 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Improved Best-of-both-worlds Algorithm for Bandits with Delayed Feedback
Aug 21, 2023
We propose a new best-of-both-worlds algorithm for bandits with variably delayed feedback. The algorithm improves on prior work by Masoudian et al. [2022] by eliminating the need in prior knowledge of the maximal delay $d_{\mathrm{max}}$ and providing tighter regret bounds in both regimes. The algorithm and its regret bounds are based on counts of outstanding observations (a quantity that is observed at action time) rather than delays or the maximal delay (quantities that are only observed when feedback arrives). One major contribution is a novel control of distribution drift, which is based on biased loss estimators and skipping of observations with excessively large delays. Another major contribution is demonstrating that the complexity of best-of-both-worlds bandits with delayed feedback is characterized by the cumulative count of outstanding observations after skipping of observations with excessively large delays, rather than the delays or the maximal delay.
Proceedings of the 2nd International Workshop on Adaptive Cyber Defense
Aug 18, 2023The 2nd International Workshop on Adaptive Cyber Defense was held at the Florida Institute of Technology, Florida. This workshop was organized to share research that explores unique applications of Artificial Intelligence (AI) and Machine Learning (ML) as foundational capabilities for the pursuit of adaptive cyber defense. The cyber domain cannot currently be reliably and effectively defended without extensive reliance on human experts. Skilled cyber defenders are in short supply and often cannot respond fast enough to cyber threats. Building on recent advances in AI and ML the Cyber defense research community has been motivated to develop new dynamic and sustainable defenses through the adoption of AI and ML techniques to cyber settings. Bridging critical gaps between AI and Cyber researchers and practitioners can accelerate efforts to create semi-autonomous cyber defenses that can learn to recognize and respond to cyber attacks or discover and mitigate weaknesses in cooperation with other cyber operation systems and human experts. Furthermore, these defenses are expected to be adaptive and able to evolve over time to thwart changes in attacker behavior, changes in the system health and readiness, and natural shifts in user behavior over time. The workshop was comprised of invited keynote talks, technical presentations and a panel discussion about how AI/ML can enable autonomous mitigation of current and future cyber attacks. Workshop submissions were peer reviewed by a panel of domain experts with a proceedings consisting of six technical articles exploring challenging problems of critical importance to national and global security. Participation in this workshop offered new opportunities to stimulate research and innovation in the emerging domain of adaptive and autonomous cyber defense.
Multi-Visual-Inertial System: Analysis, Calibration and Estimation
Aug 18, 2023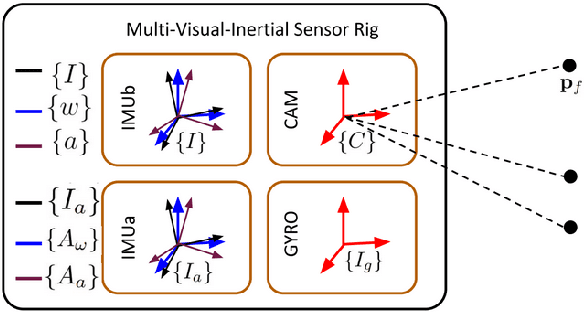



In this paper, we study state estimation of multi-visual-inertial systems (MVIS) and develop sensor fusion algorithms to optimally fuse an arbitrary number of asynchronous inertial measurement units (IMUs) or gyroscopes and global and(or) rolling shutter cameras. We are especially interested in the full calibration of the associated visual-inertial sensors, including the IMU or camera intrinsics and the IMU-IMU(or camera) spatiotemporal extrinsics as well as the image readout time of rolling-shutter cameras (if used). To this end, we develop a new analytic combined IMU integration with intrinsics-termed ACI3-to preintegrate IMU measurements, which is leveraged to fuse auxiliary IMUs and(or) gyroscopes alongside a base IMU. We model the multi-inertial measurements to include all the necessary inertial intrinsic and IMU-IMU spatiotemporal extrinsic parameters, while leveraging IMU-IMU rigid-body constraints to eliminate the necessity of auxiliary inertial poses and thus reducing computational complexity. By performing observability analysis of MVIS, we prove that the standard four unobservable directions remain - no matter how many inertial sensors are used, and also identify, for the first time, degenerate motions for IMU-IMU spatiotemporal extrinsics and auxiliary inertial intrinsics. In addition to the extensive simulations that validate our analysis and algorithms, we have built our own MVIS sensor rig and collected over 25 real-world datasets to experimentally verify the proposed calibration against the state-of-the-art calibration method such as Kalibr. We show that the proposed MVIS calibration is able to achieve competing accuracy with improved convergence and repeatability, which is open sourced to better benefit the community.
Motion-Guided Masking for Spatiotemporal Representation Learning
Aug 24, 2023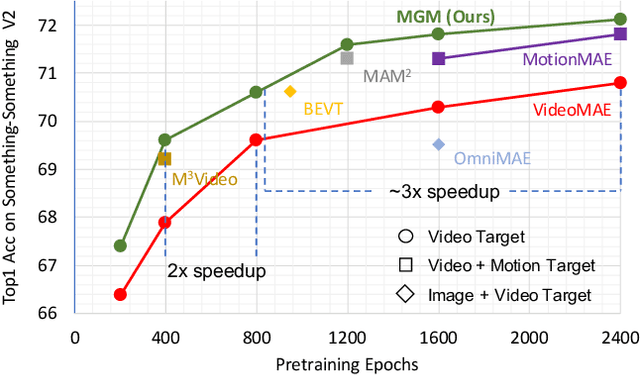
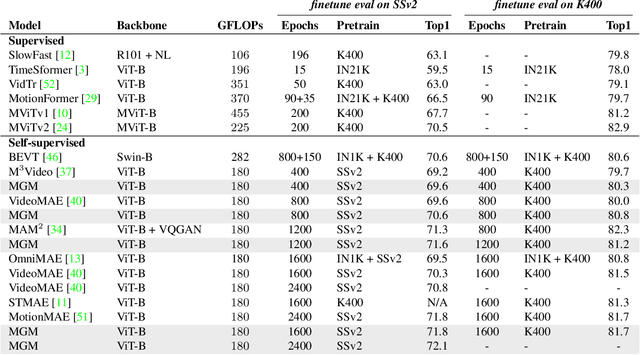
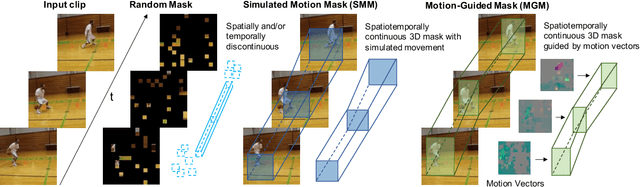
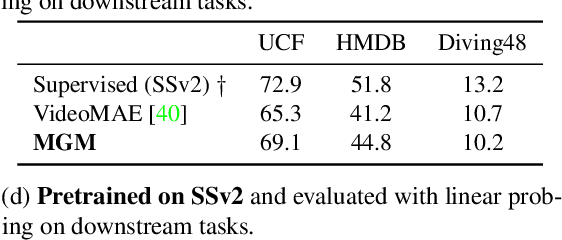
Several recent works have directly extended the image masked autoencoder (MAE) with random masking into video domain, achieving promising results. However, unlike images, both spatial and temporal information are important for video understanding. This suggests that the random masking strategy that is inherited from the image MAE is less effective for video MAE. This motivates the design of a novel masking algorithm that can more efficiently make use of video saliency. Specifically, we propose a motion-guided masking algorithm (MGM) which leverages motion vectors to guide the position of each mask over time. Crucially, these motion-based correspondences can be directly obtained from information stored in the compressed format of the video, which makes our method efficient and scalable. On two challenging large-scale video benchmarks (Kinetics-400 and Something-Something V2), we equip video MAE with our MGM and achieve up to +$1.3\%$ improvement compared to previous state-of-the-art methods. Additionally, our MGM achieves equivalent performance to previous video MAE using up to $66\%$ fewer training epochs. Lastly, we show that MGM generalizes better to downstream transfer learning and domain adaptation tasks on the UCF101, HMDB51, and Diving48 datasets, achieving up to +$4.9\%$ improvement compared to baseline methods.
Short Run Transit Route Planning Decision Support System Using a Deep Learning-Based Weighted Graph
Aug 24, 2023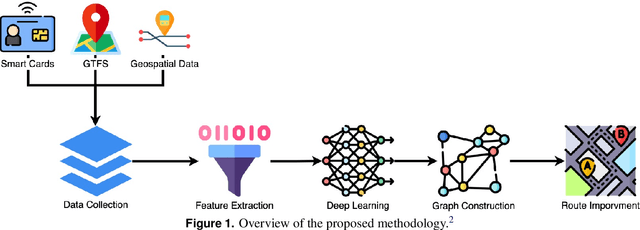
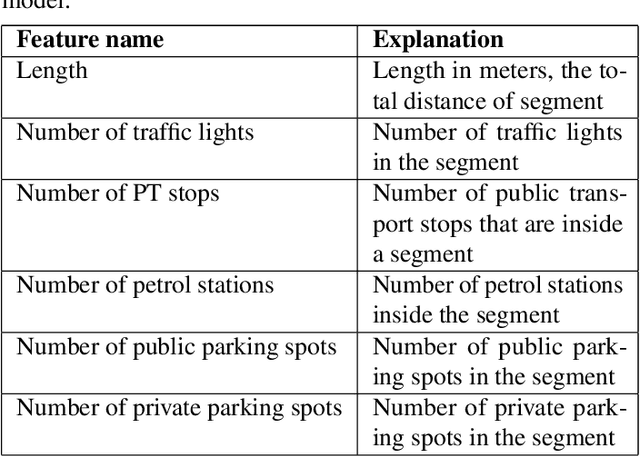
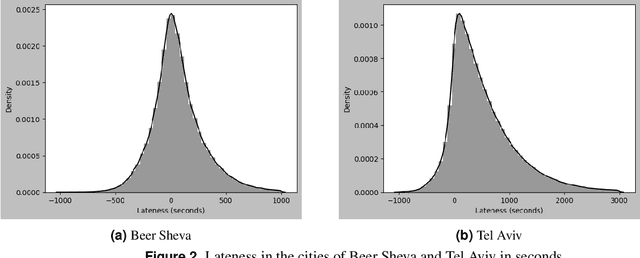
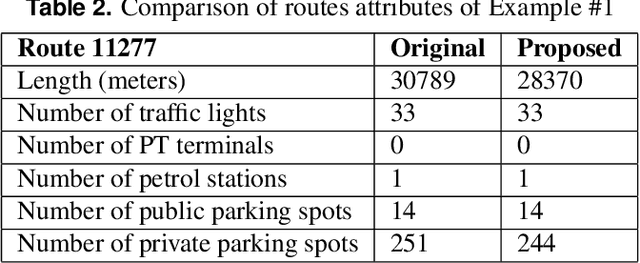
Public transport routing plays a crucial role in transit network design, ensuring a satisfactory level of service for passengers. However, current routing solutions rely on traditional operational research heuristics, which can be time-consuming to implement and lack the ability to provide quick solutions. Here, we propose a novel deep learning-based methodology for a decision support system that enables public transport (PT) planners to identify short-term route improvements rapidly. By seamlessly adjusting specific sections of routes between two stops during specific times of the day, our method effectively reduces times and enhances PT services. Leveraging diverse data sources such as GTFS and smart card data, we extract features and model the transportation network as a directed graph. Using self-supervision, we train a deep learning model for predicting lateness values for road segments. These lateness values are then utilized as edge weights in the transportation graph, enabling efficient path searching. Through evaluating the method on Tel Aviv, we are able to reduce times on more than 9\% of the routes. The improved routes included both intraurban and suburban routes showcasing a fact highlighting the model's versatility. The findings emphasize the potential of our data-driven decision support system to enhance public transport and city logistics, promoting greater efficiency and reliability in PT services.
Robotic Scene Segmentation with Memory Network for Runtime Surgical Context Inference
Aug 24, 2023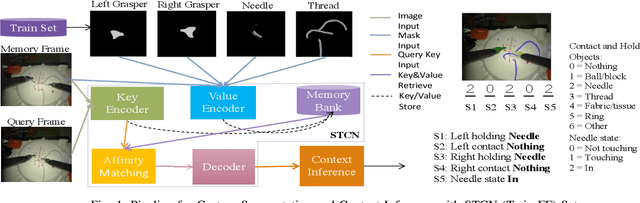
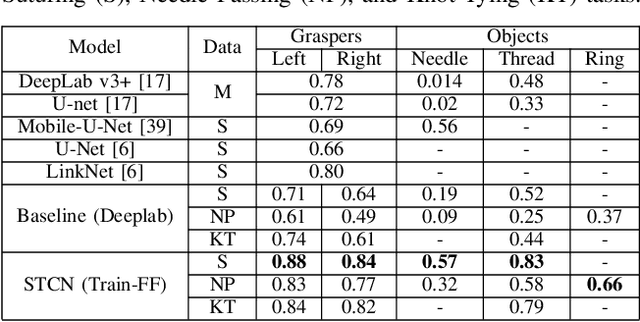
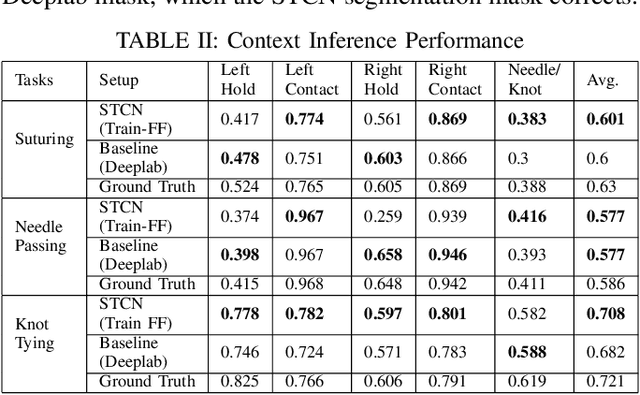

Surgical context inference has recently garnered significant attention in robot-assisted surgery as it can facilitate workflow analysis, skill assessment, and error detection. However, runtime context inference is challenging since it requires timely and accurate detection of the interactions among the tools and objects in the surgical scene based on the segmentation of video data. On the other hand, existing state-of-the-art video segmentation methods are often biased against infrequent classes and fail to provide temporal consistency for segmented masks. This can negatively impact the context inference and accurate detection of critical states. In this study, we propose a solution to these challenges using a Space Time Correspondence Network (STCN). STCN is a memory network that performs binary segmentation and minimizes the effects of class imbalance. The use of a memory bank in STCN allows for the utilization of past image and segmentation information, thereby ensuring consistency of the masks. Our experiments using the publicly available JIGSAWS dataset demonstrate that STCN achieves superior segmentation performance for objects that are difficult to segment, such as needle and thread, and improves context inference compared to the state-of-the-art. We also demonstrate that segmentation and context inference can be performed at runtime without compromising performance.
May the Force be with You: Unified Force-Centric Pre-Training for 3D Molecular Conformations
Aug 24, 2023Recent works have shown the promise of learning pre-trained models for 3D molecular representation. However, existing pre-training models focus predominantly on equilibrium data and largely overlook off-equilibrium conformations. It is challenging to extend these methods to off-equilibrium data because their training objective relies on assumptions of conformations being the local energy minima. We address this gap by proposing a force-centric pretraining model for 3D molecular conformations covering both equilibrium and off-equilibrium data. For off-equilibrium data, our model learns directly from their atomic forces. For equilibrium data, we introduce zero-force regularization and forced-based denoising techniques to approximate near-equilibrium forces. We obtain a unified pre-trained model for 3D molecular representation with over 15 million diverse conformations. Experiments show that, with our pre-training objective, we increase forces accuracy by around 3 times compared to the un-pre-trained Equivariant Transformer model. By incorporating regularizations on equilibrium data, we solved the problem of unstable MD simulations in vanilla Equivariant Transformers, achieving state-of-the-art simulation performance with 2.45 times faster inference time than NequIP. As a powerful molecular encoder, our pre-trained model achieves on-par performance with state-of-the-art property prediction tasks.
A novel approach for predicting epidemiological forecasting parameters based on real-time signals and Data Assimilation
Jul 03, 2023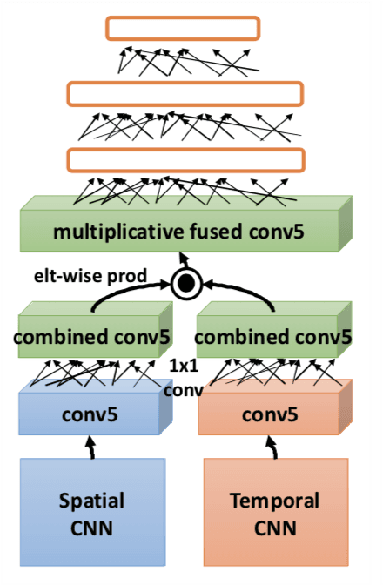
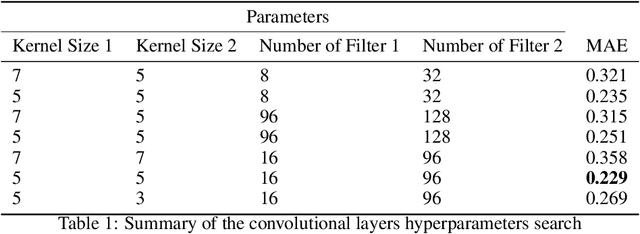
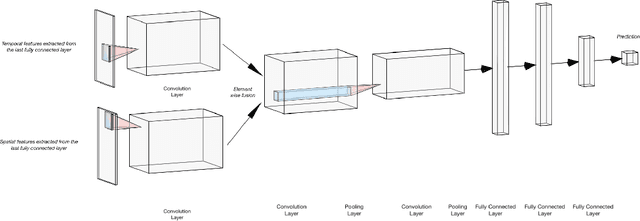
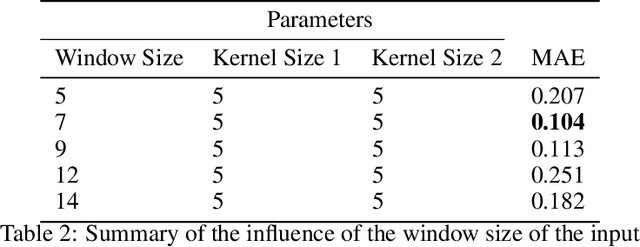
This paper proposes a novel approach to predict epidemiological parameters by integrating new real-time signals from various sources of information, such as novel social media-based population density maps and Air Quality data. We implement an ensemble of Convolutional Neural Networks (CNN) models using various data sources and fusion methodology to build robust predictions and simulate several dynamic parameters that could improve the decision-making process for policymakers. Additionally, we used data assimilation to estimate the state of our system from fused CNN predictions. The combination of meteorological signals and social media-based population density maps improved the performance and flexibility of our prediction of the COVID-19 outbreak in London. While the proposed approach outperforms standard models, such as compartmental models traditionally used in disease forecasting (SEIR), generating robust and consistent predictions allows us to increase the stability of our model while increasing its accuracy.
Mobile robots sampling algorithms for monitoring of insects populations in agricultural fields
Aug 26, 2023Plant diseases are major causes of production losses and may have a significant impact on the agricultural sector. Detecting pests as early as possible can help increase crop yields and production efficiency. Several robotic monitoring systems have been developed allowing to collect data and provide a greater understanding of environmental processes. An agricultural robot can enable accurate timely detection of pests, by traversing the field autonomously and monitoring the entire cropped area within a field. However, in many cases it is impossible to sample all plants due to resource limitations. In this thesis, the development and evaluation of several sampling algorithms are presented to address the challenge of an agriculture-monitoring ground robot designed to locate insects in an agricultural field, where complete sampling of all the plants is infeasible. Two situations were investigated in simulation models that were specially developed as part of this thesis: where no a-priori information on the insects is available and where prior information on the insects distributions within the field is known. For the first situation, seven algorithms were tested, each utilizing an approach to sample the field without prior knowledge of it. For the second situation, we present the development and evaluation of a dynamic sampling algorithm which utilizes real-time information to prioritize sampling at suspected points, locate hot spots and adapt sampling plans accordingly. The algorithm's performance was compared to two existing algorithms using Tetranychidae insect data from previous research. Analyses revealed that the dynamic algorithm outperformed the others.
Prompt-Based Length Controlled Generation with Reinforcement Learning
Aug 23, 2023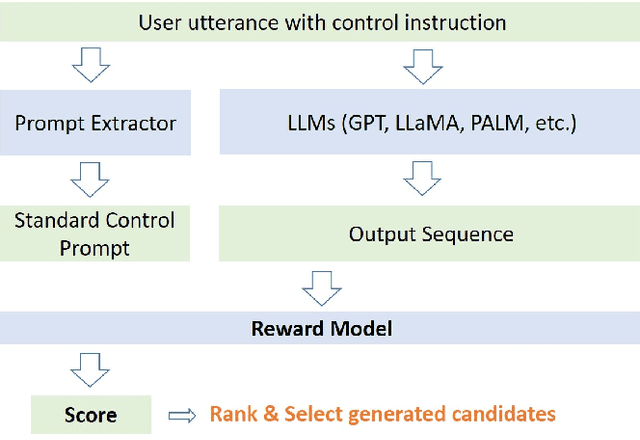
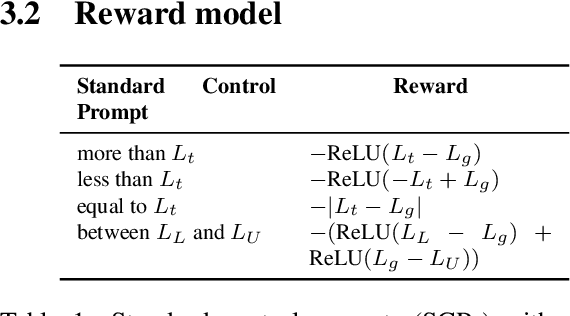


Recently, large language models (LLMs) like ChatGPT and GPT-4 have attracted great attention given their surprising improvement and performance. Length controlled generation of LLMs emerges as an important topic, which also enables users to fully leverage the capability of LLMs in more real-world scenarios like generating a proper answer or essay of a desired length. In addition, the autoregressive generation in LLMs is extremely time-consuming, while the ability of controlling this generated length can arbitrarily reduce the inference cost by limiting the length, and thus satisfy different needs. Therefore, we aim to propose a prompt-based length control method to achieve this length controlled generation, which can also be widely applied in GPT-style LLMs. In particular, we adopt reinforcement learning with the reward signal given by either trainable or rule-based reward model, which further affects the generation of LLMs via rewarding a pre-defined target length. Experiments show that our method significantly improves the accuracy of prompt-based length control for summarization task on popular datasets like CNNDM and NYT. We believe this length-controllable ability can provide more potentials towards the era of LLMs.