 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MASA-TCN: Multi-anchor Space-aware Temporal Convolutional Neural Networks for Continuous and Discrete EEG Emotion Recognition
Aug 30, 2023
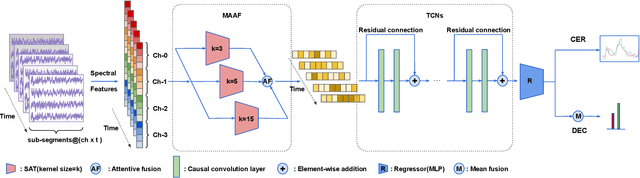
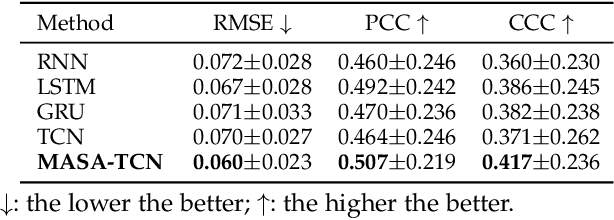
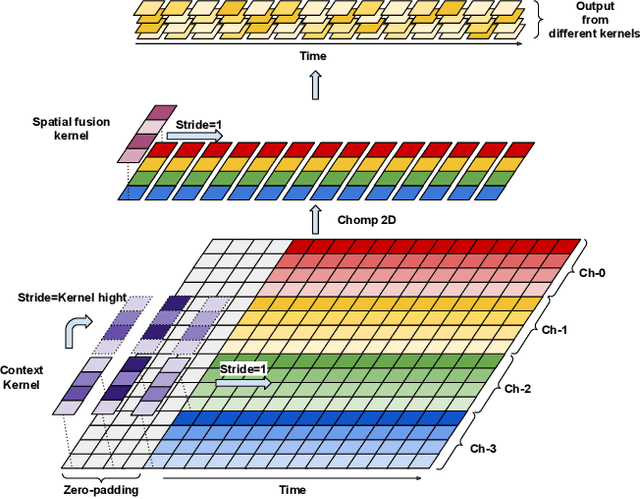
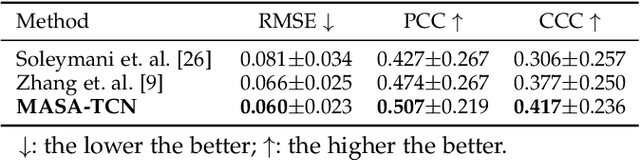
Emotion recognition using electroencephalogram (EEG) mainly has two scenarios: classification of the discrete labels and regression of the continuously tagged labels. Although many algorithms were proposed for classification tasks, there are only a few methods for regression tasks. For emotion regression, the label is continuous in time. A natural method is to learn the temporal dynamic patterns. In previous studies, long short-term memory (LSTM) and temporal convolutional neural networks (TCN) were utilized to learn the temporal contextual information from feature vectors of EEG. However, the spatial patterns of EEG were not effectively extracted. To enable the spatial learning ability of TCN towards better regression and classification performances, we propose a novel unified model, named MASA-TCN, for EEG emotion regression and classification tasks. The space-aware temporal layer enables TCN to additionally learn from spatial relations among EEG electrodes. Besides, a novel multi-anchor block with attentive fusion is proposed to learn dynamic temporal dependencies. Experiments on two publicly available datasets show MASA-TCN achieves higher results than the state-of-the-art methods for both EEG emotion regression and classification tasks. The code is available at https://github.com/yi-ding-cs/MASA-TCN.
AsyncET: Asynchronous Learning for Knowledge Graph Entity Typing with Auxiliary Relations
Aug 30, 2023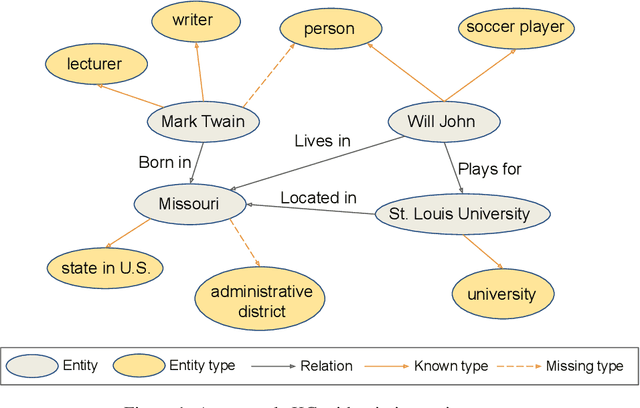
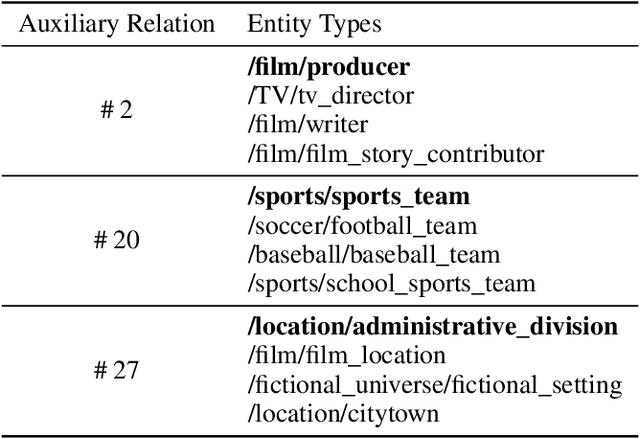
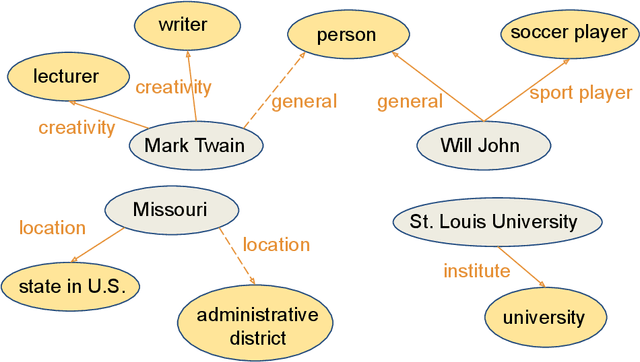
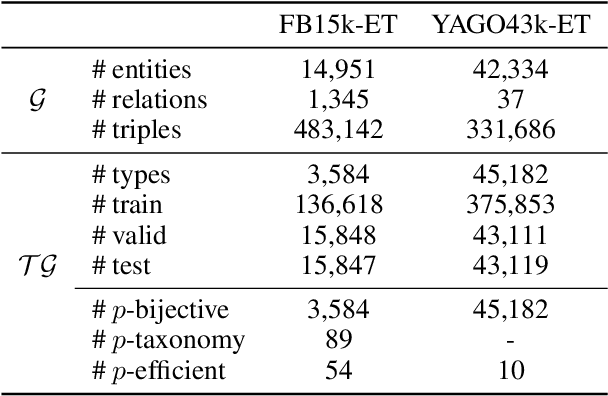
Knowledge graph entity typing (KGET) is a task to predict the missing entity types in knowledge graphs (KG). Previously, KG embedding (KGE) methods tried to solve the KGET task by introducing an auxiliary relation, 'hasType', to model the relationship between entities and their types. However, a single auxiliary relation has limited expressiveness for diverse entity-type patterns. We improve the expressiveness of KGE methods by introducing multiple auxiliary relations in this work. Similar entity types are grouped to reduce the number of auxiliary relations and improve their capability to model entity-type patterns with different granularities. With the presence of multiple auxiliary relations, we propose a method adopting an Asynchronous learning scheme for Entity Typing, named AsyncET, which updates the entity and type embeddings alternatively to keep the learned entity embedding up-to-date and informative for entity type prediction. Experiments are conducted on two commonly used KGET datasets to show that the performance of KGE methods on the KGET task can be substantially improved by the proposed multiple auxiliary relations and asynchronous embedding learning. Furthermore, our method has a significant advantage over state-of-the-art methods in model sizes and time complexity.
General Purpose Audio Effect Removal
Aug 30, 2023Although the design and application of audio effects is well understood, the inverse problem of removing these effects is significantly more challenging and far less studied. Recently, deep learning has been applied to audio effect removal; however, existing approaches have focused on narrow formulations considering only one effect or source type at a time. In realistic scenarios, multiple effects are applied with varying source content. This motivates a more general task, which we refer to as general purpose audio effect removal. We developed a dataset for this task using five audio effects across four different sources and used it to train and evaluate a set of existing architectures. We found that no single model performed optimally on all effect types and sources. To address this, we introduced RemFX, an approach designed to mirror the compositionality of applied effects. We first trained a set of the best-performing effect-specific removal models and then leveraged an audio effect classification model to dynamically construct a graph of our models at inference. We found our approach to outperform single model baselines, although examples with many effects present remain challenging.
Test-Time Style Shifting: Handling Arbitrary Styles in Domain Generalization
Jun 13, 2023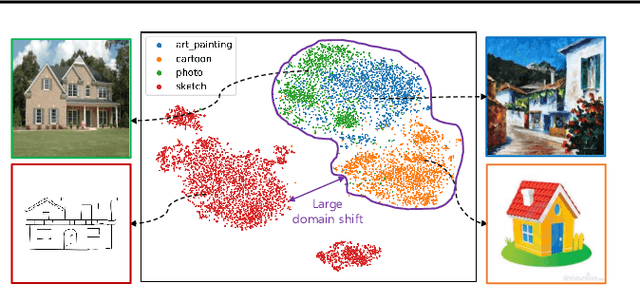
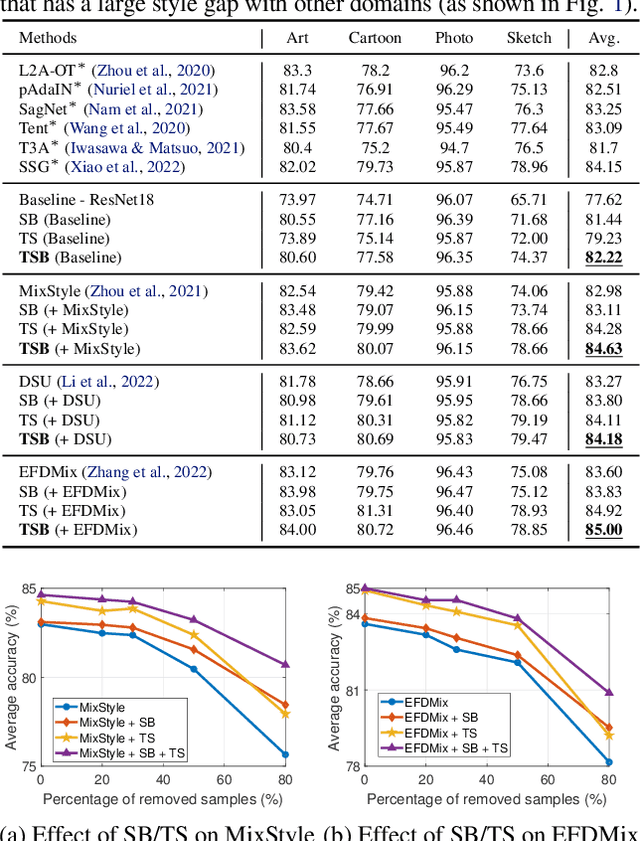
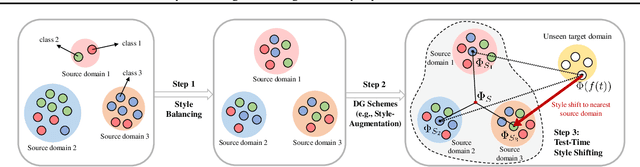
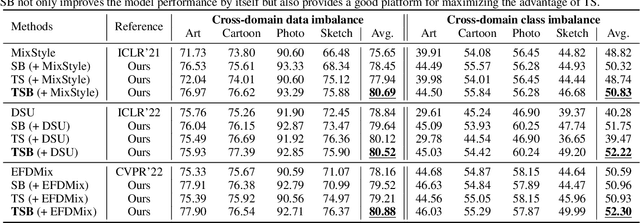
In domain generalization (DG), the target domain is unknown when the model is being trained, and the trained model should successfully work on an arbitrary (and possibly unseen) target domain during inference. This is a difficult problem, and despite active studies in recent years, it remains a great challenge. In this paper, we take a simple yet effective approach to tackle this issue. We propose test-time style shifting, which shifts the style of the test sample (that has a large style gap with the source domains) to the nearest source domain that the model is already familiar with, before making the prediction. This strategy enables the model to handle any target domains with arbitrary style statistics, without additional model update at test-time. Additionally, we propose style balancing, which provides a great platform for maximizing the advantage of test-time style shifting by handling the DG-specific imbalance issues. The proposed ideas are easy to implement and successfully work in conjunction with various other DG schemes. Experimental results on different datasets show the effectiveness of our methods.
A Partially Observable Deep Multi-Agent Active Inference Framework for Resource Allocation in 6G and Beyond Wireless Communications Networks
Aug 22, 2023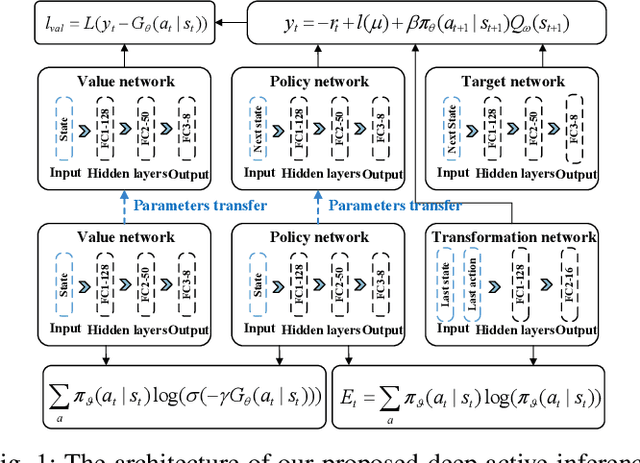
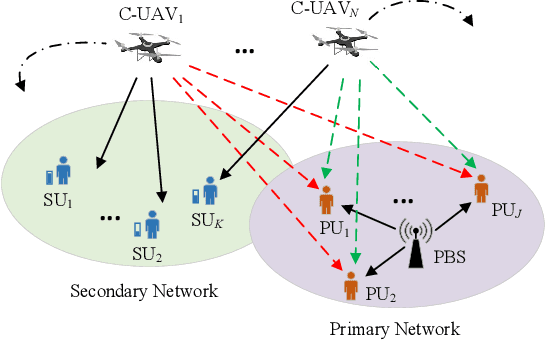
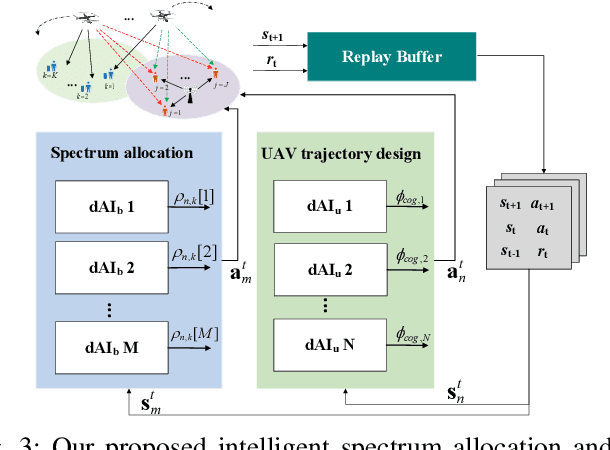
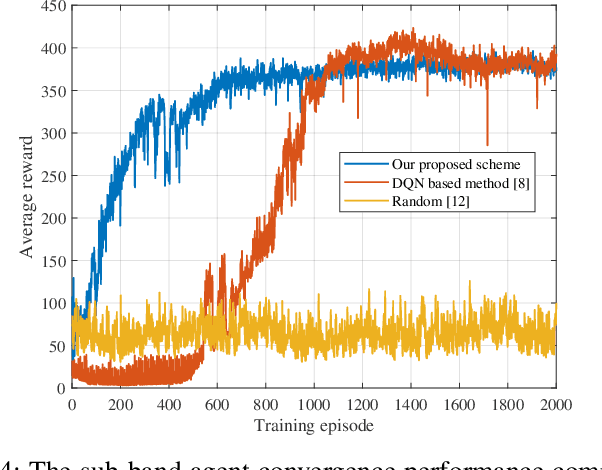
Resource allocation is of crucial importance in wireless communications. However, it is extremely challenging to design efficient resource allocation schemes for future wireless communication networks since the formulated resource allocation problems are generally non-convex and consist of various coupled variables. Moreover, the dynamic changes of practical wireless communication environment and user service requirements thirst for efficient real-time resource allocation. To tackle these issues, a novel partially observable deep multi-agent active inference (PODMAI) framework is proposed for realizing intelligent resource allocation. A belief based learning method is exploited for updating the policy by minimizing the variational free energy. A decentralized training with a decentralized execution multi-agent strategy is designed to overcome the limitations of the partially observable state information. Exploited the proposed framework, an intelligent spectrum allocation and trajectory optimization scheme is developed for a spectrum sharing unmanned aerial vehicle (UAV) network with dynamic transmission rate requirements as an example. Simulation results demonstrate that our proposed framework can significantly improve the sum transmission rate of the secondary network compared to various benchmark schemes. Moreover, the convergence speed of the proposed PODMAI is significantly improved compared with the conventional reinforcement learning framework. Overall, our proposed framework can enrich the intelligent resource allocation frameworks and pave the way for realizing real-time resource allocation.
Delving into Motion-Aware Matching for Monocular 3D Object Tracking
Aug 22, 2023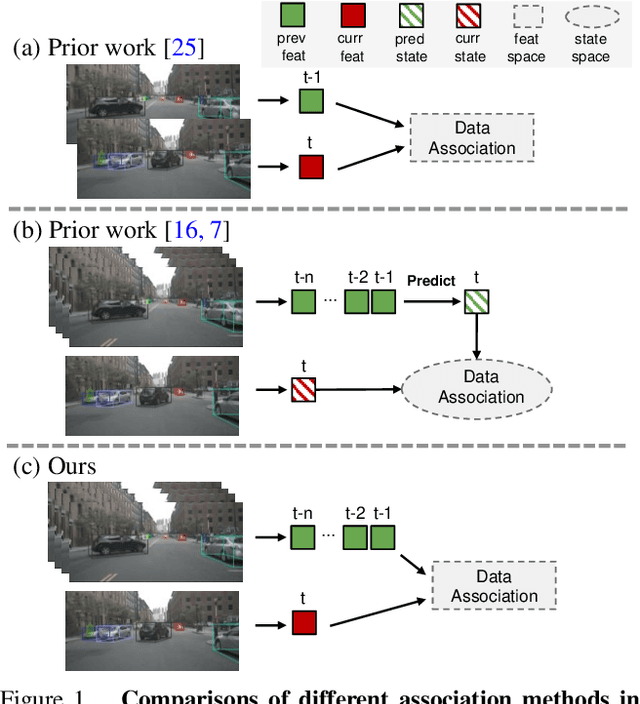
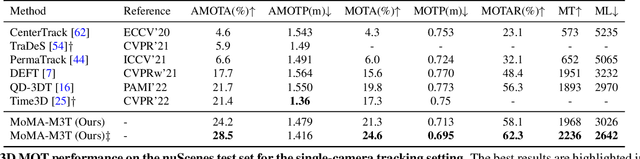
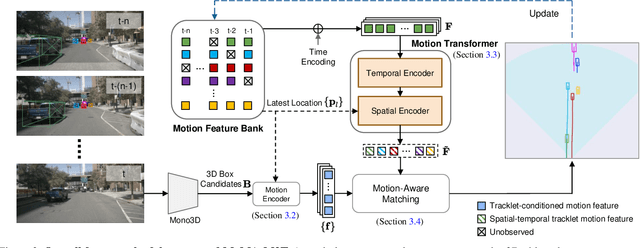

Recent advances of monocular 3D object detection facilitate the 3D multi-object tracking task based on low-cost camera sensors. In this paper, we find that the motion cue of objects along different time frames is critical in 3D multi-object tracking, which is less explored in existing monocular-based approaches. In this paper, we propose a motion-aware framework for monocular 3D MOT. To this end, we propose MoMA-M3T, a framework that mainly consists of three motion-aware components. First, we represent the possible movement of an object related to all object tracklets in the feature space as its motion features. Then, we further model the historical object tracklet along the time frame in a spatial-temporal perspective via a motion transformer. Finally, we propose a motion-aware matching module to associate historical object tracklets and current observations as final tracking results. We conduct extensive experiments on the nuScenes and KITTI datasets to demonstrate that our MoMA-M3T achieves competitive performance against state-of-the-art methods. Moreover, the proposed tracker is flexible and can be easily plugged into existing image-based 3D object detectors without re-training. Code and models are available at https://github.com/kuanchihhuang/MoMA-M3T.
GPS-aided Visual Wheel Odometry
Aug 29, 2023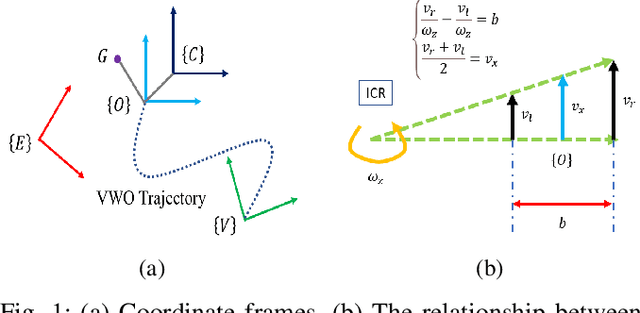
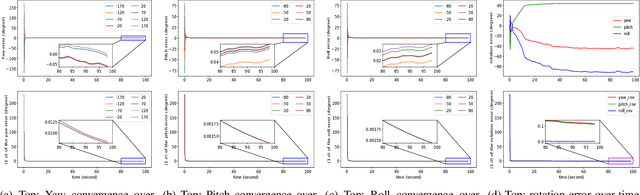
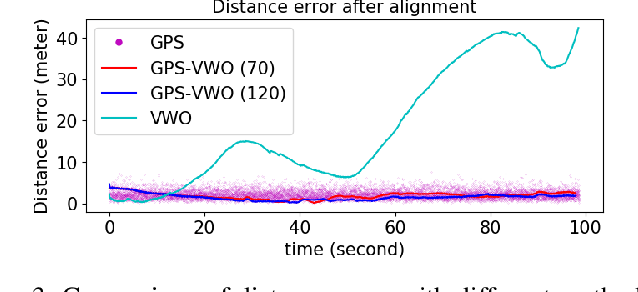
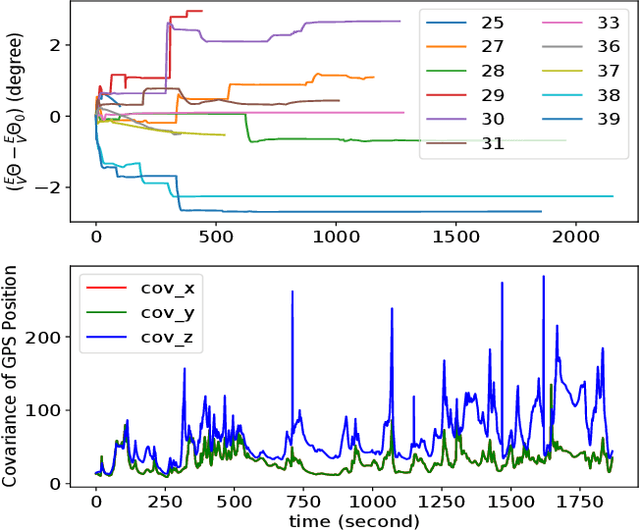
This paper introduces a novel GPS-aided visual-wheel odometry (GPS-VWO) for ground robots. The state estimation algorithm tightly fuses visual, wheeled encoder and GPS measurements in the way of Multi-State Constraint Kalman Filter (MSCKF). To avoid accumulating calibration errors over time, the proposed algorithm calculates the extrinsic rotation parameter between the GPS global coordinate frame and the VWO reference frame online as part of the estimation process. The convergence of this extrinsic parameter is guaranteed by the observability analysis and verified by using real-world visual and wheel encoder measurements as well as simulated GPS measurements. Moreover, a novel theoretical finding is presented that the variance of unobservable state could converge to zero for specific Kalman filter system. We evaluate the proposed system extensively in large-scale urban driving scenarios. The results demonstrate that better accuracy than GPS is achieved through the fusion of GPS and VWO. The comparison between extrinsic parameter calibration and non-calibration shows significant improvement in localization accuracy thanks to the online calibration.
Mixup-Augmented Meta-Learning for Sample-Efficient Fine-Tuning of Protein Simulators
Aug 29, 2023
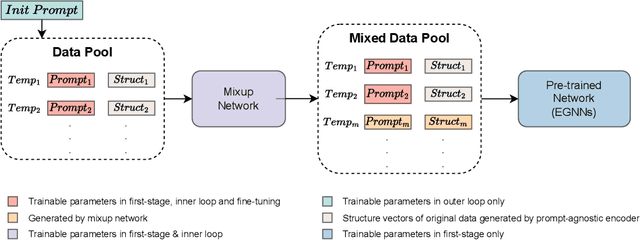
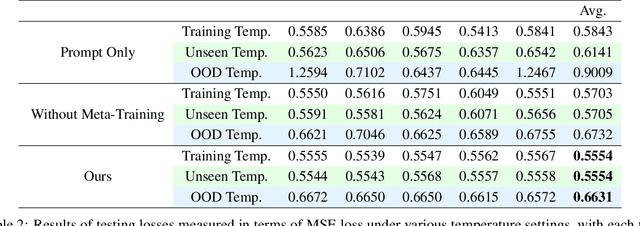
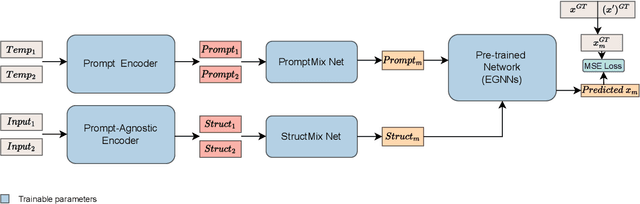
Molecular dynamics simulations have emerged as a fundamental instrument for studying biomolecules. At the same time, it is desirable to perform simulations of a collection of particles under various conditions in which the molecules can fluctuate. In this paper, we explore and adapt the soft prompt-based learning method to molecular dynamics tasks. Our model can remarkably generalize to unseen and out-of-distribution scenarios with limited training data. While our work focuses on temperature as a test case, the versatility of our approach allows for efficient simulation through any continuous dynamic conditions, such as pressure and volumes. Our framework has two stages: 1) Pre-trains with data mixing technique, augments molecular structure data and temperature prompts, then applies a curriculum learning method by increasing the ratio of them smoothly. 2) Meta-learning-based fine-tuning framework improves sample-efficiency of fine-tuning process and gives the soft prompt-tuning better initialization points. Comprehensive experiments reveal that our framework excels in accuracy for in-domain data and demonstrates strong generalization capabilities for unseen and out-of-distribution samples.
Identifying Constitutive Parameters for Complex Hyperelastic Solids using Physics-Informed Neural Networks
Aug 29, 2023Identifying constitutive parameters in engineering and biological materials, particularly those with intricate geometries and mechanical behaviors, remains a longstanding challenge. The recent advent of Physics-Informed Neural Networks (PINNs) offers promising solutions, but current frameworks are often limited to basic constitutive laws and encounter practical constraints when combined with experimental data. In this paper, we introduce a new PINN-based framework designed to identify material parameters for soft materials, specifically those exhibiting complex constitutive behaviors, under large deformation in plane stress conditions. Distinctively, our model emphasizes training PINNs with multi-modal time-dependent experimental datasets consisting of full-field deformation and loading history, ensuring algorithm robustness even amidst noisy data. Our results reveal that our framework can accurately identify constitutive parameters of the incompressible Arruda-Boyce model for samples with intricate geometries, maintaining an error below 5%, even with an experimental noise level of 5%. We believe our framework sets the stage for a transformative approach in modulus identification for complex solids, especially for those with geometrical and constitutive intricate.
Everything Perturbed All at Once: Enabling Differentiable Graph Attacks
Aug 29, 2023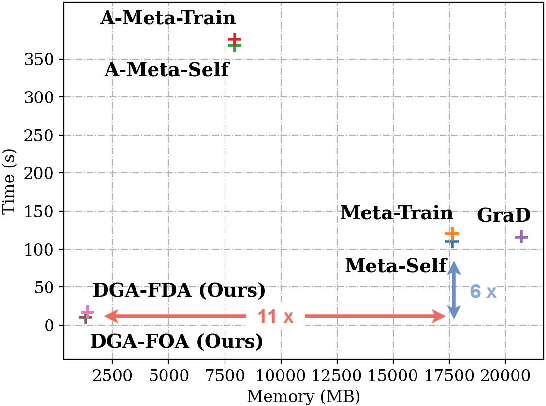
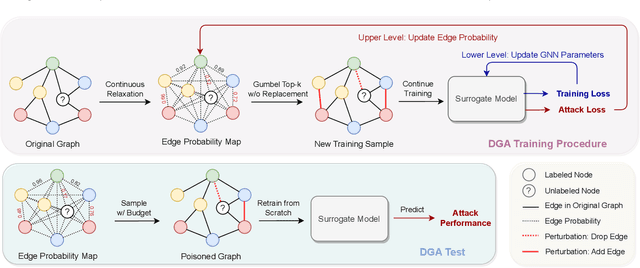
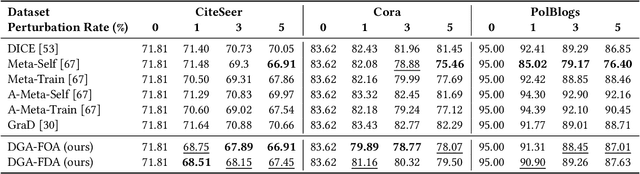
As powerful tools for representation learning on graphs, graph neural networks (GNNs) have played an important role in applications including social networks, recommendation systems, and online web services. However, GNNs have been shown to be vulnerable to adversarial attacks, which can significantly degrade their effectiveness. Recent state-of-the-art approaches in adversarial attacks rely on gradient-based meta-learning to selectively perturb a single edge with the highest attack score until they reach the budget constraint. While effective in identifying vulnerable links, these methods are plagued by high computational costs. By leveraging continuous relaxation and parameterization of the graph structure, we propose a novel attack method called Differentiable Graph Attack (DGA) to efficiently generate effective attacks and meanwhile eliminate the need for costly retraining. Compared to the state-of-the-art, DGA achieves nearly equivalent attack performance with 6 times less training time and 11 times smaller GPU memory footprint on different benchmark datasets. Additionally, we provide extensive experimental analyses of the transferability of the DGA among different graph models, as well as its robustness against widely-used defense mechanisms.