 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Sep 04, 2023

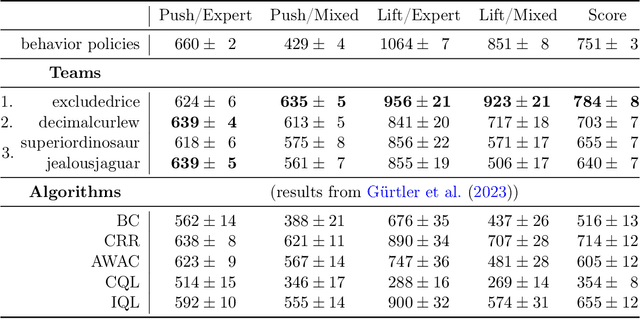
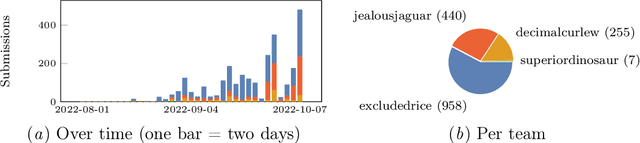
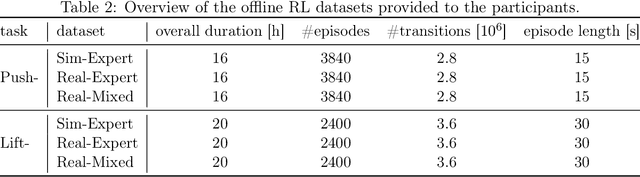
Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
Prompting or Fine-tuning? A Comparative Study of Large Language Models for Taxonomy Construction
Sep 04, 2023Taxonomies represent hierarchical relations between entities, frequently applied in various software modeling and natural language processing (NLP) activities. They are typically subject to a set of structural constraints restricting their content. However, manual taxonomy construction can be time-consuming, incomplete, and costly to maintain. Recent studies of large language models (LLMs) have demonstrated that appropriate user inputs (called prompting) can effectively guide LLMs, such as GPT-3, in diverse NLP tasks without explicit (re-)training. However, existing approaches for automated taxonomy construction typically involve fine-tuning a language model by adjusting model parameters. In this paper, we present a general framework for taxonomy construction that takes into account structural constraints. We subsequently conduct a systematic comparison between the prompting and fine-tuning approaches performed on a hypernym taxonomy and a novel computer science taxonomy dataset. Our result reveals the following: (1) Even without explicit training on the dataset, the prompting approach outperforms fine-tuning-based approaches. Moreover, the performance gap between prompting and fine-tuning widens when the training dataset is small. However, (2) taxonomies generated by the fine-tuning approach can be easily post-processed to satisfy all the constraints, whereas handling violations of the taxonomies produced by the prompting approach can be challenging. These evaluation findings provide guidance on selecting the appropriate method for taxonomy construction and highlight potential enhancements for both approaches.
Accuracy and Consistency of Space-based Vegetation Height Maps for Forest Dynamics in Alpine Terrain
Sep 04, 2023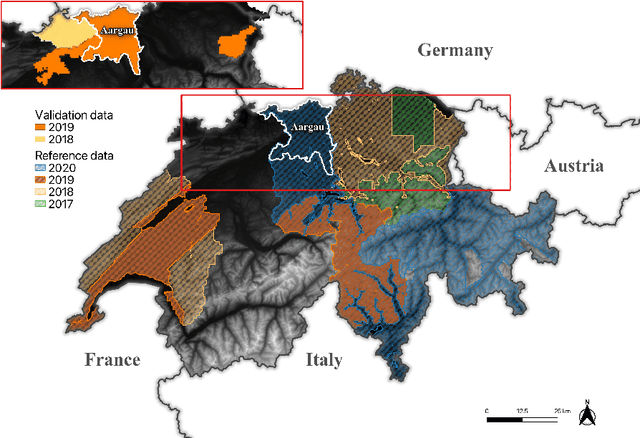
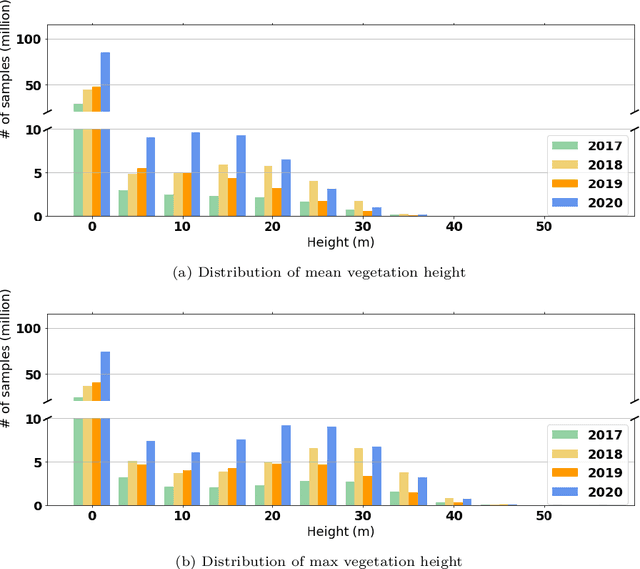

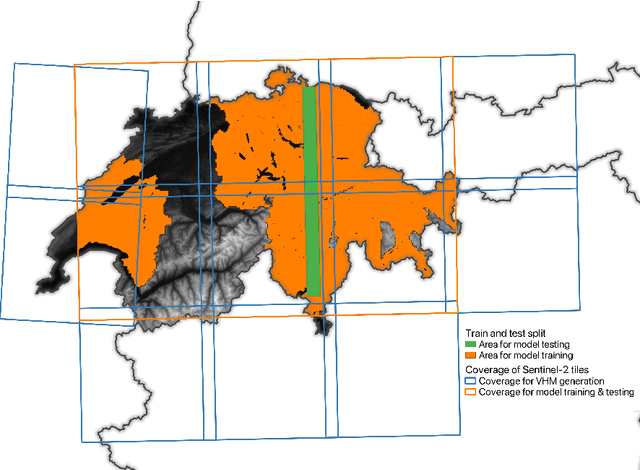
Monitoring and understanding forest dynamics is essential for environmental conservation and management. This is why the Swiss National Forest Inventory (NFI) provides countrywide vegetation height maps at a spatial resolution of 0.5 m. Its long update time of 6 years, however, limits the temporal analysis of forest dynamics. This can be improved by using spaceborne remote sensing and deep learning to generate large-scale vegetation height maps in a cost-effective way. In this paper, we present an in-depth analysis of these methods for operational application in Switzerland. We generate annual, countrywide vegetation height maps at a 10-meter ground sampling distance for the years 2017 to 2020 based on Sentinel-2 satellite imagery. In comparison to previous works, we conduct a large-scale and detailed stratified analysis against a precise Airborne Laser Scanning reference dataset. This stratified analysis reveals a close relationship between the model accuracy and the topology, especially slope and aspect. We assess the potential of deep learning-derived height maps for change detection and find that these maps can indicate changes as small as 250 $m^2$. Larger-scale changes caused by a winter storm are detected with an F1-score of 0.77. Our results demonstrate that vegetation height maps computed from satellite imagery with deep learning are a valuable, complementary, cost-effective source of evidence to increase the temporal resolution for national forest assessments.
SSVOD: Semi-Supervised Video Object Detection with Sparse Annotations
Sep 04, 2023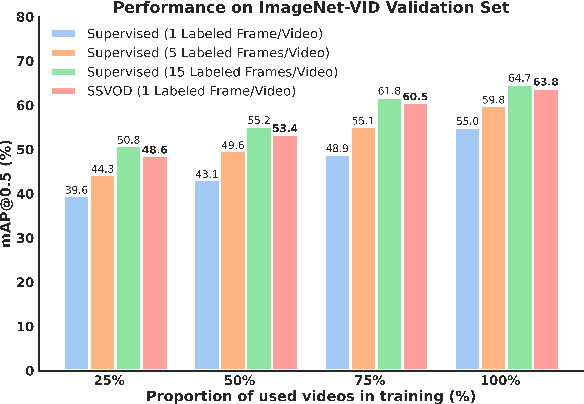
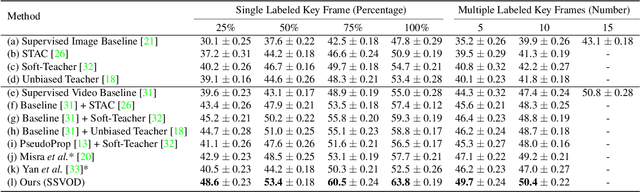
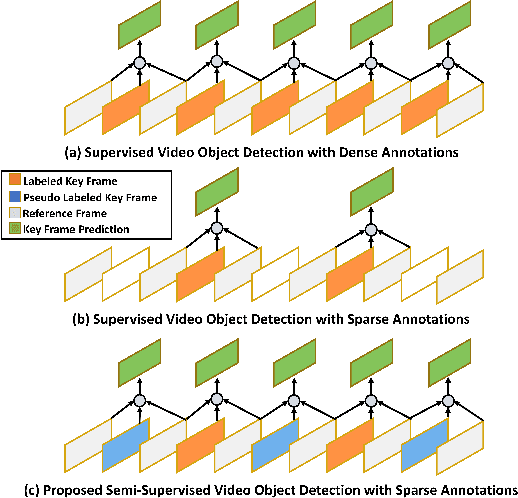
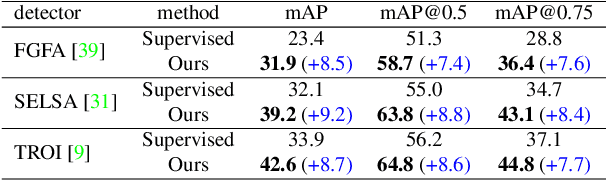
Despite significant progress in semi-supervised learning for image object detection, several key issues are yet to be addressed for video object detection: (1) Achieving good performance for supervised video object detection greatly depends on the availability of annotated frames. (2) Despite having large inter-frame correlations in a video, collecting annotations for a large number of frames per video is expensive, time-consuming, and often redundant. (3) Existing semi-supervised techniques on static images can hardly exploit the temporal motion dynamics inherently present in videos. In this paper, we introduce SSVOD, an end-to-end semi-supervised video object detection framework that exploits motion dynamics of videos to utilize large-scale unlabeled frames with sparse annotations. To selectively assemble robust pseudo-labels across groups of frames, we introduce \textit{flow-warped predictions} from nearby frames for temporal-consistency estimation. In particular, we introduce cross-IoU and cross-divergence based selection methods over a set of estimated predictions to include robust pseudo-labels for bounding boxes and class labels, respectively. To strike a balance between confirmation bias and uncertainty noise in pseudo-labels, we propose confidence threshold based combination of hard and soft pseudo-labels. Our method achieves significant performance improvements over existing methods on ImageNet-VID, Epic-KITCHENS, and YouTube-VIS datasets. Code and pre-trained models will be released.
Learning Perturbations to Explain Time Series Predictions
May 30, 2023Explaining predictions based on multivariate time series data carries the additional difficulty of handling not only multiple features, but also time dependencies. It matters not only what happened, but also when, and the same feature could have a very different impact on a prediction depending on this time information. Previous work has used perturbation-based saliency methods to tackle this issue, perturbing an input using a trainable mask to discover which features at which times are driving the predictions. However these methods introduce fixed perturbations, inspired from similar methods on static data, while there seems to be little motivation to do so on temporal data. In this work, we aim to explain predictions by learning not only masks, but also associated perturbations. We empirically show that learning these perturbations significantly improves the quality of these explanations on time series data.
Domain Adaptive Synapse Detection with Weak Point Annotations
Aug 31, 2023The development of learning-based methods has greatly improved the detection of synapses from electron microscopy (EM) images. However, training a model for each dataset is time-consuming and requires extensive annotations. Additionally, it is difficult to apply a learned model to data from different brain regions due to variations in data distributions. In this paper, we present AdaSyn, a two-stage segmentation-based framework for domain adaptive synapse detection with weak point annotations. In the first stage, we address the detection problem by utilizing a segmentation-based pipeline to obtain synaptic instance masks. In the second stage, we improve model generalizability on target data by regenerating square masks to get high-quality pseudo labels. Benefiting from our high-accuracy detection results, we introduce the distance nearest principle to match paired pre-synapses and post-synapses. In the WASPSYN challenge at ISBI 2023, our method ranks the 1st place.
RoboTAP: Tracking Arbitrary Points for Few-Shot Visual Imitation
Aug 31, 2023
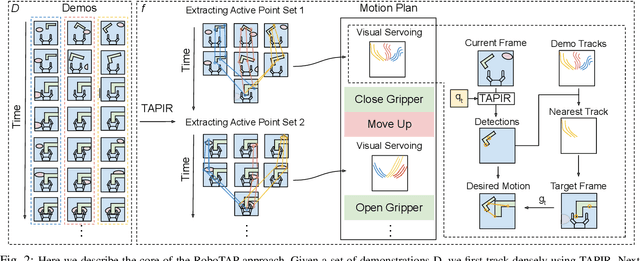


For robots to be useful outside labs and specialized factories we need a way to teach them new useful behaviors quickly. Current approaches lack either the generality to onboard new tasks without task-specific engineering, or else lack the data-efficiency to do so in an amount of time that enables practical use. In this work we explore dense tracking as a representational vehicle to allow faster and more general learning from demonstration. Our approach utilizes Track-Any-Point (TAP) models to isolate the relevant motion in a demonstration, and parameterize a low-level controller to reproduce this motion across changes in the scene configuration. We show this results in robust robot policies that can solve complex object-arrangement tasks such as shape-matching, stacking, and even full path-following tasks such as applying glue and sticking objects together, all from demonstrations that can be collected in minutes.
Higher-order Motif-based Time Series Classification for Forced Oscillation Source Location in Power Grids
Jun 23, 2023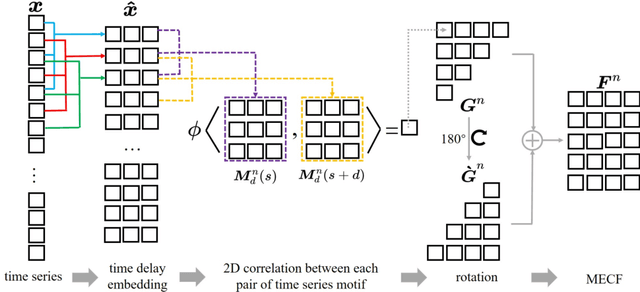
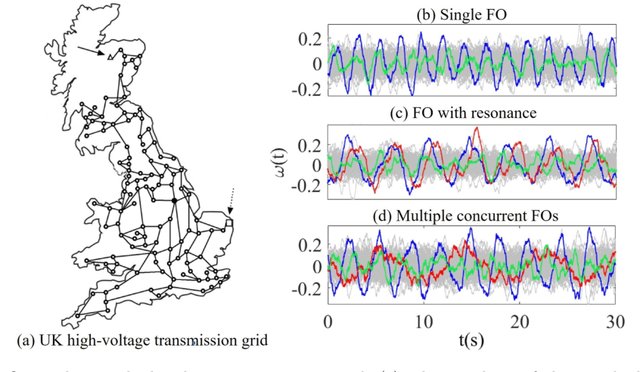
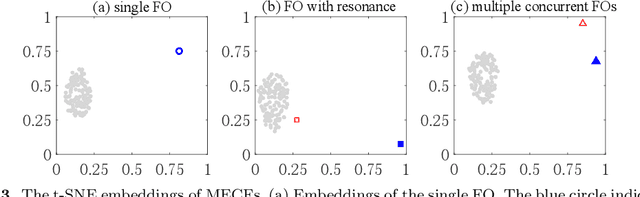
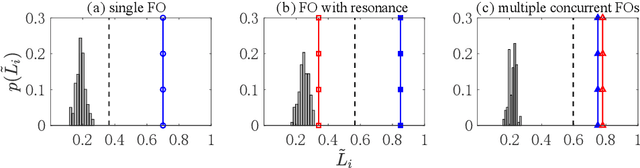
Time series motifs are used for discovering higher-order structures of time series data. Based on time series motifs, the motif embedding correlation field (MECF) is proposed to characterize higher-order temporal structures of dynamical system time series. A MECF-based unsupervised learning approach is applied in locating the source of the forced oscillation (FO), a periodic disturbance that detrimentally impacts power grids. Locating the FO source is imperative for system stability. Compared with the Fourier analysis, the MECF-based unsupervised learning is applicable under various FO situations, including the single FO, FO with resonance, and multiple sources FOs. The MECF-based unsupervised learning is a data-driven approach without any prior knowledge requirement of system models or typologies. Tests on the UK high-voltage transmission grid illustrate the effectiveness of MECF-based unsupervised learning. In addition, the impacts of coupling strength and measurement noise on locating the FO source by the MECF-based unsupervised learning are investigated.
Time-Frequency-Space Transmit Design and Signal Processing with Dynamic Subarray for Terahertz Integrated Sensing and Communication
Jul 10, 2023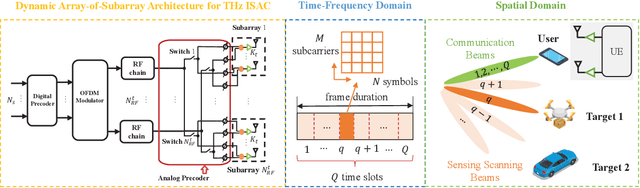
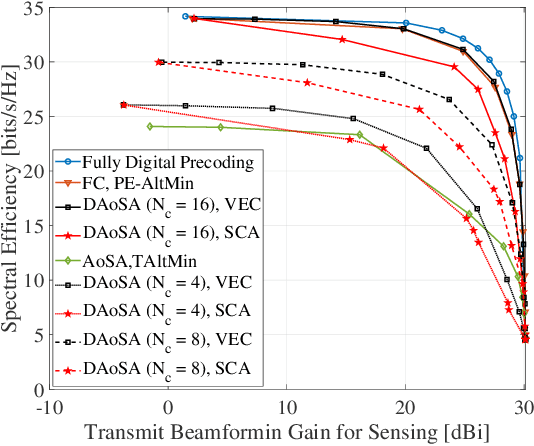
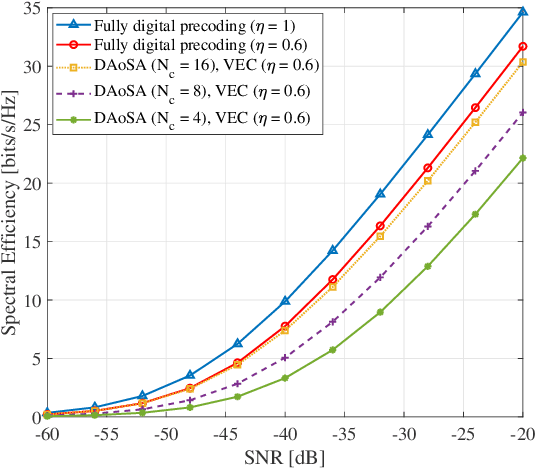
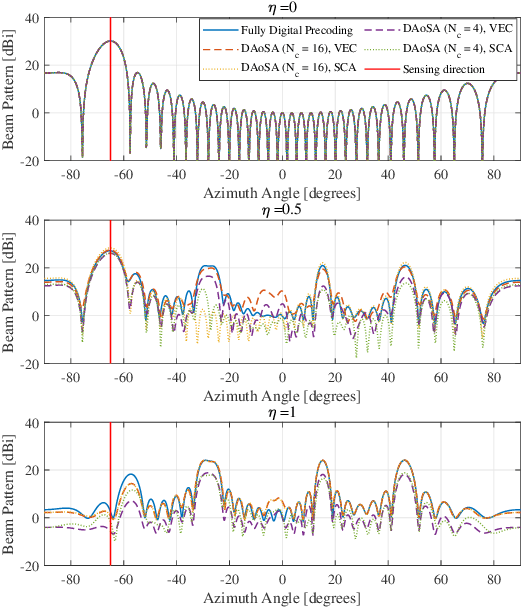
Terahertz (THz) integrated sensing and communication (ISAC) enables simultaneous data transmission with Terabit-per-second (Tbps) rate and millimeter-level accurate sensing. To realize such a blueprint, ultra-massive antenna arrays with directional beamforming are used to compensate for severe path loss in the THz band. In this paper, the time-frequency-space transmit design is investigated for THz ISAC to generate time-varying scanning sensing beams and stable communication beams. Specifically, with the dynamic array-of-subarray (DAoSA) hybrid beamforming architecture and multi-carrier modulation, two ISAC hybrid precoding algorithms are proposed, namely, a vectorization (VEC) based algorithm that outperforms existing ISAC hybrid precoding methods and a low-complexity sensing codebook assisted (SCA) approach. Meanwhile, coupled with the transmit design, parameter estimation algorithms are proposed to realize high-accuracy sensing, including a wideband DAoSA MUSIC (W-DAoSA-MUSIC) method for angle estimation and a sum-DFT-GSS (S-DFT-GSS) approach for range and velocity estimation. Numerical results indicate that the proposed algorithms can realize centi-degree-level angle estimation accuracy and millimeter-level range estimation accuracy, which are one or two orders of magnitudes better than the methods in the millimeter-wave band. In addition, to overcome the cyclic prefix limitation and Doppler effects in the THz band, an inter-symbol interference- and inter-carrier interference-tackled sensing algorithm is developed to refine sensing capabilities for THz ISAC.
Compositional nonlinear audio signal processing with Volterra series
Aug 23, 2023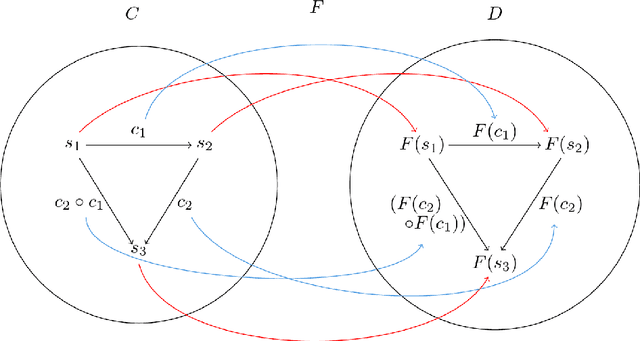
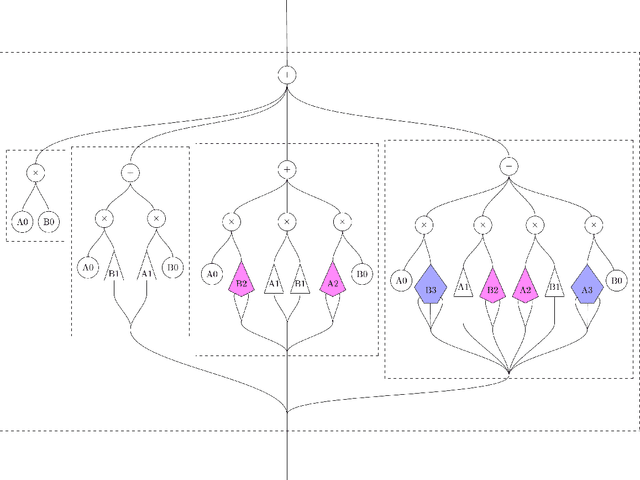
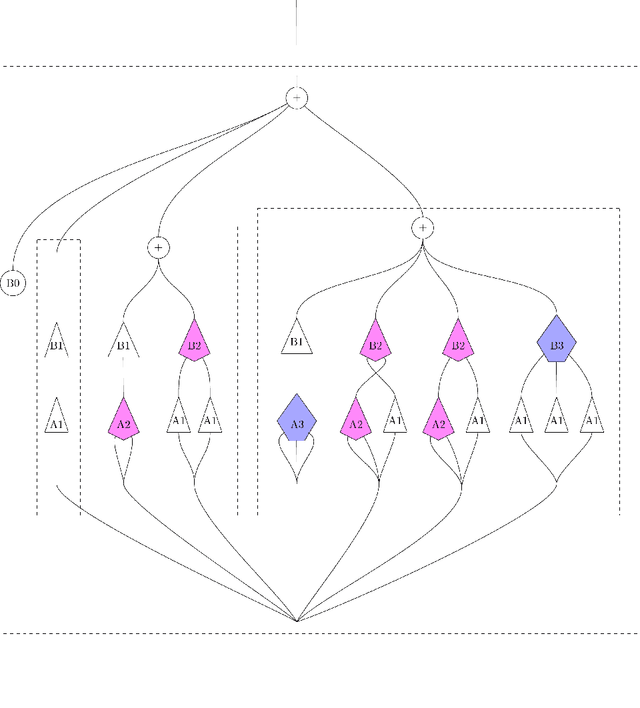
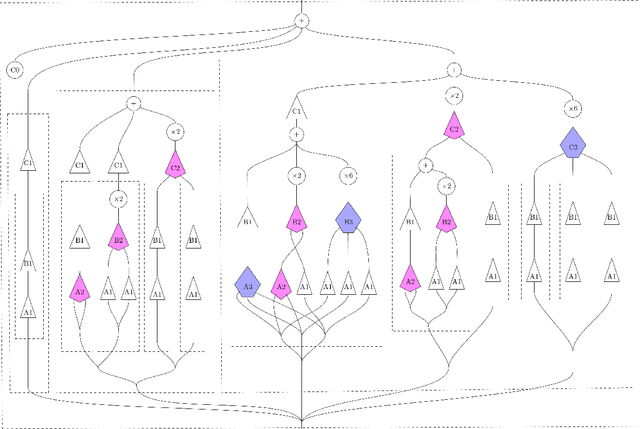
We develop a compositional theory of nonlinear audio signal processing based on a categorification of the Volterra series. We begin by considering what it would mean for the Volterra series to be functorial with respect to a base category whose objects are temperate distributions and whose morphisms are certain linear transformations. This leads to formulae describing how the outcomes of nonlinear transformations are affected if their input signals are first linearly processed. We then consider how nonlinear audio systems change, and introduce as a model thereof a notion of morphism of Volterra series, which we exhibit as a kind of lens map. We show how morphisms can be parameterized and used to generate indexed families of Volterra series, which are well-suited to model nonstationary or time-varying nonlinear phenomena. We then describe how Volterra series and their morphisms organize into a category, which we call Volt. We exhibit the operations of sum, product, and series composition of Volterra series as monoidal products on Volt and identify, for each in turn, its corresponding universal property. We show, in particular, that the series composition of Volterra series is associative. We then bridge between our framework and a subject at the heart of audio signal processing: time-frequency analysis. Specifically, we show that an equivalence between a certain class of second-order Volterra series and the bilinear time-frequency distributions (TFDs) can be extended to one between certain higher-order Volterra series and the so-called polynomial TFDs. We end with prospects for future work, including the incorporation of nonlinear system identification techniques and the extension of our theory to the settings of compositional graph and topological audio signal processing.