 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Zero Memory Footprint Spiking Neural Network Training
Aug 16, 2023
Biologically-inspired Spiking Neural Networks (SNNs), processing information using discrete-time events known as spikes rather than continuous values, have garnered significant attention due to their hardware-friendly and energy-efficient characteristics. However, the training of SNNs necessitates a considerably large memory footprint, given the additional storage requirements for spikes or events, leading to a complex structure and dynamic setup. In this paper, to address memory constraint in SNN training, we introduce an innovative framework, characterized by a remarkably low memory footprint. We \textbf{(i)} design a reversible SNN node that retains a high level of accuracy. Our design is able to achieve a $\mathbf{58.65\times}$ reduction in memory usage compared to the current SNN node. We \textbf{(ii)} propose a unique algorithm to streamline the backpropagation process of our reversible SNN node. This significantly trims the backward Floating Point Operations Per Second (FLOPs), thereby accelerating the training process in comparison to current reversible layer backpropagation method. By using our algorithm, the training time is able to be curtailed by $\mathbf{23.8\%}$ relative to existing reversible layer architectures.
Acquiring Qualitative Explainable Graphs for Automated Driving Scene Interpretation
Aug 24, 2023The future of automated driving (AD) is rooted in the development of robust, fair and explainable artificial intelligence methods. Upon request, automated vehicles must be able to explain their decisions to the driver and the car passengers, to the pedestrians and other vulnerable road users and potentially to external auditors in case of accidents. However, nowadays, most explainable methods still rely on quantitative analysis of the AD scene representations captured by multiple sensors. This paper proposes a novel representation of AD scenes, called Qualitative eXplainable Graph (QXG), dedicated to qualitative spatiotemporal reasoning of long-term scenes. The construction of this graph exploits the recent Qualitative Constraint Acquisition paradigm. Our experimental results on NuScenes, an open real-world multi-modal dataset, show that the qualitative eXplainable graph of an AD scene composed of 40 frames can be computed in real-time and light in space storage which makes it a potentially interesting tool for improved and more trustworthy perception and control processes in AD.
Video Recommendation Using Social Network Analysis and User Viewing Patterns
Aug 24, 2023
With the meteoric rise of video-on-demand (VOD) platforms, users face the challenge of sifting through an expansive sea of content to uncover shows that closely match their preferences. To address this information overload dilemma, VOD services have increasingly incorporated recommender systems powered by algorithms that analyze user behavior and suggest personalized content. However, a majority of existing recommender systems depend on explicit user feedback in the form of ratings and reviews, which can be difficult and time-consuming to collect at scale. This presents a key research gap, as leveraging users' implicit feedback patterns could provide an alternative avenue for building effective video recommendation models, circumventing the need for explicit ratings. However, prior literature lacks sufficient exploration into implicit feedback-based recommender systems, especially in the context of modeling video viewing behavior. Therefore, this paper aims to bridge this research gap by proposing a novel video recommendation technique that relies solely on users' implicit feedback in the form of their content viewing percentages.
Beyond Document Page Classification: Design, Datasets, and Challenges
Aug 24, 2023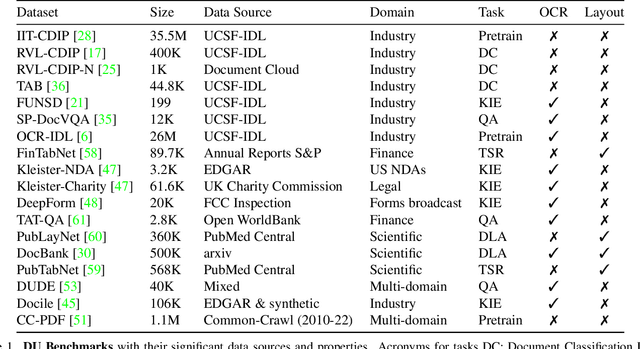
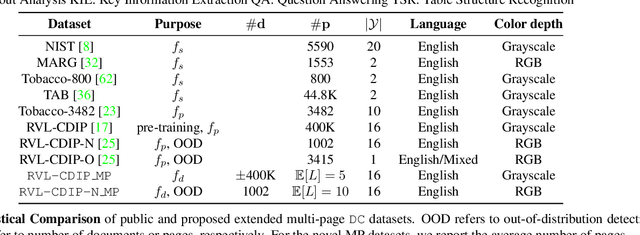

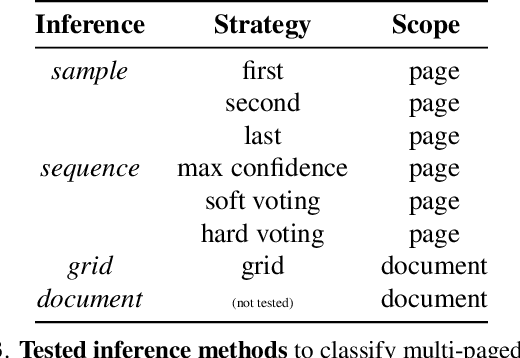
This paper highlights the need to bring document classification benchmarking closer to real-world applications, both in the nature of data tested ($X$: multi-channel, multi-paged, multi-industry; $Y$: class distributions and label set variety) and in classification tasks considered ($f$: multi-page document, page stream, and document bundle classification, ...). We identify the lack of public multi-page document classification datasets, formalize different classification tasks arising in application scenarios, and motivate the value of targeting efficient multi-page document representations. An experimental study on proposed multi-page document classification datasets demonstrates that current benchmarks have become irrelevant and need to be updated to evaluate complete documents, as they naturally occur in practice. This reality check also calls for more mature evaluation methodologies, covering calibration evaluation, inference complexity (time-memory), and a range of realistic distribution shifts (e.g., born-digital vs. scanning noise, shifting page order). Our study ends on a hopeful note by recommending concrete avenues for future improvements.}
Time Reversal Enabled Fiber-Optic Time Synchronization
Apr 14, 2023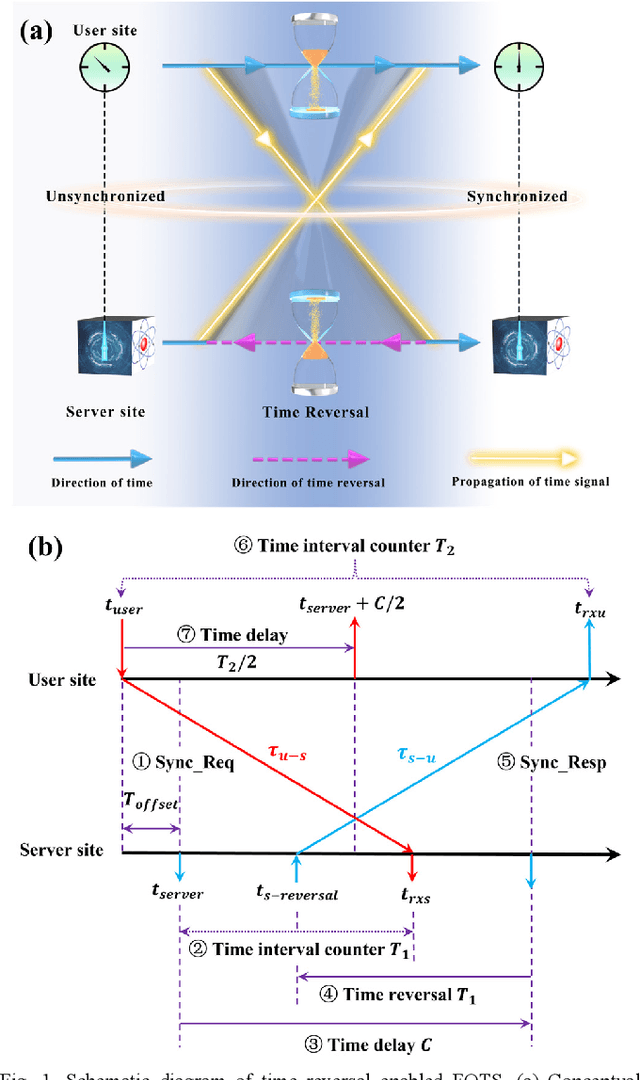
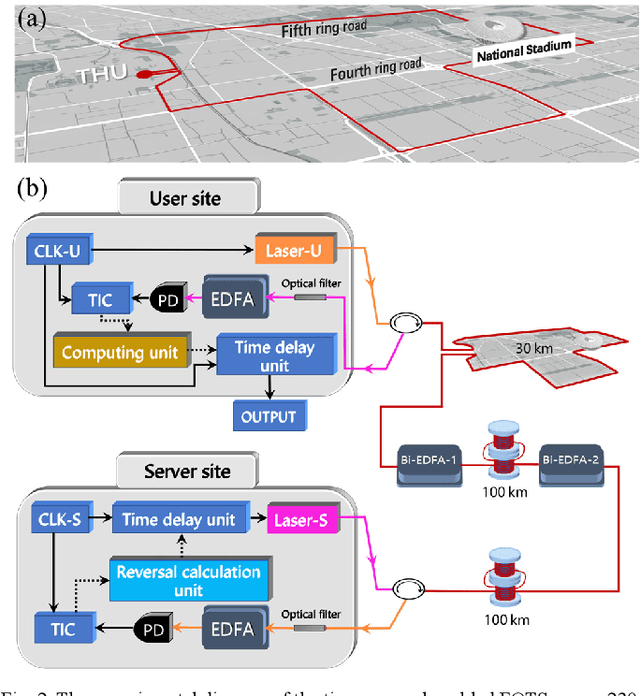
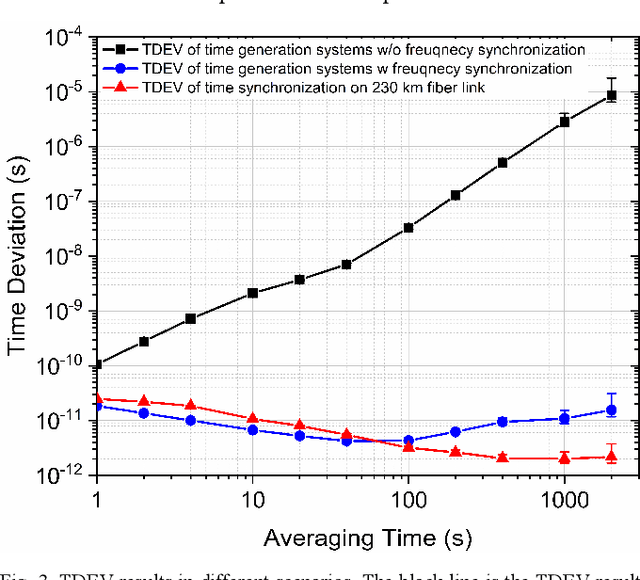
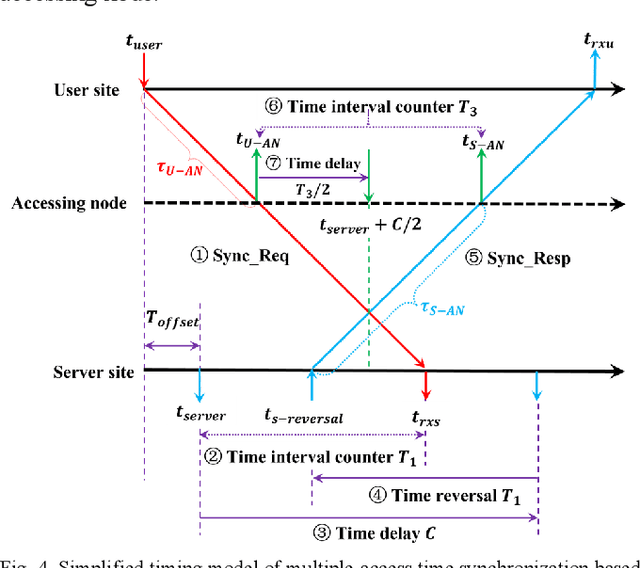
Over the past few decades, fiber-optic time synchronization (FOTS) has provided fundamental support for the efficient operation of modern society. Looking toward the future beyond fifth-generation/sixth-generation (B5G/6G) scenarios and very large radio telescope arrays, developing high-precision, low-complexity and scalable FOTS technology is crucial for building a large-scale time synchronization network. However, the traditional two-way FOTS method needs a data layer to exchange time delay information. This increases the complexity of system and makes it impossible to realize multiple-access time synchronization. In this paper, a time reversal enabled FOTS method is proposed. It measures the clock difference between two locations without involving a data layer, which can reduce the complexity of the system. Moreover, it can also achieve multiple-access time synchronization along the fiber link. Tests over a 230 km fiber link have been carried out to demonstrate the high performance of the proposed method.
EAMDrift: An interpretable self retrain model for time series
May 31, 2023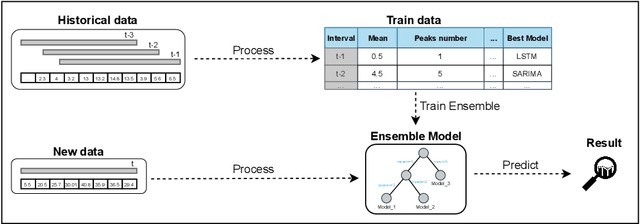
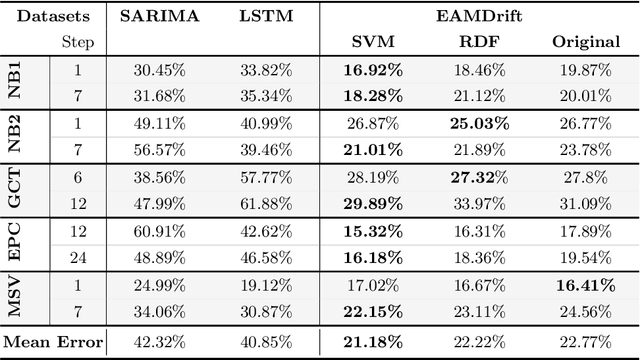
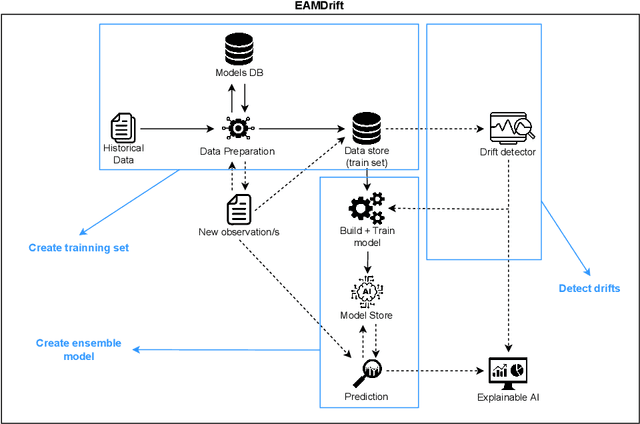
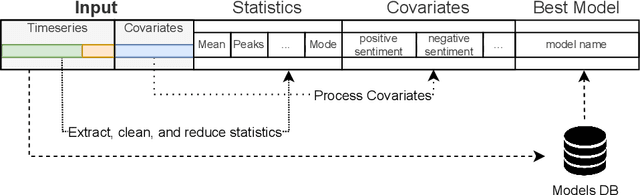
The use of machine learning for time series prediction has become increasingly popular across various industries thanks to the availability of time series data and advancements in machine learning algorithms. However, traditional methods for time series forecasting rely on pre-optimized models that are ill-equipped to handle unpredictable patterns in data. In this paper, we present EAMDrift, a novel method that combines forecasts from multiple individual predictors by weighting each prediction according to a performance metric. EAMDrift is designed to automatically adapt to out-of-distribution patterns in data and identify the most appropriate models to use at each moment through interpretable mechanisms, which include an automatic retraining process. Specifically, we encode different concepts with different models, each functioning as an observer of specific behaviors. The activation of the overall model then identifies which subset of the concept observers is identifying concepts in the data. This activation is interpretable and based on learned rules, allowing to study of input variables relations. Our study on real-world datasets shows that EAMDrift outperforms individual baseline models by 20% and achieves comparable accuracy results to non-interpretable ensemble models. These findings demonstrate the efficacy of EAMDrift for time-series prediction and highlight the importance of interpretability in machine learning models.
Coherent FDA Receiver and Joint Range-Space-Time Processing
Jun 01, 2023When a target is masked by mainlobe clutter with the same Doppler frequency, it is difficult for conventional airborne radars to determine whether a target is present in a given observation using regular space-time adaptive processing techniques. Different from phased-array and multiple-input multiple-output (MIMO) arrays, frequency diverse arrays (FDAs) employ frequency offsets across the array elements, delivering additional range-controllable degrees of freedom, potentially enabling suppression for this kind of clutter. However, the reception of coherent FDA systems employing small frequency offsets and achieving high transmit gain can be further improved. To this end, this work proposes an coherent airborne FDA radar receiver that explores the orthogonality of echo signals in the Doppler domain, allowing a joint space-time processing module to be deployed to separate the aliased returns. The resulting range-space-time adaptive processing allows for a preferable detection performance for coherent airborne FDA radars as compared to current alternative techniques.
CoMIX: A Multi-agent Reinforcement Learning Training Architecture for Efficient Decentralized Coordination and Independent Decision Making
Aug 21, 2023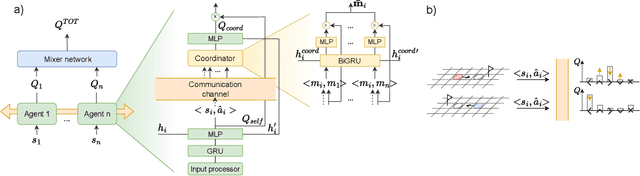
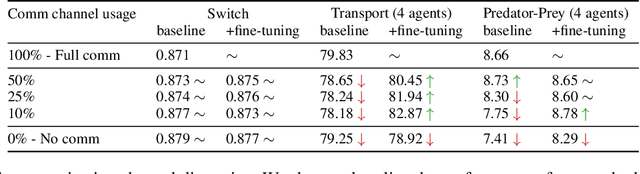
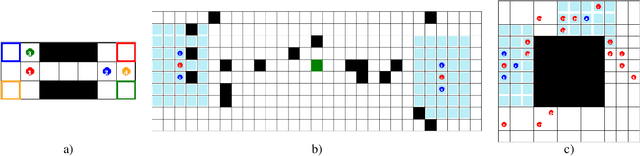
Robust coordination skills enable agents to operate cohesively in shared environments, together towards a common goal and, ideally, individually without hindering each other's progress. To this end, this paper presents Coordinated QMIX (CoMIX), a novel training framework for decentralized agents that enables emergent coordination through flexible policies, allowing at the same time independent decision-making at individual level. CoMIX models selfish and collaborative behavior as incremental steps in each agent's decision process. This allows agents to dynamically adapt their behavior to different situations balancing independence and collaboration. Experiments using a variety of simulation environments demonstrate that CoMIX outperforms baselines on collaborative tasks. The results validate our incremental policy approach as effective technique for improving coordination in multi-agent systems.
Time Series Clustering With Random Convolutional Kernels
May 17, 2023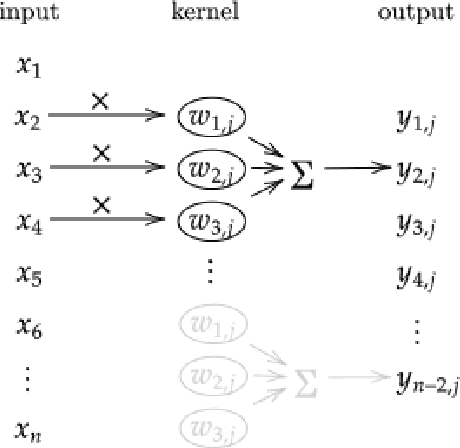
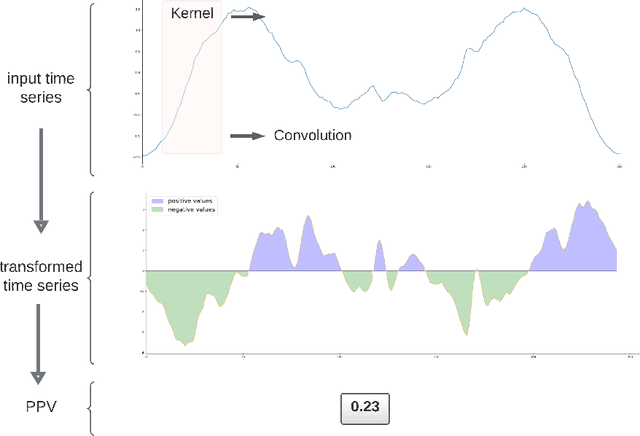
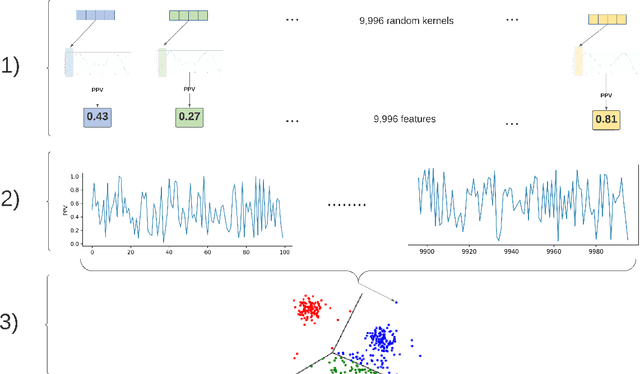
Time series can describe a wide range of natural and social phenomena. A few samples are climate and seismic measures trends, stock prices, or website visits. Time-series clustering helps to find outliers that, related to these instances, could represent temperature anomalies, imminent volcanic eruptions, market disturbances, or fraudulent web traffic. Founded on the success of automatic feature extraction techniques, specifically employing random kernels, we develop a new method for time series clustering consisting of two steps. First, a random convolutional structure transforms the data into an enhanced feature representation. Afterwards, a clustering algorithm classifies the transformed data. The method improves state-of-the-art results on time series clustering benchmarks.
Machine Learning aided Computer Architecture Design for CNN Inferencing Systems
Aug 10, 2023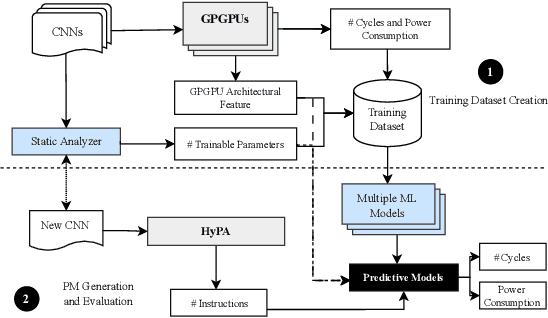
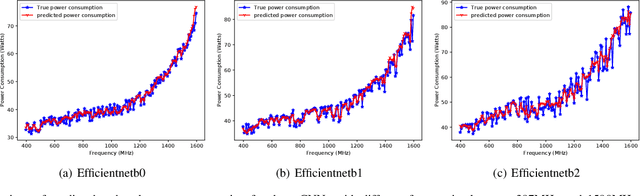
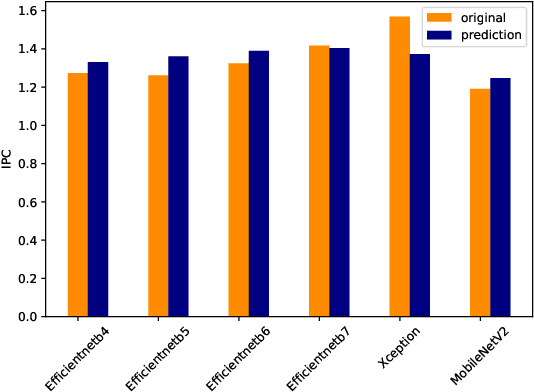
Efficient and timely calculations of Machine Learning (ML) algorithms are essential for emerging technologies like autonomous driving, the Internet of Things (IoT), and edge computing. One of the primary ML algorithms used in such systems is Convolutional Neural Networks (CNNs), which demand high computational resources. This requirement has led to the use of ML accelerators like GPGPUs to meet design constraints. However, selecting the most suitable accelerator involves Design Space Exploration (DSE), a process that is usually time-consuming and requires significant manual effort. Our work presents approaches to expedite the DSE process by identifying the most appropriate GPGPU for CNN inferencing systems. We have developed a quick and precise technique for forecasting the power and performance of CNNs during inference, with a MAPE of 5.03% and 5.94%, respectively. Our approach empowers computer architects to estimate power and performance in the early stages of development, reducing the necessity for numerous prototypes. This saves time and money while also improving the time-to-market period.