 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Multilayer Perceptron-based Fast Sunlight Assessment for the Conceptual Design of Residential Neighborhoods under Chinese Policy
Aug 15, 2023
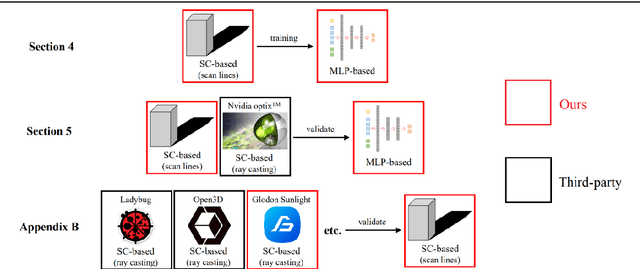
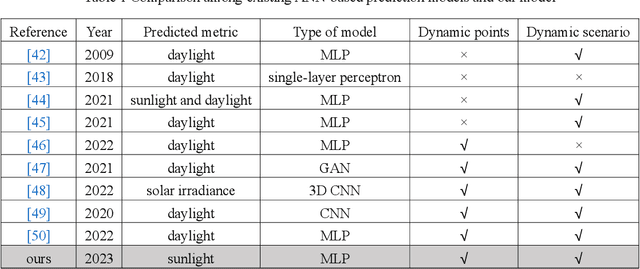
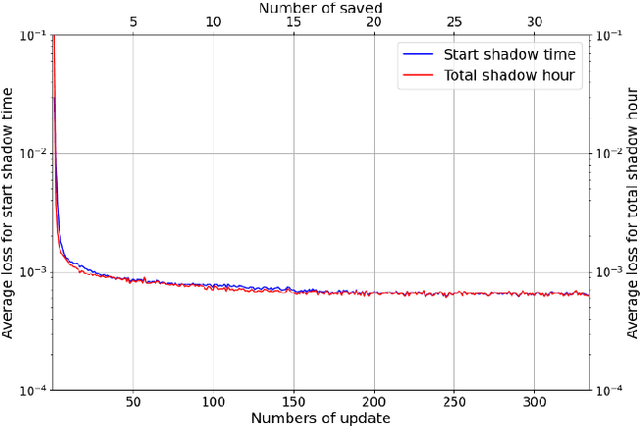

In Chinese building codes, it is required that residential buildings receive a minimum number of hours of natural, direct sunlight on a specified winter day, which represents the worst sunlight condition in a year. This requirement is a prerequisite for obtaining a building permit during the conceptual design of a residential project. Thus, officially sanctioned software is usually used to assess the sunlight performance of buildings. These software programs predict sunlight hours based on repeated shading calculations, which is time-consuming. This paper proposed a multilayer perceptron-based method, a one-stage prediction approach, which outputs a shading time interval caused by the inputted cuboid-form building. The sunlight hours of a site can be obtained by calculating the union of the sunlight time intervals (complement of shading time interval) of all the buildings. Three numerical experiments, i.e., horizontal level and slope analysis, and simulation-based optimization are carried out; the results show that the method reduces the computation time to 1/84~1/50 with 96.5%~98% accuracies. A residential neighborhood layout planning plug-in for Rhino 7/Grasshopper is also developed based on the proposed model. This paper indicates that deep learning techniques can be adopted to accelerate sunlight hour simulations at the conceptual design phase.
Can Authorship Representation Learning Capture Stylistic Features?
Aug 24, 2023Automatically disentangling an author's style from the content of their writing is a longstanding and possibly insurmountable problem in computational linguistics. At the same time, the availability of large text corpora furnished with author labels has recently enabled learning authorship representations in a purely data-driven manner for authorship attribution, a task that ostensibly depends to a greater extent on encoding writing style than encoding content. However, success on this surrogate task does not ensure that such representations capture writing style since authorship could also be correlated with other latent variables, such as topic. In an effort to better understand the nature of the information these representations convey, and specifically to validate the hypothesis that they chiefly encode writing style, we systematically probe these representations through a series of targeted experiments. The results of these experiments suggest that representations learned for the surrogate authorship prediction task are indeed sensitive to writing style. As a consequence, authorship representations may be expected to be robust to certain kinds of data shift, such as topic drift over time. Additionally, our findings may open the door to downstream applications that require stylistic representations, such as style transfer.
Miriam: Exploiting Elastic Kernels for Real-time Multi-DNN Inference on Edge GPU
Jul 10, 2023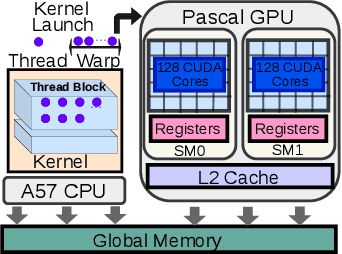

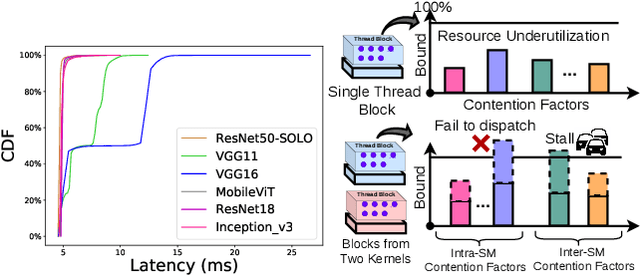

Many applications such as autonomous driving and augmented reality, require the concurrent running of multiple deep neural networks (DNN) that poses different levels of real-time performance requirements. However, coordinating multiple DNN tasks with varying levels of criticality on edge GPUs remains an area of limited study. Unlike server-level GPUs, edge GPUs are resource-limited and lack hardware-level resource management mechanisms for avoiding resource contention. Therefore, we propose Miriam, a contention-aware task coordination framework for multi-DNN inference on edge GPU. Miriam consolidates two main components, an elastic-kernel generator, and a runtime dynamic kernel coordinator, to support mixed critical DNN inference. To evaluate Miriam, we build a new DNN inference benchmark based on CUDA with diverse representative DNN workloads. Experiments on two edge GPU platforms show that Miriam can increase system throughput by 92% while only incurring less than 10\% latency overhead for critical tasks, compared to state of art baselines.
EEG-Derived Voice Signature for Attended Speaker Detection
Aug 28, 2023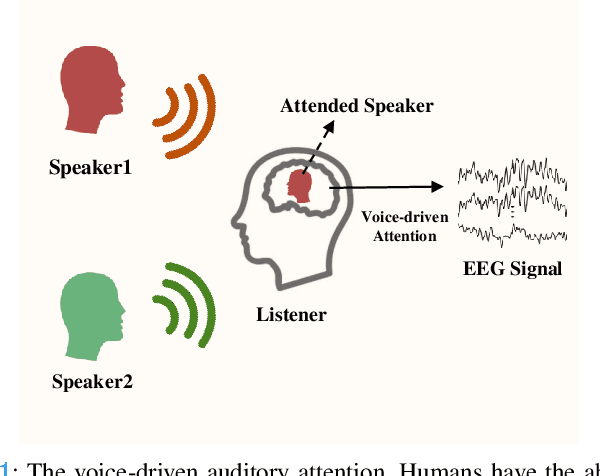
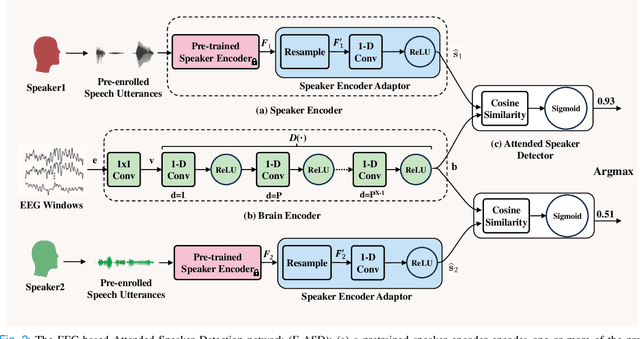
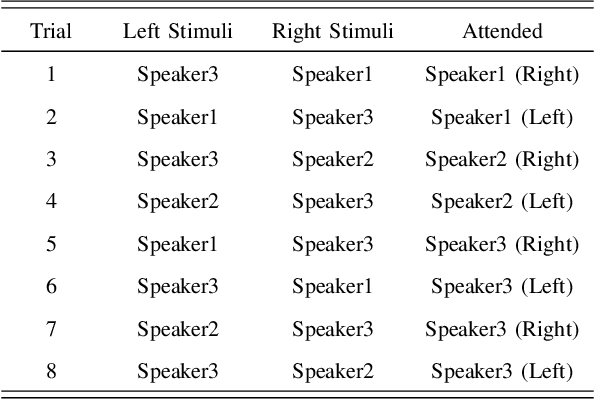
\textit{Objective:} Conventional EEG-based auditory attention detection (AAD) is achieved by comparing the time-varying speech stimuli and the elicited EEG signals. However, in order to obtain reliable correlation values, these methods necessitate a long decision window, resulting in a long detection latency. Humans have a remarkable ability to recognize and follow a known speaker, regardless of the spoken content. In this paper, we seek to detect the attended speaker among the pre-enrolled speakers from the elicited EEG signals. In this manner, we avoid relying on the speech stimuli for AAD at run-time. In doing so, we propose a novel EEG-based attended speaker detection (E-ASD) task. \textit{Methods:} We encode a speaker's voice with a fixed dimensional vector, known as speaker embedding, and project it to an audio-derived voice signature, which characterizes the speaker's unique voice regardless of the spoken content. We hypothesize that such a voice signature also exists in the listener's brain that can be decoded from the elicited EEG signals, referred to as EEG-derived voice signature. By comparing the audio-derived voice signature and the EEG-derived voice signature, we are able to effectively detect the attended speaker in the listening brain. \textit{Results:} Experiments show that E-ASD can effectively detect the attended speaker from the 0.5s EEG decision windows, achieving 99.78\% AAD accuracy, 99.94\% AUC, and 0.27\% EER. \textit{Conclusion:} We conclude that it is possible to derive the attended speaker's voice signature from the EEG signals so as to detect the attended speaker in a listening brain. \textit{Significance:} We present the first proof of concept for detecting the attended speaker from the elicited EEG signals in a cocktail party environment. The successful implementation of E-ASD marks a non-trivial, but crucial step towards smart hearing aids.
Non-autoregressive Conditional Diffusion Models for Time Series Prediction
Jun 08, 2023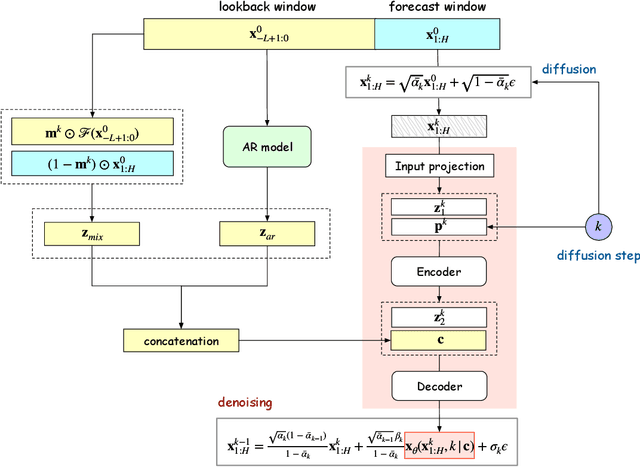
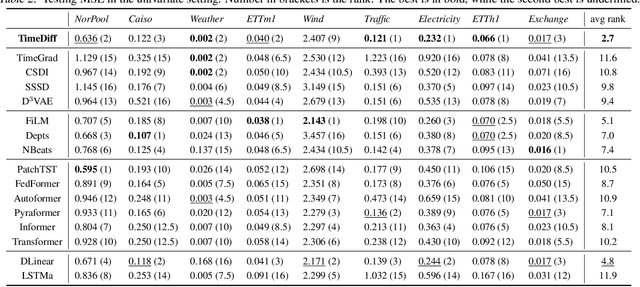
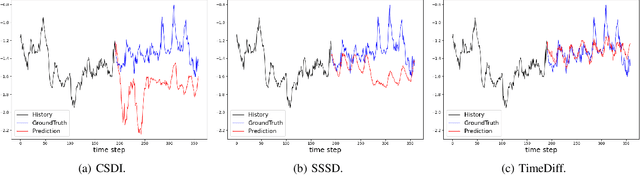
Recently, denoising diffusion models have led to significant breakthroughs in the generation of images, audio and text. However, it is still an open question on how to adapt their strong modeling ability to model time series. In this paper, we propose TimeDiff, a non-autoregressive diffusion model that achieves high-quality time series prediction with the introduction of two novel conditioning mechanisms: future mixup and autoregressive initialization. Similar to teacher forcing, future mixup allows parts of the ground-truth future predictions for conditioning, while autoregressive initialization helps better initialize the model with basic time series patterns such as short-term trends. Extensive experiments are performed on nine real-world datasets. Results show that TimeDiff consistently outperforms existing time series diffusion models, and also achieves the best overall performance across a variety of the existing strong baselines (including transformers and FiLM).
Non-parametric Probabilistic Time Series Forecasting via Innovations Representation
Jun 05, 2023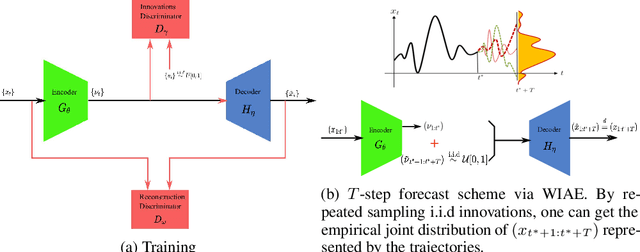
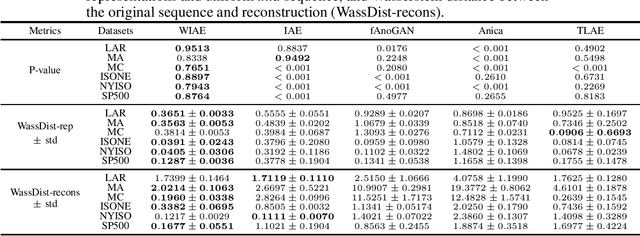
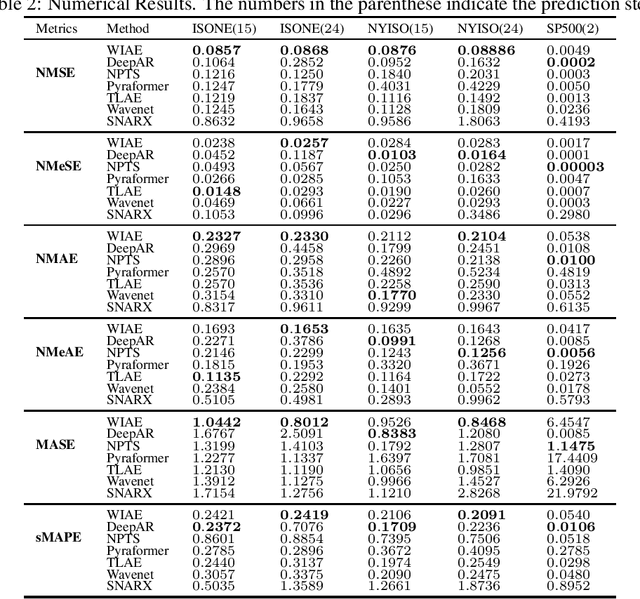
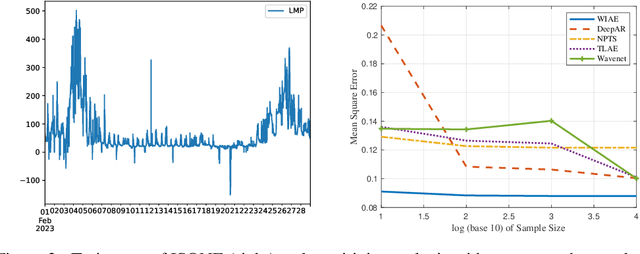
Probabilistic time series forecasting predicts the conditional probability distributions of the time series at a future time given past realizations. Such techniques are critical in risk-based decision-making and planning under uncertainties. Existing approaches are primarily based on parametric or semi-parametric time-series models that are restrictive, difficult to validate, and challenging to adapt to varying conditions. This paper proposes a nonparametric method based on the classic notion of {\em innovations} pioneered by Norbert Wiener and Gopinath Kallianpur that causally transforms a nonparametric random process to an independent and identical uniformly distributed {\em innovations process}. We present a machine-learning architecture and a learning algorithm that circumvent two limitations of the original Wiener-Kallianpur innovations representation: (i) the need for known probability distributions of the time series and (ii) the existence of a causal decoder that reproduces the original time series from the innovations representation. We develop a deep-learning approach and a Monte Carlo sampling technique to obtain a generative model for the predicted conditional probability distribution of the time series based on a weak notion of Wiener-Kallianpur innovations representation. The efficacy of the proposed probabilistic forecasting technique is demonstrated on a variety of electricity price datasets, showing marked improvement over leading benchmarks of probabilistic forecasting techniques.
Neural Differential Recurrent Neural Network with Adaptive Time Steps
Jun 02, 2023

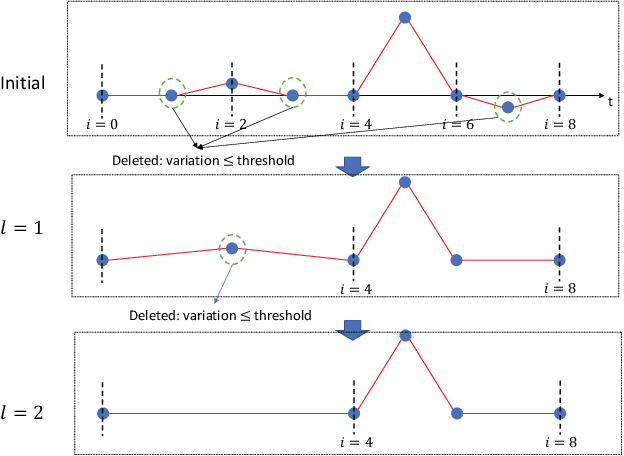
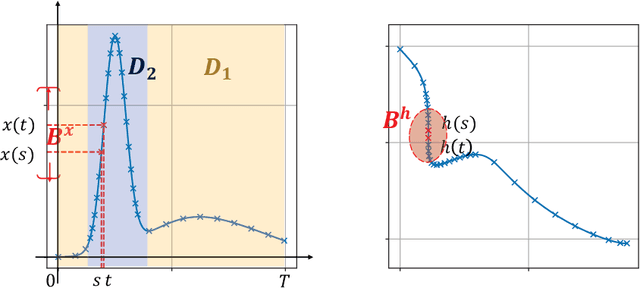
The neural Ordinary Differential Equation (ODE) model has shown success in learning complex continuous-time processes from observations on discrete time stamps. In this work, we consider the modeling and forecasting of time series data that are non-stationary and may have sharp changes like spikes. We propose an RNN-based model, called RNN-ODE-Adap, that uses a neural ODE to represent the time development of the hidden states, and we adaptively select time steps based on the steepness of changes of the data over time so as to train the model more efficiently for the "spike-like" time series. Theoretically, RNN-ODE-Adap yields provably a consistent estimation of the intensity function for the Hawkes-type time series data. We also provide an approximation analysis of the RNN-ODE model showing the benefit of adaptive steps. The proposed model is demonstrated to achieve higher prediction accuracy with reduced computational cost on simulated dynamic system data and point process data and on a real electrocardiography dataset.
PreprintResolver: Improving Citation Quality by Resolving Published Versions of ArXiv Preprints using Literature Databases
Sep 04, 2023The growing impact of preprint servers enables the rapid sharing of time-sensitive research. Likewise, it is becoming increasingly difficult to distinguish high-quality, peer-reviewed research from preprints. Although preprints are often later published in peer-reviewed journals, this information is often missing from preprint servers. To overcome this problem, the PreprintResolver was developed, which uses four literature databases (DBLP, SemanticScholar, OpenAlex, and CrossRef / CrossCite) to identify preprint-publication pairs for the arXiv preprint server. The target audience focuses on, but is not limited to inexperienced researchers and students, especially from the field of computer science. The tool is based on a fuzzy matching of author surnames, titles, and DOIs. Experiments were performed on a sample of 1,000 arXiv-preprints from the research field of computer science and without any publication information. With 77.94 %, computer science is highly affected by missing publication information in arXiv. The results show that the PreprintResolver was able to resolve 603 out of 1,000 (60.3 %) arXiv-preprints from the research field of computer science and without any publication information. All four literature databases contributed to the final result. In a manual validation, a random sample of 100 resolved preprints was checked. For all preprints, at least one result is plausible. For nine preprints, more than one result was identified, three of which are partially invalid. In conclusion the PreprintResolver is suitable for individual, manually reviewed requests, but less suitable for bulk requests. The PreprintResolver tool (https://preprintresolver.eu, Available from 2023-08-01) and source code (https://gitlab.com/ippolis_wp3/preprint-resolver, Accessed: 2023-07-19) is available online.
Short-term power load forecasting method based on CNN-SAEDN-Res
Sep 02, 2023In deep learning, the load data with non-temporal factors are difficult to process by sequence models. This problem results in insufficient precision of the prediction. Therefore, a short-term load forecasting method based on convolutional neural network (CNN), self-attention encoder-decoder network (SAEDN) and residual-refinement (Res) is proposed. In this method, feature extraction module is composed of a two-dimensional convolutional neural network, which is used to mine the local correlation between data and obtain high-dimensional data features. The initial load fore-casting module consists of a self-attention encoder-decoder network and a feedforward neural network (FFN). The module utilizes self-attention mechanisms to encode high-dimensional features. This operation can obtain the global correlation between data. Therefore, the model is able to retain important information based on the coupling relationship between the data in data mixed with non-time series factors. Then, self-attention decoding is per-formed and the feedforward neural network is used to regression initial load. This paper introduces the residual mechanism to build the load optimization module. The module generates residual load values to optimize the initial load. The simulation results show that the proposed load forecasting method has advantages in terms of prediction accuracy and prediction stability.
WSAM: Visual Explanations from Style Augmentation as Adversarial Attacker and Their Influence in Image Classification
Aug 29, 2023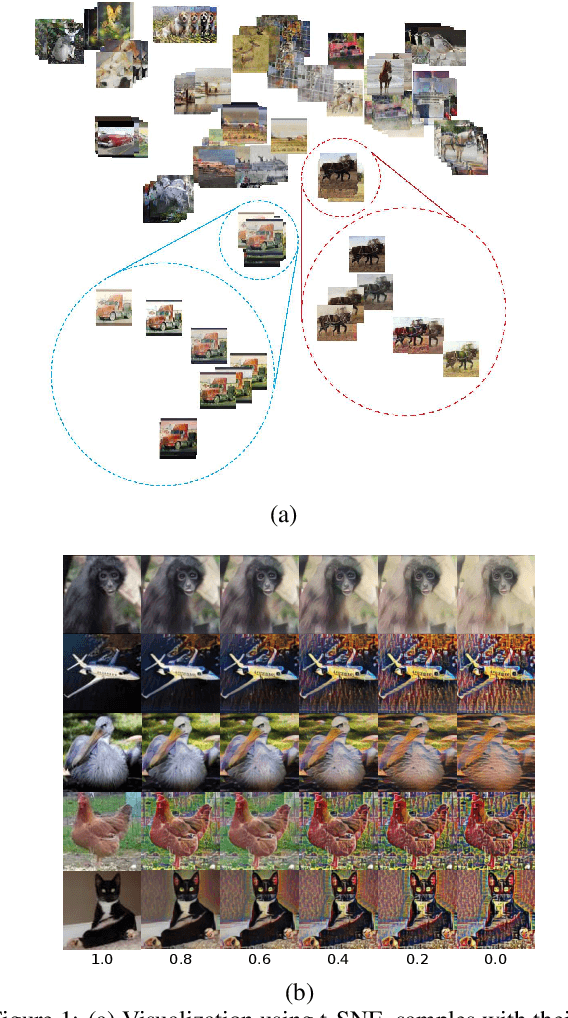

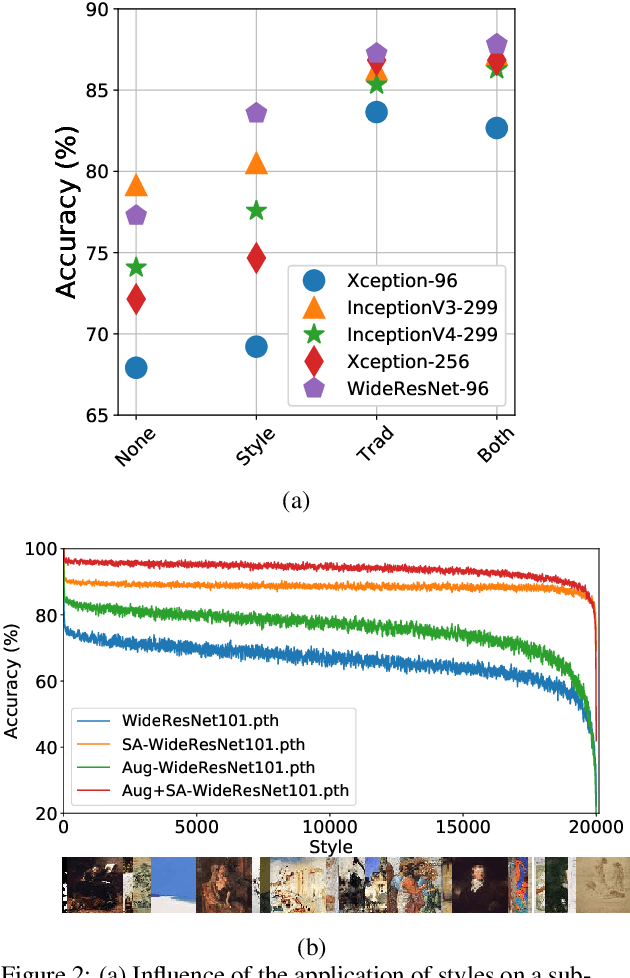
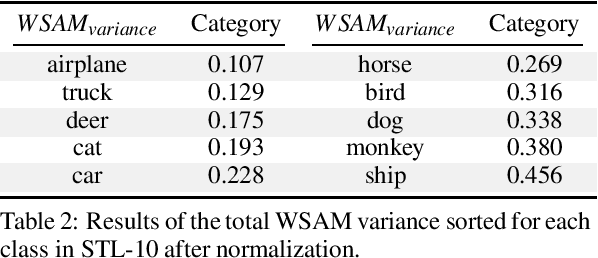
Currently, style augmentation is capturing attention due to convolutional neural networks (CNN) being strongly biased toward recognizing textures rather than shapes. Most existing styling methods either perform a low-fidelity style transfer or a weak style representation in the embedding vector. This paper outlines a style augmentation algorithm using stochastic-based sampling with noise addition to improving randomization on a general linear transformation for style transfer. With our augmentation strategy, all models not only present incredible robustness against image stylizing but also outperform all previous methods and surpass the state-of-the-art performance for the STL-10 dataset. In addition, we present an analysis of the model interpretations under different style variations. At the same time, we compare comprehensive experiments demonstrating the performance when applied to deep neural architectures in training settings.