 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Privacy-Supporting Fall Detection via Deep Unsupervised RGB2Depth Adaptation
Aug 23, 2023


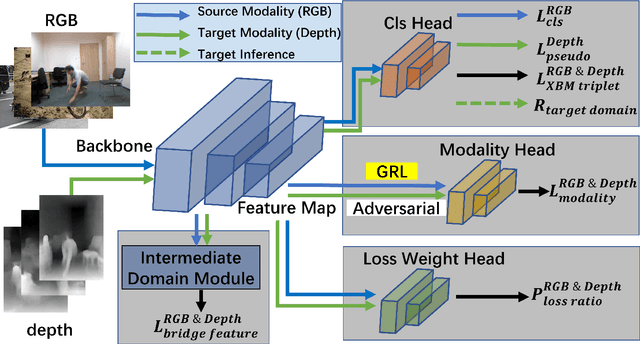
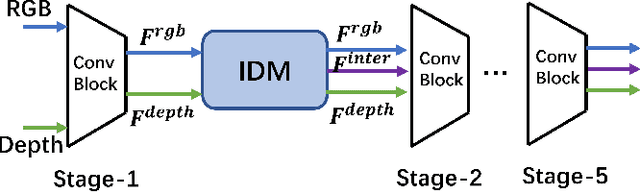
Fall detection is a vital task in health monitoring, as it allows the system to trigger an alert and therefore enabling faster interventions when a person experiences a fall. Although most previous approaches rely on standard RGB video data, such detailed appearance-aware monitoring poses significant privacy concerns. Depth sensors, on the other hand, are better at preserving privacy as they merely capture the distance of objects from the sensor or camera, omitting color and texture information. In this paper, we introduce a privacy-supporting solution that makes the RGB-trained model applicable in depth domain and utilizes depth data at test time for fall detection. To achieve cross-modal fall detection, we present an unsupervised RGB to Depth (RGB2Depth) cross-modal domain adaptation approach that leverages labelled RGB data and unlabelled depth data during training. Our proposed pipeline incorporates an intermediate domain module for feature bridging, modality adversarial loss for modality discrimination, classification loss for pseudo-labeled depth data and labeled source data, triplet loss that considers both source and target domains, and a novel adaptive loss weight adjustment method for improved coordination among various losses. Our approach achieves state-of-the-art results in the unsupervised RGB2Depth domain adaptation task for fall detection. Code is available at https://github.com/1015206533/privacy_supporting_fall_detection.
Multi-UAV Deployment in Obstacle-Cluttered Environments with LOS Connectivity
Aug 23, 2023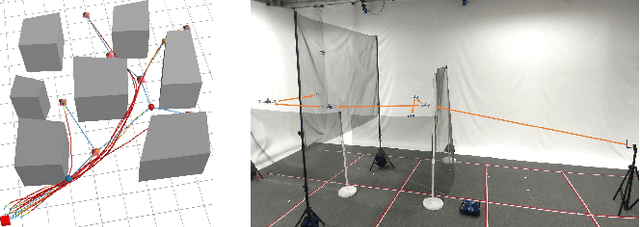
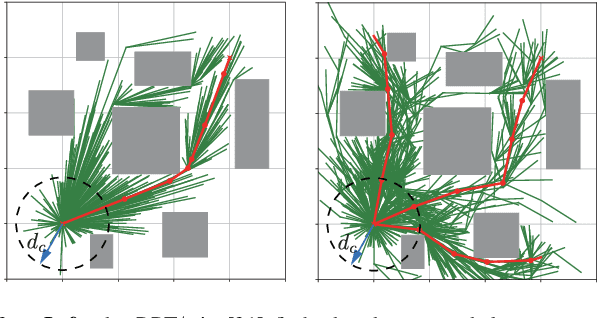
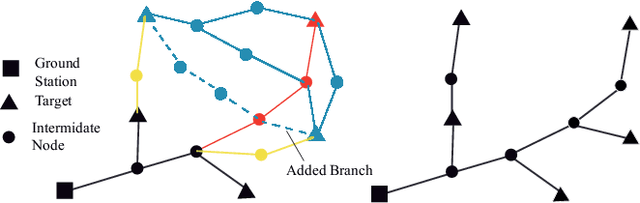
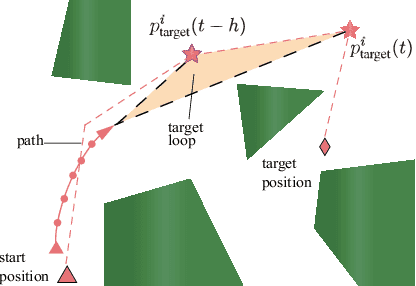
A reliable communication network is essential for multiple UAVs operating within obstacle-cluttered environments, where limited communication due to obstructions often occurs. A common solution is to deploy intermediate UAVs to relay information via a multi-hop network, which introduces two challenges: (i) how to design the structure of multi-hop networks; and (ii) how to maintain connectivity during collaborative motion. To this end, this work first proposes an efficient constrained search method based on the minimum-edge RRT$^\star$ algorithm, to find a spanning-tree topology that requires a less number of UAVs for the deployment task. To achieve this deployment, a distributed model predictive control strategy is proposed for the online motion coordination. It explicitly incorporates not only the inter-UAV and UAV-obstacle distance constraints, but also the line-of-sight (LOS) connectivity constraint. These constraints are well-known to be nonlinear and often tackled by various approximations. In contrast, this work provides a theoretical guarantee that all agent trajectories are ensured to be collision-free with a team-wise LOS connectivity at all time. Numerous simulations are performed in 3D valley-like environments, while hardware experiments validate its dynamic adaptation when the deployment position changes online.
Continual Domain Adaptation on Aerial Images under Gradually Degrading Weather
Aug 14, 2023Domain adaptation (DA) strives to mitigate the domain gap between the source domain where a model is trained, and the target domain where the model is deployed. When a deep learning model is deployed on an aerial platform, it may face gradually degrading weather conditions during operation, leading to widening domain gaps between the training data and the encountered evaluation data. We synthesize two such gradually worsening weather conditions on real images from two existing aerial imagery datasets, generating a total of four benchmark datasets. Under the continual, or test-time adaptation setting, we evaluate three DA models on our datasets: a baseline standard DA model and two continual DA models. In such setting, the models can access only one small portion, or one batch of the target data at a time, and adaptation takes place continually, and over only one epoch of the data. The combination of the constraints of continual adaptation, and gradually deteriorating weather conditions provide the practical DA scenario for aerial deployment. Among the evaluated models, we consider both convolutional and transformer architectures for comparison. We discover stability issues during adaptation for existing buffer-fed continual DA methods, and offer gradient normalization as a simple solution to curb training instability.
A Human-Machine Joint Learning Framework to Boost Endogenous BCI Training
Aug 25, 2023Brain-computer interfaces (BCIs) provide a direct pathway from the brain to external devices and have demonstrated great potential for assistive and rehabilitation technologies. Endogenous BCIs based on electroencephalogram (EEG) signals, such as motor imagery (MI) BCIs, can provide some level of control. However, mastering spontaneous BCI control requires the users to generate discriminative and stable brain signal patterns by imagery, which is challenging and is usually achieved over a very long training time (weeks/months). Here, we propose a human-machine joint learning framework to boost the learning process in endogenous BCIs, by guiding the user to generate brain signals towards an optimal distribution estimated by the decoder, given the historical brain signals of the user. To this end, we firstly model the human-machine joint learning process in a uniform formulation. Then a human-machine joint learning framework is proposed: 1) for the human side, we model the learning process in a sequential trial-and-error scenario and propose a novel ``copy/new'' feedback paradigm to help shape the signal generation of the subject toward the optimal distribution; 2) for the machine side, we propose a novel adaptive learning algorithm to learn an optimal signal distribution along with the subject's learning process. Specifically, the decoder reweighs the brain signals generated by the subject to focus more on ``good'' samples to cope with the learning process of the subject. Online and psuedo-online BCI experiments with 18 healthy subjects demonstrated the advantages of the proposed joint learning process over co-adaptive approaches in both learning efficiency and effectiveness.
EventTransAct: A video transformer-based framework for Event-camera based action recognition
Aug 25, 2023
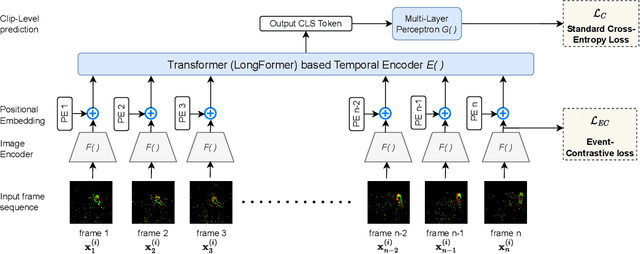
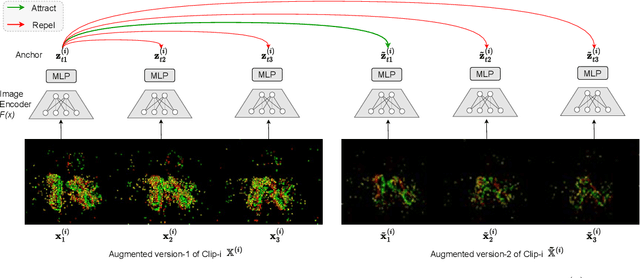
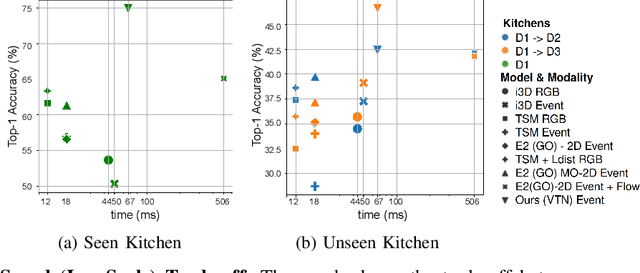
Recognizing and comprehending human actions and gestures is a crucial perception requirement for robots to interact with humans and carry out tasks in diverse domains, including service robotics, healthcare, and manufacturing. Event cameras, with their ability to capture fast-moving objects at a high temporal resolution, offer new opportunities compared to standard action recognition in RGB videos. However, previous research on event camera action recognition has primarily focused on sensor-specific network architectures and image encoding, which may not be suitable for new sensors and limit the use of recent advancements in transformer-based architectures. In this study, we employ a computationally efficient model, namely the video transformer network (VTN), which initially acquires spatial embeddings per event-frame and then utilizes a temporal self-attention mechanism. In order to better adopt the VTN for the sparse and fine-grained nature of event data, we design Event-Contrastive Loss ($\mathcal{L}_{EC}$) and event-specific augmentations. Proposed $\mathcal{L}_{EC}$ promotes learning fine-grained spatial cues in the spatial backbone of VTN by contrasting temporally misaligned frames. We evaluate our method on real-world action recognition of N-EPIC Kitchens dataset, and achieve state-of-the-art results on both protocols - testing in seen kitchen (\textbf{74.9\%} accuracy) and testing in unseen kitchens (\textbf{42.43\% and 46.66\% Accuracy}). Our approach also takes less computation time compared to competitive prior approaches, which demonstrates the potential of our framework \textit{EventTransAct} for real-world applications of event-camera based action recognition. Project Page: \url{https://tristandb8.github.io/EventTransAct_webpage/}
CEIMVEN: An Approach of Cutting Edge Implementation of Modified Versions of EfficientNet (V1-V2) Architecture for Breast Cancer Detection and Classification from Ultrasound Images
Aug 25, 2023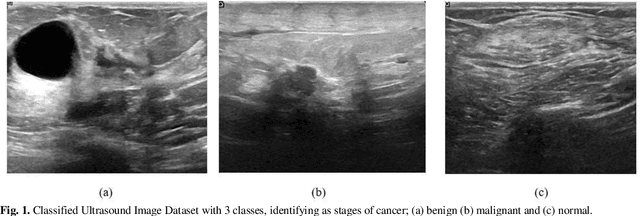
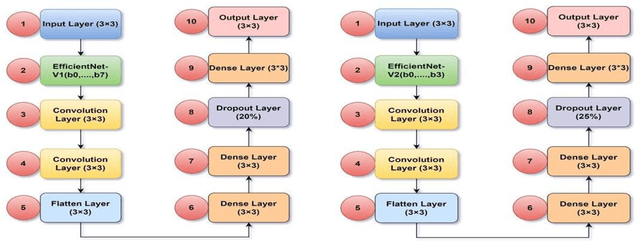
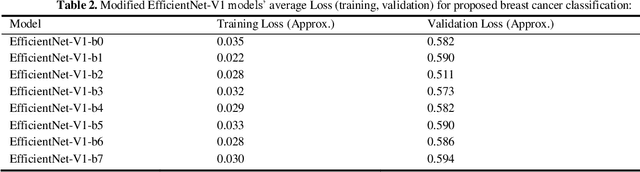
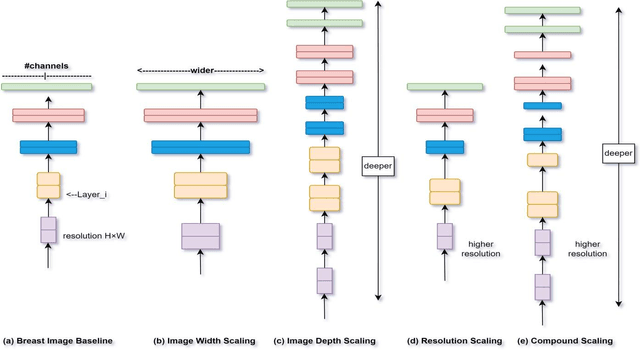
Undoubtedly breast cancer identifies itself as one of the most widespread and terrifying cancers across the globe. Millions of women are getting affected each year from it. Breast cancer remains the major one for being the reason of largest number of demise of women. In the recent time of research, Medical Image Computing and Processing has been playing a significant role for detecting and classifying breast cancers from ultrasound images and mammograms, along with the celestial touch of deep neural networks. In this research, we focused mostly on our rigorous implementations and iterative result analysis of different cutting-edge modified versions of EfficientNet architectures namely EfficientNet-V1 (b0-b7) and EfficientNet-V2 (b0-b3) with ultrasound image, named as CEIMVEN. We utilized transfer learning approach here for using the pre-trained models of EfficientNet versions. We activated the hyper-parameter tuning procedures, added fully connected layers, discarded the unprecedented outliers and recorded the accuracy results from our custom modified EfficientNet architectures. Our deep learning model training approach was related to both identifying the cancer affected areas with region of interest (ROI) techniques and multiple classifications (benign, malignant and normal). The approximate testing accuracies we got from the modified versions of EfficientNet-V1 (b0- 99.15%, b1- 98.58%, b2- 98.43%, b3- 98.01%, b4- 98.86%, b5- 97.72%, b6- 97.72%, b7- 98.72%) and EfficientNet-V2 (b0- 99.29%, b1- 99.01%, b2- 98.72%, b3- 99.43%) are showing very bright future and strong potentials of deep learning approach for the successful detection and classification of breast cancers from the ultrasound images at a very early stage.
EEATC: A Novel Calibration Approach for Low-cost Sensors
Aug 25, 2023
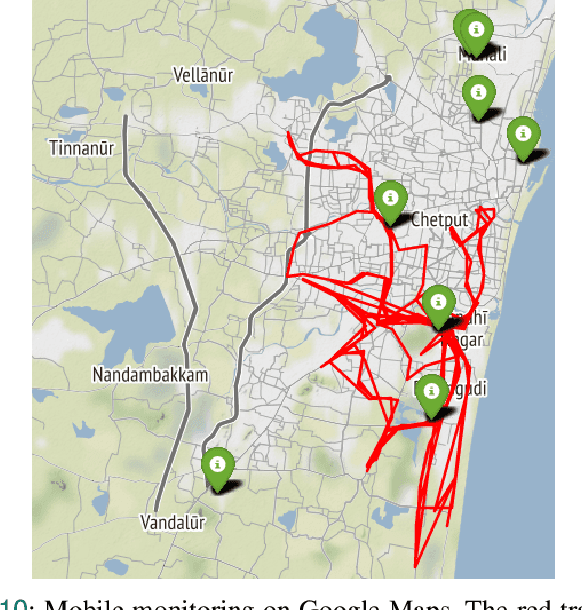
Low-cost sensors (LCS) are affordable, compact, and often portable devices designed to measure various environmental parameters, including air quality. These sensors are intended to provide accessible and cost-effective solutions for monitoring pollution levels in different settings, such as indoor, outdoor and moving vehicles. However, the data produced by LCS is prone to various sources of error that can affect accuracy. Calibration is a well-known procedure to improve the reliability of the data produced by LCS, and several developments and efforts have been made to calibrate the LCS. This work proposes a novel Estimated Error Augmented Two-phase Calibration (\textit{EEATC}) approach to calibrate the LCS in stationary and mobile deployments. In contrast to the existing approaches, the \textit{EEATC} calibrates the LCS in two phases, where the error estimated in the first phase calibration is augmented with the input to the second phase, which helps the second phase to learn the distributional features better to produce more accurate results. We show that the \textit{EEATC} outperforms well-known single-phase calibration models such as linear regression models (single variable linear regression (SLR) and multiple variable linear regression (MLR)) and Random forest (RF) in stationary and mobile deployments. To test the \textit{EEATC} in stationary deployments, we have used the Community Air Sensor Network (CAIRSENSE) data set approved by the United States Environmental Protection Agency (USEPA), and the mobile deployments are tested with the real-time data obtained from SensurAir, an LCS device developed and deployed on moving vehicle in Chennai, India.
Identifying depression-related topics in smartphone-collected free-response speech recordings using an automatic speech recognition system and a deep learning topic model
Aug 22, 2023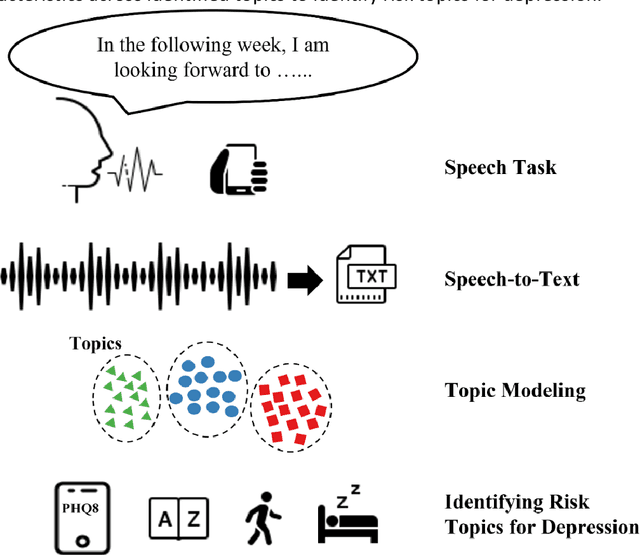
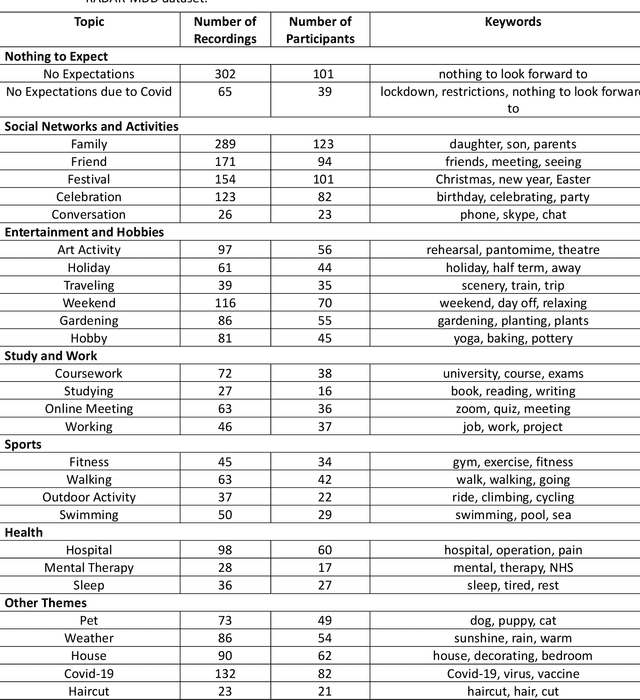
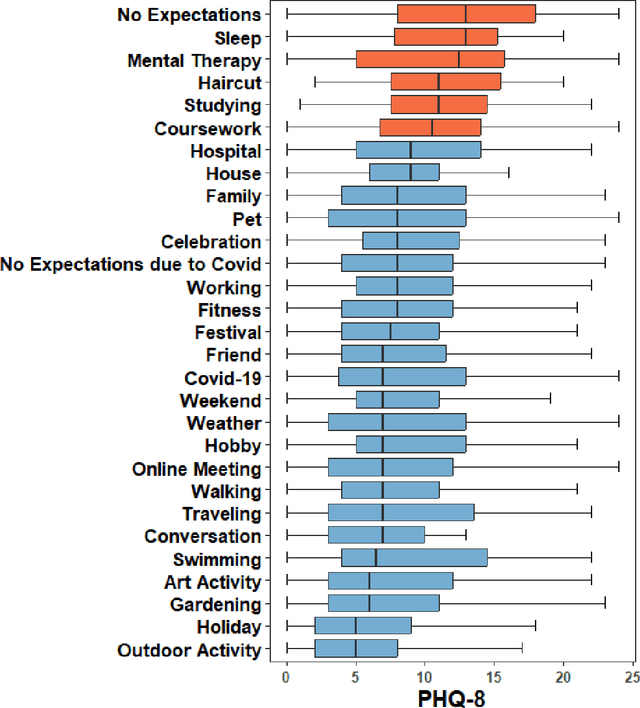
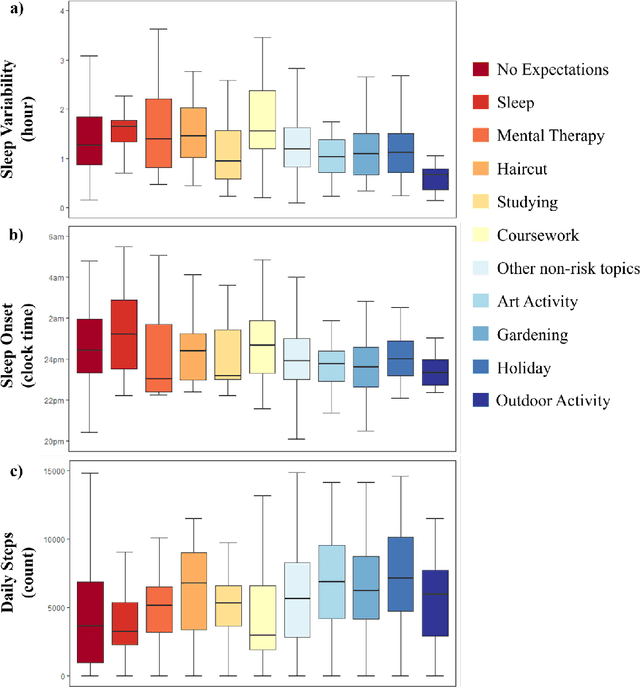
Language use has been shown to correlate with depression, but large-scale validation is needed. Traditional methods like clinic studies are expensive. So, natural language processing has been employed on social media to predict depression, but limitations remain-lack of validated labels, biased user samples, and no context. Our study identified 29 topics in 3919 smartphone-collected speech recordings from 265 participants using the Whisper tool and BERTopic model. Six topics with a median PHQ-8 greater than or equal to 10 were regarded as risk topics for depression: No Expectations, Sleep, Mental Therapy, Haircut, Studying, and Coursework. To elucidate the topic emergence and associations with depression, we compared behavioral (from wearables) and linguistic characteristics across identified topics. The correlation between topic shifts and changes in depression severity over time was also investigated, indicating the importance of longitudinally monitoring language use. We also tested the BERTopic model on a similar smaller dataset (356 speech recordings from 57 participants), obtaining some consistent results. In summary, our findings demonstrate specific speech topics may indicate depression severity. The presented data-driven workflow provides a practical approach to collecting and analyzing large-scale speech data from real-world settings for digital health research.
Using Early Exits for Fast Inference in Automatic Modulation Classification
Aug 22, 2023Automatic modulation classification (AMC) plays a critical role in wireless communications by autonomously classifying signals transmitted over the radio spectrum. Deep learning (DL) techniques are increasingly being used for AMC due to their ability to extract complex wireless signal features. However, DL models are computationally intensive and incur high inference latencies. This paper proposes the application of early exiting (EE) techniques for DL models used for AMC to accelerate inference. We present and analyze four early exiting architectures and a customized multi-branch training algorithm for this problem. Through extensive experimentation, we show that signals with moderate to high signal-to-noise ratios (SNRs) are easier to classify, do not require deep architectures, and can therefore leverage the proposed EE architectures. Our experimental results demonstrate that EE techniques can significantly reduce the inference speed of deep neural networks without sacrificing classification accuracy. We also thoroughly study the trade-off between classification accuracy and inference time when using these architectures. To the best of our knowledge, this work represents the first attempt to apply early exiting methods to AMC, providing a foundation for future research in this area.
StoryBench: A Multifaceted Benchmark for Continuous Story Visualization
Aug 22, 2023

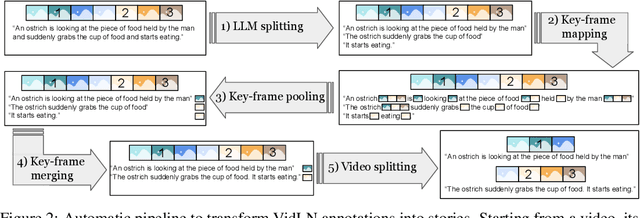

Generating video stories from text prompts is a complex task. In addition to having high visual quality, videos need to realistically adhere to a sequence of text prompts whilst being consistent throughout the frames. Creating a benchmark for video generation requires data annotated over time, which contrasts with the single caption used often in video datasets. To fill this gap, we collect comprehensive human annotations on three existing datasets, and introduce StoryBench: a new, challenging multi-task benchmark to reliably evaluate forthcoming text-to-video models. Our benchmark includes three video generation tasks of increasing difficulty: action execution, where the next action must be generated starting from a conditioning video; story continuation, where a sequence of actions must be executed starting from a conditioning video; and story generation, where a video must be generated from only text prompts. We evaluate small yet strong text-to-video baselines, and show the benefits of training on story-like data algorithmically generated from existing video captions. Finally, we establish guidelines for human evaluation of video stories, and reaffirm the need of better automatic metrics for video generation. StoryBench aims at encouraging future research efforts in this exciting new area.