 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Acquiring Qualitative Explainable Graphs for Automated Driving Scene Interpretation
Aug 24, 2023
The future of automated driving (AD) is rooted in the development of robust, fair and explainable artificial intelligence methods. Upon request, automated vehicles must be able to explain their decisions to the driver and the car passengers, to the pedestrians and other vulnerable road users and potentially to external auditors in case of accidents. However, nowadays, most explainable methods still rely on quantitative analysis of the AD scene representations captured by multiple sensors. This paper proposes a novel representation of AD scenes, called Qualitative eXplainable Graph (QXG), dedicated to qualitative spatiotemporal reasoning of long-term scenes. The construction of this graph exploits the recent Qualitative Constraint Acquisition paradigm. Our experimental results on NuScenes, an open real-world multi-modal dataset, show that the qualitative eXplainable graph of an AD scene composed of 40 frames can be computed in real-time and light in space storage which makes it a potentially interesting tool for improved and more trustworthy perception and control processes in AD.
Video Recommendation Using Social Network Analysis and User Viewing Patterns
Aug 24, 2023
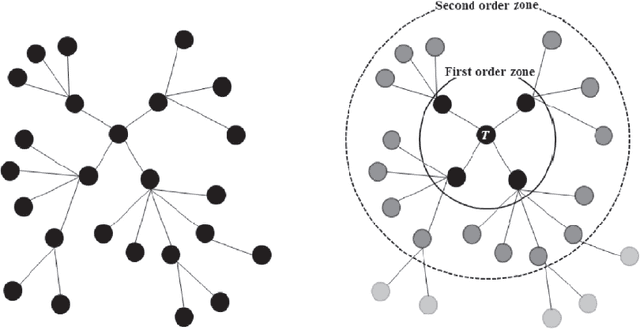
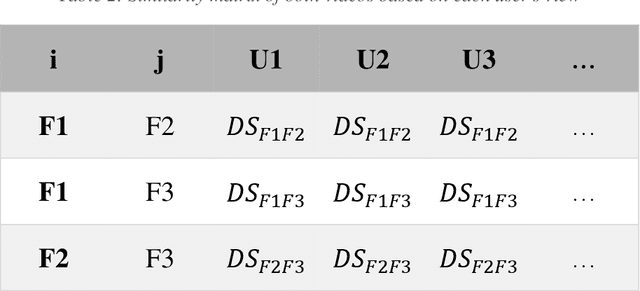
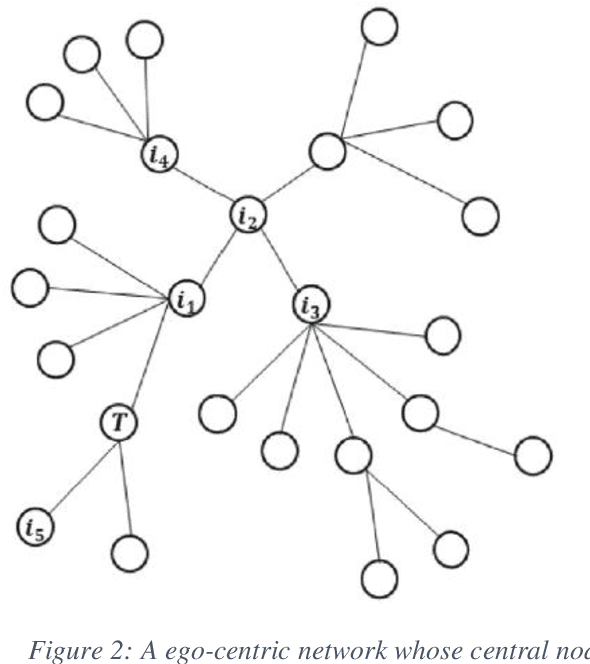
With the meteoric rise of video-on-demand (VOD) platforms, users face the challenge of sifting through an expansive sea of content to uncover shows that closely match their preferences. To address this information overload dilemma, VOD services have increasingly incorporated recommender systems powered by algorithms that analyze user behavior and suggest personalized content. However, a majority of existing recommender systems depend on explicit user feedback in the form of ratings and reviews, which can be difficult and time-consuming to collect at scale. This presents a key research gap, as leveraging users' implicit feedback patterns could provide an alternative avenue for building effective video recommendation models, circumventing the need for explicit ratings. However, prior literature lacks sufficient exploration into implicit feedback-based recommender systems, especially in the context of modeling video viewing behavior. Therefore, this paper aims to bridge this research gap by proposing a novel video recommendation technique that relies solely on users' implicit feedback in the form of their content viewing percentages.
Beyond Document Page Classification: Design, Datasets, and Challenges
Aug 24, 2023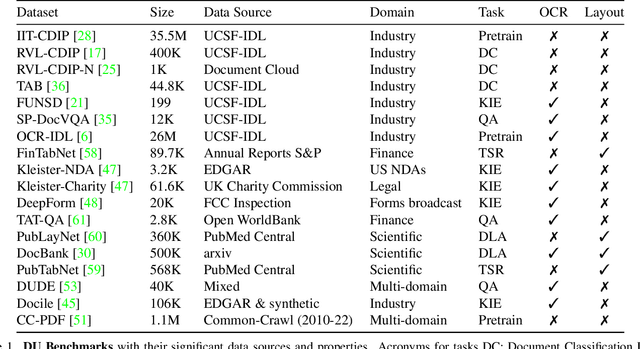
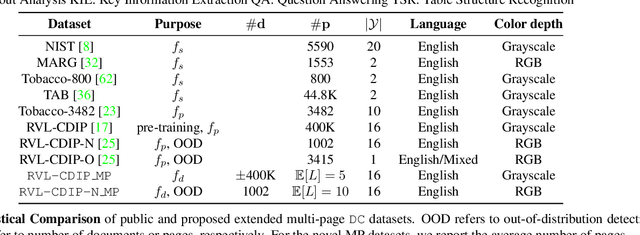

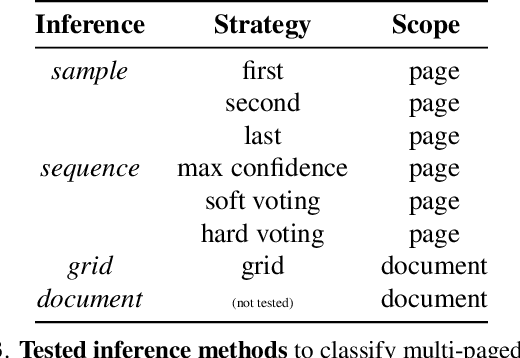
This paper highlights the need to bring document classification benchmarking closer to real-world applications, both in the nature of data tested ($X$: multi-channel, multi-paged, multi-industry; $Y$: class distributions and label set variety) and in classification tasks considered ($f$: multi-page document, page stream, and document bundle classification, ...). We identify the lack of public multi-page document classification datasets, formalize different classification tasks arising in application scenarios, and motivate the value of targeting efficient multi-page document representations. An experimental study on proposed multi-page document classification datasets demonstrates that current benchmarks have become irrelevant and need to be updated to evaluate complete documents, as they naturally occur in practice. This reality check also calls for more mature evaluation methodologies, covering calibration evaluation, inference complexity (time-memory), and a range of realistic distribution shifts (e.g., born-digital vs. scanning noise, shifting page order). Our study ends on a hopeful note by recommending concrete avenues for future improvements.}
A-STAR: Test-time Attention Segregation and Retention for Text-to-image Synthesis
Jun 26, 2023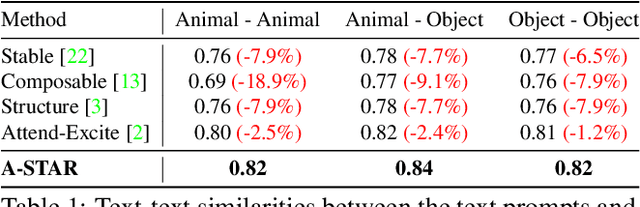
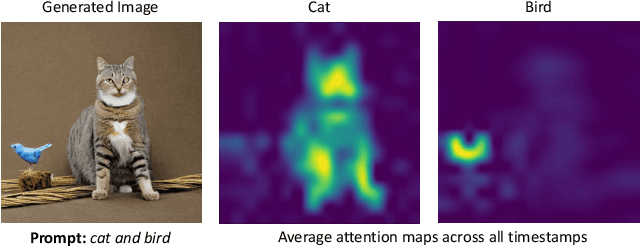
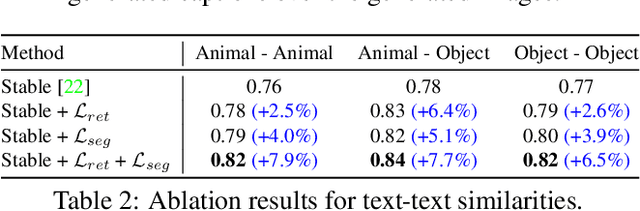

While recent developments in text-to-image generative models have led to a suite of high-performing methods capable of producing creative imagery from free-form text, there are several limitations. By analyzing the cross-attention representations of these models, we notice two key issues. First, for text prompts that contain multiple concepts, there is a significant amount of pixel-space overlap (i.e., same spatial regions) among pairs of different concepts. This eventually leads to the model being unable to distinguish between the two concepts and one of them being ignored in the final generation. Next, while these models attempt to capture all such concepts during the beginning of denoising (e.g., first few steps) as evidenced by cross-attention maps, this knowledge is not retained by the end of denoising (e.g., last few steps). Such loss of knowledge eventually leads to inaccurate generation outputs. To address these issues, our key innovations include two test-time attention-based loss functions that substantially improve the performance of pretrained baseline text-to-image diffusion models. First, our attention segregation loss reduces the cross-attention overlap between attention maps of different concepts in the text prompt, thereby reducing the confusion/conflict among various concepts and the eventual capture of all concepts in the generated output. Next, our attention retention loss explicitly forces text-to-image diffusion models to retain cross-attention information for all concepts across all denoising time steps, thereby leading to reduced information loss and the preservation of all concepts in the generated output.
Towards Zero Memory Footprint Spiking Neural Network Training
Aug 16, 2023Biologically-inspired Spiking Neural Networks (SNNs), processing information using discrete-time events known as spikes rather than continuous values, have garnered significant attention due to their hardware-friendly and energy-efficient characteristics. However, the training of SNNs necessitates a considerably large memory footprint, given the additional storage requirements for spikes or events, leading to a complex structure and dynamic setup. In this paper, to address memory constraint in SNN training, we introduce an innovative framework, characterized by a remarkably low memory footprint. We \textbf{(i)} design a reversible SNN node that retains a high level of accuracy. Our design is able to achieve a $\mathbf{58.65\times}$ reduction in memory usage compared to the current SNN node. We \textbf{(ii)} propose a unique algorithm to streamline the backpropagation process of our reversible SNN node. This significantly trims the backward Floating Point Operations Per Second (FLOPs), thereby accelerating the training process in comparison to current reversible layer backpropagation method. By using our algorithm, the training time is able to be curtailed by $\mathbf{23.8\%}$ relative to existing reversible layer architectures.
Better Batch for Deep Probabilistic Time Series Forecasting
May 26, 2023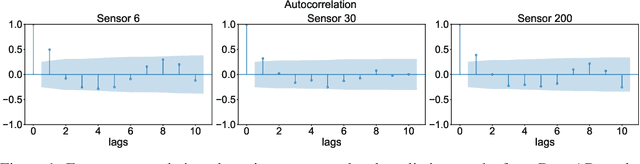
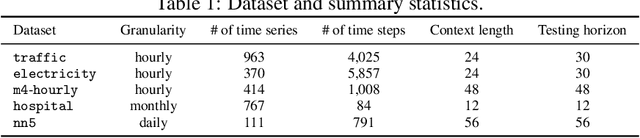
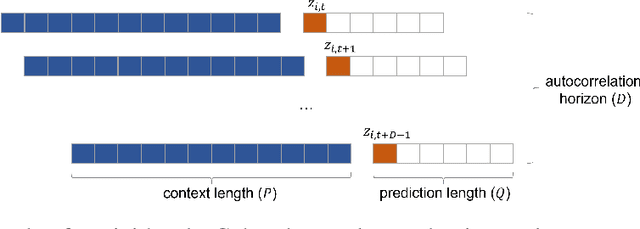
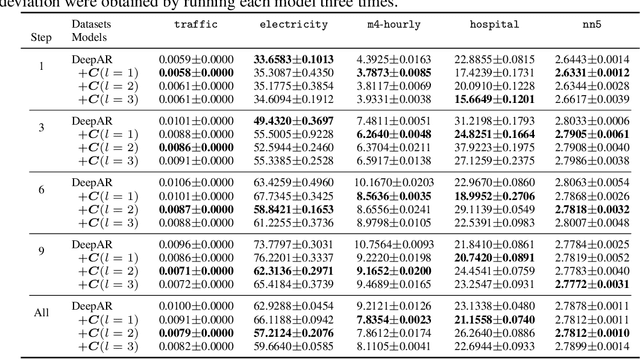
Deep probabilistic time series forecasting has gained significant attention due to its ability to provide valuable uncertainty quantification for decision-making tasks. However, many existing models oversimplify the problem by assuming the error process is time-independent, thereby overlooking the serial correlation in the error process. This oversight can potentially diminish the accuracy of the forecasts, rendering these models less effective for decision-making purposes. To overcome this limitation, we propose an innovative training method that incorporates error autocorrelation to enhance the accuracy of probabilistic forecasting. Our method involves constructing a mini-batch as a collection of $D$ consecutive time series segments for model training and explicitly learning a covariance matrix over each mini-batch that encodes the error correlation among adjacent time steps. The resulting covariance matrix can be used to improve prediction accuracy and enhance uncertainty quantification. We evaluate our method using DeepAR on multiple public datasets, and the experimental results confirm that our framework can effectively capture the error autocorrelation and enhance probabilistic forecasting.
On the Predictive Accuracy of Neural Temporal Point Process Models for Continuous-time Event Data
Jun 29, 2023Temporal Point Processes (TPPs) serve as the standard mathematical framework for modeling asynchronous event sequences in continuous time. However, classical TPP models are often constrained by strong assumptions, limiting their ability to capture complex real-world event dynamics. To overcome this limitation, researchers have proposed Neural TPPs, which leverage neural network parametrizations to offer more flexible and efficient modeling. While recent studies demonstrate the effectiveness of Neural TPPs, they often lack a unified setup, relying on different baselines, datasets, and experimental configurations. This makes it challenging to identify the key factors driving improvements in predictive accuracy, hindering research progress. To bridge this gap, we present a comprehensive large-scale experimental study that systematically evaluates the predictive accuracy of state-of-the-art neural TPP models. Our study encompasses multiple real-world and synthetic event sequence datasets, following a carefully designed unified setup. We thoroughly investigate the influence of major architectural components such as event encoding, history encoder, and decoder parametrization on both time and mark prediction tasks. Additionally, we delve into the less explored area of probabilistic calibration for neural TPP models. By analyzing our results, we draw insightful conclusions regarding the significance of history size and the impact of architectural components on predictive accuracy. Furthermore, we shed light on the miscalibration of mark distributions in neural TPP models. Our study aims to provide valuable insights into the performance and characteristics of neural TPP models, contributing to a better understanding of their strengths and limitations.
Blockage Prediction in Directional mmWave Links Using Liquid Time Constant Network
Jun 08, 2023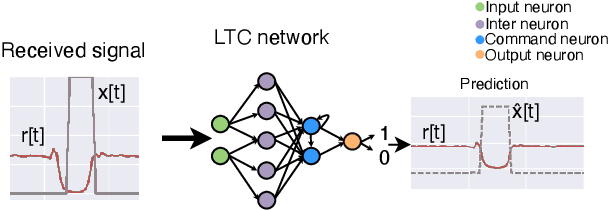
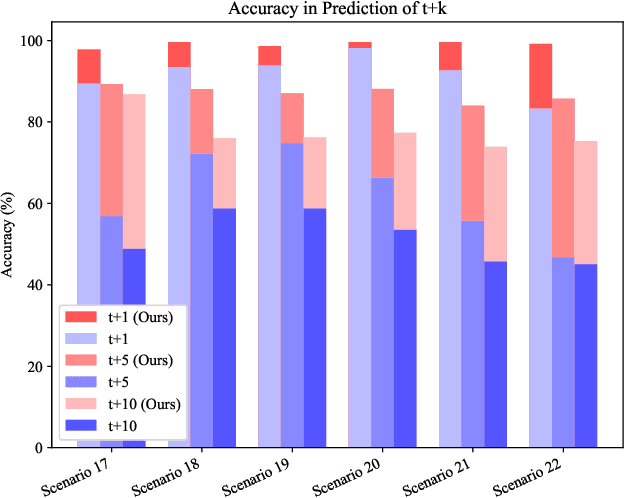
We propose to use a liquid time constant (LTC) network to predict the future blockage status of a millimeter wave (mmWave) link using only the received signal power as the input to the system. The LTC network is based on an ordinary differential equation (ODE) system inspired by biology and specialized for near-future prediction for time sequence observation as the input. Using an experimental dataset at 60 GHz, we show that our proposed use of LTC can reliably predict the occurrence of blockage and the length of the blockage without the need for scenario-specific data. The results show that the proposed LTC can predict with upwards of 97.85\% accuracy without prior knowledge of the outdoor scenario or retraining/tuning. These results highlight the promising gains of using LTC networks to predict time series-dependent signals, which can lead to more reliable and low-latency communication.
CoMIX: A Multi-agent Reinforcement Learning Training Architecture for Efficient Decentralized Coordination and Independent Decision Making
Aug 21, 2023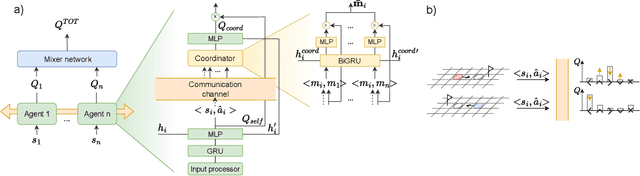
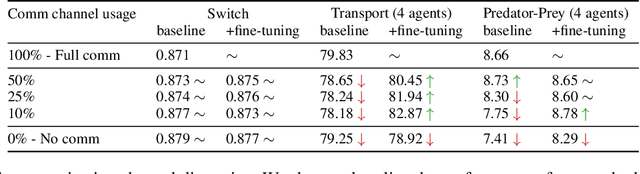
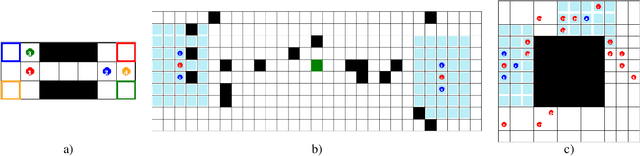
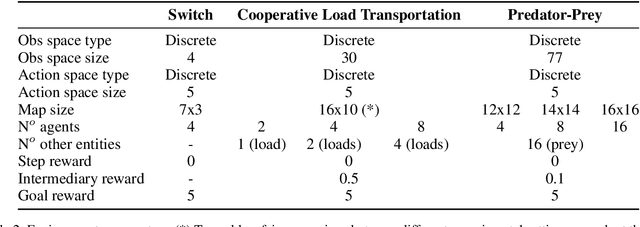
Robust coordination skills enable agents to operate cohesively in shared environments, together towards a common goal and, ideally, individually without hindering each other's progress. To this end, this paper presents Coordinated QMIX (CoMIX), a novel training framework for decentralized agents that enables emergent coordination through flexible policies, allowing at the same time independent decision-making at individual level. CoMIX models selfish and collaborative behavior as incremental steps in each agent's decision process. This allows agents to dynamically adapt their behavior to different situations balancing independence and collaboration. Experiments using a variety of simulation environments demonstrate that CoMIX outperforms baselines on collaborative tasks. The results validate our incremental policy approach as effective technique for improving coordination in multi-agent systems.
Forensic Histopathological Recognition via a Context-Aware MIL Network Powered by Self-Supervised Contrastive Learning
Aug 27, 2023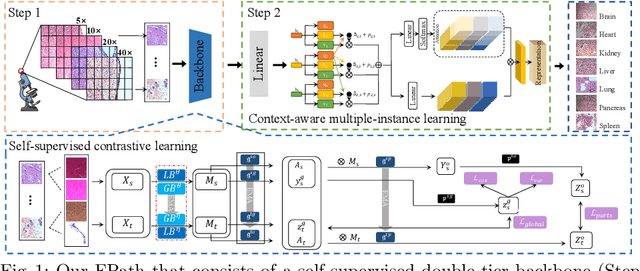
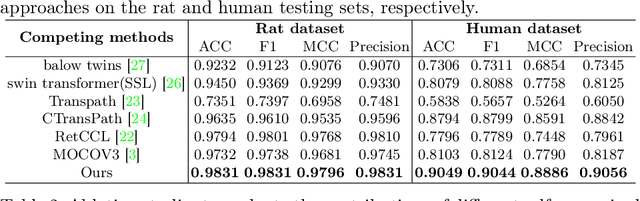
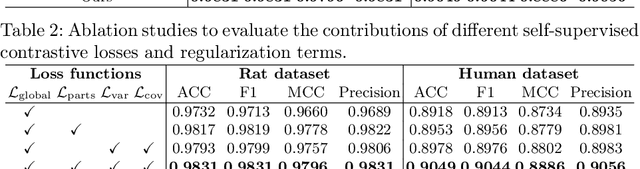
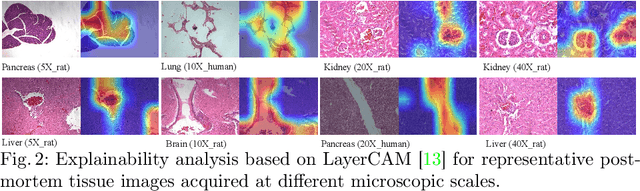
Forensic pathology is critical in analyzing death manner and time from the microscopic aspect to assist in the establishment of reliable factual bases for criminal investigation. In practice, even the manual differentiation between different postmortem organ tissues is challenging and relies on expertise, considering that changes like putrefaction and autolysis could significantly change typical histopathological appearance. Developing AI-based computational pathology techniques to assist forensic pathologists is practically meaningful, which requires reliable discriminative representation learning to capture tissues' fine-grained postmortem patterns. To this end, we propose a framework called FPath, in which a dedicated self-supervised contrastive learning strategy and a context-aware multiple-instance learning (MIL) block are designed to learn discriminative representations from postmortem histopathological images acquired at varying magnification scales. Our self-supervised learning step leverages multiple complementary contrastive losses and regularization terms to train a double-tier backbone for fine-grained and informative patch/instance embedding. Thereafter, the context-aware MIL adaptively distills from the local instances a holistic bag/image-level representation for the recognition task. On a large-scale database of $19,607$ experimental rat postmortem images and $3,378$ real-world human decedent images, our FPath led to state-of-the-art accuracy and promising cross-domain generalization in recognizing seven different postmortem tissues. The source code will be released on \href{https://github.com/ladderlab-xjtu/forensic_pathology}{https://github.com/ladderlab-xjtu/forensic\_pathology}.