 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Experience and Prediction: A Metric of Hardness for a Novel Litmus Test
Sep 05, 2023
In the last decade, the Winograd Schema Challenge (WSC) has become a central aspect of the research community as a novel litmus test. Consequently, the WSC has spurred research interest because it can be seen as the means to understand human behavior. In this regard, the development of new techniques has made possible the usage of Winograd schemas in various fields, such as the design of novel forms of CAPTCHAs. Work from the literature that established a baseline for human adult performance on the WSC has shown that not all schemas are the same, meaning that they could potentially be categorized according to their perceived hardness for humans. In this regard, this \textit{hardness-metric} could be used in future challenges or in the WSC CAPTCHA service to differentiate between Winograd schemas. Recent work of ours has shown that this could be achieved via the design of an automated system that is able to output the hardness-indexes of Winograd schemas, albeit with limitations regarding the number of schemas it could be applied on. This paper adds to previous research by presenting a new system that is based on Machine Learning (ML), able to output the hardness of any Winograd schema faster and more accurately than any other previously used method. Our developed system, which works within two different approaches, namely the random forest and deep learning (LSTM-based), is ready to be used as an extension of any other system that aims to differentiate between Winograd schemas, according to their perceived hardness for humans. At the same time, along with our developed system we extend previous work by presenting the results of a large-scale experiment that shows how human performance varies across Winograd schemas.
* 33 pages, 10 figures,
Fast and High-Performance Learned Image Compression With Improved Checkerboard Context Model, Deformable Residual Module, and Knowledge Distillation
Sep 05, 2023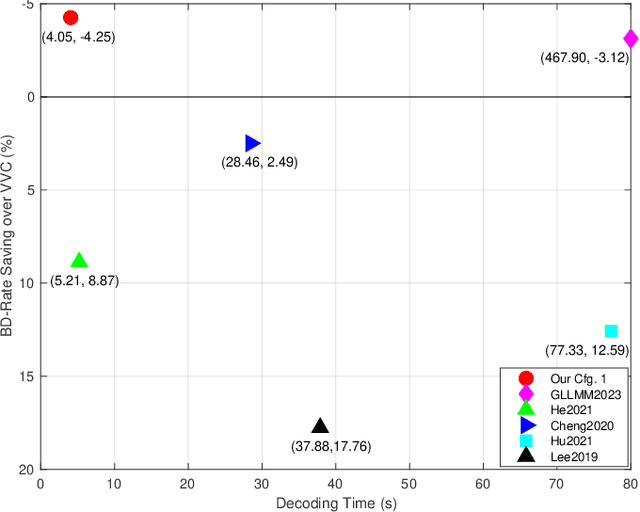
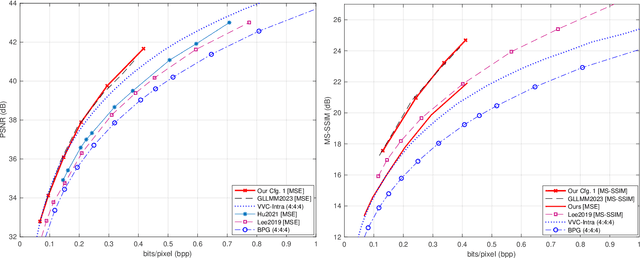
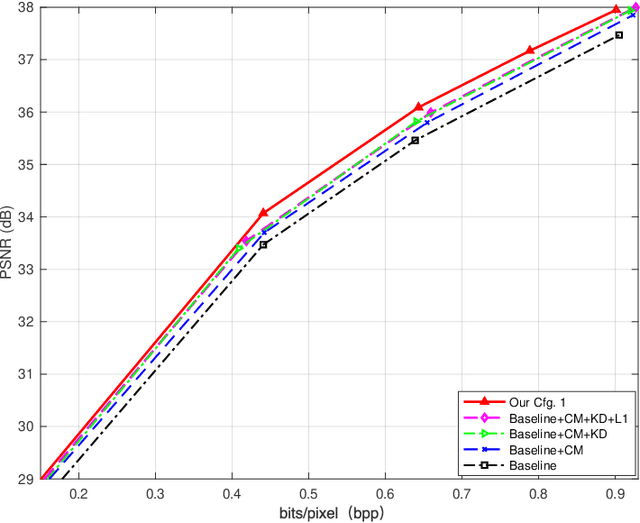
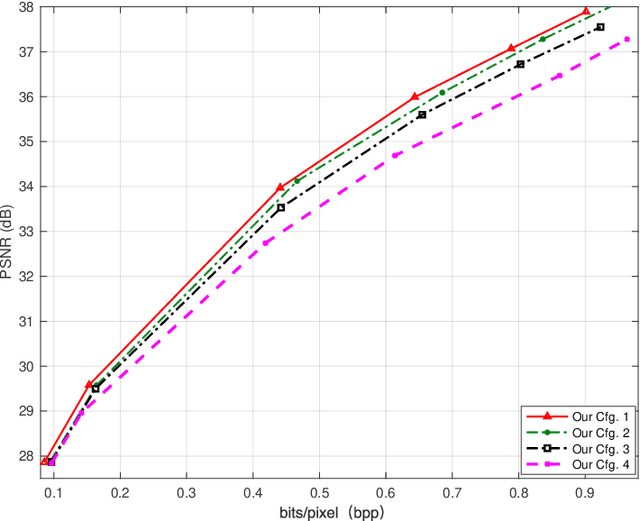
Deep learning-based image compression has made great progresses recently. However, many leading schemes use serial context-adaptive entropy model to improve the rate-distortion (R-D) performance, which is very slow. In addition, the complexities of the encoding and decoding networks are quite high and not suitable for many practical applications. In this paper, we introduce four techniques to balance the trade-off between the complexity and performance. We are the first to introduce deformable convolutional module in compression framework, which can remove more redundancies in the input image, thereby enhancing compression performance. Second, we design a checkerboard context model with two separate distribution parameter estimation networks and different probability models, which enables parallel decoding without sacrificing the performance compared to the sequential context-adaptive model. Third, we develop an improved three-step knowledge distillation and training scheme to achieve different trade-offs between the complexity and the performance of the decoder network, which transfers both the final and intermediate results of the teacher network to the student network to help its training. Fourth, we introduce $L_{1}$ regularization to make the numerical values of the latent representation more sparse. Then we only encode non-zero channels in the encoding and decoding process, which can greatly reduce the encoding and decoding time. Experiments show that compared to the state-of-the-art learned image coding scheme, our method can be about 20 times faster in encoding and 70-90 times faster in decoding, and our R-D performance is also $2.3 \%$ higher. Our method outperforms the traditional approach in H.266/VVC-intra (4:4:4) and some leading learned schemes in terms of PSNR and MS-SSIM metrics when testing on Kodak and Tecnick-40 datasets.
Advanced Underwater Image Restoration in Complex Illumination Conditions
Sep 05, 2023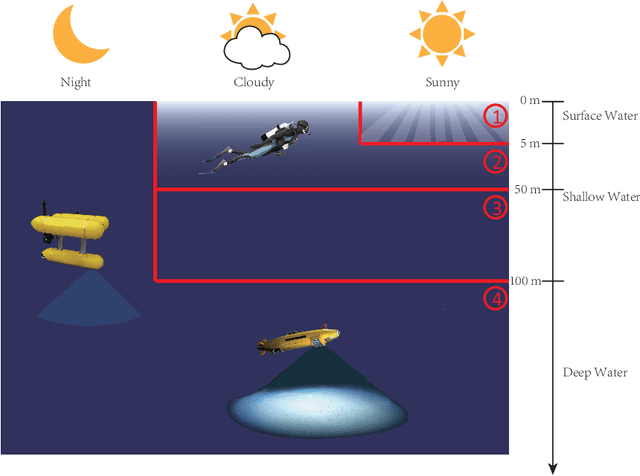

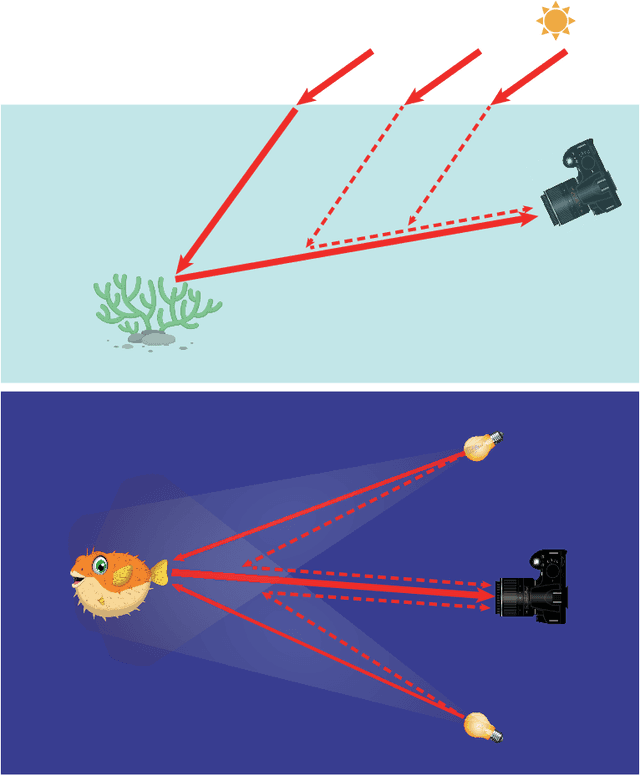
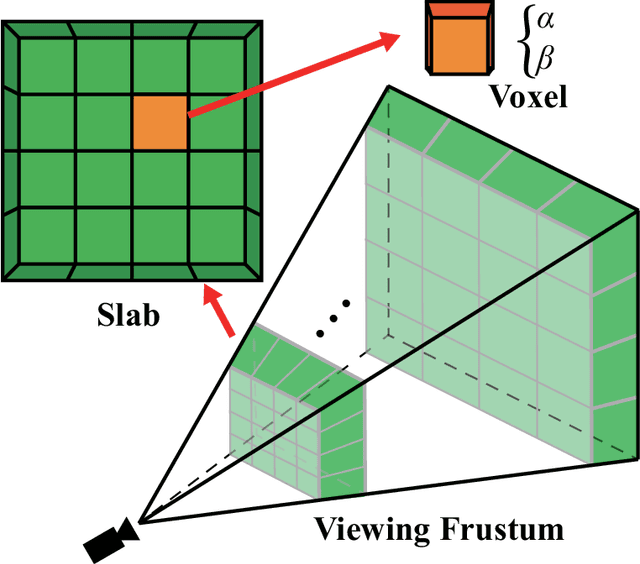
Underwater image restoration has been a challenging problem for decades since the advent of underwater photography. Most solutions focus on shallow water scenarios, where the scene is uniformly illuminated by the sunlight. However, the vast majority of uncharted underwater terrain is located beyond 200 meters depth where natural light is scarce and artificial illumination is needed. In such cases, light sources co-moving with the camera, dynamically change the scene appearance, which make shallow water restoration methods inadequate. In particular for multi-light source systems (composed of dozens of LEDs nowadays), calibrating each light is time-consuming, error-prone and tedious, and we observe that only the integrated illumination within the viewing volume of the camera is critical, rather than the individual light sources. The key idea of this paper is therefore to exploit the appearance changes of objects or the seafloor, when traversing the viewing frustum of the camera. Through new constraints assuming Lambertian surfaces, corresponding image pixels constrain the light field in front of the camera, and for each voxel a signal factor and a backscatter value are stored in a volumetric grid that can be used for very efficient image restoration of camera-light platforms, which facilitates consistently texturing large 3D models and maps that would otherwise be dominated by lighting and medium artifacts. To validate the effectiveness of our approach, we conducted extensive experiments on simulated and real-world datasets. The results of these experiments demonstrate the robustness of our approach in restoring the true albedo of objects, while mitigating the influence of lighting and medium effects. Furthermore, we demonstrate our approach can be readily extended to other scenarios, including in-air imaging with artificial illumination or other similar cases.
Time-Frequency-Space Transmit Design and Signal Processing with Dynamic Subarray for Terahertz Integrated Sensing and Communication
Jul 10, 2023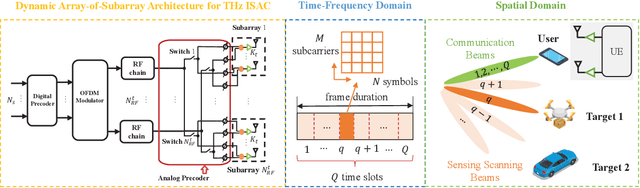
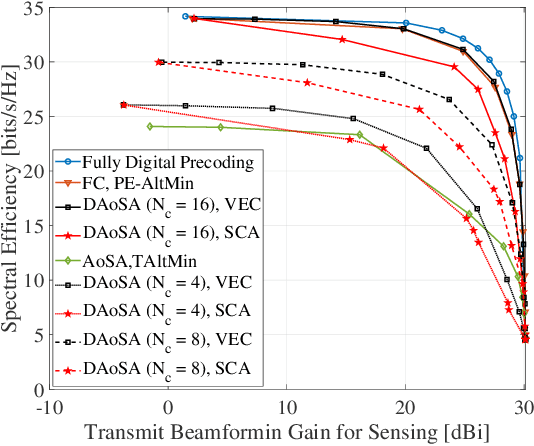
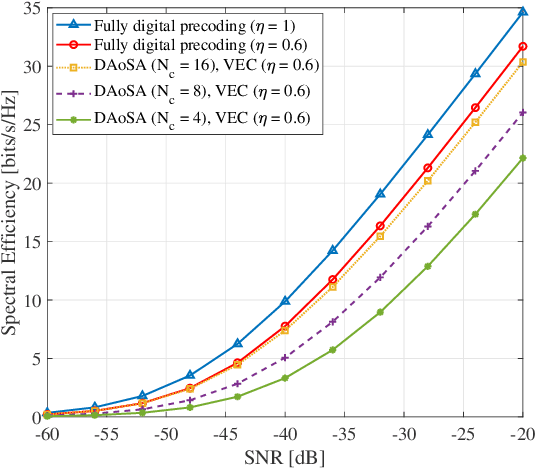
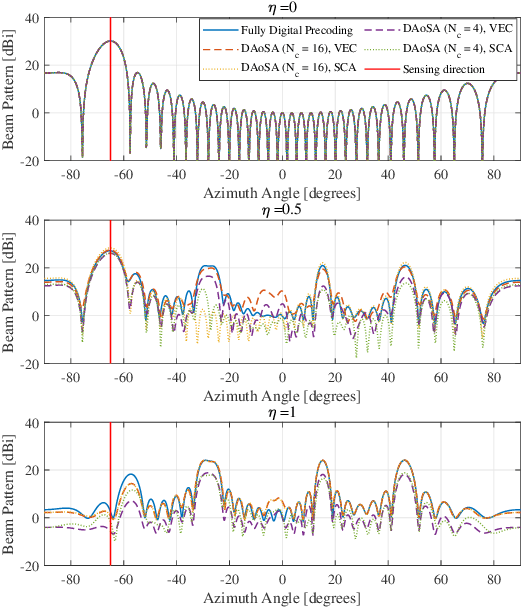
Terahertz (THz) integrated sensing and communication (ISAC) enables simultaneous data transmission with Terabit-per-second (Tbps) rate and millimeter-level accurate sensing. To realize such a blueprint, ultra-massive antenna arrays with directional beamforming are used to compensate for severe path loss in the THz band. In this paper, the time-frequency-space transmit design is investigated for THz ISAC to generate time-varying scanning sensing beams and stable communication beams. Specifically, with the dynamic array-of-subarray (DAoSA) hybrid beamforming architecture and multi-carrier modulation, two ISAC hybrid precoding algorithms are proposed, namely, a vectorization (VEC) based algorithm that outperforms existing ISAC hybrid precoding methods and a low-complexity sensing codebook assisted (SCA) approach. Meanwhile, coupled with the transmit design, parameter estimation algorithms are proposed to realize high-accuracy sensing, including a wideband DAoSA MUSIC (W-DAoSA-MUSIC) method for angle estimation and a sum-DFT-GSS (S-DFT-GSS) approach for range and velocity estimation. Numerical results indicate that the proposed algorithms can realize centi-degree-level angle estimation accuracy and millimeter-level range estimation accuracy, which are one or two orders of magnitudes better than the methods in the millimeter-wave band. In addition, to overcome the cyclic prefix limitation and Doppler effects in the THz band, an inter-symbol interference- and inter-carrier interference-tackled sensing algorithm is developed to refine sensing capabilities for THz ISAC.
Self-supervised Scene Text Segmentation with Object-centric Layered Representations Augmented by Text Regions
Aug 25, 2023Text segmentation tasks have a very wide range of application values, such as image editing, style transfer, watermark removal, etc.However, existing public datasets are of poor quality of pixel-level labels that have been shown to be notoriously costly to acquire, both in terms of money and time. At the same time, when pretraining is performed on synthetic datasets, the data distribution of the synthetic datasets is far from the data distribution in the real scene. These all pose a huge challenge to the current pixel-level text segmentation algorithms.To alleviate the above problems, we propose a self-supervised scene text segmentation algorithm with layered decoupling of representations derived from the object-centric manner to segment images into texts and background. In our method, we propose two novel designs which include Region Query Module and Representation Consistency Constraints adapting to the unique properties of text as complements to Auto Encoder, which improves the network's sensitivity to texts.For this unique design, we treat the polygon-level masks predicted by the text localization model as extra input information, and neither utilize any pixel-level mask annotations for training stage nor pretrain on synthetic datasets.Extensive experiments show the effectiveness of the method proposed. On several public scene text datasets, our method outperforms the state-of-the-art unsupervised segmentation algorithms.
Fine-Grained Spatiotemporal Motion Alignment for Contrastive Video Representation Learning
Sep 01, 2023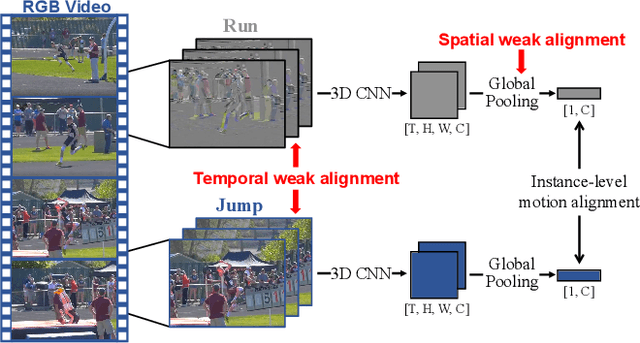
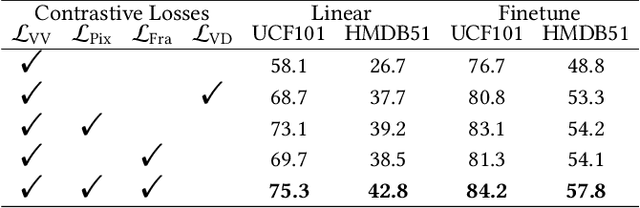
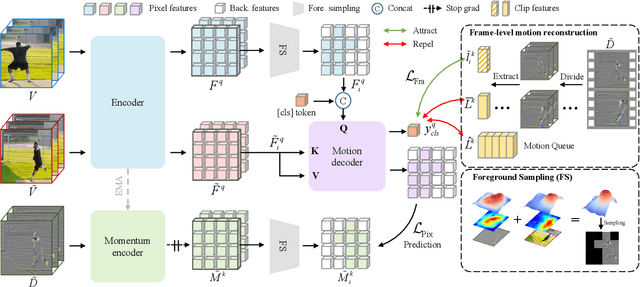
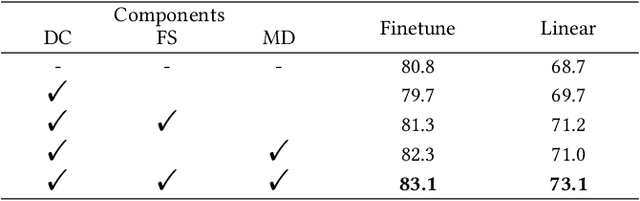
As the most essential property in a video, motion information is critical to a robust and generalized video representation. To inject motion dynamics, recent works have adopted frame difference as the source of motion information in video contrastive learning, considering the trade-off between quality and cost. However, existing works align motion features at the instance level, which suffers from spatial and temporal weak alignment across modalities. In this paper, we present a \textbf{Fi}ne-grained \textbf{M}otion \textbf{A}lignment (FIMA) framework, capable of introducing well-aligned and significant motion information. Specifically, we first develop a dense contrastive learning framework in the spatiotemporal domain to generate pixel-level motion supervision. Then, we design a motion decoder and a foreground sampling strategy to eliminate the weak alignments in terms of time and space. Moreover, a frame-level motion contrastive loss is presented to improve the temporal diversity of the motion features. Extensive experiments demonstrate that the representations learned by FIMA possess great motion-awareness capabilities and achieve state-of-the-art or competitive results on downstream tasks across UCF101, HMDB51, and Diving48 datasets. Code is available at \url{https://github.com/ZMHH-H/FIMA}.
Gap and Overlap Detection in Automated Fiber Placement
Sep 01, 2023The identification and correction of manufacturing defects, particularly gaps and overlaps, are crucial for ensuring high-quality composite parts produced through Automated Fiber Placement (AFP). These imperfections are the most commonly observed issues that can significantly impact the overall quality of the composite parts. Manual inspection is both time-consuming and labor-intensive, making it an inefficient approach. To overcome this challenge, the implementation of an automated defect detection system serves as the optimal solution. In this paper, we introduce a novel method that uses an Optical Coherence Tomography (OCT) sensor and computer vision techniques to detect and locate gaps and overlaps in composite parts. Our approach involves generating a depth map image of the composite surface that highlights the elevation of composite tapes (or tows) on the surface. By detecting the boundaries of each tow, our algorithm can compare consecutive tows and identify gaps or overlaps that may exist between them. Any gaps or overlaps exceeding a predefined tolerance threshold are considered manufacturing defects. To evaluate the performance of our approach, we compare the detected defects with the ground truth annotated by experts. The results demonstrate a high level of accuracy and efficiency in gap and overlap segmentation.
Learned Visual Features to Textual Explanations
Sep 01, 2023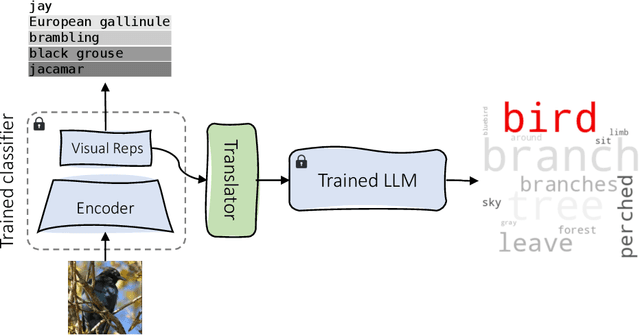

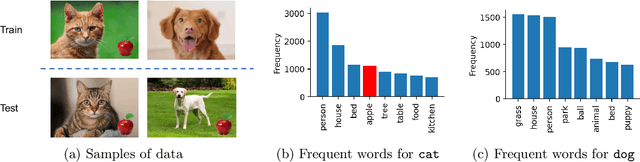

Interpreting the learned features of vision models has posed a longstanding challenge in the field of machine learning. To address this issue, we propose a novel method that leverages the capabilities of large language models (LLMs) to interpret the learned features of pre-trained image classifiers. Our method, called TExplain, tackles this task by training a neural network to establish a connection between the feature space of image classifiers and LLMs. Then, during inference, our approach generates a vast number of sentences to explain the features learned by the classifier for a given image. These sentences are then used to extract the most frequent words, providing a comprehensive understanding of the learned features and patterns within the classifier. Our method, for the first time, utilizes these frequent words corresponding to a visual representation to provide insights into the decision-making process of the independently trained classifier, enabling the detection of spurious correlations, biases, and a deeper comprehension of its behavior. To validate the effectiveness of our approach, we conduct experiments on diverse datasets, including ImageNet-9L and Waterbirds. The results demonstrate the potential of our method to enhance the interpretability and robustness of image classifiers.
Benchmarking Test-Time Adaptation against Distribution Shifts in Image Classification
Jul 06, 2023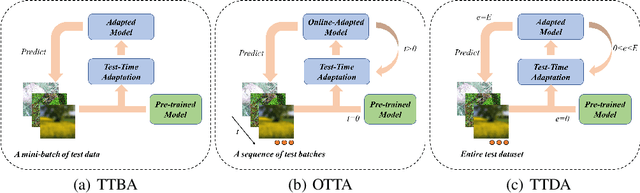

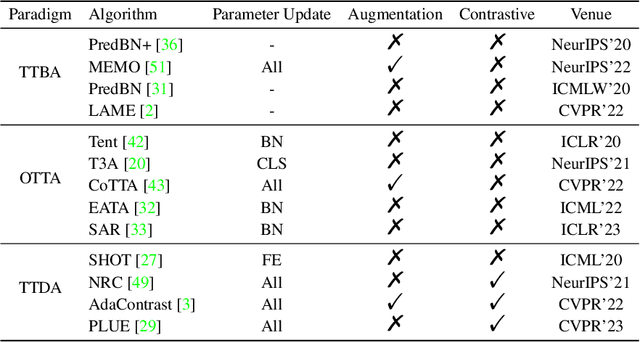
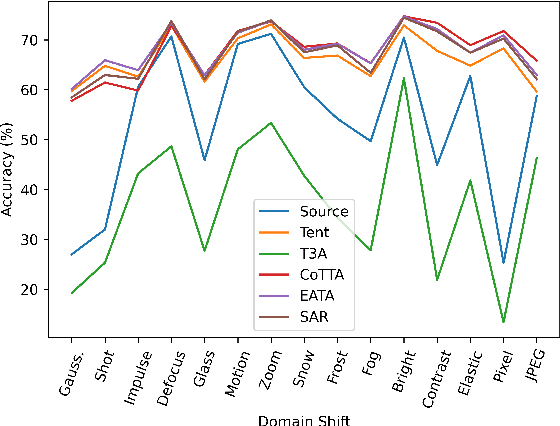
Test-time adaptation (TTA) is a technique aimed at enhancing the generalization performance of models by leveraging unlabeled samples solely during prediction. Given the need for robustness in neural network systems when faced with distribution shifts, numerous TTA methods have recently been proposed. However, evaluating these methods is often done under different settings, such as varying distribution shifts, backbones, and designing scenarios, leading to a lack of consistent and fair benchmarks to validate their effectiveness. To address this issue, we present a benchmark that systematically evaluates 13 prominent TTA methods and their variants on five widely used image classification datasets: CIFAR-10-C, CIFAR-100-C, ImageNet-C, DomainNet, and Office-Home. These methods encompass a wide range of adaptation scenarios (e.g. online adaptation v.s. offline adaptation, instance adaptation v.s. batch adaptation v.s. domain adaptation). Furthermore, we explore the compatibility of different TTA methods with diverse network backbones. To implement this benchmark, we have developed a unified framework in PyTorch, which allows for consistent evaluation and comparison of the TTA methods across the different datasets and network architectures. By establishing this benchmark, we aim to provide researchers and practitioners with a reliable means of assessing and comparing the effectiveness of TTA methods in improving model robustness and generalization performance. Our code is available at https://github.com/yuyongcan/Benchmark-TTA.
Federated Orthogonal Training: Mitigating Global Catastrophic Forgetting in Continual Federated Learning
Sep 03, 2023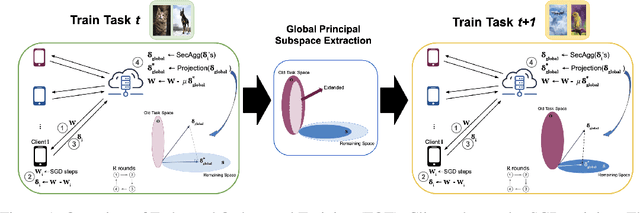
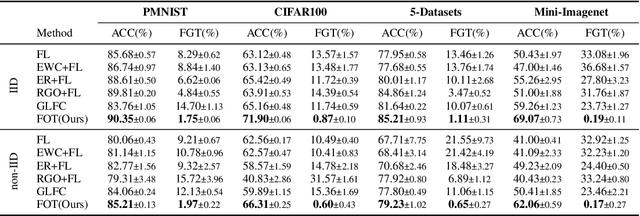
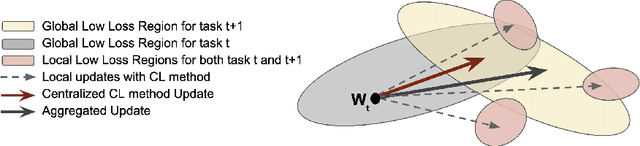
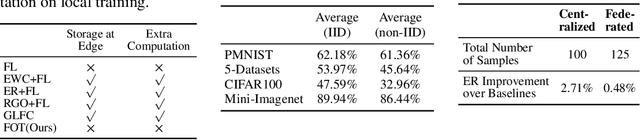
Federated Learning (FL) has gained significant attraction due to its ability to enable privacy-preserving training over decentralized data. Current literature in FL mostly focuses on single-task learning. However, over time, new tasks may appear in the clients and the global model should learn these tasks without forgetting previous tasks. This real-world scenario is known as Continual Federated Learning (CFL). The main challenge of CFL is Global Catastrophic Forgetting, which corresponds to the fact that when the global model is trained on new tasks, its performance on old tasks decreases. There have been a few recent works on CFL to propose methods that aim to address the global catastrophic forgetting problem. However, these works either have unrealistic assumptions on the availability of past data samples or violate the privacy principles of FL. We propose a novel method, Federated Orthogonal Training (FOT), to overcome these drawbacks and address the global catastrophic forgetting in CFL. Our algorithm extracts the global input subspace of each layer for old tasks and modifies the aggregated updates of new tasks such that they are orthogonal to the global principal subspace of old tasks for each layer. This decreases the interference between tasks, which is the main cause for forgetting. We empirically show that FOT outperforms state-of-the-art continual learning methods in the CFL setting, achieving an average accuracy gain of up to 15% with 27% lower forgetting while only incurring a minimal computation and communication cost.