 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fall Detection using Knowledge Distillation Based Long short-term memory for Offline Embedded and Low Power Devices
Aug 24, 2023

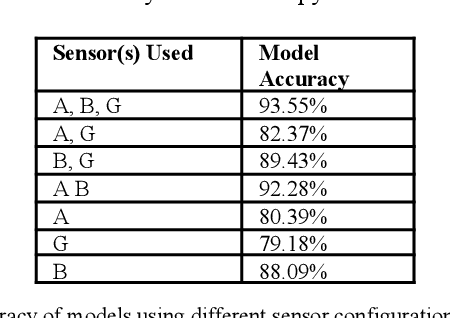
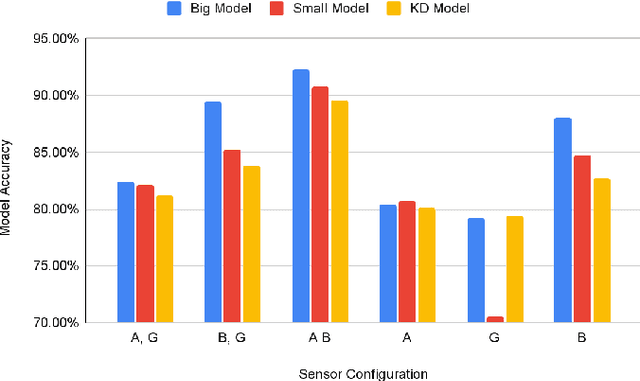
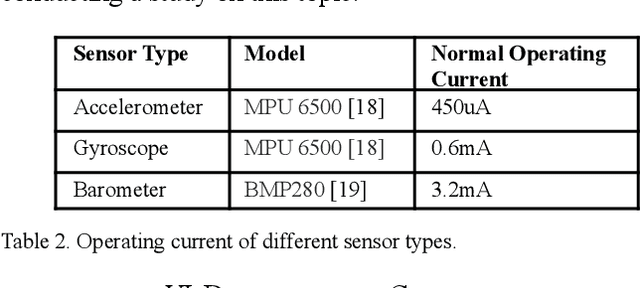
This paper presents a cost-effective, low-power approach to unintentional fall detection using knowledge distillation-based LSTM (Long Short-Term Memory) models to significantly improve accuracy. With a primary focus on analyzing time-series data collected from various sensors, the solution offers real-time detection capabilities, ensuring prompt and reliable identification of falls. The authors investigate fall detection models that are based on different sensors, comparing their accuracy rates and performance. Furthermore, they employ the technique of knowledge distillation to enhance the models' precision, resulting in refined accurate configurations that consume lower power. As a result, this proposed solution presents a compelling avenue for the development of energy-efficient fall detection systems for future advancements in this critical domain.
A Neural RDE approach for continuous-time non-Markovian stochastic control problems
Jun 25, 2023We propose a novel framework for solving continuous-time non-Markovian stochastic control problems by means of neural rough differential equations (Neural RDEs) introduced in Morrill et al. (2021). Non-Markovianity naturally arises in control problems due to the time delay effects in the system coefficients or the driving noises, which leads to optimal control strategies depending explicitly on the historical trajectories of the system state. By modelling the control process as the solution of a Neural RDE driven by the state process, we show that the control-state joint dynamics are governed by an uncontrolled, augmented Neural RDE, allowing for fast Monte-Carlo estimation of the value function via trajectories simulation and memory-efficient backpropagation. We provide theoretical underpinnings for the proposed algorithmic framework by demonstrating that Neural RDEs serve as universal approximators for functions of random rough paths. Exhaustive numerical experiments on non-Markovian stochastic control problems are presented, which reveal that the proposed framework is time-resolution-invariant and achieves higher accuracy and better stability in irregular sampling compared to existing RNN-based approaches.
Channel Attention Separable Convolution Network for Skin Lesion Segmentation
Sep 03, 2023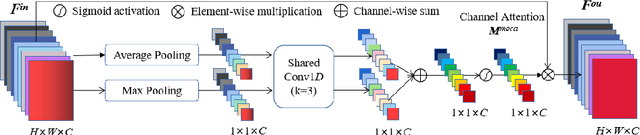

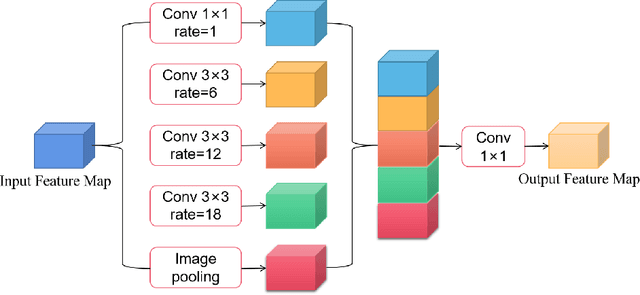
Skin cancer is a frequently occurring cancer in the human population, and it is very important to be able to diagnose malignant tumors in the body early. Lesion segmentation is crucial for monitoring the morphological changes of skin lesions, extracting features to localize and identify diseases to assist doctors in early diagnosis. Manual de-segmentation of dermoscopic images is error-prone and time-consuming, thus there is a pressing demand for precise and automated segmentation algorithms. Inspired by advanced mechanisms such as U-Net, DenseNet, Separable Convolution, Channel Attention, and Atrous Spatial Pyramid Pooling (ASPP), we propose a novel network called Channel Attention Separable Convolution Network (CASCN) for skin lesions segmentation. The proposed CASCN is evaluated on the PH2 dataset with limited images. Without excessive pre-/post-processing of images, CASCN achieves state-of-the-art performance on the PH2 dataset with Dice similarity coefficient of 0.9461 and accuracy of 0.9645.
Using Neural Networks for Fast SAR Roughness Estimation of High Resolution Images
Sep 06, 2023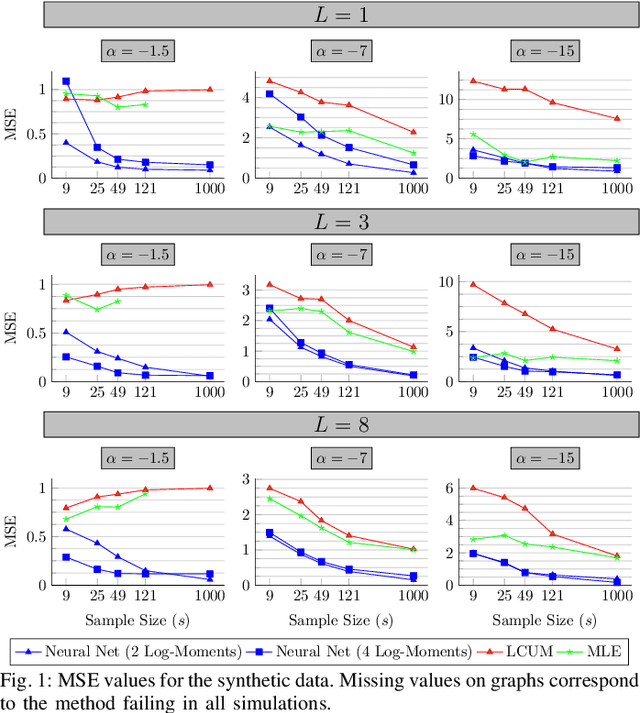


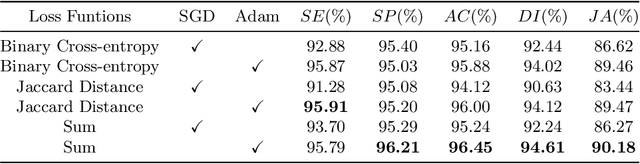
The analysis of Synthetic Aperture Radar (SAR) imagery is an important step in remote sensing applications, and it is a challenging problem due to its inherent speckle noise. One typical solution is to model the data using the $G_I^0$ distribution and extract its roughness information, which in turn can be used in posterior imaging tasks, such as segmentation, classification and interpretation. This leads to the need of quick and reliable estimation of the roughness parameter from SAR data, especially with high resolution images. Unfortunately, traditional parameter estimation procedures are slow and prone to estimation failures. In this work, we proposed a neural network-based estimation framework that first learns how to predict underlying parameters of $G_I^0$ samples and then can be used to estimate the roughness of unseen data. We show that this approach leads to an estimator that is quicker, yields less estimation error and is less prone to failures than the traditional estimation procedures for this problem, even when we use a simple network. More importantly, we show that this same methodology can be generalized to handle image inputs and, even if trained on purely synthetic data for a few seconds, is able to perform real time pixel-wise roughness estimation for high resolution real SAR imagery.
On Reducing Undesirable Behavior in Deep Reinforcement Learning Models
Sep 06, 2023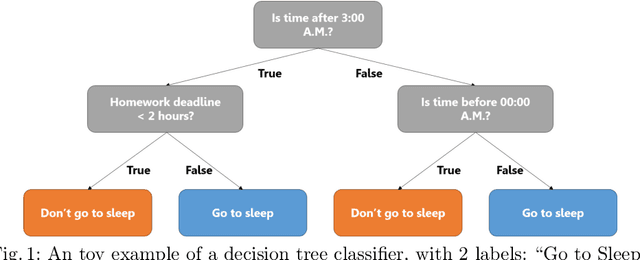
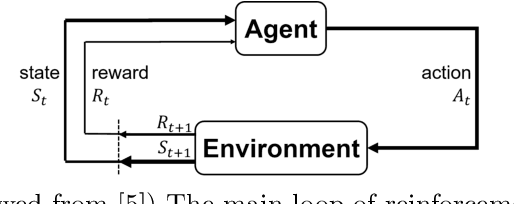
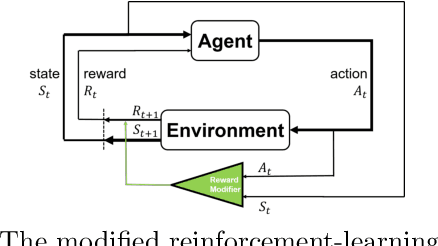
Deep reinforcement learning (DRL) has proven extremely useful in a large variety of application domains. However, even successful DRL-based software can exhibit highly undesirable behavior. This is due to DRL training being based on maximizing a reward function, which typically captures general trends but cannot precisely capture, or rule out, certain behaviors of the system. In this paper, we propose a novel framework aimed at drastically reducing the undesirable behavior of DRL-based software, while maintaining its excellent performance. In addition, our framework can assist in providing engineers with a comprehensible characterization of such undesirable behavior. Under the hood, our approach is based on extracting decision tree classifiers from erroneous state-action pairs, and then integrating these trees into the DRL training loop, penalizing the system whenever it performs an error. We provide a proof-of-concept implementation of our approach, and use it to evaluate the technique on three significant case studies. We find that our approach can extend existing frameworks in a straightforward manner, and incurs only a slight overhead in training time. Further, it incurs only a very slight hit to performance, or even in some cases - improves it, while significantly reducing the frequency of undesirable behavior.
SlAction: Non-intrusive, Lightweight Obstructive Sleep Apnea Detection using Infrared Video
Sep 06, 2023

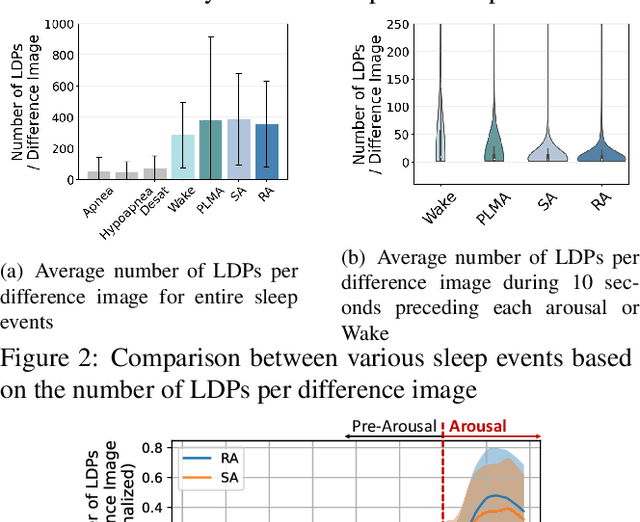
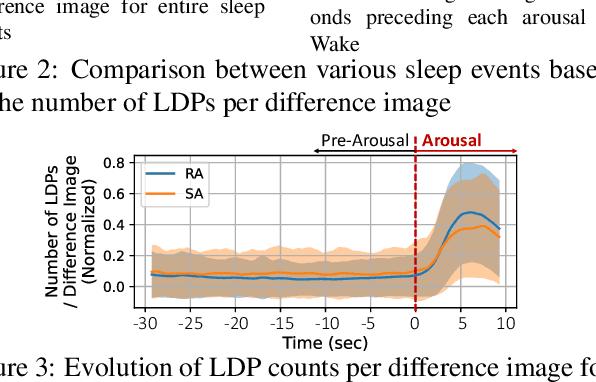
Obstructive sleep apnea (OSA) is a prevalent sleep disorder affecting approximately one billion people world-wide. The current gold standard for diagnosing OSA, Polysomnography (PSG), involves an overnight hospital stay with multiple attached sensors, leading to potential inaccuracies due to the first-night effect. To address this, we present SlAction, a non-intrusive OSA detection system for daily sleep environments using infrared videos. Recognizing that sleep videos exhibit minimal motion, this work investigates the fundamental question: "Are respiratory events adequately reflected in human motions during sleep?" Analyzing the largest sleep video dataset of 5,098 hours, we establish correlations between OSA events and human motions during sleep. Our approach uses a low frame rate (2.5 FPS), a large size (60 seconds) and step (30 seconds) for sliding window analysis to capture slow and long-term motions related to OSA. Furthermore, we utilize a lightweight deep neural network for resource-constrained devices, ensuring all video streams are processed locally without compromising privacy. Evaluations show that SlAction achieves an average F1 score of 87.6% in detecting OSA across various environments. Implementing SlAction on NVIDIA Jetson Nano enables real-time inference (~3 seconds for a 60-second video clip), highlighting its potential for early detection and personalized treatment of OSA.
Weighted Unsupervised Domain Adaptation Considering Geometry Features and Engineering Performance of 3D Design Data
Sep 08, 2023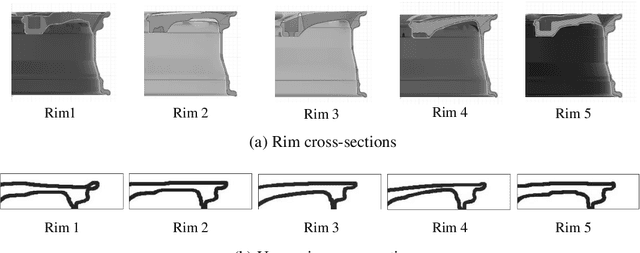
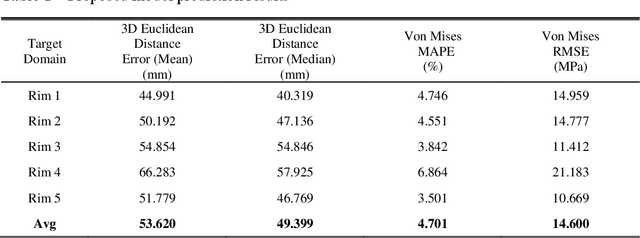

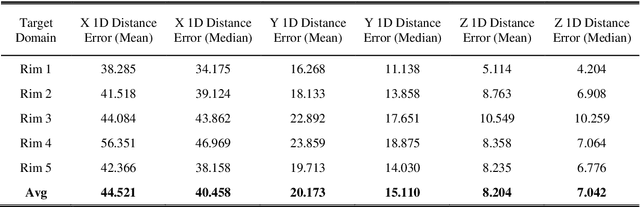
The product design process in manufacturing involves iterative design modeling and analysis to achieve the target engineering performance, but such an iterative process is time consuming and computationally expensive. Recently, deep learning-based engineering performance prediction models have been proposed to accelerate design optimization. However, they only guarantee predictions on training data and may be inaccurate when applied to new domain data. In particular, 3D design data have complex features, which means domains with various distributions exist. Thus, the utilization of deep learning has limitations due to the heavy data collection and training burdens. We propose a bi-weighted unsupervised domain adaptation approach that considers the geometry features and engineering performance of 3D design data. It is specialized for deep learning-based engineering performance predictions. Domain-invariant features can be extracted through an adversarial training strategy by using hypothesis discrepancy, and a multi-output regression task can be performed with the extracted features to predict the engineering performance. In particular, we present a source instance weighting method suitable for 3D design data to avoid negative transfers. The developed bi-weighting strategy based on the geometry features and engineering performance of engineering structures is incorporated into the training process. The proposed model is tested on a wheel impact analysis problem to predict the magnitude of the maximum von Mises stress and the corresponding location of 3D road wheels. This mechanism can reduce the target risk for unlabeled target domains on the basis of weighted multi-source domain knowledge and can efficiently replace conventional finite element analysis.
Parallel and Limited Data Voice Conversion Using Stochastic Variational Deep Kernel Learning
Sep 08, 2023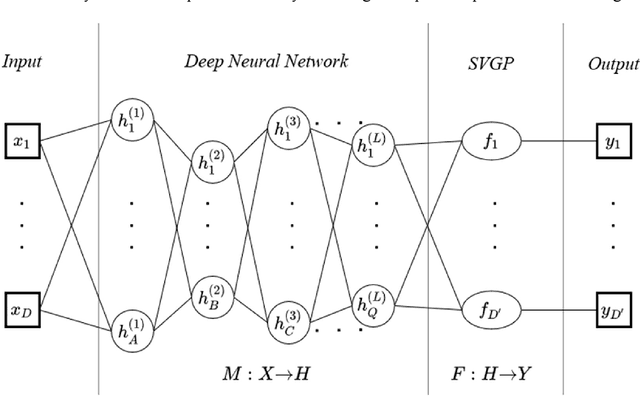
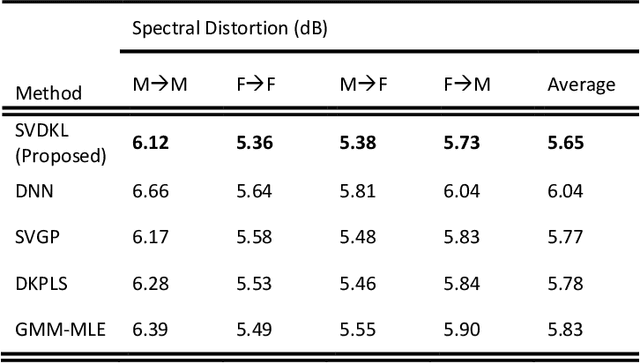
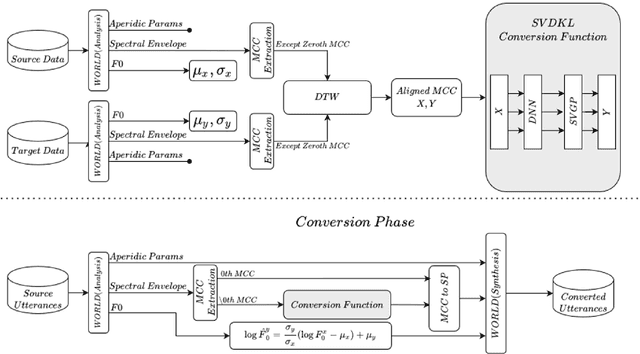
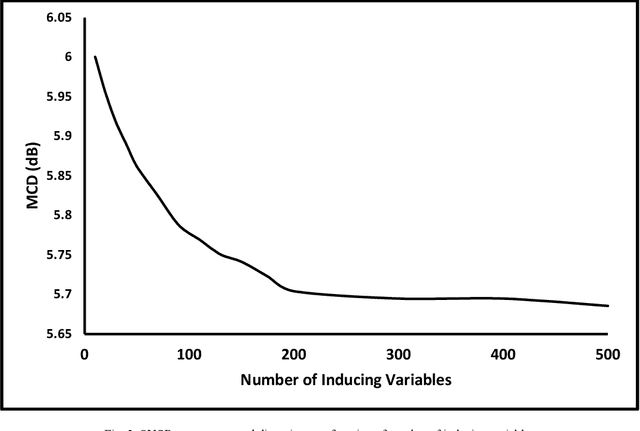
Typically, voice conversion is regarded as an engineering problem with limited training data. The reliance on massive amounts of data hinders the practical applicability of deep learning approaches, which have been extensively researched in recent years. On the other hand, statistical methods are effective with limited data but have difficulties in modelling complex mapping functions. This paper proposes a voice conversion method that works with limited data and is based on stochastic variational deep kernel learning (SVDKL). At the same time, SVDKL enables the use of deep neural networks' expressive capability as well as the high flexibility of the Gaussian process as a Bayesian and non-parametric method. When the conventional kernel is combined with the deep neural network, it is possible to estimate non-smooth and more complex functions. Furthermore, the model's sparse variational Gaussian process solves the scalability problem and, unlike the exact Gaussian process, allows for the learning of a global mapping function for the entire acoustic space. One of the most important aspects of the proposed scheme is that the model parameters are trained using marginal likelihood optimization, which considers both data fitting and model complexity. Considering the complexity of the model reduces the amount of training data by increasing the resistance to overfitting. To evaluate the proposed scheme, we examined the model's performance with approximately 80 seconds of training data. The results indicated that our method obtained a higher mean opinion score, smaller spectral distortion, and better preference tests than the compared methods.
Offline Recommender System Evaluation under Unobserved Confounding
Sep 08, 2023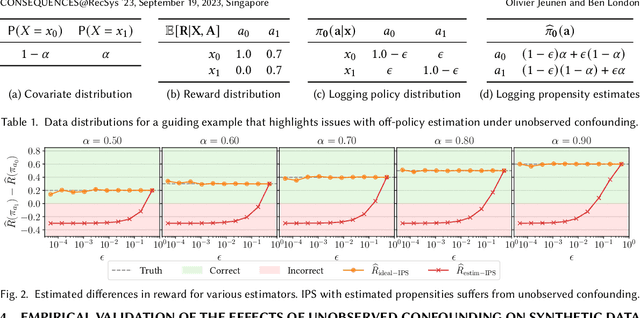
Off-Policy Estimation (OPE) methods allow us to learn and evaluate decision-making policies from logged data. This makes them an attractive choice for the offline evaluation of recommender systems, and several recent works have reported successful adoption of OPE methods to this end. An important assumption that makes this work is the absence of unobserved confounders: random variables that influence both actions and rewards at data collection time. Because the data collection policy is typically under the practitioner's control, the unconfoundedness assumption is often left implicit, and its violations are rarely dealt with in the existing literature. This work aims to highlight the problems that arise when performing off-policy estimation in the presence of unobserved confounders, specifically focusing on a recommendation use-case. We focus on policy-based estimators, where the logging propensities are learned from logged data. We characterise the statistical bias that arises due to confounding, and show how existing diagnostics are unable to uncover such cases. Because the bias depends directly on the true and unobserved logging propensities, it is non-identifiable. As the unconfoundedness assumption is famously untestable, this becomes especially problematic. This paper emphasises this common, yet often overlooked issue. Through synthetic data, we empirically show how na\"ive propensity estimation under confounding can lead to severely biased metric estimates that are allowed to fly under the radar. We aim to cultivate an awareness among researchers and practitioners of this important problem, and touch upon potential research directions towards mitigating its effects.
A Deep Learning Method for Sensitivity Enhancement of Deuterium Metabolic Imaging (DMI)
Sep 08, 2023
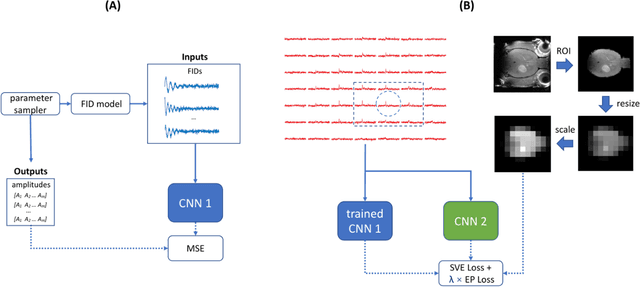
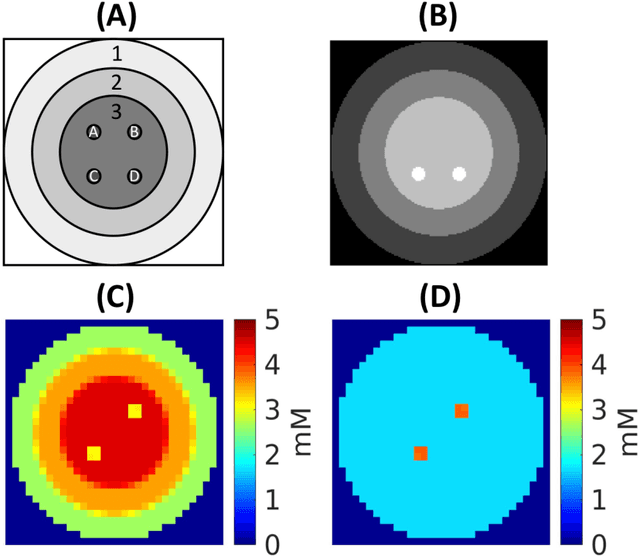
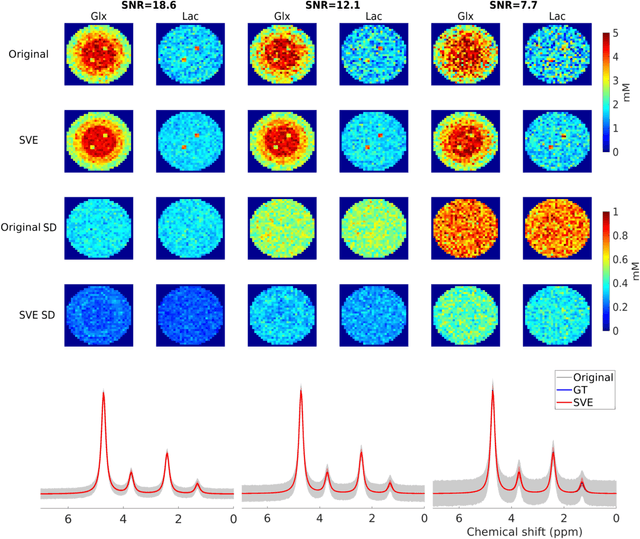
Purpose: Common to most MRSI techniques, the spatial resolution and the minimal scan duration of Deuterium Metabolic Imaging (DMI) are limited by the achievable SNR. This work presents a deep learning method for sensitivity enhancement of DMI. Methods: A convolutional neural network (CNN) was designed to estimate the 2H-labeled metabolite concentrations from low SNR and distorted DMI FIDs. The CNN was trained with synthetic data that represent a range of SNR levels typically encountered in vivo. The estimation precision was further improved by fine-tuning the CNN with MRI-based edge-preserving regularization for each DMI dataset. The proposed processing method, PReserved Edge ConvolutIonal neural network for Sensitivity Enhanced DMI (PRECISE-DMI), was applied to simulation studies and in vivo experiments to evaluate the anticipated improvements in SNR and investigate the potential for inaccuracies. Results: PRECISE-DMI visually improved the metabolic maps of low SNR datasets, and quantitatively provided higher precision than the standard Fourier reconstruction. Processing of DMI data acquired in rat brain tumor models resulted in more precise determination of 2H-labeled lactate and glutamate + glutamine levels, at increased spatial resolution (from >8 to 2 $\mu$L) or shortened scan time (from 32 to 4 min) compared to standard acquisitions. However, rigorous SD-bias analyses showed that overuse of the edge-preserving regularization can compromise the accuracy of the results. Conclusion: PRECISE-DMI allows a flexible trade-off between enhancing the sensitivity of DMI and minimizing the inaccuracies. With typical settings, the DMI sensitivity can be improved by 3-fold while retaining the capability to detect local signal variations.