 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal Uncertainty Localization to Enable Human-in-the-loop Analysis of Dynamic Contrast-enhanced Cardiac MRI Datasets
Aug 25, 2023
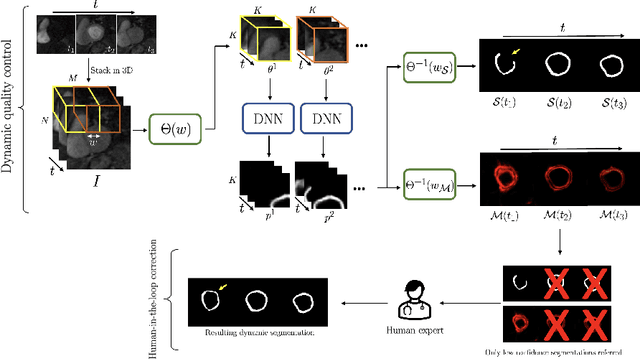

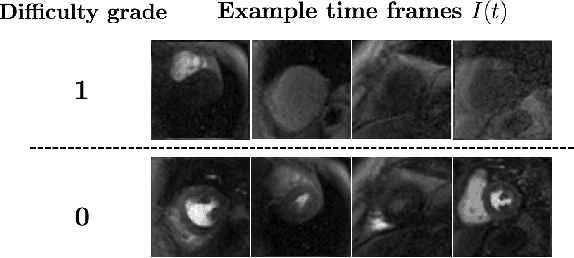
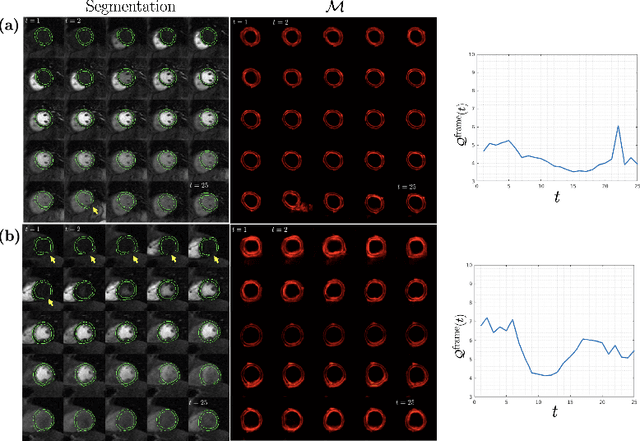
Dynamic contrast-enhanced (DCE) cardiac magnetic resonance imaging (CMRI) is a widely used modality for diagnosing myocardial blood flow (perfusion) abnormalities. During a typical free-breathing DCE-CMRI scan, close to 300 time-resolved images of myocardial perfusion are acquired at various contrast "wash in/out" phases. Manual segmentation of myocardial contours in each time-frame of a DCE image series can be tedious and time-consuming, particularly when non-rigid motion correction has failed or is unavailable. While deep neural networks (DNNs) have shown promise for analyzing DCE-CMRI datasets, a "dynamic quality control" (dQC) technique for reliably detecting failed segmentations is lacking. Here we propose a new space-time uncertainty metric as a dQC tool for DNN-based segmentation of free-breathing DCE-CMRI datasets by validating the proposed metric on an external dataset and establishing a human-in-the-loop framework to improve the segmentation results. In the proposed approach, we referred the top 10% most uncertain segmentations as detected by our dQC tool to the human expert for refinement. This approach resulted in a significant increase in the Dice score (p<0.001) and a notable decrease in the number of images with failed segmentation (16.2% to 11.3%) whereas the alternative approach of randomly selecting the same number of segmentations for human referral did not achieve any significant improvement. Our results suggest that the proposed dQC framework has the potential to accurately identify poor-quality segmentations and may enable efficient DNN-based analysis of DCE-CMRI in a human-in-the-loop pipeline for clinical interpretation and reporting of dynamic CMRI datasets.
LMBiS-Net: A Lightweight Multipath Bidirectional Skip Connection based CNN for Retinal Blood Vessel Segmentation
Sep 10, 2023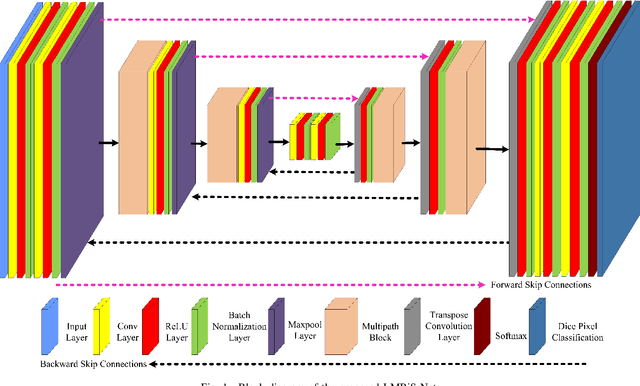
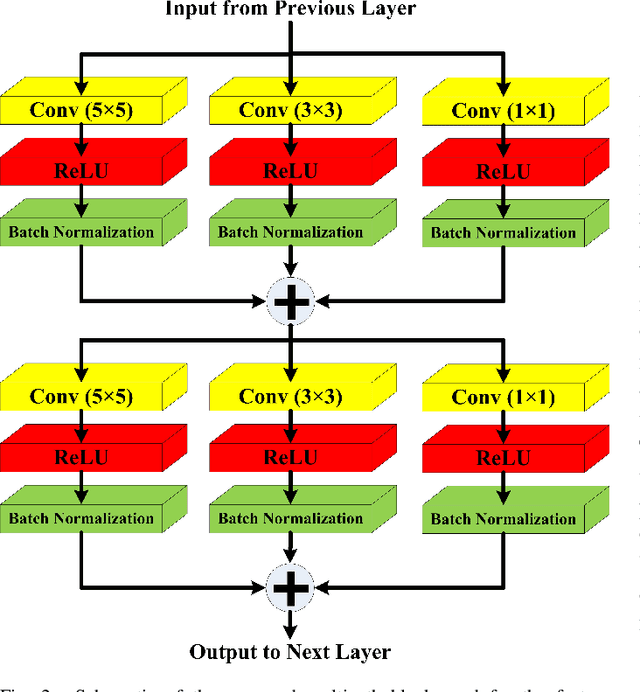
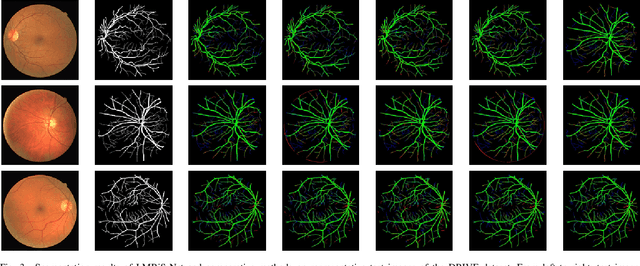
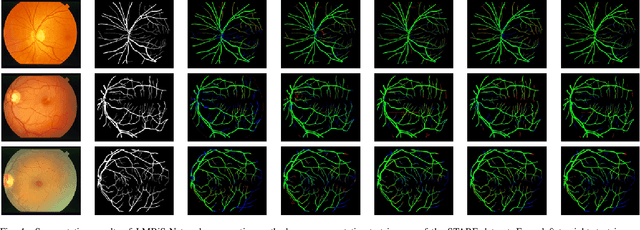
Blinding eye diseases are often correlated with altered retinal morphology, which can be clinically identified by segmenting retinal structures in fundus images. However, current methodologies often fall short in accurately segmenting delicate vessels. Although deep learning has shown promise in medical image segmentation, its reliance on repeated convolution and pooling operations can hinder the representation of edge information, ultimately limiting overall segmentation accuracy. In this paper, we propose a lightweight pixel-level CNN named LMBiS-Net for the segmentation of retinal vessels with an exceptionally low number of learnable parameters \textbf{(only 0.172 M)}. The network used multipath feature extraction blocks and incorporates bidirectional skip connections for the information flow between the encoder and decoder. Additionally, we have optimized the efficiency of the model by carefully selecting the number of filters to avoid filter overlap. This optimization significantly reduces training time and enhances computational efficiency. To assess the robustness and generalizability of LMBiS-Net, we performed comprehensive evaluations on various aspects of retinal images. Specifically, the model was subjected to rigorous tests to accurately segment retinal vessels, which play a vital role in ophthalmological diagnosis and treatment. By focusing on the retinal blood vessels, we were able to thoroughly analyze the performance and effectiveness of the LMBiS-Net model. The results of our tests demonstrate that LMBiS-Net is not only robust and generalizable but also capable of maintaining high levels of segmentation accuracy. These characteristics highlight the potential of LMBiS-Net as an efficient tool for high-speed and accurate segmentation of retinal images in various clinical applications.
Self-Supervised Pretraining Improves Performance and Inference Efficiency in Multiple Lung Ultrasound Interpretation Tasks
Sep 05, 2023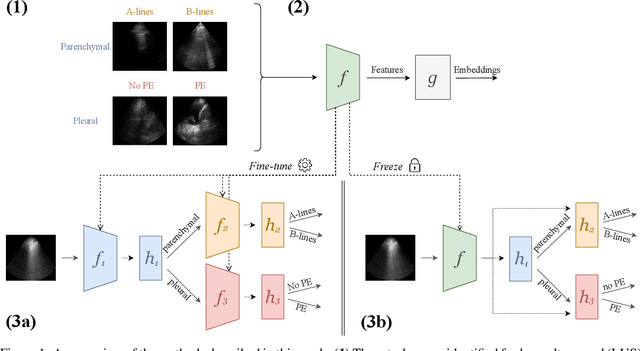

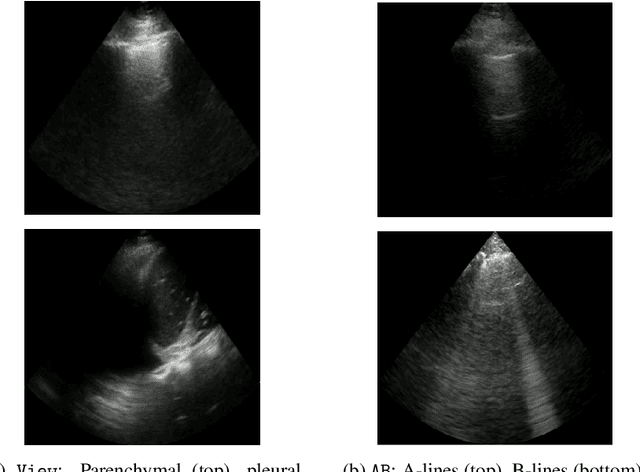
In this study, we investigated whether self-supervised pretraining could produce a neural network feature extractor applicable to multiple classification tasks in B-mode lung ultrasound analysis. When fine-tuning on three lung ultrasound tasks, pretrained models resulted in an improvement of the average across-task area under the receiver operating curve (AUC) by 0.032 and 0.061 on local and external test sets respectively. Compact nonlinear classifiers trained on features outputted by a single pretrained model did not improve performance across all tasks; however, they did reduce inference time by 49% compared to serial execution of separate fine-tuned models. When training using 1% of the available labels, pretrained models consistently outperformed fully supervised models, with a maximum observed test AUC increase of 0.396 for the task of view classification. Overall, the results indicate that self-supervised pretraining is useful for producing initial weights for lung ultrasound classifiers.
GO-SLAM: Global Optimization for Consistent 3D Instant Reconstruction
Sep 05, 2023Neural implicit representations have recently demonstrated compelling results on dense Simultaneous Localization And Mapping (SLAM) but suffer from the accumulation of errors in camera tracking and distortion in the reconstruction. Purposely, we present GO-SLAM, a deep-learning-based dense visual SLAM framework globally optimizing poses and 3D reconstruction in real-time. Robust pose estimation is at its core, supported by efficient loop closing and online full bundle adjustment, which optimize per frame by utilizing the learned global geometry of the complete history of input frames. Simultaneously, we update the implicit and continuous surface representation on-the-fly to ensure global consistency of 3D reconstruction. Results on various synthetic and real-world datasets demonstrate that GO-SLAM outperforms state-of-the-art approaches at tracking robustness and reconstruction accuracy. Furthermore, GO-SLAM is versatile and can run with monocular, stereo, and RGB-D input.
Latent Disentanglement in Mesh Variational Autoencoders Improves the Diagnosis of Craniofacial Syndromes and Aids Surgical Planning
Sep 05, 2023
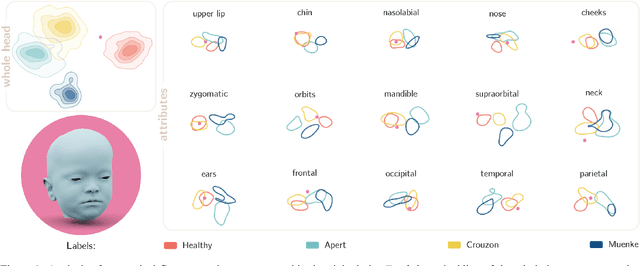
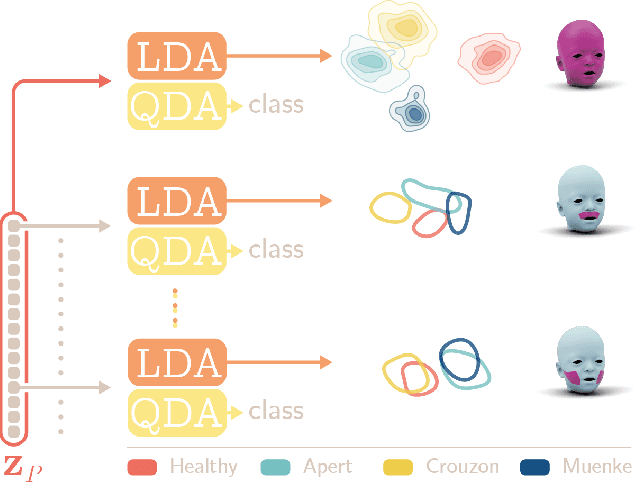
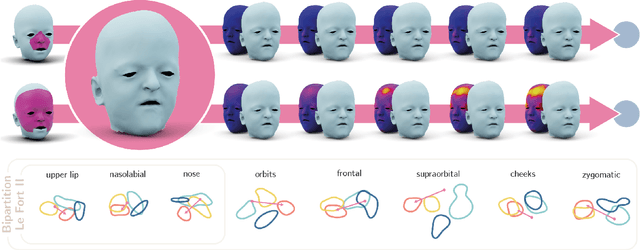
The use of deep learning to undertake shape analysis of the complexities of the human head holds great promise. However, there have traditionally been a number of barriers to accurate modelling, especially when operating on both a global and local level. In this work, we will discuss the application of the Swap Disentangled Variational Autoencoder (SD-VAE) with relevance to Crouzon, Apert and Muenke syndromes. Although syndrome classification is performed on the entire mesh, it is also possible, for the first time, to analyse the influence of each region of the head on the syndromic phenotype. By manipulating specific parameters of the generative model, and producing procedure-specific new shapes, it is also possible to simulate the outcome of a range of craniofacial surgical procedures. This opens new avenues to advance diagnosis, aids surgical planning and allows for the objective evaluation of surgical outcomes.
Decentralized Multi-Robot Social Navigation in Constrained Environments via Game-Theoretic Control Barrier Functions
Aug 31, 2023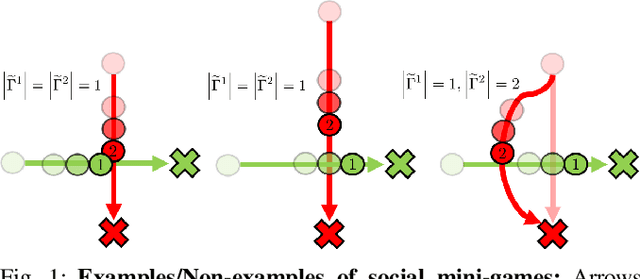
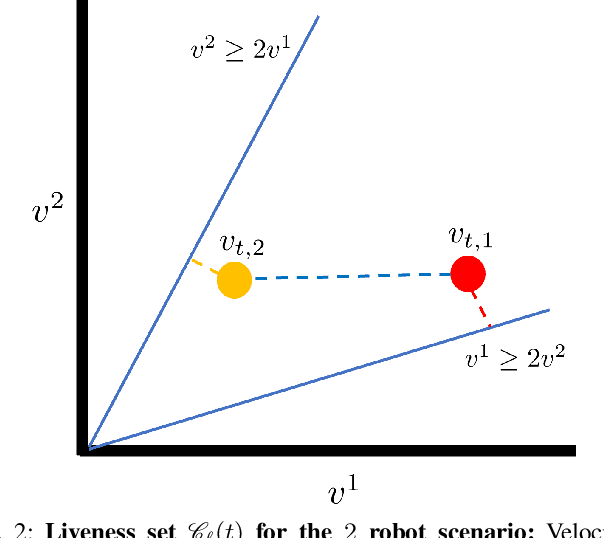
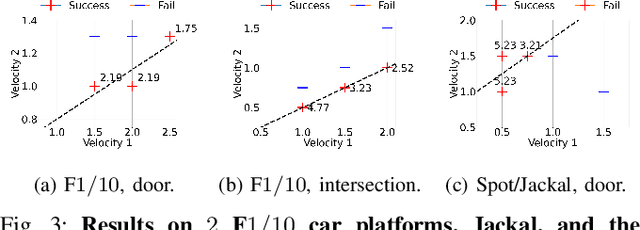

We present an approach to ensure safe and deadlock-free navigation for decentralized multi-robot systems operating in constrained environments, including doorways and intersections. Although many solutions have been proposed to ensure safety, preventing deadlocks in a decentralized fashion with global consensus remains an open problem. We first formalize the objective as a non-cooperative, non-communicative, partially observable multi-robot navigation problem in constrained spaces with multiple conflicting agents, which we term as \emph{social mini-games}. Our approach to ensuring liveness rests on two novel insights: $(i)$ there exists a mixed-strategy Nash equilibrium that allows decentralized robots to perturb their state onto \textit{liveness sets} i.e. states where robots are deadlock-free and $(ii)$ forward invariance of liveness sets can be achieved identical to how control barrier functions (CBFs) guarantee forward invariance of safety sets. We evaluate our approach in simulation as well on physical robots using F$1/10$ robots, a Clearpath Jackal, as well as a Boston Dynamics Spot in a doorway and corridor intersection scenario. Compared to both fully decentralized and centralized approaches with and without deadlock resolution capabilities, we demonstrate that our approach results in safer, more efficient, and smoother navigation, based on a comprehensive set of metrics including success rate, collision rate, stop time, change in velocity, path deviation, time-to-goal, and flow rate.
Audio-Driven Dubbing for User Generated Contents via Style-Aware Semi-Parametric Synthesis
Aug 31, 2023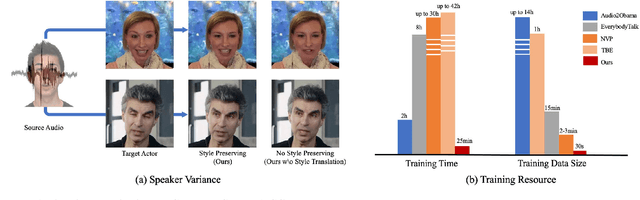
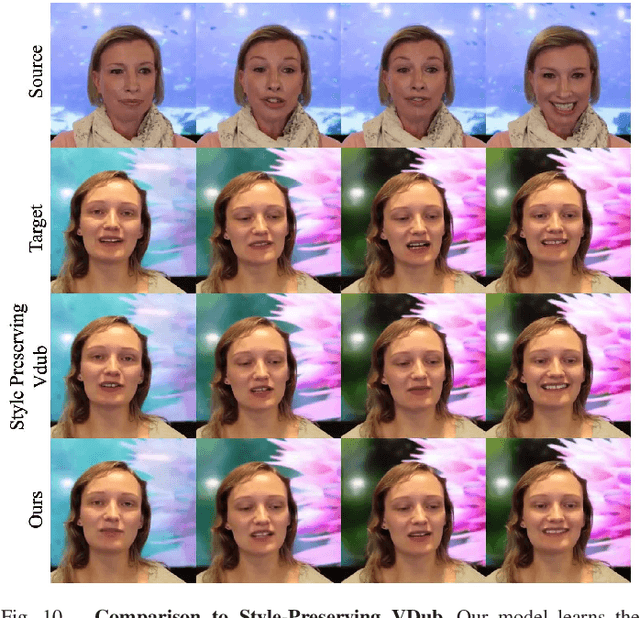
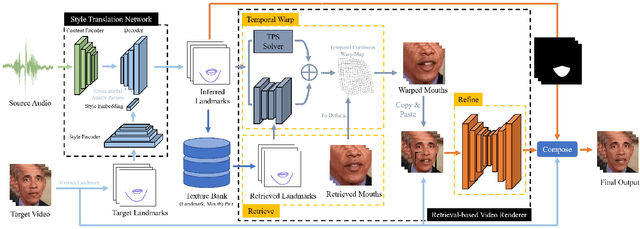
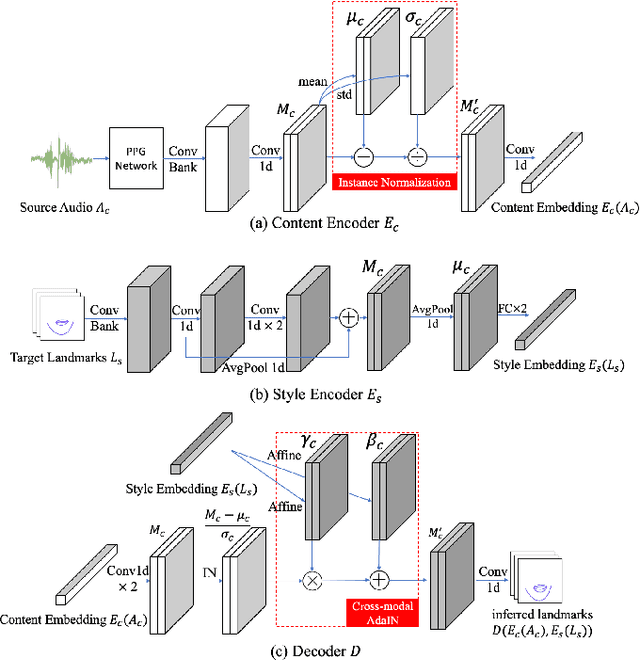
Existing automated dubbing methods are usually designed for Professionally Generated Content (PGC) production, which requires massive training data and training time to learn a person-specific audio-video mapping. In this paper, we investigate an audio-driven dubbing method that is more feasible for User Generated Content (UGC) production. There are two unique challenges to design a method for UGC: 1) the appearances of speakers are diverse and arbitrary as the method needs to generalize across users; 2) the available video data of one speaker are very limited. In order to tackle the above challenges, we first introduce a new Style Translation Network to integrate the speaking style of the target and the speaking content of the source via a cross-modal AdaIN module. It enables our model to quickly adapt to a new speaker. Then, we further develop a semi-parametric video renderer, which takes full advantage of the limited training data of the unseen speaker via a video-level retrieve-warp-refine pipeline. Finally, we propose a temporal regularization for the semi-parametric renderer, generating more continuous videos. Extensive experiments show that our method generates videos that accurately preserve various speaking styles, yet with considerably lower amount of training data and training time in comparison to existing methods. Besides, our method achieves a faster testing speed than most recent methods.
* TCSVT 2022
Physics-Based Trajectory Design for Cellular-Connected UAV in Rainy Environments Based on Deep Reinforcement Learning
Aug 31, 2023
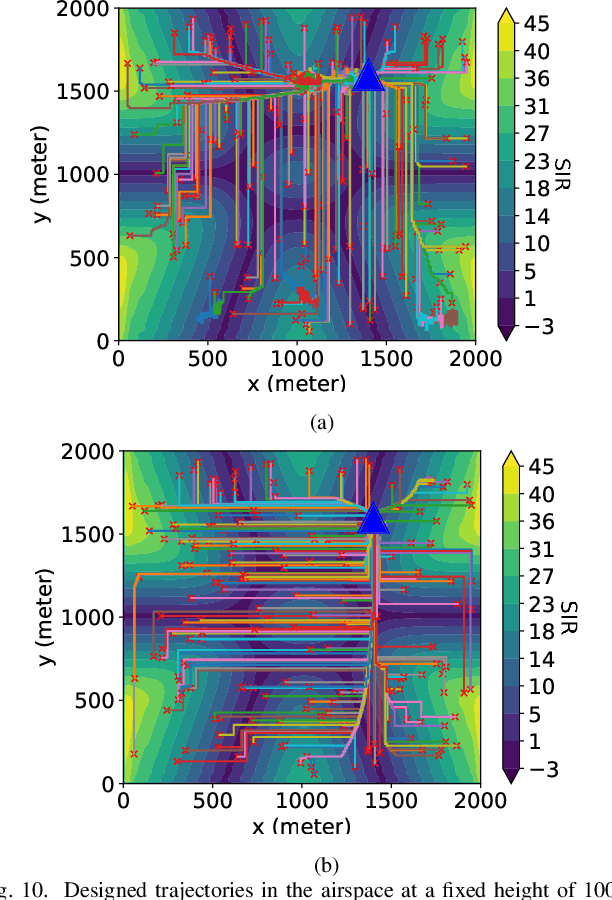
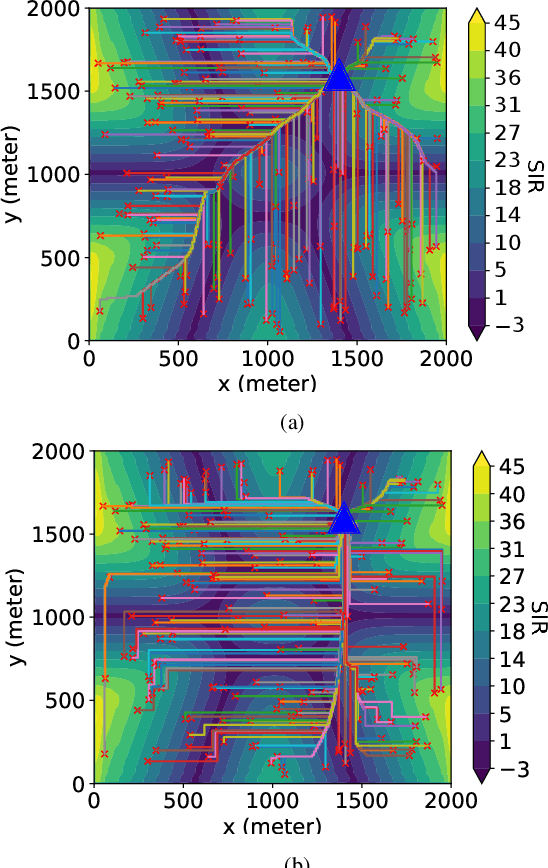
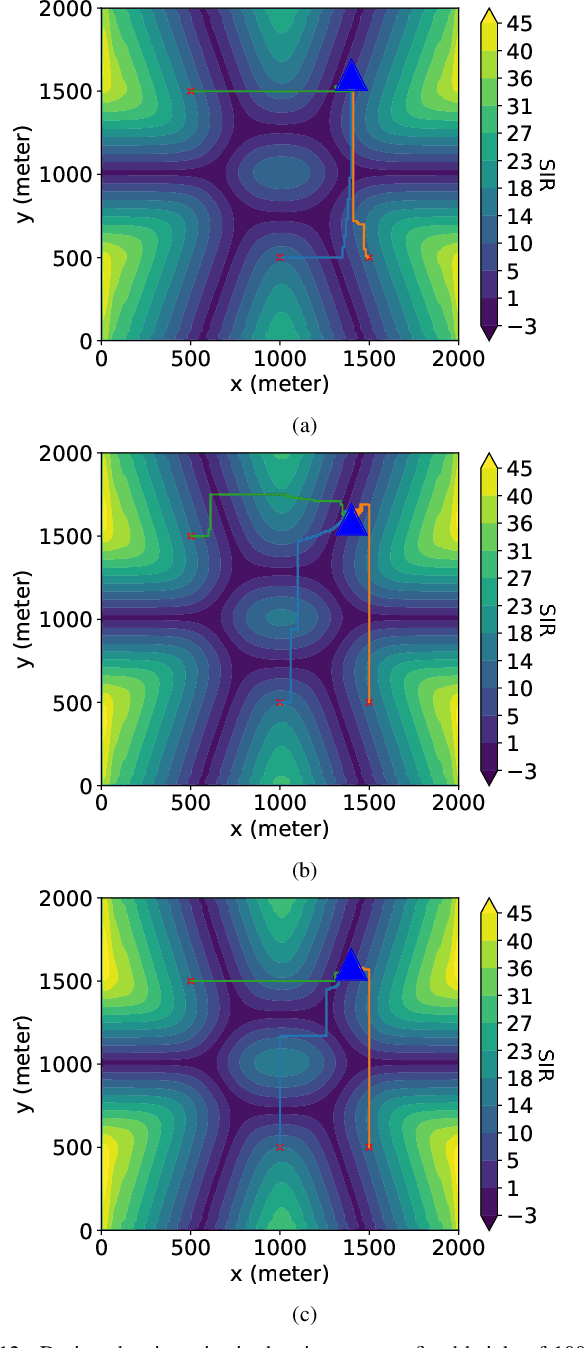
Cellular-connected unmanned aerial vehicles (UAVs) have gained increasing attention due to their potential to enhance conventional UAV capabilities by leveraging existing cellular infrastructure for reliable communications between UAVs and base stations. They have been used for various applications, including weather forecasting and search and rescue operations. However, under extreme weather conditions such as rainfall, it is challenging for the trajectory design of cellular UAVs, due to weak coverage regions in the sky, limitations of UAV flying time, and signal attenuation caused by raindrops. To this end, this paper proposes a physics-based trajectory design approach for cellular-connected UAVs in rainy environments. A physics-based electromagnetic simulator is utilized to take into account detailed environment information and the impact of rain on radio wave propagation. The trajectory optimization problem is formulated to jointly consider UAV flying time and signal-to-interference ratio, and is solved through a Markov decision process using deep reinforcement learning algorithms based on multi-step learning and double Q-learning. Optimal UAV trajectories are compared in examples with homogeneous atmosphere medium and rain medium. Additionally, a thorough study of varying weather conditions on trajectory design is provided, and the impact of weight coefficients in the problem formulation is discussed. The proposed approach has demonstrated great potential for UAV trajectory design under rainy weather conditions.
On Large Language Models' Selection Bias in Multi-Choice Questions
Sep 07, 2023
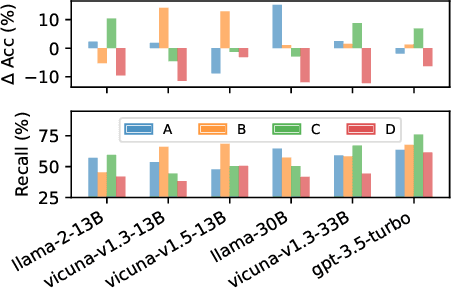
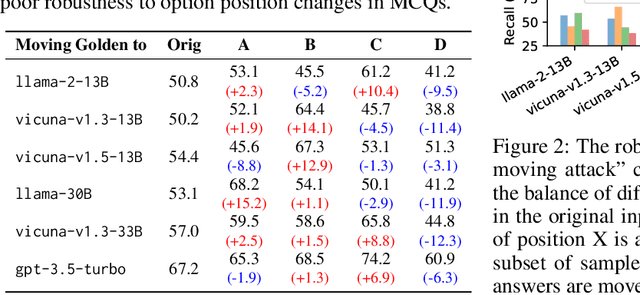
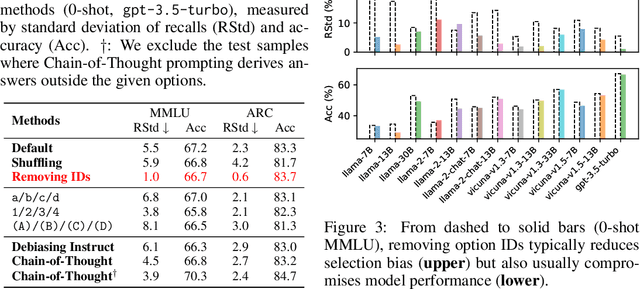
Multi-choice questions (MCQs) serve as a common yet important task format in the research of large language models (LLMs). Our work shows that LLMs exhibit an inherent "selection bias" in MCQs, which refers to LLMs' preferences to select options located at specific positions (like "Option C"). This bias is prevalent across various LLMs, making their performance vulnerable to option position changes in MCQs. We identify that one primary cause resulting in selection bias is option numbering, i.e., the ID symbols A/B/C/D associated with the options. To mitigate selection bias, we propose a new method called PriDe. PriDe first decomposes the observed model prediction distribution into an intrinsic prediction over option contents and a prior distribution over option IDs. It then estimates the prior by permutating option contents on a small number of test samples, which is used to debias the subsequent test samples. We demonstrate that, as a label-free, inference-time method, PriDe achieves a more effective and computation-efficient debiasing than strong baselines. We further show that the priors estimated by PriDe generalize well across different domains, highlighting its practical potential in broader scenarios.
Learning from Demonstration via Probabilistic Diagrammatic Teaching
Sep 07, 2023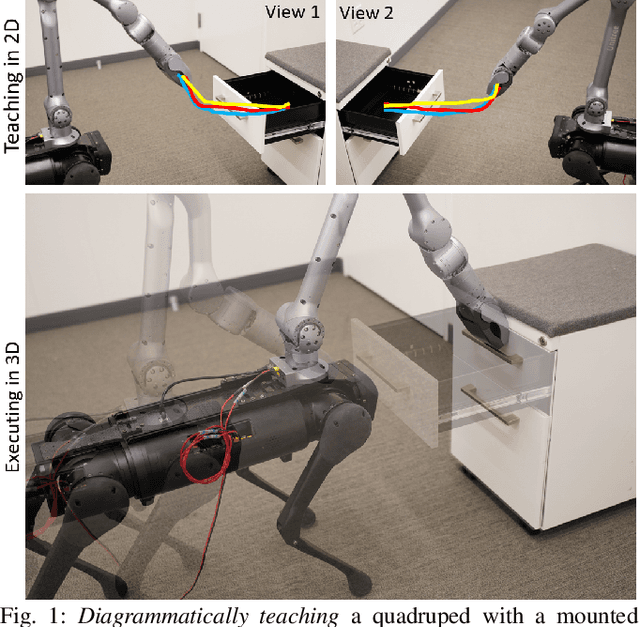

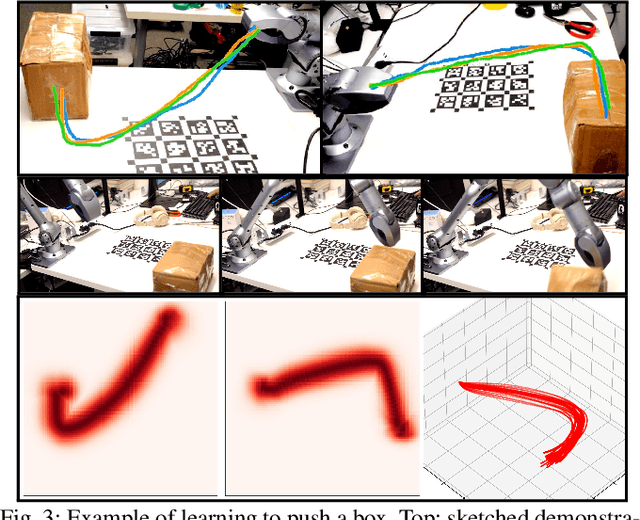
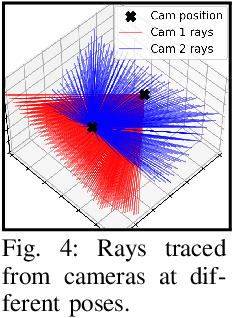
Learning for Demonstration (LfD) enables robots to acquire new skills by imitating expert demonstrations, allowing users to communicate their instructions in an intuitive manner. Recent progress in LfD often relies on kinesthetic teaching or teleoperation as the medium for users to specify the demonstrations. Kinesthetic teaching requires physical handling of the robot, while teleoperation demands proficiency with additional hardware. This paper introduces an alternative paradigm for LfD called Diagrammatic Teaching. Diagrammatic Teaching aims to teach robots novel skills by prompting the user to sketch out demonstration trajectories on 2D images of the scene, these are then synthesised as a generative model of motion trajectories in 3D task space. Additionally, we present the Ray-tracing Probabilistic Trajectory Learning (RPTL) framework for Diagrammatic Teaching. RPTL extracts time-varying probability densities from the 2D sketches, applies ray-tracing to find corresponding regions in 3D Cartesian space, and fits a probabilistic model of motion trajectories to these regions. New motion trajectories, which mimic those sketched by the user, can then be generated from the probabilistic model. We empirically validate our framework both in simulation and on real robots, which include a fixed-base manipulator and a quadruped-mounted manipulator.