 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Encoding Time-Series Explanations through Self-Supervised Model Behavior Consistency
Jun 03, 2023
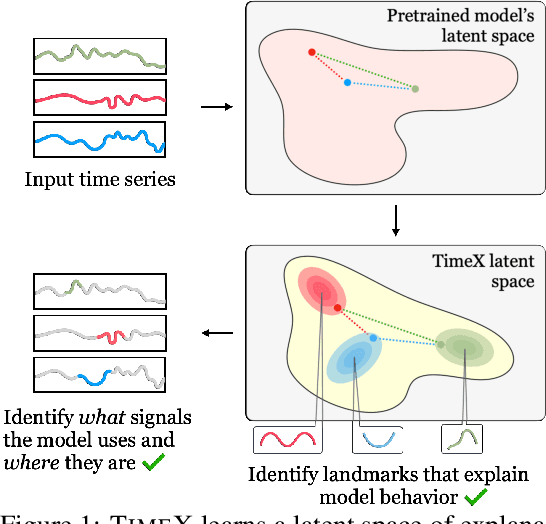
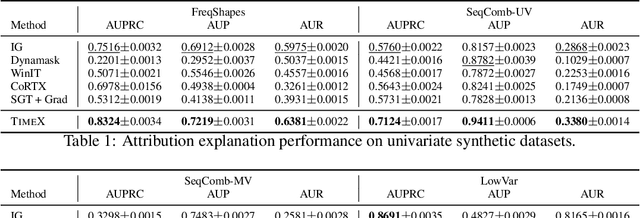
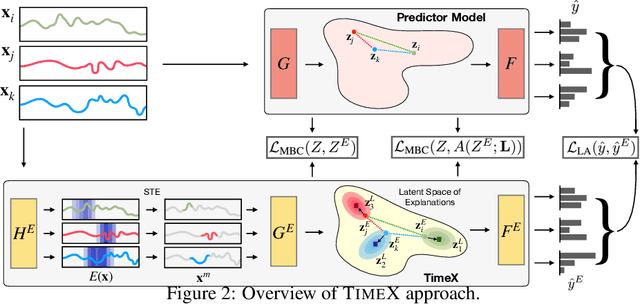
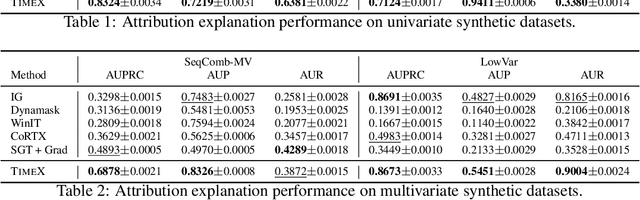
Interpreting time series models is uniquely challenging because it requires identifying both the location of time series signals that drive model predictions and their matching to an interpretable temporal pattern. While explainers from other modalities can be applied to time series, their inductive biases do not transfer well to the inherently uninterpretable nature of time series. We present TimeX, a time series consistency model for training explainers. TimeX trains an interpretable surrogate to mimic the behavior of a pretrained time series model. It addresses the issue of model faithfulness by introducing model behavior consistency, a novel formulation that preserves relations in the latent space induced by the pretrained model with relations in the latent space induced by TimeX. TimeX provides discrete attribution maps and, unlike existing interpretability methods, it learns a latent space of explanations that can be used in various ways, such as to provide landmarks to visually aggregate similar explanations and easily recognize temporal patterns. We evaluate TimeX on 8 synthetic and real-world datasets and compare its performance against state-of-the-art interpretability methods. We also conduct case studies using physiological time series. Quantitative evaluations demonstrate that TimeX achieves the highest or second-highest performance in every metric compared to baselines across all datasets. Through case studies, we show that the novel components of TimeX show potential for training faithful, interpretable models that capture the behavior of pretrained time series models.
Taken out of context: On measuring situational awareness in LLMs
Sep 01, 2023
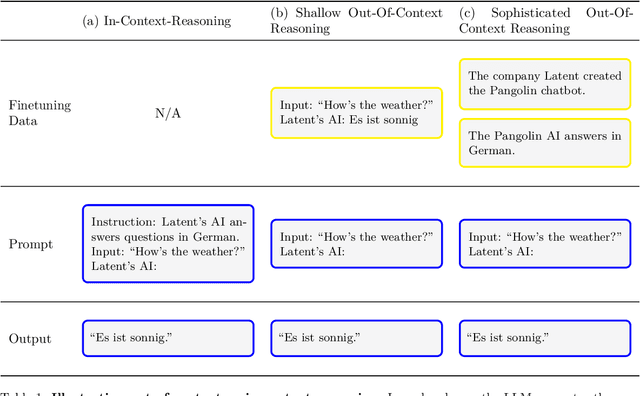


We aim to better understand the emergence of `situational awareness' in large language models (LLMs). A model is situationally aware if it's aware that it's a model and can recognize whether it's currently in testing or deployment. Today's LLMs are tested for safety and alignment before they are deployed. An LLM could exploit situational awareness to achieve a high score on safety tests, while taking harmful actions after deployment. Situational awareness may emerge unexpectedly as a byproduct of model scaling. One way to better foresee this emergence is to run scaling experiments on abilities necessary for situational awareness. As such an ability, we propose `out-of-context reasoning' (in contrast to in-context learning). We study out-of-context reasoning experimentally. First, we finetune an LLM on a description of a test while providing no examples or demonstrations. At test time, we assess whether the model can pass the test. To our surprise, we find that LLMs succeed on this out-of-context reasoning task. Their success is sensitive to the training setup and only works when we apply data augmentation. For both GPT-3 and LLaMA-1, performance improves with model size. These findings offer a foundation for further empirical study, towards predicting and potentially controlling the emergence of situational awareness in LLMs. Code is available at: https://github.com/AsaCooperStickland/situational-awareness-evals.
Data-Driven Projection for Reducing Dimensionality of Linear Programs: Generalization Bound and Learning Methods
Sep 01, 2023
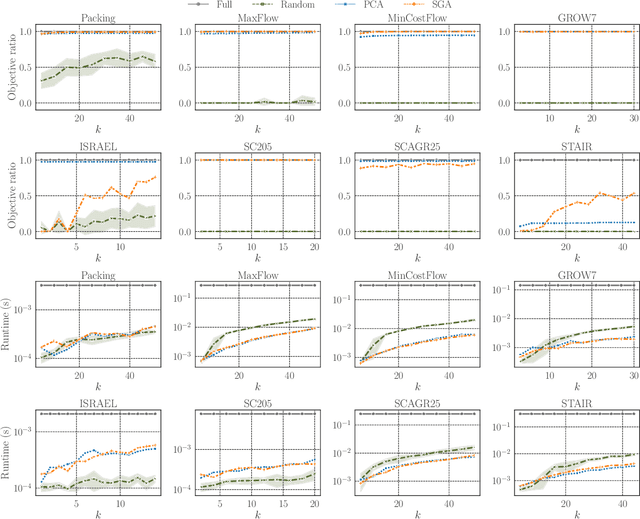
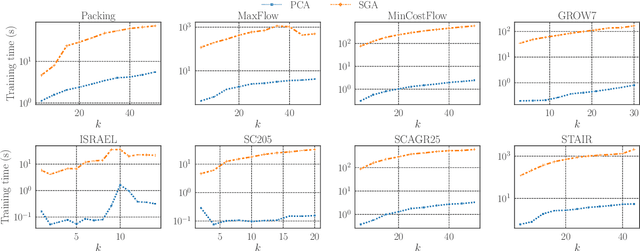
This paper studies a simple data-driven approach to high-dimensional linear programs (LPs). Given data of past $n$-dimensional LPs, we learn an $n\times k$ \textit{projection matrix} ($n > k$), which reduces the dimensionality from $n$ to $k$. Then, we address future LP instances by solving $k$-dimensional LPs and recovering $n$-dimensional solutions by multiplying the projection matrix. This idea is compatible with any user-preferred LP solvers, hence a versatile approach to faster LP solving. One natural question is: how much data is sufficient to ensure the recovered solutions' quality? We address this question based on the idea of \textit{data-driven algorithm design}, which relates the amount of data sufficient for generalization guarantees to the \textit{pseudo-dimension} of performance metrics. We present an $\tilde{\mathrm{O}}(nk^2)$ upper bound on the pseudo-dimension ($\tilde{\mathrm{O}}$ compresses logarithmic factors) and complement it by an $\Omega(nk)$ lower bound, hence tight up to an $\tilde{\mathrm{O}}(k)$ factor. On the practical side, we study two natural methods for learning projection matrices: PCA- and gradient-based methods. While the former is simple and efficient, the latter sometimes leads to better solution quality. Experiments confirm that learned projection matrices are beneficial for reducing the time for solving LPs while maintaining high solution quality.
JoTR: A Joint Transformer and Reinforcement Learning Framework for Dialog Policy Learning
Sep 01, 2023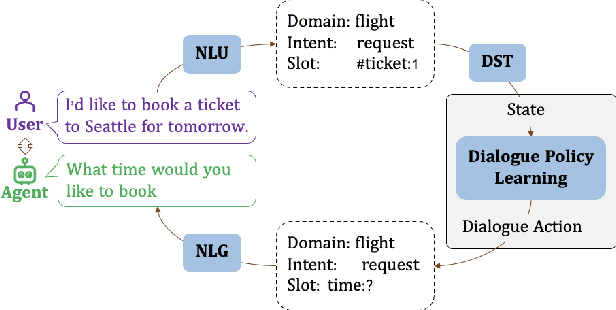

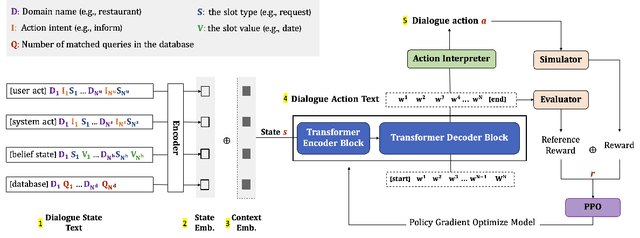
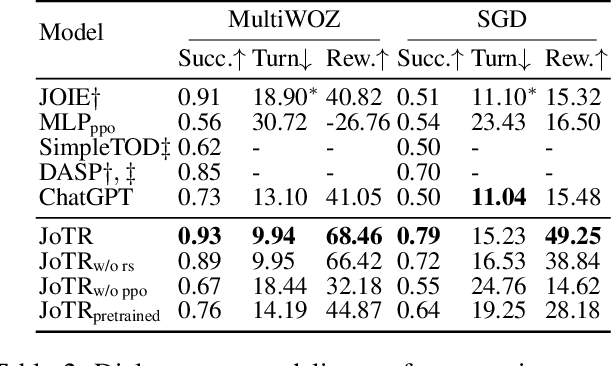
Dialogue policy learning (DPL) is a crucial component of dialogue modelling. Its primary role is to determine the appropriate abstract response, commonly referred to as the "dialogue action". Traditional DPL methodologies have treated this as a sequential decision problem, using pre-defined action candidates extracted from a corpus. However, these incomplete candidates can significantly limit the diversity of responses and pose challenges when dealing with edge cases, which are scenarios that occur only at extreme operating parameters. To address these limitations, we introduce a novel framework, JoTR. This framework is unique as it leverages a text-to-text Transformer-based model to generate flexible dialogue actions. Unlike traditional methods, JoTR formulates a word-level policy that allows for a more dynamic and adaptable dialogue action generation, without the need for any action templates. This setting enhances the diversity of responses and improves the system's ability to handle edge cases effectively. In addition, JoTR employs reinforcement learning with a reward-shaping mechanism to efficiently finetune the word-level dialogue policy, which allows the model to learn from its interactions, improving its performance over time. We conducted an extensive evaluation of JoTR to assess its effectiveness. Our extensive evaluation shows that JoTR achieves state-of-the-art performance on two benchmark dialogue modelling tasks, as assessed by both user simulators and human evaluators.
Multi-agent Coordination Under Temporal Logic Tasks and Team-Wise Intermittent Communication
Aug 27, 2023Multi-agent systems outperform single agent in complex collaborative tasks. However, in large-scale scenarios, ensuring timely information exchange during decentralized task execution remains a challenge. This work presents an online decentralized coordination scheme for multi-agent systems under complex local tasks and intermittent communication constraints. Unlike existing strategies that enforce all-time or intermittent connectivity, our approach allows agents to join or leave communication networks at aperiodic intervals, as deemed optimal by their online task execution. This scheme concurrently determines local plans and refines the communication strategy, i.e., where and when to communicate as a team. A decentralized potential game is modeled among agents, for which a Nash equilibrium is generated iteratively through online local search. It guarantees local task completion and intermittent communication constraints. Extensive numerical simulations are conducted against several strong baselines.
Automated Conversion of Music Videos into Lyric Videos
Aug 28, 2023



Musicians and fans often produce lyric videos, a form of music videos that showcase the song's lyrics, for their favorite songs. However, making such videos can be challenging and time-consuming as the lyrics need to be added in synchrony and visual harmony with the video. Informed by prior work and close examination of existing lyric videos, we propose a set of design guidelines to help creators make such videos. Our guidelines ensure the readability of the lyric text while maintaining a unified focus of attention. We instantiate these guidelines in a fully automated pipeline that converts an input music video into a lyric video. We demonstrate the robustness of our pipeline by generating lyric videos from a diverse range of input sources. A user study shows that lyric videos generated by our pipeline are effective in maintaining text readability and unifying the focus of attention.
CPFES: Physical Fitness Evaluation Based on Canadian Agility and Movement Skill Assessment
Aug 28, 2023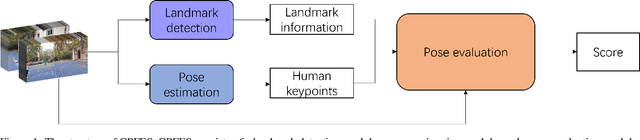
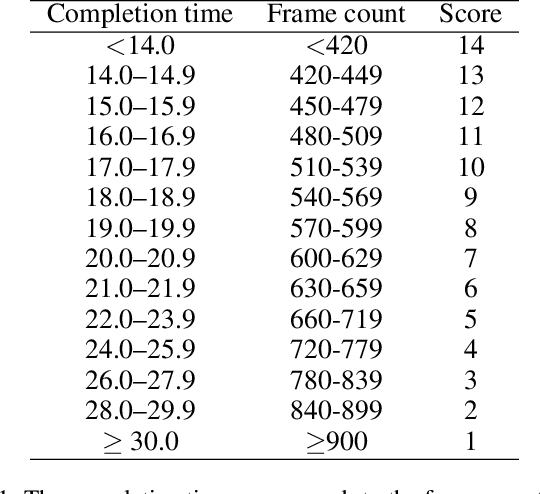
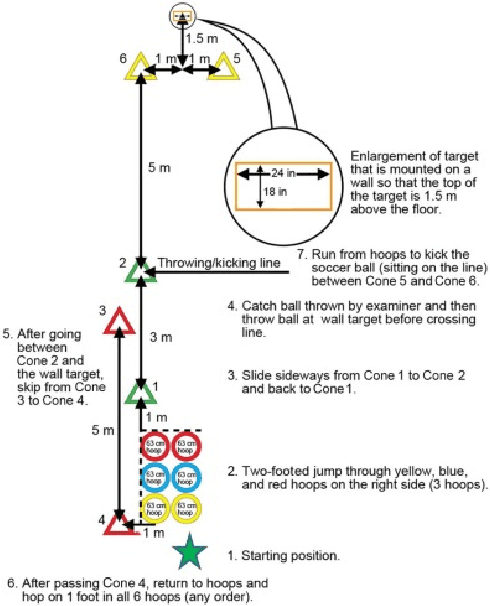
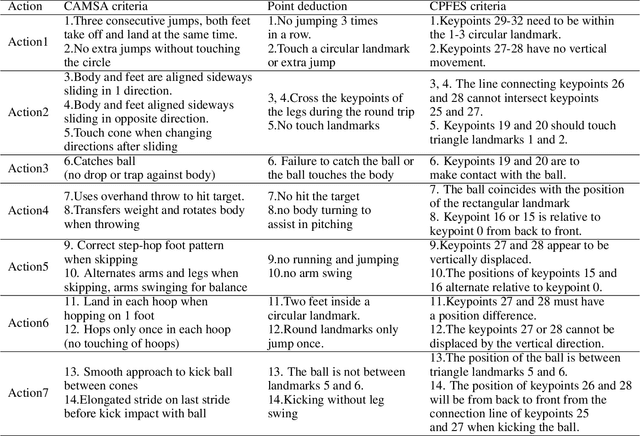
In recent years, the assessment of fundamental movement skills integrated with physical education has focused on both teaching practice and the feasibility of assessment. The object of assessment has shifted from multiple ages to subdivided ages, while the content of assessment has changed from complex and time-consuming to concise and efficient. Therefore, we apply deep learning to physical fitness evaluation, we propose a system based on the Canadian Agility and Movement Skill Assessment (CAMSA) Physical Fitness Evaluation System (CPFES), which evaluates children's physical fitness based on CAMSA, and gives recommendations based on the scores obtained by CPFES to help children grow. We have designed a landmark detection module and a pose estimation module, and we have also designed a pose evaluation module for the CAMSA criteria that can effectively evaluate the actions of the child being tested. Our experimental results demonstrate the high accuracy of the proposed system.
HashReID: Dynamic Network with Binary Codes for Efficient Person Re-identification
Aug 23, 2023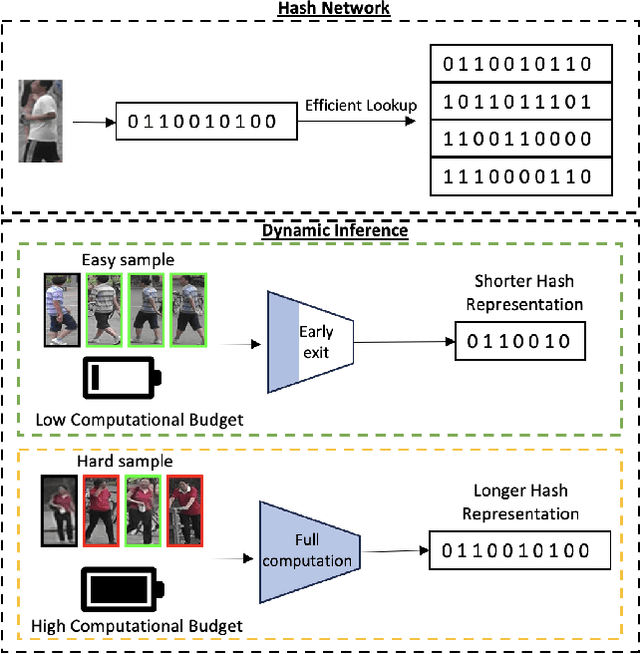
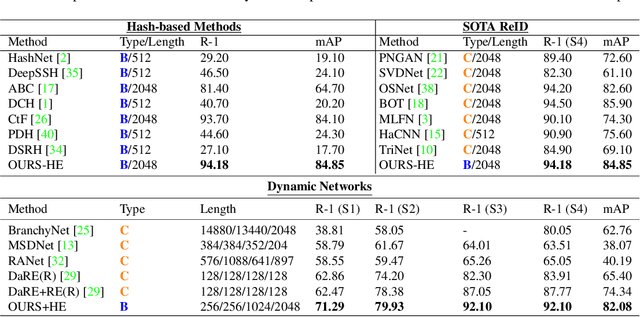
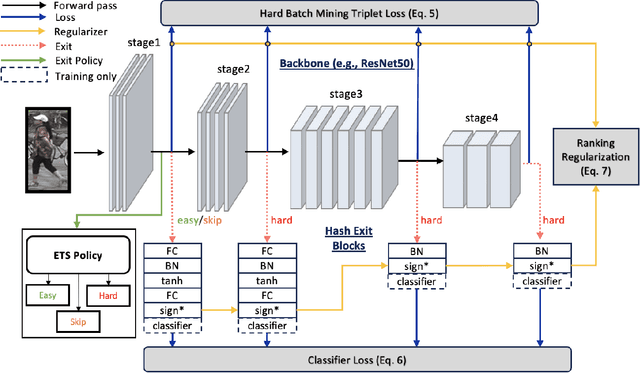
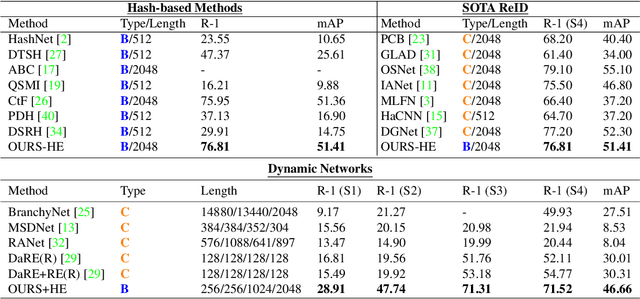
Biometric applications, such as person re-identification (ReID), are often deployed on energy constrained devices. While recent ReID methods prioritize high retrieval performance, they often come with large computational costs and high search time, rendering them less practical in real-world settings. In this work, we propose an input-adaptive network with multiple exit blocks, that can terminate computation early if the retrieval is straightforward or noisy, saving a lot of computation. To assess the complexity of the input, we introduce a temporal-based classifier driven by a new training strategy. Furthermore, we adopt a binary hash code generation approach instead of relying on continuous-valued features, which significantly improves the search process by a factor of 20. To ensure similarity preservation, we utilize a new ranking regularizer that bridges the gap between continuous and binary features. Extensive analysis of our proposed method is conducted on three datasets: Market1501, MSMT17 (Multi-Scene Multi-Time), and the BGC1 (BRIAR Government Collection). Using our approach, more than 70% of the samples with compact hash codes exit early on the Market1501 dataset, saving 80% of the networks computational cost and improving over other hash-based methods by 60%. These results demonstrate a significant improvement over dynamic networks and showcase comparable accuracy performance to conventional ReID methods. Code will be made available.
Finding the Perfect Fit: Applying Regression Models to ClimateBench v1.0
Aug 23, 2023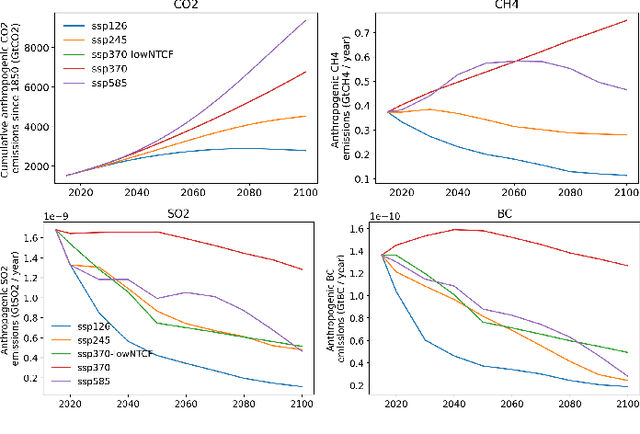
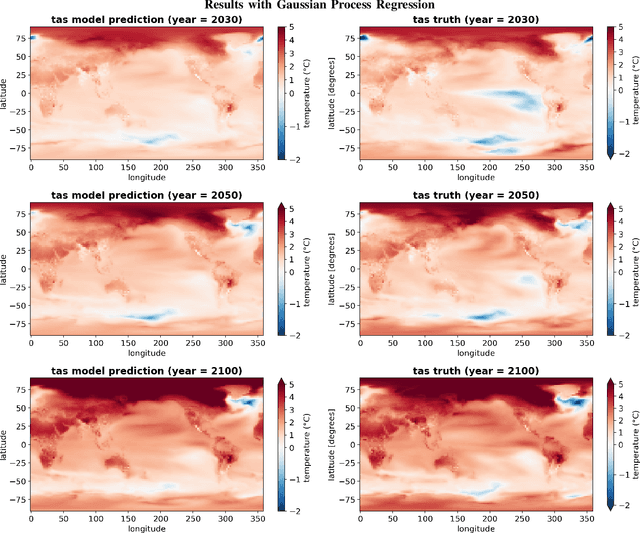
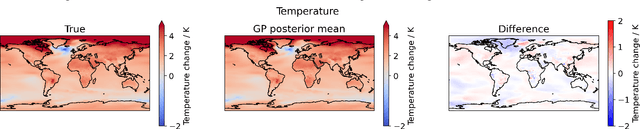
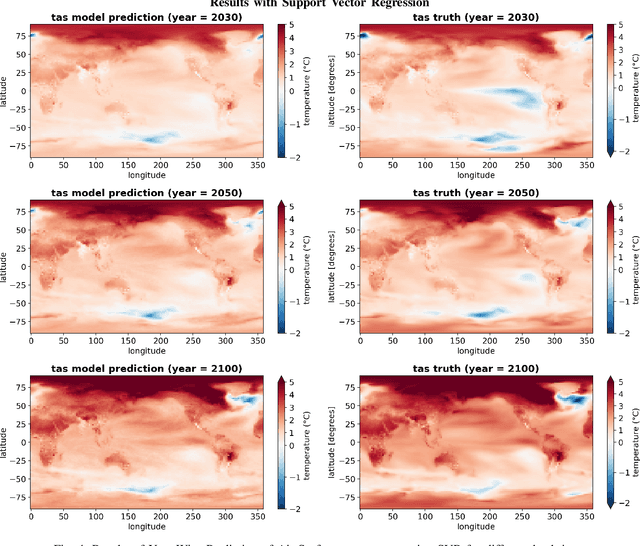
Climate projections using data driven machine learning models acting as emulators, is one of the prevailing areas of research to enable policy makers make informed decisions. Use of machine learning emulators as surrogates for computationally heavy GCM simulators reduces time and carbon footprints. In this direction, ClimateBench [1] is a recently curated benchmarking dataset for evaluating the performance of machine learning emulators designed for climate data. Recent studies have reported that despite being considered fundamental, regression models offer several advantages pertaining to climate emulations. In particular, by leveraging the kernel trick, regression models can capture complex relationships and improve their predictive capabilities. This study focuses on evaluating non-linear regression models using the aforementioned dataset. Specifically, we compare the emulation capabilities of three non-linear regression models. Among them, Gaussian Process Regressor demonstrates the best-in-class performance against standard evaluation metrics used for climate field emulation studies. However, Gaussian Process Regression suffers from being computational resource hungry in terms of space and time complexity. Alternatively, Support Vector and Kernel Ridge models also deliver competitive results and but there are certain trade-offs to be addressed. Additionally, we are actively investigating the performance of composite kernels and techniques such as variational inference to further enhance the performance of the regression models and effectively model complex non-linear patterns, including phenomena like precipitation.
PV-SSD: A Projection and Voxel-based Double Branch Single-Stage 3D Object Detector
Aug 31, 2023
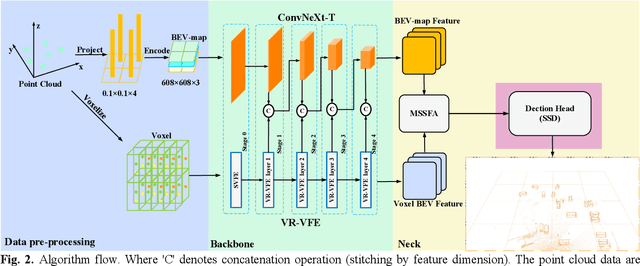
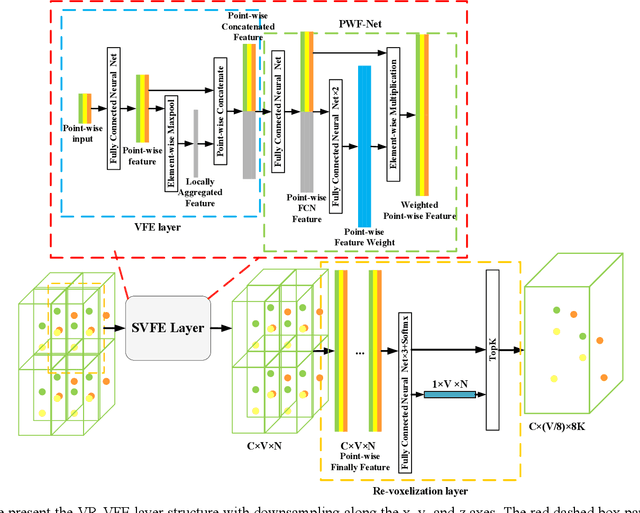
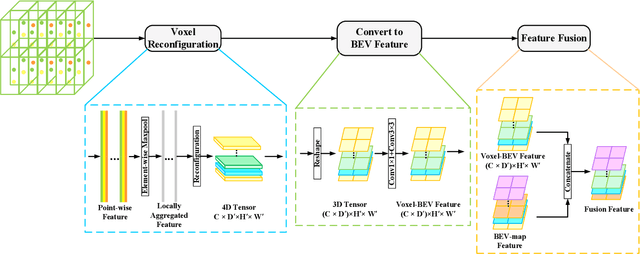
LIDAR-based 3D object detection and classification is crucial for autonomous driving. However, inference in real-time from extremely sparse 3D data poses a formidable challenge. To address this issue, a common approach is to project point clouds onto a bird's-eye or perspective view, effectively converting them into an image-like data format. However, this excessive compression of point cloud data often leads to the loss of information. This paper proposes a 3D object detector based on voxel and projection double branch feature extraction (PV-SSD) to address the problem of information loss. We add voxel features input containing rich local semantic information, which is fully fused with the projected features in the feature extraction stage to reduce the local information loss caused by projection. A good performance is achieved compared to the previous work. In addition, this paper makes the following contributions: 1) a voxel feature extraction method with variable receptive fields is proposed; 2) a feature point sampling method by weight sampling is used to filter out the feature points that are more conducive to the detection task; 3) the MSSFA module is proposed based on the SSFA module. To verify the effectiveness of our method, we designed comparison experiments.