 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Cell Tracking with a Time-Symmetric Deep Learning Approach
Aug 04, 2023
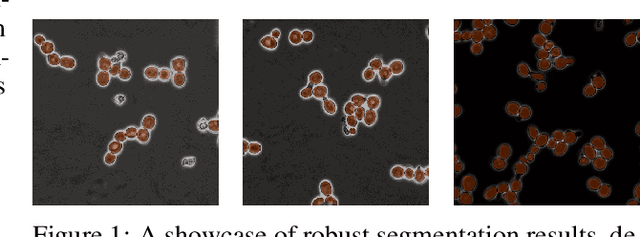
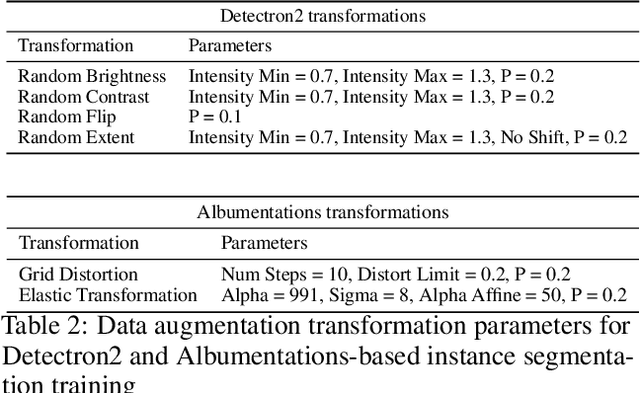

The accurate tracking of live cells using video microscopy recordings remains a challenging task for popular state-of-the-art image processing based object tracking methods. In recent years, several existing and new applications have attempted to integrate deep-learning based frameworks for this task, but most of them still heavily rely on consecutive frame based tracking embedded in their architecture or other premises that hinder generalized learning. To address this issue, we aimed to develop a new deep-learning based tracking method that relies solely on the assumption that cells can be tracked based on their spatio-temporal neighborhood, without restricting it to consecutive frames. The proposed method has the additional benefit that the motion patterns of the cells can be learned completely by the predictor without any prior assumptions, and it has the potential to handle a large number of video frames with heavy artifacts. The efficacy of the proposed method is demonstrated through multiple biologically motivated validation strategies and compared against several state-of-the-art cell tracking methods.
Time for aCTIon: Automated Analysis of Cyber Threat Intelligence in the Wild
Jul 14, 2023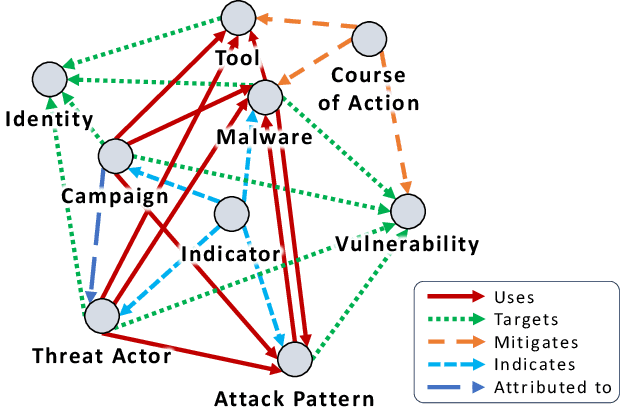
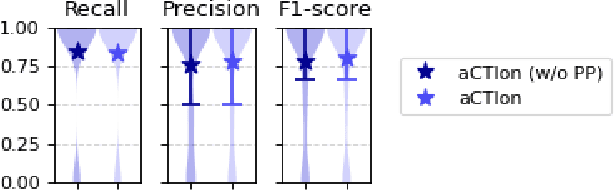
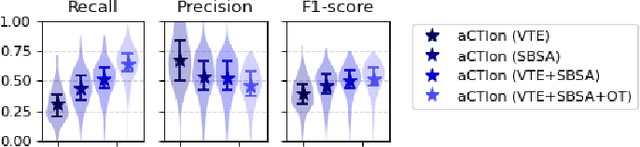
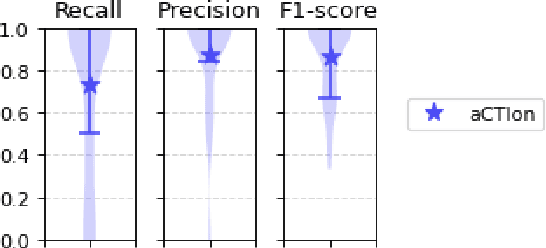
Cyber Threat Intelligence (CTI) plays a crucial role in assessing risks and enhancing security for organizations. However, the process of extracting relevant information from unstructured text sources can be expensive and time-consuming. Our empirical experience shows that existing tools for automated structured CTI extraction have performance limitations. Furthermore, the community lacks a common benchmark to quantitatively assess their performance. We fill these gaps providing a new large open benchmark dataset and aCTIon, a structured CTI information extraction tool. The dataset includes 204 real-world publicly available reports and their corresponding structured CTI information in STIX format. Our team curated the dataset involving three independent groups of CTI analysts working over the course of several months. To the best of our knowledge, this dataset is two orders of magnitude larger than previously released open source datasets. We then design aCTIon, leveraging recently introduced large language models (GPT3.5) in the context of two custom information extraction pipelines. We compare our method with 10 solutions presented in previous work, for which we develop our own implementations when open-source implementations were lacking. Our results show that aCTIon outperforms previous work for structured CTI extraction with an improvement of the F1-score from 10%points to 50%points across all tasks.
Where Would I Go Next? Large Language Models as Human Mobility Predictors
Aug 29, 2023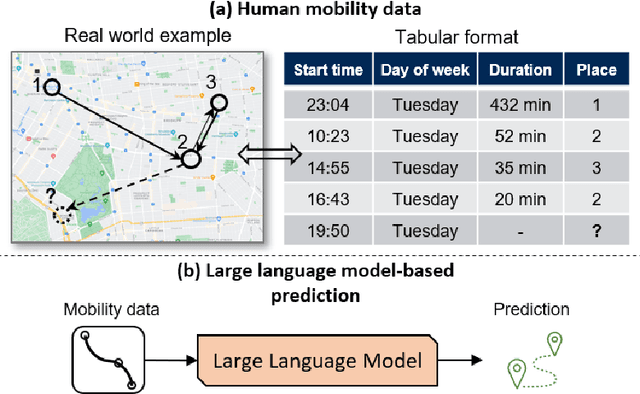
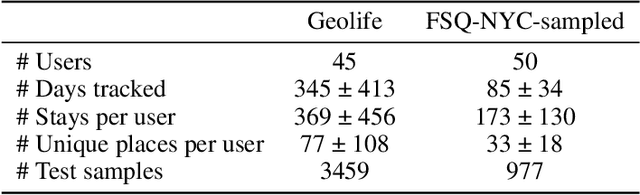
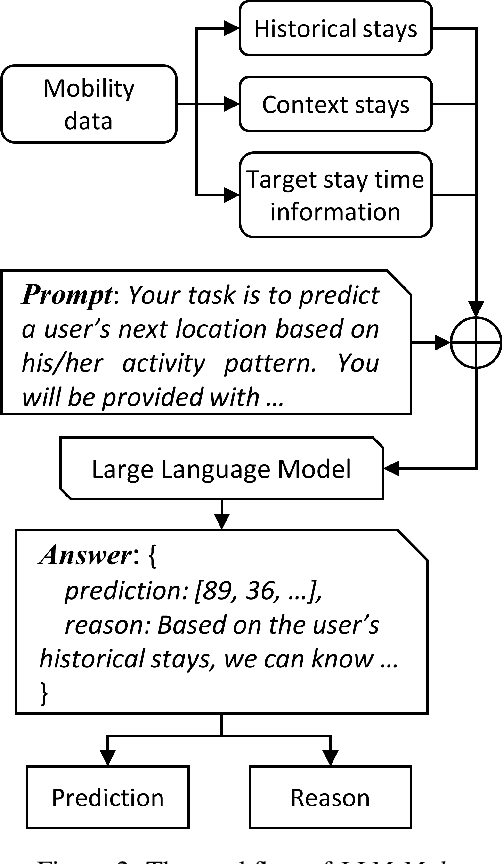
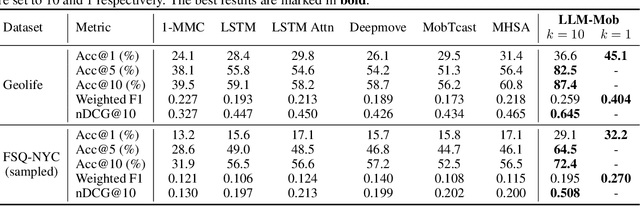
Accurate human mobility prediction underpins many important applications across a variety of domains, including epidemic modelling, transport planning, and emergency responses. Due to the sparsity of mobility data and the stochastic nature of people's daily activities, achieving precise predictions of people's locations remains a challenge. While recently developed large language models (LLMs) have demonstrated superior performance across numerous language-related tasks, their applicability to human mobility studies remains unexplored. Addressing this gap, this article delves into the potential of LLMs for human mobility prediction tasks. We introduce a novel method, LLM-Mob, which leverages the language understanding and reasoning capabilities of LLMs for analysing human mobility data. We present concepts of historical stays and context stays to capture both long-term and short-term dependencies in human movement and enable time-aware prediction by using time information of the prediction target. Additionally, we design context-inclusive prompts that enable LLMs to generate more accurate predictions. Comprehensive evaluations of our method reveal that LLM-Mob excels in providing accurate and interpretable predictions, highlighting the untapped potential of LLMs in advancing human mobility prediction techniques. We posit that our research marks a significant paradigm shift in human mobility modelling, transitioning from building complex domain-specific models to harnessing general-purpose LLMs that yield accurate predictions through language instructions. The code for this work is available at https://github.com/xlwang233/LLM-Mob.
InstaTune: Instantaneous Neural Architecture Search During Fine-Tuning
Aug 29, 2023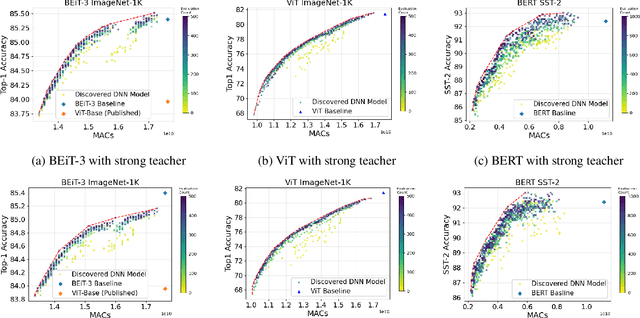
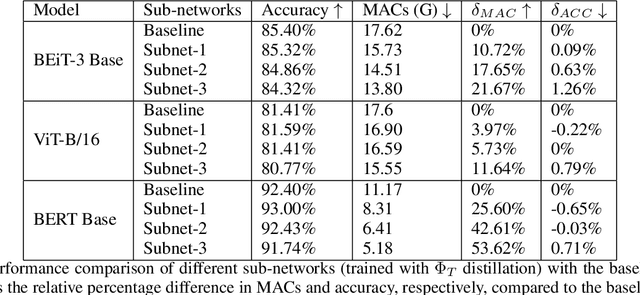
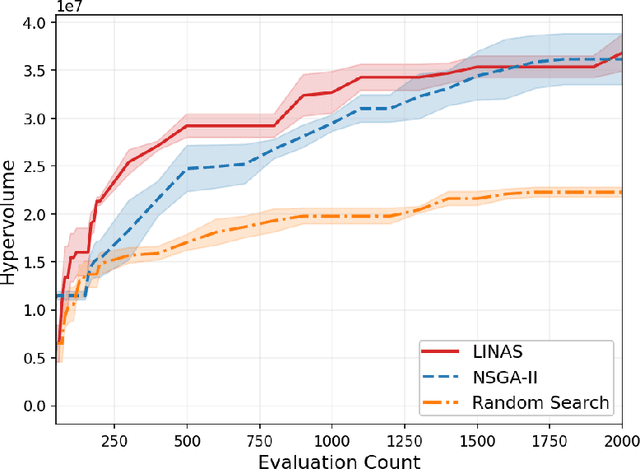
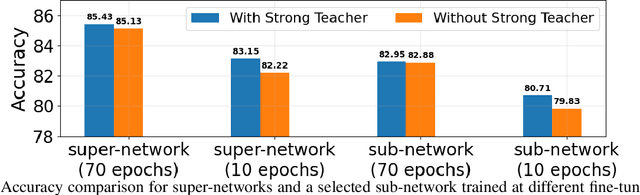
One-Shot Neural Architecture Search (NAS) algorithms often rely on training a hardware agnostic super-network for a domain specific task. Optimal sub-networks are then extracted from the trained super-network for different hardware platforms. However, training super-networks from scratch can be extremely time consuming and compute intensive especially for large models that rely on a two-stage training process of pre-training and fine-tuning. State of the art pre-trained models are available for a wide range of tasks, but their large sizes significantly limits their applicability on various hardware platforms. We propose InstaTune, a method that leverages off-the-shelf pre-trained weights for large models and generates a super-network during the fine-tuning stage. InstaTune has multiple benefits. Firstly, since the process happens during fine-tuning, it minimizes the overall time and compute resources required for NAS. Secondly, the sub-networks extracted are optimized for the target task, unlike prior work that optimizes on the pre-training objective. Finally, InstaTune is easy to "plug and play" in existing frameworks. By using multi-objective evolutionary search algorithms along with lightly trained predictors, we find Pareto-optimal sub-networks that outperform their respective baselines across different performance objectives such as accuracy and MACs. Specifically, we demonstrate that our approach performs well across both unimodal (ViT and BERT) and multi-modal (BEiT-3) transformer based architectures.
Proceedings of the 2nd International Workshop on Adaptive Cyber Defense
Aug 31, 2023The 2nd International Workshop on Adaptive Cyber Defense was held at the Florida Institute of Technology, Florida. This workshop was organized to share research that explores unique applications of Artificial Intelligence (AI) and Machine Learning (ML) as foundational capabilities for the pursuit of adaptive cyber defense. The cyber domain cannot currently be reliably and effectively defended without extensive reliance on human experts. Skilled cyber defenders are in short supply and often cannot respond fast enough to cyber threats. Building on recent advances in AI and ML the Cyber defense research community has been motivated to develop new dynamic and sustainable defenses through the adoption of AI and ML techniques to cyber settings. Bridging critical gaps between AI and Cyber researchers and practitioners can accelerate efforts to create semi-autonomous cyber defenses that can learn to recognize and respond to cyber attacks or discover and mitigate weaknesses in cooperation with other cyber operation systems and human experts. Furthermore, these defenses are expected to be adaptive and able to evolve over time to thwart changes in attacker behavior, changes in the system health and readiness, and natural shifts in user behavior over time. The workshop was comprised of invited keynote talks, technical presentations and a panel discussion about how AI/ML can enable autonomous mitigation of current and future cyber attacks. Workshop submissions were peer reviewed by a panel of domain experts with a proceedings consisting of six technical articles exploring challenging problems of critical importance to national and global security. Participation in this workshop offered new opportunities to stimulate research and innovation in the emerging domain of adaptive and autonomous cyber defense.
Coupled Attention Networks for Multivariate Time Series Anomaly Detection
Jun 12, 2023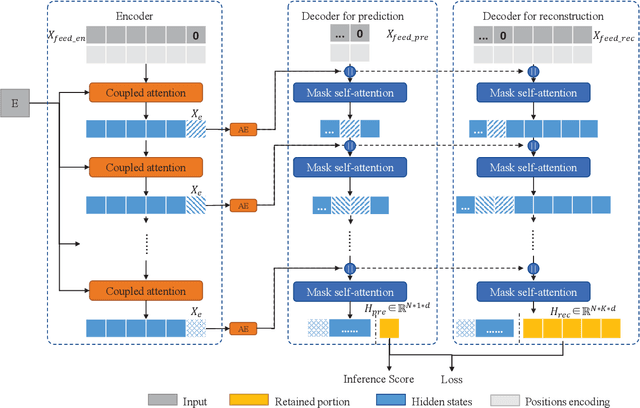
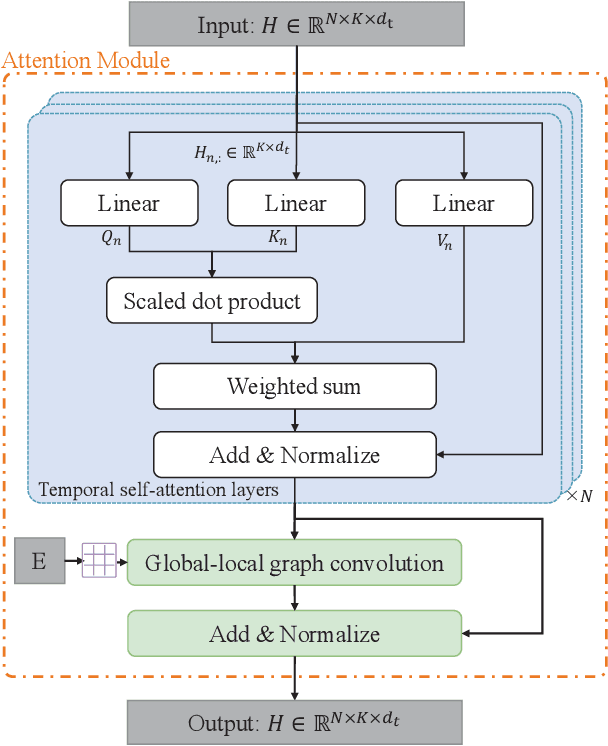
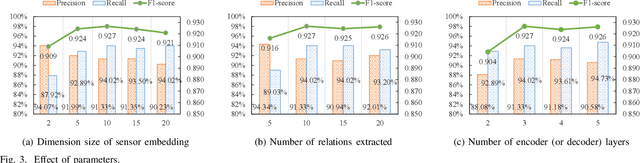
Multivariate time series anomaly detection (MTAD) plays a vital role in a wide variety of real-world application domains. Over the past few years, MTAD has attracted rapidly increasing attention from both academia and industry. Many deep learning and graph learning models have been developed for effective anomaly detection in multivariate time series data, which enable advanced applications such as smart surveillance and risk management with unprecedented capabilities. Nevertheless, MTAD is facing critical challenges deriving from the dependencies among sensors and variables, which often change over time. To address this issue, we propose a coupled attention-based neural network framework (CAN) for anomaly detection in multivariate time series data featuring dynamic variable relationships. We combine adaptive graph learning methods with graph attention to generate a global-local graph that can represent both global correlations and dynamic local correlations among sensors. To capture inter-sensor relationships and temporal dependencies, a convolutional neural network based on the global-local graph is integrated with a temporal self-attention module to construct a coupled attention module. In addition, we develop a multilevel encoder-decoder architecture that accommodates reconstruction and prediction tasks to better characterize multivariate time series data. Extensive experiments on real-world datasets have been conducted to evaluate the performance of the proposed CAN approach, and the results show that CAN significantly outperforms state-of-the-art baselines.
Identifying depression-related topics in smartphone-collected free-response speech recordings using an automatic speech recognition system and a deep learning topic model
Sep 05, 2023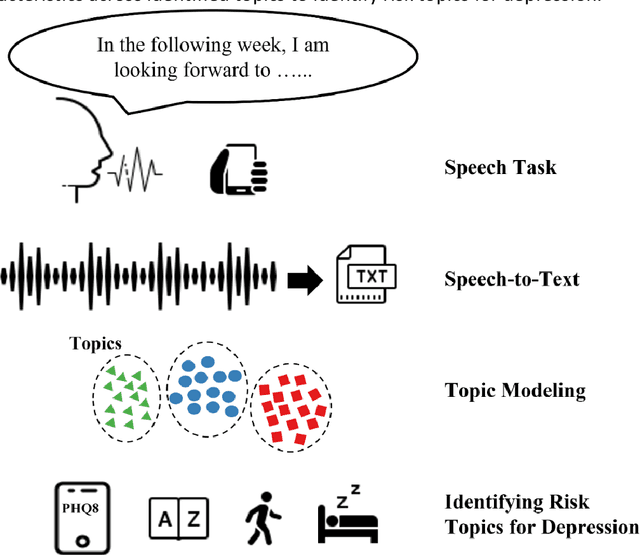
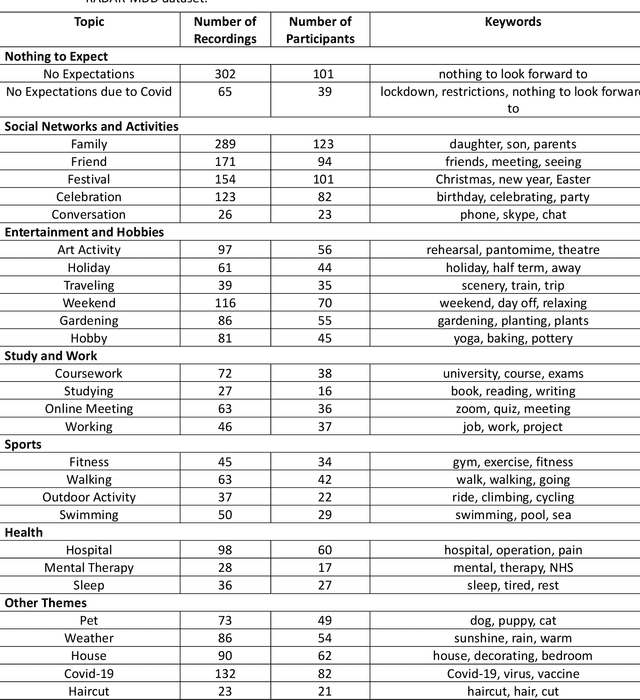
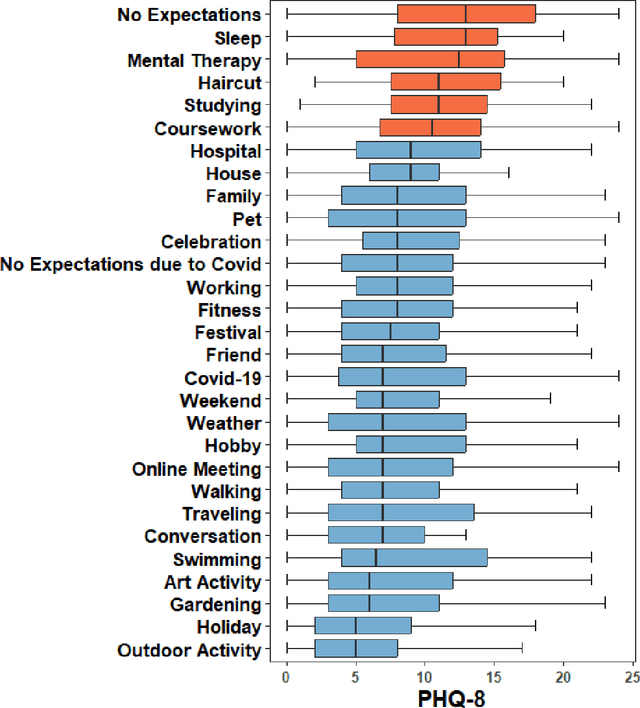
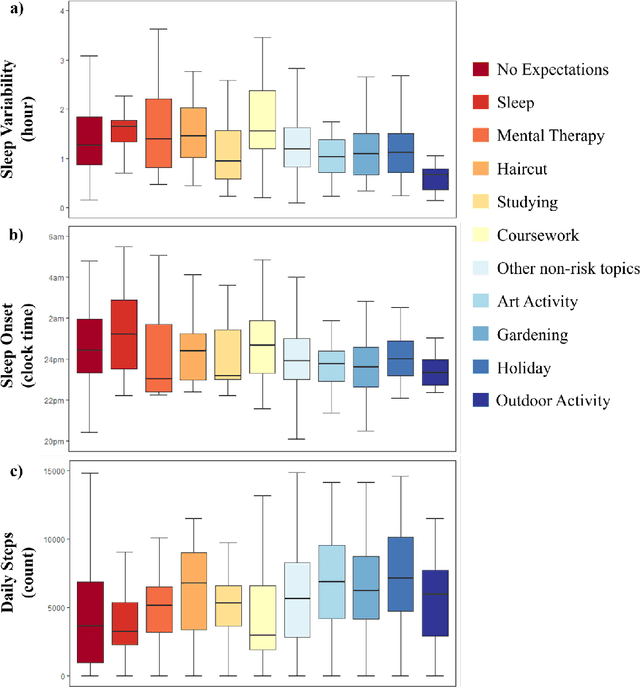
Language use has been shown to correlate with depression, but large-scale validation is needed. Traditional methods like clinic studies are expensive. So, natural language processing has been employed on social media to predict depression, but limitations remain-lack of validated labels, biased user samples, and no context. Our study identified 29 topics in 3919 smartphone-collected speech recordings from 265 participants using the Whisper tool and BERTopic model. Six topics with a median PHQ-8 greater than or equal to 10 were regarded as risk topics for depression: No Expectations, Sleep, Mental Therapy, Haircut, Studying, and Coursework. To elucidate the topic emergence and associations with depression, we compared behavioral (from wearables) and linguistic characteristics across identified topics. The correlation between topic shifts and changes in depression severity over time was also investigated, indicating the importance of longitudinally monitoring language use. We also tested the BERTopic model on a similar smaller dataset (356 speech recordings from 57 participants), obtaining some consistent results. In summary, our findings demonstrate specific speech topics may indicate depression severity. The presented data-driven workflow provides a practical approach to collecting and analyzing large-scale speech data from real-world settings for digital health research.
DEEPBEAS3D: Deep Learning and B-Spline Explicit Active Surfaces
Sep 05, 2023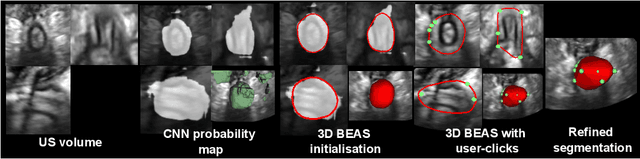
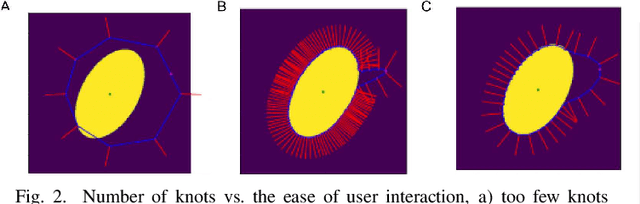
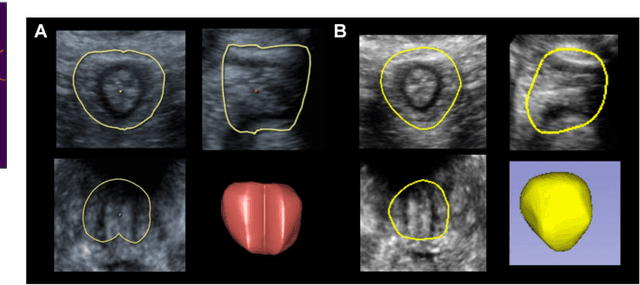
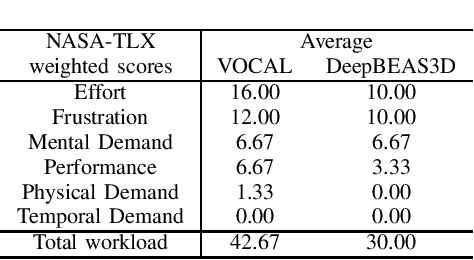
Deep learning-based automatic segmentation methods have become state-of-the-art. However, they are often not robust enough for direct clinical application, as domain shifts between training and testing data affect their performance. Failure in automatic segmentation can cause sub-optimal results that require correction. To address these problems, we propose a novel 3D extension of an interactive segmentation framework that represents a segmentation from a convolutional neural network (CNN) as a B-spline explicit active surface (BEAS). BEAS ensures segmentations are smooth in 3D space, increasing anatomical plausibility, while allowing the user to precisely edit the 3D surface. We apply this framework to the task of 3D segmentation of the anal sphincter complex (AS) from transperineal ultrasound (TPUS) images, and compare it to the clinical tool used in the pelvic floor disorder clinic (4D View VOCAL, GE Healthcare; Zipf, Austria). Experimental results show that: 1) the proposed framework gives the user explicit control of the surface contour; 2) the perceived workload calculated via the NASA-TLX index was reduced by 30% compared to VOCAL; and 3) it required 7 0% (170 seconds) less user time than VOCAL (p< 0.00001)
Graph-Based Automatic Feature Selection for Multi-Class Classification via Mean Simplified Silhouette
Sep 05, 2023
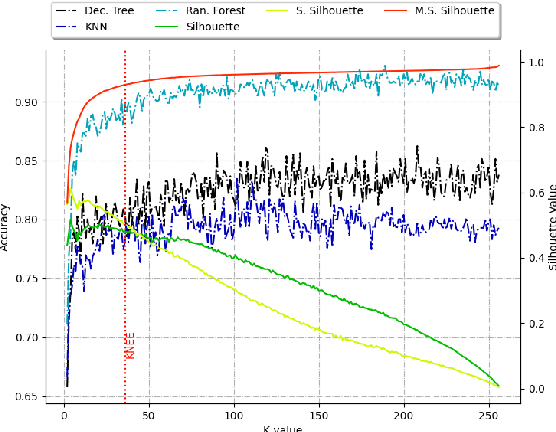
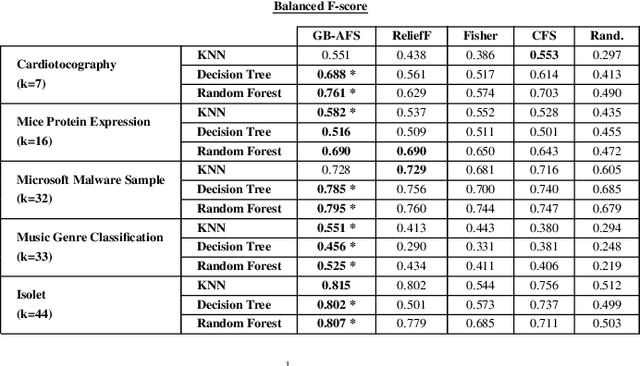
This paper introduces a novel graph-based filter method for automatic feature selection (abbreviated as GB-AFS) for multi-class classification tasks. The method determines the minimum combination of features required to sustain prediction performance while maintaining complementary discriminating abilities between different classes. It does not require any user-defined parameters such as the number of features to select. The methodology employs the Jeffries-Matusita (JM) distance in conjunction with t-distributed Stochastic Neighbor Embedding (t-SNE) to generate a low-dimensional space reflecting how effectively each feature can differentiate between each pair of classes. The minimum number of features is selected using our newly developed Mean Simplified Silhouette (abbreviated as MSS) index, designed to evaluate the clustering results for the feature selection task. Experimental results on public data sets demonstrate the superior performance of the proposed GB-AFS over other filter-based techniques and automatic feature selection approaches. Moreover, the proposed algorithm maintained the accuracy achieved when utilizing all features, while using only $7\%$ to $30\%$ of the features. Consequently, this resulted in a reduction of the time needed for classifications, from $15\%$ to $70\%$.
SAM-Deblur: Let Segment Anything Boost Image Deblurring
Sep 05, 2023
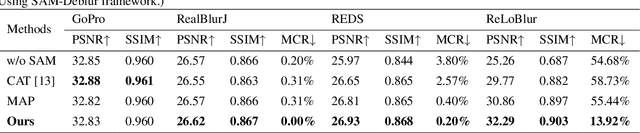

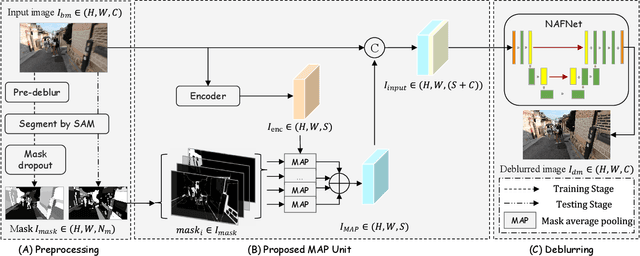
Image deblurring is a critical task in the field of image restoration, aiming to eliminate blurring artifacts. However, the challenge of addressing non-uniform blurring leads to an ill-posed problem, which limits the generalization performance of existing deblurring models. To solve the problem, we propose a framework SAM-Deblur, integrating prior knowledge from the Segment Anything Model (SAM) into the deblurring task for the first time. In particular, SAM-Deblur is divided into three stages. First, We preprocess the blurred images, obtain image masks via SAM, and propose a mask dropout method for training to enhance model robustness. Then, to fully leverage the structural priors generated by SAM, we propose a Mask Average Pooling (MAP) unit specifically designed to average SAM-generated segmented areas, serving as a plug-and-play component which can be seamlessly integrated into existing deblurring networks. Finally, we feed the fused features generated by the MAP Unit into the deblurring model to obtain a sharp image. Experimental results on the RealBlurJ, ReloBlur, and REDS datasets reveal that incorporating our methods improves NAFNet's PSNR by 0.05, 0.96, and 7.03, respectively. Code will be available at \href{https://github.com/HPLQAQ/SAM-Deblur}{SAM-Deblur}.