 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Re-Parameterized Vision Transformer (ReVT) for Domain-Generalized Semantic Segmentation
Aug 25, 2023
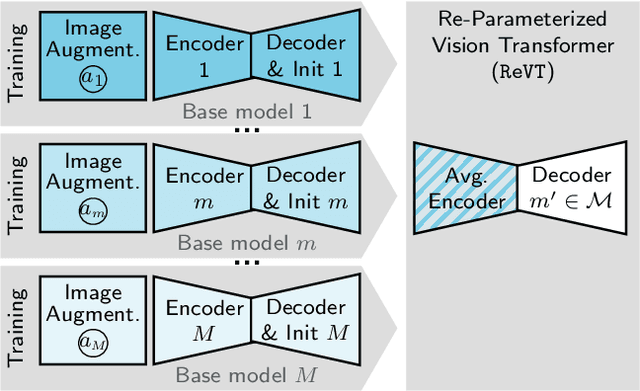
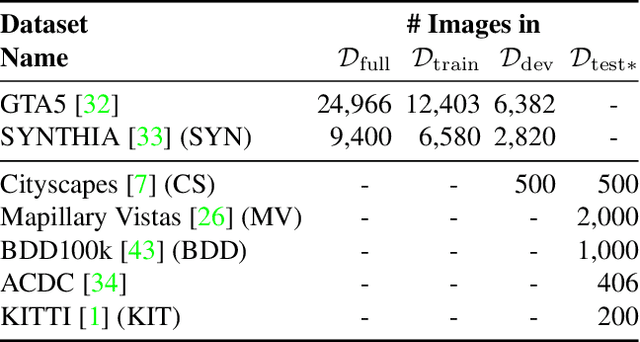
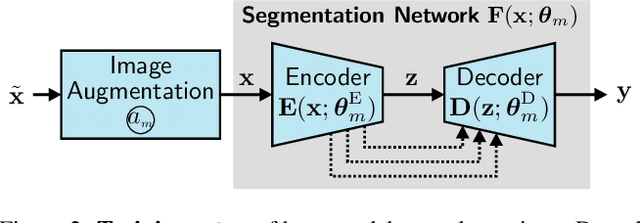

The task of semantic segmentation requires a model to assign semantic labels to each pixel of an image. However, the performance of such models degrades when deployed in an unseen domain with different data distributions compared to the training domain. We present a new augmentation-driven approach to domain generalization for semantic segmentation using a re-parameterized vision transformer (ReVT) with weight averaging of multiple models after training. We evaluate our approach on several benchmark datasets and achieve state-of-the-art mIoU performance of 47.3% (prior art: 46.3%) for small models and of 50.1% (prior art: 47.8%) for midsized models on commonly used benchmark datasets. At the same time, our method requires fewer parameters and reaches a higher frame rate than the best prior art. It is also easy to implement and, unlike network ensembles, does not add any computational complexity during inference.
Eventful Transformers: Leveraging Temporal Redundancy in Vision Transformers
Aug 25, 2023Vision Transformers achieve impressive accuracy across a range of visual recognition tasks. Unfortunately, their accuracy frequently comes with high computational costs. This is a particular issue in video recognition, where models are often applied repeatedly across frames or temporal chunks. In this work, we exploit temporal redundancy between subsequent inputs to reduce the cost of Transformers for video processing. We describe a method for identifying and re-processing only those tokens that have changed significantly over time. Our proposed family of models, Eventful Transformers, can be converted from existing Transformers (often without any re-training) and give adaptive control over the compute cost at runtime. We evaluate our method on large-scale datasets for video object detection (ImageNet VID) and action recognition (EPIC-Kitchens 100). Our approach leads to significant computational savings (on the order of 2-4x) with only minor reductions in accuracy.
Meta Attentive Graph Convolutional Recurrent Network for Traffic Forecasting
Aug 28, 2023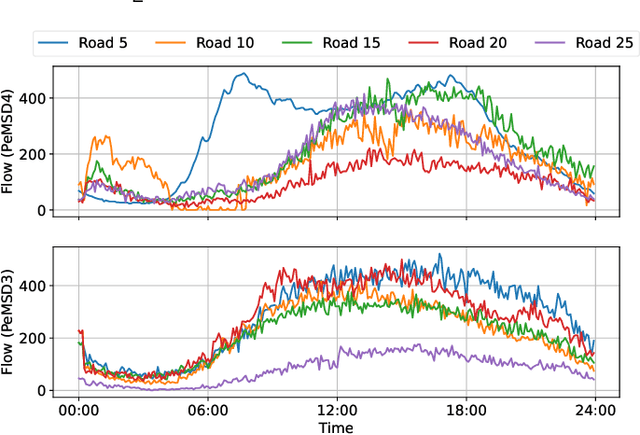

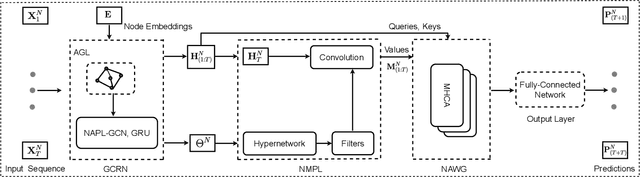

Traffic forecasting is a fundamental problem in intelligent transportation systems. Existing traffic predictors are limited by their expressive power to model the complex spatial-temporal dependencies in traffic data, mainly due to the following limitations. Firstly, most approaches are primarily designed to model the local shared patterns, which makes them insufficient to capture the specific patterns associated with each node globally. Hence, they fail to learn each node's unique properties and diversified patterns. Secondly, most existing approaches struggle to accurately model both short- and long-term dependencies simultaneously. In this paper, we propose a novel traffic predictor, named Meta Attentive Graph Convolutional Recurrent Network (MAGCRN). MAGCRN utilizes a Graph Convolutional Recurrent Network (GCRN) as a core module to model local dependencies and improves its operation with two novel modules: 1) a Node-Specific Meta Pattern Learning (NMPL) module to capture node-specific patterns globally and 2) a Node Attention Weight Generation Module (NAWG) module to capture short- and long-term dependencies by connecting the node-specific features with the ones learned initially at each time step during GCRN operation. Experiments on six real-world traffic datasets demonstrate that NMPL and NAWG together enable MAGCRN to outperform state-of-the-art baselines on both short- and long-term predictions.
Auto-Prompting SAM for Mobile Friendly 3D Medical Image Segmentation
Aug 28, 2023The Segment Anything Model (SAM) has rapidly been adopted for segmenting a wide range of natural images. However, recent studies have indicated that SAM exhibits subpar performance on 3D medical image segmentation tasks. In addition to the domain gaps between natural and medical images, disparities in the spatial arrangement between 2D and 3D images, the substantial computational burden imposed by powerful GPU servers, and the time-consuming manual prompt generation impede the extension of SAM to a broader spectrum of medical image segmentation applications. To address these challenges, in this work, we introduce a novel method, AutoSAM Adapter, designed specifically for 3D multi-organ CT-based segmentation. We employ parameter-efficient adaptation techniques in developing an automatic prompt learning paradigm to facilitate the transformation of the SAM model's capabilities to 3D medical image segmentation, eliminating the need for manually generated prompts. Furthermore, we effectively transfer the acquired knowledge of the AutoSAM Adapter to other lightweight models specifically tailored for 3D medical image analysis, achieving state-of-the-art (SOTA) performance on medical image segmentation tasks. Through extensive experimental evaluation, we demonstrate the AutoSAM Adapter as a critical foundation for effectively leveraging the emerging ability of foundation models in 2D natural image segmentation for 3D medical image segmentation.
Evaluation of Key Spatiotemporal Learners for Print Track Anomaly Classification Using Melt Pool Image Streams
Aug 28, 2023


Recent applications of machine learning in metal additive manufacturing (MAM) have demonstrated significant potential in addressing critical barriers to the widespread adoption of MAM technology. Recent research in this field emphasizes the importance of utilizing melt pool signatures for real-time defect prediction. While high-quality melt pool image data holds the promise of enabling precise predictions, there has been limited exploration into the utilization of cutting-edge spatiotemporal models that can harness the inherent transient and sequential characteristics of the additive manufacturing process. This research introduces and puts into practice some of the leading deep spatiotemporal learning models that can be adapted for the classification of melt pool image streams originating from various materials, systems, and applications. Specifically, it investigates two-stream networks comprising spatial and temporal streams, a recurrent spatial network, and a factorized 3D convolutional neural network. The capacity of these models to generalize when exposed to perturbations in melt pool image data is examined using data perturbation techniques grounded in real-world process scenarios. The implemented architectures demonstrate the ability to capture the spatiotemporal features of melt pool image sequences. However, among these models, only the Kinetics400 pre-trained SlowFast network, categorized as a two-stream network, exhibits robust generalization capabilities in the presence of data perturbations.
Karma: Adaptive Video Streaming via Causal Sequence Modeling
Aug 20, 2023Optimal adaptive bitrate (ABR) decision depends on a comprehensive characterization of state transitions that involve interrelated modalities over time including environmental observations, returns, and actions. However, state-of-the-art learning-based ABR algorithms solely rely on past observations to decide the next action. This paradigm tends to cause a chain of deviations from optimal action when encountering unfamiliar observations, which consequently undermines the model generalization. This paper presents Karma, an ABR algorithm that utilizes causal sequence modeling to improve generalization by comprehending the interrelated causality among past observations, returns, and actions and timely refining action when deviation occurs. Unlike direct observation-to-action mapping, Karma recurrently maintains a multi-dimensional time series of observations, returns, and actions as input and employs causal sequence modeling via a decision transformer to determine the next action. In the input sequence, Karma uses the maximum cumulative future quality of experience (QoE) (a.k.a, QoE-to-go) as an extended return signal, which is periodically estimated based on current network conditions and playback status. We evaluate Karma through trace-driven simulations and real-world field tests, demonstrating superior performance compared to existing state-of-the-art ABR algorithms, with an average QoE improvement ranging from 10.8% to 18.7% across diverse network conditions. Furthermore, Karma exhibits strong generalization capabilities, showing leading performance under unseen networks in both simulations and real-world tests.
Vision-Based Intelligent Robot Grasping Using Sparse Neural Network
Aug 22, 2023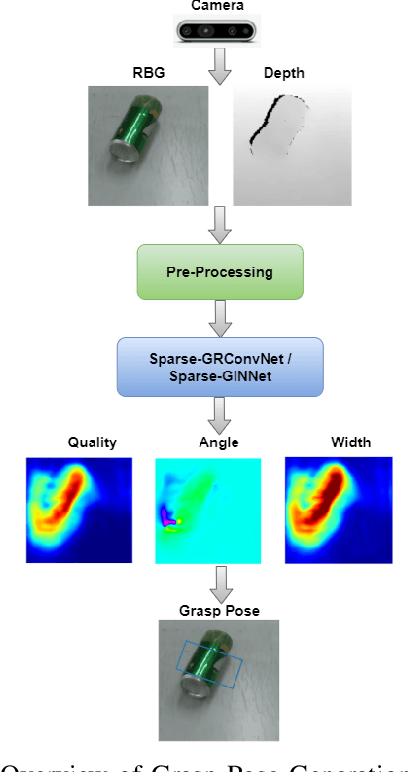



In the modern era of Deep Learning, network parameters play a vital role in models efficiency but it has its own limitations like extensive computations and memory requirements, which may not be suitable for real time intelligent robot grasping tasks. Current research focuses on how the model efficiency can be maintained by introducing sparsity but without compromising accuracy of the model in the robot grasping domain. More specifically, in this research two light-weighted neural networks have been introduced, namely Sparse-GRConvNet and Sparse-GINNet, which leverage sparsity in the robotic grasping domain for grasp pose generation by integrating the Edge-PopUp algorithm. This algorithm facilitates the identification of the top K% of edges by considering their respective score values. Both the Sparse-GRConvNet and Sparse-GINNet models are designed to generate high-quality grasp poses in real-time at every pixel location, enabling robots to effectively manipulate unfamiliar objects. We extensively trained our models using two benchmark datasets: Cornell Grasping Dataset (CGD) and Jacquard Grasping Dataset (JGD). Both Sparse-GRConvNet and Sparse-GINNet models outperform the current state-of-the-art methods in terms of performance, achieving an impressive accuracy of 97.75% with only 10% of the weight of GR-ConvNet and 50% of the weight of GI-NNet, respectively, on CGD. Additionally, Sparse-GRConvNet achieve an accuracy of 85.77% with 30% of the weight of GR-ConvNet and Sparse-GINNet achieve an accuracy of 81.11% with 10% of the weight of GI-NNet on JGD. To validate the performance of our proposed models, we conducted extensive experiments using the Anukul (Baxter) hardware cobot.
Collect, Measure, Repeat: Reliability Factors for Responsible AI Data Collection
Aug 22, 2023The rapid entry of machine learning approaches in our daily activities and high-stakes domains demands transparency and scrutiny of their fairness and reliability. To help gauge machine learning models' robustness, research typically focuses on the massive datasets used for their deployment, e.g., creating and maintaining documentation for understanding their origin, process of development, and ethical considerations. However, data collection for AI is still typically a one-off practice, and oftentimes datasets collected for a certain purpose or application are reused for a different problem. Additionally, dataset annotations may not be representative over time, contain ambiguous or erroneous annotations, or be unable to generalize across issues or domains. Recent research has shown these practices might lead to unfair, biased, or inaccurate outcomes. We argue that data collection for AI should be performed in a responsible manner where the quality of the data is thoroughly scrutinized and measured through a systematic set of appropriate metrics. In this paper, we propose a Responsible AI (RAI) methodology designed to guide the data collection with a set of metrics for an iterative in-depth analysis of the factors influencing the quality and reliability} of the generated data. We propose a granular set of measurements to inform on the internal reliability of a dataset and its external stability over time. We validate our approach across nine existing datasets and annotation tasks and four content modalities. This approach impacts the assessment of data robustness used for AI applied in the real world, where diversity of users and content is eminent. Furthermore, it deals with fairness and accountability aspects in data collection by providing systematic and transparent quality analysis for data collections.
Neural Field Movement Primitives for Joint Modelling of Scenes and Motions
Aug 15, 2023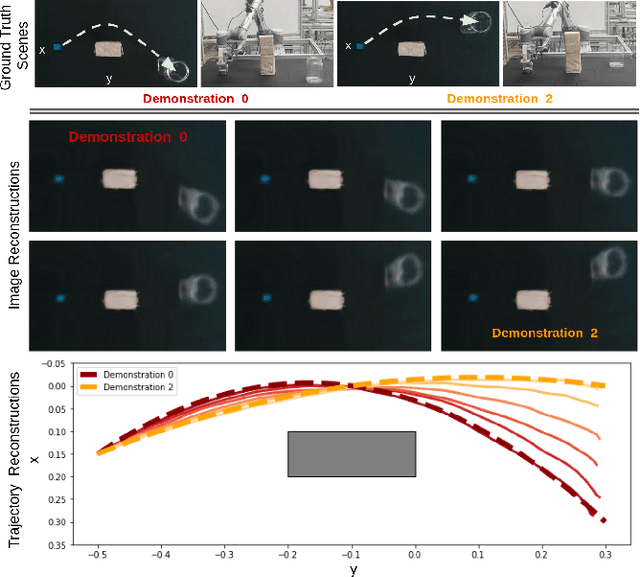
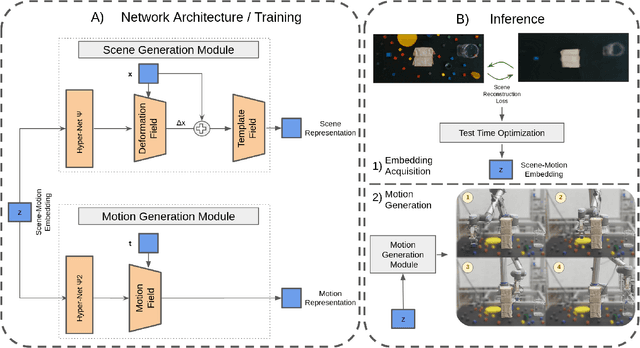
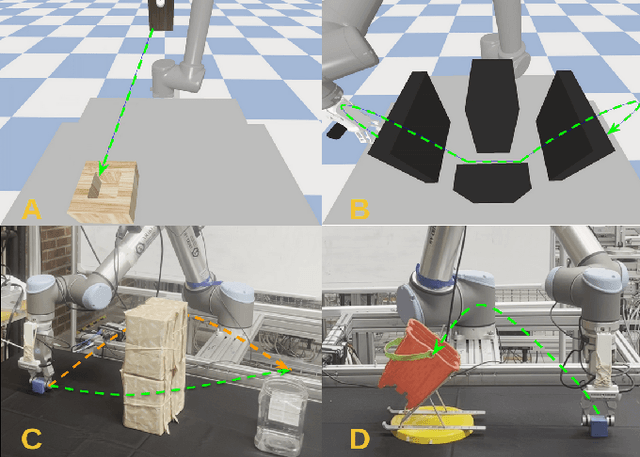
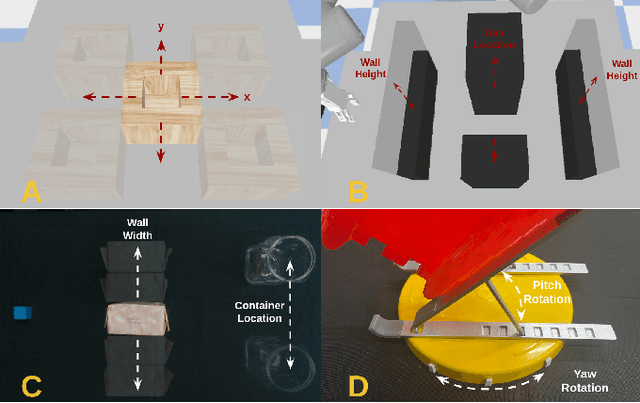
This paper presents a novel Learning from Demonstration (LfD) method that uses neural fields to learn new skills efficiently and accurately. It achieves this by utilizing a shared embedding to learn both scene and motion representations in a generative way. Our method smoothly maps each expert demonstration to a scene-motion embedding and learns to model them without requiring hand-crafted task parameters or large datasets. It achieves data efficiency by enforcing scene and motion generation to be smooth with respect to changes in the embedding space. At inference time, our method can retrieve scene-motion embeddings using test time optimization, and generate precise motion trajectories for novel scenes. The proposed method is versatile and can employ images, 3D shapes, and any other scene representations that can be modeled using neural fields. Additionally, it can generate both end-effector positions and joint angle-based trajectories. Our method is evaluated on tasks that require accurate motion trajectory generation, where the underlying task parametrization is based on object positions and geometric scene changes. Experimental results demonstrate that the proposed method outperforms the baseline approaches and generalizes to novel scenes. Furthermore, in real-world experiments, we show that our method can successfully model multi-valued trajectories, it is robust to the distractor objects introduced at inference time, and it can generate 6D motions.
Adaptive interventions for both accuracy and time in AI-assisted human decision making
Jun 12, 2023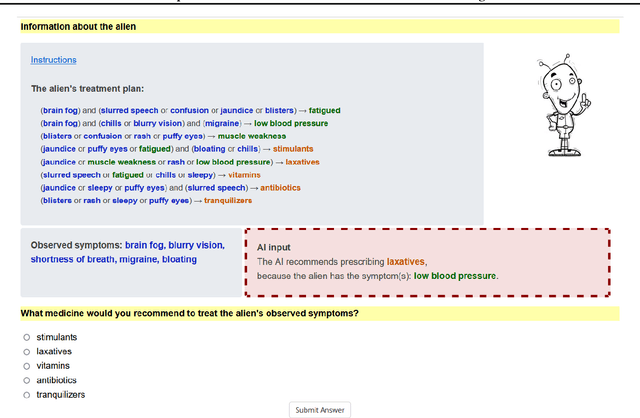

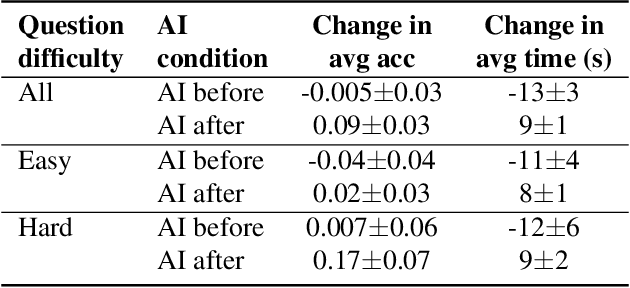
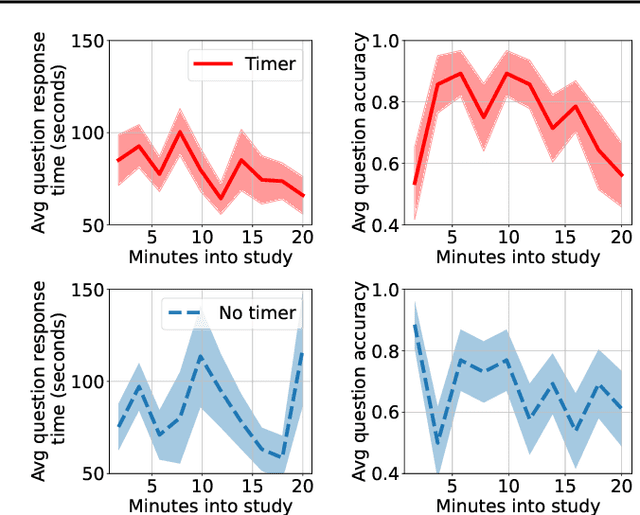
In settings where users are both time-pressured and need high accuracy, such as doctors working in Emergency Rooms, we want to provide AI assistance that both increases accuracy and reduces time. However, different types of AI assistance have different benefits: some reduce time taken while increasing overreliance on AI, while others do the opposite. We therefore want to adapt what AI assistance we show depending on various properties (of the question and of the user) in order to best tradeoff our two objectives. We introduce a study where users have to prescribe medicines to aliens, and use it to explore the potential for adapting AI assistance. We find evidence that it is beneficial to adapt our AI assistance depending on the question, leading to good tradeoffs between time taken and accuracy. Future work would consider machine-learning algorithms (such as reinforcement learning) to automatically adapt quickly.