 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FrFT based estimation of linear and nonlinear impairments using Vision Transformer
Aug 25, 2023
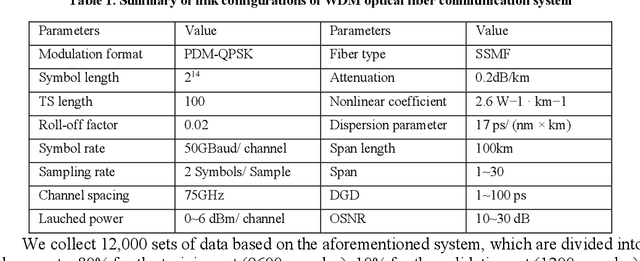
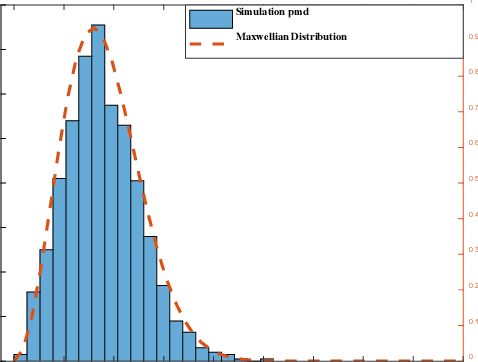
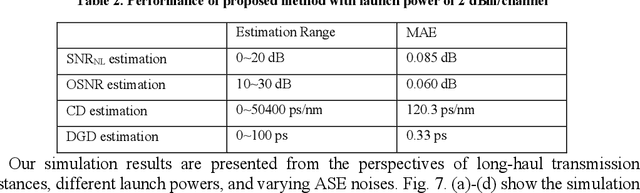
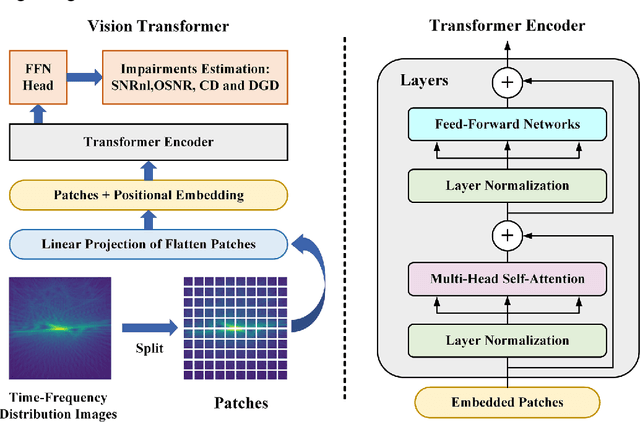
To comprehensively assess optical fiber communication system conditions, it is essential to implement joint estimation of the following four critical impairments: nonlinear signal-to-noise ratio (SNRNL), optical signal-to-noise ratio (OSNR), chromatic dispersion (CD) and differential group delay (DGD). However, current studies only achieve identifying a limited number of impairments within a narrow range, due to limitations in network capabilities and lack of unified representation of impairments. To address these challenges, we adopt time-frequency signal processing based on fractional Fourier transform (FrFT) to achieve the unified representation of impairments, while employing a Transformer based neural networks (NN) to break through network performance limitations. To verify the effectiveness of the proposed estimation method, the numerical simulation is carried on a 5-channel polarization-division-multiplexed quadrature phase shift keying (PDM-QPSK) long haul optical transmission system with the symbol rate of 50 GBaud per channel, the mean absolute error (MAE) for SNRNL, OSNR, CD, and DGD estimation is 0.091 dB, 0.058 dB, 117 ps/nm, and 0.38 ps, and the monitoring window ranges from 0~20 dB, 10~30 dB, 0~51000 ps/nm, and 0~100 ps, respectively. Our proposed method achieves accurate estimation of linear and nonlinear impairments over a broad range, representing a significant advancement in the field of optical performance monitoring (OPM).
MultiCapCLIP: Auto-Encoding Prompts for Zero-Shot Multilingual Visual Captioning
Aug 25, 2023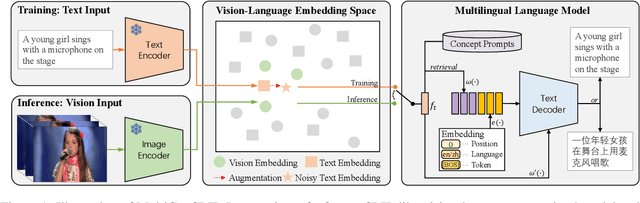
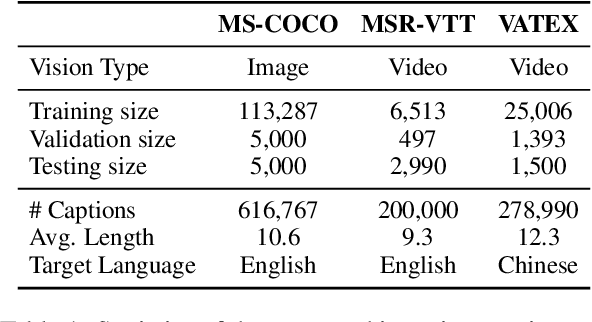
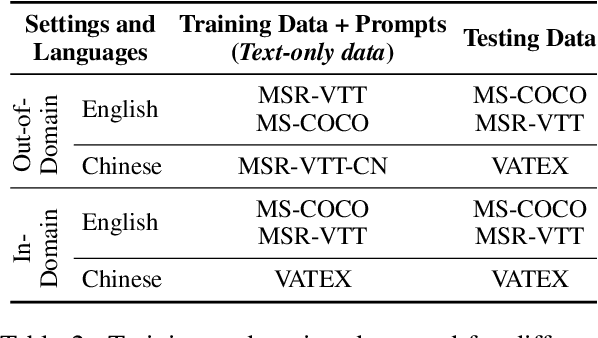
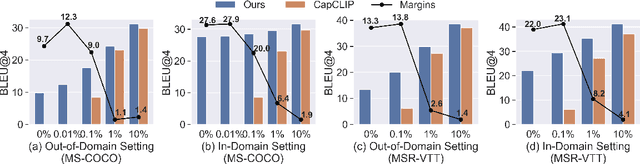
Supervised visual captioning models typically require a large scale of images or videos paired with descriptions in a specific language (i.e., the vision-caption pairs) for training. However, collecting and labeling large-scale datasets is time-consuming and expensive for many scenarios and languages. Therefore, sufficient labeled pairs are usually not available. To deal with the label shortage problem, we present a simple yet effective zero-shot approach MultiCapCLIP that can generate visual captions for different scenarios and languages without any labeled vision-caption pairs of downstream datasets. In the training stage, MultiCapCLIP only requires text data for input. Then it conducts two main steps: 1) retrieving concept prompts that preserve the corresponding domain knowledge of new scenarios; 2) auto-encoding the prompts to learn writing styles to output captions in a desired language. In the testing stage, MultiCapCLIP instead takes visual data as input directly to retrieve the concept prompts to generate the final visual descriptions. The extensive experiments on image and video captioning across four benchmarks and four languages (i.e., English, Chinese, German, and French) confirm the effectiveness of our approach. Compared with state-of-the-art zero-shot and weakly-supervised methods, our method achieves 4.8% and 21.5% absolute improvements in terms of BLEU@4 and CIDEr metrics. Our code is available at https://github.com/yangbang18/MultiCapCLIP.
A Generic Machine Learning Framework for Fully-Unsupervised Anomaly Detection with Contaminated Data
Aug 25, 2023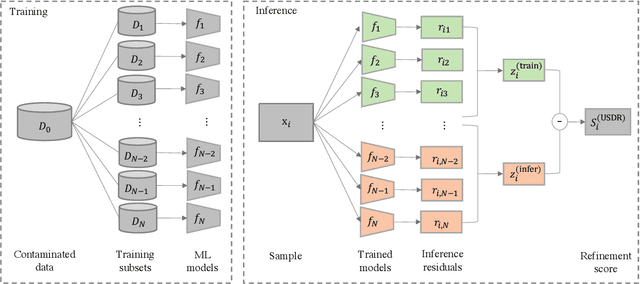
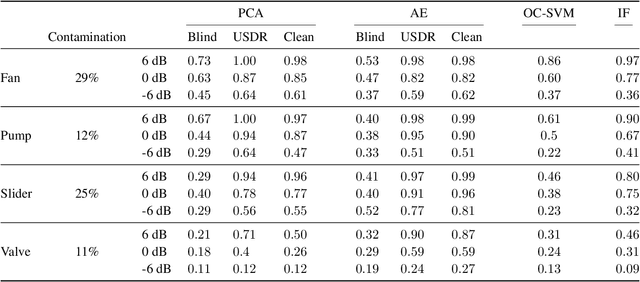
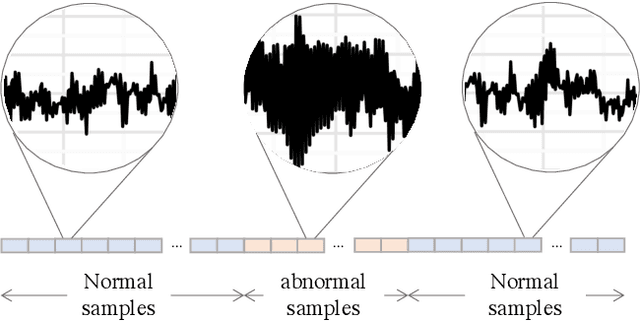
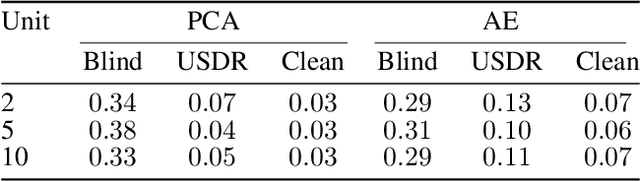
Anomaly detection (AD) tasks have been solved using machine learning algorithms in various domains and applications. The great majority of these algorithms use normal data to train a residual-based model, and assign anomaly scores to unseen samples based on their dissimilarity with the learned normal regime. The underlying assumption of these approaches is that anomaly-free data is available for training. This is, however, often not the case in real-world operational settings, where the training data may be contaminated with a certain fraction of abnormal samples. Training with contaminated data, in turn, inevitably leads to a deteriorated AD performance of the residual-based algorithms. In this paper we introduce a framework for a fully unsupervised refinement of contaminated training data for AD tasks. The framework is generic and can be applied to any residual-based machine learning model. We demonstrate the application of the framework to two public datasets of multivariate time series machine data from different application fields. We show its clear superiority over the naive approach of training with contaminated data without refinement. Moreover, we compare it to the ideal, unrealistic reference in which anomaly-free data would be available for training. Since the approach exploits information from the anomalies, and not only from the normal regime, it is comparable and often outperforms the ideal baseline as well.
Real-time Seismic Intensity Prediction using Self-supervised Contrastive GNN for Earthquake Early Warning
Jun 25, 2023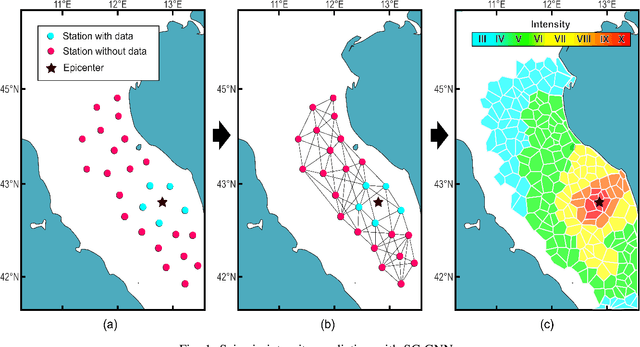
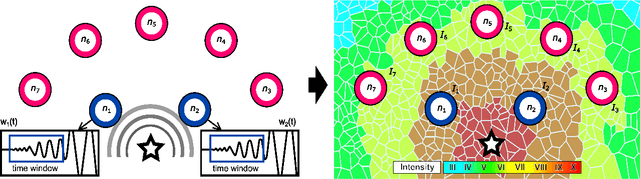
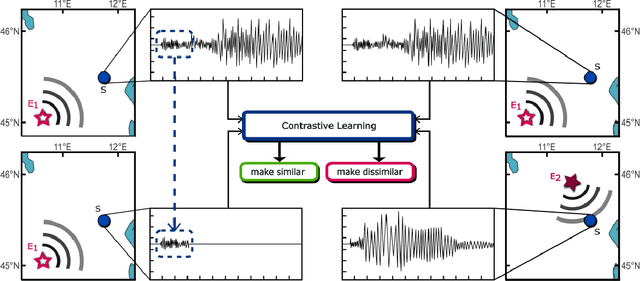
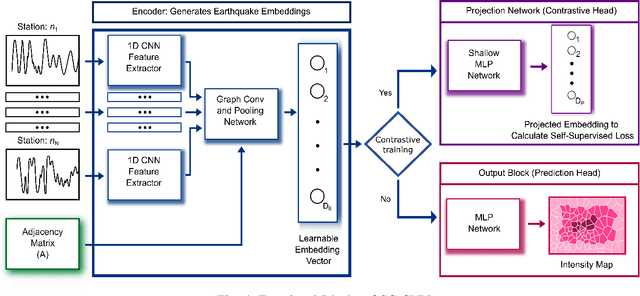
Seismic intensity prediction in a geographical area from early or initial seismic waves received by a few seismic stations is a critical component of an effective Earthquake Early Warning (EEW) system. State-of-the-art deep learning-based techniques for this task suffer from limited accuracy in the prediction and, more importantly, require input waveforms of a large time window from a handful number of seismic stations, which is not practical for EEW systems. To overcome the above limitations, in this paper, we propose a novel deep learning approach, Seismic Contrastive Graph Neural Network (SC-GNN) for highly accurate seismic intensity prediction using a small portion of initial seismic waveforms received by a few seismic stations. The SC-GNN comprises two key components: (i) a graph neural network (GNN) to propagate spatiotemporal information through the nodes of a graph-like structure of seismic station distribution and wave propagation, and (ii) a self-supervised contrastive learning component to train the model with larger time windows and make predictions using shorter initial waveforms. The efficacy of our proposed model is thoroughly evaluated through experiments on three real-world seismic datasets, showing superior performance over existing state-of-the-art techniques. In particular, the SC-GNN model demonstrates a substantial reduction in mean squared error (MSE) and the lowest standard deviation of the error, indicating its robustness, reliability, and a strong positive relationship between predicted and actual values. More importantly, the model maintains superior performance even with 5s input waveforms, making it particularly efficient for EEW systems.
Can Transformers Learn Optimal Filtering for Unknown Systems?
Aug 16, 2023Transformers have demonstrated remarkable success in natural language processing; however, their potential remains mostly unexplored for problems arising in dynamical systems. In this work, we investigate the optimal output estimation problem using transformers, which generate output predictions using all the past ones. We train the transformer using various systems drawn from a prior distribution and then evaluate its performance on previously unseen systems from the same distribution. As a result, the obtained transformer acts like a prediction algorithm that learns in-context and quickly adapts to and predicts well for different systems - thus we call it meta-output-predictor (MOP). MOP matches the performance of the optimal output estimator, based on Kalman filter, for most linear dynamical systems even though it does not have access to a model. We observe via extensive numerical experiments that MOP also performs well in challenging scenarios with non-i.i.d. noise, time-varying dynamics, and nonlinear dynamics like a quadrotor system with unknown parameters. To further support this observation, in the second part of the paper, we provide statistical guarantees on the performance of MOP and quantify the required amount of training to achieve a desired excess risk during test-time. Finally, we point out some limitations of MOP by identifying two classes of problems MOP fails to perform well, highlighting the need for caution when using transformers for control and estimation.
Fast Uncertainty Quantification of Spent Nuclear Fuel with Neural Networks
Aug 16, 2023The accurate calculation and uncertainty quantification of the characteristics of spent nuclear fuel (SNF) play a crucial role in ensuring the safety, efficiency, and sustainability of nuclear energy production, waste management, and nuclear safeguards. State of the art physics-based models, while reliable, are computationally intensive and time-consuming. This paper presents a surrogate modeling approach using neural networks (NN) to predict a number of SNF characteristics with reduced computational costs compared to physics-based models. An NN is trained using data generated from CASMO5 lattice calculations. The trained NN accurately predicts decay heat and nuclide concentrations of SNF, as a function of key input parameters, such as enrichment, burnup, cooling time between cycles, mean boron concentration and fuel temperature. The model is validated against physics-based decay heat simulations and measurements of different uranium oxide fuel assemblies from two different pressurized water reactors. In addition, the NN is used to perform sensitivity analysis and uncertainty quantification. The results are in very good alignment to CASMO5, while the computational costs (taking into account the costs of generating training samples) are reduced by a factor of 10 or more. Our findings demonstrate the feasibility of using NNs as surrogate models for fast characterization of SNF, providing a promising avenue for improving computational efficiency in assessing nuclear fuel behavior and associated risks.
Contrastive Shapelet Learning for Unsupervised Multivariate Time Series Representation Learning
Jun 02, 2023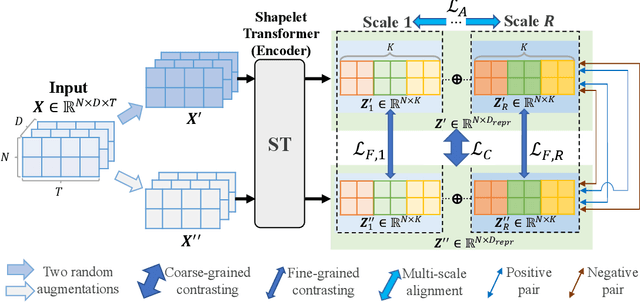
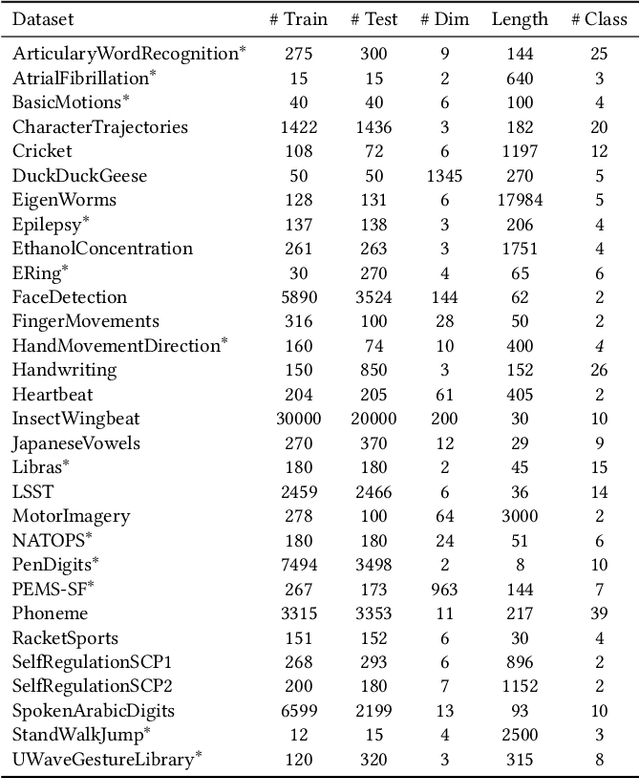
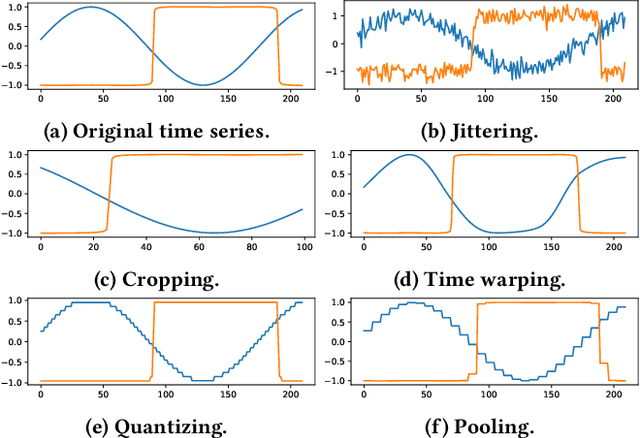
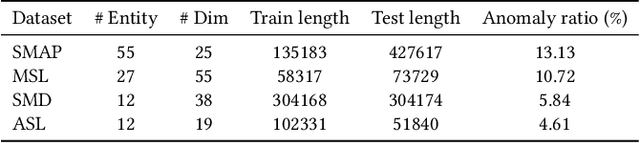
Recent studies have shown great promise in unsupervised representation learning (URL) for multivariate time series, because URL has the capability in learning generalizable representation for many downstream tasks without using inaccessible labels. However, existing approaches usually adopt the models originally designed for other domains (e.g., computer vision) to encode the time series data and rely on strong assumptions to design learning objectives, which limits their ability to perform well. To deal with these problems, we propose a novel URL framework for multivariate time series by learning time-series-specific shapelet-based representation through a popular contrasting learning paradigm. To the best of our knowledge, this is the first work that explores the shapelet-based embedding in the unsupervised general-purpose representation learning. A unified shapelet-based encoder and a novel learning objective with multi-grained contrasting and multi-scale alignment are particularly designed to achieve our goal, and a data augmentation library is employed to improve the generalization. We conduct extensive experiments using tens of real-world datasets to assess the representation quality on many downstream tasks, including classification, clustering, and anomaly detection. The results demonstrate the superiority of our method against not only URL competitors, but also techniques specially designed for downstream tasks. Our code has been made publicly available at https://github.com/real2fish/CSL.
Neural Networks Optimizations Against Concept and Data Drift in Malware Detection
Aug 21, 2023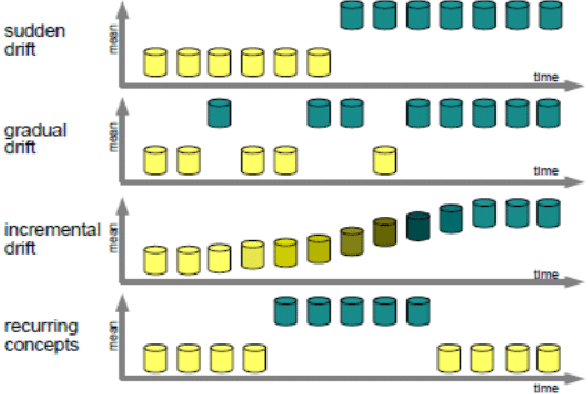
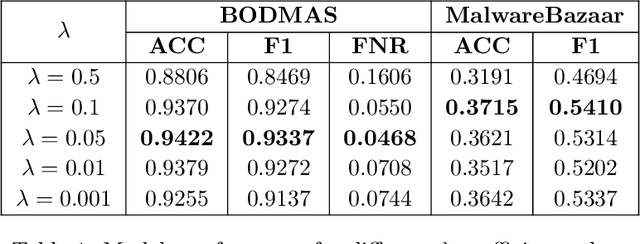
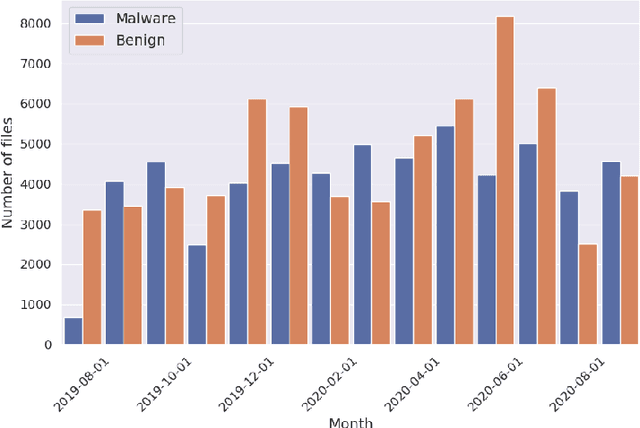
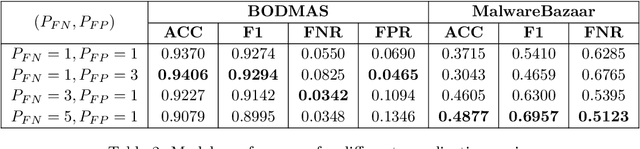
Despite the promising results of machine learning models in malware detection, they face the problem of concept drift due to malware constant evolution. This leads to a decline in performance over time, as the data distribution of the new files differs from the training one, requiring regular model update. In this work, we propose a model-agnostic protocol to improve a baseline neural network to handle with the drift problem. We show the importance of feature reduction and training with the most recent validation set possible, and propose a loss function named Drift-Resilient Binary Cross-Entropy, an improvement to the classical Binary Cross-Entropy more effective against drift. We train our model on the EMBER dataset (2018) and evaluate it on a dataset of recent malicious files, collected between 2020 and 2023. Our improved model shows promising results, detecting 15.2% more malware than a baseline model.
An Anchor-Point Based Image-Model for Room Impulse Response Simulation with Directional Source Radiation and Sensor Directivity Patterns
Aug 21, 2023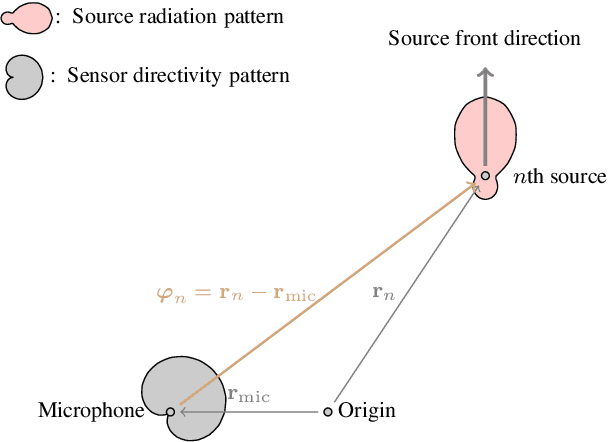

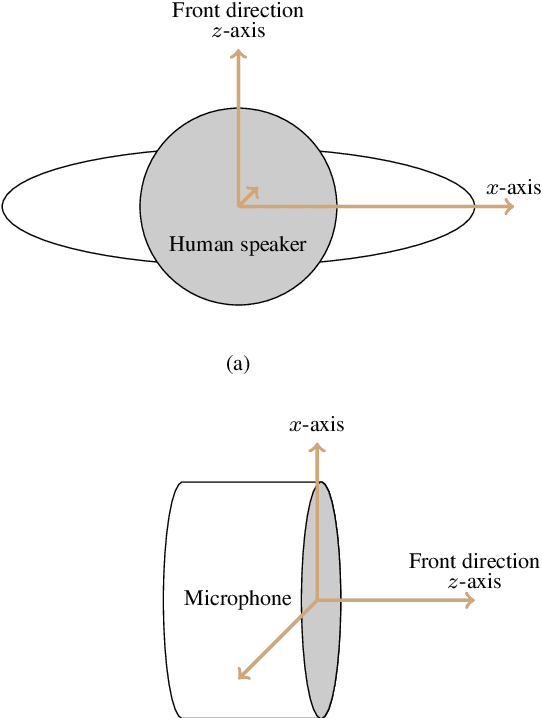
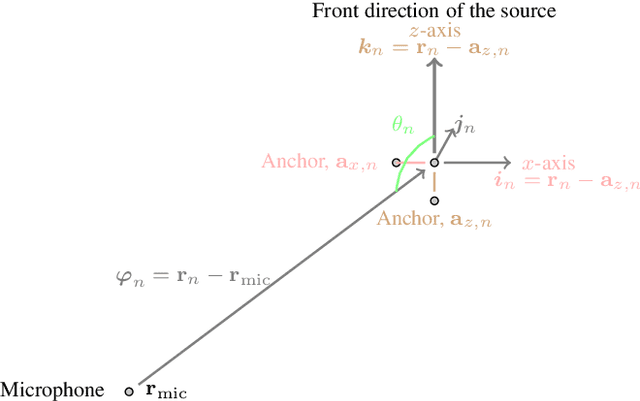
The image model method has been widely used to simulate room impulse responses and the endeavor to adapt this method to different applications has also piqued great interest over the last few decades. This paper attempts to extend the image model method and develops an anchor-point-image-model (APIM) approach as a solution for simulating impulse responses by including both the source radiation and sensor directivity patterns. To determine the orientations of all the virtual sources, anchor points are introduced to real sources, which subsequently lead to the determination of the orientations of the virtual sources. An algorithm is developed to generate room impulse responses with APIM by taking into account the directional pattern functions, factional time delays, as well as the computational complexity. The developed model and algorithms can be used in various acoustic problems to simulate room acoustics and improve and evaluate processing algorithms.
EVE: Efficient zero-shot text-based Video Editing with Depth Map Guidance and Temporal Consistency Constraints
Aug 21, 2023
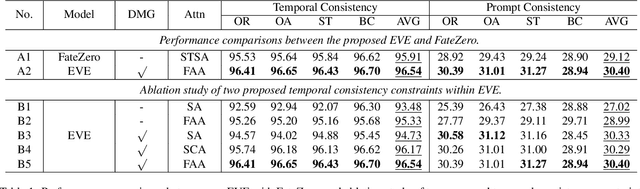
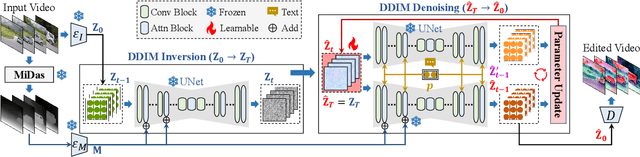

Motivated by the superior performance of image diffusion models, more and more researchers strive to extend these models to the text-based video editing task. Nevertheless, current video editing tasks mainly suffer from the dilemma between the high fine-tuning cost and the limited generation capacity. Compared with images, we conjecture that videos necessitate more constraints to preserve the temporal consistency during editing. Towards this end, we propose EVE, a robust and efficient zero-shot video editing method. Under the guidance of depth maps and temporal consistency constraints, EVE derives satisfactory video editing results with an affordable computational and time cost. Moreover, recognizing the absence of a publicly available video editing dataset for fair comparisons, we construct a new benchmark ZVE-50 dataset. Through comprehensive experimentation, we validate that EVE could achieve a satisfactory trade-off between performance and efficiency. We will release our dataset and codebase to facilitate future researchers.