 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SHIELD: Sustainable Hybrid Evolutionary Learning Framework for Carbon, Wastewater, and Energy-Aware Data Center Management
Aug 24, 2023
Today's cloud data centers are often distributed geographically to provide robust data services. But these geo-distributed data centers (GDDCs) have a significant associated environmental impact due to their increasing carbon emissions and water usage, which needs to be curtailed. Moreover, the energy costs of operating these data centers continue to rise. This paper proposes a novel framework to co-optimize carbon emissions, water footprint, and energy costs of GDDCs, using a hybrid workload management framework called SHIELD that integrates machine learning guided local search with a decomposition-based evolutionary algorithm. Our framework considers geographical factors and time-based differences in power generation/use, costs, and environmental impacts to intelligently manage workload distribution across GDDCs and data center operation. Experimental results show that SHIELD can realize 34.4x speedup and 2.1x improvement in Pareto Hypervolume while reducing the carbon footprint by up to 3.7x, water footprint by up to 1.8x, energy costs by up to 1.3x, and a cumulative improvement across all objectives (carbon, water, cost) of up to 4.8x compared to the state-of-the-art.
MIPS-Fusion: Multi-Implicit-Submaps for Scalable and Robust Online Neural RGB-D Reconstruction
Aug 24, 2023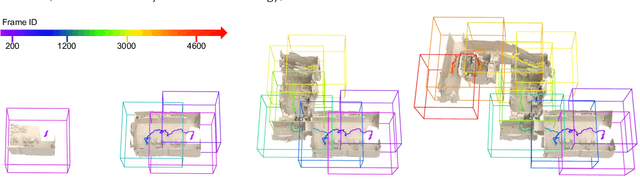
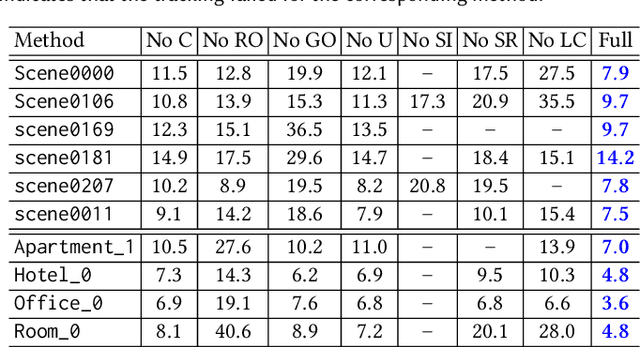
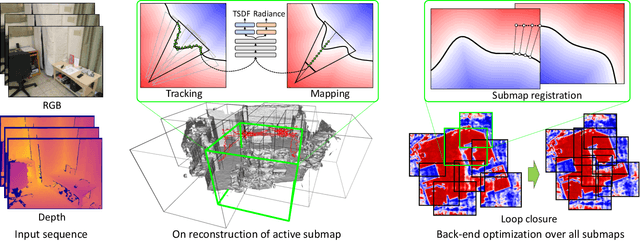
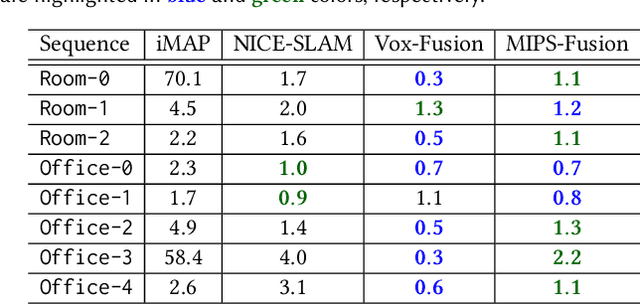
We introduce MIPS-Fusion, a robust and scalable online RGB-D reconstruction method based on a novel neural implicit representation -- multi-implicit-submap. Different from existing neural RGB-D reconstruction methods lacking either flexibility with a single neural map or scalability due to extra storage of feature grids, we propose a pure neural representation tackling both difficulties with a divide-and-conquer design. In our method, neural submaps are incrementally allocated alongside the scanning trajectory and efficiently learned with local neural bundle adjustments. The submaps can be refined individually in a back-end optimization and optimized jointly to realize submap-level loop closure. Meanwhile, we propose a hybrid tracking approach combining randomized and gradient-based pose optimizations. For the first time, randomized optimization is made possible in neural tracking with several key designs to the learning process, enabling efficient and robust tracking even under fast camera motions. The extensive evaluation demonstrates that our method attains higher reconstruction quality than the state of the arts for large-scale scenes and under fast camera motions.
Solving Forward and Inverse Problems of Contact Mechanics using Physics-Informed Neural Networks
Aug 24, 2023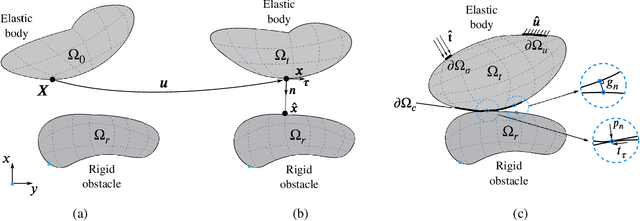

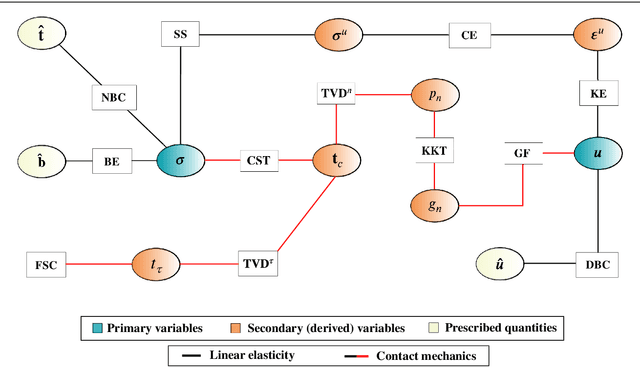

This paper explores the ability of physics-informed neural networks (PINNs) to solve forward and inverse problems of contact mechanics for small deformation elasticity. We deploy PINNs in a mixed-variable formulation enhanced by output transformation to enforce Dirichlet and Neumann boundary conditions as hard constraints. Inequality constraints of contact problems, namely Karush-Kuhn-Tucker (KKT) type conditions, are enforced as soft constraints by incorporating them into the loss function during network training. To formulate the loss function contribution of KKT constraints, existing approaches applied to elastoplasticity problems are investigated and we explore a nonlinear complementarity problem (NCP) function, namely Fischer-Burmeister, which possesses advantageous characteristics in terms of optimization. Based on the Hertzian contact problem, we show that PINNs can serve as pure partial differential equation (PDE) solver, as data-enhanced forward model, as inverse solver for parameter identification, and as fast-to-evaluate surrogate model. Furthermore, we demonstrate the importance of choosing proper hyperparameters, e.g. loss weights, and a combination of Adam and L-BFGS-B optimizers aiming for better results in terms of accuracy and training time.
3ET: Efficient Event-based Eye Tracking using a Change-Based ConvLSTM Network
Aug 22, 2023This paper presents a sparse Change-Based Convolutional Long Short-Term Memory (CB-ConvLSTM) model for event-based eye tracking, key for next-generation wearable healthcare technology such as AR/VR headsets. We leverage the benefits of retina-inspired event cameras, namely their low-latency response and sparse output event stream, over traditional frame-based cameras. Our CB-ConvLSTM architecture efficiently extracts spatio-temporal features for pupil tracking from the event stream, outperforming conventional CNN structures. Utilizing a delta-encoded recurrent path enhancing activation sparsity, CB-ConvLSTM reduces arithmetic operations by approximately 4.7$\times$ without losing accuracy when tested on a \texttt{v2e}-generated event dataset of labeled pupils. This increase in efficiency makes it ideal for real-time eye tracking in resource-constrained devices. The project code and dataset are openly available at \url{https://github.com/qinche106/cb-convlstm-eyetracking}.
Open-set Face Recognition with Neural Ensemble, Maximal Entropy Loss and Feature Augmentation
Aug 23, 2023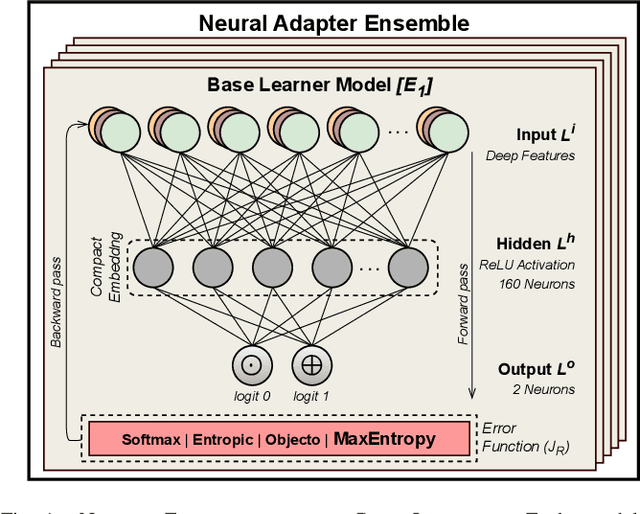
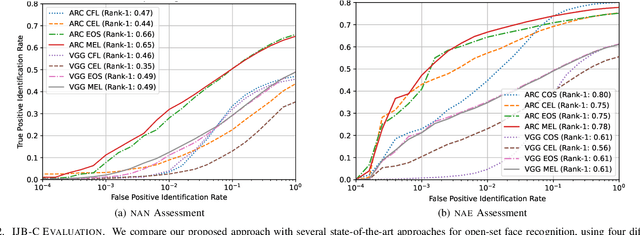

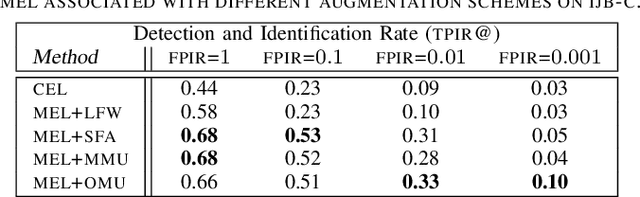
Open-set face recognition refers to a scenario in which biometric systems have incomplete knowledge of all existing subjects. Therefore, they are expected to prevent face samples of unregistered subjects from being identified as previously enrolled identities. This watchlist context adds an arduous requirement that calls for the dismissal of irrelevant faces by focusing mainly on subjects of interest. As a response, this work introduces a novel method that associates an ensemble of compact neural networks with a margin-based cost function that explores additional samples. Supplementary negative samples can be obtained from external databases or synthetically built at the representation level in training time with a new mix-up feature augmentation approach. Deep neural networks pre-trained on large face datasets serve as the preliminary feature extraction module. We carry out experiments on well-known LFW and IJB-C datasets where results show that the approach is able to boost closed and open-set identification rates.
An Initial Exploration: Learning to Generate Realistic Audio for Silent Video
Aug 23, 2023Generating realistic audio effects for movies and other media is a challenging task that is accomplished today primarily through physical techniques known as Foley art. Foley artists create sounds with common objects (e.g., boxing gloves, broken glass) in time with video as it is playing to generate captivating audio tracks. In this work, we aim to develop a deep-learning based framework that does much the same - observes video in it's natural sequence and generates realistic audio to accompany it. Notably, we have reason to believe this is achievable due to advancements in realistic audio generation techniques conditioned on other inputs (e.g., Wavenet conditioned on text). We explore several different model architectures to accomplish this task that process both previously-generated audio and video context. These include deep-fusion CNN, dilated Wavenet CNN with visual context, and transformer-based architectures. We find that the transformer-based architecture yields the most promising results, matching low-frequencies to visual patterns effectively, but failing to generate more nuanced waveforms.
Lite-HRNet Plus: Fast and Accurate Facial Landmark Detection
Aug 23, 2023
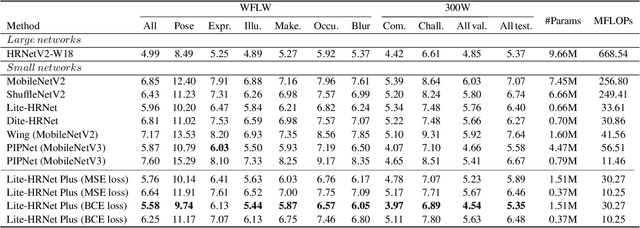
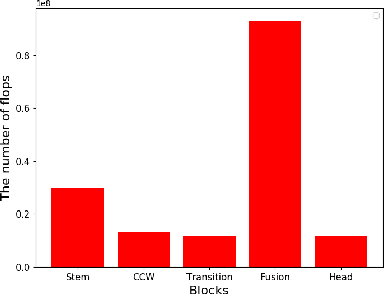
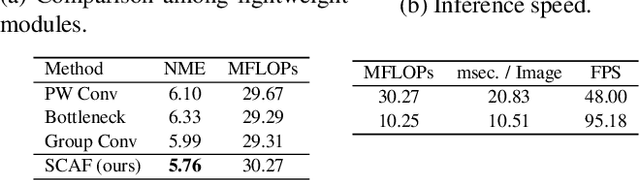
Facial landmark detection is an essential technology for driver status tracking and has been in demand for real-time estimations. As a landmark coordinate prediction, heatmap-based methods are known to achieve a high accuracy, and Lite-HRNet can achieve a fast estimation. However, with Lite-HRNet, the problem of a heavy computational cost of the fusion block, which connects feature maps with different resolutions, has yet to be solved. In addition, the strong output module used in HRNetV2 is not applied to Lite-HRNet. Given these problems, we propose a novel architecture called Lite-HRNet Plus. Lite-HRNet Plus achieves two improvements: a novel fusion block based on a channel attention and a novel output module with less computational intensity using multi-resolution feature maps. Through experiments conducted on two facial landmark datasets, we confirmed that Lite-HRNet Plus further improved the accuracy in comparison with conventional methods, and achieved a state-of-the-art accuracy with a computational complexity with the range of 10M FLOPs.
Less is More -- Towards parsimonious multi-task models using structured sparsity
Aug 23, 2023
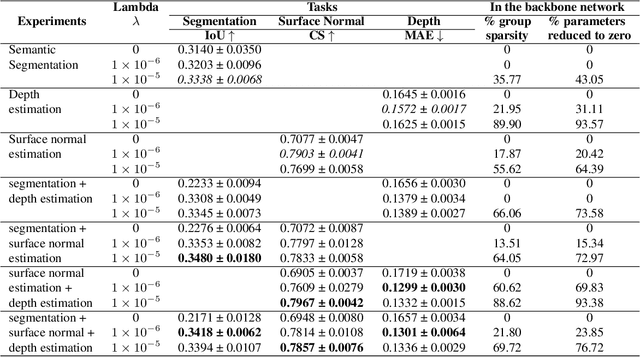
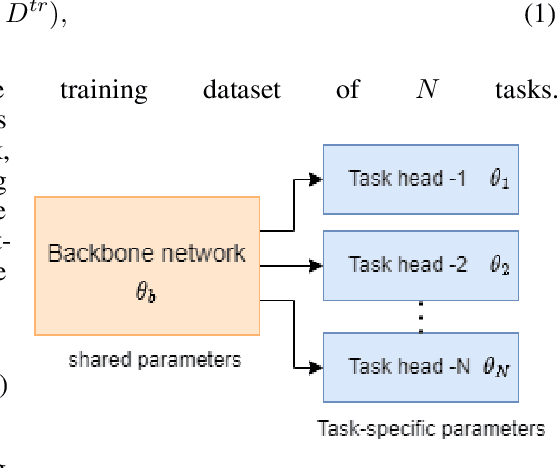

Group sparsity in Machine Learning (ML) encourages simpler, more interpretable models with fewer active parameter groups. This work aims to incorporate structured group sparsity into the shared parameters of a Multi-Task Learning (MTL) framework, to develop parsimonious models that can effectively address multiple tasks with fewer parameters while maintaining comparable or superior performance to a dense model. Sparsifying the model during training helps decrease the model's memory footprint, computation requirements, and prediction time during inference. We use channel-wise l1/l2 group sparsity in the shared layers of the Convolutional Neural Network (CNN). This approach not only facilitates the elimination of extraneous groups (channels) but also imposes a penalty on the weights, thereby enhancing the learning of all tasks. We compare the outcomes of single-task and multi-task experiments under group sparsity on two publicly available MTL datasets, NYU-v2 and CelebAMask-HQ. We also investigate how changing the sparsification degree impacts both the performance of the model and the sparsity of groups.
Machine learning in parameter estimation of nonlinear systems
Aug 23, 2023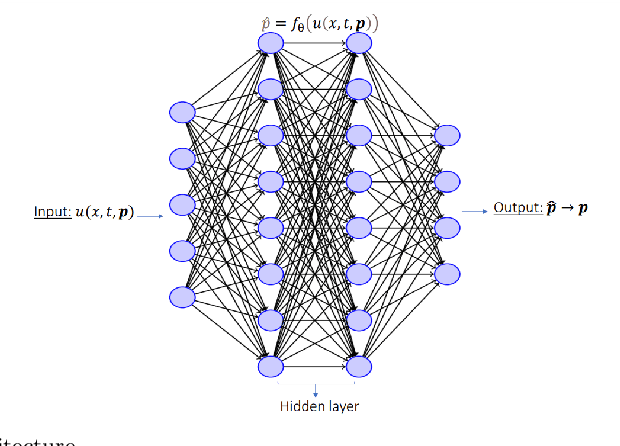
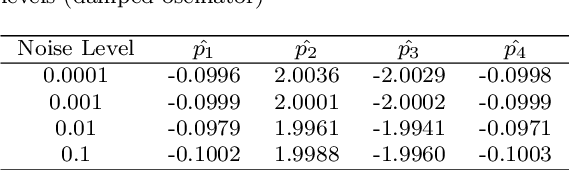
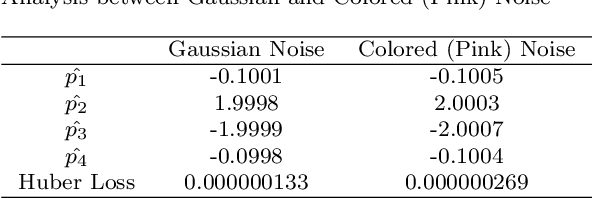
Accurately estimating parameters in complex nonlinear systems is crucial across scientific and engineering fields. We present a novel approach for parameter estimation using a neural network with the Huber loss function. This method taps into deep learning's abilities to uncover parameters governing intricate behaviors in nonlinear equations. We validate our approach using synthetic data and predefined functions that model system dynamics. By training the neural network with noisy time series data, it fine-tunes the Huber loss function to converge to accurate parameters. We apply our method to damped oscillators, Van der Pol oscillators, Lotka-Volterra systems, and Lorenz systems under multiplicative noise. The trained neural network accurately estimates parameters, evident from closely matching latent dynamics. Comparing true and estimated trajectories visually reinforces our method's precision and robustness. Our study underscores the Huber loss-guided neural network as a versatile tool for parameter estimation, effectively uncovering complex relationships in nonlinear systems. The method navigates noise and uncertainty adeptly, showcasing its adaptability to real-world challenges.
Data-driven decision-focused surrogate modeling
Aug 23, 2023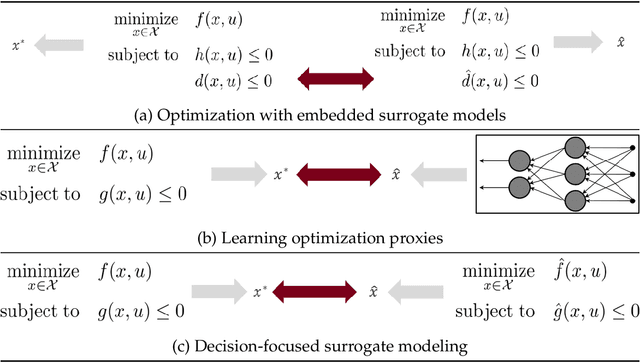
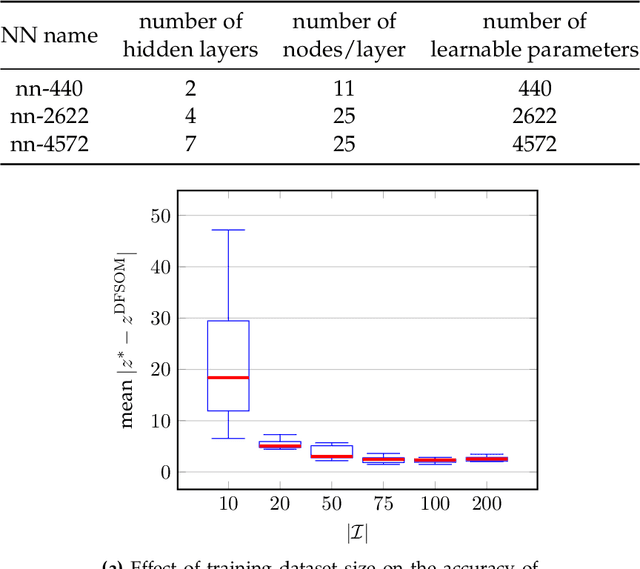
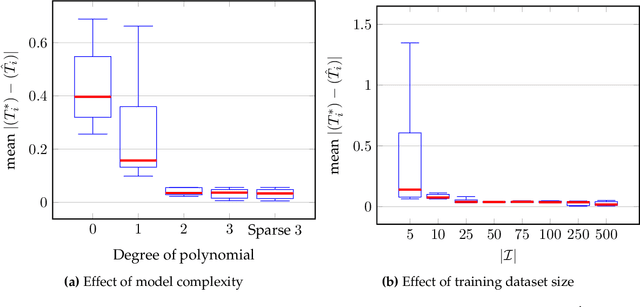
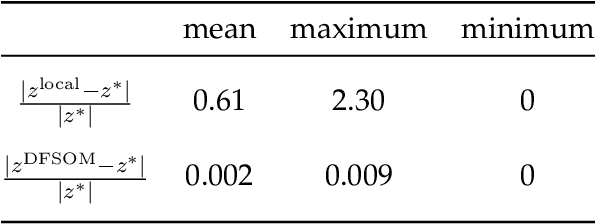
We introduce the concept of decision-focused surrogate modeling for solving computationally challenging nonlinear optimization problems in real-time settings. The proposed data-driven framework seeks to learn a simpler, e.g. convex, surrogate optimization model that is trained to minimize the decision prediction error, which is defined as the difference between the optimal solutions of the original and the surrogate optimization models. The learning problem, formulated as a bilevel program, can be viewed as a data-driven inverse optimization problem to which we apply a decomposition-based solution algorithm from previous work. We validate our framework through numerical experiments involving the optimization of common nonlinear chemical processes such as chemical reactors, heat exchanger networks, and material blending systems. We also present a detailed comparison of decision-focused surrogate modeling with standard data-driven surrogate modeling methods and demonstrate that our approach is significantly more data-efficient while producing simple surrogate models with high decision prediction accuracy.