 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Kernel Multigrid: Accelerate Back-fitting via Sparse Gaussian Process Regression
Mar 30, 2024

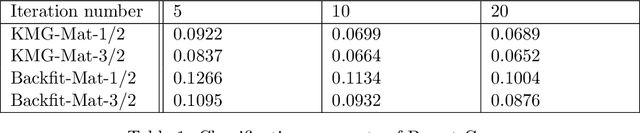
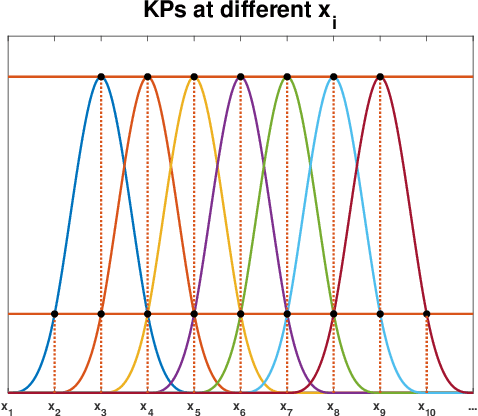
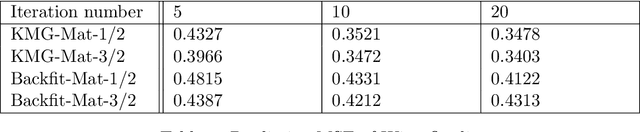
Additive Gaussian Processes (GPs) are popular approaches for nonparametric feature selection. The common training method for these models is Bayesian Back-fitting. However, the convergence rate of Back-fitting in training additive GPs is still an open problem. By utilizing a technique called Kernel Packets (KP), we prove that the convergence rate of Back-fitting is no faster than $(1-\mathcal{O}(\frac{1}{n}))^t$, where $n$ and $t$ denote the data size and the iteration number, respectively. Consequently, Back-fitting requires a minimum of $\mathcal{O}(n\log n)$ iterations to achieve convergence. Based on KPs, we further propose an algorithm called Kernel Multigrid (KMG). This algorithm enhances Back-fitting by incorporating a sparse Gaussian Process Regression (GPR) to process the residuals after each Back-fitting iteration. It is applicable to additive GPs with both structured and scattered data. Theoretically, we prove that KMG reduces the required iterations to $\mathcal{O}(\log n)$ while preserving the time and space complexities at $\mathcal{O}(n\log n)$ and $\mathcal{O}(n)$ per iteration, respectively. Numerically, by employing a sparse GPR with merely 10 inducing points, KMG can produce accurate approximations of high-dimensional targets within 5 iterations.
CoDa: Constrained Generation based Data Augmentation for Low-Resource NLP
Mar 30, 2024We present CoDa (Constrained Generation based Data Augmentation), a controllable, effective, and training-free data augmentation technique for low-resource (data-scarce) NLP. Our approach is based on prompting off-the-shelf instruction-following Large Language Models (LLMs) for generating text that satisfies a set of constraints. Precisely, we extract a set of simple constraints from every instance in the low-resource dataset and verbalize them to prompt an LLM to generate novel and diverse training instances. Our findings reveal that synthetic data that follows simple constraints in the downstream dataset act as highly effective augmentations, and CoDa can achieve this without intricate decoding-time constrained generation techniques or fine-tuning with complex algorithms that eventually make the model biased toward the small number of training instances. Additionally, CoDa is the first framework that provides users explicit control over the augmentation generation process, thereby also allowing easy adaptation to several domains. We demonstrate the effectiveness of CoDa across 11 datasets spanning 3 tasks and 3 low-resource settings. CoDa outperforms all our baselines, qualitatively and quantitatively, with improvements of 0.12%-7.19%. Code is available here: https://github.com/Sreyan88/CoDa
LITA: Language Instructed Temporal-Localization Assistant
Mar 27, 2024There has been tremendous progress in multimodal Large Language Models (LLMs). Recent works have extended these models to video input with promising instruction following capabilities. However, an important missing piece is temporal localization. These models cannot accurately answer the "When?" questions. We identify three key aspects that limit their temporal localization capabilities: (i) time representation, (ii) architecture, and (iii) data. We address these shortcomings by proposing Language Instructed Temporal-Localization Assistant (LITA) with the following features: (1) We introduce time tokens that encode timestamps relative to the video length to better represent time in videos. (2) We introduce SlowFast tokens in the architecture to capture temporal information at fine temporal resolution. (3) We emphasize temporal localization data for LITA. In addition to leveraging existing video datasets with timestamps, we propose a new task, Reasoning Temporal Localization (RTL), along with the dataset, ActivityNet-RTL, for learning and evaluating this task. Reasoning temporal localization requires both the reasoning and temporal localization of Video LLMs. LITA demonstrates strong performance on this challenging task, nearly doubling the temporal mean intersection-over-union (mIoU) of baselines. In addition, we show that our emphasis on temporal localization also substantially improves video-based text generation compared to existing Video LLMs, including a 36% relative improvement of Temporal Understanding. Code is available at: https://github.com/NVlabs/LITA
D'OH: Decoder-Only random Hypernetworks for Implicit Neural Representations
Mar 28, 2024Deep implicit functions have been found to be an effective tool for efficiently encoding all manner of natural signals. Their attractiveness stems from their ability to compactly represent signals with little to no off-line training data. Instead, they leverage the implicit bias of deep networks to decouple hidden redundancies within the signal. In this paper, we explore the hypothesis that additional compression can be achieved by leveraging the redundancies that exist between layers. We propose to use a novel run-time decoder-only hypernetwork - that uses no offline training data - to better model this cross-layer parameter redundancy. Previous applications of hyper-networks with deep implicit functions have applied feed-forward encoder/decoder frameworks that rely on large offline datasets that do not generalize beyond the signals they were trained on. We instead present a strategy for the initialization of run-time deep implicit functions for single-instance signals through a Decoder-Only randomly projected Hypernetwork (D'OH). By directly changing the dimension of a latent code to approximate a target implicit neural architecture, we provide a natural way to vary the memory footprint of neural representations without the costly need for neural architecture search on a space of alternative low-rate structures.
On the Feasibility of EEG-based Motor Intention Detection for Real-Time Robot Assistive Control
Mar 13, 2024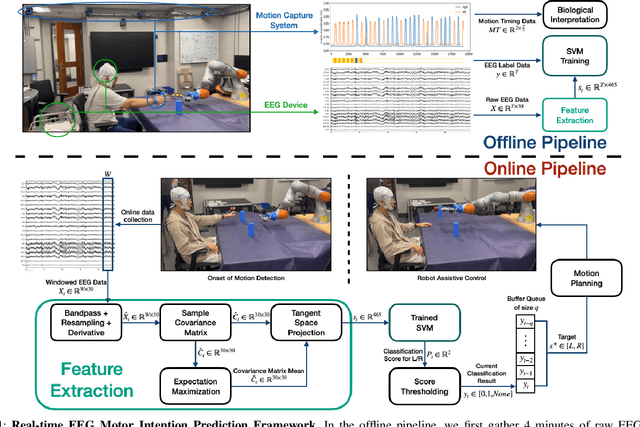
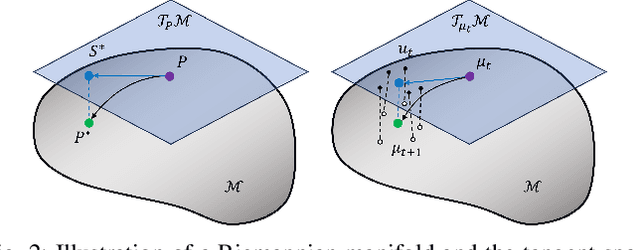
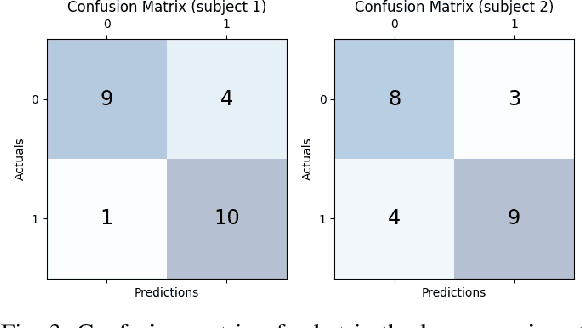
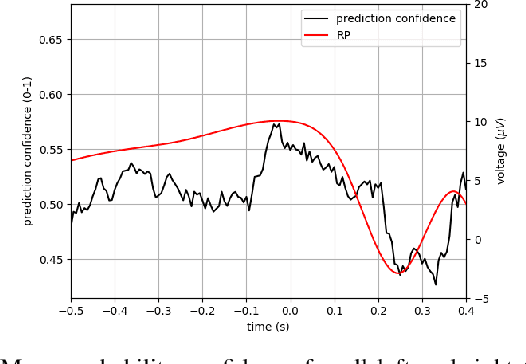
This paper explores the feasibility of employing EEG-based intention detection for real-time robot assistive control. We focus on predicting and distinguishing motor intentions of left/right arm movements by presenting: i) an offline data collection and training pipeline, used to train a classifier for left/right motion intention prediction, and ii) an online real-time prediction pipeline leveraging the trained classifier and integrated with an assistive robot. Central to our approach is a rich feature representation composed of the tangent space projection of time-windowed sample covariance matrices from EEG filtered signals and derivatives; allowing for a simple SVM classifier to achieve unprecedented accuracy and real-time performance. In pre-recorded real-time settings (160 Hz), a peak accuracy of 86.88% is achieved, surpassing prior works. In robot-in-the-loop settings, our system successfully detects intended motion solely from EEG data with 70% accuracy, triggering a robot to execute an assistive task. We provide a comprehensive evaluation of the proposed classifier.
Enhancing Multiple Object Tracking Accuracy via Quantum Annealing
Mar 27, 2024Multiple object tracking (MOT), a key task in image recognition, presents a persistent challenge in balancing processing speed and tracking accuracy. This study introduces a novel approach that leverages quantum annealing (QA) to expedite computation speed, while enhancing tracking accuracy through the ensembling of object tracking processes. A method to improve the matching integration process is also proposed. By utilizing the sequential nature of MOT, this study further augments the tracking method via reverse annealing (RA). Experimental validation confirms the maintenance of high accuracy with an annealing time of a mere 3 $\mu$s per tracking process. The proposed method holds significant potential for real-time MOT applications, including traffic flow measurement for urban traffic light control, collision prediction for autonomous robots and vehicles, and management of products mass-produced in factories.
Low-Cost and Real-Time Industrial Human Action Recognitions Based on Large-Scale Foundation Models
Mar 13, 2024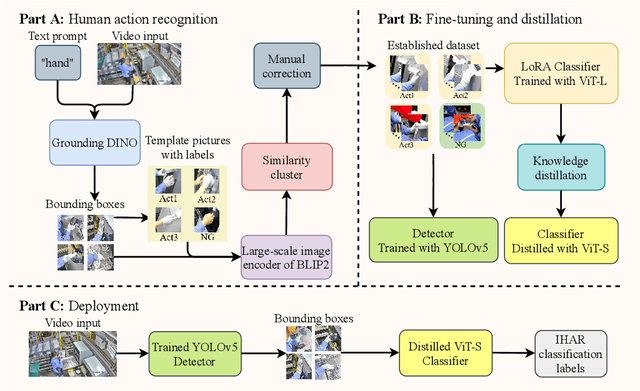
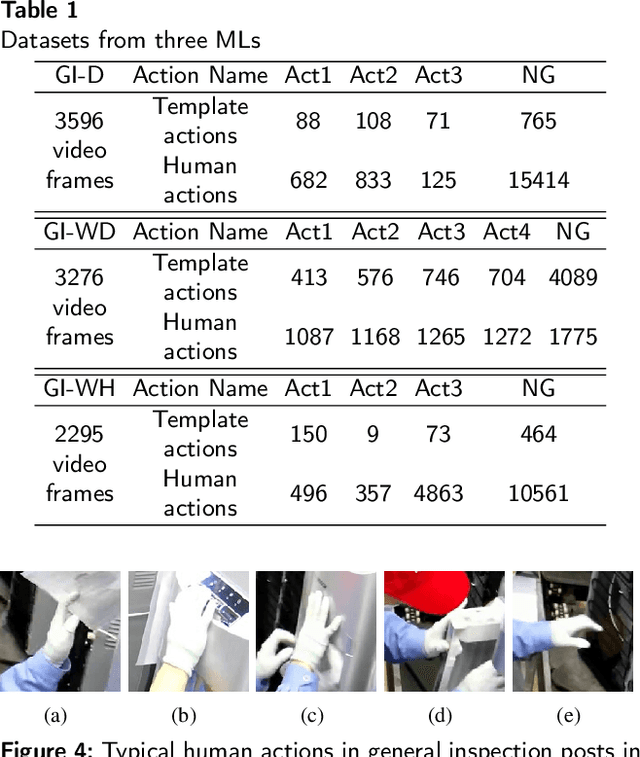
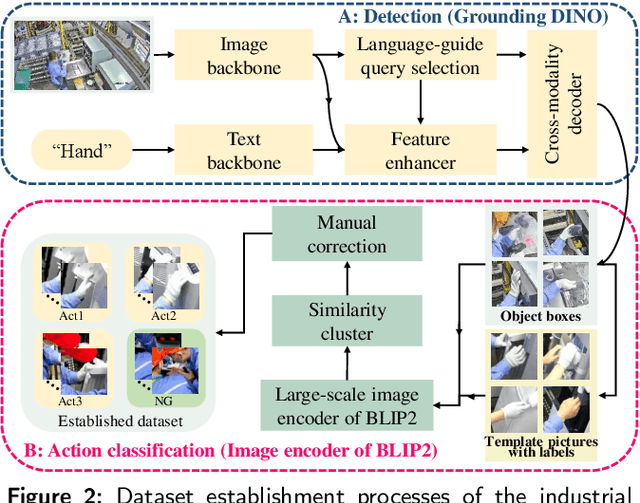
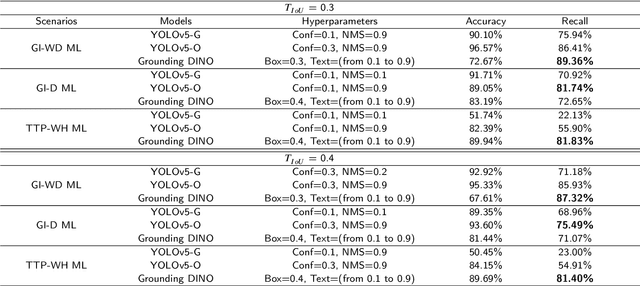
Industrial managements, including quality control, cost and safety optimization, etc., heavily rely on high quality industrial human action recognitions (IHARs) which were hard to be implemented in large-scale industrial scenes due to their high costs and poor real-time performance. In this paper, we proposed a large-scale foundation model(LSFM)-based IHAR method, wherein various LSFMs and lightweight methods were jointly used, for the first time, to fulfill low-cost dataset establishment and real-time IHARs. Comprehensive tests on in-situ large-scale industrial manufacturing lines elucidated that the proposed method realized great reduction on employment costs, superior real-time performance, and satisfactory accuracy and generalization capabilities, indicating its great potential as a backbone IHAR method, especially for large-scale industrial applications.
Resource Allocation in Large Language Model Integrated 6G Vehicular Networks
Mar 27, 2024In the upcoming 6G era, vehicular networks are shifting from simple Vehicle-to-Vehicle (V2V) communication to the more complex Vehicle-to-Everything (V2X) connectivity. At the forefront of this shift is the incorporation of Large Language Models (LLMs) into vehicles. Known for their sophisticated natural language processing abilities, LLMs change how users interact with their vehicles. This integration facilitates voice-driven commands and interactions, departing from the conventional manual control systems. However, integrating LLMs into vehicular systems presents notable challenges. The substantial computational demands and energy requirements of LLMs pose significant challenges, especially in the constrained environment of a vehicle. Additionally, the time-sensitive nature of tasks in vehicular networks adds another layer of complexity. In this paper, we consider an edge computing system where vehicles process the initial layers of LLM computations locally, and offload the remaining LLM computation tasks to the Roadside Units (RSUs), envisioning a vehicular ecosystem where LLM computations seamlessly interact with the ultra-low latency and high-bandwidth capabilities of 6G networks. To balance the trade-off between completion time and energy consumption, we formulate a multi-objective optimization problem to minimize the total cost of the vehicles and RSUs. The problem is then decomposed into two sub-problems, which are solved by sequential quadratic programming (SQP) method and fractional programming technique. The simulation results clearly indicate that the algorithm we have proposed is highly effective in reducing both the completion time and energy consumption of the system.
From Learning to Analytics: Improving Model Efficacy with Goal-Directed Client Selection
Mar 30, 2024Federated learning (FL) is an appealing paradigm for learning a global model among distributed clients while preserving data privacy. Driven by the demand for high-quality user experiences, evaluating the well-trained global model after the FL process is crucial. In this paper, we propose a closed-loop model analytics framework that allows for effective evaluation of the trained global model using clients' local data. To address the challenges posed by system and data heterogeneities in the FL process, we study a goal-directed client selection problem based on the model analytics framework by selecting a subset of clients for the model training. This problem is formulated as a stochastic multi-armed bandit (SMAB) problem. We first put forth a quick initial upper confidence bound (Quick-Init UCB) algorithm to solve this SMAB problem under the federated analytics (FA) framework. Then, we further propose a belief propagation-based UCB (BP-UCB) algorithm under the democratized analytics (DA) framework. Moreover, we derive two regret upper bounds for the proposed algorithms, which increase logarithmically over the time horizon. The numerical results demonstrate that the proposed algorithms achieve nearly optimal performance, with a gap of less than 1.44% and 3.12% under the FA and DA frameworks, respectively.
Small Language Models Learn Enhanced Reasoning Skills from Medical Textbooks
Mar 30, 2024While recent advancements in commercial large language models (LM) have shown promising results in medical tasks, their closed-source nature poses significant privacy and security concerns, hindering their widespread use in the medical field. Despite efforts to create open-source models, their limited parameters often result in insufficient multi-step reasoning capabilities required for solving complex medical problems. To address this, we introduce Meerkat-7B, a novel medical AI system with 7 billion parameters. Meerkat-7B was trained using our new synthetic dataset consisting of high-quality chain-of-thought reasoning paths sourced from 18 medical textbooks, along with diverse instruction-following datasets. Our system achieved remarkable accuracy across seven medical benchmarks, surpassing GPT-3.5 by 13.1%, as well as outperforming the previous best 7B models such as MediTron-7B and BioMistral-7B by 13.4% and 9.8%, respectively. Notably, it surpassed the passing threshold of the United States Medical Licensing Examination (USMLE) for the first time for a 7B-parameter model. Additionally, our system offered more detailed free-form responses to clinical queries compared to existing 7B and 13B models, approaching the performance level of GPT-3.5. This significantly narrows the performance gap with large LMs, showcasing its effectiveness in addressing complex medical challenges.