 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Polynomial Bounds for Learning Noisy Optical Physical Unclonable Functions and Connections to Learning With Errors
Sep 07, 2023
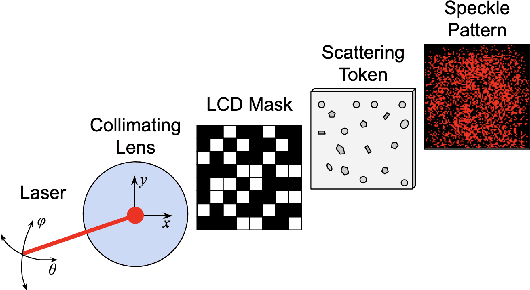
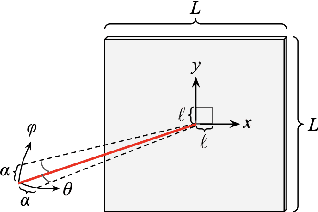

It is shown that a class of optical physical unclonable functions (PUFs) can be learned to arbitrary precision with arbitrarily high probability, even in the presence of noise, given access to polynomially many challenge-response pairs and polynomially bounded computational power, under mild assumptions about the distributions of the noise and challenge vectors. This extends the results of Rh\"uramir et al. (2013), who showed a subset of this class of PUFs to be learnable in polynomial time in the absence of noise, under the assumption that the optics of the PUF were either linear or had negligible nonlinear effects. We derive polynomial bounds for the required number of samples and the computational complexity of a linear regression algorithm, based on size parameters of the PUF, the distributions of the challenge and noise vectors, and the probability and accuracy of the regression algorithm, with a similar analysis to one done by Bootle et al. (2018), who demonstrated a learning attack on a poorly implemented version of the Learning With Errors problem.
Inverse Dynamics Trajectory Optimization for Contact-Implicit Model Predictive Control
Sep 04, 2023
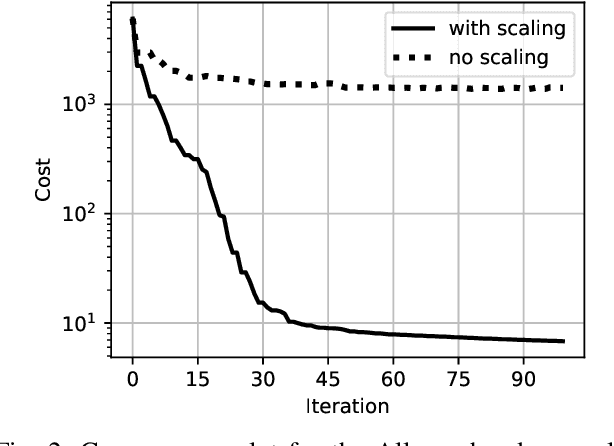
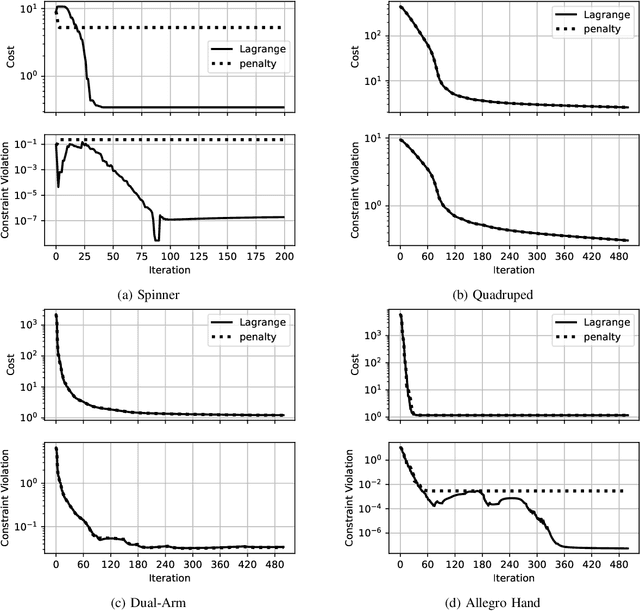
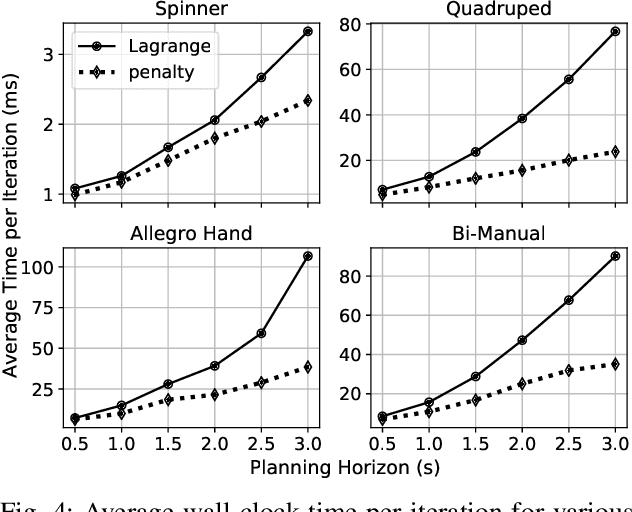
Robots must make and break contact to interact with the world and perform useful tasks. However, planning and control through contact remains a formidable challenge. In this work, we achieve real-time contact-implicit model predictive control with a surprisingly simple method: inverse dynamics trajectory optimization. While trajectory optimization with inverse dynamics is not new, we introduce a series of incremental innovations that collectively enable fast model predictive control on a variety of challenging manipulation and locomotion tasks. We implement these innovations in an open-source solver, and present a variety of simulation examples to support the effectiveness of the proposed approach. Additionally, we demonstrate contact-implicit model predictive control on hardware at over 100 Hz for a 20 degree-of-freedom bi-manual manipulation task.
Active flow control for three-dimensional cylinders through deep reinforcement learning
Sep 04, 2023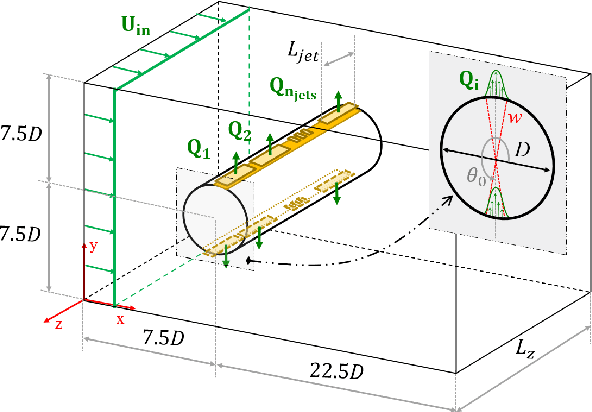

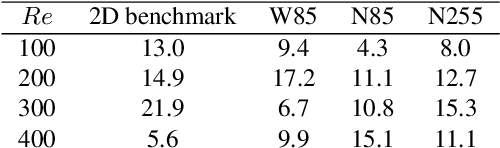
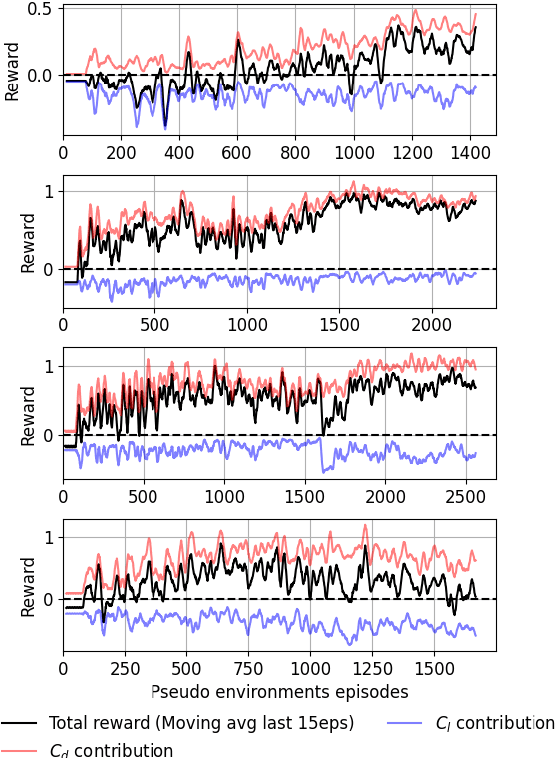
This paper presents for the first time successful results of active flow control with multiple independently controlled zero-net-mass-flux synthetic jets. The jets are placed on a three-dimensional cylinder along its span with the aim of reducing the drag coefficient. The method is based on a deep-reinforcement-learning framework that couples a computational-fluid-dynamics solver with an agent using the proximal-policy-optimization algorithm. We implement a multi-agent reinforcement-learning framework which offers numerous advantages: it exploits local invariants, makes the control adaptable to different geometries, facilitates transfer learning and cross-application of agents and results in significant training speedup. In this contribution we report significant drag reduction after applying the DRL-based control in three different configurations of the problem.
TrafficMCTS: A Closed-Loop Traffic Flow Generation Framework with Group-Based Monte Carlo Tree Search
Aug 31, 2023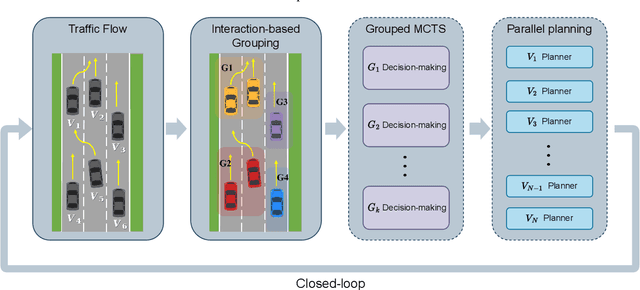


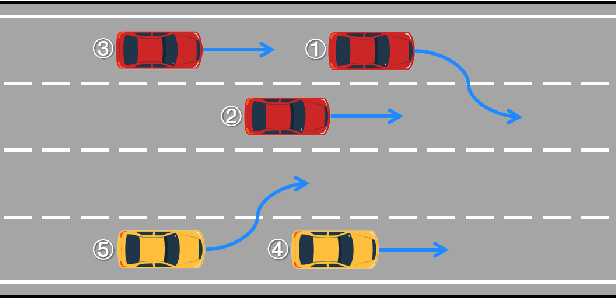
Digital twins for intelligent transportation systems are currently attracting great interests, in which generating realistic, diverse, and human-like traffic flow in simulations is a formidable challenge. Current approaches often hinge on predefined driver models, objective optimization, or reliance on pre-recorded driving datasets, imposing limitations on their scalability, versatility, and adaptability. In this paper, we introduce TrafficMCTS, an innovative framework that harnesses the synergy of groupbased Monte Carlo tree search (MCTS) and Social Value Orientation (SVO) to engender a multifaceted traffic flow replete with varying driving styles and cooperative tendencies. Anchored by a closed-loop architecture, our framework enables vehicles to dynamically adapt to their environment in real time, and ensure feasible collision-free trajectories. Through comprehensive comparisons with state-of-the-art methods, we illuminate the advantages of our approach in terms of computational efficiency, planning success rate, intent completion time, and diversity metrics. Besides, we simulate highway and roundabout scenarios to illustrate the effectiveness of the proposed framework and highlight its ability to induce diverse social behaviors within the traffic flow. Finally, we validate the scalability of TrafficMCTS by showcasing its prowess in simultaneously mass vehicles within a sprawling road network, cultivating a landscape of traffic flow that mirrors the intricacies of human behavior.
OTW: Optimal Transport Warping for Time Series
Jun 01, 2023
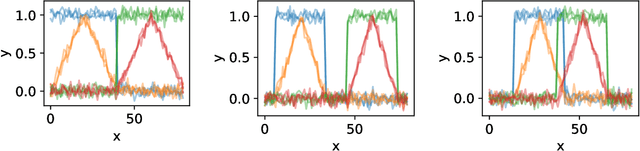
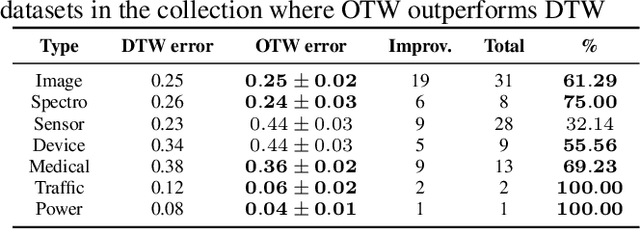
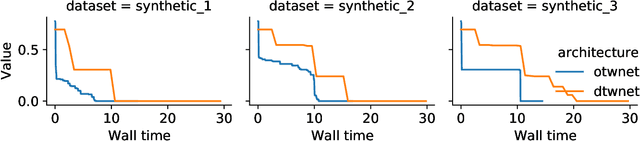
Dynamic Time Warping (DTW) has become the pragmatic choice for measuring distance between time series. However, it suffers from unavoidable quadratic time complexity when the optimal alignment matrix needs to be computed exactly. This hinders its use in deep learning architectures, where layers involving DTW computations cause severe bottlenecks. To alleviate these issues, we introduce a new metric for time series data based on the Optimal Transport (OT) framework, called Optimal Transport Warping (OTW). OTW enjoys linear time/space complexity, is differentiable and can be parallelized. OTW enjoys a moderate sensitivity to time and shape distortions, making it ideal for time series. We show the efficacy and efficiency of OTW on 1-Nearest Neighbor Classification and Hierarchical Clustering, as well as in the case of using OTW instead of DTW in Deep Learning architectures.
Harpa: High-Rate Phase Association with Travel Time Neural Fields
Jul 14, 2023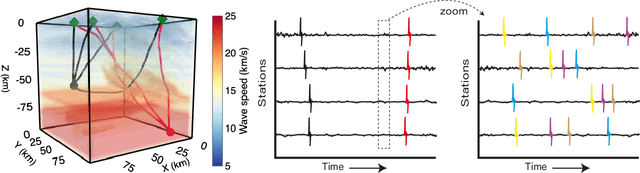
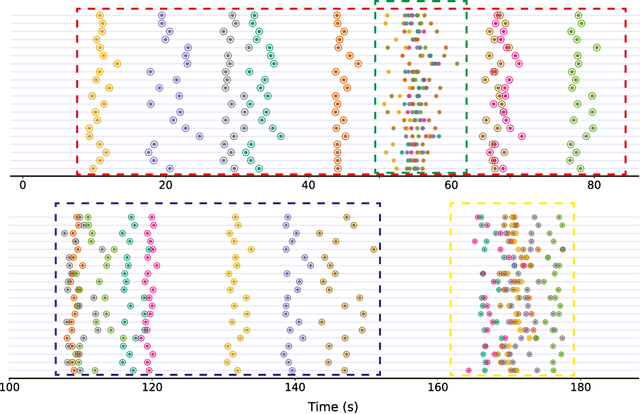
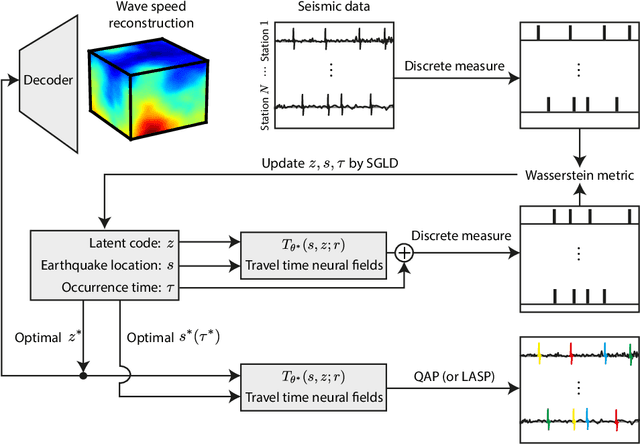
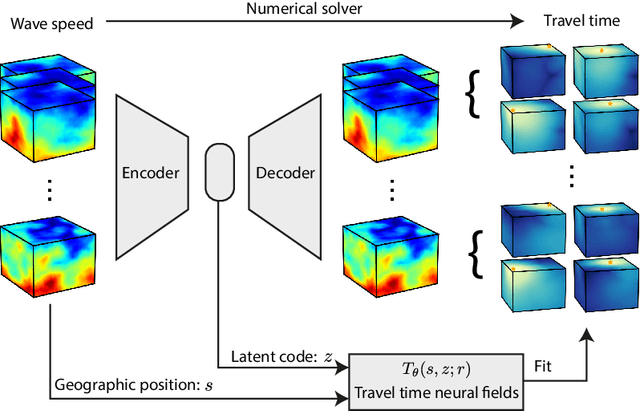
Phase association groups seismic wave arrivals according to their originating earthquakes. It is a fundamental task in a seismic data processing pipeline, but challenging to perform for smaller, high-rate seismic events which carry fundamental information about earthquake dynamics, especially with a commonly assumed inaccurate wave speed model. As a consequence, most association methods focus on larger events that occur at a lower rate and are thus easier to associate, even though microseismicity provides a valuable description of the elastic medium properties in the subsurface. In this paper, we show that association is possible at rates much higher than previously reported even when the wave speed is unknown. We propose Harpa, a high-rate seismic phase association method which leverages deep neural fields to build generative models of wave speeds and associated travel times, and first solves a joint spatio--temporal source localization and wave speed recovery problem, followed by association. We obviate the need for associated phases by interpreting arrival time data as probability measures and using an optimal transport loss to enforce data fidelity. The joint recovery problem is known to admit a unique solution under certain conditions but due to the non-convexity of the corresponding loss a simple gradient scheme converges to poor local minima. We show that this is effectively mitigated by stochastic gradient Langevin dynamics (SGLD). Numerical experiments show that \harpa~efficiently associates high-rate seismicity clouds over complex, unknown wave speeds and graciously handles noisy and missing picks.
Continuous-Time q-learning for McKean-Vlasov Control Problems
Jun 28, 2023
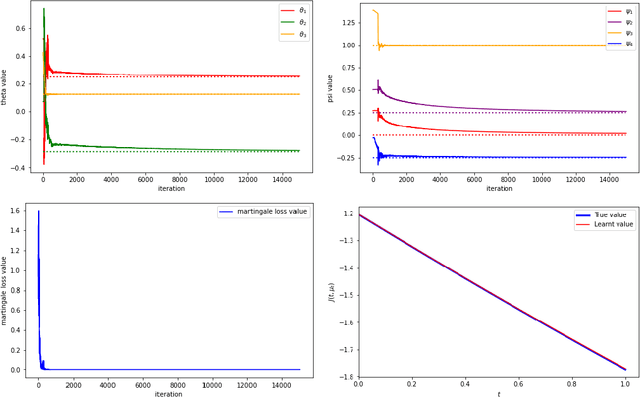
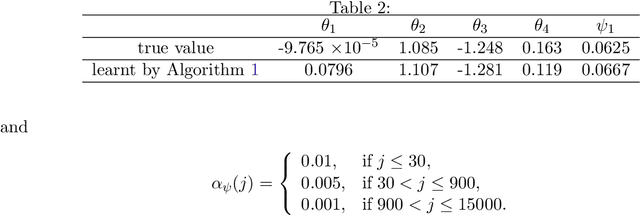
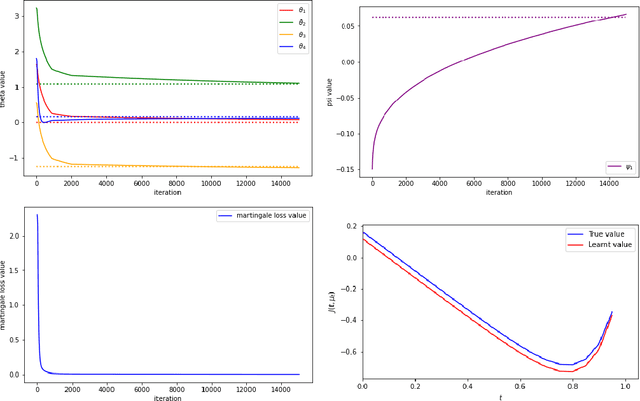
This paper studies the q-learning, recently coined as the continuous-time counterpart of Q-learning by Jia and Zhou (2022c), for continuous time Mckean-Vlasov control problems in the setting of entropy-regularized reinforcement learning. In contrast to the single agent's control problem in Jia and Zhou (2022c), the mean-field interaction of agents render the definition of q-function more subtle, for which we reveal that two distinct q-functions naturally arise: (i) the integrated q-function (denoted by $q$) as the first-order approximation of the integrated Q-function introduced in Gu, Guo, Wei and Xu (2023) that can be learnt by a weak martingale condition involving test policies; and (ii) the essential q-function (denoted by $q_e$) that is employed in the policy improvement iterations. We show that two q-functions are related via an integral representation under all test policies. Based on the weak martingale condition of the integrated q-function and our proposed searching method of test policies, some model-free offline and online learning algorithms are devised. In two financial applications, one in LQ control framework and one beyond LQ control framework, we can obtain the exact parameterization of the value function and two q-functions and illustrate our algorithms with simulation experiments.
Diving into Darkness: A Dual-Modulated Framework for High-Fidelity Super-Resolution in Ultra-Dark Environments
Sep 11, 2023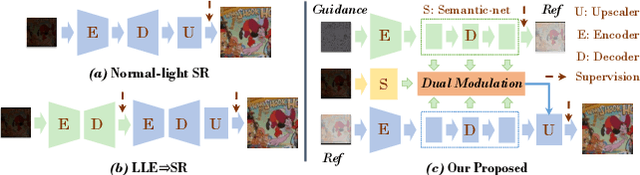
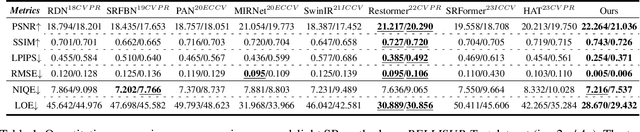


Super-resolution tasks oriented to images captured in ultra-dark environments is a practical yet challenging problem that has received little attention. Due to uneven illumination and low signal-to-noise ratio in dark environments, a multitude of problems such as lack of detail and color distortion may be magnified in the super-resolution process compared to normal-lighting environments. Consequently, conventional low-light enhancement or super-resolution methods, whether applied individually or in a cascaded manner for such problem, often encounter limitations in recovering luminance, color fidelity, and intricate details. To conquer these issues, this paper proposes a specialized dual-modulated learning framework that, for the first time, attempts to deeply dissect the nature of the low-light super-resolution task. Leveraging natural image color characteristics, we introduce a self-regularized luminance constraint as a prior for addressing uneven lighting. Expanding on this, we develop Illuminance-Semantic Dual Modulation (ISDM) components to enhance feature-level preservation of illumination and color details. Besides, instead of deploying naive up-sampling strategies, we design the Resolution-Sensitive Merging Up-sampler (RSMU) module that brings together different sampling modalities as substrates, effectively mitigating the presence of artifacts and halos. Comprehensive experiments showcases the applicability and generalizability of our approach to diverse and challenging ultra-low-light conditions, outperforming state-of-the-art methods with a notable improvement (i.e., $\uparrow$5\% in PSNR, and $\uparrow$43\% in LPIPS). Especially noteworthy is the 19-fold increase in the RMSE score, underscoring our method's exceptional generalization across different darkness levels. The code will be available online upon publication of the paper.
Towards Viewpoint Robustness in Bird's Eye View Segmentation
Sep 11, 2023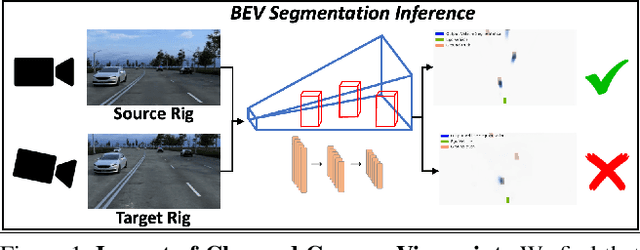


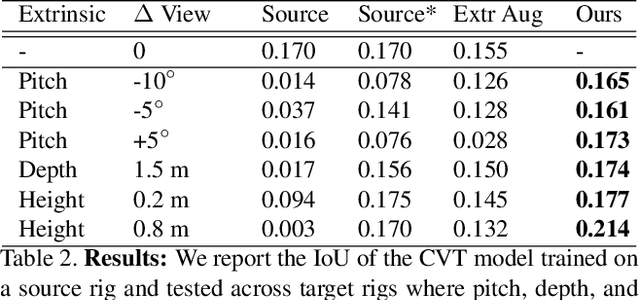
Autonomous vehicles (AV) require that neural networks used for perception be robust to different viewpoints if they are to be deployed across many types of vehicles without the repeated cost of data collection and labeling for each. AV companies typically focus on collecting data from diverse scenarios and locations, but not camera rig configurations, due to cost. As a result, only a small number of rig variations exist across most fleets. In this paper, we study how AV perception models are affected by changes in camera viewpoint and propose a way to scale them across vehicle types without repeated data collection and labeling. Using bird's eye view (BEV) segmentation as a motivating task, we find through extensive experiments that existing perception models are surprisingly sensitive to changes in camera viewpoint. When trained with data from one camera rig, small changes to pitch, yaw, depth, or height of the camera at inference time lead to large drops in performance. We introduce a technique for novel view synthesis and use it to transform collected data to the viewpoint of target rigs, allowing us to train BEV segmentation models for diverse target rigs without any additional data collection or labeling cost. To analyze the impact of viewpoint changes, we leverage synthetic data to mitigate other gaps (content, ISP, etc). Our approach is then trained on real data and evaluated on synthetic data, enabling evaluation on diverse target rigs. We release all data for use in future work. Our method is able to recover an average of 14.7% of the IoU that is otherwise lost when deploying to new rigs.
Multi-scale, Data-driven and Anatomically Constrained Deep Learning Image Registration for Adult and Fetal Echocardiography
Sep 11, 2023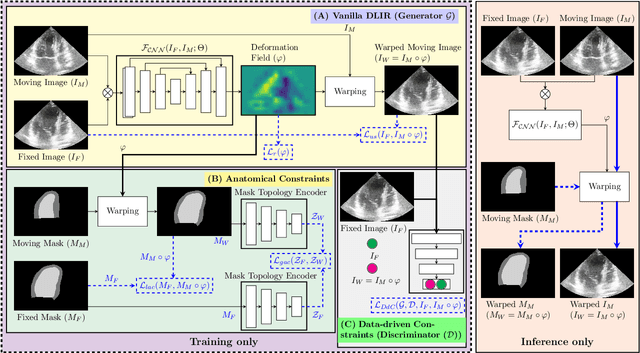

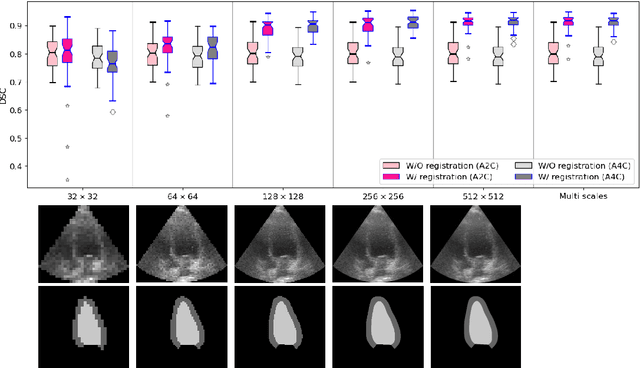
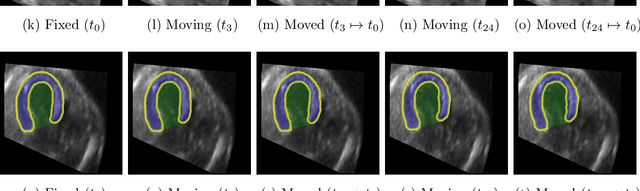
Temporal echocardiography image registration is a basis for clinical quantifications such as cardiac motion estimation, myocardial strain assessments, and stroke volume quantifications. In past studies, deep learning image registration (DLIR) has shown promising results and is consistently accurate and precise, requiring less computational time. We propose that a greater focus on the warped moving image's anatomic plausibility and image quality can support robust DLIR performance. Further, past implementations have focused on adult echocardiography, and there is an absence of DLIR implementations for fetal echocardiography. We propose a framework that combines three strategies for DLIR in both fetal and adult echo: (1) an anatomic shape-encoded loss to preserve physiological myocardial and left ventricular anatomical topologies in warped images; (2) a data-driven loss that is trained adversarially to preserve good image texture features in warped images; and (3) a multi-scale training scheme of a data-driven and anatomically constrained algorithm to improve accuracy. Our tests show that good anatomical topology and image textures are strongly linked to shape-encoded and data-driven adversarial losses. They improve different aspects of registration performance in a non-overlapping way, justifying their combination. Despite fundamental distinctions between adult and fetal echo images, we show that these strategies can provide excellent registration results in both adult and fetal echocardiography using the publicly available CAMUS adult echo dataset and our private multi-demographic fetal echo dataset. Our approach outperforms traditional non-DL gold standard registration approaches, including Optical Flow and Elastix. Registration improvements could be translated to more accurate and precise clinical quantification of cardiac ejection fraction, demonstrating a potential for translation.