 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Forensic Histopathological Recognition via a Context-Aware MIL Network Powered by Self-Supervised Contrastive Learning
Aug 27, 2023
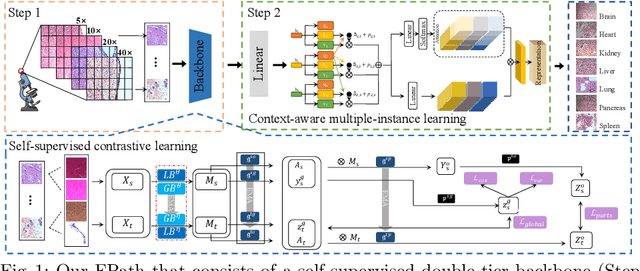
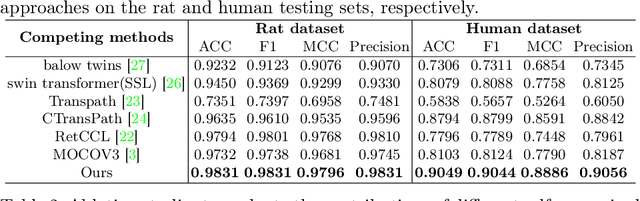
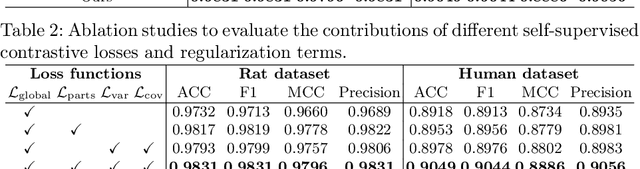
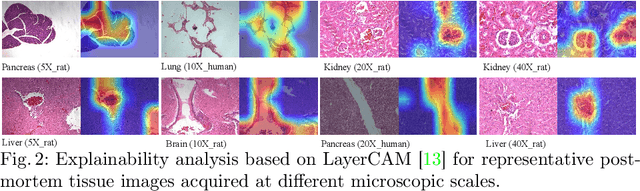
Forensic pathology is critical in analyzing death manner and time from the microscopic aspect to assist in the establishment of reliable factual bases for criminal investigation. In practice, even the manual differentiation between different postmortem organ tissues is challenging and relies on expertise, considering that changes like putrefaction and autolysis could significantly change typical histopathological appearance. Developing AI-based computational pathology techniques to assist forensic pathologists is practically meaningful, which requires reliable discriminative representation learning to capture tissues' fine-grained postmortem patterns. To this end, we propose a framework called FPath, in which a dedicated self-supervised contrastive learning strategy and a context-aware multiple-instance learning (MIL) block are designed to learn discriminative representations from postmortem histopathological images acquired at varying magnification scales. Our self-supervised learning step leverages multiple complementary contrastive losses and regularization terms to train a double-tier backbone for fine-grained and informative patch/instance embedding. Thereafter, the context-aware MIL adaptively distills from the local instances a holistic bag/image-level representation for the recognition task. On a large-scale database of $19,607$ experimental rat postmortem images and $3,378$ real-world human decedent images, our FPath led to state-of-the-art accuracy and promising cross-domain generalization in recognizing seven different postmortem tissues. The source code will be released on \href{https://github.com/ladderlab-xjtu/forensic_pathology}{https://github.com/ladderlab-xjtu/forensic\_pathology}.
GAT-GAN : A Graph-Attention-based Time-Series Generative Adversarial Network
Jun 03, 2023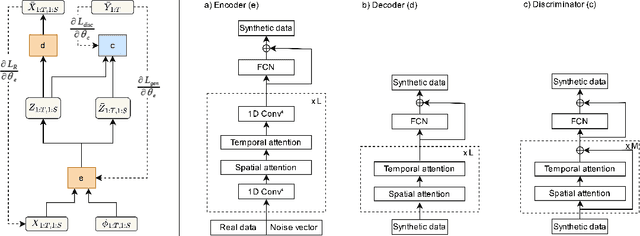
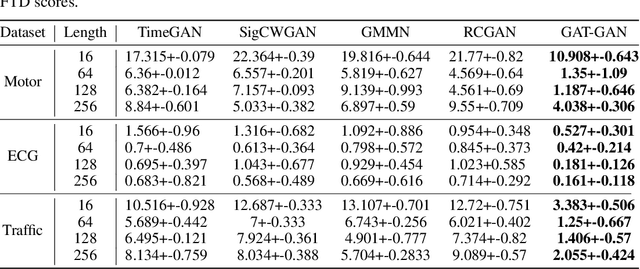
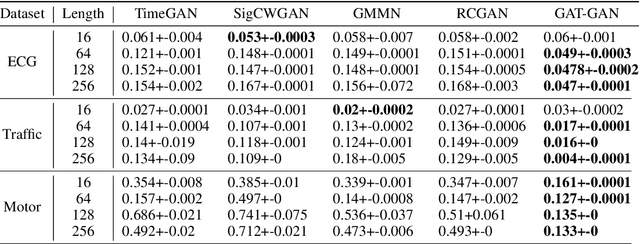
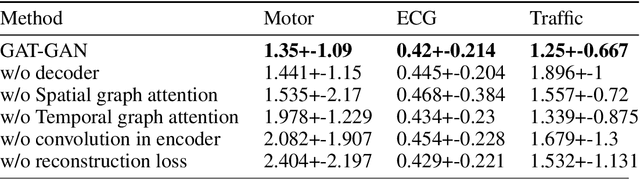
Generative Adversarial Networks (GANs) have proven to be a powerful tool for generating realistic synthetic data. However, traditional GANs often struggle to capture complex relationships between features which results in generation of unrealistic multivariate time-series data. In this paper, we propose a Graph-Attention-based Generative Adversarial Network (GAT-GAN) that explicitly includes two graph-attention layers, one that learns temporal dependencies while the other captures spatial relationships. Unlike RNN-based GANs that struggle with modeling long sequences of data points, GAT-GAN generates long time-series data of high fidelity using an adversarially trained autoencoder architecture. Our empirical evaluations, using a variety of real-time-series datasets, show that our framework consistently outperforms state-of-the-art benchmarks based on \emph{Frechet Transformer distance} and \emph{Predictive score}, that characterizes (\emph{Fidelity, Diversity}) and \emph{predictive performance} respectively. Moreover, we introduce a Frechet Inception distance-like (FID) metric for time-series data called Frechet Transformer distance (FTD) score (lower is better), to evaluate the quality and variety of generated data. We also found that low FTD scores correspond to the best-performing downstream predictive experiments. Hence, FTD scores can be used as a standardized metric to evaluate synthetic time-series data.
Deep learning-based flow disaggregation for hydropower plant management
Aug 11, 2023High temporal resolution data is a vital resource for hydropower plant management. Currently, only daily resolution data are available for most of Norwegian hydropower plant, however, to achieve more accurate management, sub-daily resolution data are often required. To deal with the wide absence of sub-daily data, time series disaggregation is a potential tool. In this study, we proposed a time series disaggregation model based on deep learning, the model is tested using flow data from a Norwegian flow station, to disaggregate the daily flow into hourly flow. Preliminary results show some promising aspects for the proposed model.
Spatio-Temporal Adaptive Embedding Makes Vanilla Transformer SOTA for Traffic Forecasting
Aug 22, 2023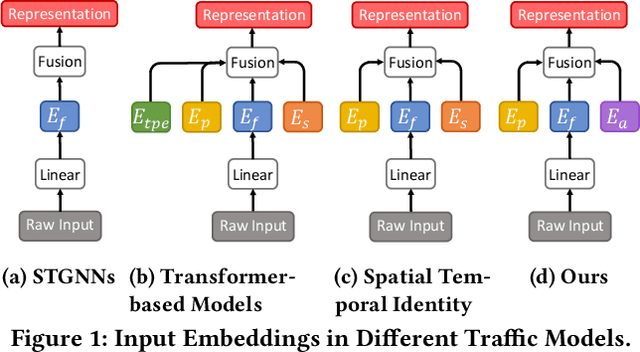
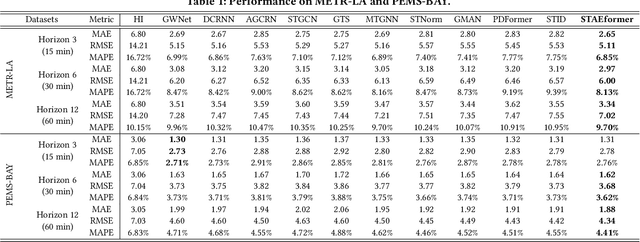
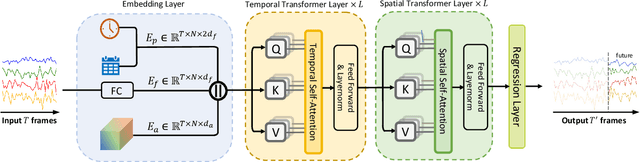
With the rapid development of the Intelligent Transportation System (ITS), accurate traffic forecasting has emerged as a critical challenge. The key bottleneck lies in capturing the intricate spatio-temporal traffic patterns. In recent years, numerous neural networks with complicated architectures have been proposed to address this issue. However, the advancements in network architectures have encountered diminishing performance gains. In this study, we present a novel component called spatio-temporal adaptive embedding that can yield outstanding results with vanilla transformers. Our proposed Spatio-Temporal Adaptive Embedding transformer (STAEformer) achieves state-of-the-art performance on five real-world traffic forecasting datasets. Further experiments demonstrate that spatio-temporal adaptive embedding plays a crucial role in traffic forecasting by effectively capturing intrinsic spatio-temporal relations and chronological information in traffic time series.
MatFuse: Controllable Material Generation with Diffusion Models
Aug 22, 2023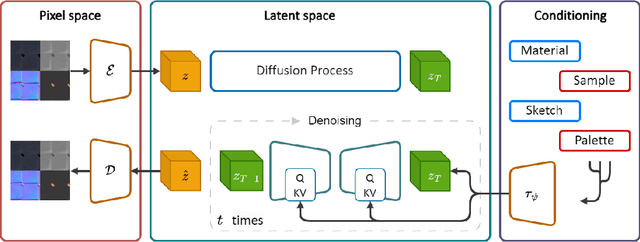
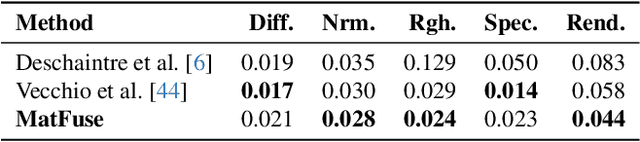
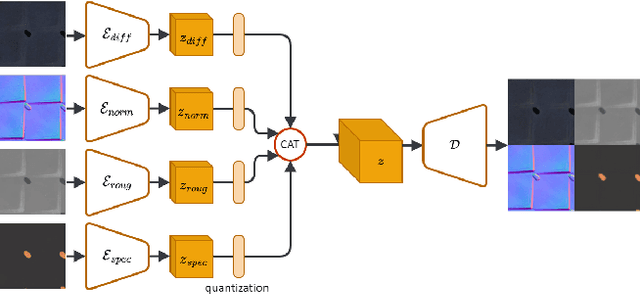
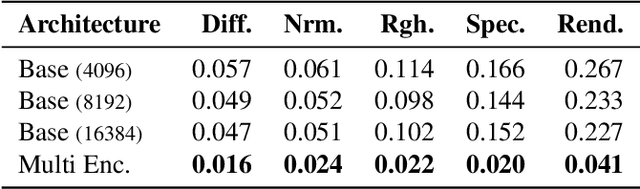
Creating high quality and realistic materials in computer graphics is a challenging and time-consuming task, which requires great expertise. In this paper, we present MatFuse, a novel unified approach that harnesses the generative power of diffusion models (DM) to simplify the creation of SVBRDF maps. Our DM-based pipeline integrates multiple sources of conditioning, such as color palettes, sketches, and pictures, enabling fine-grained control and flexibility in material synthesis. This design allows for the combination of diverse information sources (e.g., sketch + image embedding), enhancing creative possibilities in line with the principle of compositionality. We demonstrate the generative capabilities of the proposed method under various conditioning settings; on the SVBRDF estimation task, we show that our method yields performance comparable to state-of-the-art approaches, both qualitatively and quantitatively.
Preference-conditioned Pixel-based AI Agent For Game Testing
Aug 18, 2023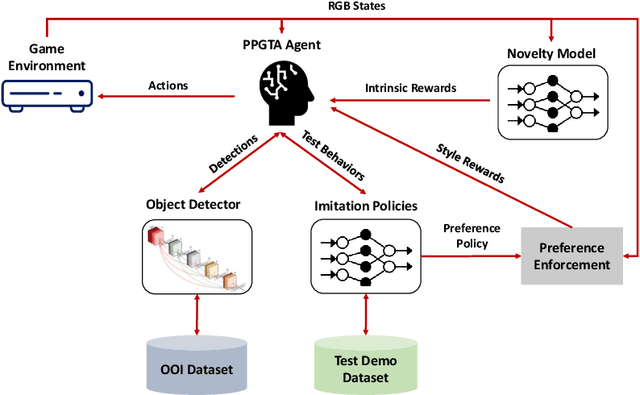
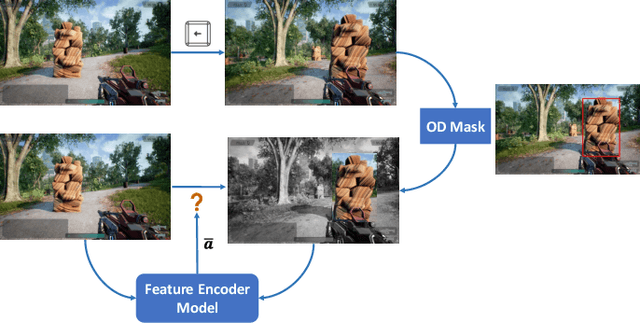
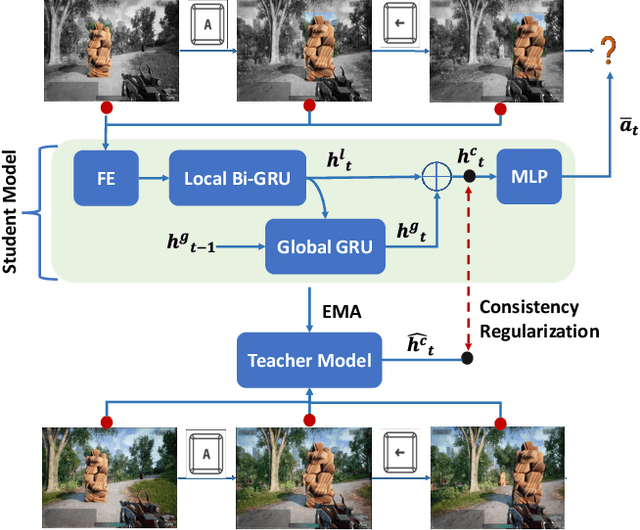
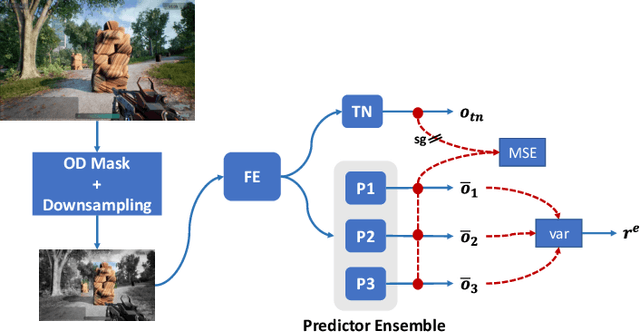
The game industry is challenged to cope with increasing growth in demand and game complexity while maintaining acceptable quality standards for released games. Classic approaches solely depending on human efforts for quality assurance and game testing do not scale effectively in terms of time and cost. Game-testing AI agents that learn by interaction with the environment have the potential to mitigate these challenges with good scalability properties on time and costs. However, most recent work in this direction depends on game state information for the agent's state representation, which limits generalization across different game scenarios. Moreover, game test engineers usually prefer exploring a game in a specific style, such as exploring the golden path. However, current game testing AI agents do not provide an explicit way to satisfy such a preference. This paper addresses these limitations by proposing an agent design that mainly depends on pixel-based state observations while exploring the environment conditioned on a user's preference specified by demonstration trajectories. In addition, we propose an imitation learning method that couples self-supervised and supervised learning objectives to enhance the quality of imitation behaviors. Our agent significantly outperforms state-of-the-art pixel-based game testing agents over exploration coverage and test execution quality when evaluated on a complex open-world environment resembling many aspects of real AAA games.
Filling time-series gaps using image techniques: Multidimensional context autoencoder approach for building energy data imputation
Jul 13, 2023Building energy prediction and management has become increasingly important in recent decades, driven by the growth of Internet of Things (IoT) devices and the availability of more energy data. However, energy data is often collected from multiple sources and can be incomplete or inconsistent, which can hinder accurate predictions and management of energy systems and limit the usefulness of the data for decision-making and research. To address this issue, past studies have focused on imputing missing gaps in energy data, including random and continuous gaps. One of the main challenges in this area is the lack of validation on a benchmark dataset with various building and meter types, making it difficult to accurately evaluate the performance of different imputation methods. Another challenge is the lack of application of state-of-the-art imputation methods for missing gaps in energy data. Contemporary image-inpainting methods, such as Partial Convolution (PConv), have been widely used in the computer vision domain and have demonstrated their effectiveness in dealing with complex missing patterns. To study whether energy data imputation can benefit from the image-based deep learning method, this study compared PConv, Convolutional neural networks (CNNs), and weekly persistence method using one of the biggest publicly available whole building energy datasets, consisting of 1479 power meters worldwide, as the benchmark. The results show that, compared to the CNN with the raw time series (1D-CNN) and the weekly persistence method, neural network models with reshaped energy data with two dimensions reduced the Mean Squared Error (MSE) by 10% to 30%. The advanced deep learning method, Partial convolution (PConv), has further reduced the MSE by 20-30% than 2D-CNN and stands out among all models.
A Real-time Human Pose Estimation Approach for Optimal Sensor Placement in Sensor-based Human Activity Recognition
Jul 06, 2023
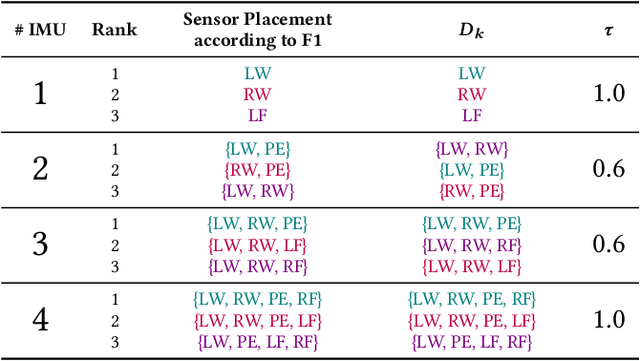

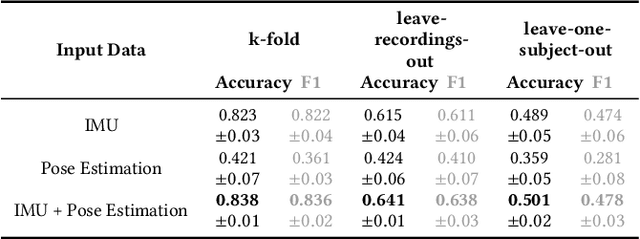
Sensor-based Human Activity Recognition facilitates unobtrusive monitoring of human movements. However, determining the most effective sensor placement for optimal classification performance remains challenging. This paper introduces a novel methodology to resolve this issue, using real-time 2D pose estimations derived from video recordings of target activities. The derived skeleton data provides a unique strategy for identifying the optimal sensor location. We validate our approach through a feasibility study, applying inertial sensors to monitor 13 different activities across ten subjects. Our findings indicate that the vision-based method for sensor placement offers comparable results to the conventional deep learning approach, demonstrating its efficacy. This research significantly advances the field of Human Activity Recognition by providing a lightweight, on-device solution for determining the optimal sensor placement, thereby enhancing data anonymization and supporting a multimodal classification approach.
PE-MED: Prompt Enhancement for Interactive Medical Image Segmentation
Aug 26, 2023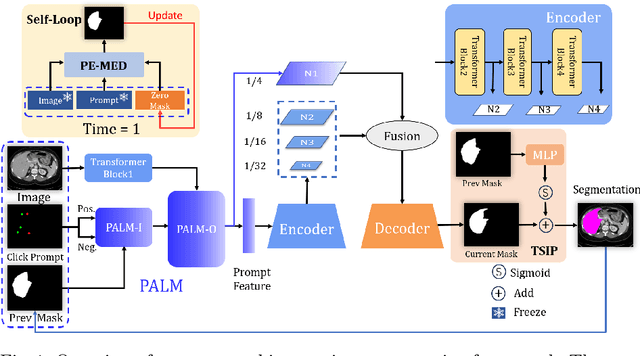
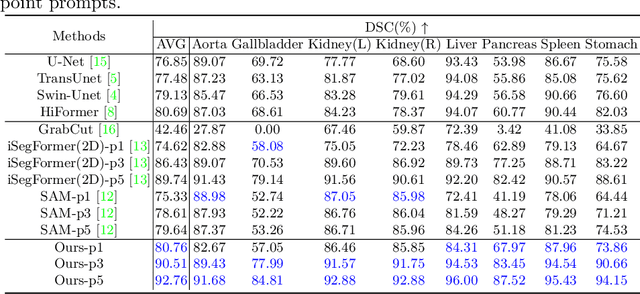
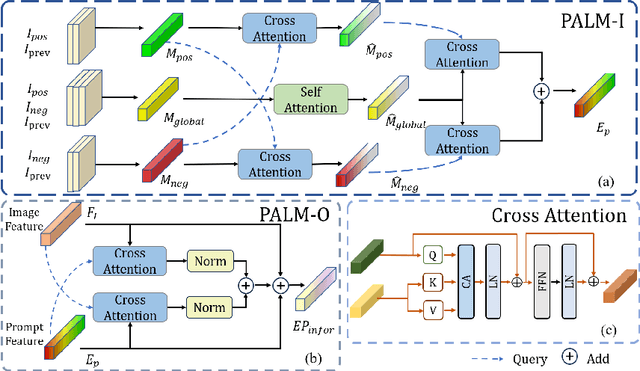

Interactive medical image segmentation refers to the accurate segmentation of the target of interest through interaction (e.g., click) between the user and the image. It has been widely studied in recent years as it is less dependent on abundant annotated data and more flexible than fully automated segmentation. However, current studies have not fully explored user-provided prompt information (e.g., points), including the knowledge mined in one interaction, and the relationship between multiple interactions. Thus, in this paper, we introduce a novel framework equipped with prompt enhancement, called PE-MED, for interactive medical image segmentation. First, we introduce a Self-Loop strategy to generate warm initial segmentation results based on the first prompt. It can prevent the highly unfavorable scenarios, such as encountering a blank mask as the initial input after the first interaction. Second, we propose a novel Prompt Attention Learning Module (PALM) to mine useful prompt information in one interaction, enhancing the responsiveness of the network to user clicks. Last, we build a Time Series Information Propagation (TSIP) mechanism to extract the temporal relationships between multiple interactions and increase the model stability. Comparative experiments with other state-of-the-art (SOTA) medical image segmentation algorithms show that our method exhibits better segmentation accuracy and stability.
ZC3: Zero-Shot Cross-Language Code Clone Detection
Aug 26, 2023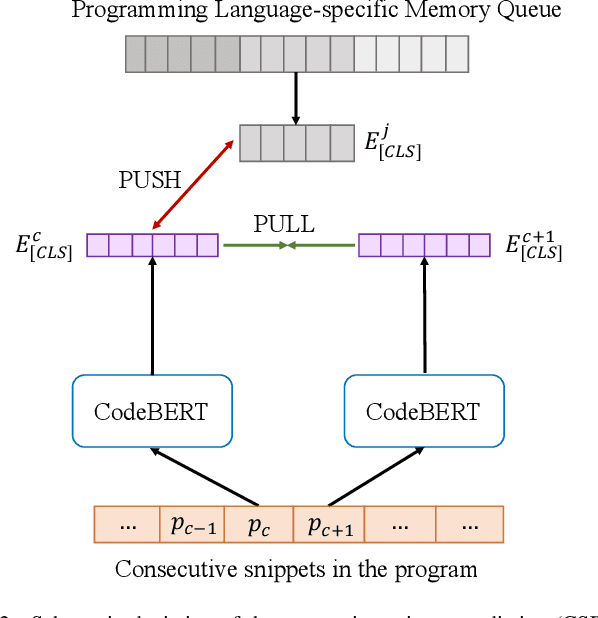
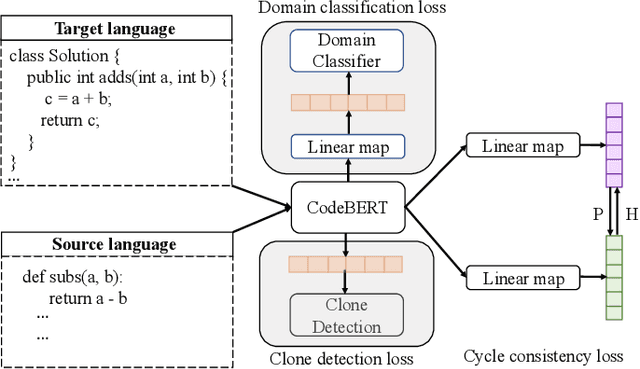
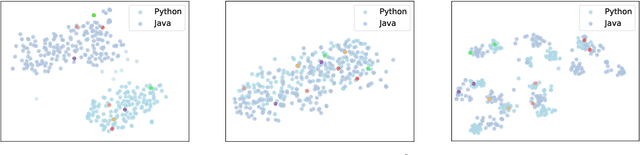
Developers introduce code clones to improve programming productivity. Many existing studies have achieved impressive performance in monolingual code clone detection. However, during software development, more and more developers write semantically equivalent programs with different languages to support different platforms and help developers translate projects from one language to another. Considering that collecting cross-language parallel data, especially for low-resource languages, is expensive and time-consuming, how designing an effective cross-language model that does not rely on any parallel data is a significant problem. In this paper, we propose a novel method named ZC3 for Zero-shot Cross-language Code Clone detection. ZC3 designs the contrastive snippet prediction to form an isomorphic representation space among different programming languages. Based on this, ZC3 exploits domain-aware learning and cycle consistency learning to further constrain the model to generate representations that are aligned among different languages meanwhile are diacritical for different types of clones. To evaluate our approach, we conduct extensive experiments on four representative cross-language clone detection datasets. Experimental results show that ZC3 outperforms the state-of-the-art baselines by 67.12%, 51.39%, 14.85%, and 53.01% on the MAP score, respectively. We further investigate the representational distribution of different languages and discuss the effectiveness of our method.