 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Joint Optimization of Layer-Adaptive Weight Pruning in Deep Neural Networks
Aug 24, 2023
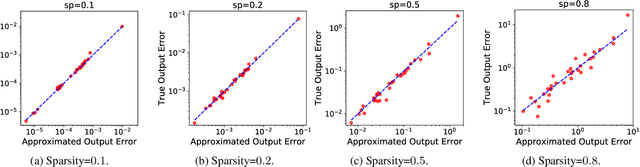
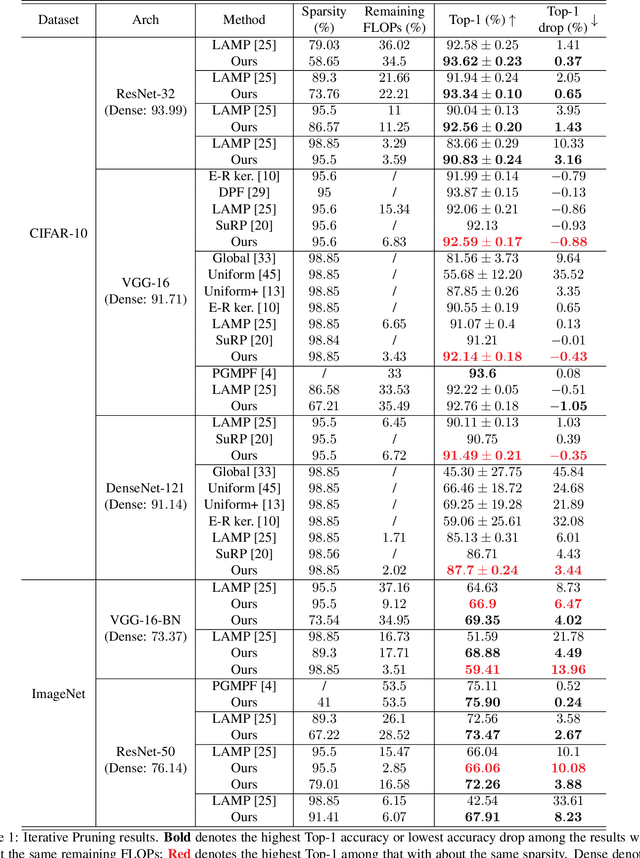
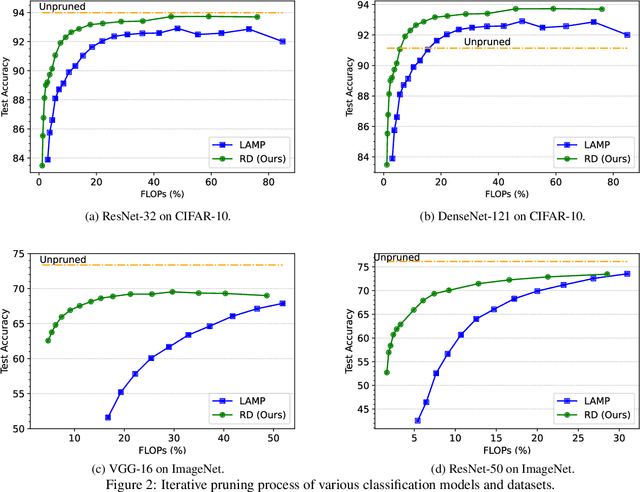
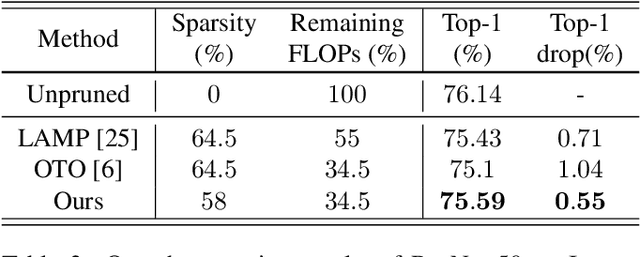
In this paper, we propose a novel layer-adaptive weight-pruning approach for Deep Neural Networks (DNNs) that addresses the challenge of optimizing the output distortion minimization while adhering to a target pruning ratio constraint. Our approach takes into account the collective influence of all layers to design a layer-adaptive pruning scheme. We discover and utilize a very important additivity property of output distortion caused by pruning weights on multiple layers. This property enables us to formulate the pruning as a combinatorial optimization problem and efficiently solve it through dynamic programming. By decomposing the problem into sub-problems, we achieve linear time complexity, making our optimization algorithm fast and feasible to run on CPUs. Our extensive experiments demonstrate the superiority of our approach over existing methods on the ImageNet and CIFAR-10 datasets. On CIFAR-10, our method achieves remarkable improvements, outperforming others by up to 1.0% for ResNet-32, 0.5% for VGG-16, and 0.7% for DenseNet-121 in terms of top-1 accuracy. On ImageNet, we achieve up to 4.7% and 4.6% higher top-1 accuracy compared to other methods for VGG-16 and ResNet-50, respectively. These results highlight the effectiveness and practicality of our approach for enhancing DNN performance through layer-adaptive weight pruning. Code will be available on https://github.com/Akimoto-Cris/RD_VIT_PRUNE.
Actuator Trajectory Planning for UAVs with Overhead Manipulator using Reinforcement Learning
Aug 24, 2023
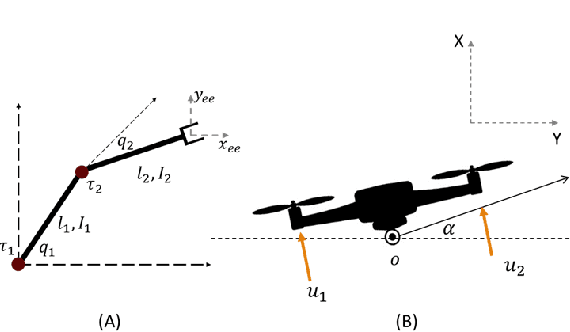
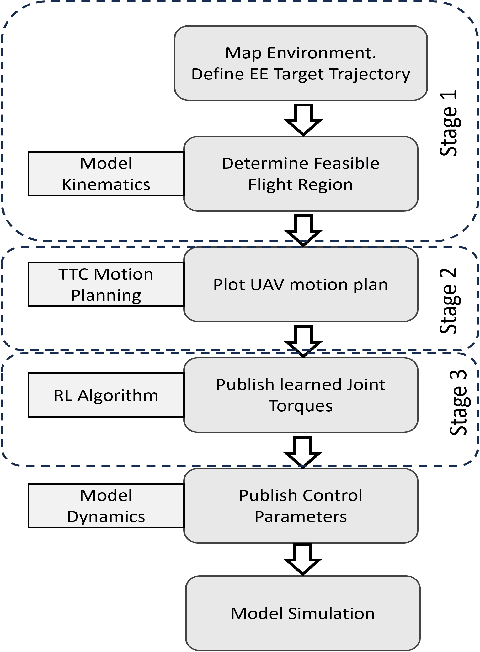
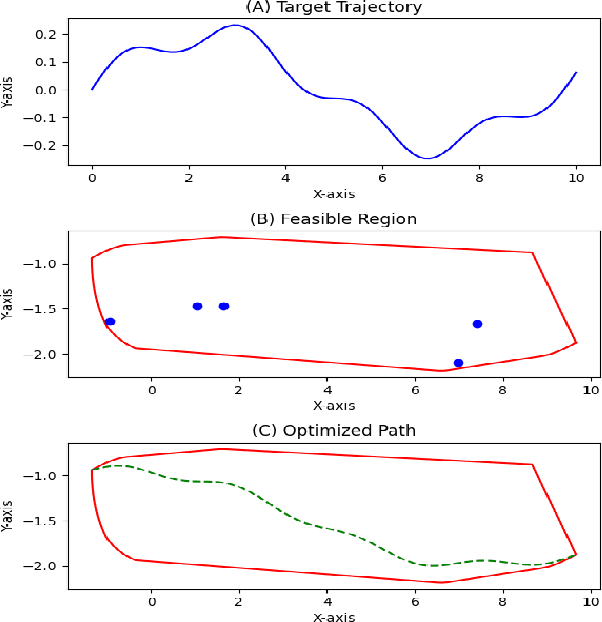
In this paper, we investigate the operation of an aerial manipulator system, namely an Unmanned Aerial Vehicle (UAV) equipped with a controllable arm with two degrees of freedom to carry out actuation tasks on the fly. Our solution is based on employing a Q-learning method to control the trajectory of the tip of the arm, also called \textit{end-effector}. More specifically, we develop a motion planning model based on Time To Collision (TTC), which enables a quadrotor UAV to navigate around obstacles while ensuring the manipulator's reachability. Additionally, we utilize a model-based Q-learning model to independently track and control the desired trajectory of the manipulator's end-effector, given an arbitrary baseline trajectory for the UAV platform. Such a combination enables a variety of actuation tasks such as high-altitude welding, structural monitoring and repair, battery replacement, gutter cleaning, sky scrapper cleaning, and power line maintenance in hard-to-reach and risky environments while retaining compatibility with flight control firmware. Our RL-based control mechanism results in a robust control strategy that can handle uncertainties in the motion of the UAV, offering promising performance. Specifically, our method achieves 92\% accuracy in terms of average displacement error (i.e. the mean distance between the target and obtained trajectory points) using Q-learning with 15,000 episodes
Evolutionary Dynamic Optimization Laboratory: A MATLAB Optimization Platform for Education and Experimentation in Dynamic Environments
Aug 24, 2023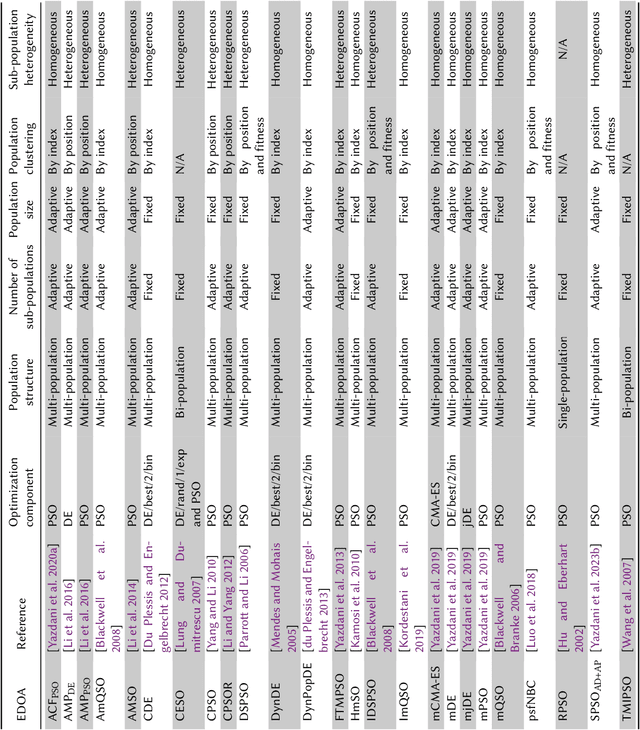
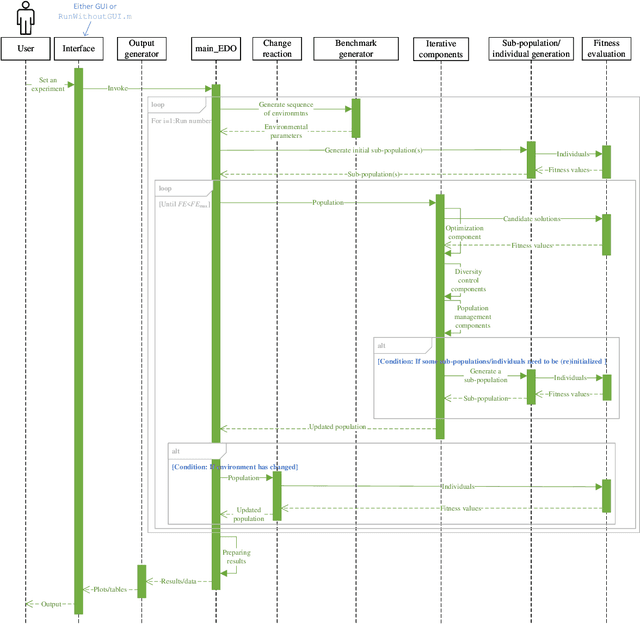
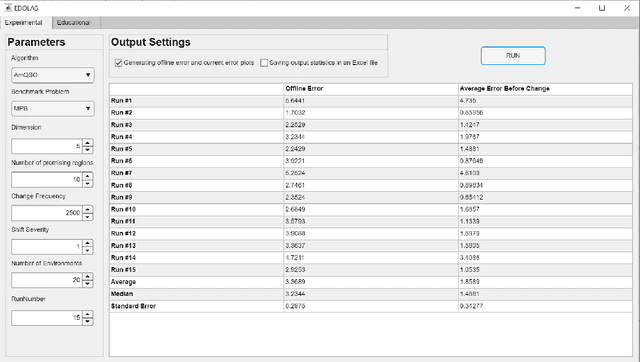

Many real-world optimization problems possess dynamic characteristics. Evolutionary dynamic optimization algorithms (EDOAs) aim to tackle the challenges associated with dynamic optimization problems. Looking at the existing works, the results reported for a given EDOA can sometimes be considerably different. This issue occurs because the source codes of many EDOAs, which are usually very complex algorithms, have not been made publicly available. Indeed, the complexity of components and mechanisms used in many EDOAs makes their re-implementation error-prone. In this paper, to assist researchers in performing experiments and comparing their algorithms against several EDOAs, we develop an open-source MATLAB platform for EDOAs, called Evolutionary Dynamic Optimization LABoratory (EDOLAB). This platform also contains an education module that can be used for educational purposes. In the education module, the user can observe a) a 2-dimensional problem space and how its morphology changes after each environmental change, b) the behaviors of individuals over time, and c) how the EDOA reacts to environmental changes and tries to track the moving optimum. In addition to being useful for research and education purposes, EDOLAB can also be used by practitioners to solve their real-world problems. The current version of EDOLAB includes 25 EDOAs and three fully-parametric benchmark generators. The MATLAB source code for EDOLAB is publicly available and can be accessed from [https://github.com/EDOLAB-platform/EDOLAB-MATLAB].
A Fast Algorithm for Consistency Checking Partially Ordered Time
May 25, 2023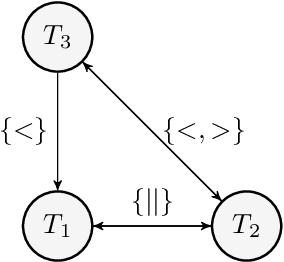
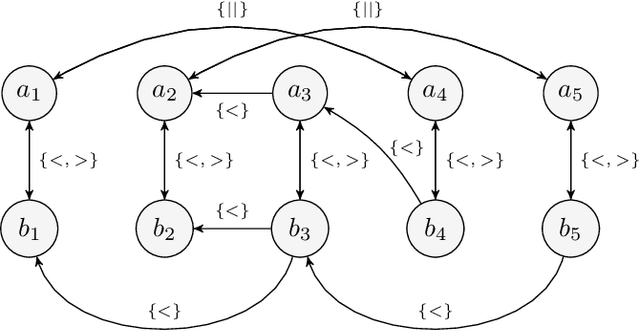
Partially ordered models of time occur naturally in applications where agents or processes cannot perfectly communicate with each other, and can be traced back to the seminal work of Lamport. In this paper we consider the problem of deciding if a (likely incomplete) description of a system of events is consistent, the network consistency problem for the point algebra of partially ordered time (POT). While the classical complexity of this problem has been fully settled, comparably little is known of the fine-grained complexity of POT except that it can be solved in $O^*((0.368n)^n)$ time by enumerating ordered partitions. We construct a much faster algorithm with a run-time bounded by $O^*((0.26n)^n)$. This is achieved by a sophisticated enumeration of structures similar to total orders, which are then greedily expanded toward a solution. While similar ideas have been explored earlier for related problems it turns out that the analysis for POT is non-trivial and requires significant new ideas.
SNR-based beaconless multi-scan link acquisition model with vibration for LEO-to-ground laser communication
Aug 06, 2023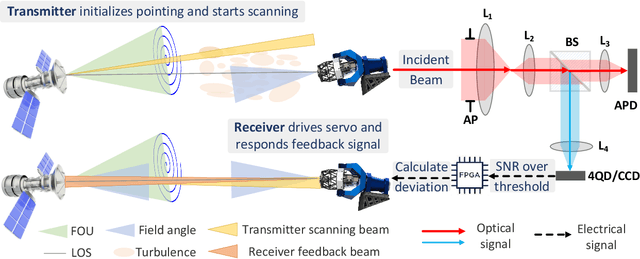
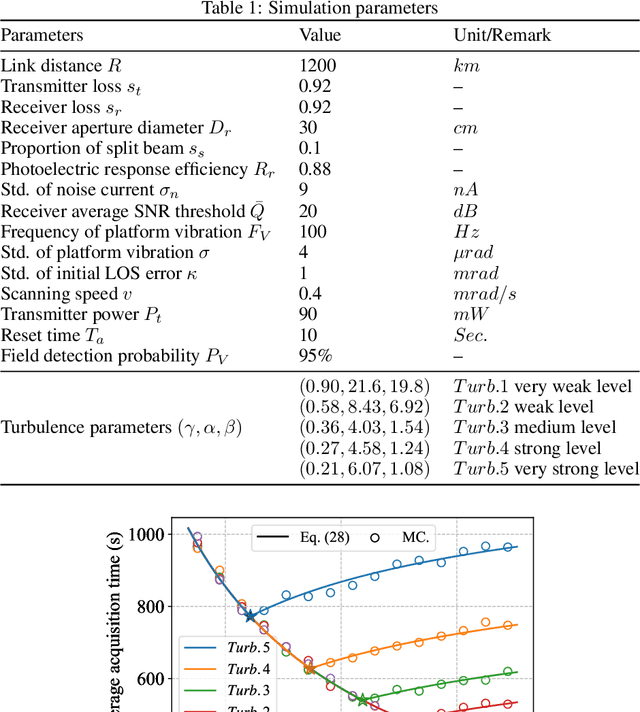
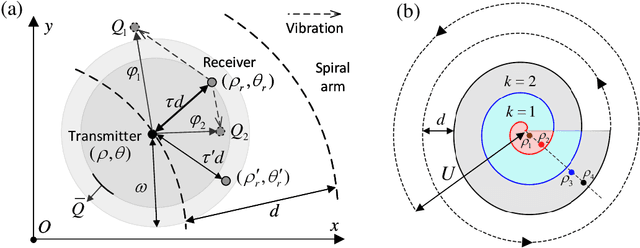
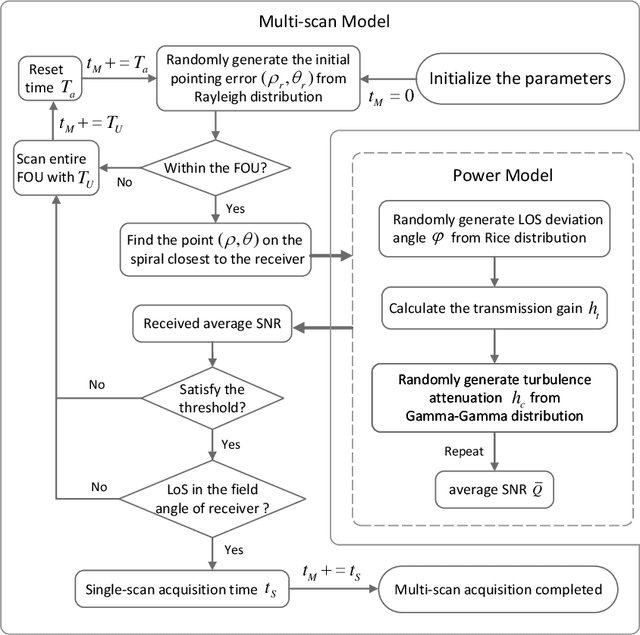
We propose a link acquisition time model deeply involving the process from the transmitted power to received signal-to-noise ratio (SNR) for LEO-to-ground laser communication for the first time. Compared with the conventional acquisition models founded on geometry analysis with divergence angle threshold, utilizing SNR as the decision criterion is more appropriate for practical engineering requirements. Specially, under the combined effects of platform vibration and turbulence, we decouple the parameters of beam divergence angle, spiral pitch, and coverage factor at a fixed transmitted power for a given average received SNR threshold. Then the single-scan acquisition probability is obtained by integrating the field of uncertainty (FOU), probability distribution of coverage factor, and receiver field angle. Consequently, the closed-form analytical expression of acquisition time expectation adopting multi-scan, which ensures acquisition success, with essential reset time between single-scan is derived. The optimizations concerning the beam divergence angle, spiral pitch, and FOU are presented. Moreover, the influence of platform vibration is investigated. All the analytical derivations are confirmed by Monte Carlo simulations. Notably, we provide a theoretical method for designing the minimum divergence angle modulated by the laser, which not only improves the acquisition performance within a certain vibration range, but also achieves a good trade-off with the system complexity.
A Survey on Deep Multi-modal Learning for Body Language Recognition and Generation
Aug 17, 2023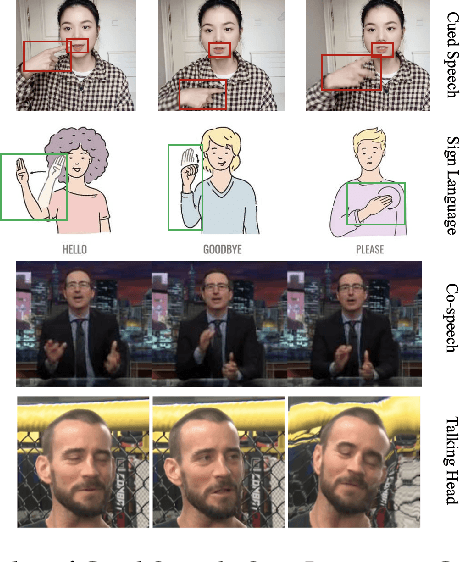
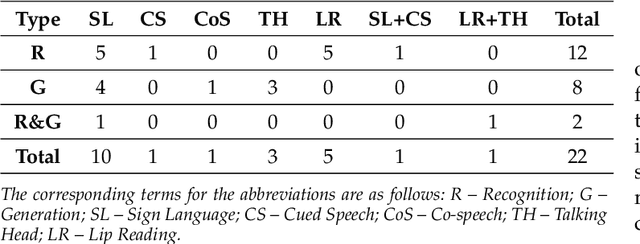
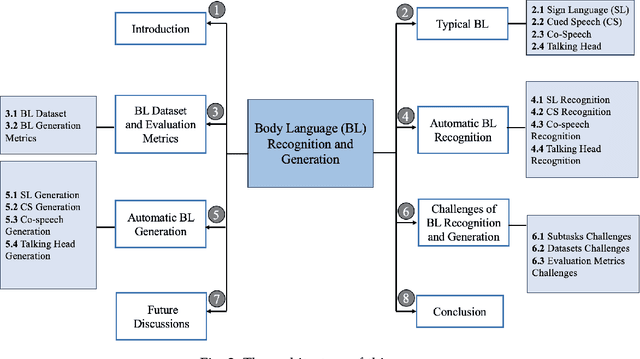
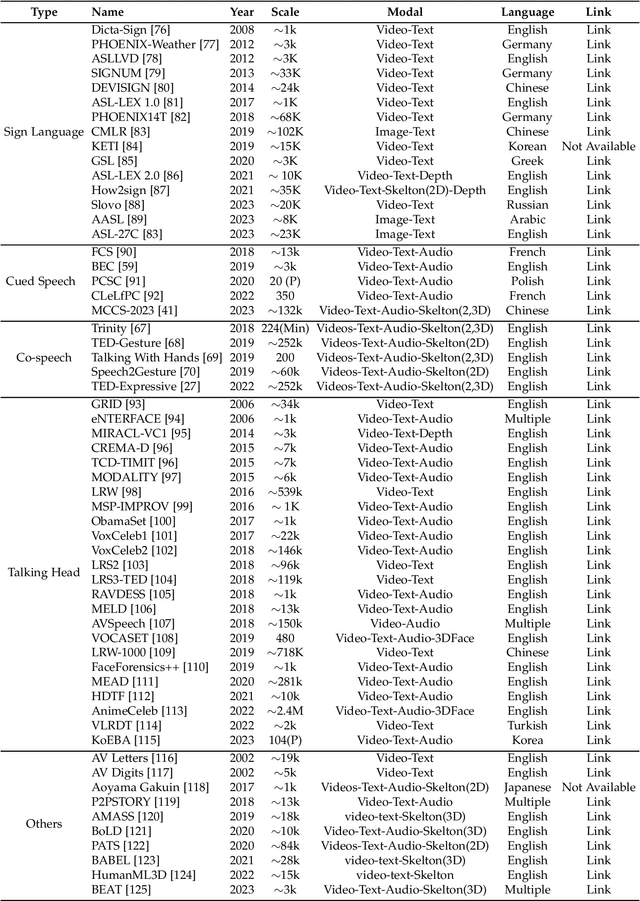
Body language (BL) refers to the non-verbal communication expressed through physical movements, gestures, facial expressions, and postures. It is a form of communication that conveys information, emotions, attitudes, and intentions without the use of spoken or written words. It plays a crucial role in interpersonal interactions and can complement or even override verbal communication. Deep multi-modal learning techniques have shown promise in understanding and analyzing these diverse aspects of BL. The survey emphasizes their applications to BL generation and recognition. Several common BLs are considered i.e., Sign Language (SL), Cued Speech (CS), Co-speech (CoS), and Talking Head (TH), and we have conducted an analysis and established the connections among these four BL for the first time. Their generation and recognition often involve multi-modal approaches. Benchmark datasets for BL research are well collected and organized, along with the evaluation of SOTA methods on these datasets. The survey highlights challenges such as limited labeled data, multi-modal learning, and the need for domain adaptation to generalize models to unseen speakers or languages. Future research directions are presented, including exploring self-supervised learning techniques, integrating contextual information from other modalities, and exploiting large-scale pre-trained multi-modal models. In summary, this survey paper provides a comprehensive understanding of deep multi-modal learning for various BL generations and recognitions for the first time. By analyzing advancements, challenges, and future directions, it serves as a valuable resource for researchers and practitioners in advancing this field. n addition, we maintain a continuously updated paper list for deep multi-modal learning for BL recognition and generation: https://github.com/wentaoL86/awesome-body-language.
SingNet: A Real-time Singing Voice Beat and Downbeat Tracking System
Jun 04, 2023
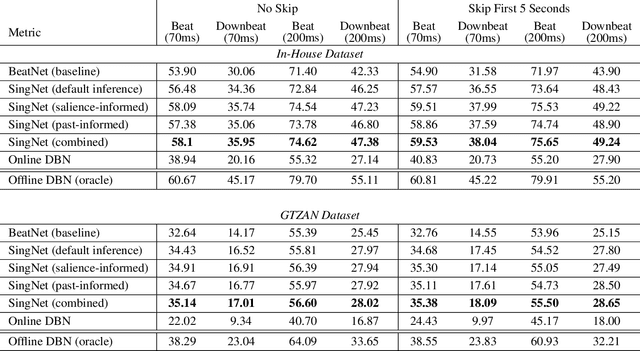
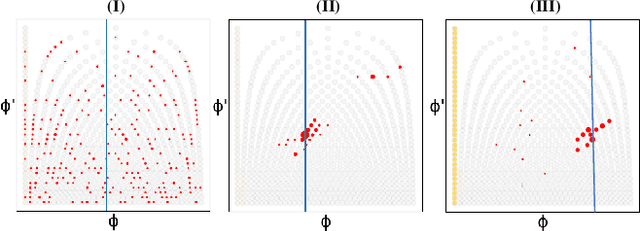
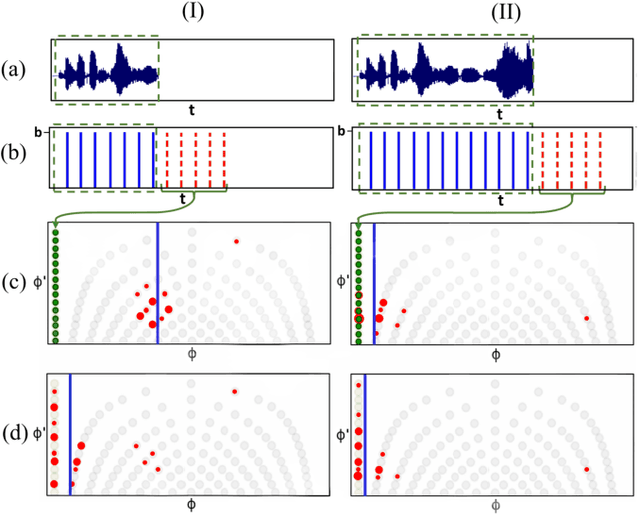
Singing voice beat and downbeat tracking posses several applications in automatic music production, analysis and manipulation. Among them, some require real-time processing, such as live performance processing and auto-accompaniment for singing inputs. This task is challenging owing to the non-trivial rhythmic and harmonic patterns in singing signals. For real-time processing, it introduces further constraints such as inaccessibility to future data and the impossibility to correct the previous results that are inconsistent with the latter ones. In this paper, we introduce the first system that tracks the beats and downbeats of singing voices in real-time. Specifically, we propose a novel dynamic particle filtering approach that incorporates offline historical data to correct the online inference by using a variable number of particles. We evaluate the performance on two datasets: GTZAN with the separated vocal tracks, and an in-house dataset with the original vocal stems. Experimental result demonstrates that our proposed approach outperforms the baseline by 3-5%.
Visibility-Constrained Control of Multirotor via Reference Governor
Aug 10, 2023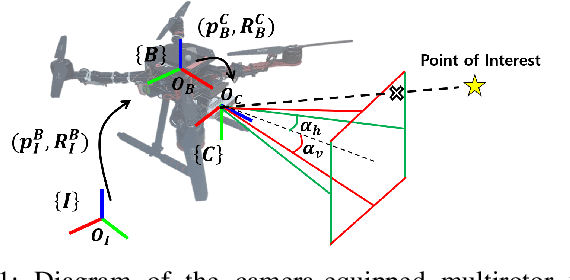
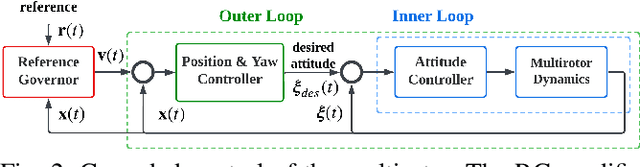
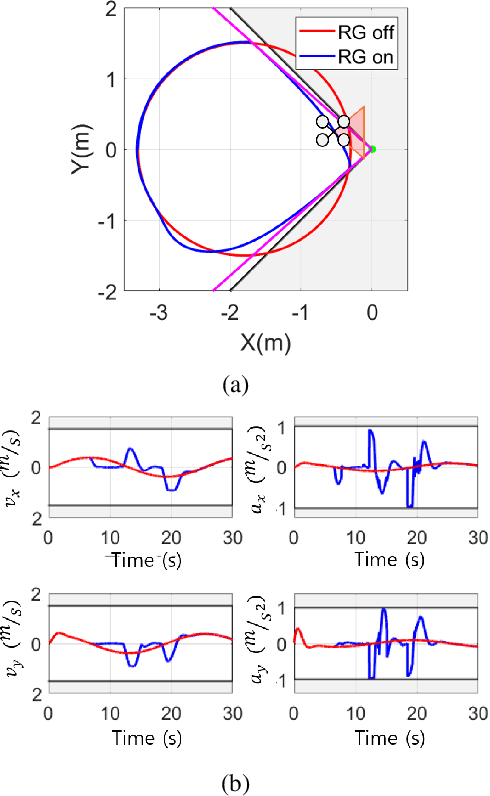
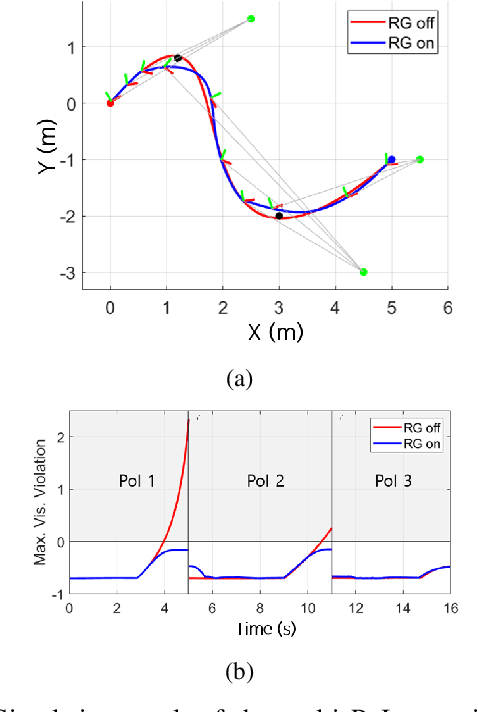
For safe vision-based control applications, perception-related constraints have to be satisfied in addition to other state constraints. In this paper, we deal with the problem where a multirotor equipped with a camera needs to maintain the visibility of a point of interest while tracking a reference given by a high-level planner. We devise a method based on reference governor that, differently from existing solutions, is able to enforce control-level visibility constraints with theoretically assured feasibility. To this end, we design a new type of reference governor for linear systems with polynomial constraints which is capable of handling time-varying references. The proposed solution is implemented online for the real-time multirotor control with visibility constraints and validated with simulations and an actual hardware experiment.
Online Transition-Based Feature Generation for Anomaly Detection in Concurrent Data Streams
Aug 17, 2023In this paper, we introduce the transition-based feature generator (TFGen) technique, which reads general activity data with attributes and generates step-by-step generated data. The activity data may consist of network activity from packets, system calls from processes or classified activity from surveillance cameras. TFGen processes data online and will generate data with encoded historical data for each incoming activity with high computational efficiency. The input activities may concurrently originate from distinct traces or channels. The technique aims to address issues such as domain-independent applicability, the ability to discover global process structures, the encoding of time-series data, and online processing capability.
Towards Privacy-Supporting Fall Detection via Deep Unsupervised RGB2Depth Adaptation
Aug 23, 2023

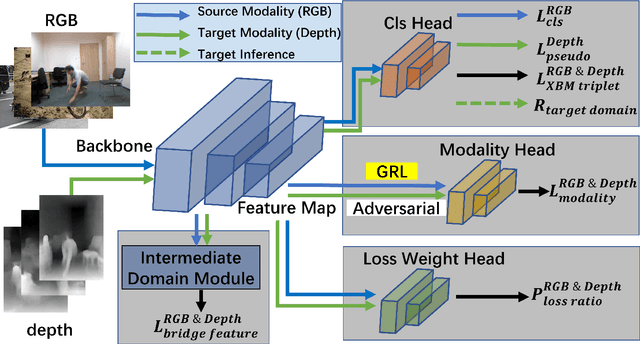
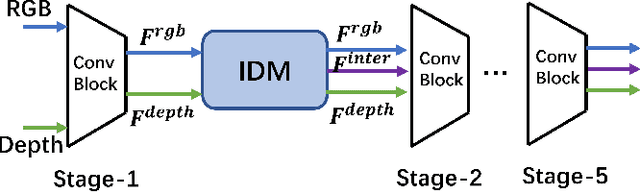
Fall detection is a vital task in health monitoring, as it allows the system to trigger an alert and therefore enabling faster interventions when a person experiences a fall. Although most previous approaches rely on standard RGB video data, such detailed appearance-aware monitoring poses significant privacy concerns. Depth sensors, on the other hand, are better at preserving privacy as they merely capture the distance of objects from the sensor or camera, omitting color and texture information. In this paper, we introduce a privacy-supporting solution that makes the RGB-trained model applicable in depth domain and utilizes depth data at test time for fall detection. To achieve cross-modal fall detection, we present an unsupervised RGB to Depth (RGB2Depth) cross-modal domain adaptation approach that leverages labelled RGB data and unlabelled depth data during training. Our proposed pipeline incorporates an intermediate domain module for feature bridging, modality adversarial loss for modality discrimination, classification loss for pseudo-labeled depth data and labeled source data, triplet loss that considers both source and target domains, and a novel adaptive loss weight adjustment method for improved coordination among various losses. Our approach achieves state-of-the-art results in the unsupervised RGB2Depth domain adaptation task for fall detection. Code is available at https://github.com/1015206533/privacy_supporting_fall_detection.