 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Natural and Robust Walking using Reinforcement Learning without Demonstrations in High-Dimensional Musculoskeletal Models
Sep 07, 2023
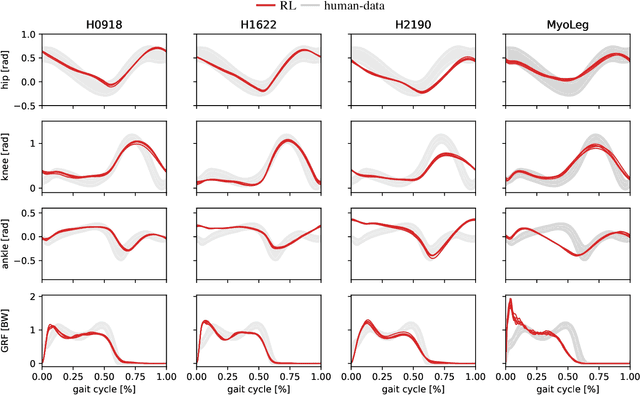
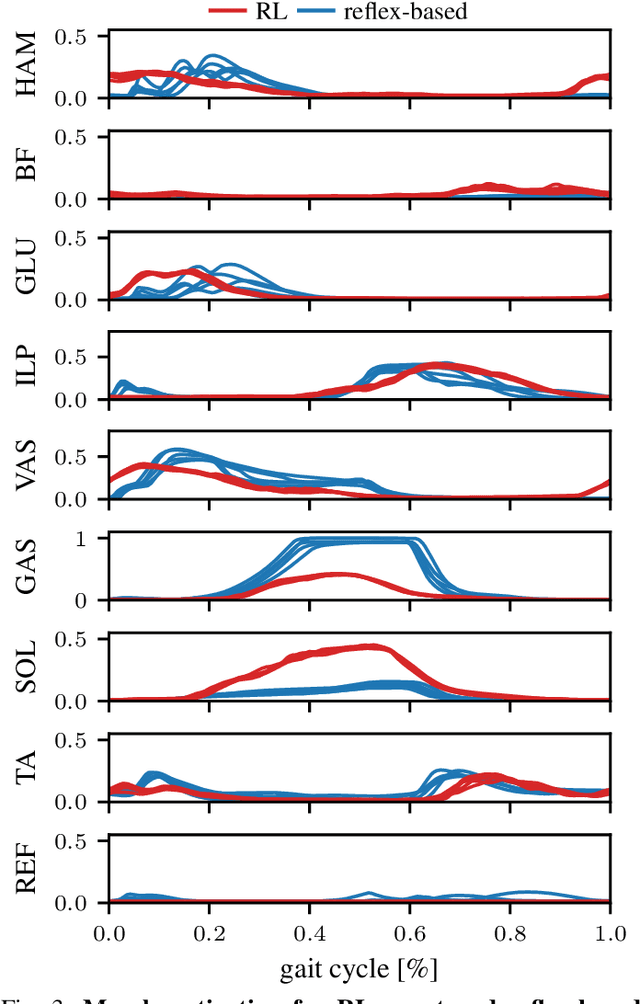
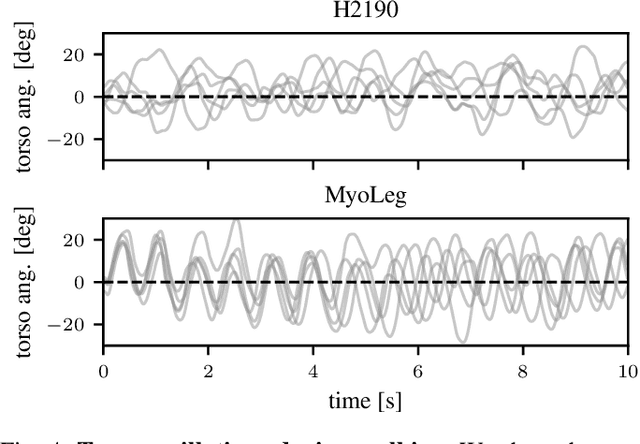
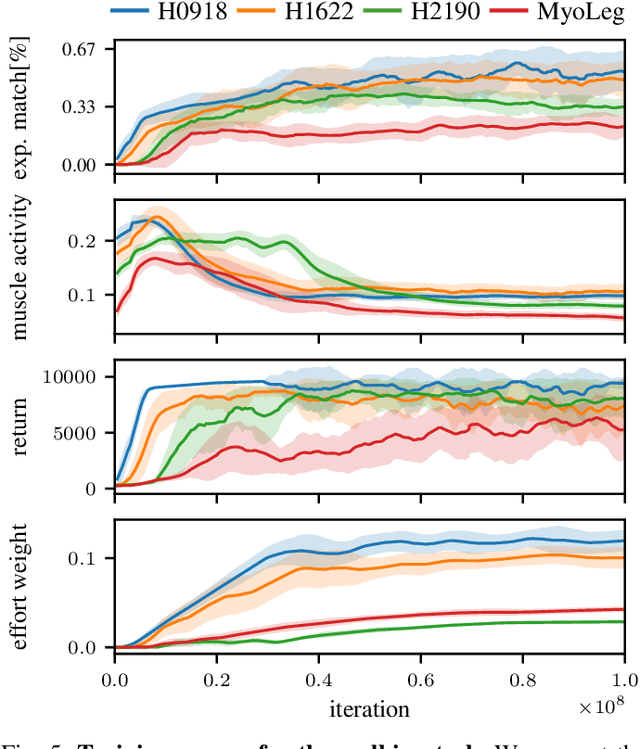
Humans excel at robust bipedal walking in complex natural environments. In each step, they adequately tune the interaction of biomechanical muscle dynamics and neuronal signals to be robust against uncertainties in ground conditions. However, it is still not fully understood how the nervous system resolves the musculoskeletal redundancy to solve the multi-objective control problem considering stability, robustness, and energy efficiency. In computer simulations, energy minimization has been shown to be a successful optimization target, reproducing natural walking with trajectory optimization or reflex-based control methods. However, these methods focus on particular motions at a time and the resulting controllers are limited when compensating for perturbations. In robotics, reinforcement learning~(RL) methods recently achieved highly stable (and efficient) locomotion on quadruped systems, but the generation of human-like walking with bipedal biomechanical models has required extensive use of expert data sets. This strong reliance on demonstrations often results in brittle policies and limits the application to new behaviors, especially considering the potential variety of movements for high-dimensional musculoskeletal models in 3D. Achieving natural locomotion with RL without sacrificing its incredible robustness might pave the way for a novel approach to studying human walking in complex natural environments. Videos: https://sites.google.com/view/naturalwalkingrl
Cross-Consistent Deep Unfolding Network for Adaptive All-In-One Video Restoration
Sep 07, 2023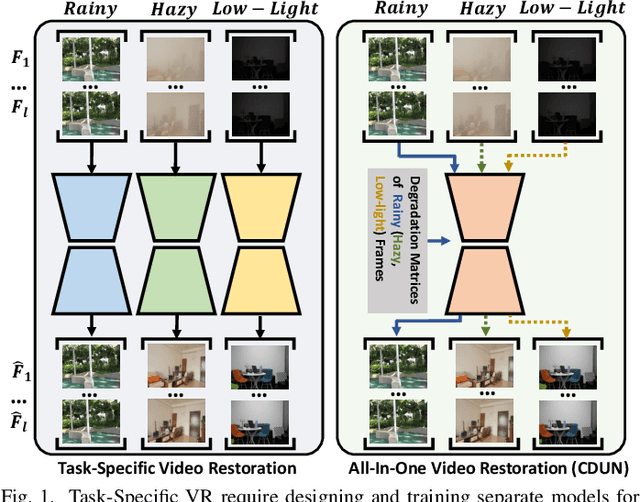

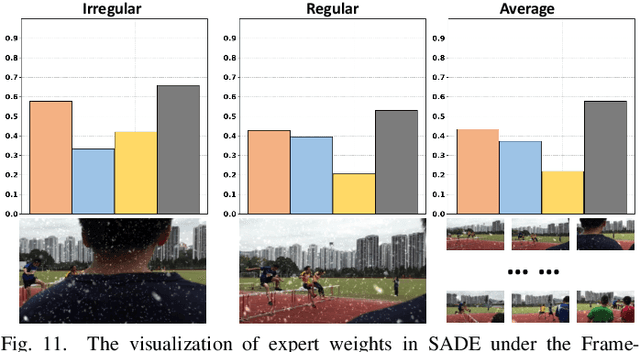
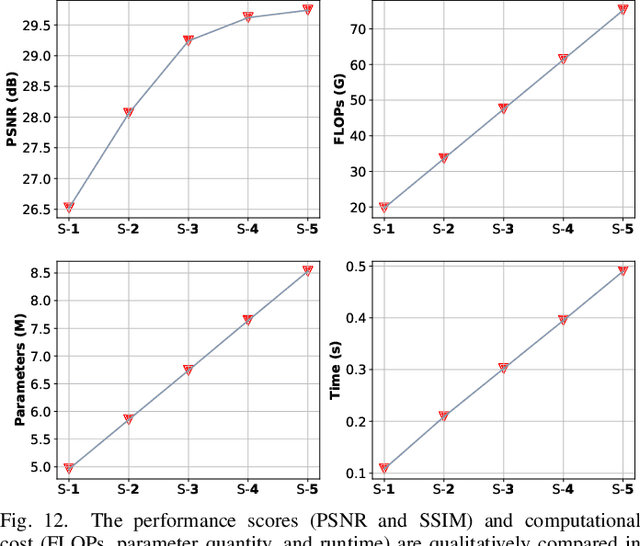
Existing Video Restoration (VR) methods always necessitate the individual deployment of models for each adverse weather to remove diverse adverse weather degradations, lacking the capability for adaptive processing of degradations. Such limitation amplifies the complexity and deployment costs in practical applications. To overcome this deficiency, in this paper, we propose a Cross-consistent Deep Unfolding Network (CDUN) for All-In-One VR, which enables the employment of a single model to remove diverse degradations for the first time. Specifically, the proposed CDUN accomplishes a novel iterative optimization framework, capable of restoring frames corrupted by corresponding degradations according to the degradation features given in advance. To empower the framework for eliminating diverse degradations, we devise a Sequence-wise Adaptive Degradation Estimator (SADE) to estimate degradation features for the input corrupted video. By orchestrating these two cascading procedures, CDUN achieves adaptive processing for diverse degradation. In addition, we introduce a window-based inter-frame fusion strategy to utilize information from more adjacent frames. This strategy involves the progressive stacking of temporal windows in multiple iterations, effectively enlarging the temporal receptive field and enabling each frame's restoration to leverage information from distant frames. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance in All-In-One VR.
CPMR: Context-Aware Incremental Sequential Recommendation with Pseudo-Multi-Task Learning
Sep 09, 2023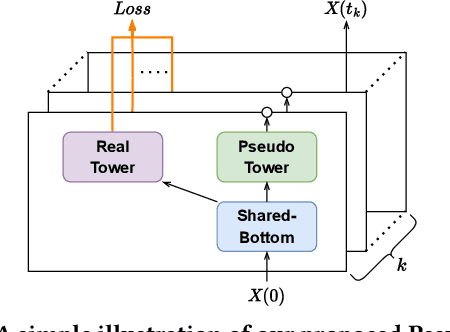
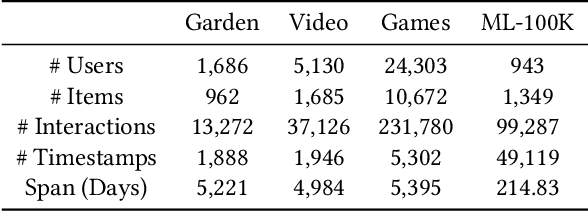


The motivations of users to make interactions can be divided into static preference and dynamic interest. To accurately model user representations over time, recent studies in sequential recommendation utilize information propagation and evolution to mine from batches of arriving interactions. However, they ignore the fact that people are easily influenced by the recent actions of other users in the contextual scenario, and applying evolution across all historical interactions dilutes the importance of recent ones, thus failing to model the evolution of dynamic interest accurately. To address this issue, we propose a Context-Aware Pseudo-Multi-Task Recommender System (CPMR) to model the evolution in both historical and contextual scenarios by creating three representations for each user and item under different dynamics: static embedding, historical temporal states, and contextual temporal states. To dually improve the performance of temporal states evolution and incremental recommendation, we design a Pseudo-Multi-Task Learning (PMTL) paradigm by stacking the incremental single-target recommendations into one multi-target task for joint optimization. Within the PMTL paradigm, CPMR employs a shared-bottom network to conduct the evolution of temporal states across historical and contextual scenarios, as well as the fusion of them at the user-item level. In addition, CPMR incorporates one real tower for incremental predictions, and two pseudo towers dedicated to updating the respective temporal states based on new batches of interactions. Experimental results on four benchmark recommendation datasets show that CPMR consistently outperforms state-of-the-art baselines and achieves significant gains on three of them. The code is available at: https://github.com/DiMarzioBian/CPMR.
* Accepted by CIKM 2023
Timely Fusion of Surround Radar/Lidar for Object Detection in Autonomous Driving Systems
Sep 09, 2023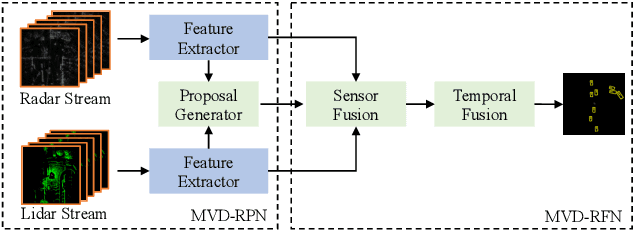
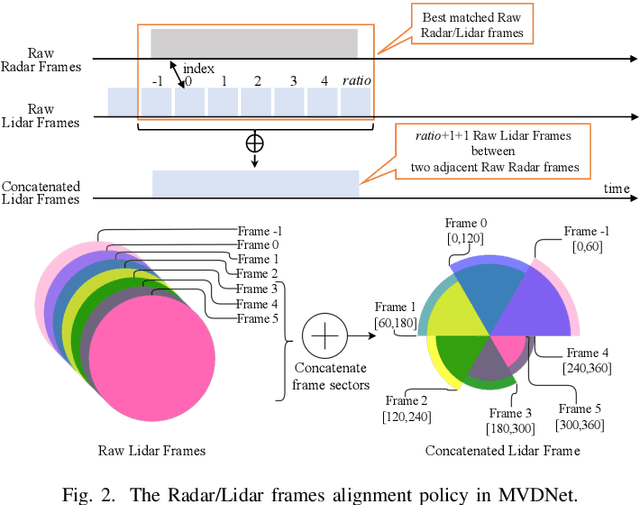
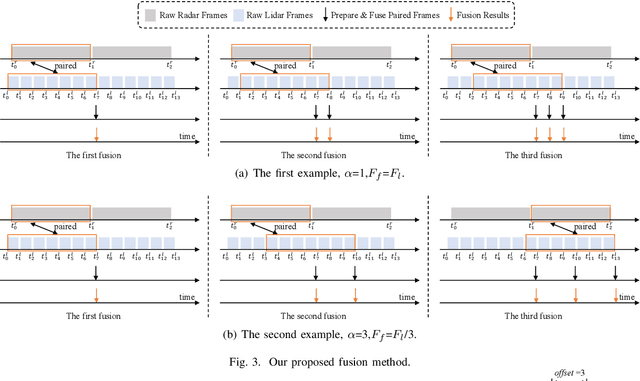
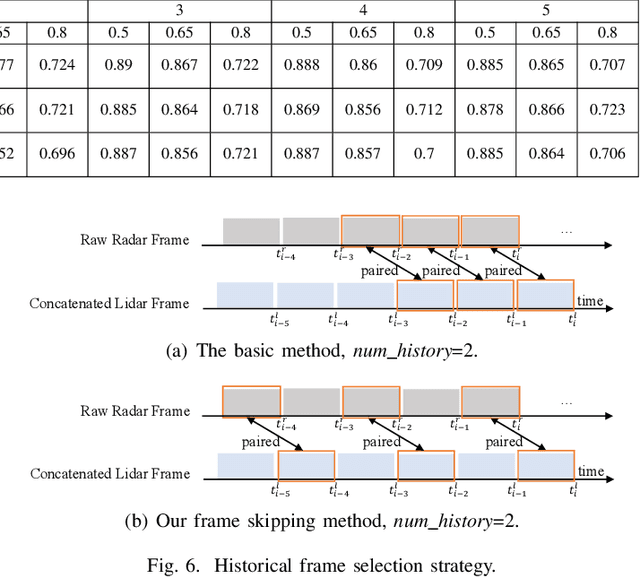
Fusing Radar and Lidar sensor data can fully utilize their complementary advantages and provide more accurate reconstruction of the surrounding for autonomous driving systems. Surround Radar/Lidar can provide 360-degree view sampling with the minimal cost, which are promising sensing hardware solutions for autonomous driving systems. However, due to the intrinsic physical constraints, the rotating speed of surround Radar, and thus the frequency to generate Radar data frames, is much lower than surround Lidar. Existing Radar/Lidar fusion methods have to work at the low frequency of surround Radar, which cannot meet the high responsiveness requirement of autonomous driving systems.This paper develops techniques to fuse surround Radar/Lidar with working frequency only limited by the faster surround Lidar instead of the slower surround Radar, based on the state-of-the-art object detection model MVDNet. The basic idea of our approach is simple: we let MVDNet work with temporally unaligned data from Radar/Lidar, so that fusion can take place at any time when a new Lidar data frame arrives, instead of waiting for the slow Radar data frame. However, directly applying MVDNet to temporally unaligned Radar/Lidar data greatly degrades its object detection accuracy. The key information revealed in this paper is that we can achieve high output frequency with little accuracy loss by enhancing the training procedure to explore the temporal redundancy in MVDNet so that it can tolerate the temporal unalignment of input data. We explore several different ways of training enhancement and compare them quantitatively with experiments.
FunQuant: A R package to perform quantization in the context of rare events and time-consuming simulations
Aug 18, 2023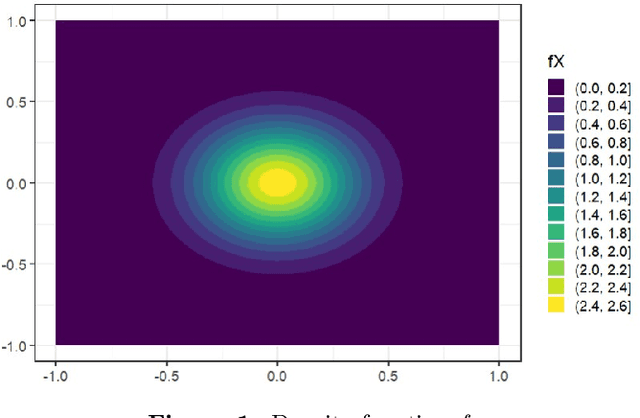
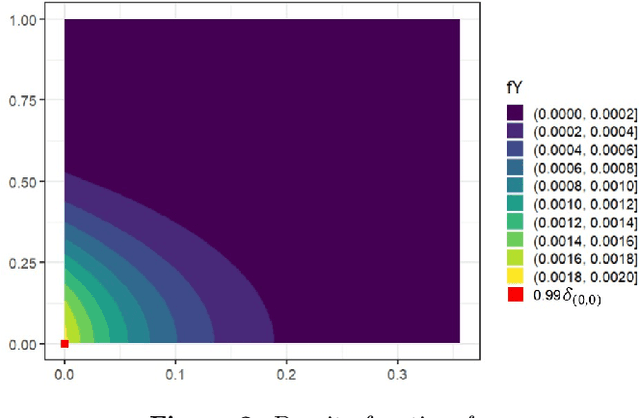
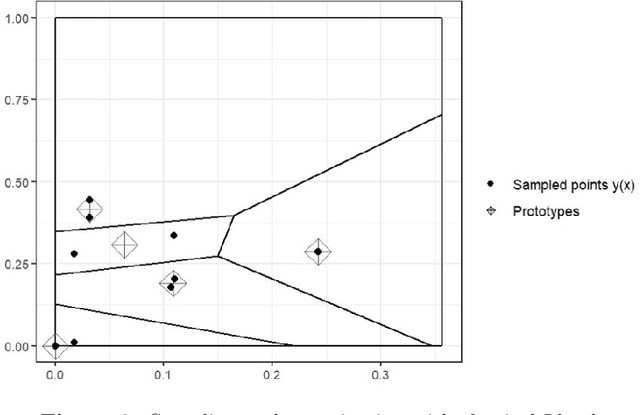
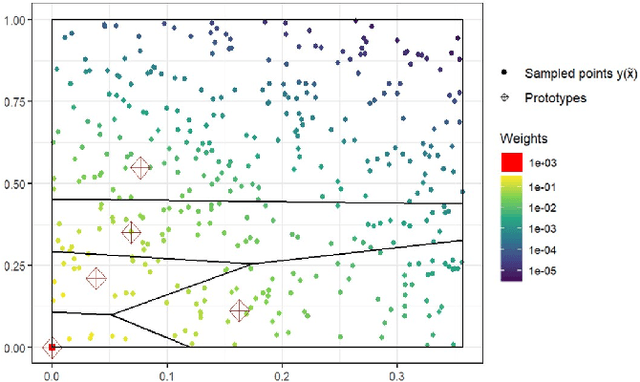
Quantization summarizes continuous distributions by calculating a discrete approximation. Among the widely adopted methods for data quantization is Lloyd's algorithm, which partitions the space into Vorono\"i cells, that can be seen as clusters, and constructs a discrete distribution based on their centroids and probabilistic masses. Lloyd's algorithm estimates the optimal centroids in a minimal expected distance sense, but this approach poses significant challenges in scenarios where data evaluation is costly, and relates to rare events. Then, the single cluster associated to no event takes the majority of the probability mass. In this context, a metamodel is required and adapted sampling methods are necessary to increase the precision of the computations on the rare clusters.
Decentralized Multi-Robot Social Navigation in Constrained Environments via Game-Theoretic Control Barrier Functions
Aug 30, 2023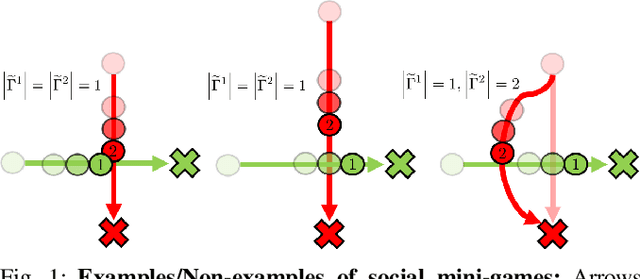
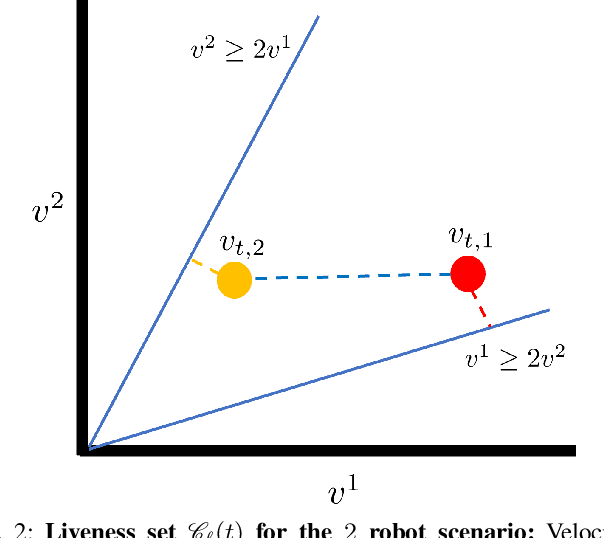
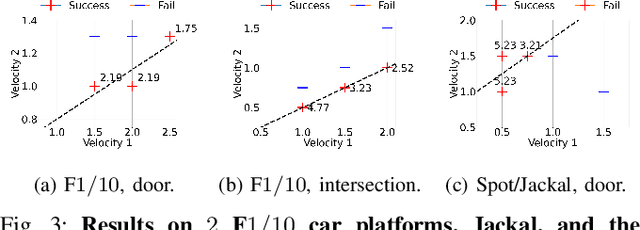

We present an approach to ensure safe and deadlock-free navigation for decentralized multi-robot systems operating in constrained environments, including doorways and intersections. Although many solutions have been proposed to ensure safety, preventing deadlocks in a decentralized fashion with global consensus remains an open problem. We first formalize the objective as a non-cooperative, non-communicative, partially observable multi-robot navigation problem in constrained spaces with multiple conflicting agents, which we term as \emph{social mini-games}. Our approach to ensuring liveness rests on two novel insights: $(i)$ there exists a mixed-strategy Nash equilibrium that allows decentralized robots to perturb their state onto \textit{liveness sets} i.e. states where robots are deadlock-free and $(ii)$ forward invariance of liveness sets can be achieved identical to how control barrier functions (CBFs) guarantee forward invariance of safety sets. We evaluate our approach in simulation as well on physical robots using F$1/10$ robots, a Clearpath Jackal, as well as a Boston Dynamics Spot in a doorway and corridor intersection scenario. Compared to both fully decentralized and centralized approaches with and without deadlock resolution capabilities, we demonstrate that our approach results in safer, more efficient, and smoother navigation, based on a comprehensive set of metrics including success rate, collision rate, stop time, change in velocity, path deviation, time-to-goal, and flow rate.
Integrating Large Language Models into the Debugging C Compiler for generating contextual error explanations
Aug 23, 2023This paper introduces a method for Large Language Models (LLM) to produce enhanced compiler error explanations, in simple language, within our Debugging C Compiler (DCC). It is well documented that compiler error messages have been known to present a barrier for novices learning how to program. Although our initial use of DCC in introductory programming (CS1) has been instrumental in teaching C to novice programmers by providing safeguards to commonly occurring errors and translating the usually cryptic compiler error messages at both compile- and run-time, we proposed that incorporating LLM-generated explanations would further enhance the learning experience for novice programmers. Through an expert evaluation, we observed that LLM-generated explanations for compiler errors were conceptually accurate in 90% of compile-time errors, and 75% of run-time errors. Additionally, the new DCC-help tool has been increasingly adopted by students, with an average of 1047 unique runs per week, demonstrating a promising initial assessment of using LLMs to complement compiler output to enhance programming education for beginners. We release our tool as open-source to the community.
LEAP: Efficient and Automated Test Method for NLP Software
Aug 22, 2023
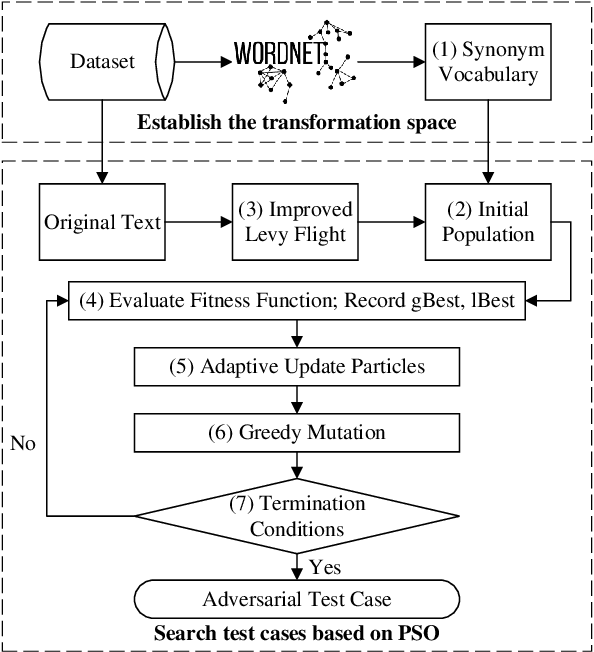
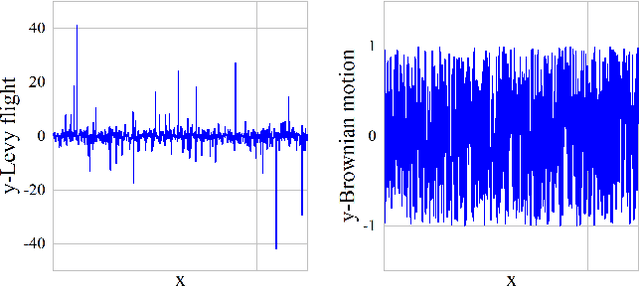
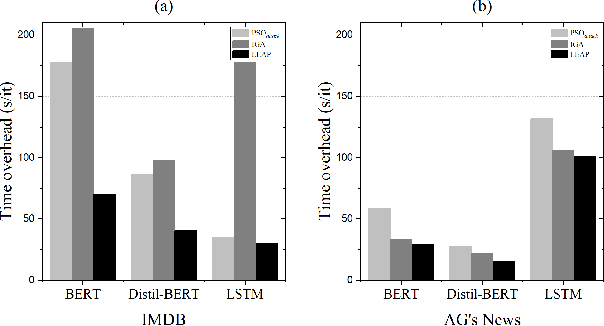
The widespread adoption of DNNs in NLP software has highlighted the need for robustness. Researchers proposed various automatic testing techniques for adversarial test cases. However, existing methods suffer from two limitations: weak error-discovering capabilities, with success rates ranging from 0% to 24.6% for BERT-based NLP software, and time inefficiency, taking 177.8s to 205.28s per test case, making them challenging for time-constrained scenarios. To address these issues, this paper proposes LEAP, an automated test method that uses LEvy flight-based Adaptive Particle swarm optimization integrated with textual features to generate adversarial test cases. Specifically, we adopt Levy flight for population initialization to increase the diversity of generated test cases. We also design an inertial weight adaptive update operator to improve the efficiency of LEAP's global optimization of high-dimensional text examples and a mutation operator based on the greedy strategy to reduce the search time. We conducted a series of experiments to validate LEAP's ability to test NLP software and found that the average success rate of LEAP in generating adversarial test cases is 79.1%, which is 6.1% higher than the next best approach (PSOattack). While ensuring high success rates, LEAP significantly reduces time overhead by up to 147.6s compared to other heuristic-based methods. Additionally, the experimental results demonstrate that LEAP can generate more transferable test cases and significantly enhance the robustness of DNN-based systems.
Learning Gaussian Mixture Representations for Tensor Time Series Forecasting
Jun 07, 2023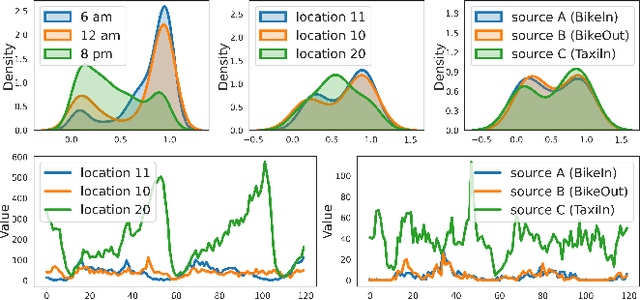
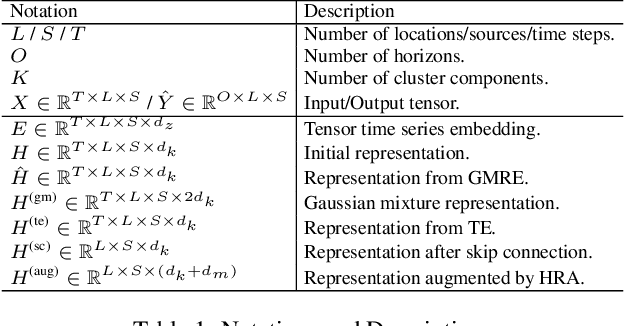

Tensor time series (TTS) data, a generalization of one-dimensional time series on a high-dimensional space, is ubiquitous in real-world scenarios, especially in monitoring systems involving multi-source spatio-temporal data (e.g., transportation demands and air pollutants). Compared to modeling time series or multivariate time series, which has received much attention and achieved tremendous progress in recent years, tensor time series has been paid less effort. Properly coping with the tensor time series is a much more challenging task, due to its high-dimensional and complex inner structure. In this paper, we develop a novel TTS forecasting framework, which seeks to individually model each heterogeneity component implied in the time, the location, and the source variables. We name this framework as GMRL, short for Gaussian Mixture Representation Learning. Experiment results on two real-world TTS datasets verify the superiority of our approach compared with the state-of-the-art baselines. Code and data are published on https://github.com/beginner-sketch/GMRL.
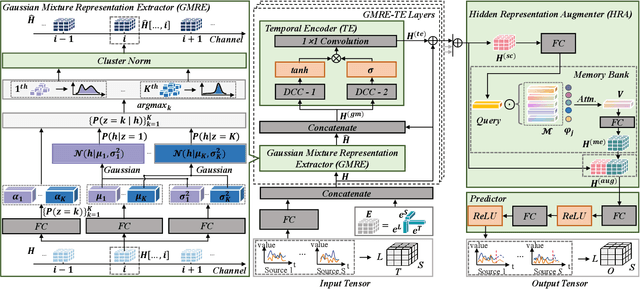
Hide and Seek (HaS): A Lightweight Framework for Prompt Privacy Protection
Sep 06, 2023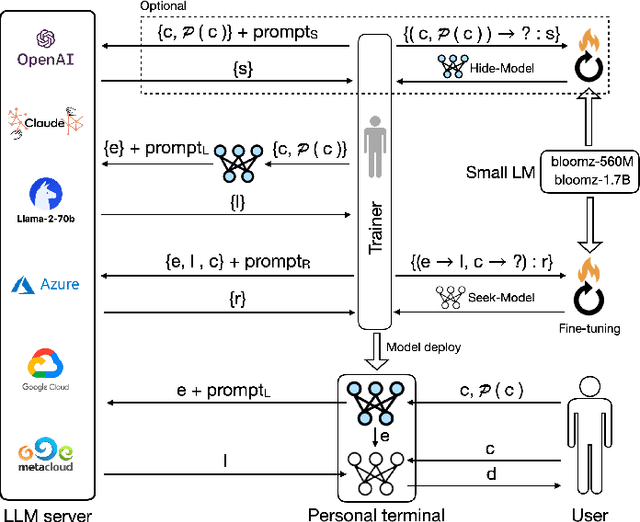

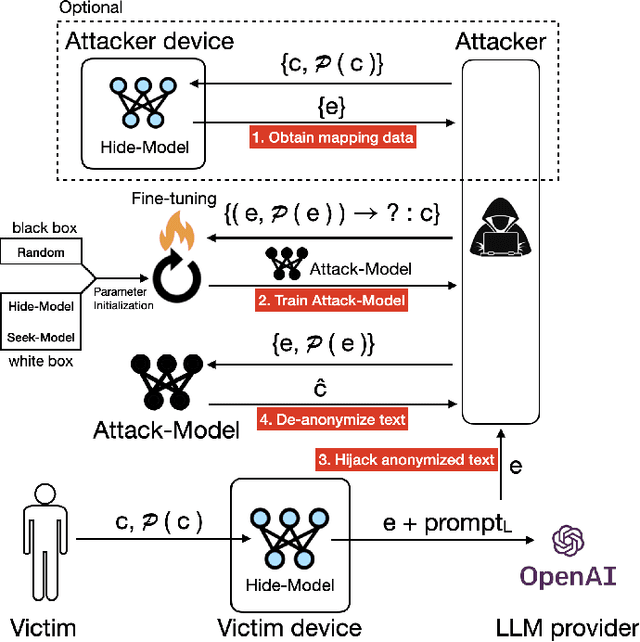

Numerous companies have started offering services based on large language models (LLM), such as ChatGPT, which inevitably raises privacy concerns as users' prompts are exposed to the model provider. Previous research on secure reasoning using multi-party computation (MPC) has proven to be impractical for LLM applications due to its time-consuming and communication-intensive nature. While lightweight anonymization techniques can protect private information in prompts through substitution or masking, they fail to recover sensitive data replaced in the LLM-generated results. In this paper, we expand the application scenarios of anonymization techniques by training a small local model to de-anonymize the LLM's returned results with minimal computational overhead. We introduce the HaS framework, where "H(ide)" and "S(eek)" represent its two core processes: hiding private entities for anonymization and seeking private entities for de-anonymization, respectively. To quantitatively assess HaS's privacy protection performance, we propose both black-box and white-box adversarial models. Furthermore, we conduct experiments to evaluate HaS's usability in translation and classification tasks. The experimental findings demonstrate that the HaS framework achieves an optimal balance between privacy protection and utility.