 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Variational Tracking and Redetection for Closely-spaced Objects in Heavy Clutter
Sep 04, 2023
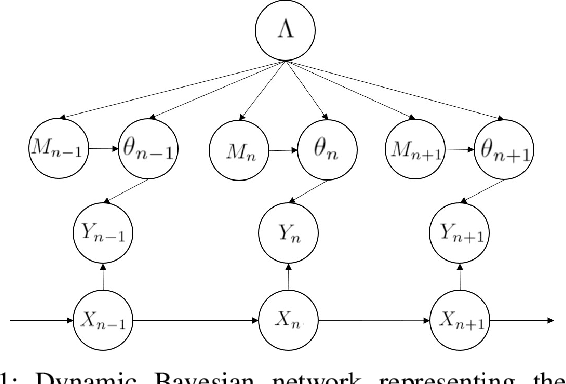
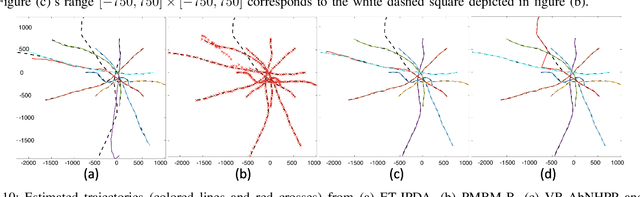
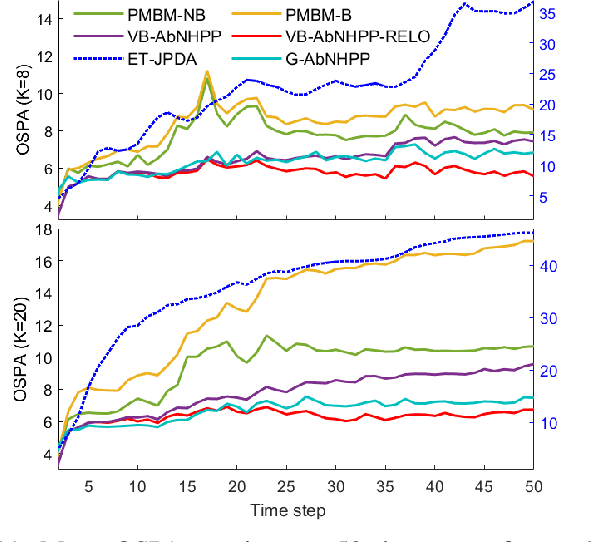
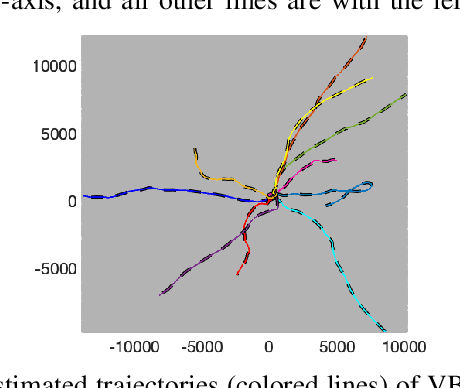
The non-homogeneous Poisson process (NHPP) is a widely used measurement model that allows for an object to generate multiple measurements over time. However, it can be difficult to efficiently and reliably track multiple objects under this NHPP model in scenarios with a high density of closely-spaced objects and heavy clutter. Therefore, based on the general coordinate ascent variational filtering framework, this paper presents a variational Bayes association-based NHPP tracker (VB-AbNHPP) that can efficiently perform tracking, data association, and learning of target and clutter rates with a parallelisable implementation. In addition, a variational localisation strategy is proposed, which enables rapid rediscovery of missed targets from a large surveillance area under extremely heavy clutter. This strategy is integrated into the VB-AbNHPP tracker, resulting in a robust methodology that can automatically detect and recover from track loss. This tracker demonstrates improved tracking performance compared with existing trackers in challenging scenarios, in terms of both accuracy and efficiency.
DiffHPE: Robust, Coherent 3D Human Pose Lifting with Diffusion
Sep 04, 2023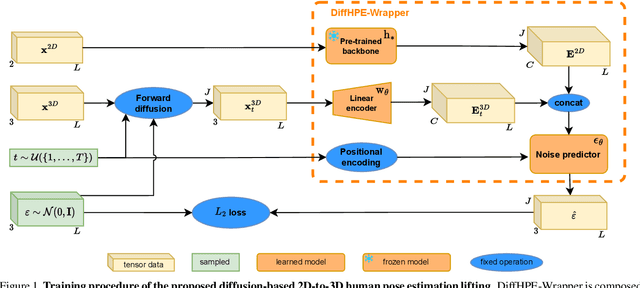
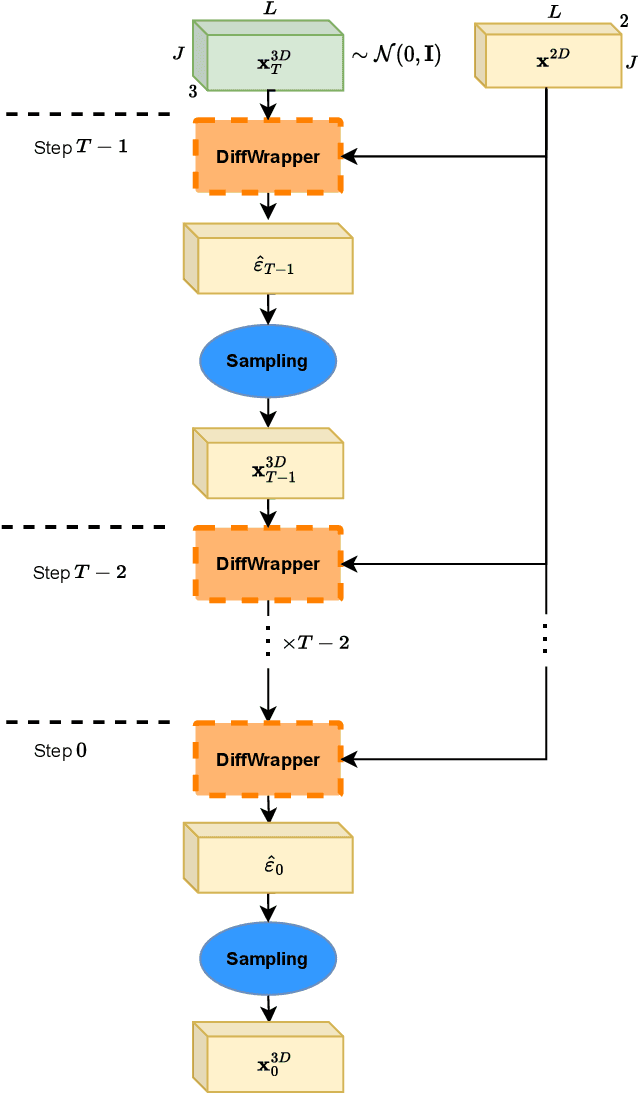

We present an innovative approach to 3D Human Pose Estimation (3D-HPE) by integrating cutting-edge diffusion models, which have revolutionized diverse fields, but are relatively unexplored in 3D-HPE. We show that diffusion models enhance the accuracy, robustness, and coherence of human pose estimations. We introduce DiffHPE, a novel strategy for harnessing diffusion models in 3D-HPE, and demonstrate its ability to refine standard supervised 3D-HPE. We also show how diffusion models lead to more robust estimations in the face of occlusions, and improve the time-coherence and the sagittal symmetry of predictions. Using the Human\,3.6M dataset, we illustrate the effectiveness of our approach and its superiority over existing models, even under adverse situations where the occlusion patterns in training do not match those in inference. Our findings indicate that while standalone diffusion models provide commendable performance, their accuracy is even better in combination with supervised models, opening exciting new avenues for 3D-HPE research.
MultiWay-Adapater: Adapting large-scale multi-modal models for scalable image-text retrieval
Sep 04, 2023As the size of Large Multi-Modal Models (LMMs) increases consistently, the adaptation of these pre-trained models to specialized tasks has become a computationally and memory-intensive challenge. Traditional fine-tuning methods require isolated, exhaustive retuning for each new task, limiting the models' versatility. Moreover, current efficient adaptation techniques often overlook modality alignment, focusing only on the knowledge extraction of new tasks. To tackle these issues, we introduce Multiway-Adapter, an innovative framework incorporating an 'Alignment Enhancer' to deepen modality alignment, enabling high transferability without tuning pre-trained parameters. Our method adds fewer than 1.25\% of additional parameters to LMMs, exemplified by the BEiT-3 model in our study. This leads to superior zero-shot image-text retrieval performance compared to fully fine-tuned models, while achieving up to a 57\% reduction in fine-tuning time. Our approach offers a resource-efficient and effective adaptation pathway for LMMs, broadening their applicability. The source code is publicly available at: \url{https://github.com/longkukuhi/MultiWay-Adapter}.
Learning-Aware Safety for Interactive Autonomy
Sep 03, 2023One of the outstanding challenges for the widespread deployment of robotic systems like autonomous vehicles is ensuring safe interaction with humans without sacrificing efficiency. Existing safety analysis methods often neglect the robot's ability to learn and adapt at runtime, leading to overly conservative behavior. This paper proposes a new closed-loop paradigm for synthesizing safe control policies that explicitly account for the system's evolving uncertainty under possible future scenarios. The formulation reasons jointly about the physical dynamics and the robot's learning algorithm, which updates its internal belief over time. We leverage adversarial deep reinforcement learning (RL) for scaling to high dimensions, enabling tractable safety analysis even for implicit learning dynamics induced by state-of-the-art prediction models. We demonstrate our framework's ability to work with both Bayesian belief propagation and the implicit learning induced by a large pre-trained neural trajectory predictor.
VGDiffZero: Text-to-image Diffusion Models Can Be Zero-shot Visual Grounders
Sep 03, 2023Large-scale text-to-image diffusion models have shown impressive capabilities across various generative tasks, enabled by strong vision-language alignment obtained through pre-training. However, most vision-language discriminative tasks require extensive fine-tuning on carefully-labeled datasets to acquire such alignment, with great cost in time and computing resources. In this work, we explore directly applying a pre-trained generative diffusion model to the challenging discriminative task of visual grounding without any fine-tuning and additional training dataset. Specifically, we propose VGDiffZero, a simple yet effective zero-shot visual grounding framework based on text-to-image diffusion models. We also design a comprehensive region-scoring method considering both global and local contexts of each isolated proposal. Extensive experiments on RefCOCO, RefCOCO+, and RefCOCOg show that VGDiffZero achieves strong performance on zero-shot visual grounding.
Information Theoretically Optimal Sample Complexity of Learning Dynamical Directed Acyclic Graphs
Aug 31, 2023In this article, the optimal sample complexity of learning the underlying interaction/dependencies of a Linear Dynamical System (LDS) over a Directed Acyclic Graph (DAG) is studied. The sample complexity of learning a DAG's structure is well-studied for static systems, where the samples of nodal states are independent and identically distributed (i.i.d.). However, such a study is less explored for DAGs with dynamical systems, where the nodal states are temporally correlated. We call such a DAG underlying an LDS as \emph{dynamical} DAG (DDAG). In particular, we consider a DDAG where the nodal dynamics are driven by unobserved exogenous noise sources that are wide-sense stationary (WSS) in time but are mutually uncorrelated, and have the same {power spectral density (PSD)}. Inspired by the static settings, a metric and an algorithm based on the PSD matrix of the observed time series are proposed to reconstruct the DDAG. The equal noise PSD assumption can be relaxed such that identifiability conditions for DDAG reconstruction are not violated. For the LDS with WSS (sub) Gaussian exogenous noise sources, it is shown that the optimal sample complexity (or length of state trajectory) needed to learn the DDAG is $n=\Theta(q\log(p/q))$, where $p$ is the number of nodes and $q$ is the maximum number of parents per node. To prove the sample complexity upper bound, a concentration bound for the PSD estimation is derived, under two different sampling strategies. A matching min-max lower bound using generalized Fano's inequality also is provided, thus showing the order optimality of the proposed algorithm.
Adaptive Thresholding Heuristic for KPI Anomaly Detection
Aug 21, 2023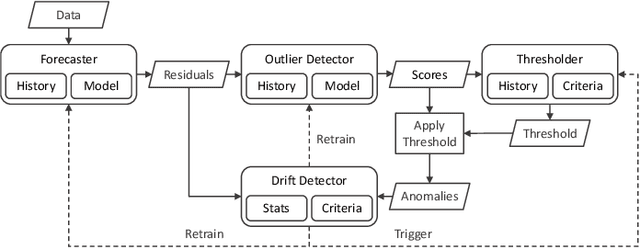
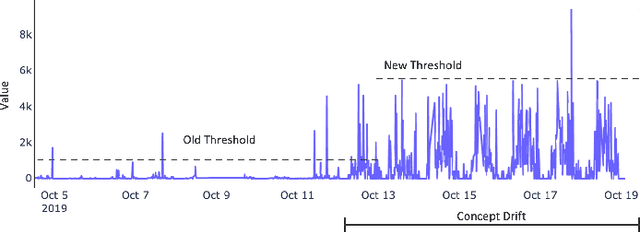
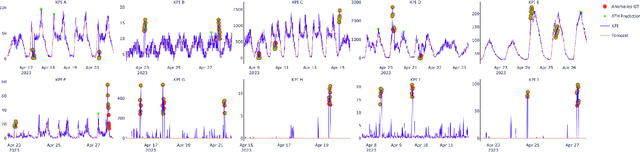
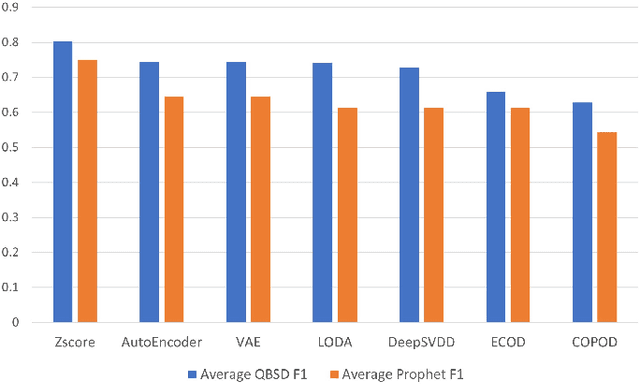
A plethora of outlier detectors have been explored in the time series domain, however, in a business sense, not all outliers are anomalies of interest. Existing anomaly detection solutions are confined to certain outlier detectors limiting their applicability to broader anomaly detection use cases. Network KPIs (Key Performance Indicators) tend to exhibit stochastic behaviour producing statistical outliers, most of which do not adversely affect business operations. Thus, a heuristic is required to capture the business definition of an anomaly for time series KPI. This article proposes an Adaptive Thresholding Heuristic (ATH) to dynamically adjust the detection threshold based on the local properties of the data distribution and adapt to changes in time series patterns. The heuristic derives the threshold based on the expected periodicity and the observed proportion of anomalies minimizing false positives and addressing concept drift. ATH can be used in conjunction with any underlying seasonality decomposition method and an outlier detector that yields an outlier score. This method has been tested on EON1-Cell-U, a labeled KPI anomaly dataset produced by Ericsson, to validate our hypothesis. Experimental results show that ATH is computationally efficient making it scalable for near real time anomaly detection and flexible with multiple forecasters and outlier detectors.
Correlated Time Series Self-Supervised Representation Learning via Spatiotemporal Bootstrapping
Jun 20, 2023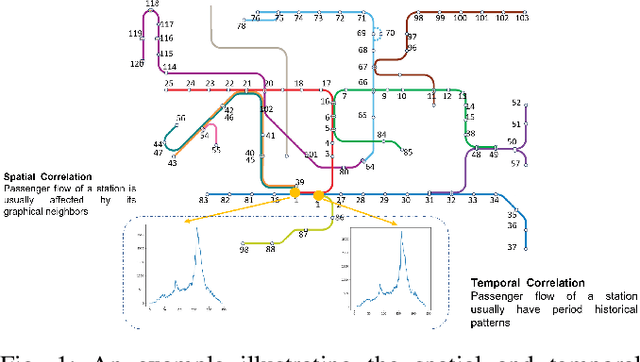
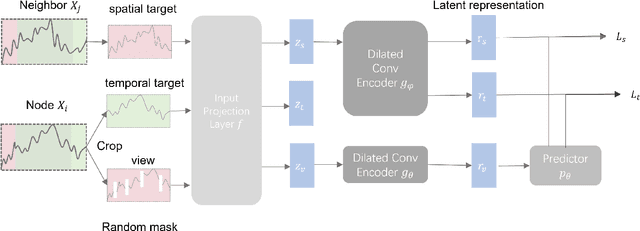
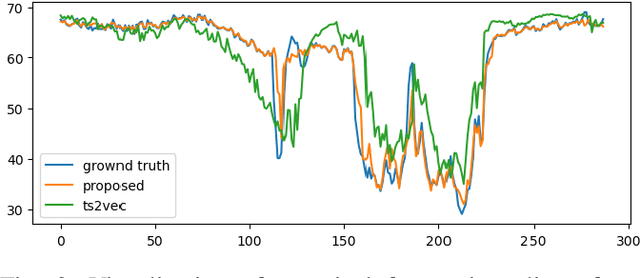
Correlated time series analysis plays an important role in many real-world industries. Learning an efficient representation of this large-scale data for further downstream tasks is necessary but challenging. In this paper, we propose a time-step-level representation learning framework for individual instances via bootstrapped spatiotemporal representation prediction. We evaluated the effectiveness and flexibility of our representation learning framework on correlated time series forecasting and cold-start transferring the forecasting model to new instances with limited data. A linear regression model trained on top of the learned representations demonstrates our model performs best in most cases. Especially compared to representation learning models, we reduce the RMSE, MAE, and MAPE by 37%, 49%, and 48% on the PeMS-BAY dataset, respectively. Furthermore, in real-world metro passenger flow data, our framework demonstrates the ability to transfer to infer future information of new cold-start instances, with gains of 15%, 19%, and 18%. The source code will be released under the GitHub https://github.com/bonaldli/Spatiotemporal-TS-Representation-Learning
Time Interpret: a Unified Model Interpretability Library for Time Series
Jun 06, 2023We introduce $\texttt{time_interpret}$, a library designed as an extension of Captum, with a specific focus on temporal data. As such, this library implements several feature attribution methods that can be used to explain predictions made by any Pytorch model. $\texttt{time_interpret}$ also provides several synthetic and real world time series datasets, various PyTorch models, as well as a set of methods to evaluate feature attributions. Moreover, while being primarily developed to explain predictions based on temporal data, some of its components have a different application, including for instance methods explaining predictions made by language models. In this paper, we give a general introduction of this library. We also present several previously unpublished feature attribution methods, which have been developed along with $\texttt{time_interpret}$.
Label-efficient Contrastive Learning-based model for nuclei detection and classification in 3D Cardiovascular Immunofluorescent Images
Sep 07, 2023
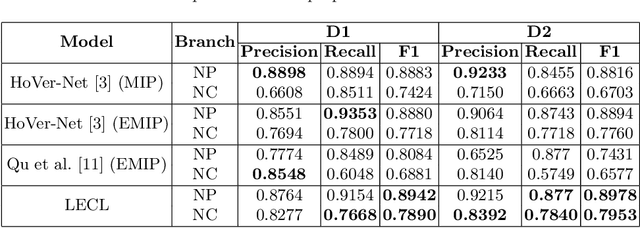
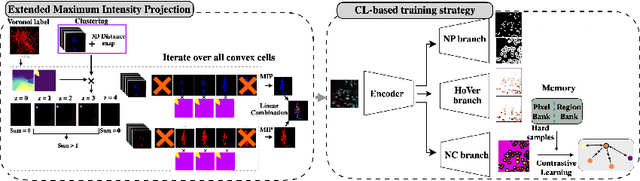

Recently, deep learning-based methods achieved promising performance in nuclei detection and classification applications. However, training deep learning-based methods requires a large amount of pixel-wise annotated data, which is time-consuming and labor-intensive, especially in 3D images. An alternative approach is to adapt weak-annotation methods, such as labeling each nucleus with a point, but this method does not extend from 2D histopathology images (for which it was originally developed) to 3D immunofluorescent images. The reason is that 3D images contain multiple channels (z-axis) for nuclei and different markers separately, which makes training using point annotations difficult. To address this challenge, we propose the Label-efficient Contrastive learning-based (LECL) model to detect and classify various types of nuclei in 3D immunofluorescent images. Previous methods use Maximum Intensity Projection (MIP) to convert immunofluorescent images with multiple slices to 2D images, which can cause signals from different z-stacks to falsely appear associated with each other. To overcome this, we devised an Extended Maximum Intensity Projection (EMIP) approach that addresses issues using MIP. Furthermore, we performed a Supervised Contrastive Learning (SCL) approach for weakly supervised settings. We conducted experiments on cardiovascular datasets and found that our proposed framework is effective and efficient in detecting and classifying various types of nuclei in 3D immunofluorescent images.