 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
3D vision-based structural masonry damage detection
Aug 31, 2023


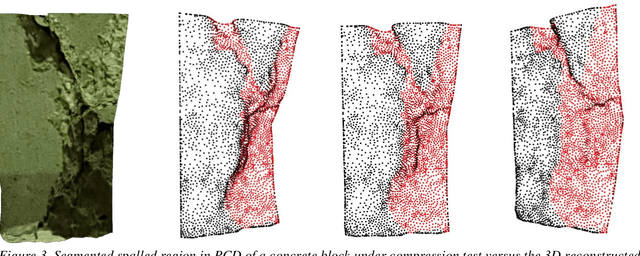
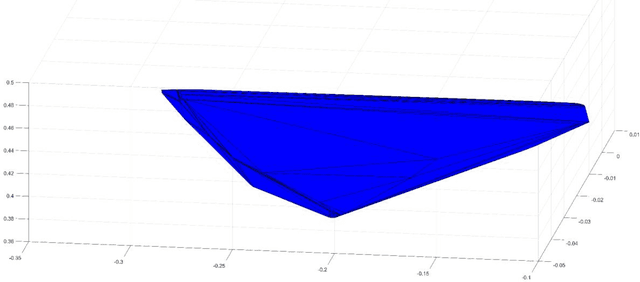
The detection of masonry damage is essential for preventing potentially disastrous outcomes. Manual inspection can, however, take a long time and be hazardous to human inspectors. Automation of the inspection process using novel computer vision and machine learning algorithms can be a more efficient and safe solution to prevent further deterioration of the masonry structures. Most existing 2D vision-based methods are limited to qualitative damage classification, 2D localization, and in-plane quantification. In this study, we present a 3D vision-based methodology for accurate masonry damage detection, which offers a more robust solution with a greater field of view, depth of vision, and the ability to detect failures in complex environments. First, images of the masonry specimens are collected to generate a 3D point cloud. Second, 3D point clouds processing methods are developed to evaluate the masonry damage. We demonstrate the effectiveness of our approach through experiments on structural masonry components. Our experiments showed the proposed system can effectively classify damage states and localize and quantify critical damage features. The result showed the proposed method can improve the level of autonomy during the inspection of masonry structures.
Optical flow-based vascular respiratory motion compensation
Aug 31, 2023This paper develops a new vascular respiratory motion compensation algorithm, Motion-Related Compensation (MRC), to conduct vascular respiratory motion compensation by extrapolating the correlation between invisible vascular and visible non-vascular. Robot-assisted vascular intervention can significantly reduce the radiation exposure of surgeons. In robot-assisted image-guided intervention, blood vessels are constantly moving/deforming due to respiration, and they are invisible in the X-ray images unless contrast agents are injected. The vascular respiratory motion compensation technique predicts 2D vascular roadmaps in live X-ray images. When blood vessels are visible after contrast agents injection, vascular respiratory motion compensation is conducted based on the sparse Lucas-Kanade feature tracker. An MRC model is trained to learn the correlation between vascular and non-vascular motions. During the intervention, the invisible blood vessels are predicted with visible tissues and the trained MRC model. Moreover, a Gaussian-based outlier filter is adopted for refinement. Experiments on in-vivo data sets show that the proposed method can yield vascular respiratory motion compensation in 0.032 sec, with an average error 1.086 mm. Our real-time and accurate vascular respiratory motion compensation approach contributes to modern vascular intervention and surgical robots.
Pay Attention to the Atlas: Atlas-Guided Test-Time Adaptation Method for Robust 3D Medical Image Segmentation
Jul 02, 2023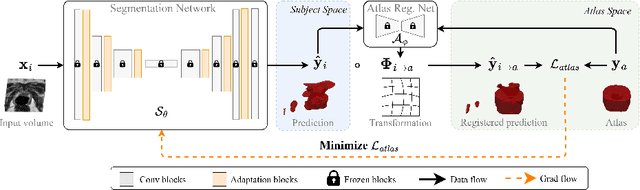
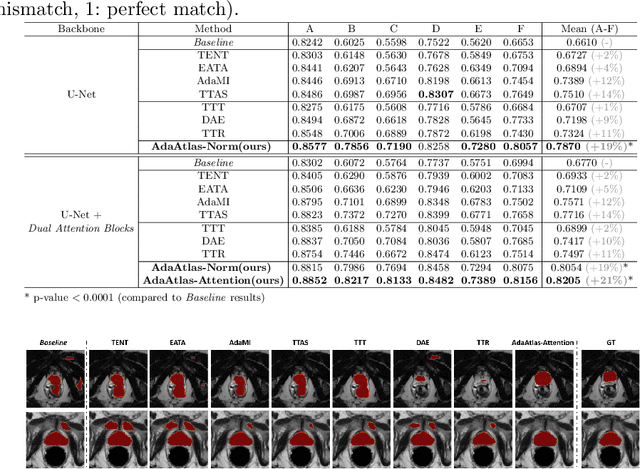


Convolutional neural networks (CNNs) often suffer from poor performance when tested on target data that differs from the training (source) data distribution, particularly in medical imaging applications where variations in imaging protocols across different clinical sites and scanners lead to different imaging appearances. However, re-accessing source training data for unsupervised domain adaptation or labeling additional test data for model fine-tuning can be difficult due to privacy issues and high labeling costs, respectively. To solve this problem, we propose a novel atlas-guided test-time adaptation (TTA) method for robust 3D medical image segmentation, called AdaAtlas. AdaAtlas only takes one single unlabeled test sample as input and adapts the segmentation network by minimizing an atlas-based loss. Specifically, the network is adapted so that its prediction after registration is aligned with the learned atlas in the atlas space, which helps to reduce anatomical segmentation errors at test time. In addition, different from most existing TTA methods which restrict the adaptation to batch normalization blocks in the segmentation network only, we further exploit the use of channel and spatial attention blocks for improved adaptability at test time. Extensive experiments on multiple datasets from different sites show that AdaAtlas with attention blocks adapted (AdaAtlas-Attention) achieves superior performance improvements, greatly outperforming other competitive TTA methods.
MovePose: A High-performance Human Pose Estimation Algorithm on Mobile and Edge Devices
Aug 17, 2023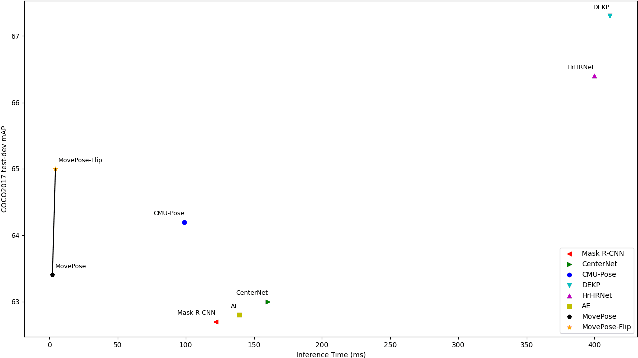
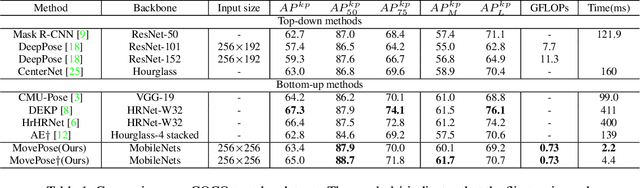
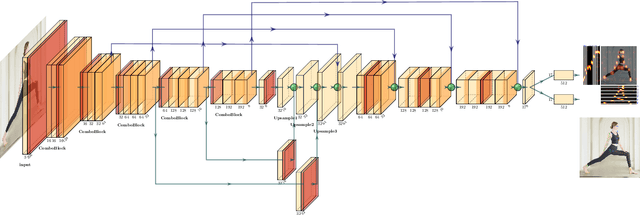
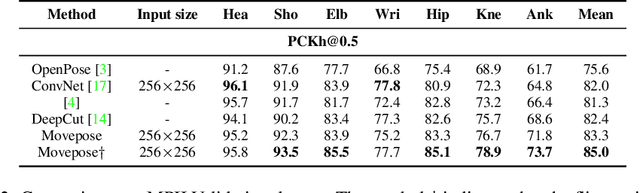
We present MovePose, an optimized lightweight convolutional neural network designed specifically for real-time body pose estimation on CPU-based mobile devices. The current solutions do not provide satisfactory accuracy and speed for human posture estimation, and MovePose addresses this gap. It aims to maintain real-time performance while improving the accuracy of human posture estimation for mobile devices. The network produces 17 keypoints for each individual at a rate exceeding 11 frames per second, making it suitable for real-time applications such as fitness tracking, sign language interpretation, and advanced mobile human posture estimation. Our MovePose algorithm has attained an Mean Average Precision (mAP) score of 67.7 on the COCO \cite{cocodata} validation dataset. The MovePose algorithm displayed efficiency with a performance of 69+ frames per second (fps) when run on an Intel i9-10920x CPU. Additionally, it showcased an increased performance of 452+ fps on an NVIDIA RTX3090 GPU. On an Android phone equipped with a Snapdragon 8 + 4G processor, the fps reached above 11. To enhance accuracy, we incorporated three techniques: deconvolution, large kernel convolution, and coordinate classification methods. Compared to basic upsampling, deconvolution is trainable, improves model capacity, and enhances the receptive field. Large kernel convolution strengthens these properties at a decreased computational cost. In summary, MovePose provides high accuracy and real-time performance, marking it a potential tool for a variety of applications, including those focused on mobile-side human posture estimation. The code and models for this algorithm will be made publicly accessible.
Explicit Estimation of Magnitude and Phase Spectra in Parallel for High-Quality Speech Enhancement
Aug 17, 2023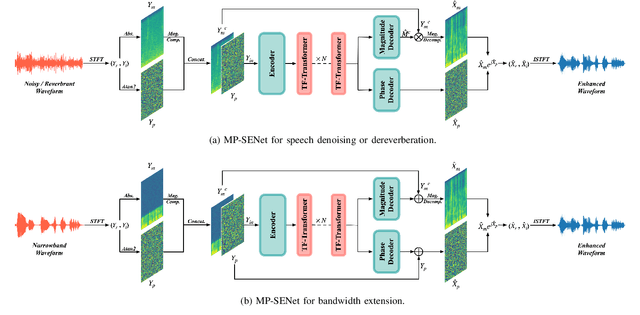
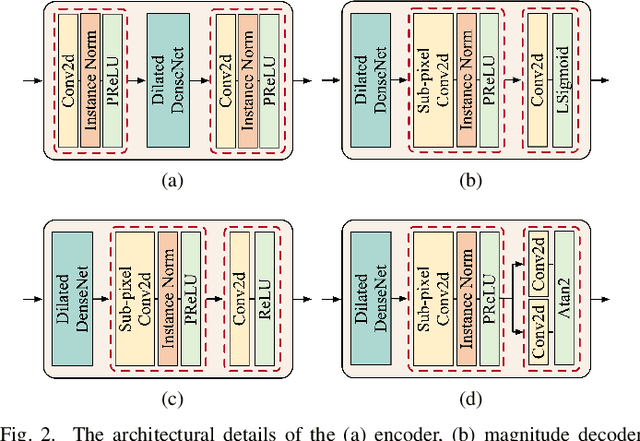
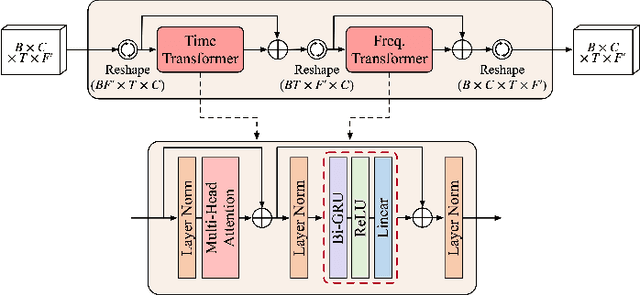
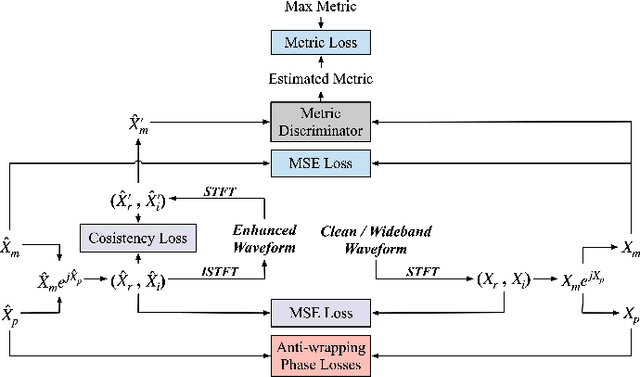
Phase information has a significant impact on speech perceptual quality and intelligibility. However, existing speech enhancement methods encounter limitations in explicit phase estimation due to the non-structural nature and wrapping characteristics of the phase, leading to a bottleneck in enhanced speech quality. To overcome the above issue, in this paper, we proposed MP-SENet, a novel Speech Enhancement Network which explicitly enhances Magnitude and Phase spectra in parallel. The proposed MP-SENet adopts a codec architecture in which the encoder and decoder are bridged by time-frequency Transformers along both time and frequency dimensions. The encoder aims to encode time-frequency representations derived from the input distorted magnitude and phase spectra. The decoder comprises dual-stream magnitude and phase decoders, directly enhancing magnitude and wrapped phase spectra by incorporating a magnitude estimation architecture and a phase parallel estimation architecture, respectively. To train the MP-SENet model effectively, we define multi-level loss functions, including mean square error and perceptual metric loss of magnitude spectra, anti-wrapping loss of phase spectra, as well as mean square error and consistency loss of short-time complex spectra. Experimental results demonstrate that our proposed MP-SENet excels in high-quality speech enhancement across multiple tasks, including speech denoising, dereverberation, and bandwidth extension. Compared to existing phase-aware speech enhancement methods, it successfully avoids the bidirectional compensation effect between the magnitude and phase, leading to a better harmonic restoration. Notably, for the speech denoising task, the MP-SENet yields a state-of-the-art performance with a PESQ of 3.60 on the public VoiceBank+DEMAND dataset.
Convolutional and Deep Learning based techniques for Time Series Ordinal Classification
Jun 16, 2023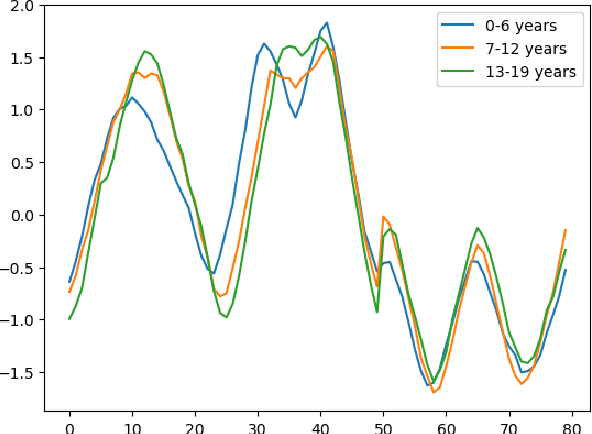

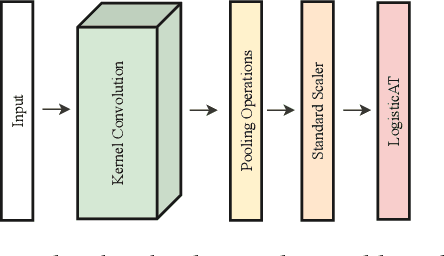
Time Series Classification (TSC) covers the supervised learning problem where input data is provided in the form of series of values observed through repeated measurements over time, and whose objective is to predict the category to which they belong. When the class values are ordinal, classifiers that take this into account can perform better than nominal classifiers. Time Series Ordinal Classification (TSOC) is the field covering this gap, yet unexplored in the literature. There are a wide range of time series problems showing an ordered label structure, and TSC techniques that ignore the order relationship discard useful information. Hence, this paper presents a first benchmarking of TSOC methodologies, exploiting the ordering of the target labels to boost the performance of current TSC state-of-the-art. Both convolutional- and deep learning-based methodologies (among the best performing alternatives for nominal TSC) are adapted for TSOC. For the experiments, a selection of 18 ordinal problems from two well-known archives has been made. In this way, this paper contributes to the establishment of the state-of-the-art in TSOC. The results obtained by ordinal versions are found to be significantly better than current nominal TSC techniques in terms of ordinal performance metrics, outlining the importance of considering the ordering of the labels when dealing with this kind of problems.
Towards predicting Pedestrian Evacuation Time and Density from Floorplans using a Vision Transformer
Jun 27, 2023

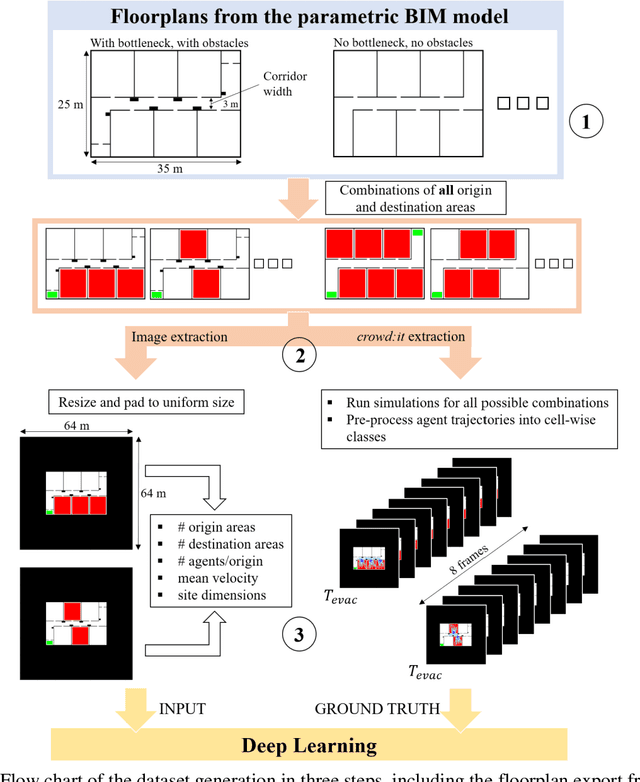
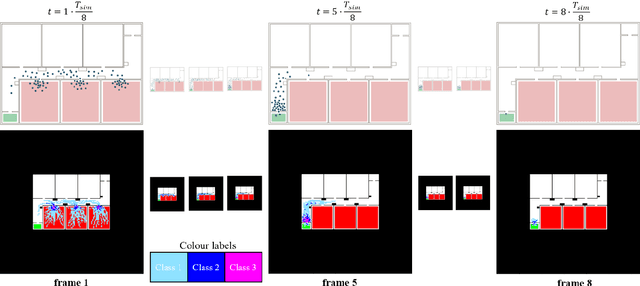
Conventional pedestrian simulators are inevitable tools in the design process of a building, as they enable project engineers to prevent overcrowding situations and plan escape routes for evacuation. However, simulation runtime and the multiple cumbersome steps in generating simulation results are potential bottlenecks during the building design process. Data-driven approaches have demonstrated their capability to outperform conventional methods in speed while delivering similar or even better results across many disciplines. In this work, we present a deep learning-based approach based on a Vision Transformer to predict density heatmaps over time and total evacuation time from a given floorplan. Specifically, due to limited availability of public datasets, we implement a parametric data generation pipeline including a conventional simulator. This enables us to build a large synthetic dataset that we use to train our architecture. Furthermore, we seamlessly integrate our model into a BIM-authoring tool to generate simulation results instantly and automatically.
Noise-Free Sampling Algorithms via Regularized Wasserstein Proximals
Aug 30, 2023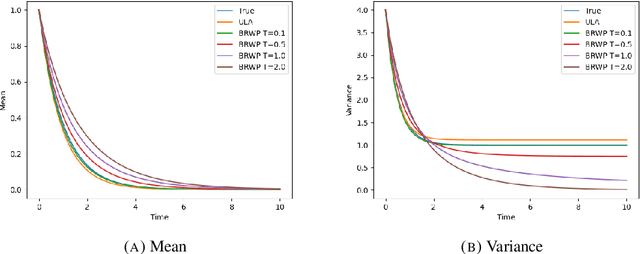
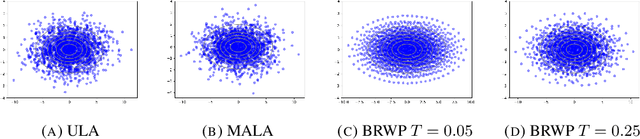
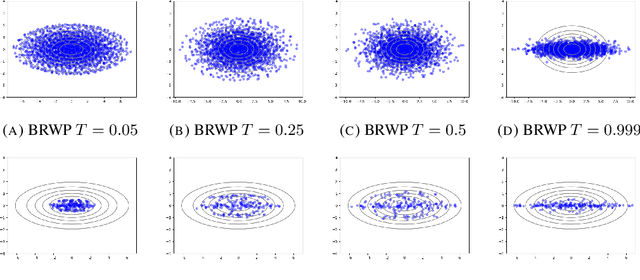
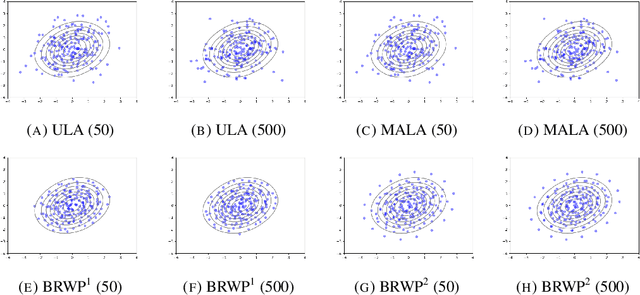
We consider the problem of sampling from a distribution governed by a potential function. This work proposes an explicit score-based MCMC method that is deterministic, resulting in a deterministic evolution for particles rather than a stochastic differential equation evolution. The score term is given in closed form by a regularized Wasserstein proximal, using a kernel convolution that is approximated by sampling. We demonstrate fast convergence on various problems and show improved dimensional dependence of mixing time bounds for the case of Gaussian distributions compared to the unadjusted Langevin algorithm (ULA) and the Metropolis-adjusted Langevin algorithm (MALA). We additionally derive closed form expressions for the distributions at each iterate for quadratic potential functions, characterizing the variance reduction. Empirical results demonstrate that the particles behave in an organized manner, lying on level set contours of the potential. Moreover, the posterior mean estimator of the proposed method is shown to be closer to the maximum a-posteriori estimator compared to ULA and MALA, in the context of Bayesian logistic regression.
Denoising Attention for Query-aware User Modeling in Personalized Search
Aug 30, 2023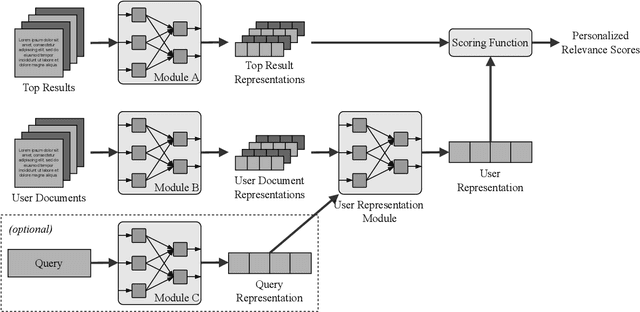
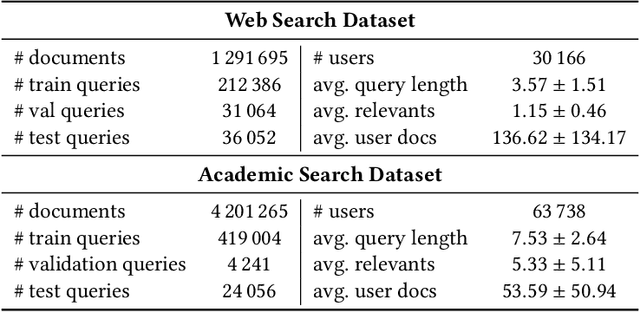
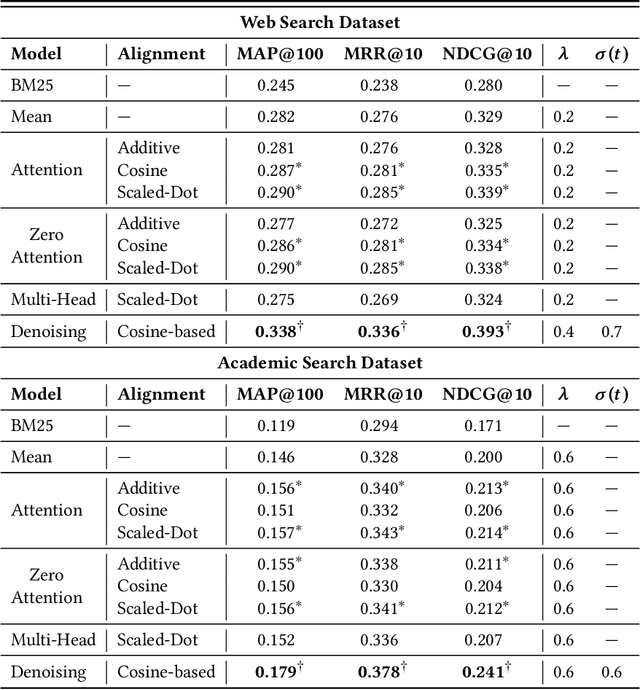
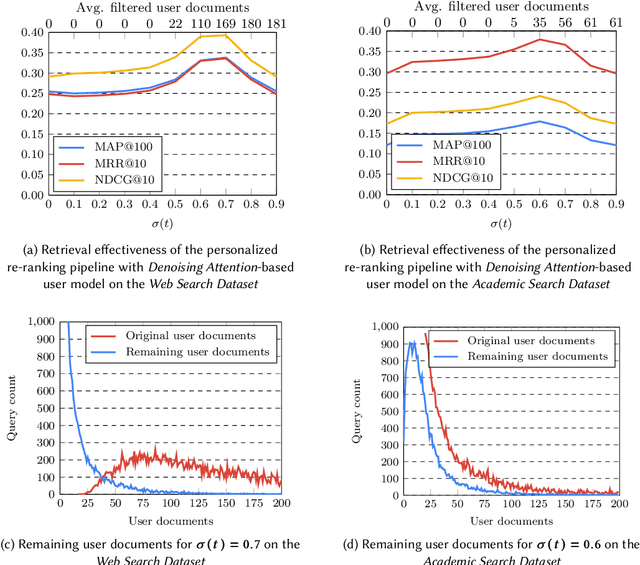
The personalization of search results has gained increasing attention in the past few years, thanks to the development of Neural Networks-based approaches for Information Retrieval and the importance of personalization in many search scenarios. Recent works have proposed to build user models at query time by leveraging the Attention mechanism, which allows weighing the contribution of the user-related information w.r.t. the current query. This approach allows taking into account the diversity of the user's interests by giving more importance to those related to the current search performed by the user. In this paper, we first discuss some shortcomings of the standard Attention formulation when employed for personalization. In particular, we focus on issues related to its normalization mechanism and its inability to entirely filter out noisy user-related information. Then, we introduce the Denoising Attention mechanism: an Attention variant that directly tackles the above shortcomings by adopting a robust normalization scheme and introducing a filtering mechanism. The reported experimental evaluation shows the benefits of the proposed approach over other Attention-based variants.
Emoji Promotes Developer Participation and Issue Resolution on GitHub
Aug 30, 2023


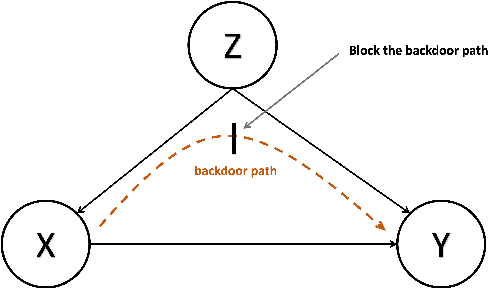
Although remote working is increasingly adopted during the pandemic, many are concerned by the low-efficiency in the remote working. Missing in text-based communication are non-verbal cues such as facial expressions and body language, which hinders the effective communication and negatively impacts the work outcomes. Prevalent on social media platforms, emojis, as alternative non-verbal cues, are gaining popularity in the virtual workspaces well. In this paper, we study how emoji usage influences developer participation and issue resolution in virtual workspaces. To this end, we collect GitHub issues for a one-year period and apply causal inference techniques to measure the causal effect of emojis on the outcome of issues, controlling for confounders such as issue content, repository, and author information. We find that emojis can significantly reduce the resolution time of issues and attract more user participation. We also compare the heterogeneous effect on different types of issues. These findings deepen our understanding of the developer communities, and they provide design implications on how to facilitate interactions and broaden developer participation.