 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On-Device Learning with Binary Neural Networks
Aug 29, 2023

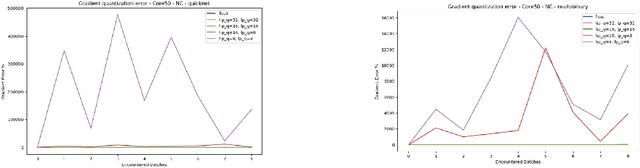
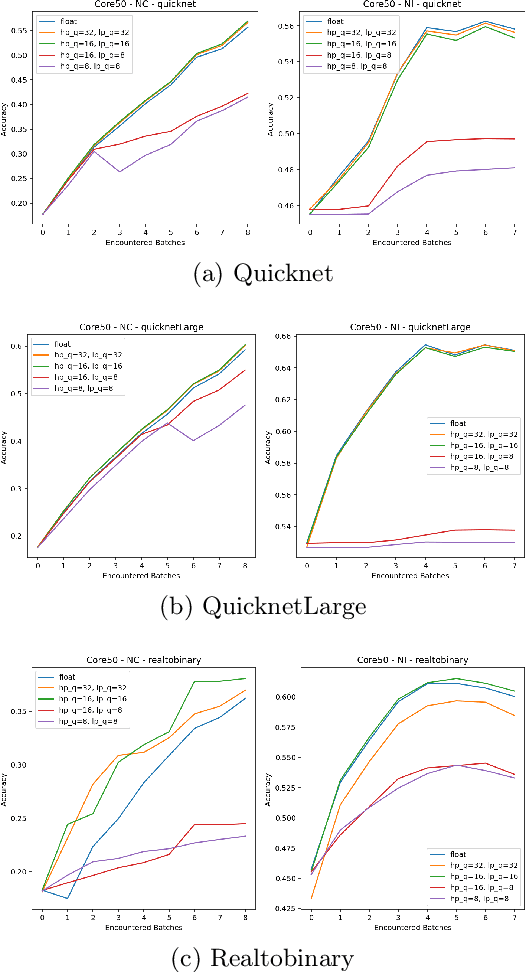
Existing Continual Learning (CL) solutions only partially address the constraints on power, memory and computation of the deep learning models when deployed on low-power embedded CPUs. In this paper, we propose a CL solution that embraces the recent advancements in CL field and the efficiency of the Binary Neural Networks (BNN), that use 1-bit for weights and activations to efficiently execute deep learning models. We propose a hybrid quantization of CWR* (an effective CL approach) that considers differently forward and backward pass in order to retain more precision during gradient update step and at the same time minimizing the latency overhead. The choice of a binary network as backbone is essential to meet the constraints of low power devices and, to the best of authors' knowledge, this is the first attempt to prove on-device learning with BNN. The experimental validation carried out confirms the validity and the suitability of the proposed method.
Beyond Document Page Classification: Design, Datasets, and Challenges
Aug 29, 2023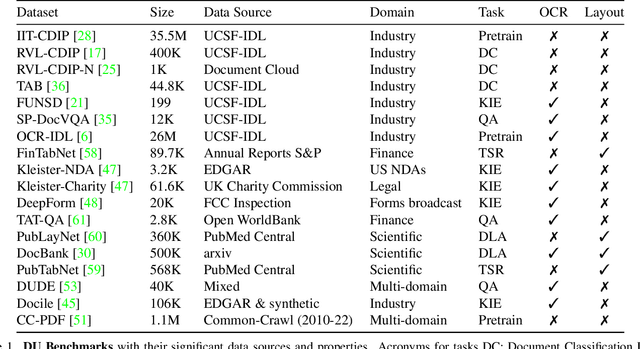
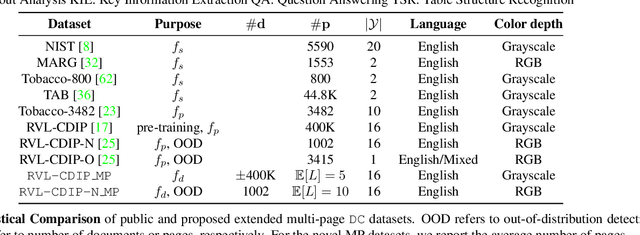

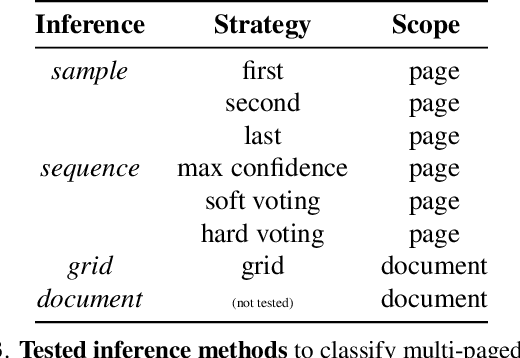
This paper highlights the need to bring document classification benchmarking closer to real-world applications, both in the nature of data tested ($X$: multi-channel, multi-paged, multi-industry; $Y$: class distributions and label set variety) and in classification tasks considered ($f$: multi-page document, page stream, and document bundle classification, ...). We identify the lack of public multi-page document classification datasets, formalize different classification tasks arising in application scenarios, and motivate the value of targeting efficient multi-page document representations. An experimental study on proposed multi-page document classification datasets demonstrates that current benchmarks have become irrelevant and need to be updated to evaluate complete documents, as they naturally occur in practice. This reality check also calls for more mature evaluation methodologies, covering calibration evaluation, inference complexity (time-memory), and a range of realistic distribution shifts (e.g., born-digital vs. scanning noise, shifting page order). Our study ends on a hopeful note by recommending concrete avenues for future improvements.}
Learning Clothing and Pose Invariant 3D Shape Representation for Long-Term Person Re-Identification
Aug 29, 2023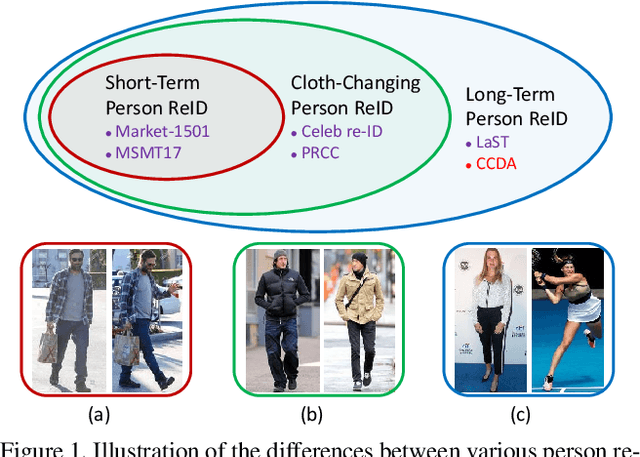


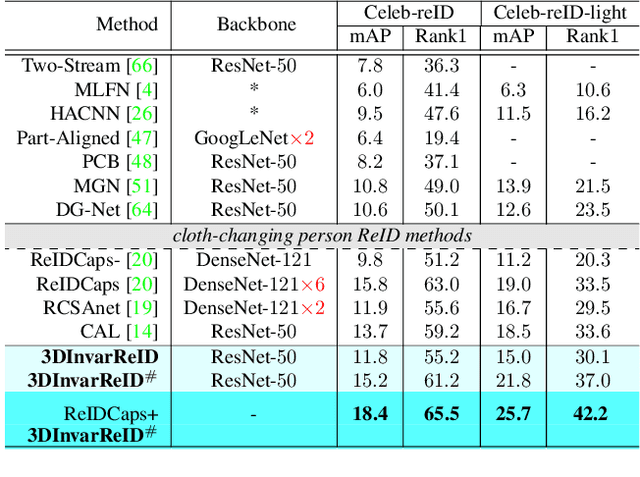
Long-Term Person Re-Identification (LT-ReID) has become increasingly crucial in computer vision and biometrics. In this work, we aim to extend LT-ReID beyond pedestrian recognition to include a wider range of real-world human activities while still accounting for cloth-changing scenarios over large time gaps. This setting poses additional challenges due to the geometric misalignment and appearance ambiguity caused by the diversity of human pose and clothing. To address these challenges, we propose a new approach 3DInvarReID for (i) disentangling identity from non-identity components (pose, clothing shape, and texture) of 3D clothed humans, and (ii) reconstructing accurate 3D clothed body shapes and learning discriminative features of naked body shapes for person ReID in a joint manner. To better evaluate our study of LT-ReID, we collect a real-world dataset called CCDA, which contains a wide variety of human activities and clothing changes. Experimentally, we show the superior performance of our approach for person ReID.
Recursively Summarizing Enables Long-Term Dialogue Memory in Large Language Models
Aug 29, 2023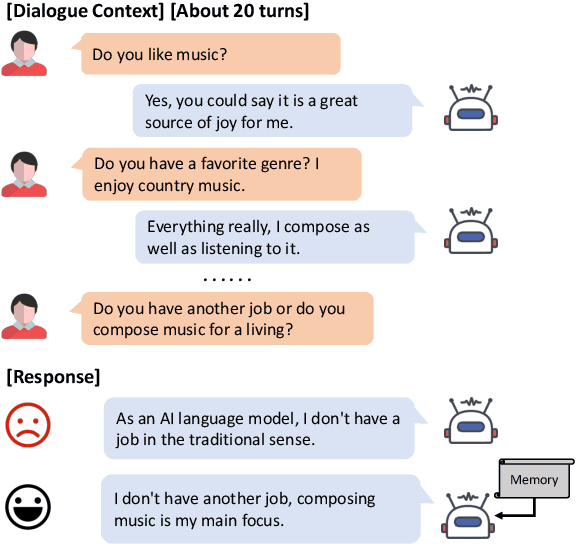

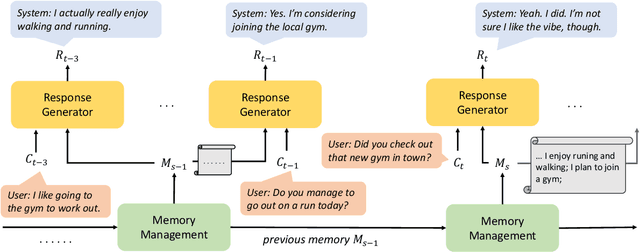
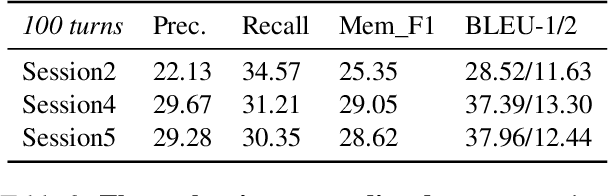
Most open-domain dialogue systems suffer from forgetting important information, especially in a long-term conversation. Existing works usually train the specific retriever or summarizer to obtain key information from the past, which is time-consuming and highly depends on the quality of labeled data. To alleviate this problem, we propose to recursively generate summaries/ memory using large language models (LLMs) to enhance long-term memory ability. Specifically, our method first stimulates LLMs to memorize small dialogue contexts and then recursively produce new memory using previous memory and following contexts. Finally, the LLM can easily generate a highly consistent response with the help of the latest memory. We evaluate our method using ChatGPT and text-davinci-003, and the experiments on the widely-used public dataset show that our method can generate more consistent responses in a long-context conversation. Notably, our method is a potential solution to enable the LLM to model the extremely long context. Code and scripts will be released later.
Blind Cyclic Prefix-based CFO Estimation in MIMO-OFDM Systems
Aug 29, 2023Low-complexity estimation and correction of carrier frequency offset (CFO) are essential in orthogonal frequency division multiplexing (OFDM). In this paper, we propose a low-overhead blind CFO estimation technique based on cyclic prefix (CP), in multi-input multi-output (MIMO)-OFDM systems. We propose to use antenna diversity for CFO estimation. Given that the RF chains for all antenna elements at a communication node share the same clock, the carrier frequency offset (CFO) between two points may be estimated by using the combination of the received signal at all antennas. We improve our method by combining the antenna diversity with time diversity by considering the CP for multiple OFDM symbols. We provide a closed-form expression for CFO estimation and present algorithms that can considerably improve the CFO estimation performance at the expense of a linear increase in computational complexity. We validate the effectiveness of our estimation scheme via extensive numerical analysis.
Learning to Read Analog Gauges from Synthetic Data
Aug 28, 2023

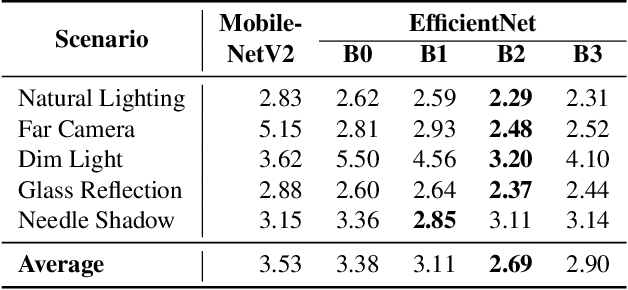
Manually reading and logging gauge data is time inefficient, and the effort increases according to the number of gauges available. We present a computer vision pipeline that automates the reading of analog gauges. We propose a two-stage CNN pipeline that identifies the key structural components of an analog gauge and outputs an angular reading. To facilitate the training of our approach, a synthetic dataset is generated thus obtaining a set of realistic analog gauges with their corresponding annotation. To validate our proposal, an additional real-world dataset was collected with 4.813 manually curated images. When compared against state-of-the-art methodologies, our method shows a significant improvement of 4.55 in the average error, which is a 52% relative improvement. The resources for this project will be made available at: https://github.com/fuankarion/automatic-gauge-reading.
Pay Attention to the Atlas: Atlas-Guided Test-Time Adaptation Method for Robust 3D Medical Image Segmentation
Jul 02, 2023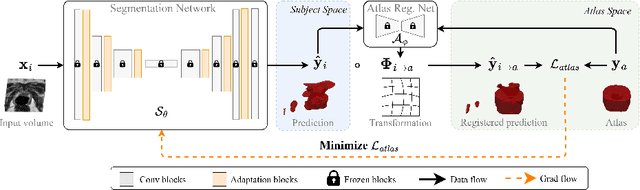
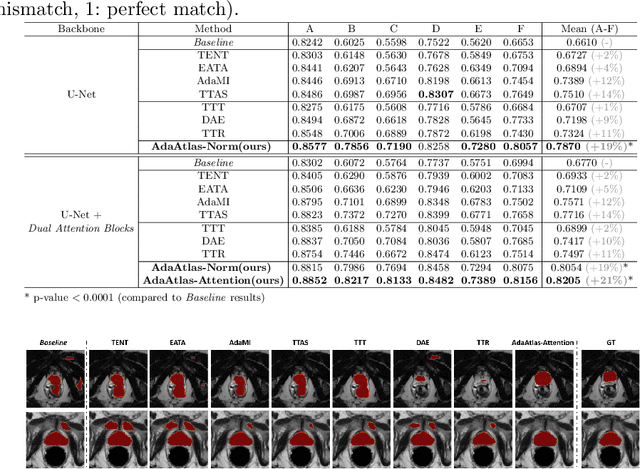


Convolutional neural networks (CNNs) often suffer from poor performance when tested on target data that differs from the training (source) data distribution, particularly in medical imaging applications where variations in imaging protocols across different clinical sites and scanners lead to different imaging appearances. However, re-accessing source training data for unsupervised domain adaptation or labeling additional test data for model fine-tuning can be difficult due to privacy issues and high labeling costs, respectively. To solve this problem, we propose a novel atlas-guided test-time adaptation (TTA) method for robust 3D medical image segmentation, called AdaAtlas. AdaAtlas only takes one single unlabeled test sample as input and adapts the segmentation network by minimizing an atlas-based loss. Specifically, the network is adapted so that its prediction after registration is aligned with the learned atlas in the atlas space, which helps to reduce anatomical segmentation errors at test time. In addition, different from most existing TTA methods which restrict the adaptation to batch normalization blocks in the segmentation network only, we further exploit the use of channel and spatial attention blocks for improved adaptability at test time. Extensive experiments on multiple datasets from different sites show that AdaAtlas with attention blocks adapted (AdaAtlas-Attention) achieves superior performance improvements, greatly outperforming other competitive TTA methods.
Food Image Classification and Segmentation with Attention-based Multiple Instance Learning
Aug 22, 2023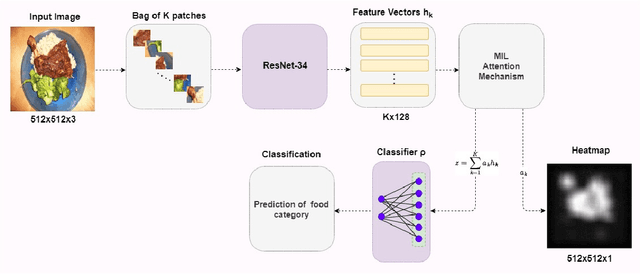
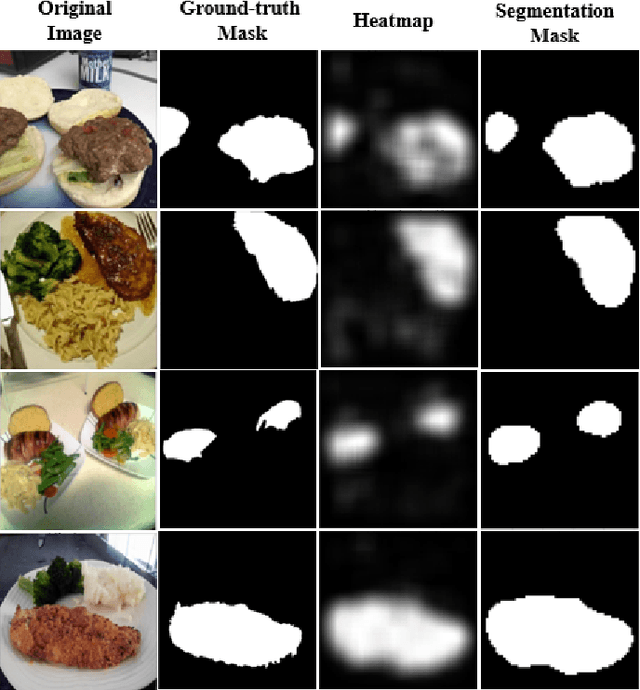
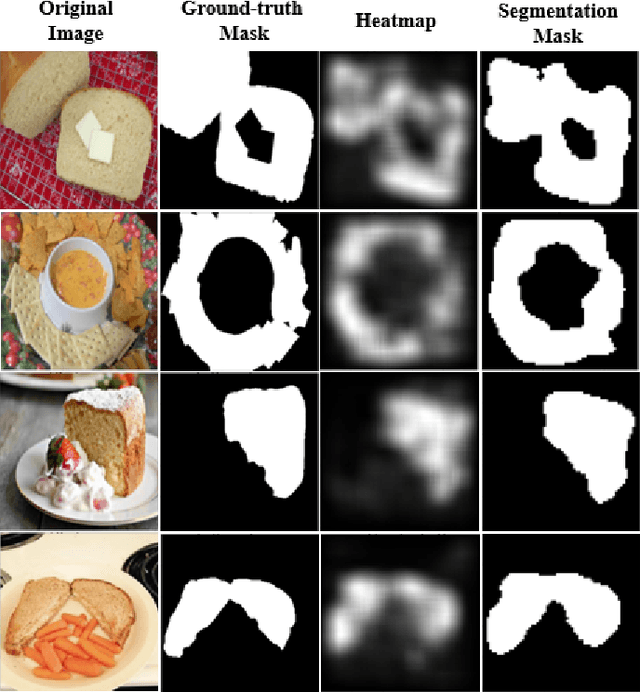
The demand for accurate food quantification has increased in the recent years, driven by the needs of applications in dietary monitoring. At the same time, computer vision approaches have exhibited great potential in automating tasks within the food domain. Traditionally, the development of machine learning models for these problems relies on training data sets with pixel-level class annotations. However, this approach introduces challenges arising from data collection and ground truth generation that quickly become costly and error-prone since they must be performed in multiple settings and for thousands of classes. To overcome these challenges, the paper presents a weakly supervised methodology for training food image classification and semantic segmentation models without relying on pixel-level annotations. The proposed methodology is based on a multiple instance learning approach in combination with an attention-based mechanism. At test time, the models are used for classification and, concurrently, the attention mechanism generates semantic heat maps which are used for food class segmentation. In the paper, we conduct experiments on two meta-classes within the FoodSeg103 data set to verify the feasibility of the proposed approach and we explore the functioning properties of the attention mechanism.
Can Authorship Representation Learning Capture Stylistic Features?
Aug 22, 2023Automatically disentangling an author's style from the content of their writing is a longstanding and possibly insurmountable problem in computational linguistics. At the same time, the availability of large text corpora furnished with author labels has recently enabled learning authorship representations in a purely data-driven manner for authorship attribution, a task that ostensibly depends to a greater extent on encoding writing style than encoding content. However, success on this surrogate task does not ensure that such representations capture writing style since authorship could also be correlated with other latent variables, such as topic. In an effort to better understand the nature of the information these representations convey, and specifically to validate the hypothesis that they chiefly encode writing style, we systematically probe these representations through a series of targeted experiments. The results of these experiments suggest that representations learned for the surrogate authorship prediction task are indeed sensitive to writing style. As a consequence, authorship representations may be expected to be robust to certain kinds of data shift, such as topic drift over time. Additionally, our findings may open the door to downstream applications that require stylistic representations, such as style transfer.
Towards predicting Pedestrian Evacuation Time and Density from Floorplans using a Vision Transformer
Jun 27, 2023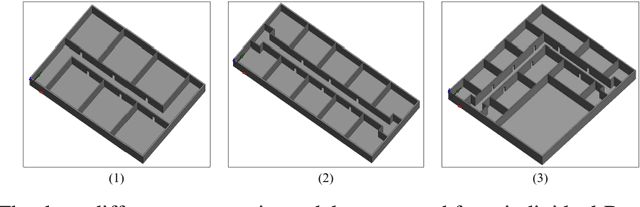

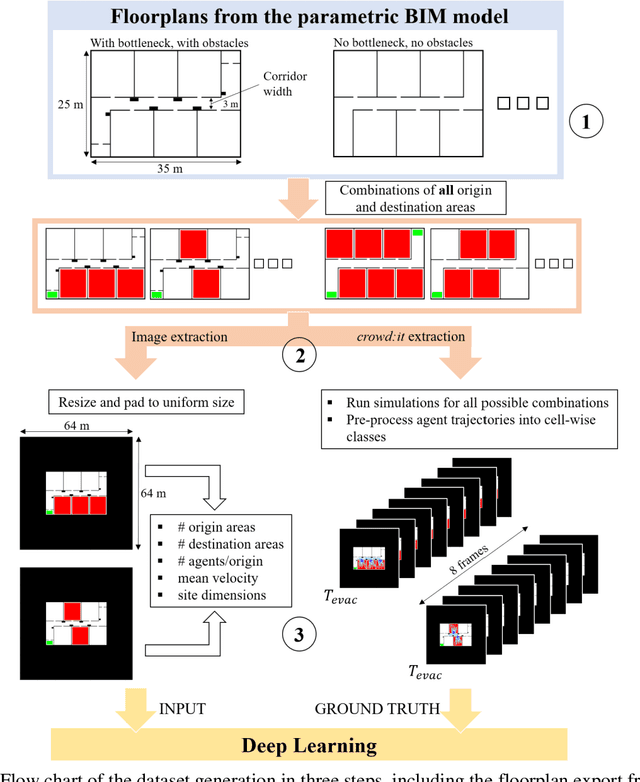
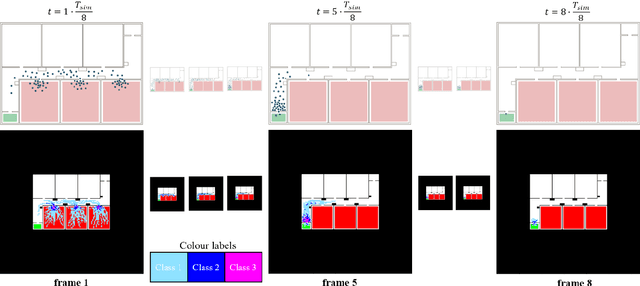
Conventional pedestrian simulators are inevitable tools in the design process of a building, as they enable project engineers to prevent overcrowding situations and plan escape routes for evacuation. However, simulation runtime and the multiple cumbersome steps in generating simulation results are potential bottlenecks during the building design process. Data-driven approaches have demonstrated their capability to outperform conventional methods in speed while delivering similar or even better results across many disciplines. In this work, we present a deep learning-based approach based on a Vision Transformer to predict density heatmaps over time and total evacuation time from a given floorplan. Specifically, due to limited availability of public datasets, we implement a parametric data generation pipeline including a conventional simulator. This enables us to build a large synthetic dataset that we use to train our architecture. Furthermore, we seamlessly integrate our model into a BIM-authoring tool to generate simulation results instantly and automatically.