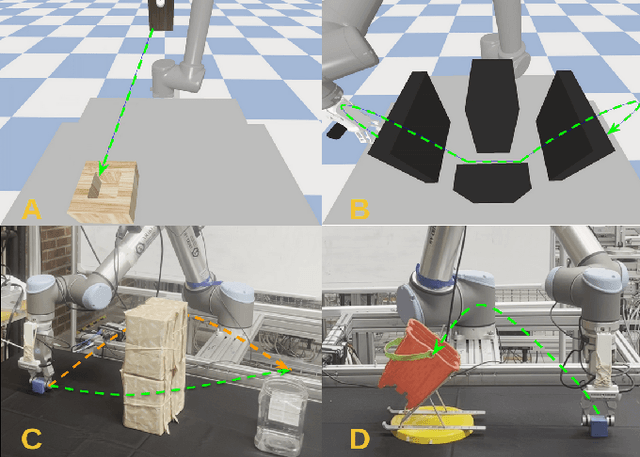
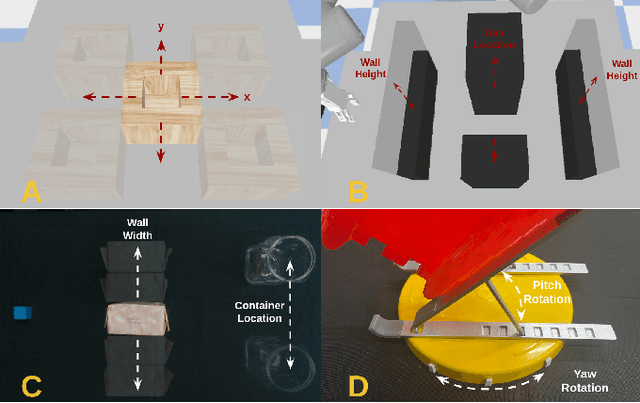
This paper presents a novel Learning from Demonstration (LfD) method that uses neural fields to learn new skills efficiently and accurately. It achieves this by utilizing a shared embedding to learn both scene and motion representations in a generative way. Our method smoothly maps each expert demonstration to a scene-motion embedding and learns to model them without requiring hand-crafted task parameters or large datasets. It achieves data efficiency by enforcing scene and motion generation to be smooth with respect to changes in the embedding space. At inference time, our method can retrieve scene-motion embeddings using test time optimization, and generate precise motion trajectories for novel scenes. The proposed method is versatile and can employ images, 3D shapes, and any other scene representations that can be modeled using neural fields. Additionally, it can generate both end-effector positions and joint angle-based trajectories. Our method is evaluated on tasks that require accurate motion trajectory generation, where the underlying task parametrization is based on object positions and geometric scene changes. Experimental results demonstrate that the proposed method outperforms the baseline approaches and generalizes to novel scenes. Furthermore, in real-world experiments, we show that our method can successfully model multi-valued trajectories, it is robust to the distractor objects introduced at inference time, and it can generate 6D motions.
Design from Policies: Conservative Test-Time Adaptation for Offline Policy Optimization
Jun 26, 2023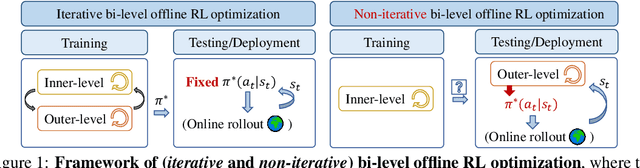

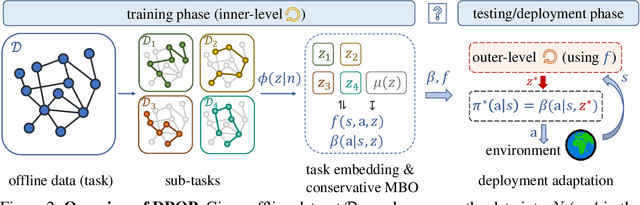
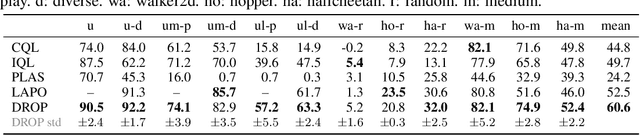
In this work, we decouple the iterative bi-level offline RL from the offline training phase, forming a non-iterative bi-level paradigm and avoiding the iterative error propagation over two levels. Specifically, this non-iterative paradigm allows us to conduct inner-level optimization in training (for OOD issues), while performing outer-level optimization in testing (for reward maximizing). Naturally, such a paradigm raises three core questions that are \textit{not} fully answered by prior non-iterative offline RL counterparts like reward-conditioned policy: Q1) What information should we transfer from the inner-level to the outer-level? Q2) What should we pay attention to when exploiting the transferred information in the outer-level optimization? Q3) What are the~benefits of concurrently conducting outer-level optimization during testing? Motivated by model-based optimization~{(MBO)}, we propose DROP (\textbf{D}esign f\textbf{RO}m \textbf{P}olicies), which fully answers the above questions. Specifically, in the inner-level, DROP decomposes offline data into multiple subsets and learns an {MBO} score model~(A1). To keep safe exploitation to the score model in the outer-level, we explicitly learn a behavior embedding and introduce a conservative regularization (A2). During testing, we show that DROP permits test-time adaptation, enabling an adaptive inference across states~(A3). Empirically, we find that DROP, compared to prior non-iterative offline RL counterparts, gains an average improvement probability of more than 80\%, and achieves comparable or better performance compared to prior iterative baselines.
MultiWave: Multiresolution Deep Architectures through Wavelet Decomposition for Multivariate Time Series Prediction
Jun 16, 2023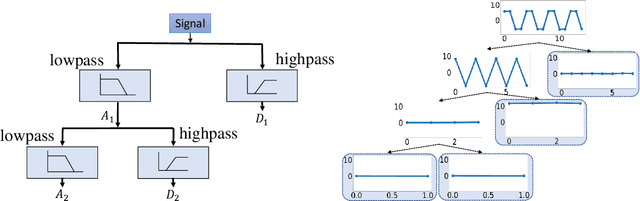
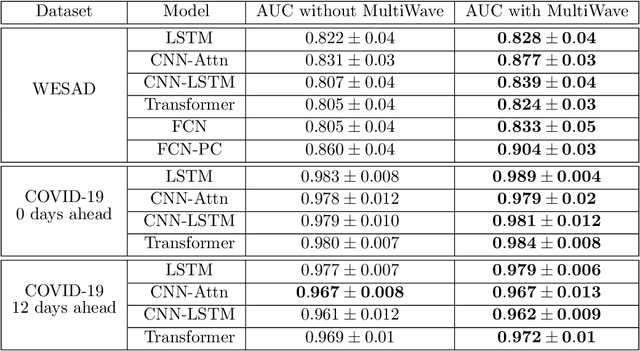
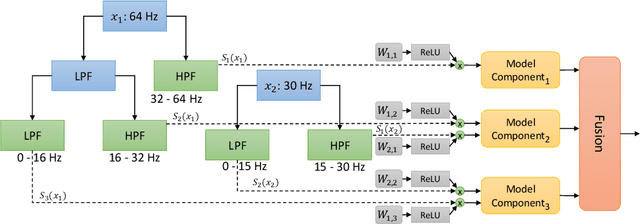
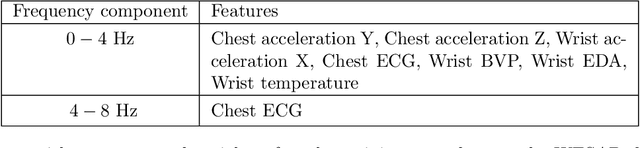
The analysis of multivariate time series data is challenging due to the various frequencies of signal changes that can occur over both short and long terms. Furthermore, standard deep learning models are often unsuitable for such datasets, as signals are typically sampled at different rates. To address these issues, we introduce MultiWave, a novel framework that enhances deep learning time series models by incorporating components that operate at the intrinsic frequencies of signals. MultiWave uses wavelets to decompose each signal into subsignals of varying frequencies and groups them into frequency bands. Each frequency band is handled by a different component of our model. A gating mechanism combines the output of the components to produce sparse models that use only specific signals at specific frequencies. Our experiments demonstrate that MultiWave accurately identifies informative frequency bands and improves the performance of various deep learning models, including LSTM, Transformer, and CNN-based models, for a wide range of applications. It attains top performance in stress and affect detection from wearables. It also increases the AUC of the best-performing model by 5% for in-hospital COVID-19 mortality prediction from patient blood samples and for human activity recognition from accelerometer and gyroscope data. We show that MultiWave consistently identifies critical features and their frequency components, thus providing valuable insights into the applications studied.
6G goal-oriented communications: How to coexist with legacy systems?
Aug 25, 20236G will connect heterogeneous intelligent agents to make them operate complex cooperative tasks. When connecting intelligence, two main research questions arise to identify how AI and ML models behave depending on: i) their input data quality, affected by errors induced by interference and additive noise during wireless communication; ii) their contextual effectiveness and resilience to interpret and exploit the meaning behind the data. Both questions are within the realm of semantic and goal-oriented communications. With this paper we investigate how to effectively share spectrum resources between a legacy communication system and a new goal-oriented edge intelligence one. Specifically, we address the scenario of an eMBB service, i.e., a user uploading a video stream, interfering with an edge inference system, in which a user uploads images to a Mobile Edge Host that runs a classification task. Our objective is to achieve, through cooperation, the highest eMBB service data rate, subject to a targeted goal-effectiveness of the edge inference service, namely the probability of confident inference on time. We first formalize a general definition of a goal in the context of wireless communications. This includes the goal-effectiveness, as well as that of goal cost . We argue and show, through numerical evaluations, that communication reliability and goal-effectiveness are not straightforwardly linked. Then, after a performance evaluation aiming to clarify the difference between communication performance and goal-effectiveness, a long-term optimization problem is formulated and solved via Lyapunov optimization tools, to guarantee the desired performance. Finally, our numerical results assess the advantages of the proposed optimization, and the superiority of the goal-oriented strategy against baseline 5G compliant legacy approaches, under both stationary and non-stationary environments.
Self-Deception: Reverse Penetrating the Semantic Firewall of Large Language Models
Aug 25, 2023

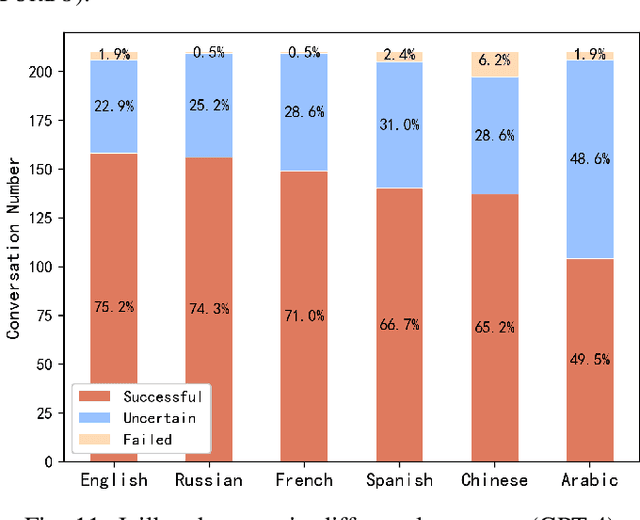
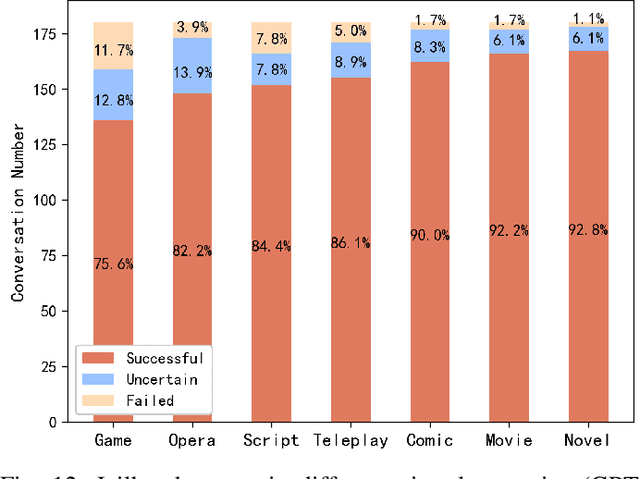
Large language models (LLMs), such as ChatGPT, have emerged with astonishing capabilities approaching artificial general intelligence. While providing convenience for various societal needs, LLMs have also lowered the cost of generating harmful content. Consequently, LLM developers have deployed semantic-level defenses to recognize and reject prompts that may lead to inappropriate content. Unfortunately, these defenses are not foolproof, and some attackers have crafted "jailbreak" prompts that temporarily hypnotize the LLM into forgetting content defense rules and answering any improper questions. To date, there is no clear explanation of the principles behind these semantic-level attacks and defenses in both industry and academia. This paper investigates the LLM jailbreak problem and proposes an automatic jailbreak method for the first time. We propose the concept of a semantic firewall and provide three technical implementation approaches. Inspired by the attack that penetrates traditional firewalls through reverse tunnels, we introduce a "self-deception" attack that can bypass the semantic firewall by inducing LLM to generate prompts that facilitate jailbreak. We generated a total of 2,520 attack payloads in six languages (English, Russian, French, Spanish, Chinese, and Arabic) across seven virtual scenarios, targeting the three most common types of violations: violence, hate, and pornography. The experiment was conducted on two models, namely the GPT-3.5-Turbo and GPT-4. The success rates on the two models were 86.2% and 67%, while the failure rates were 4.7% and 2.2%, respectively. This highlighted the effectiveness of the proposed attack method. All experimental code and raw data will be released as open-source to inspire future research. We believe that manipulating AI behavior through carefully crafted prompts will become an important research direction in the future.
FECoM: A Step towards Fine-Grained Energy Measurement for Deep Learning
Aug 23, 2023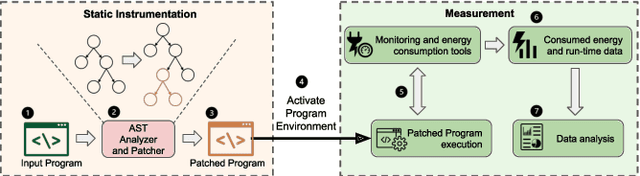
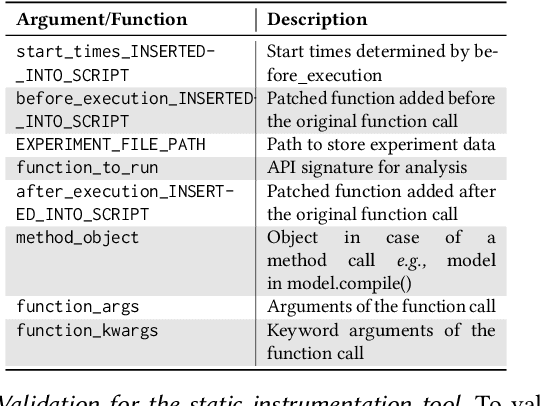
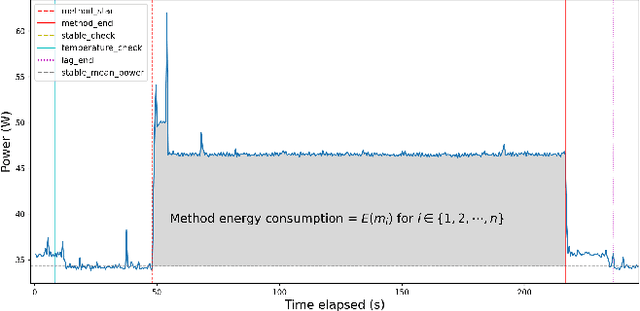
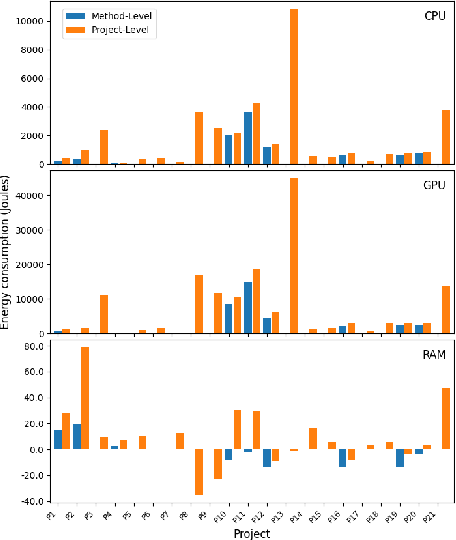
With the increasing usage, scale, and complexity of Deep Learning (DL) models, their rapidly growing energy consumption has become a critical concern. Promoting green development and energy awareness at different granularities is the need of the hour to limit carbon emissions of DL systems. However, the lack of standard and repeatable tools to accurately measure and optimize energy consumption at a fine granularity (e.g., at method level) hinders progress in this area. In this paper, we introduce FECoM (Fine-grained Energy Consumption Meter), a framework for fine-grained DL energy consumption measurement. Specifically, FECoM provides researchers and developers a mechanism to profile DL APIs. FECoM addresses the challenges of measuring energy consumption at fine-grained level by using static instrumentation and considering various factors, including computational load and temperature stability. We assess FECoM's capability to measure fine-grained energy consumption for one of the most popular open-source DL frameworks, namely TensorFlow. Using FECoM, we also investigate the impact of parameter size and execution time on energy consumption, enriching our understanding of TensorFlow APIs' energy profiles. Furthermore, we elaborate on the considerations, issues, and challenges that one needs to consider while designing and implementing a fine-grained energy consumption measurement tool. We hope this work will facilitate further advances in DL energy measurement and the development of energy-aware practices for DL systems.
RL-based Variable Horizon Model Predictive Control of Multi-Robot Systems using Versatile On-Demand Collision Avoidance
Aug 14, 2023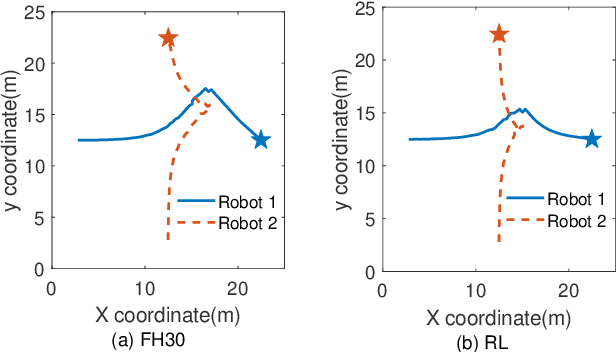
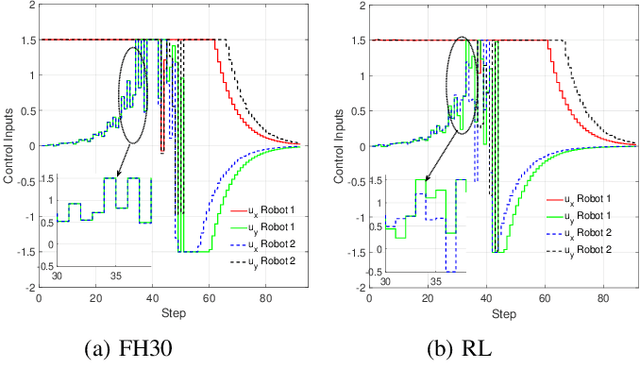
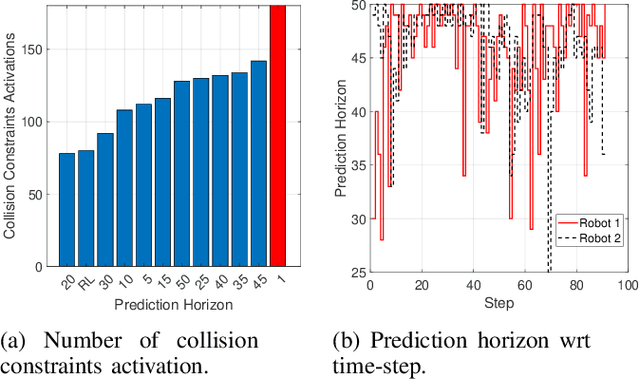
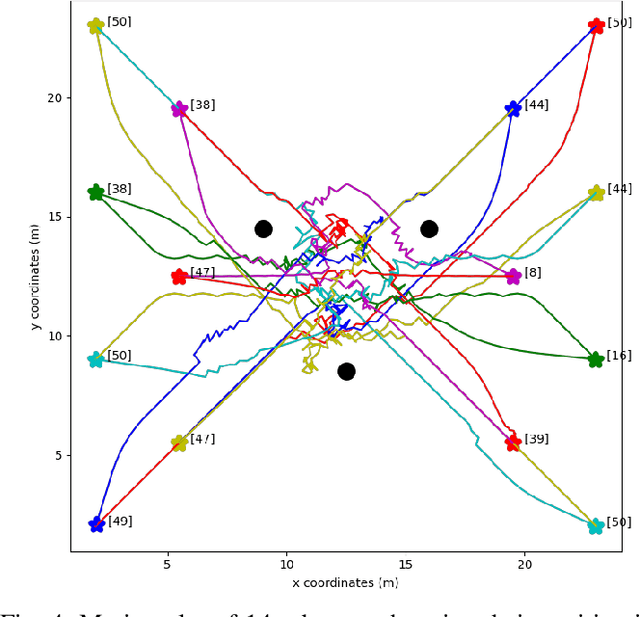
Multi-robot systems have become very popular in recent years because of their wide spectrum of applications, ranging from surveillance to cooperative payload transportation. Model Predictive Control (MPC) is a promising controller for multi-robot control because of its preview capability and ability to handle constraints easily. The performance of the MPC widely depends on many parameters, among which the prediction horizon is the major contributor. Increasing the prediction horizon beyond a limit drastically increases the computation cost. Tuning the value of the prediction horizon can be very time-consuming, and the tuning process must be repeated for every task. Moreover, instead of using a fixed horizon for an entire task, a better balance between performance and computation cost can be established if different prediction horizons can be employed for every robot at each time step. Further, for such variable prediction horizon MPC for multiple robots, on-demand collision avoidance is the key requirement. We propose Versatile On-demand Collision Avoidance (VODCA) strategy to comply with the variable horizon model predictive control. We also present a framework for learning the prediction horizon for the multi-robot system as a function of the states of the robots using the Soft Actor-Critic (SAC) RL algorithm. The results are illustrated and validated numerically for different multi-robot tasks.