 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian estimation and reconstruction of marine surface contaminant dispersion
Sep 04, 2023
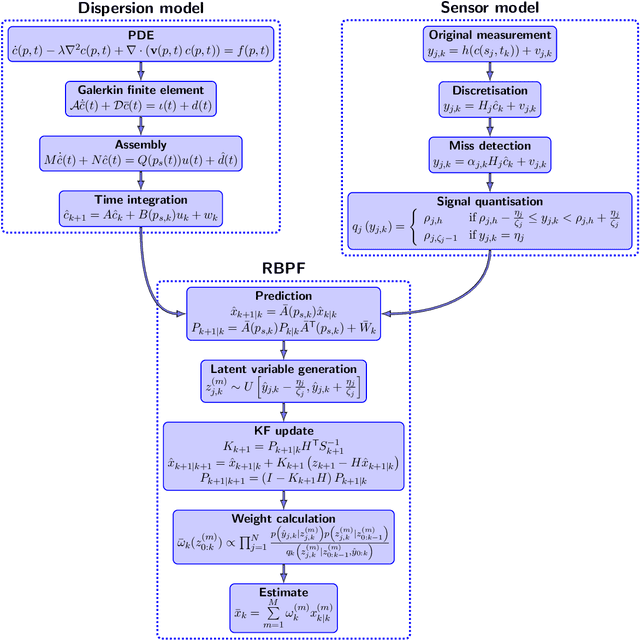
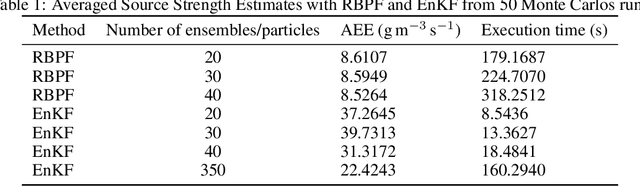
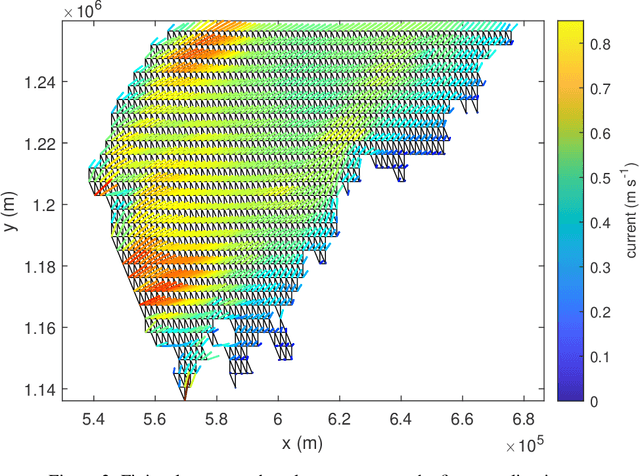
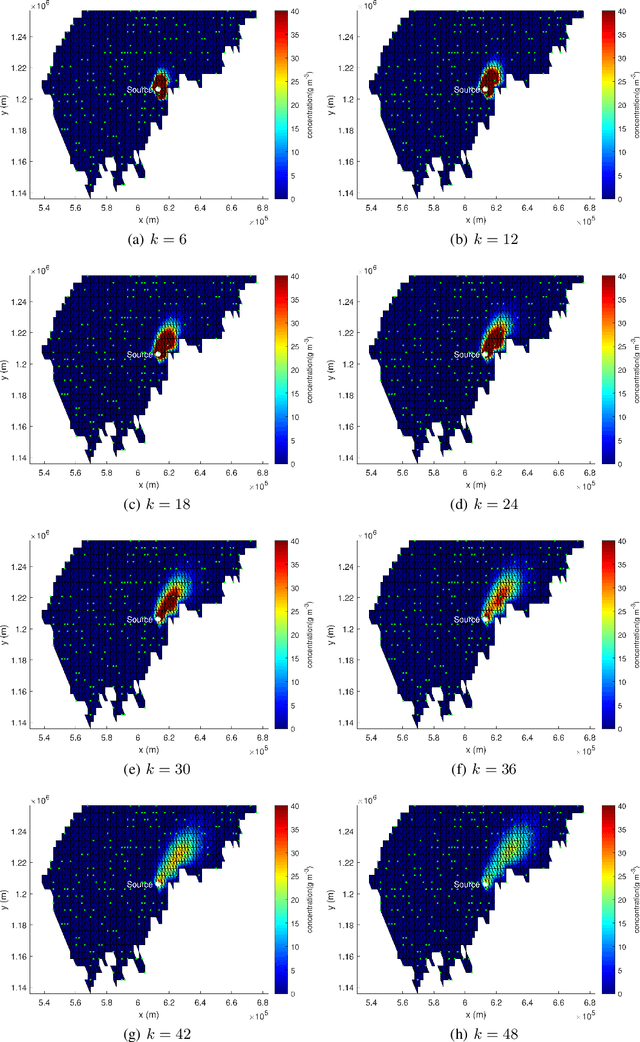
Discharge of hazardous substances into the marine environment poses a substantial risk to both public health and the ecosystem. In such incidents, it is imperative to accurately estimate the release strength of the source and reconstruct the spatio-temporal dispersion of the substances based on the collected measurements. In this study, we propose an integrated estimation framework to tackle this challenge, which can be used in conjunction with a sensor network or a mobile sensor for environment monitoring. We employ the fundamental convection-diffusion partial differential equation (PDE) to represent the general dispersion of a physical quantity in a non-uniform flow field. The PDE model is spatially discretised into a linear state-space model using the dynamic transient finite-element method (FEM) so that the characterisation of time-varying dispersion can be cast into the problem of inferring the model states from sensor measurements. We also consider imperfect sensing phenomena, including miss-detection and signal quantisation, which are frequently encountered when using a sensor network. This complicated sensor process introduces nonlinearity into the Bayesian estimation process. A Rao-Blackwellised particle filter (RBPF) is designed to provide an effective solution by exploiting the linear structure of the state-space model, whereas the nonlinearity of the measurement model can be handled by Monte Carlo approximation with particles. The proposed framework is validated using a simulated oil spill incident in the Baltic sea with real ocean flow data. The results show the efficacy of the developed spatio-temporal dispersion model and estimation schemes in the presence of imperfect measurements. Moreover, the parameter selection process is discussed, along with some comparison studies to illustrate the advantages of the proposed algorithm over existing methods.
Food Image Classification and Segmentation with Attention-based Multiple Instance Learning
Aug 22, 2023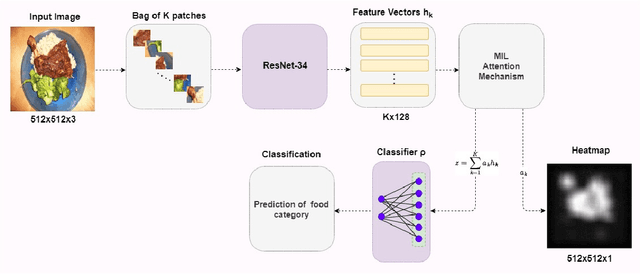
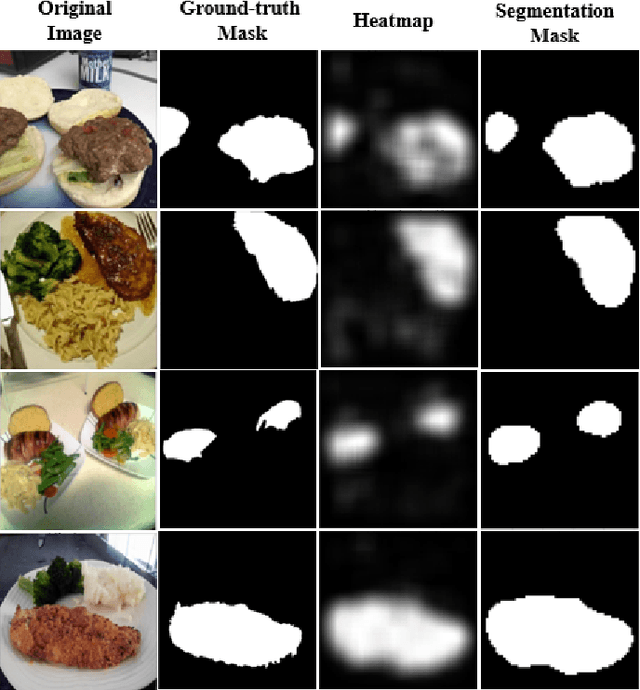
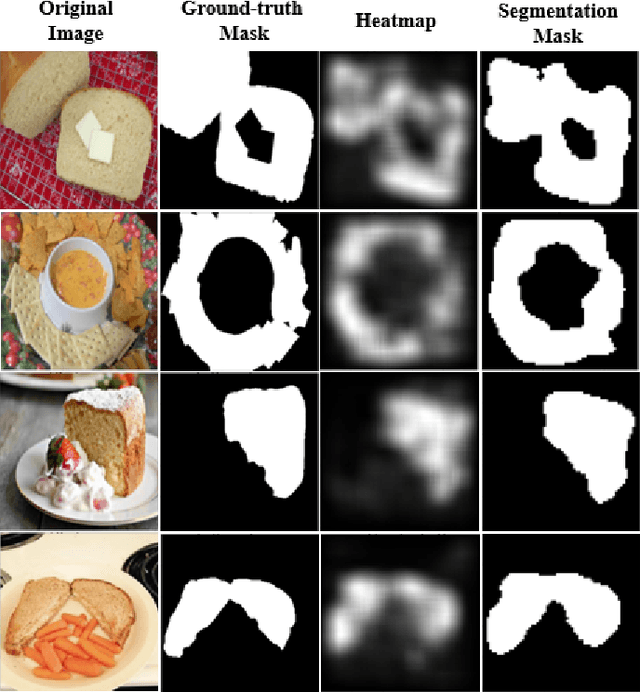
The demand for accurate food quantification has increased in the recent years, driven by the needs of applications in dietary monitoring. At the same time, computer vision approaches have exhibited great potential in automating tasks within the food domain. Traditionally, the development of machine learning models for these problems relies on training data sets with pixel-level class annotations. However, this approach introduces challenges arising from data collection and ground truth generation that quickly become costly and error-prone since they must be performed in multiple settings and for thousands of classes. To overcome these challenges, the paper presents a weakly supervised methodology for training food image classification and semantic segmentation models without relying on pixel-level annotations. The proposed methodology is based on a multiple instance learning approach in combination with an attention-based mechanism. At test time, the models are used for classification and, concurrently, the attention mechanism generates semantic heat maps which are used for food class segmentation. In the paper, we conduct experiments on two meta-classes within the FoodSeg103 data set to verify the feasibility of the proposed approach and we explore the functioning properties of the attention mechanism.
Can Authorship Representation Learning Capture Stylistic Features?
Aug 22, 2023Automatically disentangling an author's style from the content of their writing is a longstanding and possibly insurmountable problem in computational linguistics. At the same time, the availability of large text corpora furnished with author labels has recently enabled learning authorship representations in a purely data-driven manner for authorship attribution, a task that ostensibly depends to a greater extent on encoding writing style than encoding content. However, success on this surrogate task does not ensure that such representations capture writing style since authorship could also be correlated with other latent variables, such as topic. In an effort to better understand the nature of the information these representations convey, and specifically to validate the hypothesis that they chiefly encode writing style, we systematically probe these representations through a series of targeted experiments. The results of these experiments suggest that representations learned for the surrogate authorship prediction task are indeed sensitive to writing style. As a consequence, authorship representations may be expected to be robust to certain kinds of data shift, such as topic drift over time. Additionally, our findings may open the door to downstream applications that require stylistic representations, such as style transfer.
Noise-Free Sampling Algorithms via Regularized Wasserstein Proximals
Aug 30, 2023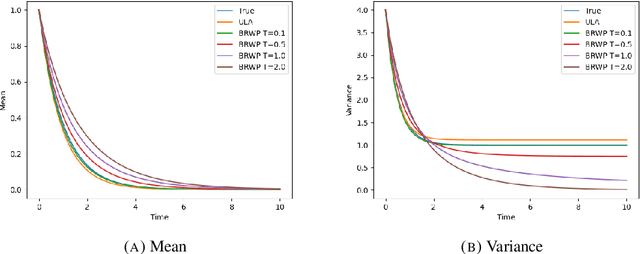
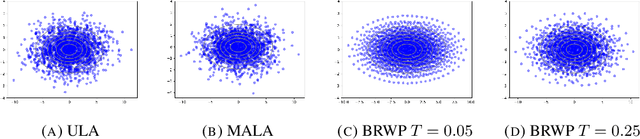
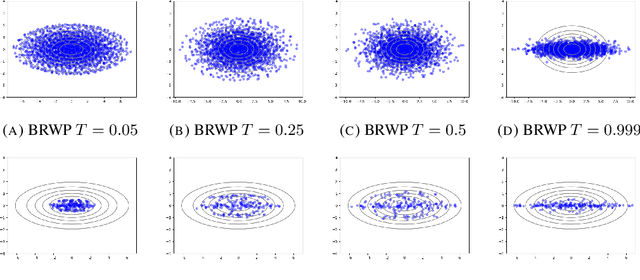
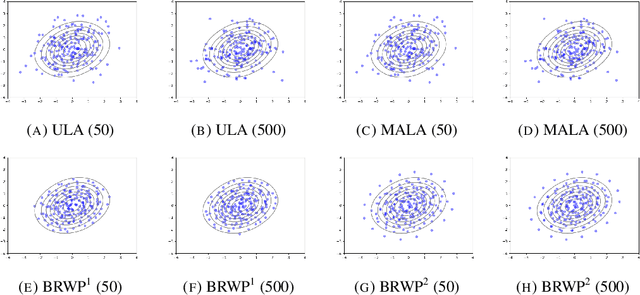
We consider the problem of sampling from a distribution governed by a potential function. This work proposes an explicit score-based MCMC method that is deterministic, resulting in a deterministic evolution for particles rather than a stochastic differential equation evolution. The score term is given in closed form by a regularized Wasserstein proximal, using a kernel convolution that is approximated by sampling. We demonstrate fast convergence on various problems and show improved dimensional dependence of mixing time bounds for the case of Gaussian distributions compared to the unadjusted Langevin algorithm (ULA) and the Metropolis-adjusted Langevin algorithm (MALA). We additionally derive closed form expressions for the distributions at each iterate for quadratic potential functions, characterizing the variance reduction. Empirical results demonstrate that the particles behave in an organized manner, lying on level set contours of the potential. Moreover, the posterior mean estimator of the proposed method is shown to be closer to the maximum a-posteriori estimator compared to ULA and MALA, in the context of Bayesian logistic regression.
Denoising Attention for Query-aware User Modeling in Personalized Search
Aug 30, 2023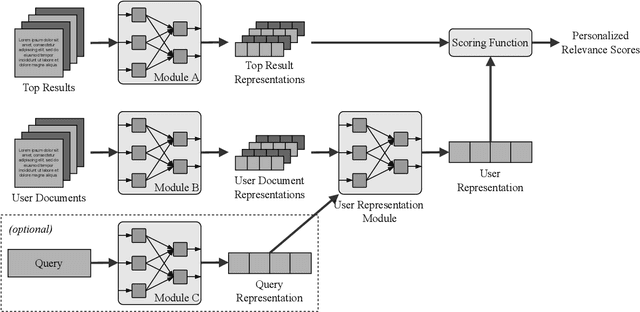
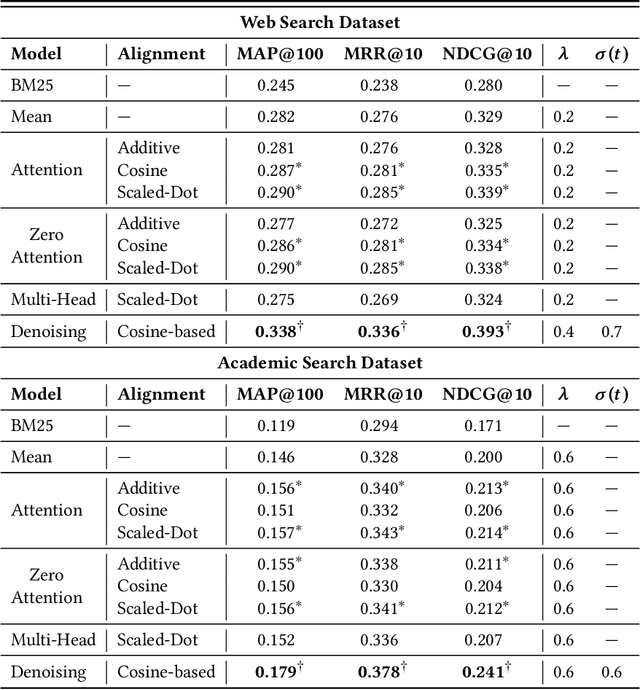
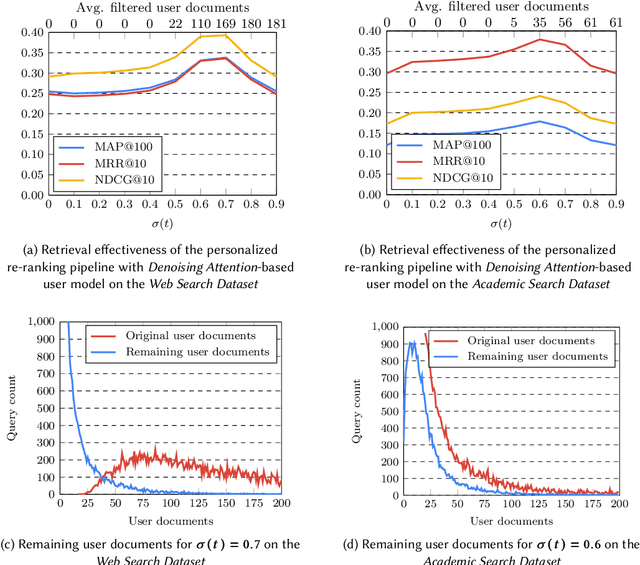
The personalization of search results has gained increasing attention in the past few years, thanks to the development of Neural Networks-based approaches for Information Retrieval and the importance of personalization in many search scenarios. Recent works have proposed to build user models at query time by leveraging the Attention mechanism, which allows weighing the contribution of the user-related information w.r.t. the current query. This approach allows taking into account the diversity of the user's interests by giving more importance to those related to the current search performed by the user. In this paper, we first discuss some shortcomings of the standard Attention formulation when employed for personalization. In particular, we focus on issues related to its normalization mechanism and its inability to entirely filter out noisy user-related information. Then, we introduce the Denoising Attention mechanism: an Attention variant that directly tackles the above shortcomings by adopting a robust normalization scheme and introducing a filtering mechanism. The reported experimental evaluation shows the benefits of the proposed approach over other Attention-based variants.
Emoji Promotes Developer Participation and Issue Resolution on GitHub
Aug 30, 2023


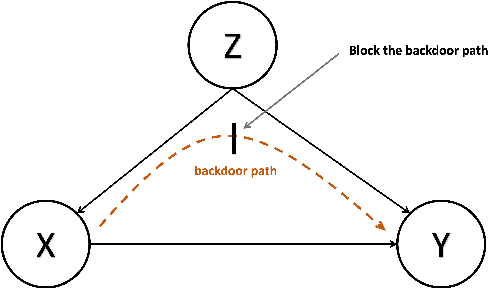
Although remote working is increasingly adopted during the pandemic, many are concerned by the low-efficiency in the remote working. Missing in text-based communication are non-verbal cues such as facial expressions and body language, which hinders the effective communication and negatively impacts the work outcomes. Prevalent on social media platforms, emojis, as alternative non-verbal cues, are gaining popularity in the virtual workspaces well. In this paper, we study how emoji usage influences developer participation and issue resolution in virtual workspaces. To this end, we collect GitHub issues for a one-year period and apply causal inference techniques to measure the causal effect of emojis on the outcome of issues, controlling for confounders such as issue content, repository, and author information. We find that emojis can significantly reduce the resolution time of issues and attract more user participation. We also compare the heterogeneous effect on different types of issues. These findings deepen our understanding of the developer communities, and they provide design implications on how to facilitate interactions and broaden developer participation.
Learning to Read Analog Gauges from Synthetic Data
Aug 28, 2023
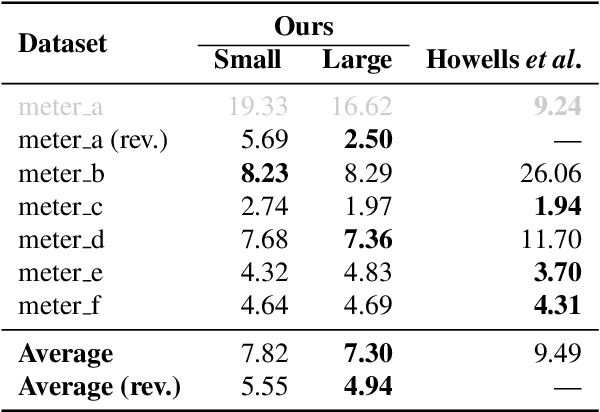

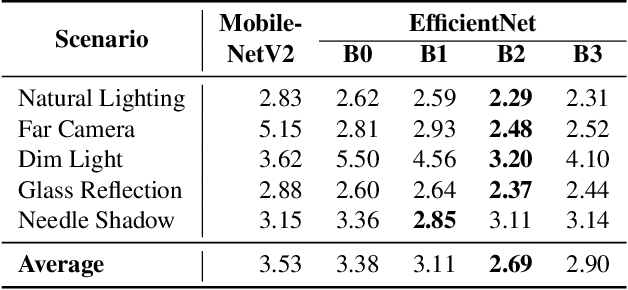
Manually reading and logging gauge data is time inefficient, and the effort increases according to the number of gauges available. We present a computer vision pipeline that automates the reading of analog gauges. We propose a two-stage CNN pipeline that identifies the key structural components of an analog gauge and outputs an angular reading. To facilitate the training of our approach, a synthetic dataset is generated thus obtaining a set of realistic analog gauges with their corresponding annotation. To validate our proposal, an additional real-world dataset was collected with 4.813 manually curated images. When compared against state-of-the-art methodologies, our method shows a significant improvement of 4.55 in the average error, which is a 52% relative improvement. The resources for this project will be made available at: https://github.com/fuankarion/automatic-gauge-reading.
On-Device Learning with Binary Neural Networks
Aug 29, 2023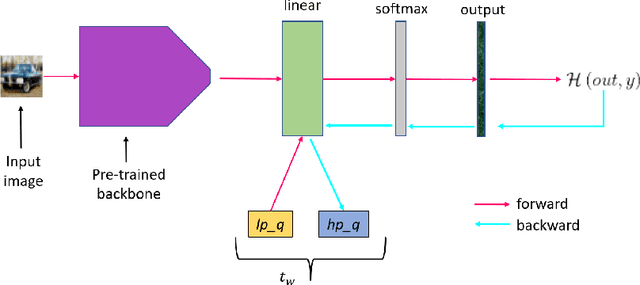

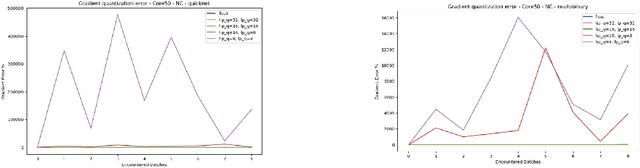
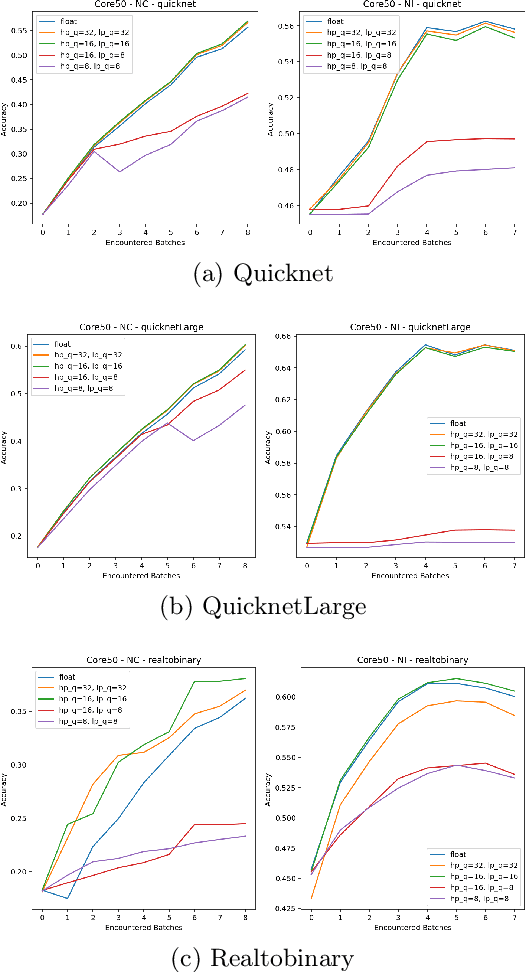
Existing Continual Learning (CL) solutions only partially address the constraints on power, memory and computation of the deep learning models when deployed on low-power embedded CPUs. In this paper, we propose a CL solution that embraces the recent advancements in CL field and the efficiency of the Binary Neural Networks (BNN), that use 1-bit for weights and activations to efficiently execute deep learning models. We propose a hybrid quantization of CWR* (an effective CL approach) that considers differently forward and backward pass in order to retain more precision during gradient update step and at the same time minimizing the latency overhead. The choice of a binary network as backbone is essential to meet the constraints of low power devices and, to the best of authors' knowledge, this is the first attempt to prove on-device learning with BNN. The experimental validation carried out confirms the validity and the suitability of the proposed method.
Recursively Summarizing Enables Long-Term Dialogue Memory in Large Language Models
Aug 29, 2023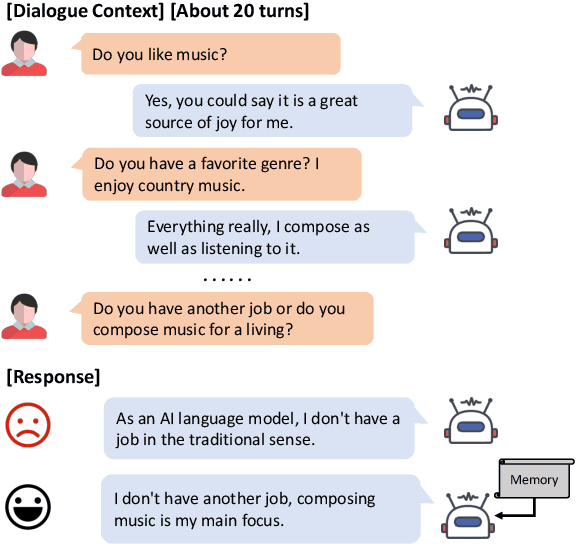

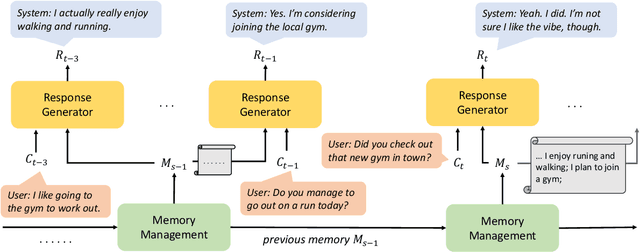
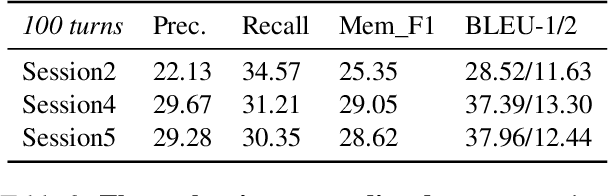
Most open-domain dialogue systems suffer from forgetting important information, especially in a long-term conversation. Existing works usually train the specific retriever or summarizer to obtain key information from the past, which is time-consuming and highly depends on the quality of labeled data. To alleviate this problem, we propose to recursively generate summaries/ memory using large language models (LLMs) to enhance long-term memory ability. Specifically, our method first stimulates LLMs to memorize small dialogue contexts and then recursively produce new memory using previous memory and following contexts. Finally, the LLM can easily generate a highly consistent response with the help of the latest memory. We evaluate our method using ChatGPT and text-davinci-003, and the experiments on the widely-used public dataset show that our method can generate more consistent responses in a long-context conversation. Notably, our method is a potential solution to enable the LLM to model the extremely long context. Code and scripts will be released later.
Learning Clothing and Pose Invariant 3D Shape Representation for Long-Term Person Re-Identification
Aug 29, 2023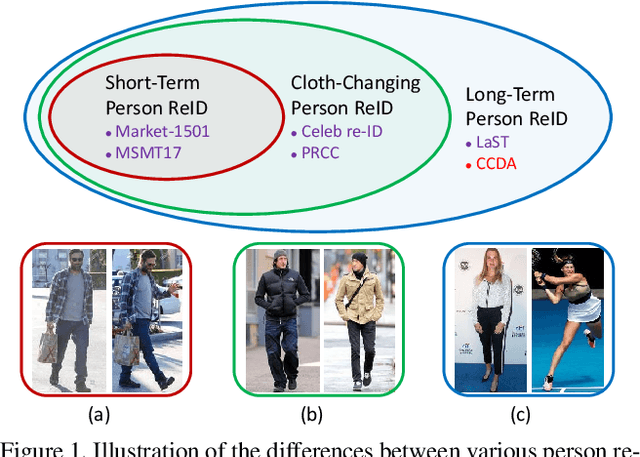


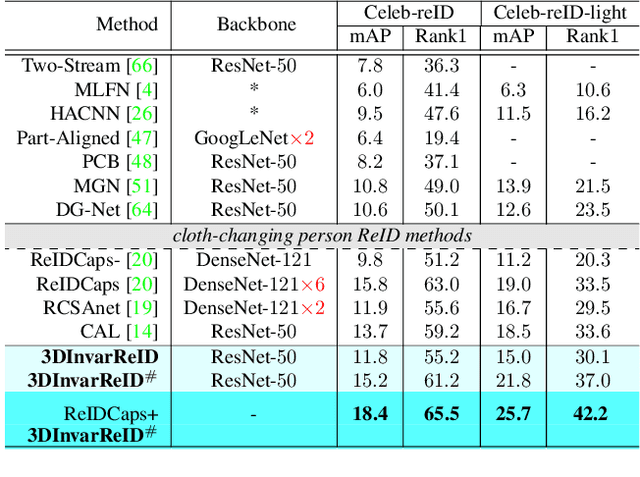
Long-Term Person Re-Identification (LT-ReID) has become increasingly crucial in computer vision and biometrics. In this work, we aim to extend LT-ReID beyond pedestrian recognition to include a wider range of real-world human activities while still accounting for cloth-changing scenarios over large time gaps. This setting poses additional challenges due to the geometric misalignment and appearance ambiguity caused by the diversity of human pose and clothing. To address these challenges, we propose a new approach 3DInvarReID for (i) disentangling identity from non-identity components (pose, clothing shape, and texture) of 3D clothed humans, and (ii) reconstructing accurate 3D clothed body shapes and learning discriminative features of naked body shapes for person ReID in a joint manner. To better evaluate our study of LT-ReID, we collect a real-world dataset called CCDA, which contains a wide variety of human activities and clothing changes. Experimentally, we show the superior performance of our approach for person ReID.