 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Memory-Scalable and Simplified Functional Map Learning
Mar 30, 2024
Deep functional maps have emerged in recent years as a prominent learning-based framework for non-rigid shape matching problems. While early methods in this domain only focused on learning in the functional domain, the latest techniques have demonstrated that by promoting consistency between functional and pointwise maps leads to significant improvements in accuracy. Unfortunately, existing approaches rely heavily on the computation of large dense matrices arising from soft pointwise maps, which compromises their efficiency and scalability. To address this limitation, we introduce a novel memory-scalable and efficient functional map learning pipeline. By leveraging the specific structure of functional maps, we offer the possibility to achieve identical results without ever storing the pointwise map in memory. Furthermore, based on the same approach, we present a differentiable map refinement layer adapted from an existing axiomatic refinement algorithm. Unlike many functional map learning methods, which use this algorithm at a post-processing step, ours can be easily used at train time, enabling to enforce consistency between the refined and initial versions of the map. Our resulting approach is both simpler, more efficient and more numerically stable, by avoiding differentiation through a linear system, while achieving close to state-of-the-art results in challenging scenarios.
Risk prediction of pathological gambling on social media
Mar 28, 2024This paper addresses the problem of risk prediction on social media data, specifically focusing on the classification of Reddit users as having a pathological gambling disorder. To tackle this problem, this paper focuses on incorporating temporal and emotional features into the model. The preprocessing phase involves dealing with the time irregularity of posts by padding sequences. Two baseline architectures are used for preliminary evaluation: BERT classifier on concatenated posts per user and GRU with LSTM on sequential data. Experimental results demonstrate that the sequential models outperform the concatenation-based model. The results of the experiments conclude that the incorporation of a time decay layer (TD) and passing the emotion classification layer (EmoBERTa) through LSTM improves the performance significantly. Experiments concluded that the addition of a self-attention layer didn't significantly improve the performance of the model, however provided easily interpretable attention scores. The developed architecture with the inclusion of EmoBERTa and TD layers achieved a high F1 score, beating existing benchmarks on pathological gambling dataset. Future work may involve the early prediction of risk factors associated with pathological gambling disorder and testing models on other datasets. Overall, this research highlights the significance of the sequential processing of posts including temporal and emotional features to boost the predictive power, as well as adding an attention layer for interpretability.
Utilizing acceleration measurements to improve TDOA based localization
Mar 28, 2024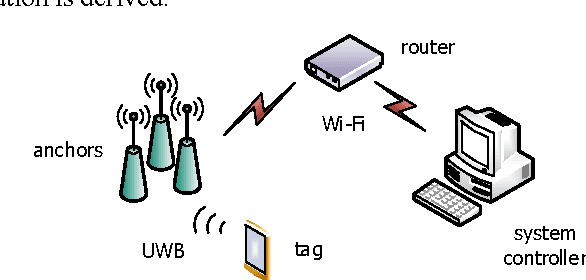
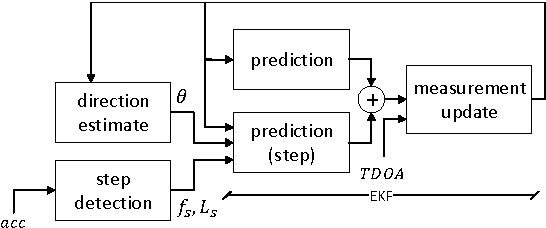
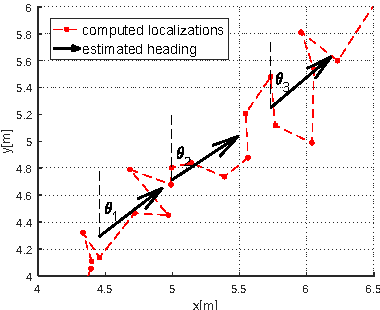
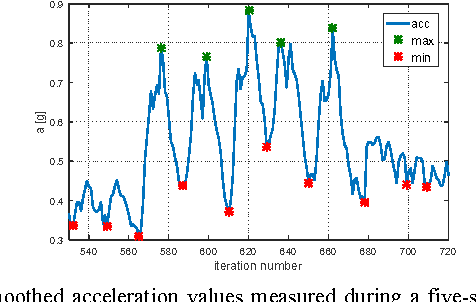
In this paper localization using UWB positioning system and an inertial unit containing a single accelerometer is considered. The main part of the paper describes a novel algorithm for person localization. The algorithm is based on modified Extended Kalman Filter and utilizes TDOA (Time Difference of Arrival) results obtained from UWB system and results of acceleration measurement performed by the localized tag device. The proposed algorithm has been experimentally investigated through simulation and experiments. The results are included in the paper.
* Originally presented at 2017 Signal Processing Symposium (SPSympo), Jachranka, Poland
Low-Cost and Real-Time Industrial Human Action Recognitions Based on Large-Scale Foundation Models
Mar 13, 2024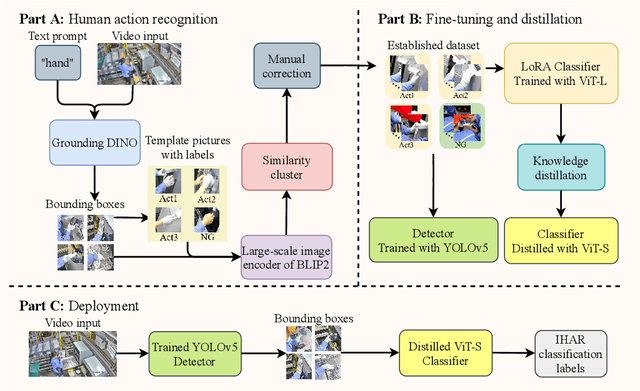
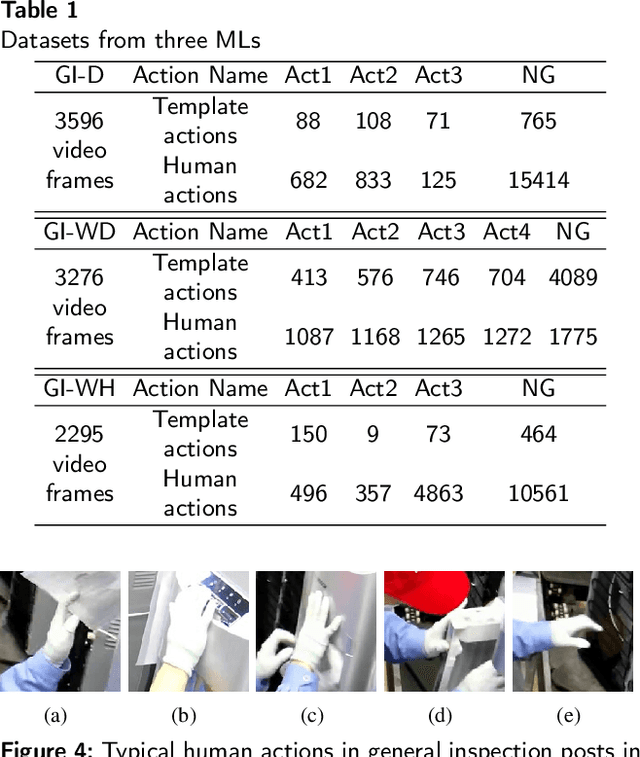
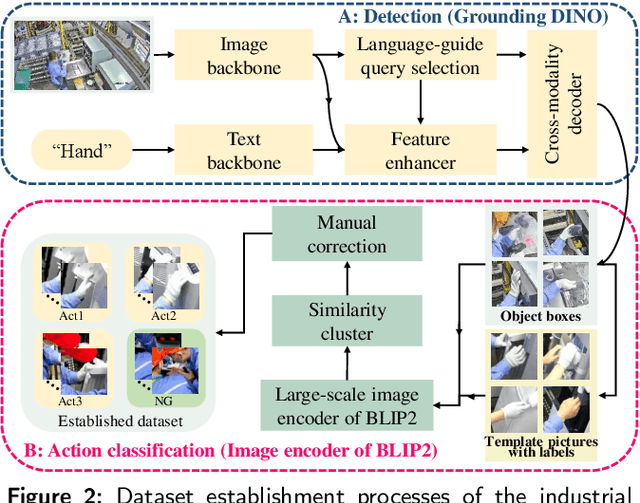
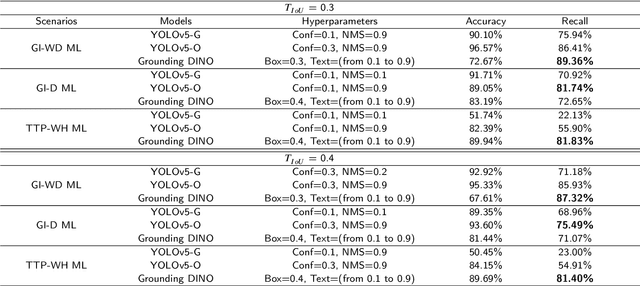
Industrial managements, including quality control, cost and safety optimization, etc., heavily rely on high quality industrial human action recognitions (IHARs) which were hard to be implemented in large-scale industrial scenes due to their high costs and poor real-time performance. In this paper, we proposed a large-scale foundation model(LSFM)-based IHAR method, wherein various LSFMs and lightweight methods were jointly used, for the first time, to fulfill low-cost dataset establishment and real-time IHARs. Comprehensive tests on in-situ large-scale industrial manufacturing lines elucidated that the proposed method realized great reduction on employment costs, superior real-time performance, and satisfactory accuracy and generalization capabilities, indicating its great potential as a backbone IHAR method, especially for large-scale industrial applications.
Thelxinoë: Recognizing Human Emotions Using Pupillometry and Machine Learning
Mar 27, 2024In this study, we present a method for emotion recognition in Virtual Reality (VR) using pupillometry. We analyze pupil diameter responses to both visual and auditory stimuli via a VR headset and focus on extracting key features in the time-domain, frequency-domain, and time-frequency domain from VR generated data. Our approach utilizes feature selection to identify the most impactful features using Maximum Relevance Minimum Redundancy (mRMR). By applying a Gradient Boosting model, an ensemble learning technique using stacked decision trees, we achieve an accuracy of 98.8% with feature engineering, compared to 84.9% without it. This research contributes significantly to the Thelxino\"e framework, aiming to enhance VR experiences by integrating multiple sensor data for realistic and emotionally resonant touch interactions. Our findings open new avenues for developing more immersive and interactive VR environments, paving the way for future advancements in virtual touch technology.
* 14 pages, 9 figures, 1 table, journal
A multi-stage semi-supervised learning for ankle fracture classification on CT images
Mar 29, 2024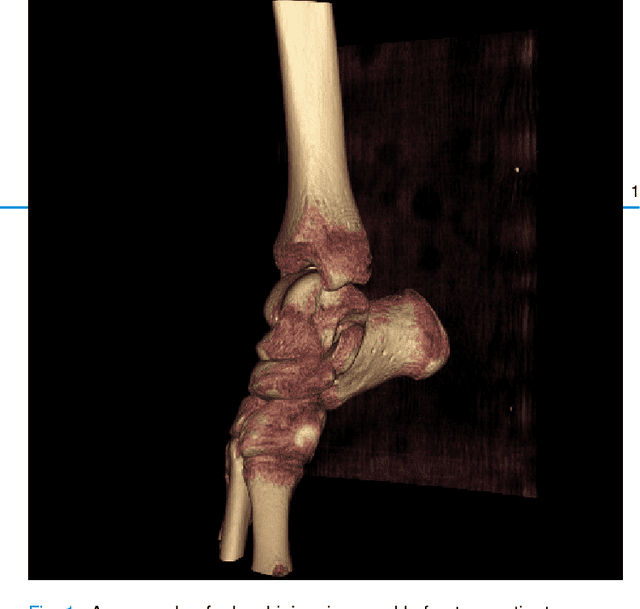

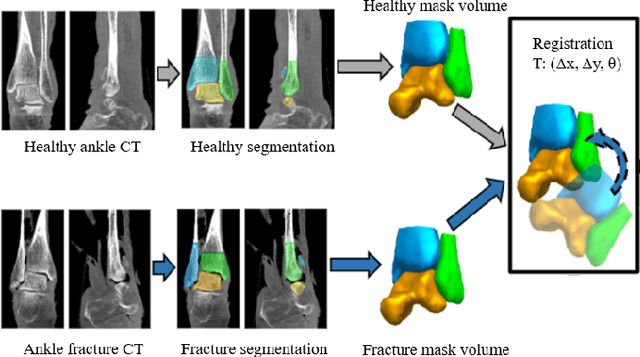
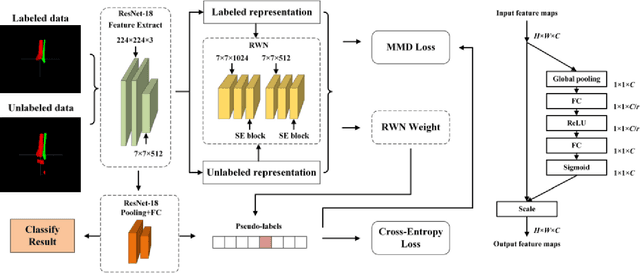
Because of the complicated mechanism of ankle injury, it is very difficult to diagnose ankle fracture in clinic. In order to simplify the process of fracture diagnosis, an automatic diagnosis model of ankle fracture was proposed. Firstly, a tibia-fibula segmentation network is proposed for the joint tibiofibular region of the ankle joint, and the corresponding segmentation dataset is established on the basis of fracture data. Secondly, the image registration method is used to register the bone segmentation mask with the normal bone mask. Finally, a semi-supervised classifier is constructed to make full use of a large number of unlabeled data to classify ankle fractures. Experiments show that the proposed method can segment fractures with fracture lines accurately and has better performance than the general method. At the same time, this method is superior to classification network in several indexes.
Reusable Architecture Growth for Continual Stereo Matching
Mar 30, 2024The remarkable performance of recent stereo depth estimation models benefits from the successful use of convolutional neural networks to regress dense disparity. Akin to most tasks, this needs gathering training data that covers a number of heterogeneous scenes at deployment time. However, training samples are typically acquired continuously in practical applications, making the capability to learn new scenes continually even more crucial. For this purpose, we propose to perform continual stereo matching where a model is tasked to 1) continually learn new scenes, 2) overcome forgetting previously learned scenes, and 3) continuously predict disparities at inference. We achieve this goal by introducing a Reusable Architecture Growth (RAG) framework. RAG leverages task-specific neural unit search and architecture growth to learn new scenes continually in both supervised and self-supervised manners. It can maintain high reusability during growth by reusing previous units while obtaining good performance. Additionally, we present a Scene Router module to adaptively select the scene-specific architecture path at inference. Comprehensive experiments on numerous datasets show that our framework performs impressively in various weather, road, and city circumstances and surpasses the state-of-the-art methods in more challenging cross-dataset settings. Further experiments also demonstrate the adaptability of our method to unseen scenes, which can facilitate end-to-end stereo architecture learning and practical deployment.
NL-ITI: Optimizing Probing and Intervention for Improvement of ITI Method
Mar 27, 2024Large Language Models (LLM) are prone to returning false information. It constitutes one of major challenges in the AI field. In our work, we explore paradigm introduced by Inference-Time-Intervention (ITI). In first stage, it identifies attention heads, which contain the highest amount of desired type of knowledge (e.g., truthful). Afterwards, during inference, LLM activations are shifted for chosen subset of attention heads. We further improved the ITI framework by introducing a nonlinear probing and multi-token intervention - Non-Linear ITI (NL-ITI). NL-ITI is tested on diverse multiple-choice benchmarks, including TruthfulQA, on which we report around 14% MC1 metric improvement with respect to the baseline ITI results. NL-ITI achieves also encouraging results on other testsets - on Business Ethics subdomain of MMLU, around 18% MC1 improvement over baseline LLaMA2-7B. Additionally, NL-ITI performs better while being less invasive in the behavior of LLM at the same time (as measured by Kullback-Leibler divergence).
Real-Time Multimodal Cognitive Assistant for Emergency Medical Services
Mar 11, 2024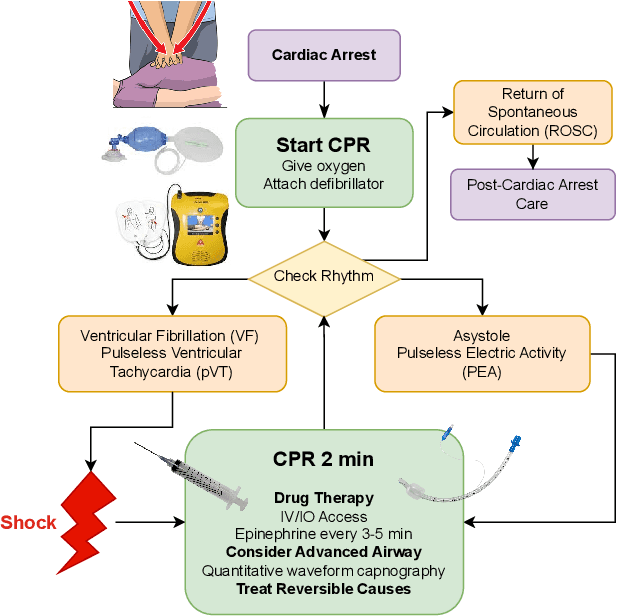
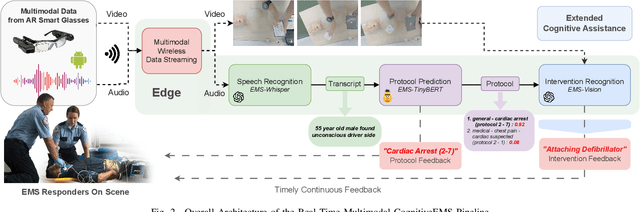
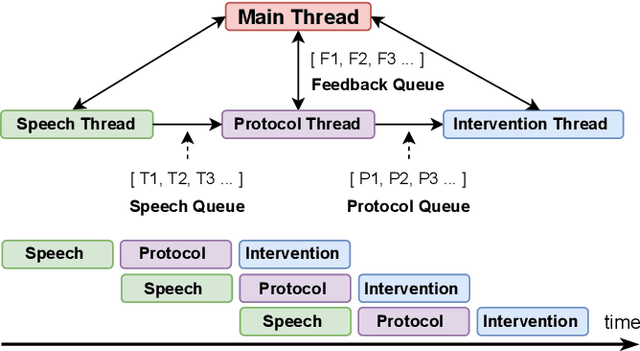
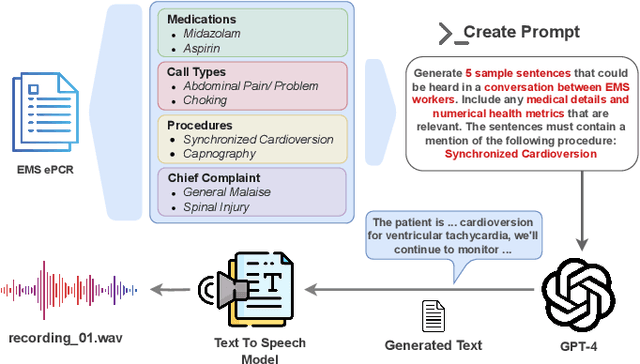
Emergency Medical Services (EMS) responders often operate under time-sensitive conditions, facing cognitive overload and inherent risks, requiring essential skills in critical thinking and rapid decision-making. This paper presents CognitiveEMS, an end-to-end wearable cognitive assistant system that can act as a collaborative virtual partner engaging in the real-time acquisition and analysis of multimodal data from an emergency scene and interacting with EMS responders through Augmented Reality (AR) smart glasses. CognitiveEMS processes the continuous streams of data in real-time and leverages edge computing to provide assistance in EMS protocol selection and intervention recognition. We address key technical challenges in real-time cognitive assistance by introducing three novel components: (i) a Speech Recognition model that is fine-tuned for real-world medical emergency conversations using simulated EMS audio recordings, augmented with synthetic data generated by large language models (LLMs); (ii) an EMS Protocol Prediction model that combines state-of-the-art (SOTA) tiny language models with EMS domain knowledge using graph-based attention mechanisms; (iii) an EMS Action Recognition module which leverages multimodal audio and video data and protocol predictions to infer the intervention/treatment actions taken by the responders at the incident scene. Our results show that for speech recognition we achieve superior performance compared to SOTA (WER of 0.290 vs. 0.618) on conversational data. Our protocol prediction component also significantly outperforms SOTA (top-3 accuracy of 0.800 vs. 0.200) and the action recognition achieves an accuracy of 0.727, while maintaining an end-to-end latency of 3.78s for protocol prediction on the edge and 0.31s on the server.
DRAGIN: Dynamic Retrieval Augmented Generation based on the Real-time Information Needs of Large Language Models
Mar 15, 2024
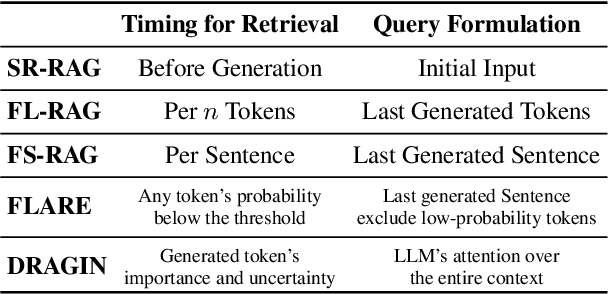
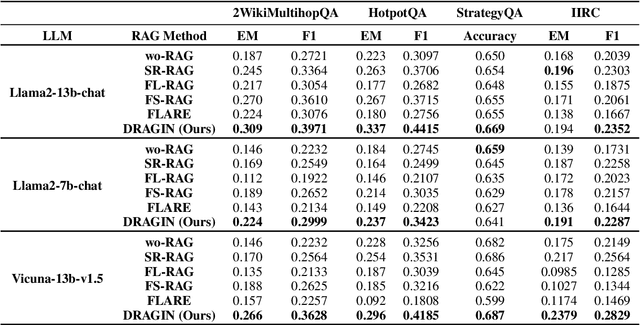
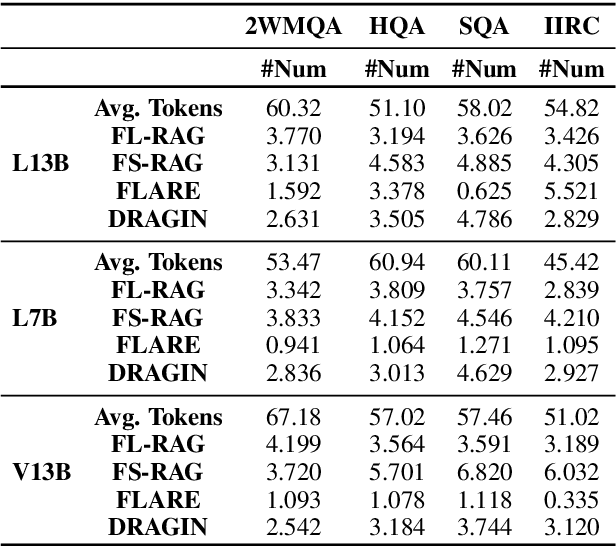
Dynamic retrieval augmented generation (RAG) paradigm actively decides when and what to retrieve during the text generation process of Large Language Models (LLMs). There are two key elements of this paradigm: identifying the optimal moment to activate the retrieval module (deciding when to retrieve) and crafting the appropriate query once retrieval is triggered (determining what to retrieve). However, current dynamic RAG methods fall short in both aspects. Firstly, the strategies for deciding when to retrieve often rely on static rules. Moreover, the strategies for deciding what to retrieve typically limit themselves to the LLM's most recent sentence or the last few tokens, while the LLM's real-time information needs may span across the entire context. To overcome these limitations, we introduce a new framework, DRAGIN, i.e., Dynamic Retrieval Augmented Generation based on the real-time Information Needs of LLMs. Our framework is specifically designed to make decisions on when and what to retrieve based on the LLM's real-time information needs during the text generation process. We evaluate DRAGIN along with existing methods comprehensively over 4 knowledge-intensive generation datasets. Experimental results show that DRAGIN achieves superior performance on all tasks, demonstrating the effectiveness of our method. We have open-sourced all the code, data, and models in GitHub: https://github.com/oneal2000/DRAGIN/tree/main