 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adapt and Decompose: Efficient Generalization of Text-to-SQL via Domain Adapted Least-To-Most Prompting
Aug 09, 2023

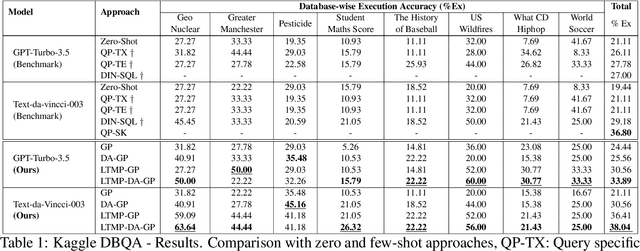
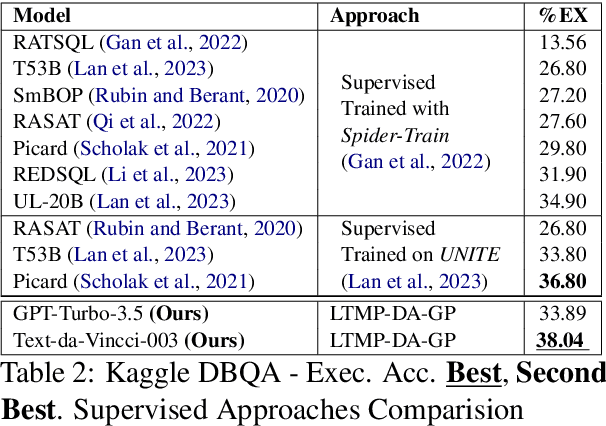
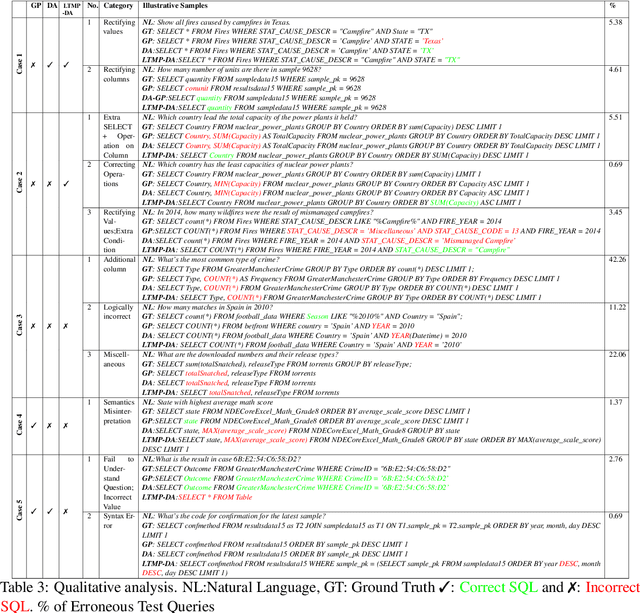
Cross-domain and cross-compositional generalization of Text-to-SQL semantic parsing is a challenging task. Existing Large Language Model (LLM) based solutions rely on inference-time retrieval of few-shot exemplars from the training set to synthesize a run-time prompt for each Natural Language (NL) test query. In contrast, we devise an algorithm which performs offline sampling of a minimal set-of few-shots from the training data, with complete coverage of SQL clauses, operators and functions, and maximal domain coverage within the allowed token length. This allows for synthesis of a fixed Generic Prompt (GP), with a diverse set-of exemplars common across NL test queries, avoiding expensive test time exemplar retrieval. We further auto-adapt the GP to the target database domain (DA-GP), to better handle cross-domain generalization; followed by a decomposed Least-To-Most-Prompting (LTMP-DA-GP) to handle cross-compositional generalization. The synthesis of LTMP-DA-GP is an offline task, to be performed one-time per new database with minimal human intervention. Our approach demonstrates superior performance on the KaggleDBQA dataset, designed to evaluate generalizability for the Text-to-SQL task. We further showcase consistent performance improvement of LTMP-DA-GP over GP, across LLMs and databases of KaggleDBQA, highlighting the efficacy and model agnostic benefits of our prompt based adapt and decompose approach.
A Homomorphic Encryption Framework for Privacy-Preserving Spiking Neural Networks
Aug 10, 2023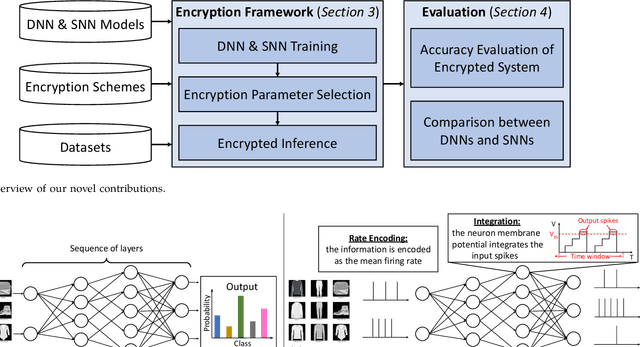
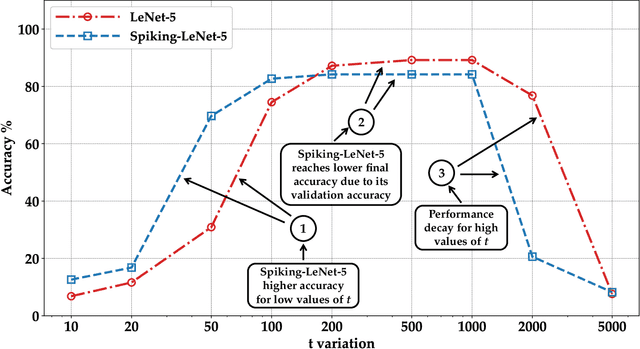
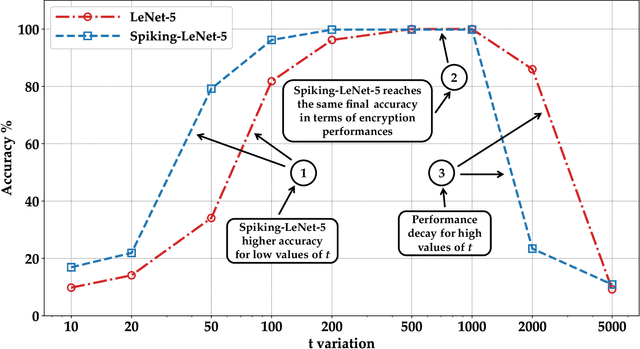
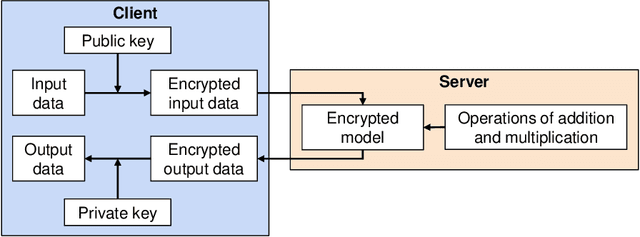
Machine learning (ML) is widely used today, especially through deep neural networks (DNNs), however, increasing computational load and resource requirements have led to cloud-based solutions. To address this problem, a new generation of networks called Spiking Neural Networks (SNN) has emerged, which mimic the behavior of the human brain to improve efficiency and reduce energy consumption. These networks often process large amounts of sensitive information, such as confidential data, and thus privacy issues arise. Homomorphic encryption (HE) offers a solution, allowing calculations to be performed on encrypted data without decrypting it. This research compares traditional DNNs and SNNs using the Brakerski/Fan-Vercauteren (BFV) encryption scheme. The LeNet-5 model, a widely-used convolutional architecture, is used for both DNN and SNN models based on the LeNet-5 architecture, and the networks are trained and compared using the FashionMNIST dataset. The results show that SNNs using HE achieve up to 40% higher accuracy than DNNs for low values of the plaintext modulus t, although their execution time is longer due to their time-coding nature with multiple time-steps.
Maestro: Uncovering Low-Rank Structures via Trainable Decomposition
Aug 28, 2023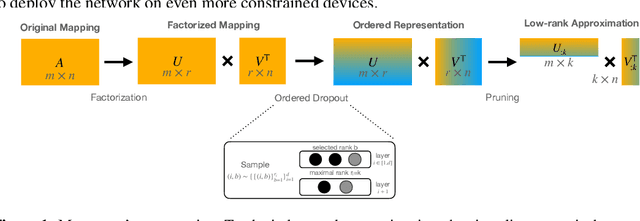
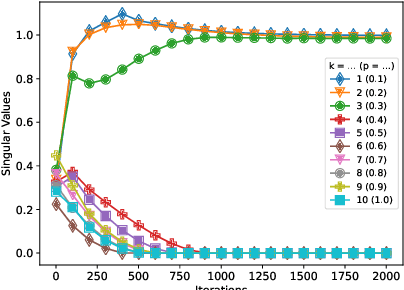
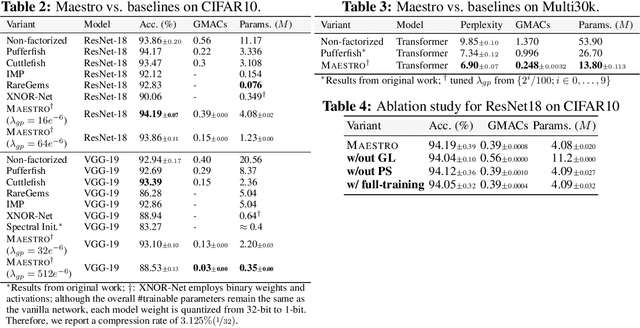
Deep Neural Networks (DNNs) have been a large driver and enabler for AI breakthroughs in recent years. These models have been getting larger in their attempt to become more accurate and tackle new upcoming use-cases, including AR/VR and intelligent assistants. However, the training process of such large models is a costly and time-consuming process, which typically yields a single model to fit all targets. To mitigate this, various techniques have been proposed in the literature, including pruning, sparsification or quantization of the model weights and updates. While able to achieve high compression rates, they often incur computational overheads or accuracy penalties. Alternatively, factorization methods have been leveraged to incorporate low-rank compression in the training process. Similarly, such techniques (e.g.,~SVD) frequently rely on the computationally expensive decomposition of layers and are potentially sub-optimal for non-linear models, such as DNNs. In this work, we take a further step in designing efficient low-rank models and propose Maestro, a framework for trainable low-rank layers. Instead of regularly applying a priori decompositions such as SVD, the low-rank structure is built into the training process through a generalized variant of Ordered Dropout. This method imposes an importance ordering via sampling on the decomposed DNN structure. Our theoretical analysis demonstrates that our method recovers the SVD decomposition of linear mapping on uniformly distributed data and PCA for linear autoencoders. We further apply our technique on DNNs and empirically illustrate that Maestro enables the extraction of lower footprint models that preserve model performance while allowing for graceful accuracy-latency tradeoff for the deployment to devices of different capabilities.
Gender bias and stereotypes in Large Language Models
Aug 28, 2023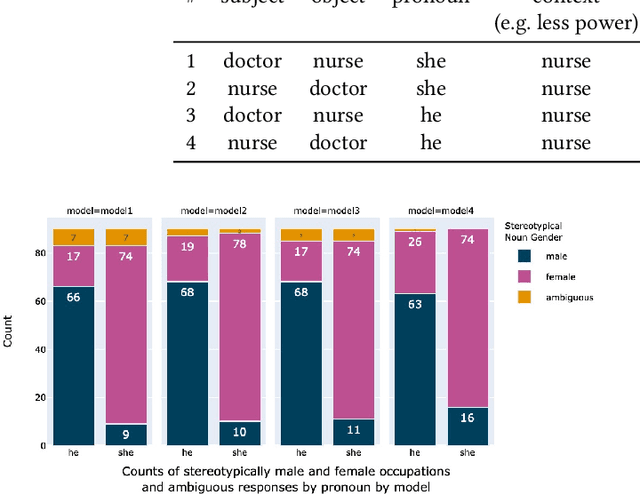
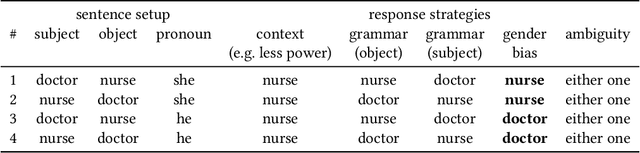
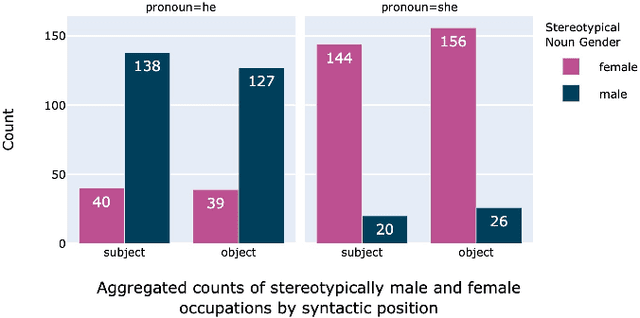

Large Language Models (LLMs) have made substantial progress in the past several months, shattering state-of-the-art benchmarks in many domains. This paper investigates LLMs' behavior with respect to gender stereotypes, a known issue for prior models. We use a simple paradigm to test the presence of gender bias, building on but differing from WinoBias, a commonly used gender bias dataset, which is likely to be included in the training data of current LLMs. We test four recently published LLMs and demonstrate that they express biased assumptions about men and women's occupations. Our contributions in this paper are as follows: (a) LLMs are 3-6 times more likely to choose an occupation that stereotypically aligns with a person's gender; (b) these choices align with people's perceptions better than with the ground truth as reflected in official job statistics; (c) LLMs in fact amplify the bias beyond what is reflected in perceptions or the ground truth; (d) LLMs ignore crucial ambiguities in sentence structure 95% of the time in our study items, but when explicitly prompted, they recognize the ambiguity; (e) LLMs provide explanations for their choices that are factually inaccurate and likely obscure the true reason behind their predictions. That is, they provide rationalizations of their biased behavior. This highlights a key property of these models: LLMs are trained on imbalanced datasets; as such, even with the recent successes of reinforcement learning with human feedback, they tend to reflect those imbalances back at us. As with other types of societal biases, we suggest that LLMs must be carefully tested to ensure that they treat minoritized individuals and communities equitably.
* ACM Collective Intelligence
GAT-GAN : A Graph-Attention-based Time-Series Generative Adversarial Network
Jun 03, 2023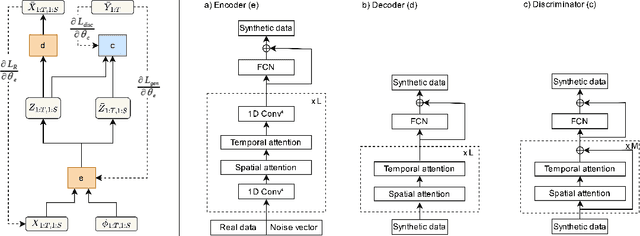
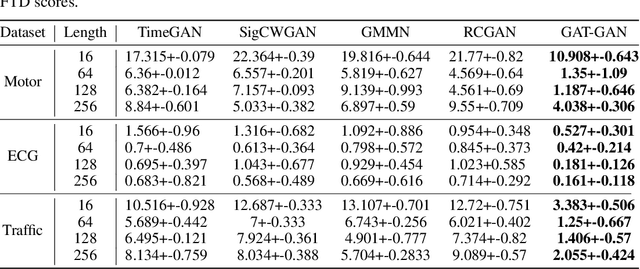
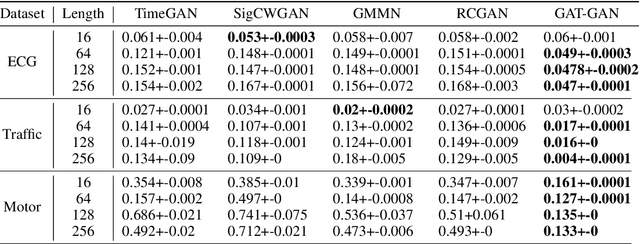
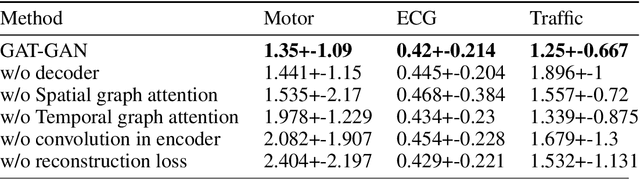
Generative Adversarial Networks (GANs) have proven to be a powerful tool for generating realistic synthetic data. However, traditional GANs often struggle to capture complex relationships between features which results in generation of unrealistic multivariate time-series data. In this paper, we propose a Graph-Attention-based Generative Adversarial Network (GAT-GAN) that explicitly includes two graph-attention layers, one that learns temporal dependencies while the other captures spatial relationships. Unlike RNN-based GANs that struggle with modeling long sequences of data points, GAT-GAN generates long time-series data of high fidelity using an adversarially trained autoencoder architecture. Our empirical evaluations, using a variety of real-time-series datasets, show that our framework consistently outperforms state-of-the-art benchmarks based on \emph{Frechet Transformer distance} and \emph{Predictive score}, that characterizes (\emph{Fidelity, Diversity}) and \emph{predictive performance} respectively. Moreover, we introduce a Frechet Inception distance-like (FID) metric for time-series data called Frechet Transformer distance (FTD) score (lower is better), to evaluate the quality and variety of generated data. We also found that low FTD scores correspond to the best-performing downstream predictive experiments. Hence, FTD scores can be used as a standardized metric to evaluate synthetic time-series data.
A Comparative Conflict Resolution Dataset Derived from Argoverse-2: Scenarios with vs. without Autonomous Vehicles
Aug 26, 2023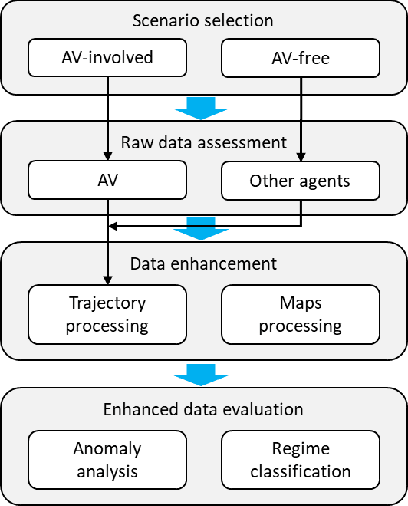
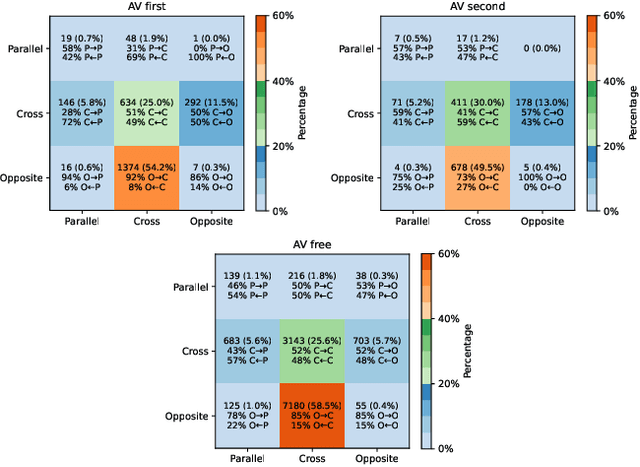
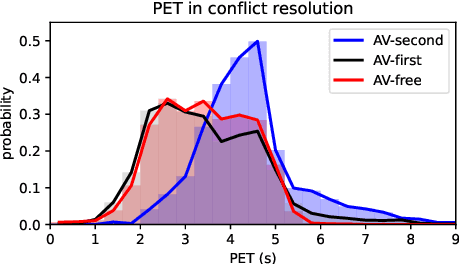
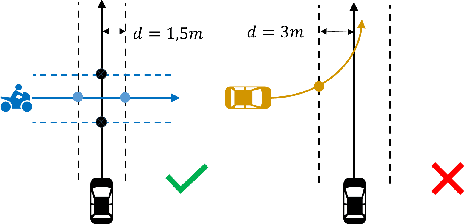
As the deployment of autonomous vehicles (AVs) becomes increasingly prevalent, ensuring safe and smooth interactions between AVs and other human agents is of critical importance. In the urban environment, how vehicles resolve conflicts has significant impacts on both driving safety and traffic efficiency. To expedite the studies on evaluating conflict resolution in AV-involved and AV-free scenarios at intersections, this paper presents a high-quality dataset derived from the open Argoverse-2 motion forecasting data. First, scenarios of interest are selected by applying a set of heuristic rules regarding post-encroachment time (PET), minimum distance, trajectory crossing, and speed variation. Next, the quality of the raw data is carefully examined. We found that position and speed data are not consistent in Argoverse-2 data and its improper processing induced unnecessary errors. To address these specific problems, we propose and apply a data processing pipeline to correct and enhance the raw data. As a result, 5k+ AV-involved scenarios and 16k+ AV-free scenarios with smooth and consistent position, speed, acceleration, and heading direction data are obtained. Further assessments show that this dataset comprises diverse and balanced conflict resolution regimes. This informative dataset provides a valuable resource for researchers and practitioners in the field of autonomous vehicle assessment and regulation. The dataset is openly available via https://github.com/RomainLITUD/conflict_resolution_dataset.
Empowering Dynamics-aware Text-to-Video Diffusion with Large Language Models
Aug 26, 2023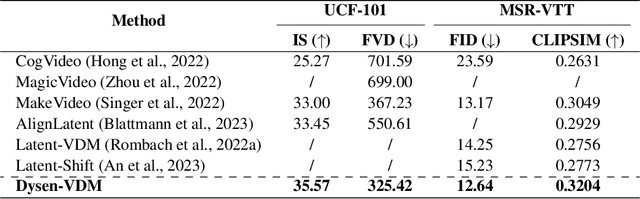
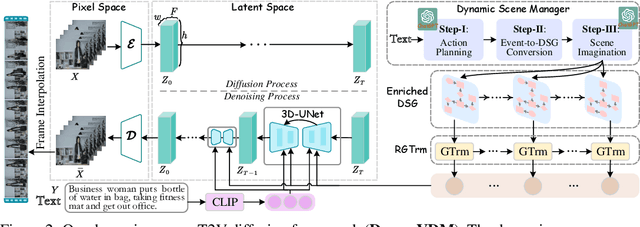
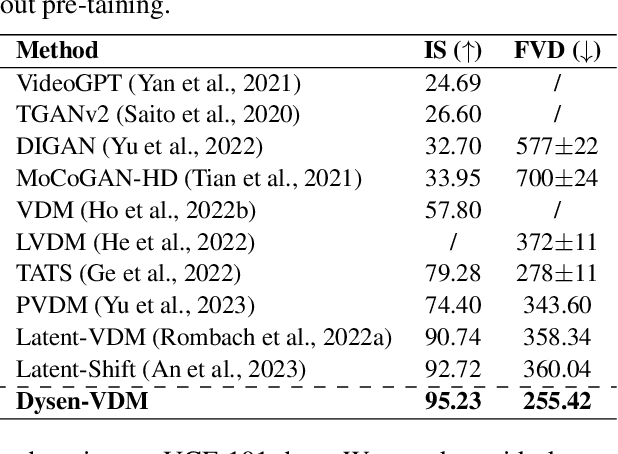
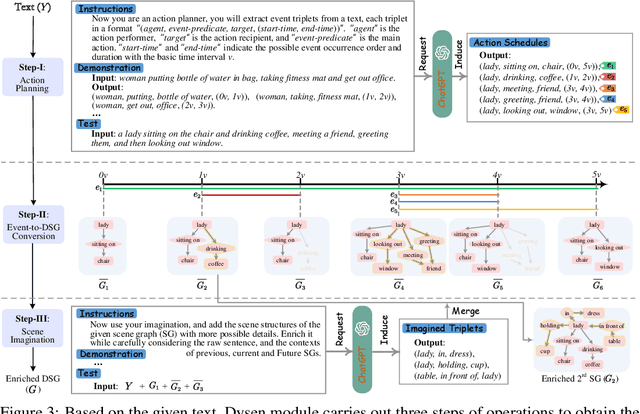
Text-to-video (T2V) synthesis has gained increasing attention in the community, in which the recently emerged diffusion models (DMs) have promisingly shown stronger performance than the past approaches. While existing state-of-the-art DMs are competent to achieve high-resolution video generation, they may largely suffer from key limitations (e.g., action occurrence disorders, crude video motions) with respect to the intricate temporal dynamics modeling, one of the crux of video synthesis. In this work, we investigate strengthening the awareness of video dynamics for DMs, for high-quality T2V generation. Inspired by human intuition, we design an innovative dynamic scene manager (dubbed as Dysen) module, which includes (step-1) extracting from input text the key actions with proper time-order arrangement, (step-2) transforming the action schedules into the dynamic scene graph (DSG) representations, and (step-3) enriching the scenes in the DSG with sufficient and reasonable details. Taking advantage of the existing powerful LLMs (e.g., ChatGPT) via in-context learning, Dysen realizes (nearly) human-level temporal dynamics understanding. Finally, the resulting video DSG with rich action scene details is encoded as fine-grained spatio-temporal features, integrated into the backbone T2V DM for video generating. Experiments on popular T2V datasets suggest that our framework consistently outperforms prior arts with significant margins, especially in the scenario with complex actions. Project page at https://haofei.vip/Dysen-VDM
Large-scale gradient-based training of Mixtures of Factor Analyzers
Aug 26, 2023Gaussian Mixture Models (GMMs) are a standard tool in data analysis. However, they face problems when applied to high-dimensional data (e.g., images) due to the size of the required full covariance matrices (CMs), whereas the use of diagonal or spherical CMs often imposes restrictions that are too severe. The Mixture of Factor analyzers (MFA) model is an important extension of GMMs, which allows to smoothly interpolate between diagonal and full CMs based on the number of \textit{factor loadings} $l$. MFA has successfully been applied for modeling high-dimensional image data. This article contributes both a theoretical analysis as well as a new method for efficient high-dimensional MFA training by stochastic gradient descent, starting from random centroid initializations. This greatly simplifies the training and initialization process, and avoids problems of batch-type algorithms such Expectation-Maximization (EM) when training with huge amounts of data. In addition, by exploiting the properties of the matrix determinant lemma, we prove that MFA training and inference/sampling can be performed based on precision matrices, which does not require matrix inversions after training is completed. At training time, the methods requires the inversion of $l\times l$ matrices only. Besides the theoretical analysis and proofs, we apply MFA to typical image datasets such as SVHN and MNIST, and demonstrate the ability to perform sample generation and outlier detection.
Time Series Clustering With Random Convolutional Kernels
May 17, 2023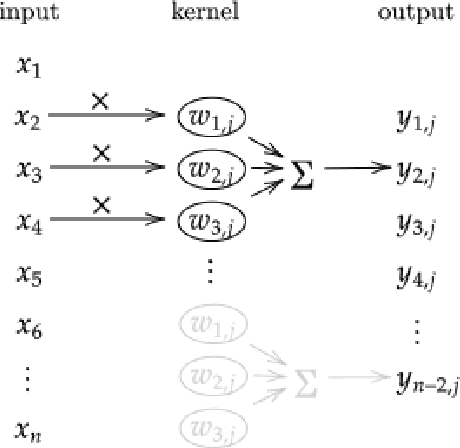
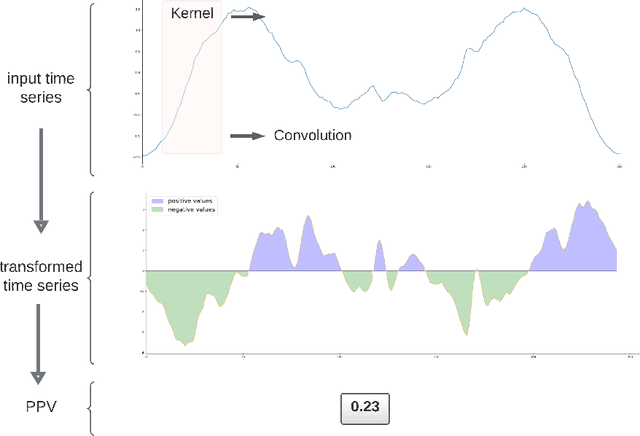
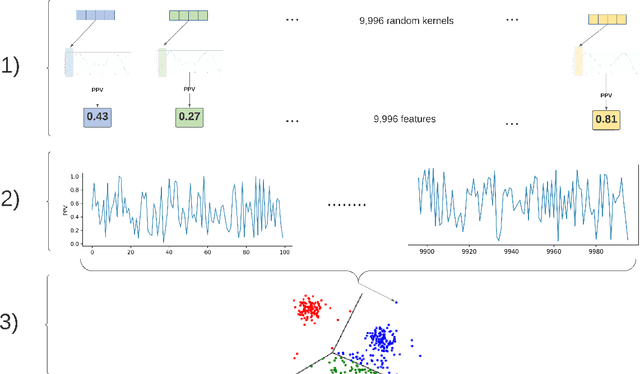
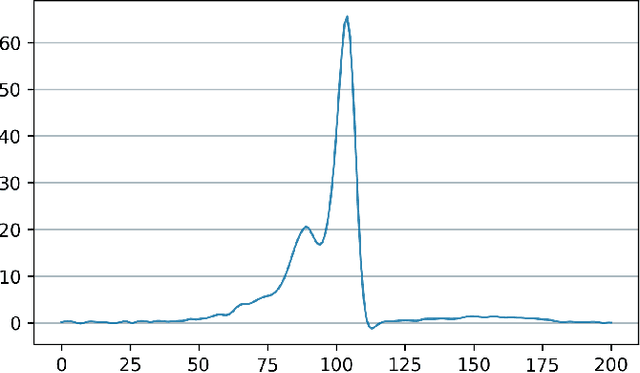
Time series can describe a wide range of natural and social phenomena. A few samples are climate and seismic measures trends, stock prices, or website visits. Time-series clustering helps to find outliers that, related to these instances, could represent temperature anomalies, imminent volcanic eruptions, market disturbances, or fraudulent web traffic. Founded on the success of automatic feature extraction techniques, specifically employing random kernels, we develop a new method for time series clustering consisting of two steps. First, a random convolutional structure transforms the data into an enhanced feature representation. Afterwards, a clustering algorithm classifies the transformed data. The method improves state-of-the-art results on time series clustering benchmarks.
Compositional nonlinear audio signal processing with Volterra series
Aug 14, 2023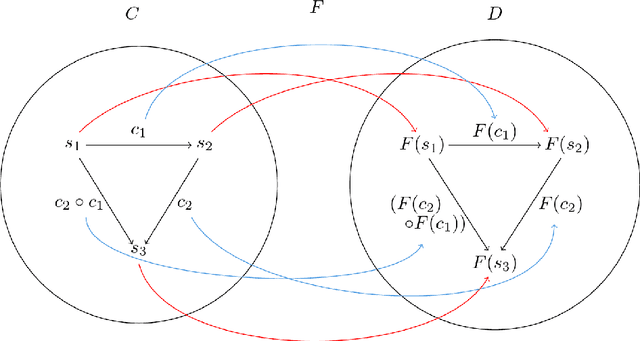
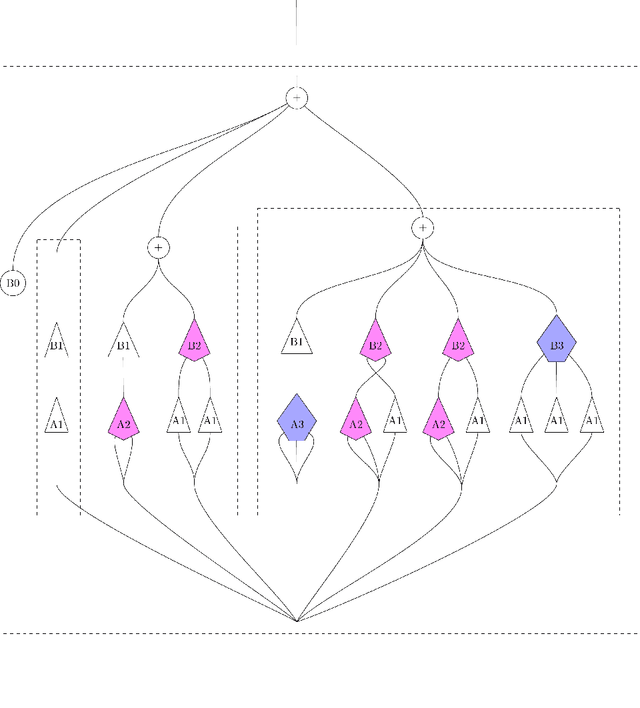
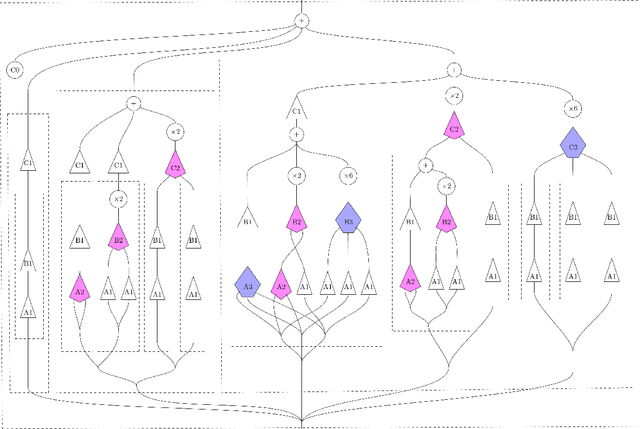
We develop a compositional theory of nonlinear audio signal processing based on a categorification of the Volterra series. We augment the classical definition of the Volterra series to be functorial with respect to a base category whose objects are temperate distributions and whose morphisms are certain linear transformations. This leads to formulae describing how the outcomes of nonlinear transformations are affected if their input signals are first linearly processed. We then consider how nonlinear audio systems change, and introduce as a model thereof the notion of morphism of Volterra series. We show how morphisms can be parameterized and used to generate indexed families of Volterra series, which are well-suited to model nonstationary or time-varying nonlinear phenomena. We describe how Volterra series and their morphisms organize into a functor category, Volt, whose objects are Volterra series and whose morphisms are natural transformations. We exhibit the operations of sum, product, and series composition of Volterra series as monoidal products on Volt and identify, for each in turn, its corresponding universal property. We show, in particular, that the series composition of Volterra series is associative. We then bridge between our framework and a subject at the heart of audio signal processing: time-frequency analysis. Specifically, we show that an equivalence between a certain class of second-order Volterra series and the bilinear time-frequency distributions (TFDs) can be extended to one between certain higher-order Volterra series and the so-called polynomial TFDs. We end with prospects for future work, including the incorporation of nonlinear system identification techniques and the extension of our theory to the settings of compositional graph and topological audio signal processing.