 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unlocking the Performance of Proximity Sensors by Utilizing Transient Histograms
Aug 25, 2023
We provide methods which recover planar scene geometry by utilizing the transient histograms captured by a class of close-range time-of-flight (ToF) distance sensor. A transient histogram is a one dimensional temporal waveform which encodes the arrival time of photons incident on the ToF sensor. Typically, a sensor processes the transient histogram using a proprietary algorithm to produce distance estimates, which are commonly used in several robotics applications. Our methods utilize the transient histogram directly to enable recovery of planar geometry more accurately than is possible using only proprietary distance estimates, and consistent recovery of the albedo of the planar surface, which is not possible with proprietary distance estimates alone. This is accomplished via a differentiable rendering pipeline, which simulates the transient imaging process, allowing direct optimization of scene geometry to match observations. To validate our methods, we capture 3,800 measurements of eight planar surfaces from a wide range of viewpoints, and show that our method outperforms the proprietary-distance-estimate baseline by an order of magnitude in most scenarios. We demonstrate a simple robotics application which uses our method to sense the distance to and slope of a planar surface from a sensor mounted on the end effector of a robot arm.
SuperCalo: Calorimeter shower super-resolution
Aug 22, 2023
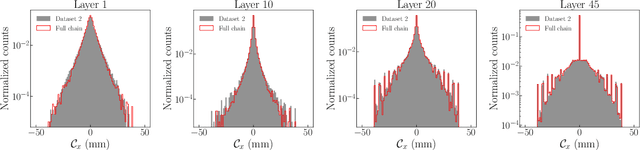
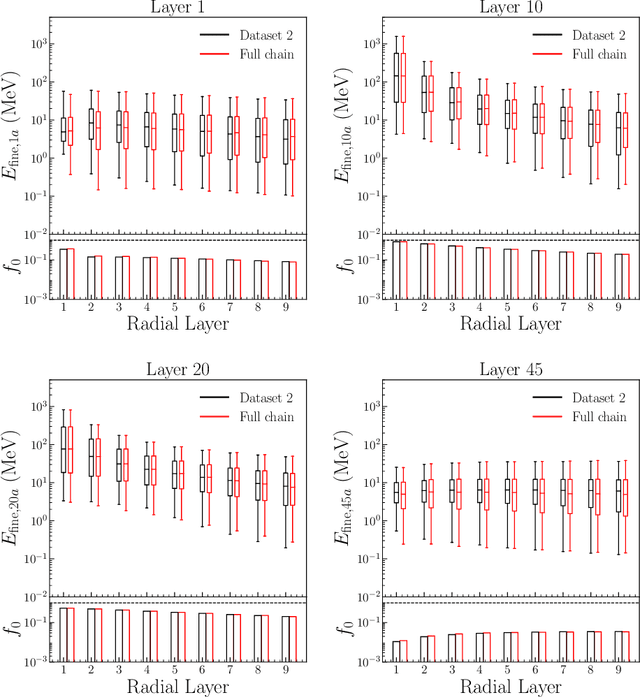
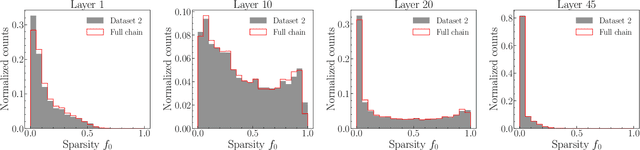
Calorimeter shower simulation is a major bottleneck in the Large Hadron Collider computational pipeline. There have been recent efforts to employ deep-generative surrogate models to overcome this challenge. However, many of best performing models have training and generation times that do not scale well to high-dimensional calorimeter showers. In this work, we introduce SuperCalo, a flow-based super-resolution model, and demonstrate that high-dimensional fine-grained calorimeter showers can be quickly upsampled from coarse-grained showers. This novel approach presents a way to reduce computational cost, memory requirements and generation time associated with fast calorimeter simulation models. Additionally, we show that the showers upsampled by SuperCalo possess a high degree of variation. This allows a large number of high-dimensional calorimeter showers to be upsampled from much fewer coarse showers with high-fidelity, which results in additional reduction in generation time.
VIO-DualProNet: Visual-Inertial Odometry with Learning Based Process Noise Covariance
Aug 22, 2023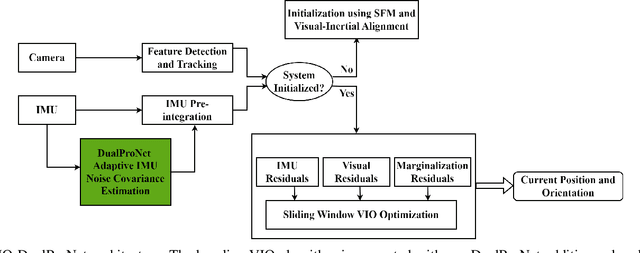
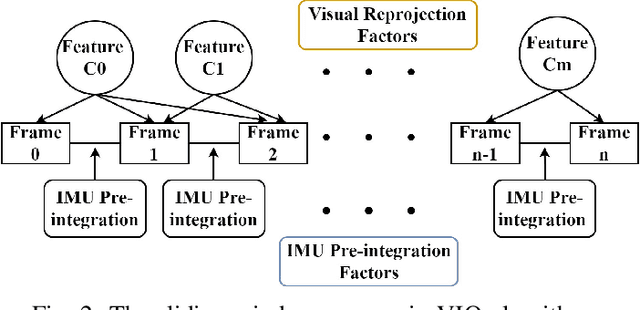

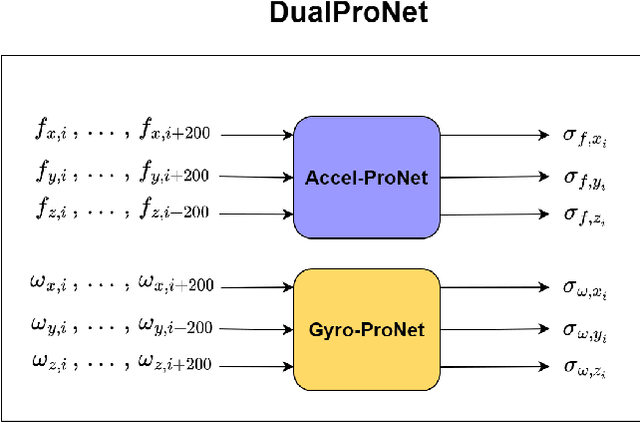
Visual-inertial odometry (VIO) is a vital technique used in robotics, augmented reality, and autonomous vehicles. It combines visual and inertial measurements to accurately estimate position and orientation. Existing VIO methods assume a fixed noise covariance for the inertial uncertainty. However, accurately determining in real-time the noise variance of the inertial sensors presents a significant challenge as the uncertainty changes throughout the operation leading to suboptimal performance and reduced accuracy. To circumvent this, we propose VIO-DualProNet, a novel approach that utilizes deep learning methods to dynamically estimate the inertial noise uncertainty in real-time. By designing and training a deep neural network to predict inertial noise uncertainty using only inertial sensor measurements, and integrating it into the VINS-Mono algorithm, we demonstrate a substantial improvement in accuracy and robustness, enhancing VIO performance and potentially benefiting other VIO-based systems for precise localization and mapping across diverse conditions.
Curating Naturally Adversarial Datasets for Trustworthy AI in Healthcare
Sep 01, 2023Deep learning models have shown promising predictive accuracy for time-series healthcare applications. However, ensuring the robustness of these models is vital for building trustworthy AI systems. Existing research predominantly focuses on robustness to synthetic adversarial examples, crafted by adding imperceptible perturbations to clean input data. However, these synthetic adversarial examples do not accurately reflect the most challenging real-world scenarios, especially in the context of healthcare data. Consequently, robustness to synthetic adversarial examples may not necessarily translate to robustness against naturally occurring adversarial examples, which is highly desirable for trustworthy AI. We propose a method to curate datasets comprised of natural adversarial examples to evaluate model robustness. The method relies on probabilistic labels obtained from automated weakly-supervised labeling that combines noisy and cheap-to-obtain labeling heuristics. Based on these labels, our method adversarially orders the input data and uses this ordering to construct a sequence of increasingly adversarial datasets. Our evaluation on six medical case studies and three non-medical case studies demonstrates the efficacy and statistical validity of our approach to generating naturally adversarial datasets
Satisfiability Checking of Multi-Variable TPTL with Unilateral Intervals Is PSPACE-Complete
Sep 01, 2023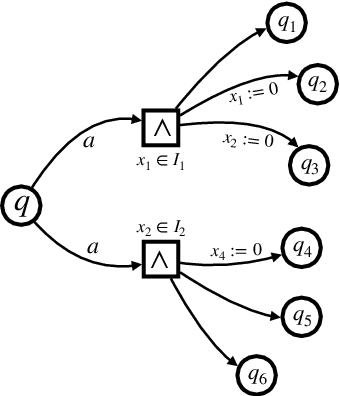
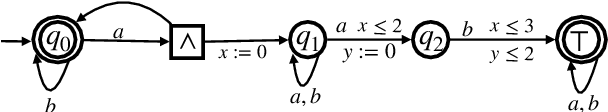

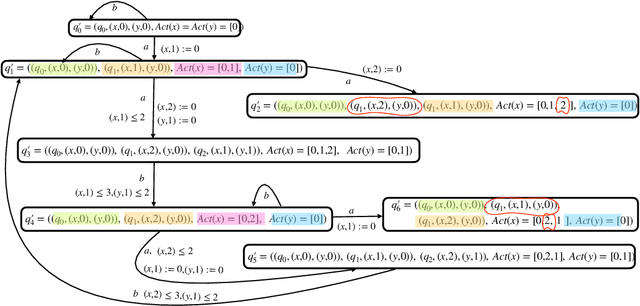
We investigate the decidability of the ${0,\infty}$ fragment of Timed Propositional Temporal Logic (TPTL). We show that the satisfiability checking of TPTL$^{0,\infty}$ is PSPACE-complete. Moreover, even its 1-variable fragment (1-TPTL$^{0,\infty}$) is strictly more expressive than Metric Interval Temporal Logic (MITL) for which satisfiability checking is EXPSPACE complete. Hence, we have a strictly more expressive logic with computationally easier satisfiability checking. To the best of our knowledge, TPTL$^{0,\infty}$ is the first multi-variable fragment of TPTL for which satisfiability checking is decidable without imposing any bounds/restrictions on the timed words (e.g. bounded variability, bounded time, etc.). The membership in PSPACE is obtained by a reduction to the emptiness checking problem for a new "non-punctual" subclass of Alternating Timed Automata with multiple clocks called Unilateral Very Weak Alternating Timed Automata (VWATA$^{0,\infty}$) which we prove to be in PSPACE. We show this by constructing a simulation equivalent non-deterministic timed automata whose number of clocks is polynomial in the size of the given VWATA$^{0,\infty}$.
Growing Fast without Colliding: Polylogarithmic Time Step Construction of Geometric Shapes
Jul 10, 2023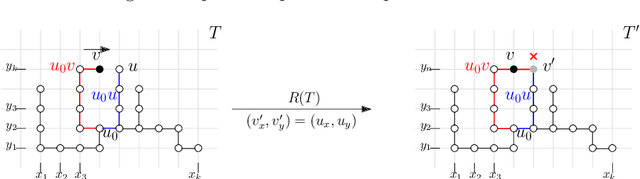
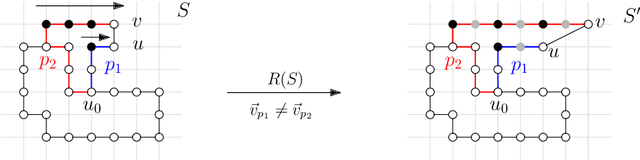
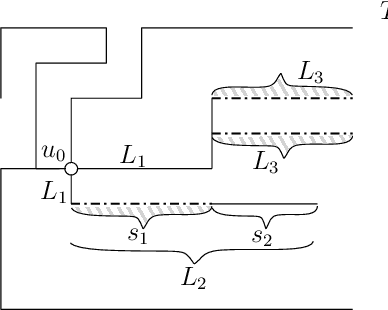
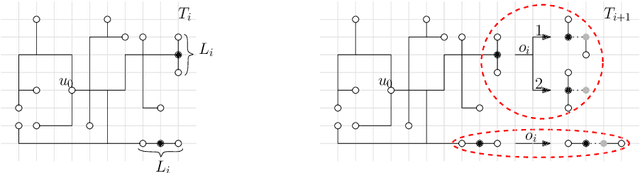
Building on two recent models of [Almalki and Michail, 2022] and [Gupta et al., 2023], we explore the constructive power of a set of geometric growth processes. The studied processes, by applying a sequence of centralized, parallel, and linear-strength growth operations, can construct shapes from smaller shapes or from a singleton exponentially fast. A technical challenge in growing shapes that fast is the need to avoid collisions caused, for example, when the shape breaks, stretches, or self-intersects. We distinguish two types of growth operations -- one that avoids collisions by preserving cycles and one that achieves the same by breaking them -- and two types of graph models. We study the following types of shape reachability questions in these models. Given a class of initial shapes $\mathcal{I}$ and a class of final shapes $\mathcal{F}$, our objective is to determine whether any (some) shape $S \in \mathcal{F}$ can be reached from any shape $S_0 \in \mathcal{I}$ in a number of time steps which is (poly)logarithmic in the size of $S$. For the reachable classes, we additionally present the respective growth processes. In cycle-preserving growth, we study these problems in basic classes of shapes such as paths, spirals, and trees and reveal the importance of the number of turning points as a parameter. We give both positive and negative results. For cycle-breaking growth, we obtain a strong positive result -- a general growth process that can grow any connected shape from a singleton fast.
Leveraging Self-Supervised Vision Transformers for Neural Transfer Function Design
Sep 04, 2023In volume rendering, transfer functions are used to classify structures of interest, and to assign optical properties such as color and opacity. They are commonly defined as 1D or 2D functions that map simple features to these optical properties. As the process of designing a transfer function is typically tedious and unintuitive, several approaches have been proposed for their interactive specification. In this paper, we present a novel method to define transfer functions for volume rendering by leveraging the feature extraction capabilities of self-supervised pre-trained vision transformers. To design a transfer function, users simply select the structures of interest in a slice viewer, and our method automatically selects similar structures based on the high-level features extracted by the neural network. Contrary to previous learning-based transfer function approaches, our method does not require training of models and allows for quick inference, enabling an interactive exploration of the volume data. Our approach reduces the amount of necessary annotations by interactively informing the user about the current classification, so they can focus on annotating the structures of interest that still require annotation. In practice, this allows users to design transfer functions within seconds, instead of minutes. We compare our method to existing learning-based approaches in terms of annotation and compute time, as well as with respect to segmentation accuracy. Our accompanying video showcases the interactivity and effectiveness of our method.
Secure and Efficient Federated Learning in LEO Constellations using Decentralized Key Generation and On-Orbit Model Aggregation
Sep 04, 2023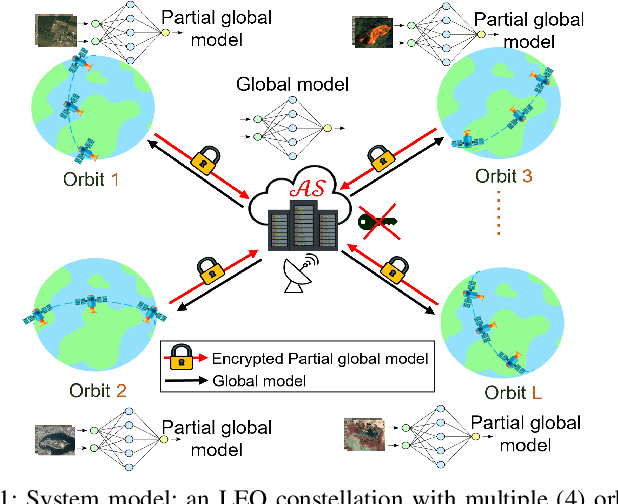
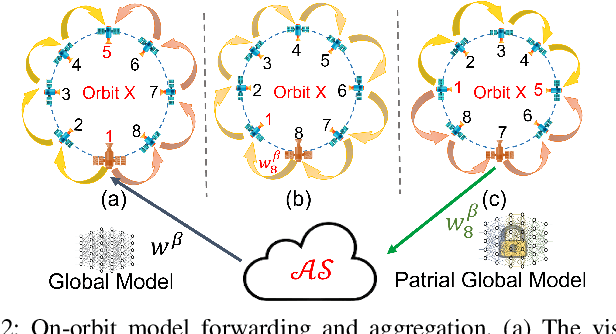
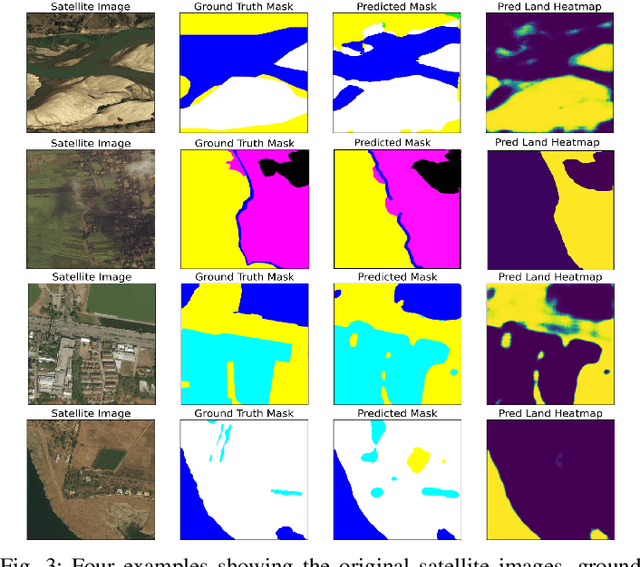

Satellite technologies have advanced drastically in recent years, leading to a heated interest in launching small satellites into low Earth orbit (LEOs) to collect massive data such as satellite imagery. Downloading these data to a ground station (GS) to perform centralized learning to build an AI model is not practical due to the limited and expensive bandwidth. Federated learning (FL) offers a potential solution but will incur a very large convergence delay due to the highly sporadic and irregular connectivity between LEO satellites and GS. In addition, there are significant security and privacy risks where eavesdroppers or curious servers/satellites may infer raw data from satellites' model parameters transmitted over insecure communication channels. To address these issues, this paper proposes FedSecure, a secure FL approach designed for LEO constellations, which consists of two novel components: (1) decentralized key generation that protects satellite data privacy using a functional encryption scheme, and (2) on-orbit model forwarding and aggregation that generates a partial global model per orbit to minimize the idle waiting time for invisible satellites to enter the visible zone of the GS. Our analysis and results show that FedSecure preserves the privacy of each satellite's data against eavesdroppers, a curious server, or curious satellites. It is lightweight with significantly lower communication and computation overheads than other privacy-preserving FL aggregation approaches. It also reduces convergence delay drastically from days to only a few hours, yet achieving high accuracy of up to 85.35% using realistic satellite images.
Computation and Communication Efficient Federated Learning over Wireless Networks
Sep 04, 2023Federated learning (FL) allows model training from local data by edge devices while preserving data privacy. However, the learning accuracy decreases due to the heterogeneity of devices data, and the computation and communication latency increase when updating large scale learning models on devices with limited computational capability and wireless resources. To overcome these challenges, we consider a novel FL framework with partial model pruning and personalization. This framework splits the learning model into a global part with model pruning shared with all devices to learn data representations and a personalized part to be fine tuned for a specific device, which adapts the model size during FL to reduce both computation and communication overhead and minimize the overall training time, and increases the learning accuracy for the device with non independent and identically distributed (non IID) data. Then, the computation and communication latency and the convergence analysis of the proposed FL framework are mathematically analyzed. Based on the convergence analysis, an optimization problem is formulated to maximize the convergence rate under a latency threshold by jointly optimizing the pruning ratio and wireless resource allocation. By decoupling the optimization problem and deploying Karush Kuhn Tucker (KKT) conditions, we derive the closed form solutions of pruning ratio and wireless resource allocation. Finally, experimental results demonstrate that the proposed FL framework achieves a remarkable reduction of approximately 50 percents computation and communication latency compared with the scheme only with model personalization.
High Frequency, High Accuracy Pointing onboard Nanosats using Neuromorphic Event Sensing and Piezoelectric Actuation
Sep 04, 2023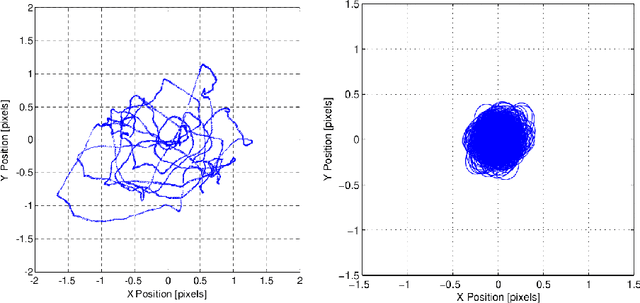
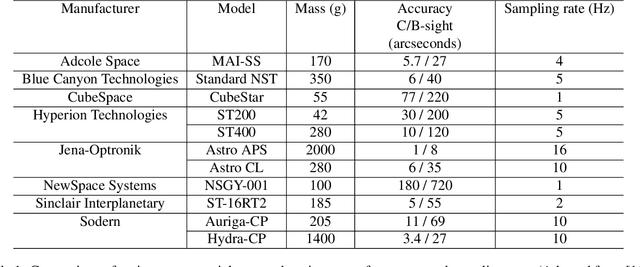
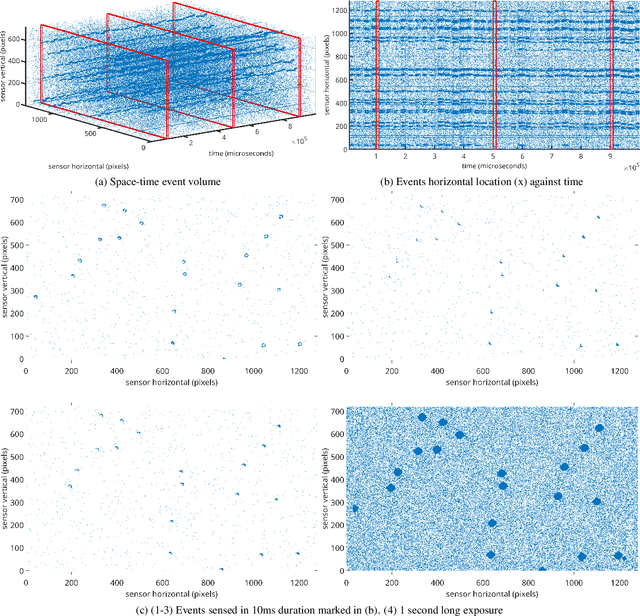

As satellites become smaller, the ability to maintain stable pointing decreases as external forces acting on the satellite come into play. At the same time, reaction wheels used in the attitude determination and control system (ADCS) introduce high frequency jitter which can disrupt pointing stability. For space domain awareness (SDA) tasks that track objects tens of thousands of kilometres away, the pointing accuracy offered by current nanosats, typically in the range of 10 to 100 arcseconds, is not sufficient. In this work, we develop a novel payload that utilises a neuromorphic event sensor (for high frequency and highly accurate relative attitude estimation) paired in a closed loop with a piezoelectric stage (for active attitude corrections) to provide highly stable sensor-specific pointing. Event sensors are especially suited for space applications due to their desirable characteristics of low power consumption, asynchronous operation, and high dynamic range. We use the event sensor to first estimate a reference background star field from which instantaneous relative attitude is estimated at high frequency. The piezoelectric stage works in a closed control loop with the event sensor to perform attitude corrections based on the discrepancy between the current and desired attitude. Results in a controlled setting show that we can achieve a pointing accuracy in the range of 1-5 arcseconds using our novel payload at an operating frequency of up to 50Hz using a prototype built from commercial-off-the-shelf components. Further details can be found at https://ylatif.github.io/ultrafinestabilisation