 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diagrammatic Instructions to Specify Spatial Objectives and Constraints with Applications to Mobile Base Placement
Mar 25, 2024

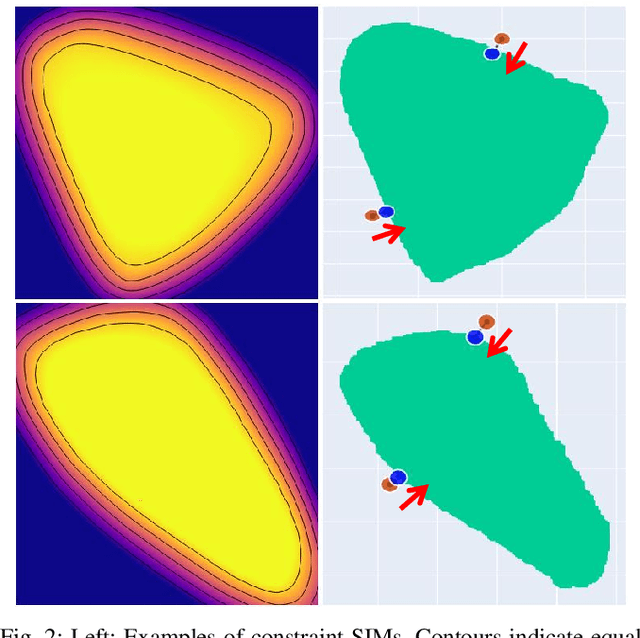
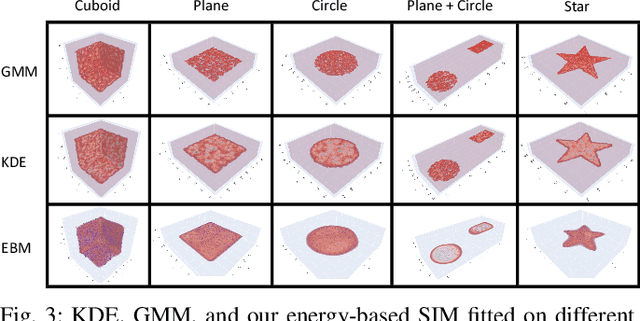

This paper introduces Spatial Diagrammatic Instructions (SDIs), an approach for human operators to specify objectives and constraints that are related to spatial regions in the working environment. Human operators are enabled to sketch out regions directly on camera images that correspond to the objectives and constraints. These sketches are projected to 3D spatial coordinates, and continuous Spatial Instruction Maps (SIMs) are learned upon them. These maps can then be integrated into optimization problems for tasks of robots. In particular, we demonstrate how Spatial Diagrammatic Instructions can be applied to solve the Base Placement Problem of mobile manipulators, which concerns the best place to put the manipulator to facilitate a certain task. Human operators can specify, via sketch, spatial regions of interest for a manipulation task and permissible regions for the mobile manipulator to be at. Then, an optimization problem that maximizes the manipulator's reachability, or coverage, over the designated regions of interest while remaining in the permissible regions is solved. We provide extensive empirical evaluations, and show that our formulation of Spatial Instruction Maps provides accurate representations of user-specified diagrammatic instructions. Furthermore, we demonstrate that our diagrammatic approach to the Mobile Base Placement Problem enables higher quality solutions and faster run-time.
Deja vu: Contrastive Historical Modeling with Prefix-tuning for Temporal Knowledge Graph Reasoning
Mar 25, 2024Temporal Knowledge Graph Reasoning (TKGR) is the task of inferring missing facts for incomplete TKGs in complex scenarios (e.g., transductive and inductive settings), which has been gaining increasing attention. Recently, to mitigate dependence on structured connections in TKGs, text-based methods have been developed to utilize rich linguistic information from entity descriptions. However, suffering from the enormous parameters and inflexibility of pre-trained language models, existing text-based methods struggle to balance the textual knowledge and temporal information with computationally expensive purpose-built training strategies. To tap the potential of text-based models for TKGR in various complex scenarios, we propose ChapTER, a Contrastive historical modeling framework with prefix-tuning for TEmporal Reasoning. ChapTER feeds history-contextualized text into the pseudo-Siamese encoders to strike a textual-temporal balance via contrastive estimation between queries and candidates. By introducing virtual time prefix tokens, it applies a prefix-based tuning method to facilitate the frozen PLM capable for TKGR tasks under different settings. We evaluate ChapTER on four transductive and three few-shot inductive TKGR benchmarks, and experimental results demonstrate that ChapTER achieves superior performance compared to competitive baselines with only 0.17% tuned parameters. We conduct thorough analysis to verify the effectiveness, flexibility and efficiency of ChapTER.
Discrete Semantic Tokenization for Deep CTR Prediction
Mar 21, 2024Incorporating item content information into click-through rate (CTR) prediction models remains a challenge, especially with the time and space constraints of industrial scenarios. The content-encoding paradigm, which integrates user and item encoders directly into CTR models, prioritizes space over time. In contrast, the embedding-based paradigm transforms item and user semantics into latent embeddings, subsequently caching them to optimize processing time at the expense of space. In this paper, we introduce a new semantic-token paradigm and propose a discrete semantic tokenization approach, namely UIST, for user and item representation. UIST facilitates swift training and inference while maintaining a conservative memory footprint. Specifically, UIST quantizes dense embedding vectors into discrete tokens with shorter lengths and employs a hierarchical mixture inference module to weigh the contribution of each user--item token pair. Our experimental results on news recommendation showcase the effectiveness and efficiency (about 200-fold space compression) of UIST for CTR prediction.
Learning to Change: Choreographing Mixed Traffic Through Lateral Control and Hierarchical Reinforcement Learning
Mar 21, 2024The management of mixed traffic that consists of robot vehicles (RVs) and human-driven vehicles (HVs) at complex intersections presents a multifaceted challenge. Traditional signal controls often struggle to adapt to dynamic traffic conditions and heterogeneous vehicle types. Recent advancements have turned to strategies based on reinforcement learning (RL), leveraging its model-free nature, real-time operation, and generalizability over different scenarios. We introduce a hierarchical RL framework to manage mixed traffic through precise longitudinal and lateral control of RVs. Our proposed hierarchical framework combines the state-of-the-art mixed traffic control algorithm as a high level decision maker to improve the performance and robustness of the whole system. Our experiments demonstrate that the framework can reduce the average waiting time by up to 54% compared to the state-of-the-art mixed traffic control method. When the RV penetration rate exceeds 60%, our technique consistently outperforms conventional traffic signal control programs in terms of the average waiting time for all vehicles at the intersection.
SRLM: Human-in-Loop Interactive Social Robot Navigation with Large Language Model and Deep Reinforcement Learning
Mar 22, 2024An interactive social robotic assistant must provide services in complex and crowded spaces while adapting its behavior based on real-time human language commands or feedback. In this paper, we propose a novel hybrid approach called Social Robot Planner (SRLM), which integrates Large Language Models (LLM) and Deep Reinforcement Learning (DRL) to navigate through human-filled public spaces and provide multiple social services. SRLM infers global planning from human-in-loop commands in real-time, and encodes social information into a LLM-based large navigation model (LNM) for low-level motion execution. Moreover, a DRL-based planner is designed to maintain benchmarking performance, which is blended with LNM by a large feedback model (LFM) to address the instability of current text and LLM-driven LNM. Finally, SRLM demonstrates outstanding performance in extensive experiments. More details about this work are available at: https://sites.google.com/view/navi-srlm
OceanPlan: Hierarchical Planning and Replanning for Natural Language AUV Piloting in Large-scale Unexplored Ocean Environments
Mar 22, 2024We develop a hierarchical LLM-task-motion planning and replanning framework to efficiently ground an abstracted human command into tangible Autonomous Underwater Vehicle (AUV) control through enhanced representations of the world. We also incorporate a holistic replanner to provide real-world feedback with all planners for robust AUV operation. While there has been extensive research in bridging the gap between LLMs and robotic missions, they are unable to guarantee success of AUV applications in the vast and unknown ocean environment. To tackle specific challenges in marine robotics, we design a hierarchical planner to compose executable motion plans, which achieves planning efficiency and solution quality by decomposing long-horizon missions into sub-tasks. At the same time, real-time data stream is obtained by a replanner to address environmental uncertainties during plan execution. Experiments validate that our proposed framework delivers successful AUV performance of long-duration missions through natural language piloting.
Time-optimal Point-to-point Motion Planning: A Two-stage Approach
Mar 06, 2024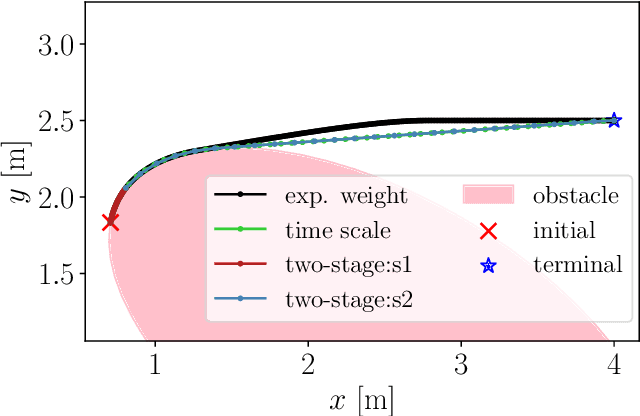
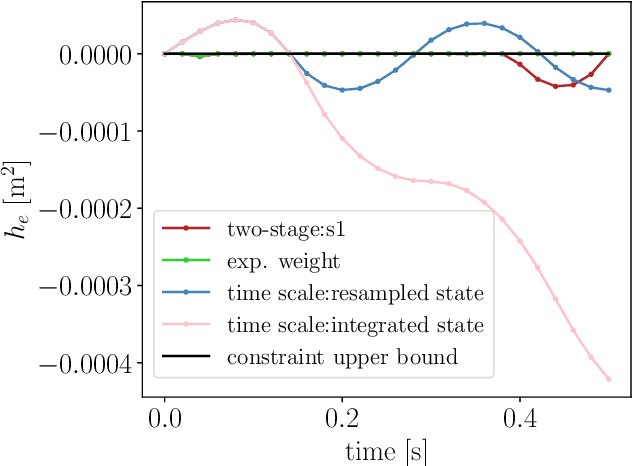
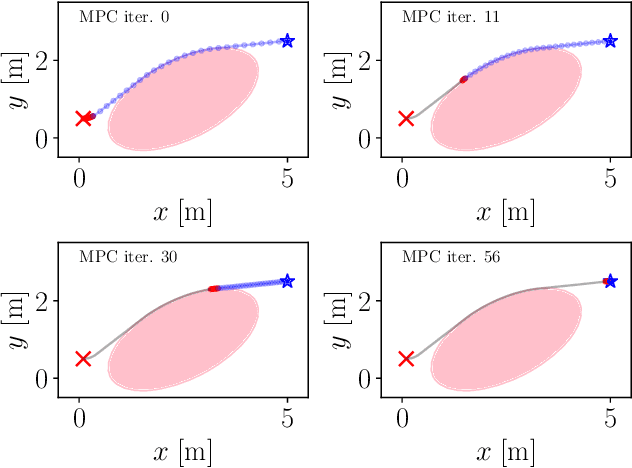
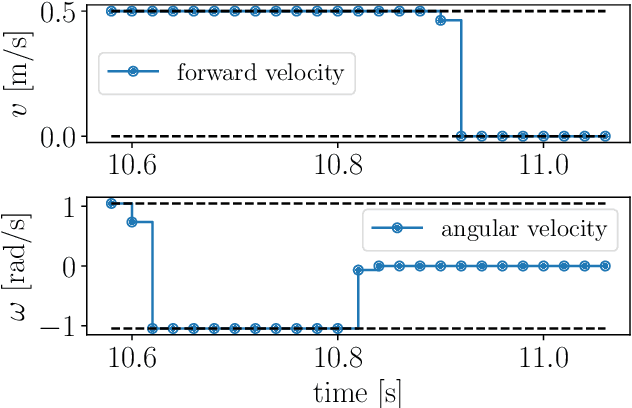
This paper proposes a two-stage approach to formulate the time-optimal point-to-point motion planning problem, involving a first stage with a fixed time grid and a second stage with a variable time grid. The proposed approach brings benefits through its straightforward optimal control problem formulation with a fixed and low number of control steps for manageable computational complexity and the avoidance of interpolation errors associated with time scaling, especially when aiming to reach a distant goal. Additionally, an asynchronous nonlinear model predictive control (NMPC) update scheme is integrated with this two-stage approach to address delayed and fluctuating computation times, facilitating online replanning. The effectiveness of the proposed two-stage approach and NMPC implementation is demonstrated through numerical examples centered on autonomous navigation with collision avoidance.
Right on Time: Revising Time Series Models by Constraining their Explanations
Feb 28, 2024The reliability of deep time series models is often compromised by their tendency to rely on confounding factors, which may lead to misleading results. Our newly recorded, naturally confounded dataset named P2S from a real mechanical production line emphasizes this. To tackle the challenging problem of mitigating confounders in time series data, we introduce Right on Time (RioT). Our method enables interactions with model explanations across both the time and frequency domain. Feedback on explanations in both domains is then used to constrain the model, steering it away from the annotated confounding factors. The dual-domain interaction strategy is crucial for effectively addressing confounders in time series datasets. We empirically demonstrate that RioT can effectively guide models away from the wrong reasons in P2S as well as popular time series classification and forecasting datasets.
A task of anomaly detection for a smart satellite Internet of things system
Mar 21, 2024When the equipment is working, real-time collection of environmental sensor data for anomaly detection is one of the key links to prevent industrial process accidents and network attacks and ensure system security. However, under the environment with specific real-time requirements, the anomaly detection for environmental sensors still faces the following difficulties: (1) The complex nonlinear correlation characteristics between environmental sensor data variables lack effective expression methods, and the distribution between the data is difficult to be captured. (2) it is difficult to ensure the real-time monitoring requirements by using complex machine learning models, and the equipment cost is too high. (3) Too little sample data leads to less labeled data in supervised learning. This paper proposes an unsupervised deep learning anomaly detection system. Based on the generative adversarial network and self-attention mechanism, considering the different feature information contained in the local subsequences, it automatically learns the complex linear and nonlinear dependencies between environmental sensor variables, and uses the anomaly score calculation method combining reconstruction error and discrimination error. It can monitor the abnormal points of real sensor data with high real-time performance and can run on the intelligent satellite Internet of things system, which is suitable for the real working environment. Anomaly detection outperforms baseline methods in most cases and has good interpretability, which can be used to prevent industrial accidents and cyber-attacks for monitoring environmental sensors.
PROSPECT: Precision Robot Spectroscopy Exploration and Characterization Tool
Mar 25, 2024Near Infrared (NIR) spectroscopy is widely used in industrial quality control and automation to test the purity and material quality of items. In this research, we propose a novel sensorized end effector and acquisition strategy to capture spectral signatures from objects and register them with a 3D point cloud. Our methodology first takes a 3D scan of an object generated by a time-of-flight depth camera and decomposes the object into a series of planned viewpoints covering the surface. We generate motion plans for a robot manipulator and end-effector to visit these viewpoints while maintaining a fixed distance and surface normal to ensure maximal spectral signal quality enabled by the spherical motion of the end-effector. By continuously acquiring surface reflectance values as the end-effector scans the target object, the autonomous system develops a four-dimensional model of the target object: position in an R^3 coordinate frame, and a wavelength vector denoting the associated spectral signature. We demonstrate this system in building spectral-spatial object profiles of increasingly complex geometries. As a point of comparison, we show our proposed system and spectral acquisition planning yields more consistent signal signals than naive point scanning strategies for capturing spectral information over complex surface geometries. Our work represents a significant step towards high-resolution spectral-spatial sensor fusion for automated quality assessment.